Creare un endpoint server di Sincronizzazione file di Azure
Articolo
Un endpoint server rappresenta una posizione specifica in un server registrato, ad esempio una cartella in un volume del server. Un endpoint server deve soddisfare le condizioni seguenti:
Un endpoint server deve essere un percorso in un server registrato (anziché una condivisione montata). L'archiviazione NAS (Network Attached Storage) non è supportata.
Anche se l'endpoint server può trovarsi nel volume di sistema, gli endpoint server nel volume di sistema potrebbero non usare il cloud a livelli.
La modifica del percorso o della lettera di unità dopo aver stabilito un endpoint server in un volume non è supportata. Assicurarsi di usare un percorso appropriato prima di creare l'endpoint server.
Un server registrato può supportare più endpoint server, ma un gruppo di sincronizzazione può avere un solo endpoint server per ogni server registrato in qualsiasi momento. Altri endpoint server all'interno del gruppo di sincronizzazione devono trovarsi in server registrati diversi.
Possono esistere più endpoint server nello stesso volume se i relativi spazi dei nomi non si sovrappongono, ad esempio F:\sync1 e F:\sync2, e ogni endpoint effettua la sincronizzazione a un gruppo specifico.
Verificare che sia stato distribuito un servizio di sincronizzazione archiviazione. Per informazioni dettagliate sulla distribuzione di un servizio di sincronizzazione archiviazione, vedere Come distribuire Sincronizzazione file di Azure.
Verificare che il server sia connesso a Internet e che Azure sia accessibile. Sincronizzazione file di Azure usa la porta 443 per tutte le comunicazioni tra il server e il servizio cloud.
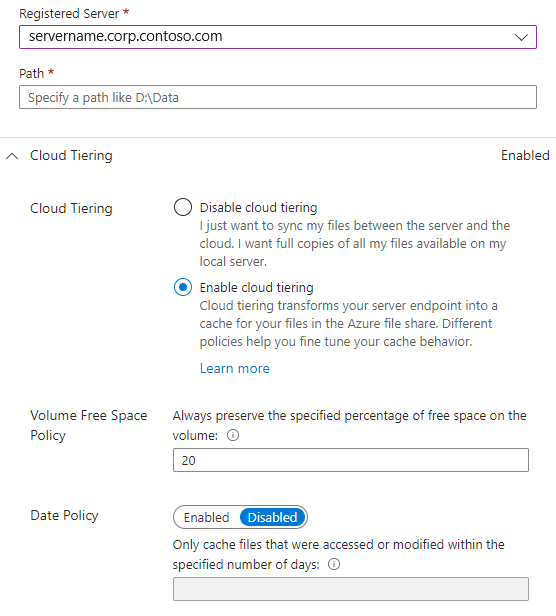
Per aggiungere un endpoint server, passare al gruppo di sincronizzazione appena creato. In Endpoint server selezionare +Aggiungi endpoint server. Verrà visualizzato il pannello Aggiungi endpoint server. Per creare un nuovo endpoint server, immettere le informazioni seguenti:
Server registrato: il nome del server o del cluster in cui viene creato l'endpoint server.
Percorso: percorso in Windows Server da sincronizzare con la condivisione file di Azure. Il percorso può essere una cartella (ad esempio, D:\Dati), una radice del volume (ad esempio, D:\) o un punto di montaggio del volume (ad esempio, D:\Montaggio).
Suddivisione in livelli cloud: l'opzione che abilita o disabilita la suddivisione in livelli cloud, che consente di archiviare a livelli in File di Azure i file che si usano o a cui si accede raramente. Quando si abilita il cloud a livelli, è possibile impostare due criteri per comunicare a Sincronizzazione file di Azure quando eseguire l'archiviazione a livelli dei file ad accesso sporadico: Criterio spazio disponibile volume e Criteri data.
Spazio disponibile nel volume: la quantità di spazio disponibile da riservare nel volume in cui si trova l'endpoint server. Se ad esempio lo spazio disponibile nel volume è impostato su 50% per un volume con un singolo endpoint server, circa la metà dei dati viene archiviata a livelli in File di Azure. A prescindere dall'abilitazione o meno della suddivisione in livelli nel cloud, per la condivisione file di Azure è sempre disponibile una copia completa dei dati nel gruppo di sincronizzazione.
