Document Intelligence モデルを使用する
このコンテンツの適用対象: ![]() v3.1 (GA) | 最新バージョン:
v3.1 (GA) | 最新バージョン: ![]() v4.0 (プレビュー) | 以前のバージョン:
v4.0 (プレビュー) | 以前のバージョン: ![]() v3.0
v3.0 ![]() v2.1
v2.1
このコンテンツの適用対象: ![]() v3.0 (GA) | 最新バージョン:
v3.0 (GA) | 最新バージョン: ![]() v4.0 (プレビュー)
v4.0 (プレビュー) ![]() v3.1 | 以前のバージョン:
v3.1 | 以前のバージョン: ![]() v2.1
v2.1
このコンテンツの適用対象: ![]() v2.1 | 最新バージョン:
v2.1 | 最新バージョン: ![]() v4.0 (プレビュー)
v4.0 (プレビュー)
このガイドでは、アプリケーションとワークフローに Document Intelligence モデルを追加する方法について説明します。 任意のプログラミング言語または REST API を使用します。
Azure AI Document Intelligence は、機械学習を使用してドキュメントから主要なテキストと構造体要素を抽出するクラウドベースの Azure AIサービス です。 このテクノロジを学習している間は、無料のサービスを使用することをお勧めします。 無料のページは 1 か月あたり 500 ページに制限されていることに注意してください。
次の Document Intelligence モデルから選択して、フォームとドキュメントからデータと値を分析および抽出します:
事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
readモデルが使用されます。事前構築済みレイアウト モデルは、ドキュメントと画像からテキストとテキストの場所、テーブル、選択マーク、構造体情報を抽出します。 オプションのクエリ文字列パラメーター
features=keyValuePairsが有効になっているレイアウト モデルを使用して、キーと値のペアを抽出できます。prebuilt-contract モデルは、契約合意から重要な情報を抽出します。
prebuilt-healthInsuranceCard.us モデルは、米国の医療保険カードから重要な情報を抽出します。
事前構築済み税務書類モデルは、US 納税申告書で報告された情報を抽出します。
事前構築済み請求書モデルは、さまざまな形式と品質の売上請求書から主なフィールドと品目を抽出します。 フィールドには、電話でキャプチャされた画像、スキャンされたドキュメント、デジタル PDF などが含まれます。
事前構築済み領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
事前構築済み idDocument モデルは、米国の運転免許証、国際パスポートの略歴ページ、米国の州の ID、社会保障カード、永住者カードから重要な情報を抽出します。
- 事前構築済み businessCard モデルは、名刺の画像から重要な情報と連絡先の詳細を抽出します。
クライアント ライブラリ | SDK リファレンス | REST API リファレンス | パッケージ| サンプル|サポートされている REST API バージョン
前提条件
Azure サブスクリプション。無料で作成できます。
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
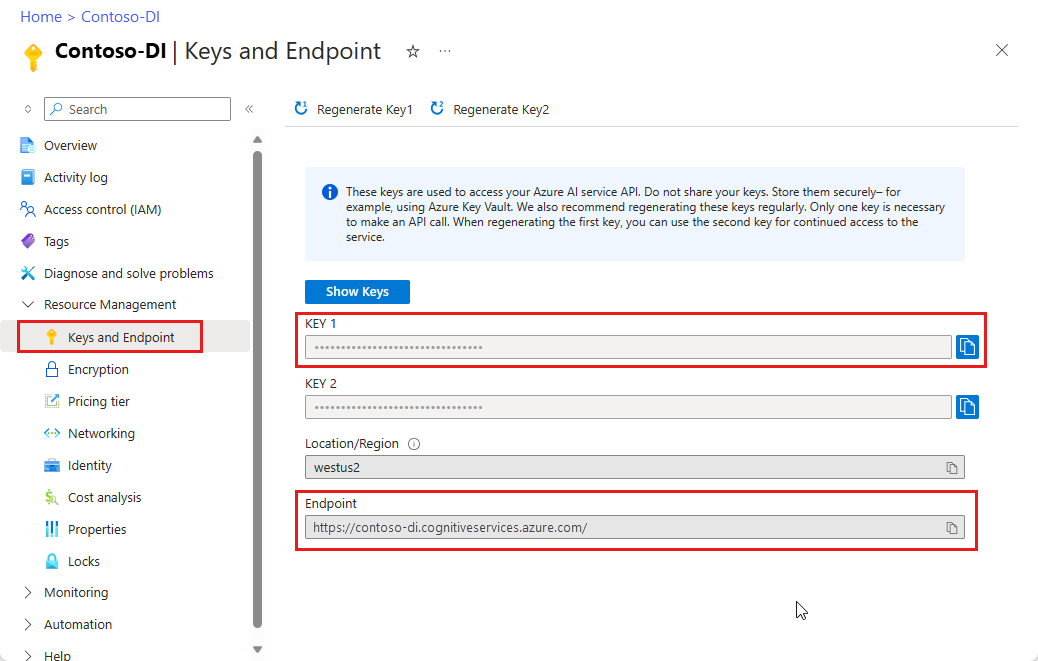
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定された場所にあるドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
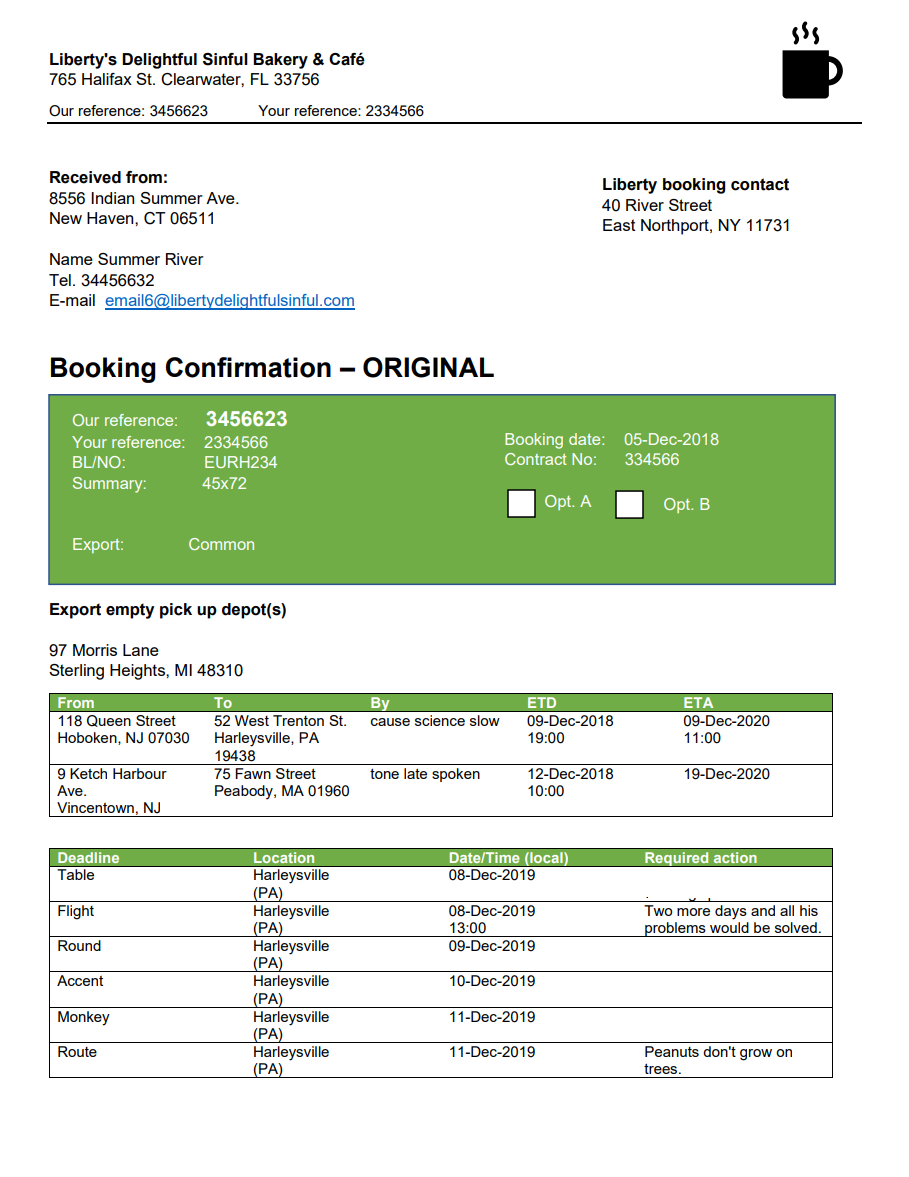
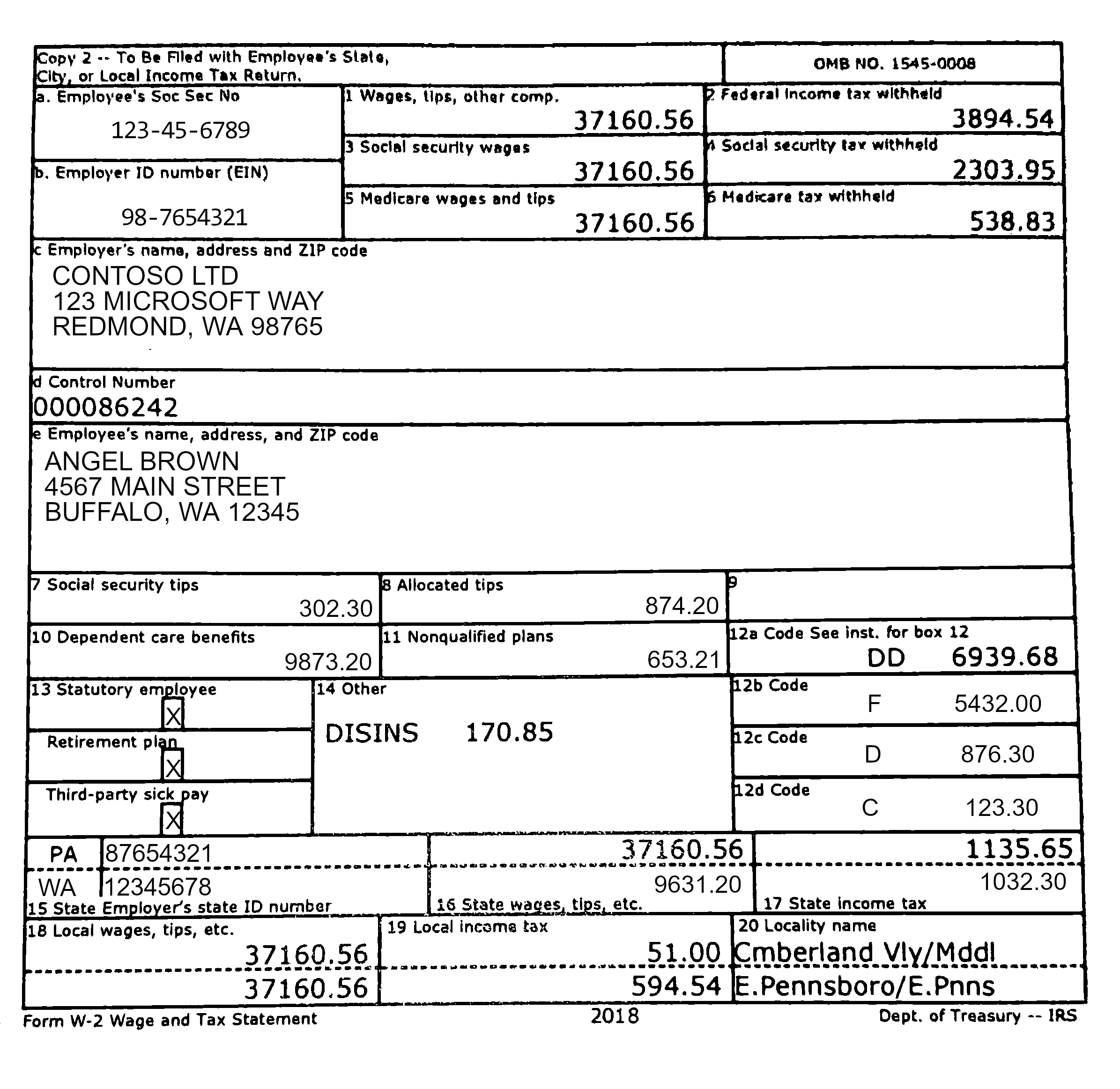
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
Visual Studio を起動します。
スタート ページで、[新しいプロジェクトの作成] を選択します。
[新しいプロジェクトの作成] ページで、検索ボックスに「コンソール」と入力します。 [コンソール アプリケーション] テンプレートを選択し、[次へ] を選択します。
![Visual Studio の [新しいプロジェクトの作成] ページのスクリーンショット。](../media/quickstarts/create-new-project.png?view=doc-intel-4.0.0)
[新しいプロジェクトの構成] ページの [プロジェクト名] に「docIntelligence_app」と入力します。 [次へ] を選択します。
![Visual Studio の [新しいプロジェクトの構成] ページのスクリーンショット。](../media/quickstarts/configure-new-project-console.png?view=doc-intel-4.0.0)
[追加情報] ページで、[.NET 8.0 (長期的なサポート)] を選択し、[作成] を選択します。
![Visual Studio の [追加情報] ページのスクリーンショット。](../media/quickstarts/additional-information.png?view=doc-intel-4.0.0)
NuGet を使用してクライアント ライブラリをインストールする
docIntelligence_app プロジェクトを右クリックし、[Manage NuGet Packages...] (NuGet パッケージの管理...) を選択します。
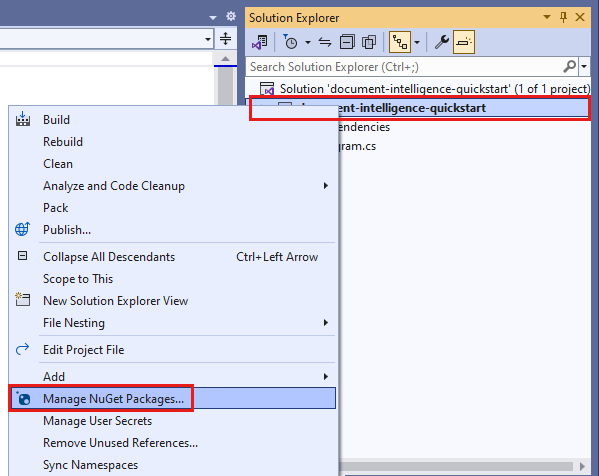
[参照] タブを選択し、「Azure.AI.FormRecognizer」と入力します。
[
Include prerelease] チェックボックスを選択します。
ドロップダウン メニューからバージョンを選択し、プロジェクトにパッケージをインストールします。
アプリケーションをビルドする
注意
.NET 6 以降では、console テンプレートを使用する新しいプロジェクトによって、以前のバージョンとは異なる新しいプログラム スタイルが生成されます。 この新しい出力では、記述する必要があるコードを簡素化できる最新の C# 機能が使用されています。
新しいバージョンで使用する場合、記述する必要があるのは、
Program.cs ファイルを開きます。
行
Console.Writeline("Hello World!")を含む既存のコードを削除します。次のいずれかのコード サンプルを選択してコピーし、アプリケーションの Program.cs ファイルに貼り付けます。
アプリケーションにコード サンプルを追加したら、プロジェクト名の横にある緑色の [開始] ボタンを選択してプログラムをビルドして実行するか、または F5 キーを押します。

読み取りモデルを使用する
using Azure;
using Azure.AI.DocumentIntelligence;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentIntelligenceClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentIntelligenceClient client = new DocumentIntelligenceClient(new Uri(endpoint), credential);
