Monitorare Azure Service Fabric
L'articolo illustra:
- I tipi di dati di monitoraggio che è possibile raccogliere per questo servizio.
- Modi per analizzare i dati.
Nota
Se si ha già familiarità con questo servizio e/o il Monitoraggio di Azure e si vuole solo sapere come analizzare i dati di monitoraggio, vedere la sezione Analizza alla fine di questo articolo.
Quando si hanno applicazioni e processi di business critici che si basano sulle risorse di Azure, è necessario monitorare e ricevere avvisi per il sistema. Il servizio Monitoraggio di Azure raccoglie e aggrega metriche e log da ogni componente del sistema. Il Monitoraggio di Azure offre una visione sulla disponibilità, le prestazioni e la resilienza e notifica i problemi. È possibile usare il portale di Azure, PowerShell, l'interfaccia della riga di comando di Azure, l'API REST o le librerie client per configurare e visualizzare i dati di monitoraggio.
- Per altre informazioni sul monitoraggio di Azure, vedere Informazioni generali sul Monitoraggio di Azure.
- Per altre informazioni su come monitorare le risorse di Azure in generale, vedere Monitorare le risorse di Azure con Monitoraggio di Azure.
Azure Service Fabric include i livelli seguenti che è possibile monitorare:
- Monitoraggio delle applicazioni: le applicazioni eseguite nei nodi. È possibile monitorare le applicazioni con la chiave o l'SDK di Application Insights, EventStore o ASP.NET la registrazione core.
- Monitoraggio della piattaforma (cluster):metriche dei client, dei log e degli eventi per i nodi della piattaforma o del cluster, incluse le metriche dei contenitori. Le metriche e i log sono diversi per i nodi Linux o Windows.
- Monitoraggio dell'infrastruttura (prestazioni): contatori dell'integrità dei servizi e delle prestazioni per l'infrastruttura del servizio.
È possibile monitorare le modalità di utilizzo delle applicazioni, le azioni eseguite dalla piattaforma Service Fabric, l'utilizzo delle risorse con i contatori delle prestazioni e l'integrità generale del cluster. I log di Monitoraggio di Azure e Application Insights offrono l'integrazione predefinita con Service Fabric.
- Per informazioni sulle procedure consigliate, vedere Procedure consigliate per il monitoraggio e la diagnostica per Azure Service Fabric.
- Per un'esercitazione che illustra come visualizzare gli eventi e i report sull'integrità di Service Fabric, eseguire query sulle API EventStore e monitorare i contatori delle prestazioni, vedere Esercitazione: Monitorare un cluster di Service Fabric in Azure.
- Per informazioni su come configurare i log di Monitoraggio di Azure per monitorare i contenitori Windows orchestrati in Service Fabric, vedere Esercitazione: Monitorare i contenitori Windows in Service Fabric con i log di Monitoraggio di Azure.
Service Fabric Explorer, un'applicazione desktop per Windows, macOS e Linux, è uno strumento open source per esaminare e gestire i cluster di Azure Service Fabric. Per abilitare l'automazione, ogni azione eseguibile con Service Fabric Explorer può essere eseguita anche tramite PowerShell o un'API REST.
Il monitoraggio delle applicazioni tiene traccia del modo in cui vengono usati le funzionalità e i componenti dell'applicazione. Con il monitoraggio delle applicazioni è possibile, ad esempio, identificare i problemi che possono incidere sugli utenti. La responsabilità del monitoraggio di un'applicazione è dell'utente che l'ha sviluppata insieme ai relativi servizi, in quanto è esclusivo della logica di business dell'applicazione. Il monitoraggio delle applicazioni può essere utile negli scenari seguenti:
- Quanto traffico si riscontra nell'applicazione? È necessario ridimensionare i servizi per soddisfare le esigenze degli utenti o risolvere un potenziale collo di bottiglia nell'applicazione?
- Le chiamate da servizio a servizio vengono eseguite correttamente e monitorate?
- Quali azioni vengono eseguite dagli utenti dell'applicazione? La raccolta dei dati di telemetria può indirizzare lo sviluppo di funzionalità future e migliorare la diagnostica degli errori delle applicazioni.
- L'applicazione genera eccezioni non gestite?
- Cosa accade all'interno dei servizi eseguiti nei contenitori?