Criteri data: i file vengono archiviati a livelli nel cloud se l'utente non vi ha eseguito l'accesso (ovvero operazioni di lettura e scrittura) per il numero di giorni specificato. Ad esempio, se si è notato che i file che a cui non è eseguito l'accesso per più di 15 giorni sono in genere file di archiviazione, è consigliabile impostare i criteri data su 15 giorni.
Sincronizzazione iniziale: la sezione Sincronizzazione iniziale è disponibile solo per il primo endpoint server in un gruppo di sincronizzazione (la sezione diventa in Download iniziale quando si creano più endpoint server in un gruppo di sincronizzazione). Nella sezione Sincronizzazione iniziale è possibile selezionare il comportamento di caricamento iniziale e download iniziale.
Caricamento iniziale: è possibile selezionare il modo in cui il server carica inizialmente i dati nella condivisione file di Azure:
Opzione 1: unire il contenuto di questo percorso del server con il contenuto nella condivisione file di Azure. I file con lo stesso nome e percorso causeranno conflitti se il contenuto è diverso. Le due versioni di tali file verranno archiviate l'una accanto all'altra. Se il percorso del server o la condivisione file di Azure sono vuoti, scegliere sempre questa opzione.
Opzione 2: sovrascrivere in modo autorevole file e cartelle nella condivisione file di Azure con il contenuto di questo percorso del server. Tale opzione consente di evitare conflitti di file.
Download iniziale: è possibile selezionare il modo in cui il server scarica inizialmente i dati della condivisione file di Azure. Questa impostazione è importante quando il server si connette a una condivisione file di Azure e contiene già alcuni file. "Spazio dei nomi" indica la struttura di file e cartelle senza il contenuto dei file. Il contenuto dei file di "file a livelli" viene richiamato dal cloud al server in base all'accesso o ai criteri locali.
Opzione n. 1: scaricare prima lo spazio dei nomi e quindi richiamare il contenuto dei file, in un quantitativo adatto al disco locale.
Opzione 2: scaricare solo lo spazio dei nomi. Il contenuto dei file verrà richiamato all'accesso.
Opzione 3: evitare file a livelli. I file verranno visualizzati nel server solo dopo il download completo.
Per aggiungere l'endpoint server, selezionare Crea. I file vengono ora mantenuti sincronizzati tra la condivisione file di Azure e Windows Server.
Nota
Sincronizzazione file di Azure crea uno snapshot della condivisione file di Azure come backup prima di creare l'endpoint server. Questo snapshot può essere usato per ripristinare lo stato della condivisione prima della creazione dell'endpoint server. Lo snapshot non viene rimosso automaticamente dopo la creazione dell'endpoint server, quindi è possibile eliminarlo manualmente se non è necessario. È possibile trovare gli snapshot creati da Sincronizzazione file di Azure esaminando gli snapshot per la condivisione file di Azure e controllando AzureFileSync nella colonna Iniziatore.
Eseguire i comandi di PowerShell seguenti per creare l'endpoint server e assicurarsi di sostituire <your-server-endpoint-path> e <your-volume-free-space> con i valori desiderati. Controllare le impostazioni per i criteri facoltativi di download iniziale e caricamento iniziale.
$serverEndpointPath = "<your-server-endpoint-path>"
$cloudTieringDesired = $true
$volumeFreeSpacePercentage = <your-volume-free-space>
# Optional property. Choose from: [NamespaceOnly] default when cloud tiering is enabled. [NamespaceThenModifiedFiles] default when cloud tiering is disabled. [AvoidTieredFiles] only available when cloud tiering is disabled.