//sample document
Uri fileUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png");
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(WaitUntil.Completed, "prebuilt-read", fileUri);
AnalyzeResult result = operation.Value;
foreach (DocumentPage page in result.Pages)
{
Console.WriteLine($"Document Page {page.PageNumber} has {page.Lines.Count} line(s), {page.Words.Count} word(s),");
Console.WriteLine($"and {page.SelectionMarks.Count} selection mark(s).");
for (int i = 0; i < page.Lines.Count; i++)
{
DocumentLine line = page.Lines[i];
Console.WriteLine($" Line {i} has content: '{line.Content}'.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < line.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {line.BoundingPolygon[j].X}, Y: {line.BoundingPolygon[j].Y}");
}
}
}
foreach (DocumentStyle style in result.Styles)
{
// Check the style and style confidence to see if text is handwritten.
// Note that value '0.8' is used as an example.
bool isHandwritten = style.IsHandwritten.HasValue && style.IsHandwritten == true;
if (isHandwritten && style.Confidence > 0.8)
{
Console.WriteLine($"Handwritten content found:");
foreach (DocumentSpan span in style.Spans)
{
Console.WriteLine($" Content: {result.Content.Substring(span.Index, span.Length)}");
}
}
}
Console.WriteLine("Detected languages:");
foreach (DocumentLanguage language in result.Languages)
{
Console.WriteLine($" Found language with locale'{language.Locale}' with confidence {language.Confidence}.");
}
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
using Azure;
using Azure.AI.DocumentIntelligence;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentIntelligenceClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentIntelligenceClient client = new DocumentIntelligenceClient(new Uri(endpoint), credential);
// sample document document
Uri fileUri = new Uri ("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png");
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(WaitUntil.Completed, "prebuilt-layout", fileUri);
AnalyzeResult result = operation.Value;
foreach (DocumentPage page in result.Pages)
{
Console.WriteLine($"Document Page {page.PageNumber} has {page.Lines.Count} line(s), {page.Words.Count} word(s),");
Console.WriteLine($"and {page.SelectionMarks.Count} selection mark(s).");
for (int i = 0; i < page.Lines.Count; i++)
{
DocumentLine line = page.Lines[i];
Console.WriteLine($" Line {i} has content: '{line.Content}'.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < line.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {line.BoundingPolygon[j].X}, Y: {line.BoundingPolygon[j].Y}");
}
}
for (int i = 0; i < page.SelectionMarks.Count; i++)
{
DocumentSelectionMark selectionMark = page.SelectionMarks[i];
Console.WriteLine($" Selection Mark {i} is {selectionMark.State}.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < selectionMark.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {selectionMark.BoundingPolygon[j].X}, Y: {selectionMark.BoundingPolygon[j].Y}");
}
}
}
Console.WriteLine("Paragraphs:");
foreach (DocumentParagraph paragraph in result.Paragraphs)
{
Console.WriteLine($" Paragraph content: {paragraph.Content}");
if (paragraph.Role != null)
{
Console.WriteLine($" Role: {paragraph.Role}");
}
}
foreach (DocumentStyle style in result.Styles)
{
// Check the style and style confidence to see if text is handwritten.