Uno dei lati positivi del monitoraggio delle applicazioni è che gli sviluppatori possono usare gli strumenti e il framework che preferiscono, dato che questa funzionalità è intrinseca al contesto dell'applicazione. Per altre informazioni sulla soluzione di Azure per il monitoraggio delle applicazioni con Monitoraggio di Azure - Application Insights, vedere Analisi degli eventi con Application Insights.
È disponibile anche un'esercitazione su come configurare il monitoraggio per le applicazioni .NET. Questa esercitazione spiega come installare gli strumenti corretti, fornisce un esempio di scrittura dei dati di telemetria personalizzati nell'applicazione e visualizza i dati di diagnostica e telemetria dell'applicazione nel portale di Azure.
La strumentazione del codice non è solo un modo per ottenere informazioni dettagliate sugli utenti, ma anche l'unico modo per sapere se ci sono problemi nell'applicazione e per diagnosticare cosa deve essere corretto. Anche se è tecnicamente possibile connettere un debugger a un servizio di produzione, questa non è una procedura comune. I dati dettagliati di strumentazione sono quindi importanti.
Alcuni prodotti instrumentano automaticamente il codice. Queste soluzioni sono efficaci, ma perché siano specifiche della logica di business applicata è quasi sempre necessaria la strumentazione manuale. Alla fine, è necessario disporre di informazioni sufficienti per eseguire un debug accurato dell'applicazione. È possibile instrumentare le applicazioni di Service Fabric con qualsiasi framework di registrazione. Questa sezione illustra alcuni approcci alla strumentazione del codice e indica quando è consigliabile scegliere un approccio rispetto a un altro.
Application Insights SDK: per impostazione predefinita Application Insights offre un'integrazione avanzata con Service Fabric. Gli utenti possono aggiungere i pacchetti nuget di intelligenza artificiale per Service Fabric e ricevere dati e log creati e raccolti visualizzabili nel portale di Azure. Inoltre, gli utenti sono invitati ad aggiungere i propri dati di telemetria per diagnosticare ed eseguire il debug delle applicazioni e rilevare i servizi e le parti dell'applicazione usate con maggior frequenza. La classe TelemetryClient nell'SDK offre diversi modi per rilevare la telemetria nelle applicazioni. Per altre informazioni, vedere Analisi e visualizzazione degli eventi con Application Insights.
Consultare un esempio su come instrumentare e aggiungere Application Insights nell’esercitazione sul monitoraggio e la diagnostica di un'applicazione .NET.
EventSource: quando si crea una soluzione di Service Fabric da un modello in Visual Studio, viene generata una classe derivata da EventSource (ServiceEventSource o ActorEventSource). Viene creato un modello in cui è possibile aggiungere eventi per l'applicazione o il servizio. Il nome di EventSourcedeve essere univoco e deve essere rinominato dalla stringa del modello predefinito MyCompany-<solution>-<project>. Se esistono più definizioni di EventSource con lo stesso nome, potranno verificarsi errori di runtime. Ogni evento definito deve avere un identificatore univoco. Se un identificatore non è univoco, si verificherà un errore di runtime. Alcune organizzazioni preassegnano intervalli di valori per gli identificatori, in modo da evitare conflitti tra team di sviluppo separati. Per altre informazioni, vedere il blog di Vance o la documentazione di MSDN.
Registrazione di ASP.NET Core: è importante pianificare con attenzione come instrumentare il codice. Il piano di strumentazione corretto può consentire di evitare la potenziale destabilizzazione della codebase e la conseguente necessità di ripetere la strumentazione del codice. Per ridurre il rischio, è possibile scegliere una libreria di strumentazione come Microsoft.Extensions.Logging, inclusa in Microsoft ASP.NET Core. ASP.NET Core ha un'interfaccia ILogger che può essere usata con il provider preferito, riducendo al minimo l'effetto sul codice esistente. È possibile usare il codice in ASP.NET Core in Windows e Linux e in .NET Framework completo, in modo da standardizzare la strumentazione del codice.
Per esempi su come usare questi suggerimenti, vedere Aggiungere la registrazione all'applicazione di Service Fabric.