$initialDownloadPolicy = "NamespaceOnly"
$initialUploadPolicy = "Merge"
# Optional property. Choose from: [Merge] default for all new server endpoints. Content from the server and the cloud merge. This is the right choice if one location is empty or other server endpoints already exist in the sync group. [ServerAuthoritative] This is the right choice when you seeded the Azure file share (e.g. with Data Box) AND you are connecting the server location you seeded from. This enables you to catch up the Azure file share with the changes that happened on the local server since the seeding.
if ($cloudTieringDesired) {
# Ensure endpoint path is not the system volume
$directoryRoot = [System.IO.Directory]::GetDirectoryRoot($serverEndpointPath)
$osVolume = "$($env:SystemDrive)\"
if ($directoryRoot -eq $osVolume) {
throw [System.Exception]::new("Cloud tiering cannot be enabled on the system volume")
}
# Create server endpoint
New-AzStorageSyncServerEndpoint `
-Name $registeredServer.FriendlyName `
-SyncGroup $syncGroup `
-ServerResourceId $registeredServer.ResourceId `
-ServerLocalPath $serverEndpointPath `
-CloudTiering `
-VolumeFreeSpacePercent $volumeFreeSpacePercentage `
-InitialDownloadPolicy $initialDownloadPolicy `
-InitialUploadPolicy $initialUploadPolicy
} else {
# Create server endpoint
New-AzStorageSyncServerEndpoint `
-Name $registeredServer.FriendlyName `
-SyncGroup $syncGroup `
-ServerResourceId $registeredServer.ResourceId `
-ServerLocalPath $serverEndpointPath `
-InitialDownloadPolicy $initialDownloadPolicy
}
# Create a new sync group server endpoint
az storagesync sync-group server-endpoint create --resource-group myResourceGroupName \
--name myNewServerEndpointName
--registered-server-id 91beed22-7e9e-4bda-9313-fec96c286e0
--server-local-path d:\myPath
--storage-sync-service myStorageSyncServiceNAme
--sync-group-name mySyncGroupName
# Create a new sync group server endpoint with additional optional parameters
az storagesync sync-group server-endpoint create --resource-group myResourceGroupName \
--storage-sync-service myStorageSyncServiceName \
--sync-group-name mySyncGroupName \
--name myNewServerEndpointName \
--registered-server-id 91beed22-7e9e-4bda-9313-fec96c286e0 \
--server-local-path d:\myPath \
--cloud-tiering on \
--volume-free-space-percent 85 \
--tier-files-older-than-days 15 \
--initial-download-policy NamespaceOnly [OR] NamespaceThenModifiedFiles [OR] AvoidTieredFiles
--initial-upload-policy Merge [OR] ServerAuthoritative
Sezione Cloud a livelli
Quando si crea un nuovo endpoint server, è possibile acconsentire esplicitamente alla funzionalità di suddivisione in livelli cloud di Sincronizzazione file di Azure. Le opzioni disponibili nella sezione Cloud a livelli possono essere modificate in un secondo momento. Tuttavia, sono disponibili opzioni diverse nella sezione seguente in base al fatto che il cloud a livelli sia abilitato o meno per il nuovo endpoint server.
La sezione Sincronizzazione iniziale è disponibile solo per il primo endpoint server in un gruppo di sincronizzazione. Per qualsiasi endpoint server aggiuntivo, vedere la sezione Download iniziale.
Esistono due comportamenti di sincronizzazione iniziali fondamentalmente diversi:
Unione
Caricamento autorevole
Merge è l'opzione standard e selezionata per impostazione predefinita. È consigliabile lasciare la selezione su merge tranne che per determinati scenari di migrazione.
Quando si aggiunge un percorso del server, nella maggior parte degli scenari la posizione del server o la condivisione cloud è vuota. In questi casi, il Merge è il comportamento corretto e porterà ai risultati previsti.
Quando entrambi i percorsi contengono file e cartelle, gli spazi dei nomi verranno uniti. Se sono presenti file o nomi di cartelle nel server che esistono anche nella condivisione cloud, si verifica un conflitto di sincronizzazione. I conflitti vengono risolti automaticamente.