// Note that value '0.8' is used as an example.
bool isHandwritten = style.IsHandwritten.HasValue && style.IsHandwritten == true;
if (isHandwritten && style.Confidence > 0.8)
{
Console.WriteLine($"Handwritten content found:");
foreach (DocumentSpan span in style.Spans)
{
Console.WriteLine($" Content: {result.Content.Substring(span.Index, span.Length)}");
}
}
}
Console.WriteLine("The following tables were extracted:");
for (int i = 0; i < result.Tables.Count; i++)
{
DocumentTable table = result.Tables[i];
Console.WriteLine($" Table {i} has {table.RowCount} rows and {table.ColumnCount} columns.");
foreach (DocumentTableCell cell in table.Cells)
{
Console.WriteLine($" Cell ({cell.RowIndex}, {cell.ColumnIndex}) has kind '{cell.Kind}' and content: '{cell.Content}'.");
}
}
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
一般的なドキュメント モデルを使用する
using Azure;
using Azure.AI.DocumentIntelligence;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentIntelligenceClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentIntelligenceClient client = new DocumentIntelligenceClient(new Uri(endpoint), credential);
// sample document document
Uri fileUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-layout.pdf");
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(WaitUntil.Completed, "prebuilt-document", fileUri);
AnalyzeResult result = operation.Value;
Console.WriteLine("Detected key-value pairs:");
foreach (DocumentKeyValuePair kvp in result.KeyValuePairs)
{
if (kvp.Value == null)
{
Console.WriteLine($" Found key with no value: '{kvp.Key.Content}'");
}
else
{
Console.WriteLine($" Found key-value pair: '{kvp.Key.Content}' and '{kvp.Value.Content}'");
}
}
foreach (DocumentPage page in result.Pages)
{
Console.WriteLine($"Document Page {page.PageNumber} has {page.Lines.Count} line(s), {page.Words.Count} word(s),");
Console.WriteLine($"and {page.SelectionMarks.Count} selection mark(s).");
for (int i = 0; i < page.Lines.Count; i++)
{
DocumentLine line = page.Lines[i];
Console.WriteLine($" Line {i} has content: '{line.Content}'.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < line.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {line.BoundingPolygon[j].X}, Y: {line.BoundingPolygon[j].Y}");
}
}
for (int i = 0; i < page.SelectionMarks.Count; i++)
{
DocumentSelectionMark selectionMark = page.SelectionMarks[i];
Console.WriteLine($" Selection Mark {i} is {selectionMark.State}.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < selectionMark.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {selectionMark.BoundingPolygon[j].X}, Y: {selectionMark.BoundingPolygon[j].Y}");
}
}
}
foreach (DocumentStyle style in result.Styles)
{
// Check the style and style confidence to see if text is handwritten.
// Note that value '0.8' is used as an example.
bool isHandwritten = style.IsHandwritten.HasValue && style.IsHandwritten == true;
if (isHandwritten && style.Confidence > 0.8)
{
Console.WriteLine($"Handwritten content found:");
foreach (DocumentSpan span in style.Spans)
{
Console.WriteLine($" Content: {result.Content.Substring(span.Index, span.Length)}");
}
}
}
Console.WriteLine("The following tables were extracted:");
for (int i = 0; i < result.Tables.Count; i++)
{
DocumentTable table = result.Tables[i];
Console.WriteLine($" Table {i} has {table.RowCount} rows and {table.ColumnCount} columns.");
foreach (DocumentTableCell cell in table.Cells)
{
Console.WriteLine($" Cell ({cell.RowIndex}, {cell.ColumnIndex}) has kind '{cell.Kind}' and content: '{cell.Content}'.");
}
}
一般的なドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
W-2 税モデルを使用する
using Azure;
using Azure.AI.DocumentIntelligence;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentIntelligenceClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentIntelligenceClient client = new DocumentIntelligenceClient(new Uri(endpoint), credential);
// sample document document
Uri w2Uri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png");
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(WaitUntil.Completed, "prebuilt-tax.us.w2", w2Uri);
AnalyzeResult result = operation.Value;
for (int i = 0; i < result.Documents.Count; i++)
{
Console.WriteLine($"Document {i}:");
AnalyzedDocument document = result.Documents[i];
if (document.Fields.TryGetValue("AdditionalInfo", out DocumentField? additionalInfoField))
{
if (additionalInfoField.FieldType == DocumentFieldType.List)
{
foreach (DocumentField infoField in additionalInfoField.Value.AsList())
{
Console.WriteLine("AdditionalInfo:");
if (infoField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> infoFields = infoField.Value.AsDictionary();
if (infoFields.TryGetValue("Amount", out DocumentField? amountField))
{
if (amountField.FieldType == DocumentFieldType.Double)
{
double amount = amountField.Value.AsDouble();
Console.WriteLine($" Amount: '{amount}', with confidence {amountField.Confidence}");
}
}
if (infoFields.TryGetValue("LetterCode", out DocumentField? letterCodeField))
{
if (letterCodeField.FieldType == DocumentFieldType.String)
{
string letterCode = letterCodeField.Value.AsString();
Console.WriteLine($" LetterCode: '{letterCode}', with confidence {letterCodeField.Confidence}");
}
}
}
}
}
}
if (document.Fields.TryGetValue("AllocatedTips", out DocumentField? allocatedTipsField))
{
if (allocatedTipsField.FieldType == DocumentFieldType.Double)
{
double allocatedTips = allocatedTipsField.Value.AsDouble();
Console.WriteLine($"Allocated Tips: '{allocatedTips}', with confidence {allocatedTipsField.Confidence}");
}
}
if (document.Fields.TryGetValue("Employer", out DocumentField? employerField))
{
if (employerField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> employerFields = employerField.Value.AsDictionary();
if (employerFields.TryGetValue("Name", out DocumentField? employerNameField))
{
if (employerNameField.FieldType == DocumentFieldType.String)
{
string name = employerNameField.Value.AsString();
Console.WriteLine($"Employer Name: '{name}', with confidence {employerNameField.Confidence}");
}
}
if (employerFields.TryGetValue("IdNumber", out DocumentField? idNumberField))
{
if (idNumberField.FieldType == DocumentFieldType.String)
{
string id = idNumberField.Value.AsString();
Console.WriteLine($"Employer ID Number: '{id}', with confidence {idNumberField.Confidence}");
}
}
if (employerFields.TryGetValue("Address", out DocumentField? addressField))
{
if (addressField.FieldType == DocumentFieldType.Address)
{
Console.WriteLine($"Employer Address: '{addressField.Content}', with confidence {addressField.Confidence}");
}
}
}
}
}
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
using Azure;
using Azure.AI.DocumentIntelligence;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentIntelligenceClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentIntelligenceClient client = new DocumentIntelligenceClient(new Uri(endpoint), credential);
// sample document document
Uri invoiceUri = new Uri("https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf");
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(WaitUntil.Completed, "prebuilt-invoice", invoiceUri);
AnalyzeResult result = operation.Value;
for (int i = 0; i < result.Documents.Count; i++)
{
Console.WriteLine($"Document {i}:");
AnalyzedDocument document = result.Documents[i];
if (document.Fields.TryGetValue("VendorName", out DocumentField vendorNameField))
{
if (vendorNameField.FieldType == DocumentFieldType.String)
{
string vendorName = vendorNameField.Value.AsString();
Console.WriteLine($"Vendor Name: '{vendorName}', with confidence {vendorNameField.Confidence}");
}
}
if (document.Fields.TryGetValue("CustomerName", out DocumentField customerNameField))
{
if (customerNameField.FieldType == DocumentFieldType.String)
{
string customerName = customerNameField.Value.AsString();
Console.WriteLine($"Customer Name: '{customerName}', with confidence {customerNameField.Confidence}");
}
}
if (document.Fields.TryGetValue("Items", out DocumentField itemsField))
{
if (itemsField.FieldType == DocumentFieldType.List)
{
foreach (DocumentField itemField in itemsField.Value.AsList())
{
Console.WriteLine("Item:");
if (itemField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> itemFields = itemField.Value.AsDictionary();
if (itemFields.TryGetValue("Description", out DocumentField itemDescriptionField))
{
if (itemDescriptionField.FieldType == DocumentFieldType.String)
{
string itemDescription = itemDescriptionField.Value.AsString();
Console.WriteLine($" Description: '{itemDescription}', with confidence {itemDescriptionField.Confidence}");
}
}
if (itemFields.TryGetValue("Amount", out DocumentField itemAmountField))
{
if (itemAmountField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue itemAmount = itemAmountField.Value.AsCurrency();
Console.WriteLine($" Amount: '{itemAmount.Symbol}{itemAmount.Amount}', with confidence {itemAmountField.Confidence}");
}
}
}
}
}
}
if (document.Fields.TryGetValue("SubTotal", out DocumentField subTotalField))
{
if (subTotalField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue subTotal = subTotalField.Value.AsCurrency();
Console.WriteLine($"Sub Total: '{subTotal.Symbol}{subTotal.Amount}', with confidence {subTotalField.Confidence}");
}
}
if (document.Fields.TryGetValue("TotalTax", out DocumentField totalTaxField))
{
if (totalTaxField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue totalTax = totalTaxField.Value.AsCurrency();
Console.WriteLine($"Total Tax: '{totalTax.Symbol}{totalTax.Amount}', with confidence {totalTaxField.Confidence}");
}
}
if (document.Fields.TryGetValue("InvoiceTotal", out DocumentField invoiceTotalField))
{
if (invoiceTotalField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue invoiceTotal = invoiceTotalField.Value.AsCurrency();
Console.WriteLine($"Invoice Total: '{invoiceTotal.Symbol}{invoiceTotal.Amount}', with confidence {invoiceTotalField.Confidence}");
}
}
}
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レシート モデルを使用する
using Azure;