L'utente ha il controllo dei dati di telemetria che provengono dalla sua applicazione, in quanto si occupa personalmente della scrittura del codice. Ma cosa dire dei dati di diagnostica della piattaforma Service Fabric? Uno dei principali obiettivi di Service Fabric è mantenere le applicazioni resilienti agli errori hardware. Questo obiettivo viene conseguito grazie alla capacità dei servizi di sistema della piattaforma di rilevare eventuali problemi dell'infrastruttura ed eseguire rapidamente il failover dei carichi di lavoro su altri nodi del cluster. In questo caso specifico, tuttavia, cosa accade se sono presenti problemi anche nei servizi di sistema? O se, nel tentativo di distribuire o spostare un carico di lavoro, vengono violate le regole relative al posizionamento dei servizi? Service Fabric offre funzionalità di diagnostica per questi e altri problemi per garantire che l'utente sia sempre informato sulle attività che hanno luogo nel cluster. Ecco alcuni scenari di esempio per il monitoraggio del cluster:
Per altre informazioni sul monitoraggio della piattaforma (cluster), vedere Monitoraggio del cluster.
Service Fabric offre un set completo di eventi di diagnostica predefiniti, a cui è possibile accedere tramite EventStore o il canale eventi operativo esposto dalla piattaforma. Questi eventi di Service Fabric illustrano le azioni eseguite dalla piattaforma su entità diverse, come nodi, applicazioni, servizi e partizioni. Gli stessi eventi sono disponibili sia in cluster di Windows che in cluster di Linux.
Canali eventi di Service Fabric: in Windows, gli eventi di Service Fabric vengono resi disponibili da un singolo provider ETW (Event Tracing for Windows) con un set di
logLevelKeywordFilterspertinenti usati per la selezione tra canali operativi e di dati e messaggistica. Questo è il modo in cui si separano gli eventi di Service Fabric in uscita perché possano essere filtrati in base alle esigenze. In Linux, tutti gli eventi di Service Fabric vengono forniti tramite LTTng e raccolti in una tabella di Archiviazione, da dove possono essere filtrati in base alle esigenze. Questi canali contengono eventi curati e strutturati che consentono di comprendere meglio lo stato del cluster. Il canale di diagnostica è abilitato per impostazione predefinita al momento della creazione di un cluster, nel corso della quale viene creata una tabella di archiviazione di Azure in cui vengono inviati gli eventi generati dai canali, su cui poter eseguire query in futuro.EventStore è una funzionalità che mostra gli eventi della piattaforma di Service Fabric in Service Fabric Explorer e a livello di codice tramite l'API REST della libreria client di Service Fabric. È possibile visualizzare uno snapshot di cosa sta succedendo nel cluster per ogni nodo, servizio, applicazione e query in base all'ora dell'evento. Le API EventStore sono disponibili solo per i cluster Windows eseguiti in Azure. Nei computer Windows, questi eventi vengono inseriti nel registro eventi ed è quindi possibile visualizzare gli eventi di Service Fabric nel Visualizzatore eventi.
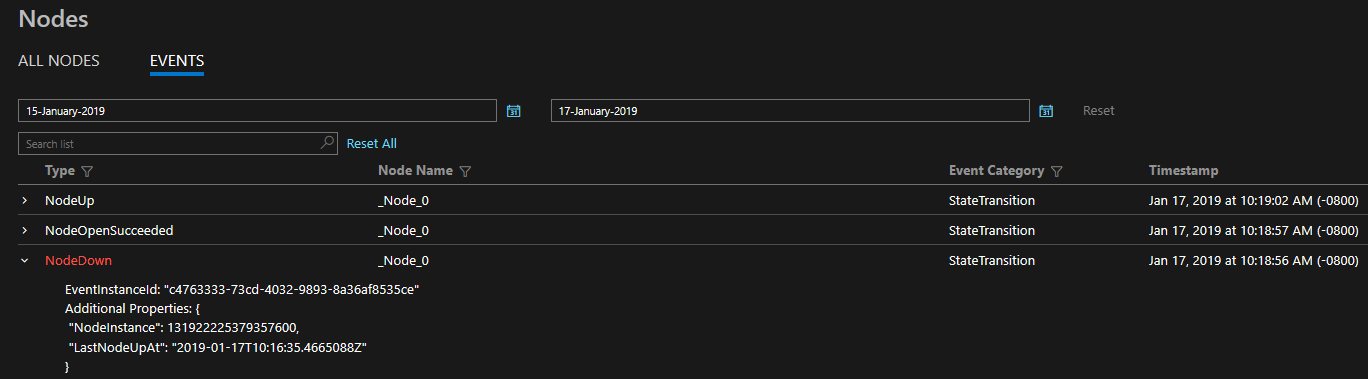
Le funzionalità di diagnostica fornite sono costituite da un set completo di eventi predefiniti. Questi eventi di Service Fabric illustrano le azioni eseguite dalla piattaforma su entità diverse, come Nodi, Applicazioni, Servizi, Partizioni e così via. Nell'ultimo scenario riportato sopra, se un nodo diventasse inattivo, la piattaforma genererebbe un evento NodeDown e si riceverebbe immediatamente una notifica dallo strumento di monitoraggio scelto. Altri esempi comuni sono ApplicationUpgradeRollbackStarted o PartitionReconfigured durante un failover. Gli stessi eventi sono disponibili sia in cluster di Windows che in cluster di Linux.