All'interno dell'opzione merge è necessario selezionare il modo in cui il contenuto della condivisione file di Azure arriverà inizialmente nel server. Questa selezione non ha alcun impatto se la condivisione file di Azure è vuota. Per altri dettagli, vedere il paragrafo successivo: Download iniziale
Caricamento autorevole è un'opzione di sincronizzazione iniziale riservata per uno scenario di migrazione specifico. Sincronizzazione dello stesso percorso del server usato anche per eseguire il seeding della condivisione cloud con ad esempio Azure Data Box. In questo caso, il cloud e le posizioni del server hanno principalmente gli stessi dati, ma il server è leggermente più recente. Gli utenti continuavano a apportare modifiche durante lo spostamento di Data Box. Questo scenario di migrazione richiede quindi di aggiornare il cloud senza problemi con le modifiche nel server (più recente) senza generare conflitti. Il server è quindi l'autorità della forma dello spazio dei nomi e Data Box è stato usato per evitare un caricamento iniziale su larga scala dal server. Il caricamento autorevole del server consente un'adozione senza tempi di inattività del cloud, anche quando è stato usato un meccanismo di trasporto dati offline per eseguire il seeding dell'archiviazione cloud.
Un endpoint server può avere esito positivo solo con l'opzione di caricamento autorevole, quando il percorso del server contiene dati. Questo blocco prevede la protezione da errori di configurazione accidentali. Il caricamento autorevole funziona come RoboCopy /MIR. Questa modalità rispecchia l'origine di destinazione. L'origine è il server AFS e la destinazione è la condivisione cloud. Il caricamento autorevole forma la destinazione nell'immagine dell'origine.
I file e le cartelle nuovi o aggiornati verranno caricati dal server.
I file e le cartelle che non esistono più nel server verranno eliminati dalla condivisione cloud.
Le modifiche solo ai file e alle cartelle nel server verranno spostate in modo efficiente nella condivisione cloud come aggiornamenti di soli metadati.
I file e le cartelle potrebbero esistere nel server e nella condivisione cloud. Tuttavia, alcuni file o cartelle potrebbero aver modificato la directory padre nel server dopo il seeding della condivisione file di Azure. Questi file e cartelle verranno eliminati dalla condivisione cloud e caricati di nuovo. Per questo motivo, è consigliabile evitare di ristrutturare lo spazio dei nomi su larga scala durante una migrazione.
Sezione di download iniziale
La sezione Download iniziale è disponibile per il secondo e per altri endpoint server in un gruppo di sincronizzazione. Il primo endpoint server in un gruppo di sincronizzazione include opzioni aggiuntive correlate alla migrazione con Azure Data Box. Queste opzioni non si applicano se questo endpoint server non è il primo nel gruppo di sincronizzazione.
Nota
La selezione di un'opzione di download iniziale non ha alcun impatto se la condivisione file di Azure è vuota.
Come parte di questa sezione, è possibile scegliere il modo in cui il contenuto della condivisione file di Azure arriverà inizialmente nel server:
Solo spazio dei nomi Porterà solo la struttura di file e cartelle dalla condivisione file di Azure al server locale. Nessuno dei contenuti del file viene scaricato. Questa opzione è l'impostazione predefinita se in precedenza è stata abilitata la suddivisione in livelli cloud per questo nuovo endpoint server.
Prima lo spazio dei nomi, quindi il contenuto Per una maggiore disponibilità dei dati, lo spazio dei nomi viene prima ridotto, indipendentemente dall'impostazione di suddivisione in livelli cloud. Quando lo spazio dei nomi è disponibile nel server, il contenuto del file viene quindi richiamato dal cloud al server. Il richiamo si verifica in base al timestamp dell'ultima modifica in ogni file. Se lo spazio disponibile nel volume del server è inferiore al 10%, i file rimanenti rimarranno a livelli. Questa opzione è l'impostazione predefinita se non è stata attivata la suddivisione in livelli cloud per questo endpoint server.
Evita file a livelli Questa opzione scaricherà tutti i file nella loro interezza prima di visualizzarli nella cartella nel server. Questa opzione consente di evitare l'esistenza di un file a livelli nel server. Un elemento dello spazio dei nomi e il contenuto del file sono sempre presenti contemporaneamente. Evitare questa opzione se il ripristino di emergenza rapido dal cloud è il motivo per cui si crea un endpoint server. Se si dispone di applicazioni che richiedono file completi da presentare e non possono tollerare file a livelli nello spazio dei nomi, è la soluzione ideale. Questa opzione non è disponibile se si usa la suddivisione in livelli cloud per il nuovo endpoint server.