using Azure.AI.DocumentIntelligence;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentIntelligenceClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentIntelligenceClient client = new DocumentIntelligenceClient(new Uri(endpoint), credential);
// sample document document
Uri receiptUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png");
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(WaitUntil.Completed, "prebuilt-receipt", receiptUri);
AnalyzeResult receipts = operation.Value;
foreach (AnalyzedDocument receipt in receipts.Documents)
{
if (receipt.Fields.TryGetValue("MerchantName", out DocumentField merchantNameField))
{
if (merchantNameField.FieldType == DocumentFieldType.String)
{
string merchantName = merchantNameField.Value.AsString();
Console.WriteLine($"Merchant Name: '{merchantName}', with confidence {merchantNameField.Confidence}");
}
}
if (receipt.Fields.TryGetValue("TransactionDate", out DocumentField transactionDateField))
{
if (transactionDateField.FieldType == DocumentFieldType.Date)
{
DateTimeOffset transactionDate = transactionDateField.Value.AsDate();
Console.WriteLine($"Transaction Date: '{transactionDate}', with confidence {transactionDateField.Confidence}");
}
}
if (receipt.Fields.TryGetValue("Items", out DocumentField itemsField))
{
if (itemsField.FieldType == DocumentFieldType.List)
{
foreach (DocumentField itemField in itemsField.Value.AsList())
{
Console.WriteLine("Item:");
if (itemField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> itemFields = itemField.Value.AsDictionary();
if (itemFields.TryGetValue("Description", out DocumentField itemDescriptionField))
{
if (itemDescriptionField.FieldType == DocumentFieldType.String)
{
string itemDescription = itemDescriptionField.Value.AsString();
Console.WriteLine($" Description: '{itemDescription}', with confidence {itemDescriptionField.Confidence}");
}
}
if (itemFields.TryGetValue("TotalPrice", out DocumentField itemTotalPriceField))
{
if (itemTotalPriceField.FieldType == DocumentFieldType.Double)
{
double itemTotalPrice = itemTotalPriceField.Value.AsDouble();
Console.WriteLine($" Total Price: '{itemTotalPrice}', with confidence {itemTotalPriceField.Confidence}");
}
}
}
}
}
}
if (receipt.Fields.TryGetValue("Total", out DocumentField totalField))
{
if (totalField.FieldType == DocumentFieldType.Double)
{
double total = totalField.Value.AsDouble();
Console.WriteLine($"Total: '{total}', with confidence '{totalField.Confidence}'");
}
}
}
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデルを使用する
using Azure;
using Azure.AI.DocumentIntelligence;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentIntelligenceClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentIntelligenceClient client = new DocumentIntelligenceClient(new Uri(endpoint), credential);
// sample document document
Uri idDocumentUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png");
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(WaitUntil.Completed, "prebuilt-idDocument", idDocumentUri);
AnalyzeResult identityDocuments = operation.Value;
AnalyzedDocument identityDocument = identityDocuments.Documents.Single();
if (identityDocument.Fields.TryGetValue("Address", out DocumentField addressField))
{
if (addressField.FieldType == DocumentFieldType.String)
{
string address = addressField.Value. AsString();
Console.WriteLine($"Address: '{address}', with confidence {addressField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("CountryRegion", out DocumentField countryRegionField))
{
if (countryRegionField.FieldType == DocumentFieldType.CountryRegion)
{
string countryRegion = countryRegionField.Value.AsCountryRegion();
Console.WriteLine($"CountryRegion: '{countryRegion}', with confidence {countryRegionField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfBirth", out DocumentField dateOfBirthField))
{
if (dateOfBirthField.FieldType == DocumentFieldType.Date)
{
DateTimeOffset dateOfBirth = dateOfBirthField.Value.AsDate();
Console.WriteLine($"Date Of Birth: '{dateOfBirth}', with confidence {dateOfBirthField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfExpiration", out DocumentField dateOfExpirationField))
{
if (dateOfExpirationField.FieldType == DocumentFieldType.Date)
{
DateTimeOffset dateOfExpiration = dateOfExpirationField.Value.AsDate();
Console.WriteLine($"Date Of Expiration: '{dateOfExpiration}', with confidence {dateOfExpirationField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DocumentNumber", out DocumentField documentNumberField))
{
if (documentNumberField.FieldType == DocumentFieldType.String)
{
string documentNumber = documentNumberField.Value.AsString();
Console.WriteLine($"Document Number: '{documentNumber}', with confidence {documentNumberField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("FirstName", out DocumentField firstNameField))
{
if (firstNameField.FieldType == DocumentFieldType.String)
{
string firstName = firstNameField.Value.AsString();
Console.WriteLine($"First Name: '{firstName}', with confidence {firstNameField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("LastName", out DocumentField lastNameField))
{
if (lastNameField.FieldType == DocumentFieldType.String)
{
string lastName = lastNameField.Value.AsString();
Console.WriteLine($"Last Name: '{lastName}', with confidence {lastNameField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("Region", out DocumentField regionfield))
{
if (regionfield.FieldType == DocumentFieldType.String)
{
string region = regionfield.Value.AsString();
Console.WriteLine($"Region: '{region}', with confidence {regionfield.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("Sex", out DocumentField sexfield))
{
if (sexfield.FieldType == DocumentFieldType.String)
{
string sex = sexfield.Value.AsString();
Console.WriteLine($"Sex: '{sex}', with confidence {sexfield.Confidence}");
}
}
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
前提条件
Azure サブスクリプション。無料で作成できます。
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定された場所にあるドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書 名刺モデル 事前構築された名刺 サンプル名刺
{kind=link}
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
Visual Studio を起動します。
スタート ページで、[新しいプロジェクトの作成] を選択します。
[新しいプロジェクトの作成] ページで、検索ボックスに「コンソール」と入力します。 [コンソール アプリケーション] テンプレートを選択し、[次へ] を選択します。
[新しいプロジェクトの構成] ページの [プロジェクト名] に「docIntelligence_app」と入力します。 [次へ] を選択します。
[追加情報] ページで、[.NET 8.0 (長期的なサポート)] を選択し、[作成] を選択します。
NuGet を使用してクライアント ライブラリをインストールする
docIntelligence_app プロジェクトを右クリックし、[Manage NuGet Packages...] (NuGet パッケージの管理...) を選択します。
[参照] タブを選択し、「Azure.AI.FormRecognizer」と入力します。
ドロップダウン メニューからバージョンを選択し、プロジェクトにパッケージをインストールします。
アプリケーションをビルドする
注意
.NET 6 以降では、console テンプレートを使用する新しいプロジェクトによって、以前のバージョンとは異なる新しいプログラム スタイルが生成されます。 この新しい出力では、記述する必要があるコードを簡素化できる最新の C# 機能が使用されています。
新しいバージョンで使用する場合、記述する必要があるのは、
Program.cs ファイルを開きます。
行
Console.Writeline("Hello World!")を含む既存のコードを削除します。次のいずれかのコード サンプルを選択してコピーし、アプリケーションの Program.cs ファイルに貼り付けます。
アプリケーションにコード サンプルを追加したら、プロジェクト名の横にある緑色の [開始] ボタンを選択してプログラムをビルドして実行するか、または F5 キーを押します。
読み取りモデルを使用する
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
//sample document
Uri fileUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-read", fileUri);
AnalyzeResult result = operation.Value;
foreach (DocumentPage page in result.Pages)
{
Console.WriteLine($"Document Page {page.PageNumber} has {page.Lines.Count} line(s), {page.Words.Count} word(s),");
Console.WriteLine($"and {page.SelectionMarks.Count} selection mark(s).");
for (int i = 0; i < page.Lines.Count; i++)
{
DocumentLine line = page.Lines[i];
Console.WriteLine($" Line {i} has content: '{line.Content}'.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < line.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {line.BoundingPolygon[j].X}, Y: {line.BoundingPolygon[j].Y}");
}
}
}
foreach (DocumentStyle style in result.Styles)
{
// Check the style and style confidence to see if text is handwritten.
// Note that value '0.8' is used as an example.
bool isHandwritten = style.IsHandwritten.HasValue && style.IsHandwritten == true;
if (isHandwritten && style.Confidence > 0.8)
{
Console.WriteLine($"Handwritten content found:");
foreach (DocumentSpan span in style.Spans)
{
Console.WriteLine($" Content: {result.Content.Substring(span.Index, span.Length)}");
}
}
}
Console.WriteLine("Detected languages:");
foreach (DocumentLanguage language in result.Languages)
{
Console.WriteLine($" Found language with locale'{language.Locale}' with confidence {language.Confidence}.");
}
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
// sample document document
Uri fileUri = new Uri ("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-layout", fileUri);
AnalyzeResult result = operation.Value;
foreach (DocumentPage page in result.Pages)
{
Console.WriteLine($"Document Page {page.PageNumber} has {page.Lines.Count} line(s), {page.Words.Count} word(s),");
Console.WriteLine($"and {page.SelectionMarks.Count} selection mark(s).");
for (int i = 0; i < page.Lines.Count; i++)
{
DocumentLine line = page.Lines[i];
Console.WriteLine($" Line {i} has content: '{line.Content}'.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < line.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {line.BoundingPolygon[j].X}, Y: {line.BoundingPolygon[j].Y}");
}
}
for (int i = 0; i < page.SelectionMarks.Count; i++)
{
DocumentSelectionMark selectionMark = page.SelectionMarks[i];
Console.WriteLine($" Selection Mark {i} is {selectionMark.State}.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < selectionMark.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {selectionMark.BoundingPolygon[j].X}, Y: {selectionMark.BoundingPolygon[j].Y}");
}
}
}
Console.WriteLine("Paragraphs:");
foreach (DocumentParagraph paragraph in result.Paragraphs)
{
Console.WriteLine($" Paragraph content: {paragraph.Content}");
if (paragraph.Role != null)
{
Console.WriteLine($" Role: {paragraph.Role}");
}
}
foreach (DocumentStyle style in result.Styles)
{
// Check the style and style confidence to see if text is handwritten.