Gli eventi vengono inviati tramite canali standard sia su Windows che su Linux e possono essere letti da qualsiasi strumento di monitoraggio che li supporti. La soluzione Monitoraggio di Azure è rappresentata dai log di Monitoraggio di Azure. L'integrazione dei log di Monitoraggio di Azure include un dashboard operativo personalizzato per il cluster e alcune query di esempio da cui è possibile creare avvisi. Per altri concetti di monitoraggio del cluster, vedere Monitoraggio del cluster e della piattaforma.
La piattaforma Service Fabric include un modello di integrità che fornisce report di integrità estendibili sullo stato delle entità presenti in un cluster. Ogni nodo, applicazione, servizio, partizione, replica o istanza presenta uno stato di integrità costantemente aggiornabile, che può essere "OK", "Avviso" o "Errore". Gli eventi di Service Fabric possono essere definiti come operazioni eseguite dal cluster sulle varie entità, mentre l'integrità è uno stato che si applica a ogni entità. Ad ogni transizione dell'integrità di una particolare entità viene generato anche un evento. In questo modo è possibile configurare query e avvisi per gli eventi di integrità nello strumento di monitoraggio scelto, come avviene con qualsiasi altro evento.
Gli utenti possono inoltre eseguire l'override dell'integrità delle entità. Se l'applicazione è in fase di aggiornamento e non supera i test di convalida, è possibile scrivere nel servizio di monitoraggio dell'integrità di Service Fabric usando l'API Integrità per indicare che l'applicazione non è più integra. Service Fabric ripristinerà automaticamente lo stato precedente all'aggiornamento. Per altre informazioni sul modello di integrità, vedere Introduzione al monitoraggio dell'integrità di Service Fabric.
In genere, un watchdog è un servizio separato che controlla l'integrità e il carico tra servizi, esegue il ping degli endpoint e crea report di eventi di integrità imprevisti nel cluster. Questo consente di evitare errori che non verrebbero rilevati visualizzando le prestazioni di un singolo servizio. I watchdog possono essere usati anche per ospitare codice che esegue azioni correttive senza l'intervento dell'utente, ad esempio la cancellazione dei file di log nell'archiviazione a specifici intervalli di tempo. Se si vuole un servizio watchdog SF open source completamente implementato che includa un modello di estendibilità watchdog facile da usare ed eseguibile in cluster Windows e Linux, vedere il progetto FabricObserver. FabricObserver è un software pronto per la produzione. È consigliabile distribuire FabricObserver nei cluster di test e di produzione ed estenderlo per soddisfare le proprie esigenze tramite il modello plug-in o tramite la creazione di fork e la scrittura di osservatori predefiniti. Il primo (plug-in) è l'approccio consigliato.
Ora che conosciamo le funzionalità di diagnostica disponibili nell'applicazione e nella piattaforma, come possiamo stabilire se l'hardware funziona nel modo previsto? Il monitoraggio dell'infrastruttura sottostante è un fattore essenziale per conoscere lo stato del cluster e le modalità di utilizzo delle risorse. La misurazione delle prestazioni del sistema dipende da numerosi fattori che possono essere soggettivi a seconda dei carichi di lavoro. Questi fattori vengono in genere misurati tramite contatori delle prestazioni. Questi contatori delle prestazioni possono avere varie origini, ad esempio il sistema operativo, .NET Framework o la piattaforma Service Fabric stessa. Ecco alcuni scenari in cui possono essere utili.