Dopo aver selezionato un'opzione di download iniziale, non è possibile modificarla una volta verificata la creazione dell'endpoint server.
Nota
Quando si aggiunge un endpoint server ed esistono file nella condivisione file di Azure, se si sceglie di scaricare prima lo spazio dei nomi, i file verranno visualizzati come a livelli finché non vengono scaricati in locale. I file vengono scaricati usando un singolo thread per impostazione predefinita per limitare l'utilizzo della larghezza di banda di rete. Per migliorare le prestazioni di download dei file, usare il cmdlet Invoke-StorageSyncFileRecall con un numero di thread maggiore di 1.
Comportamento di download dei file al termine del download iniziale
La modalità di visualizzazione dei file nel server al termine del download iniziale dipende dall'uso della funzionalità di suddivisione in livelli nel cloud e dal fatto che sia stato scelto di richiamare in modo proattivo le modifiche nel cloud. Quest'ultima è una funzionalità utile per i gruppi di sincronizzazione con più endpoint server in posizioni geografiche diverse.
La suddivisione cloud a livelli è abilitata File nuovi e modificati da altri endpoint server verranno visualizzati come file a livelli in questo endpoint server. Queste modifiche verranno gestite come file completi solo se si è scelto il richiamo proattivo delle modifiche nella condivisione file di Azure da altri endpoint server.
La suddivisione cloud a livelli è disabilitata File nuovi e modificati da altri endpoint server verranno visualizzati come file completi in questo endpoint server. Non verranno prima visualizzati come file a livelli e quindi richiamati. I file a livelli con suddivisione cloud a livelli sono una funzionalità di ripristino di emergenza veloce e vengono visualizzati solo durante il provisioning iniziale.
Passaggi di provisioning
Quando viene creato un nuovo endpoint server usando il portale o PowerShell, l'endpoint non è pronto per essere usato immediatamente. A seconda della quantità di dati presenti nella condivisione file corrispondente nel cloud, potrebbero essere necessari alcuni minuti prima che l'endpoint server sia funzionale e pronto per l'uso.
In passato, se si voleva controllare lo stato del provisioning dell'endpoint server e se il server fosse pronto per consentire agli utenti di accedere ai dati, era necessario accedere all'endpoint server e verificare se tutti i dati fossero stati scaricati. Con la procedura di provisioning, è possibile comprendere se un endpoint server è pronto per l'uso o meno e se la sincronizzazione è completamente funzionante direttamente dal portale di Azure, nel pannello Panoramica dell'endpoint server.
Per gli scenari supportati, la scheda Passaggi di provisioning fornisce informazioni su cosa accade nell'endpoint server, incluso quando l'endpoint server è pronto per l'accesso degli utenti.
Scenari supportati
Attualmente, i passaggi di provisioning vengono visualizzati solo quando il nuovo endpoint server aggiunto non contiene dati nel percorso del server selezionato per l'endpoint server. In altri scenari la scheda Passaggi di provisioning non è disponibile.
Stato del provisioning
Ecco i diversi stati visualizzati quando il provisioning degli endpoint server è in corso e il loro significato:
In corso: SEP non è pronto per l'accesso degli utenti.
Pronto (sincronizzazione non funzionale): gli utenti possono accedere ai dati, ma le modifiche non verranno sincronizzate con la condivisione file cloud.
Pronto (funzionalità di sincronizzazione): gli utenti possono accedere ai dati e le modifiche verranno sincronizzate con la condivisione cloud, cosa che rende l'endpoint completamente funzionante.
Operazione non riuscita: il provisioning non è riuscito a causa di un errore.
La scheda Passaggi di provisioning è visibile solo nel portale di Azure per gli scenari supportati. Non sarà disponibile o visibile per gli scenari non supportati.
Passaggi successivi
Sono disponibili altre informazioni sulle condivisioni file di Azure e Sincronizzazione file di Azure. Gli articoli seguenti consentono di comprendere le opzioni avanzate e le procedure consigliate. Forniscono anche assistenza per la risoluzione dei problemi. Questi articoli contengono collegamenti alla Documentazione di Condivisione file di Azure, ove appropriato.