// Note that value '0.8' is used as an example.
bool isHandwritten = style.IsHandwritten.HasValue && style.IsHandwritten == true;
if (isHandwritten && style.Confidence > 0.8)
{
Console.WriteLine($"Handwritten content found:");
foreach (DocumentSpan span in style.Spans)
{
Console.WriteLine($" Content: {result.Content.Substring(span.Index, span.Length)}");
}
}
}
Console.WriteLine("The following tables were extracted:");
for (int i = 0; i < result.Tables.Count; i++)
{
DocumentTable table = result.Tables[i];
Console.WriteLine($" Table {i} has {table.RowCount} rows and {table.ColumnCount} columns.");
foreach (DocumentTableCell cell in table.Cells)
{
Console.WriteLine($" Cell ({cell.RowIndex}, {cell.ColumnIndex}) has kind '{cell.Kind}' and content: '{cell.Content}'.");
}
}
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
一般的なドキュメント モデルを使用する
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
// sample document document
Uri fileUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-layout.pdf");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-document", fileUri);
AnalyzeResult result = operation.Value;
Console.WriteLine("Detected key-value pairs:");
foreach (DocumentKeyValuePair kvp in result.KeyValuePairs)
{
if (kvp.Value == null)
{
Console.WriteLine($" Found key with no value: '{kvp.Key.Content}'");
}
else
{
Console.WriteLine($" Found key-value pair: '{kvp.Key.Content}' and '{kvp.Value.Content}'");
}
}
foreach (DocumentPage page in result.Pages)
{
Console.WriteLine($"Document Page {page.PageNumber} has {page.Lines.Count} line(s), {page.Words.Count} word(s),");
Console.WriteLine($"and {page.SelectionMarks.Count} selection mark(s).");
for (int i = 0; i < page.Lines.Count; i++)
{
DocumentLine line = page.Lines[i];
Console.WriteLine($" Line {i} has content: '{line.Content}'.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < line.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {line.BoundingPolygon[j].X}, Y: {line.BoundingPolygon[j].Y}");
}
}
for (int i = 0; i < page.SelectionMarks.Count; i++)
{
DocumentSelectionMark selectionMark = page.SelectionMarks[i];
Console.WriteLine($" Selection Mark {i} is {selectionMark.State}.");
Console.WriteLine($" Its bounding polygon (points ordered clockwise):");
for (int j = 0; j < selectionMark.BoundingPolygon.Count; j++)
{
Console.WriteLine($" Point {j} => X: {selectionMark.BoundingPolygon[j].X}, Y: {selectionMark.BoundingPolygon[j].Y}");
}
}
}
foreach (DocumentStyle style in result.Styles)
{
// Check the style and style confidence to see if text is handwritten.
// Note that value '0.8' is used as an example.
bool isHandwritten = style.IsHandwritten.HasValue && style.IsHandwritten == true;
if (isHandwritten && style.Confidence > 0.8)
{
Console.WriteLine($"Handwritten content found:");
foreach (DocumentSpan span in style.Spans)
{
Console.WriteLine($" Content: {result.Content.Substring(span.Index, span.Length)}");
}
}
}
Console.WriteLine("The following tables were extracted:");
for (int i = 0; i < result.Tables.Count; i++)
{
DocumentTable table = result.Tables[i];
Console.WriteLine($" Table {i} has {table.RowCount} rows and {table.ColumnCount} columns.");
foreach (DocumentTableCell cell in table.Cells)
{
Console.WriteLine($" Cell ({cell.RowIndex}, {cell.ColumnIndex}) has kind '{cell.Kind}' and content: '{cell.Content}'.");
}
}
一般的なドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
W-2 税モデルを使用する
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
// sample document document
Uri w2Uri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-tax.us.w2", w2Uri);
AnalyzeResult result = operation.Value;
for (int i = 0; i < result.Documents.Count; i++)
{
Console.WriteLine($"Document {i}:");
AnalyzedDocument document = result.Documents[i];
if (document.Fields.TryGetValue("AdditionalInfo", out DocumentField? additionalInfoField))
{
if (additionalInfoField.FieldType == DocumentFieldType.List)
{
foreach (DocumentField infoField in additionalInfoField.Value.AsList())
{
Console.WriteLine("AdditionalInfo:");
if (infoField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> infoFields = infoField.Value.AsDictionary();
if (infoFields.TryGetValue("Amount", out DocumentField? amountField))
{
if (amountField.FieldType == DocumentFieldType.Double)
{
double amount = amountField.Value.AsDouble();
Console.WriteLine($" Amount: '{amount}', with confidence {amountField.Confidence}");
}
}
if (infoFields.TryGetValue("LetterCode", out DocumentField? letterCodeField))
{
if (letterCodeField.FieldType == DocumentFieldType.String)
{
string letterCode = letterCodeField.Value.AsString();
Console.WriteLine($" LetterCode: '{letterCode}', with confidence {letterCodeField.Confidence}");
}
}
}
}
}
}
if (document.Fields.TryGetValue("AllocatedTips", out DocumentField? allocatedTipsField))
{
if (allocatedTipsField.FieldType == DocumentFieldType.Double)
{
double allocatedTips = allocatedTipsField.Value.AsDouble();
Console.WriteLine($"Allocated Tips: '{allocatedTips}', with confidence {allocatedTipsField.Confidence}");
}
}
if (document.Fields.TryGetValue("Employer", out DocumentField? employerField))
{
if (employerField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> employerFields = employerField.Value.AsDictionary();
if (employerFields.TryGetValue("Name", out DocumentField? employerNameField))
{
if (employerNameField.FieldType == DocumentFieldType.String)
{
string name = employerNameField.Value.AsString();
Console.WriteLine($"Employer Name: '{name}', with confidence {employerNameField.Confidence}");
}
}
if (employerFields.TryGetValue("IdNumber", out DocumentField? idNumberField))
{
if (idNumberField.FieldType == DocumentFieldType.String)
{
string id = idNumberField.Value.AsString();
Console.WriteLine($"Employer ID Number: '{id}', with confidence {idNumberField.Confidence}");
}
}
if (employerFields.TryGetValue("Address", out DocumentField? addressField))
{
if (addressField.FieldType == DocumentFieldType.Address)
{
Console.WriteLine($"Employer Address: '{addressField.Content}', with confidence {addressField.Confidence}");
}
}
}
}
}
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
// sample document document
Uri invoiceUri = new Uri("https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-invoice", invoiceUri);
AnalyzeResult result = operation.Value;
for (int i = 0; i < result.Documents.Count; i++)
{
Console.WriteLine($"Document {i}:");
AnalyzedDocument document = result.Documents[i];
if (document.Fields.TryGetValue("VendorName", out DocumentField vendorNameField))
{
if (vendorNameField.FieldType == DocumentFieldType.String)
{
string vendorName = vendorNameField.Value.AsString();
Console.WriteLine($"Vendor Name: '{vendorName}', with confidence {vendorNameField.Confidence}");
}
}
if (document.Fields.TryGetValue("CustomerName", out DocumentField customerNameField))
{
if (customerNameField.FieldType == DocumentFieldType.String)
{
string customerName = customerNameField.Value.AsString();
Console.WriteLine($"Customer Name: '{customerName}', with confidence {customerNameField.Confidence}");
}
}
if (document.Fields.TryGetValue("Items", out DocumentField itemsField))
{
if (itemsField.FieldType == DocumentFieldType.List)
{
foreach (DocumentField itemField in itemsField.Value.AsList())
{
Console.WriteLine("Item:");
if (itemField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> itemFields = itemField.Value.AsDictionary();
if (itemFields.TryGetValue("Description", out DocumentField itemDescriptionField))
{
if (itemDescriptionField.FieldType == DocumentFieldType.String)
{
string itemDescription = itemDescriptionField.Value.AsString();
Console.WriteLine($" Description: '{itemDescription}', with confidence {itemDescriptionField.Confidence}");
}
}
if (itemFields.TryGetValue("Amount", out DocumentField itemAmountField))
{
if (itemAmountField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue itemAmount = itemAmountField.Value.AsCurrency();
Console.WriteLine($" Amount: '{itemAmount.Symbol}{itemAmount.Amount}', with confidence {itemAmountField.Confidence}");
}
}
}
}
}
}
if (document.Fields.TryGetValue("SubTotal", out DocumentField subTotalField))
{
if (subTotalField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue subTotal = subTotalField.Value.AsCurrency();
Console.WriteLine($"Sub Total: '{subTotal.Symbol}{subTotal.Amount}', with confidence {subTotalField.Confidence}");
}
}
if (document.Fields.TryGetValue("TotalTax", out DocumentField totalTaxField))
{
if (totalTaxField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue totalTax = totalTaxField.Value.AsCurrency();
Console.WriteLine($"Total Tax: '{totalTax.Symbol}{totalTax.Amount}', with confidence {totalTaxField.Confidence}");
}
}
if (document.Fields.TryGetValue("InvoiceTotal", out DocumentField invoiceTotalField))
{
if (invoiceTotalField.FieldType == DocumentFieldType.Currency)
{
CurrencyValue invoiceTotal = invoiceTotalField.Value.AsCurrency();
Console.WriteLine($"Invoice Total: '{invoiceTotal.Symbol}{invoiceTotal.Amount}', with confidence {invoiceTotalField.Confidence}");
}
}
}
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レシート モデルを使用する
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
// sample document document