- L'hardware viene utilizzato in modo efficiente? Si può scegliere di usare l'hardware al 90% della CPU o al 10%. Risulta utile quando occorre ridimensionare il cluster o ottimizzare i processi dell'applicazione.
- È possibile prevedere i problemi dell'infrastruttura in modo proattivo? Molti problemi sono preceduti da improvvise variazioni (cali) delle prestazioni, quindi è possibile usare contatori delle prestazioni come l'I/O di rete e l'utilizzo della CPU per anticipare e diagnosticare eventuali problemi in modo proattivo.
Un elenco dei contatori delle prestazioni che è possibile raccogliere a livello di infrastruttura è disponibile in Metriche delle prestazioni.
I log di Monitoraggio di Azure sono la soluzione consigliata per monitorare gli eventi a livello di cluster. Dopo aver configurato l'agente di Log Analytics con l'area di lavoro, è possibile raccogliere:
- Metriche delle prestazioni, ad esempio utilizzo della CPU.
- Contatori delle prestazioni .NET, ad esempio l'utilizzo della CPU a livello di processo.
- Contatori delle prestazioni di Service Fabric, ad esempio il numero di eccezioni di un servizio Reliable Services.
- Metriche del contenitore, ad esempio Utilizzo della CPU.
Azure usa il concetto di tipi di risorse e ID per identificare tutti gli elementi in una sottoscrizione. I tipi di risorse fanno anche parte degli ID della risorsa per ogni risorsa in esecuzione in Azure. Ad esempio, un tipo di risorsa per una macchina virtuale è Microsoft.Compute/virtualMachines. Per un elenco dei servizi e dei relativi tipi di risorse associati, vedere Provider di risorse.
Il Monitoraggio di Azure organizza in modo analogo i dati di monitoraggio di base in metriche e log in base ai tipi di risorse, detti anche spazi dei nomi. Sono disponibili metriche e log diversi per diversi tipi di risorse. Il servizio potrebbe essere associato a più tipi di risorse.
Per altre informazioni sui tipi di risorse per Azure Service Fabric, vedere Informazioni di riferimento sui dati di monitoraggio di Service Fabric.
Per il Monitoraggio di Azure:
- I dati delle metriche vengono archiviati dal database di metriche del Monitoraggio di Azure.
- I dati di log vengono archiviati nell'archivio dei log del Monitoraggio di Azure. Log Analytics è uno strumento nel portale di Azure in grado di eseguire query su questo archivio.
- Il log attività di Azure è un archivio separato con la propria interfaccia nel portale di Azure.
Facoltativamente, è possibile instradare i dati delle metriche e dei log attività all'archivio dei log di Monitoraggio di Azure. È quindi possibile usare Analisi dei log per eseguire query sui dati e correlarli con altri dati di log.
Molti servizi possono usare le impostazioni di diagnostica per inviare i dati delle metriche e dei log ad altre posizioni di archiviazione all'esterno di Monitoraggio di Azure. Gli esempi includono Archiviazione di Azure, sistemi partner ospitati e sistemi partner non Azure usando Hub eventi.
Per informazioni dettagliate su come il Monitoraggio di Azure archivia i dati, vedere la piattaforma dati del Monitoraggio di Azure.
Monitoraggio di Azure offre metriche della piattaforma per molti servizi. Per un elenco di tutte le metriche che è possibile raccogliere per tutte le risorse nel Monitoraggio di Azure, vedere Metriche supportate nel Monitoraggio di Azure.
Questo servizio non raccoglie le metriche della piattaforma.
Questo servizio fornisce altre metriche non incluse nel database delle metriche di Monitoraggio di Azure.
Le metriche per il sistema operativo guest in esecuzione nei nodi del cluster di Service Fabric devono essere raccolte tramite uno o più agenti eseguiti nel sistema operativo guest. Le metriche del sistema operativo guest includono contatori delle prestazioni che tengono traccia della percentuale di CPU o dell'utilizzo della memoria guest, entrambi usati di frequente per la scalabilità automatica o gli avvisi.
Una procedura consigliata consiste nell'usare e configurare l'agente di Monitoraggio di Azure per inviare metriche delle prestazioni del sistema operativo guest tramite l'API delle metriche personalizzate nel database delle metriche di Monitoraggio di Azure. È possibile inviare le metriche del sistema operativo guest ai log di Monitoraggio di Azure usando lo stesso agente. È quindi possibile eseguire query su tali metriche e log usando Log Analytics.
Nota
L'agente di Monitoraggio di Azure sostituisce l'estensione Diagnostica di Azure e l'agente di Log Analytics per il routing del sistema operativo guest. Per altre informazioni, vedere Panoramica degli agenti di Monitoraggio di Azure.
I log delle risorse forniscono informazioni dettagliate sulle operazioni eseguite da una risorsa di Azure. I log vengono generati automaticamente, ma è necessario indirizzarli ai log di Monitoraggio di Azure per salvarli o eseguirne query. I log e sono organizzati in categorie. Uno spazio dei nomi può avere più categorie di log delle risorse che è possibile raccogliere.
Questo servizio non raccoglie i log delle risorse, ma è possibile trovare informazioni su di esse in Monitoraggio dei dati dalle risorse di Azure.
Service Fabric può raccogliere i log seguenti:
- Per i cluster Windows, è possibile configurare il monitoraggio del cluster con l'agente di diagnostica e i log di Monitoraggio di Azure.
- Anche per i cluster Linux, lo strumento consigliato per il monitoraggio dell'infrastruttura e della piattaforma Azure è Log di Monitoraggio di Azure. La diagnostica della piattaforma Linux richiede una configurazione diversa. Per altre informazioni, vedere Eventi del cluster Linux di Service Fabric in Syslog.
- È possibile configurare l'agente di Monitoraggio di Azure per inviare i log del sistema operativo guest ai log di Monitoraggio di Azure, in cui è possibile eseguire query su di essi usando Log Analytics.
- È possibile scrivere log dei contenitori di Service Fabric in stdout o stderr in modo che siano disponibili nei log di Monitoraggio di Azure.
- È possibile configurare la soluzione di monitoraggio dei contenitori per i log di Monitoraggio di Azure per visualizzare gli eventi del contenitore.
Anche se le due soluzioni consigliate, log di Monitoraggio di Azure eApplication Insights, includono l'integrazione predefinita con Service Fabric, molti eventi vengono scritti tramite provider ETW e sono estendibili con altre soluzioni di registrazione. È opportuno prendere in considerazione anche Elastic Stack, soprattutto se si intende eseguire un cluster in un ambiente offline, Dynatrace o qualsiasi altra piattaforma preferita. Per un elenco dei partner integrati, vedere Partner di monitoraggio di Azure Service Fabric.
Nella scelta della piattaforma si deve considerare la familiarità con l'interfaccia utente, le funzionalità di query, le visualizzazioni personalizzate e i dashboard disponibili e gli strumenti aggiuntivi offerti per migliorare l'esperienza di monitoraggio.
Il log attività contiene eventi a livello di sottoscrizione che tengono traccia delle operazioni per ogni risorsa di Azure vista dall'esterno, ad esempio la creazione di una nuova risorsa o l'avvio di una macchina virtuale.
Raccolta: gli eventi del log attività vengono generati e raccolti automaticamente in un archivio separato per la visualizzazione nel portale di Azure.
Pianificazione percorso: è possibile inviare i dati del log attività ai log di Monitoraggio di Azure in modo da poterli analizzare insieme ad altri dati di log. Sono disponibili anche altre posizioni, ad esempio Archiviazione di Azure, Hub eventi di Azure e alcuni partner di monitoraggio Microsoft. Per altre informazioni su come instradare i log attività, vedere Informazioni generali sul log attività di Azure.
Sono disponibili molti strumenti per l'analisi dei dati di monitoraggio.
Il Monitoraggio di Azure supporta gli strumenti di base seguenti:
Esplora metriche, uno strumento nel portale di Azure che consente di visualizzare e analizzare le metriche per le risorse di Azure. Per altre informazioni, vedere Analizzare le metriche con Esplora metriche di Monitoraggio di Azure.