Uri receiptUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-receipt", receiptUri);
AnalyzeResult receipts = operation.Value;
foreach (AnalyzedDocument receipt in receipts.Documents)
{
if (receipt.Fields.TryGetValue("MerchantName", out DocumentField merchantNameField))
{
if (merchantNameField.FieldType == DocumentFieldType.String)
{
string merchantName = merchantNameField.Value.AsString();
Console.WriteLine($"Merchant Name: '{merchantName}', with confidence {merchantNameField.Confidence}");
}
}
if (receipt.Fields.TryGetValue("TransactionDate", out DocumentField transactionDateField))
{
if (transactionDateField.FieldType == DocumentFieldType.Date)
{
DateTimeOffset transactionDate = transactionDateField.Value.AsDate();
Console.WriteLine($"Transaction Date: '{transactionDate}', with confidence {transactionDateField.Confidence}");
}
}
if (receipt.Fields.TryGetValue("Items", out DocumentField itemsField))
{
if (itemsField.FieldType == DocumentFieldType.List)
{
foreach (DocumentField itemField in itemsField.Value.AsList())
{
Console.WriteLine("Item:");
if (itemField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> itemFields = itemField.Value.AsDictionary();
if (itemFields.TryGetValue("Description", out DocumentField itemDescriptionField))
{
if (itemDescriptionField.FieldType == DocumentFieldType.String)
{
string itemDescription = itemDescriptionField.Value.AsString();
Console.WriteLine($" Description: '{itemDescription}', with confidence {itemDescriptionField.Confidence}");
}
}
if (itemFields.TryGetValue("TotalPrice", out DocumentField itemTotalPriceField))
{
if (itemTotalPriceField.FieldType == DocumentFieldType.Double)
{
double itemTotalPrice = itemTotalPriceField.Value.AsDouble();
Console.WriteLine($" Total Price: '{itemTotalPrice}', with confidence {itemTotalPriceField.Confidence}");
}
}
}
}
}
}
if (receipt.Fields.TryGetValue("Total", out DocumentField totalField))
{
if (totalField.FieldType == DocumentFieldType.Double)
{
double total = totalField.Value.AsDouble();
Console.WriteLine($"Total: '{total}', with confidence '{totalField.Confidence}'");
}
}
}
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデル
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
// sample document document
Uri idDocumentUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-idDocument", idDocumentUri);
AnalyzeResult identityDocuments = operation.Value;
AnalyzedDocument identityDocument = identityDocuments.Documents.Single();
if (identityDocument.Fields.TryGetValue("Address", out DocumentField addressField))
{
if (addressField.FieldType == DocumentFieldType.String)
{
string address = addressField.Value. AsString();
Console.WriteLine($"Address: '{address}', with confidence {addressField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("CountryRegion", out DocumentField countryRegionField))
{
if (countryRegionField.FieldType == DocumentFieldType.CountryRegion)
{
string countryRegion = countryRegionField.Value.AsCountryRegion();
Console.WriteLine($"CountryRegion: '{countryRegion}', with confidence {countryRegionField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfBirth", out DocumentField dateOfBirthField))
{
if (dateOfBirthField.FieldType == DocumentFieldType.Date)
{
DateTimeOffset dateOfBirth = dateOfBirthField.Value.AsDate();
Console.WriteLine($"Date Of Birth: '{dateOfBirth}', with confidence {dateOfBirthField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfExpiration", out DocumentField dateOfExpirationField))
{
if (dateOfExpirationField.FieldType == DocumentFieldType.Date)
{
DateTimeOffset dateOfExpiration = dateOfExpirationField.Value.AsDate();
Console.WriteLine($"Date Of Expiration: '{dateOfExpiration}', with confidence {dateOfExpirationField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DocumentNumber", out DocumentField documentNumberField))
{
if (documentNumberField.FieldType == DocumentFieldType.String)
{
string documentNumber = documentNumberField.Value.AsString();
Console.WriteLine($"Document Number: '{documentNumber}', with confidence {documentNumberField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("FirstName", out DocumentField firstNameField))
{
if (firstNameField.FieldType == DocumentFieldType.String)
{
string firstName = firstNameField.Value.AsString();
Console.WriteLine($"First Name: '{firstName}', with confidence {firstNameField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("LastName", out DocumentField lastNameField))
{
if (lastNameField.FieldType == DocumentFieldType.String)
{
string lastName = lastNameField.Value.AsString();
Console.WriteLine($"Last Name: '{lastName}', with confidence {lastNameField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("Region", out DocumentField regionfield))
{
if (regionfield.FieldType == DocumentFieldType.String)
{
string region = regionfield.Value.AsString();
Console.WriteLine($"Region: '{region}', with confidence {regionfield.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("Sex", out DocumentField sexfield))
{
if (sexfield.FieldType == DocumentFieldType.String)
{
string sex = sexfield.Value.AsString();
Console.WriteLine($"Sex: '{sex}', with confidence {sexfield.Confidence}");
}
}
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
名刺モデルを使用する
using Azure;
using Azure.AI.FormRecognizer.DocumentAnalysis;
//use your `key` and `endpoint` environment variables to create your `AzureKeyCredential` and `DocumentAnalysisClient` instances
string key = Environment.GetEnvironmentVariable("DI_KEY");
string endpoint = Environment.GetEnvironmentVariable("DI_ENDPOINT");
AzureKeyCredential credential = new AzureKeyCredential(key);
DocumentAnalysisClient client = new DocumentAnalysisClient(new Uri(endpoint), credential);
// sample document document
Uri businessCardUri = new Uri("https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/business-card-english.jpg");
AnalyzeDocumentOperation operation = await client.AnalyzeDocumentFromUriAsync(WaitUntil.Completed, "prebuilt-businessCard", businessCardUri);
AnalyzeResult businessCards = operation.Value;
foreach (AnalyzedDocument businessCard in businessCards.Documents)
{
if (businessCard.Fields.TryGetValue("ContactNames", out DocumentField ContactNamesField))
{
if (ContactNamesField.FieldType == DocumentFieldType.List)
{
foreach (DocumentField contactNameField in ContactNamesField.Value.AsList())
{
Console.WriteLine("Contact Name: ");
if (contactNameField.FieldType == DocumentFieldType.Dictionary)
{
IReadOnlyDictionary<string, DocumentField> contactNameFields = contactNameField.Value.AsDictionary();
if (contactNameFields.TryGetValue("FirstName", out DocumentField firstNameField))
{
if (firstNameField.FieldType == DocumentFieldType.String)
{
string firstName = firstNameField.Value.AsString();
Console.WriteLine($" First Name: '{firstName}', with confidence {firstNameField.Confidence}");
}
}
if (contactNameFields.TryGetValue("LastName", out DocumentField lastNameField))
{
if (lastNameField.FieldType == DocumentFieldType.String)
{
string lastName = lastNameField.Value.AsString();
Console.WriteLine($" Last Name: '{lastName}', with confidence {lastNameField.Confidence}");
}
}
}
}
}
}
if (businessCard.Fields.TryGetValue("JobTitles", out DocumentField jobTitlesFields))
{
if (jobTitlesFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField jobTitleField in jobTitlesFields.Value.AsList())
{
if (jobTitleField.FieldType == DocumentFieldType.String)
{
string jobTitle = jobTitleField.Value.AsString();
Console.WriteLine($"Job Title: '{jobTitle}', with confidence {jobTitleField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("Departments", out DocumentField departmentFields))
{
if (departmentFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField departmentField in departmentFields.Value.AsList())
{
if (departmentField.FieldType == DocumentFieldType.String)
{
string department = departmentField.Value.AsString();
Console.WriteLine($"Department: '{department}', with confidence {departmentField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("Emails", out DocumentField emailFields))
{
if (emailFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField emailField in emailFields.Value.AsList())
{
if (emailField.FieldType == DocumentFieldType.String)
{
string email = emailField.Value.AsString();
Console.WriteLine($"Email: '{email}', with confidence {emailField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("Websites", out DocumentField websiteFields))
{
if (websiteFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField websiteField in websiteFields.Value.AsList())
{
if (websiteField.FieldType == DocumentFieldType.String)
{
string website = websiteField.Value.AsString();
Console.WriteLine($"Website: '{website}', with confidence {websiteField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("MobilePhones", out DocumentField mobilePhonesFields))
{
if (mobilePhonesFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField mobilePhoneField in mobilePhonesFields.Value.AsList())
{
if (mobilePhoneField.FieldType == DocumentFieldType.PhoneNumber)
{
string mobilePhone = mobilePhoneField.Value.AsPhoneNumber();
Console.WriteLine($"Mobile phone number: '{mobilePhone}', with confidence {mobilePhoneField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("WorkPhones", out DocumentField workPhonesFields))
{
if (workPhonesFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField workPhoneField in workPhonesFields.Value.AsList())
{
if (workPhoneField.FieldType == DocumentFieldType.PhoneNumber)
{
string workPhone = workPhoneField.Value.AsPhoneNumber();
Console.WriteLine($"Work phone number: '{workPhone}', with confidence {workPhoneField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("Faxes", out DocumentField faxesFields))
{
if (faxesFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField faxField in faxesFields.Value.AsList())
{
if (faxField.FieldType == DocumentFieldType.PhoneNumber)
{
string fax = faxField.Value.AsPhoneNumber();
Console.WriteLine($"Fax phone number: '{fax}', with confidence {faxField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("Addresses", out DocumentField addressesFields))
{
if (addressesFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField addressField in addressesFields.Value.AsList())
{
if (addressField.FieldType == DocumentFieldType.String)
{
string address = addressField.Value.AsString();
Console.WriteLine($"Address: '{address}', with confidence {addressField.Confidence}");
}
}
}
}
if (businessCard.Fields.TryGetValue("CompanyNames", out DocumentField companyNamesFields))
{
if (companyNamesFields.FieldType == DocumentFieldType.List)
{
foreach (DocumentField companyNameField in companyNamesFields.Value.AsList())
{
if (companyNameField.FieldType == DocumentFieldType.String)
{
string companyName = companyNameField.Value.AsString();
Console.WriteLine($"Company name: '{companyName}', with confidence {companyNameField.Confidence}");
}
}
}
}
}
名刺モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
クライアント ライブラリ | SDK リファレンス | API リファレンス | パッケージ (Maven) | サンプル |サポートされている REST API バージョン
前提条件
Azure サブスクリプション。無料で作成できます。
Visual Studio Code または好みの IDE の最新バージョン。 「Java in Visual Studio Code」を参照してください。
- Visual Studio Code には、Windows および macOS 向けに Coding Pack for Javaが用意されています。 このコーディング パックは、
VSCode、Java Development Kit (JDK)、および Microsoft が推奨する拡張機能のコレクションのバンドルです。 コーディング パックを使用して、既存の開発環境を修正できます。 VSCode と Coding Pack For Java を使用している場合は、Gradle for Java 拡張機能をインストールします。
Visual Studio Code を使用していない場合、開発環境に次のものがインストールされていることを確認してください。
- A Java Development Kit (JDK) バージョン 8 以降。 詳しくは、「Microsoft Build of OpenJDK」を参照してください。
- Gradle、バージョン 6.8 以降。
- Visual Studio Code には、Windows および macOS 向けに Coding Pack for Javaが用意されています。 このコーディング パックは、
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。ヒント
1 つのエンドポイントとキーを使用して複数の Azure AI サービスにアクセスする予定の場合は、Azure AI サービス リソースを作成します。 Document Intelligence へのアクセスのみの場合は、Document Intelligence リソースを作成します。 Microsoft Entra 認証を使用する場合は、単一サービス リソースが必要です。
アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定されたドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
プログラミング環境を設定するには、Gradle プロジェクトを作成し、クライアント ライブラリをインストールします。
Gradle プロジェクトを作成する
コンソール ウィンドウで、アプリの新しいディレクトリを doc-intelligence-app という名前で作成し、そのディレクトリに移動します。
mkdir doc-intelligence-app cd doc-intelligence-app作業ディレクトリから
gradle initコマンドを実行します。 このコマンドによって、Gradle 用の重要なビルド ファイルが作成されます。たとえば、実行時にアプリケーションを作成して構成するために使用される build.gradle.kts などです。gradle init --type basicDSL を選択するよう求められたら、Kotlin を選択します。
[Enter] を選択して、既定のプロジェクト名 doc-intelligence-app をそのまま使用します。
クライアント ライブラリをインストールする
この記事では、Gradle 依存関係マネージャーを使用します。 クライアント ライブラリとその他の依存関係マネージャーの情報については、Maven Central Repository を参照してください。
IDE でプロジェクトの build.gradle.kts ファイルを開きます。 次のコードをコピーして貼り付け、必要なプラグインと設定と共に、クライアント ライブラリを
implementationステートメントとして含めます。plugins { java application } application { mainClass.set("DocIntelligence") } repositories { mavenCentral() } dependencies { implementation group: 'com.azure', name: 'azure-ai-documentintelligence', version: '1.0.0-beta.4' }
Java アプリケーションの作成
Document Intelligence サービスとやり取りするために、DocumentIntelligenceClient クラスのインスタンスを作成します。 これを行うために、Azure portal の key を使用して AzureKeyCredential を作成し、その AzureKeyCredential と Document Intelligence の endpoint を使用して DocumentIntelligenceClient インスタンスを作成します。
doc-intelligence-app ディレクトリから、次のコマンドを実行します。
mkdir -p src/main/java
このコマンドにより、次のディレクトリ構造が作成されます。
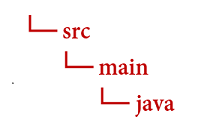
javaディレクトリに移動して、DocIntelligence.java という名前のファイルを作成します。ヒント
PowerShell を使用して新しいファイルを作成できます。 Shift キーを押しながらフォルダーを右クリックして、プロジェクト ディレクトリで PowerShell ウィンドウを開き、次のコマンドを入力します。New-Item DocIntelligence.java。
DocIntelligence.java ファイルを開き、次のいずれかのコード サンプルを選択してコピーし、アプリケーションに貼り付けます。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
readモデルが使用されます。 - 事前構築済みレイアウト モデルは、ドキュメントと画像からテキストとテキストの場所、テーブル、選択マーク、構造体情報を抽出します。
- 事前構築済み tax.us.w2 モデルは、米国内国歳入庁 (IRS) の税フォームで報告された情報を抽出します。
- 事前構築済み請求書モデルは、さまざまな形式の売上請求書から主なフィールドと品目を抽出します。
- 事前構築済み領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
- 事前構築済み idDocument モデルは、米国の運転免許証、国際パスポートの略歴ページ、米国の州の ID、社会保障カード、永住者カードから重要な情報を抽出します。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
次のコマンドを入力します。
gradle build gradle run
読み取りモデルを使用する
import com.azure.ai.documentintelligence;
import com.azure.ai.documentintelligence.models.AnalyzeDocumentRequest;
import com.azure.ai.documentintelligence.models.AnalyzeResult;
import com.azure.ai.documentintelligence.models.AnalyzeResultOperation;
import com.azure.ai.documentintelligence.models.Document;
import com.azure.ai.documentintelligence.models.DocumentField;
import com.azure.ai.documentintelligence.models.DocumentFieldType;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
public class DocIntelligence {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
DocumentIntelligenceClient client = new DocumentIntelligenceClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String documentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png";
String modelId = "prebuilt-read";
SyncPoller < OperationResult, AnalyzeResult > analyzeLayoutResultPoller =
client.beginAnalyzeDocument(modelId, invoiceUrl);;
AnalyzeResult analyzeLayoutResult = analyzeLayoutResultPoller.getFinalResult().getAnalyzeResult();
// pages
analyzeLayoutResult.getPages().forEach(documentPage -> {
System.out.printf("Page has width: %.2f and height: %.2f, measured with unit: %s%n",
documentPage.getWidth(),
documentPage.getHeight(),
documentPage.getUnit());
// lines
documentPage.getLines().forEach(documentLine ->
System.out.printf("Line %s is within a bounding polygon %s.%n",
documentLine.getContent(),
documentLine.getBoundingPolygon().toString()));
// words
documentPage.getWords().forEach(documentWord ->
System.out.printf("Word '%s' has a confidence score of %.2f.%n",
documentWord.getContent(),
documentWord.getConfidence()));
});
}
}
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
import com.azure.ai.documentintelligence;
import com.azure.ai.documentintelligence.models.AnalyzeDocumentRequest;
import com.azure.ai.documentintelligence.models.AnalyzeResult;
import com.azure.ai.documentintelligence.models.AnalyzeResultOperation;
import com.azure.ai.documentintelligence.models.Document;
import com.azure.ai.documentintelligence.models.DocumentField;
import com.azure.ai.documentintelligence.models.DocumentFieldType;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
public class DocIntelligence {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
DocumentIntelligenceClient client = new DocumentIntelligenceClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String layoutDocumentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png";
String modelId = "prebuilt-layout";
SyncPoller < OperationResult, AnalyzeResult > analyzeLayoutResultPoller =
client.beginAnalyzeDocument(modelId, layoutDocumentUrl);
AnalyzeResult analyzeLayoutResult = analyzeLayoutResultPoller.getFinalResult().getAnalyzeResult();
// pages
analyzeLayoutResult.getPages().forEach(documentPage -> {
System.out.printf("Page has width: %.2f and height: %.2f, measured with unit: %s%n",
documentPage.getWidth(),
documentPage.getHeight(),
documentPage.getUnit());
// lines
documentPage.getLines().forEach(documentLine ->
System.out.printf("Line %s is within a bounding polygon %s.%n",
documentLine.getContent(),
documentLine.getBoundingPolygon().toString()));
// words
documentPage.getWords().forEach(documentWord ->
System.out.printf("Word '%s' has a confidence score of %.2f%n",
documentWord.getContent(),
documentWord.getConfidence()));
// selection marks
documentPage.getSelectionMarks().forEach(documentSelectionMark ->
System.out.printf("Selection mark is '%s' and is within a bounding polygon %s with confidence %.2f.%n",
documentSelectionMark.getSelectionMarkState().toString(),
getBoundingCoordinates(documentSelectionMark.getBoundingPolygon()),
documentSelectionMark.getConfidence()));
});
// tables
List < DocumentTable > tables = analyzeLayoutResult.getTables();
for (int i = 0; i < tables.size(); i++) {
DocumentTable documentTables = tables.get(i);
System.out.printf("Table %d has %d rows and %d columns.%n", i, documentTables.getRowCount(),
documentTables.getColumnCount());
documentTables.getCells().forEach(documentTableCell -> {
System.out.printf("Cell '%s', has row index %d and column index %d.%n", documentTableCell.getContent(),
documentTableCell.getRowIndex(), documentTableCell.getColumnIndex());
});
System.out.println();
}
}
// Utility function to get the bounding polygon coordinates.