Log Analytics, uno strumento nel portale di Azure che consente di eseguire query e analizzare i dati di log usando il linguaggio di query Kusto (KQL). Per altre informazioni, vedere Introduzione alle query dei log del Monitoraggio di Azure.
Log attività, che dispone di un'interfaccia utente nel portale di Azure per la visualizzazione e le ricerche di base. Per eseguire analisi più approfondite, è necessario instradare i dati verso i log di Monitoraggio di Azure ed eseguire query più complesse in Log Analytics.
Gli strumenti che consentono una visualizzazione più complessa includono:
- I dashboard che consentono di combinare tipi di dati diversi in un singolo riquadro nel portale di Azure.
- Cartelle di lavoro, report personalizzabili che è possibile creare nel portale di Azure. Le cartelle di lavoro possono includere testo, metriche e query di log.
- Grafana è una piattaforma aperta, ideale per i dashboard operativi. È possibile usare Grafana per creare dashboard che includano dati da più origini diverse dal Monitoraggio di Azure.
- Power BI, un servizio di analisi aziendale che fornisce visualizzazioni interattive per un'ampia varietà di origini dati. È possibile configurare per Power BI per importare automaticamente i dati di log da Monitoraggio di Azure per sfruttare i vantaggi di queste visualizzazioni.
Per una panoramica degli scenari di analisi di monitoraggio comuni di Service Fabric, vedere Diagnosticare scenari comuni con Service Fabric.
È possibile ottenere dati dal Monitoraggio di Azure in altri strumenti usando i metodi seguenti:
Metriche: usare l'API REST per le metriche per estrarre i dati delle metriche dal database delle metriche del Monitoraggio di Azure. L'API supporta espressioni di filtro per perfezionare i dati recuperati. Per altre informazioni, vedere Informazioni di riferimento sull'API REST del Monitoraggio di Azure.
Log: usare l'API REST o le librerie client associate.
Un'altra opzione è l'esportazione dati dell'area di lavoro.
Per iniziare a usare l'API REST per il Monitoraggio di Azure, vedere Procedura dettagliata per l'API REST del Monitoraggio di Azure.
È possibile analizzare i dati di monitoraggio nell'archivio dei Log/Log Analytics del Monitoraggio di Azure usando il linguaggio di query Kusto (KQL).
Importante
Quando si seleziona Log dal menu del servizio nel portale, Analisi dei log si apre con l'ambito della query impostato sul servizio corrente. Questo ambito fa sì che le query di log includano solo i dati di tale tipo di risorsa. Se si vuole eseguire una query che includa dati di altri servizi di Azure, selezionare Log nel menu di Monitoraggio di Azure. Per i dettagli, vedere Ambito e intervallo di tempo delle query su log in Log Analytics di Monitoraggio di Azure.
Per un elenco delle query comuni per qualsiasi servizio, vedere l'interfaccia query di Analisi dei log.
Le query seguenti restituiscono eventi di Service Fabric, incluse le azioni nei nodi. Per altre query utili, vedere Eventi di Service Fabric.
Restituire gli eventi operativi registrati nell'ultima ora:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Restituire i report di integrità con HealthState == 3 (Errore) ed estrarre altre proprietà dal campo EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Ottenere gli eventi operativi di Service Fabric aggregati con il servizio e il nodo specificati:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Gli avvisi di Monitoraggio di Azure notificano in modo proattivo quando vengono riscontrate condizioni specifiche nei dati di monitoraggio. Consentono di identificare e risolvere i problemi del sistema prima che gli utenti li notino. Per altre informazioni, vedere Avvisi di Monitoraggio di Azure.
Esistono molte origini di avvisi comuni per le risorse di Azure. Per esempi di avvisi comuni per le risorse di Azure, vedere Query di avviso di log di esempio. Il sito Avvisi di base di Monitoraggio di Azure (AMBA) offre un metodo semi-automatizzato per implementare importanti avvisi, dashboard e linee guida per le metriche della piattaforma. Il sito si applica a un sottoinsieme di servizi di Azure in continua espansione, inclusi tutti i servizi che fanno parte della zona di destinazione di Azure.
Lo schema di avviso comune standardizza l'utilizzo delle notifiche di avviso di Monitoraggio di Azure. Per altre informazioni, vedere lo Schema degli avvisi comuni.
È possibile creare avvisi su qualsiasi metrica o fonte di dati di log nella piattaforma di dati di Monitoraggio di Azure. Esistono molti tipi diversi di avvisi a seconda dei servizi monitorati e dei dati di monitoraggio raccolti. Ogni tipo di avviso presenta vantaggi e svantaggi. Per altre informazioni, vedere Scegliere il tipo di avviso di monitoraggio corretto.
L'elenco seguente descrive i tipi di avvisi del Monitoraggio di Azure che è possibile creare:
- Gli avvisi delle metriche valutano le metriche delle risorse a intervalli regolari. Le metriche possono essere metriche della piattaforma, metriche personalizzate, log di Monitoraggio di Azure convertiti in metriche o metriche di Application Insights. Gli avvisi delle metriche possono anche applicare più condizioni e soglie dinamiche.
- Gli avvisi relativi ai log consentono agli utenti di utilizzare una query di Log Analytics per valutare i log delle risorse con una frequenza predefinita.
- Gli avvisi dei log attività vengono attivati quando si verifica un nuovo evento del log attività che soddisfa le condizioni definite. Gli avvisi sull'integrità delle risorse e gli avvisi sull'integrità dei servizi sono avvisi di log delle attività che segnalano l'integrità dei servizi e delle risorse.
Alcuni servizi di Azure supportano anche avvisi di rilevamento intelligente, avvisi Prometheus o regole di avviso consigliate.
Per alcuni servizi, è possibile effettuare un monitoraggio su larga scala applicando la stessa regola di avviso delle metriche a più risorse dello stesso tipo presenti nella stessa area di Azure. Vengono inviate notifiche singole per ogni risorsa monitorata. Per i servizi e i cloud di Azure supportati, vedere Monitorare più risorse con una regola di avviso.
Nella tabella seguente sono elencate alcune regole di avviso per Service Fabric. Questi avvisi sono solo esempi. È possibile impostare avvisi per qualsiasi voce di metrica, voce di log o log attività elencata nel riferimento ai dati di monitoraggio di Service Fabric o nell'elenco di eventi di Service Fabric.
| Tipo di avviso | Condizione | Descrizione |
|---|---|---|
| Evento Node | Il nodo diventa inattivo | ServiceFabricOperationalEvent dove EventID >= 25622 e EventID <= 25626. Questi ID evento sono inclusi nella documentazione di riferimento sugli eventi dei nodi. |
| Dati del log | Application aggiornamento-ripristino dello stato precedente | ServiceFabricOperationalEvent dove EventID == 29623 o EventID == 29624. Questi ID evento sono inclusi nella documentazione di riferimento sugli eventi dell'applicazione. |
| Integrità delle risorse | Aggiornamento del servizio non raggiungibile/non disponibile | Il cluster passa allo stato UpgradeServiceUnreachable. |
Per alcuni servizi, se si verificano condizioni critiche o modifiche imminenti durante le operazioni sulle risorse, viene visualizzato un avviso nella pagina Panoramica del servizio nel portale. È possibile trovare altre informazioni e correzioni consigliate per l'avviso in Consigli di Advisor in Monitoraggio nel menu a sinistra. Durante il normale funzionamento non viene visualizzato nessun consiglio di Advisor.
Per altre informazioni su Azure Advisor, vedere Informazioni generali su Azure Advisor.
Completata la descrizione di ogni area di monitoraggio, con i relativi scenari di esempio, ecco un riepilogo degli strumenti di monitoraggio di Azure e della configurazione necessari per monitorare tutte queste aree.
- Monitoraggio delle applicazioni con Application Insights
- Monitoraggio del cluster con l'agente di diagnostica e i log di Monitoraggio di Azure
- Monitoraggio dell'infrastruttura con i log di Monitoraggio di Azure
È anche possibile usare e modificare il modello ARM di esempio per automatizzare la distribuzione di tutte le risorse e gli agenti necessari.
- Per informazioni di riferimento sulle metriche, i log e altri valori importanti creati per Service Fabric, vedere Informazioni di riferimento sui dati di monitoraggio del Service Fabric.
- Per informazioni generali sul monitoraggio delle risorse di Azure, vedere Monitoraggio delle risorse di Azure con Monitoraggio di Azure.
- Vedere l'Elenco degli eventi di Service Fabric.