private static String getBoundingCoordinates(List < Point > boundingPolygon) {
return boundingPolygon.stream().map(point -> String.format("[%.2f, %.2f]", point.getX(),
point.getY())).collect(Collectors.joining(", "));
}
}
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
一般的なドキュメント モデルを使用する
import com.azure.ai.documentintelligence;
import com.azure.ai.documentintelligence.models.AnalyzeDocumentRequest;
import com.azure.ai.documentintelligence.models.AnalyzeResult;
import com.azure.ai.documentintelligence.models.AnalyzeResultOperation;
import com.azure.ai.documentintelligence.models.Document;
import com.azure.ai.documentintelligence.models.DocumentField;
import com.azure.ai.documentintelligence.models.DocumentFieldType;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
public class DocIntelligence {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
DocumentIntelligenceClient client = new DocumentIntelligenceClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String generalDocumentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-layout.pdf";
String modelId = "prebuilt-document";
SyncPoller < OperationResult, AnalyzeResult > analyzeDocumentPoller =
client.beginAnalyzeDocument(modelId, generalDocumentUrl);
AnalyzeResult analyzeResult = analyzeDocumentPoller.getFinalResult().getAnalyzeResult();;
// pages
analyzeResult.getPages().forEach(documentPage -> {
System.out.printf("Page has width: %.2f and height: %.2f, measured with unit: %s%n",
documentPage.getWidth(),
documentPage.getHeight(),
documentPage.getUnit());
// lines
documentPage.getLines().forEach(documentLine ->
System.out.printf("Line %s is within a bounding polygon %s.%n",
documentLine.getContent(),
documentLine.getBoundingPolygon().toString()));
// words
documentPage.getWords().forEach(documentWord ->
System.out.printf("Word %s has a confidence score of %.2f%n.",
documentWord.getContent(),
documentWord.getConfidence()));
});
// tables
List < DocumentTable > tab_les = analyzeResult.getTables();
for (int i = 0; i < tab_les.size(); i++) {
DocumentTable documentTable = tab_les.get(i);
System.out.printf("Table %d has %d rows and %d columns.%n", i, documentTable.getRowCount(),
documentTable.getColumnCount());
documentTable.getCells().forEach(documentTableCell -> {
System.out.printf("Cell '%s', has row index %d and column index %d.%n",
documentTableCell.getContent(),
documentTableCell.getRowIndex(), documentTableCell.getColumnIndex());
});
System.out.println();
}
// Key-value pairs
analyzeResult.getKeyValuePairs().forEach(documentKeyValuePair -> {
System.out.printf("Key content: %s%n", documentKeyValuePair.getKey().getContent());
System.out.printf("Key content bounding region: %s%n",
documentKeyValuePair.getKey().getBoundingRegions().toString());
if (documentKeyValuePair.getValue() != null) {
System.out.printf("Value content: %s%n", documentKeyValuePair.getValue().getContent());
System.out.printf("Value content bounding region: %s%n", documentKeyValuePair.getValue().getBoundingRegions().toString());
}
});
}
}
一般的なドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
W-2 税モデルを使用する
import com.azure.ai.documentintelligence;
import com.azure.ai.documentintelligence.models.AnalyzeDocumentRequest;
import com.azure.ai.documentintelligence.models.AnalyzeResult;
import com.azure.ai.documentintelligence.models.AnalyzeResultOperation;
import com.azure.ai.documentintelligence.models.Document;
import com.azure.ai.documentintelligence.models.DocumentField;
import com.azure.ai.documentintelligence.models.DocumentFieldType;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
public class DocIntelligence {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
DocumentIntelligenceClient client = new DocumentIntelligenceClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
// sample document
String w2Url = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png";
String modelId = "prebuilt-tax.us.w2";
SyncPoller < OperationResult, AnalyzeResult > analyzeW2Poller =
client.beginAnalyzeDocument(modelId, w2Url);
AnalyzeResult analyzeTaxResult = analyzeW2Poller.getFinalResult().getAnalyzeResult();
for (int i = 0; i < analyzeTaxResult.getDocuments().size(); i++) {
AnalyzedDocument analyzedTaxDocument = analyzeTaxResult.getDocuments().get(i);
Map < String, DocumentField > taxFields = analyzedTaxDocument.getFields();
System.out.printf("----------- Analyzing Document %d -----------%n", i);
DocumentField w2FormVariantField = taxFields.get("W2FormVariant");
if (w2FormVariantField != null) {
if (DocumentFieldType.STRING == w2FormVariantField.getType()) {
String merchantName = w2FormVariantField.getValueAsString();
System.out.printf("Form variant: %s, confidence: %.2f%n",
merchantName, w2FormVariantField.getConfidence());
}
}
DocumentField employeeField = taxFields.get("Employee");
if (employeeField != null) {
System.out.println("Employee Data: ");
if (DocumentFieldType.MAP == employeeField.getType()) {
Map < String, DocumentField > employeeDataFieldMap = employeeField.getValueAsMap();
DocumentField employeeName = employeeDataFieldMap.get("Name");
if (employeeName != null) {
if (DocumentFieldType.STRING == employeeName.getType()) {
String employeesName = employeeName.getValueAsString();
System.out.printf("Employee Name: %s, confidence: %.2f%n",
employeesName, employeeName.getConfidence());
}
}
DocumentField employeeAddrField = employeeDataFieldMap.get("Address");
if (employeeAddrField != null) {
if (DocumentFieldType.STRING == employeeAddrField.getType()) {
String employeeAddress = employeeAddrField.getValueAsString();
System.out.printf("Employee Address: %s, confidence: %.2f%n",
employeeAddress, employeeAddrField.getConfidence());
}
}
}
}
DocumentField employerField = taxFields.get("Employer");
if (employerField != null) {
System.out.println("Employer Data: ");
if (DocumentFieldType.MAP == employerField.getType()) {
Map < String, DocumentField > employerDataFieldMap = employerField.getValueAsMap();
DocumentField employerNameField = employerDataFieldMap.get("Name");
if (employerNameField != null) {
if (DocumentFieldType.STRING == employerNameField.getType()) {
String employerName = employerNameField.getValueAsString();
System.out.printf("Employer Name: %s, confidence: %.2f%n",
employerName, employerNameField.getConfidence());
}
}
DocumentField employerIDNumberField = employerDataFieldMap.get("IdNumber");
if (employerIDNumberField != null) {
if (DocumentFieldType.STRING == employerIDNumberField.getType()) {
String employerIdNumber = employerIDNumberField.getValueAsString();
System.out.printf("Employee ID Number: %s, confidence: %.2f%n",
employerIdNumber, employerIDNumberField.getConfidence());
}
}
}
}
DocumentField taxYearField = taxFields.get("TaxYear");
if (taxYearField != null) {
if (DocumentFieldType.STRING == taxYearField.getType()) {
String taxYear = taxYearField.getValueAsString();
System.out.printf("Tax year: %s, confidence: %.2f%n",
taxYear, taxYearField.getConfidence());
}
}
DocumentField taxDateField = taxFields.get("TaxDate");
if (taxDateField != null) {
if (DocumentFieldType.DATE == taxDateField.getType()) {
LocalDate taxDate = taxDateField.getValueAsDate();
System.out.printf("Tax Date: %s, confidence: %.2f%n",
taxDate, taxDateField.getConfidence());
}
}
DocumentField socialSecurityTaxField = taxFields.get("SocialSecurityTaxWithheld");
if (socialSecurityTaxField != null) {
if (DocumentFieldType.DOUBLE == socialSecurityTaxField.getType()) {
Double socialSecurityTax = socialSecurityTaxField.getValueAsDouble();
System.out.printf("Social Security Tax withheld: %.2f, confidence: %.2f%n",
socialSecurityTax, socialSecurityTaxField.getConfidence());
}
}
}
}
}
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
import com.azure.ai.documentintelligence;
import com.azure.ai.documentintelligence.models.AnalyzeDocumentRequest;
import com.azure.ai.documentintelligence.models.AnalyzeResult;
import com.azure.ai.documentintelligence.models.AnalyzeResultOperation;
import com.azure.ai.documentintelligence.models.Document;
import com.azure.ai.documentintelligence.models.DocumentField;
import com.azure.ai.documentintelligence.models.DocumentFieldType;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
public class DocIntelligence {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
DocumentIntelligenceClient client = new DocumentIntelligenceClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
// sample document
String invoiceUrl = "https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf";
String modelId = "prebuilt-invoice";
SyncPoller < OperationResult, AnalyzeResult > analyzeInvoicesPoller =
client.beginAnalyzeDocument(modelId, invoiceUrl);
AnalyzeResult analyzeInvoiceResult = analyzeInvoicesPoller.getFinalResult().getAnalyzeResult();
for (int i = 0; i < analyzeInvoiceResult.getDocuments().size(); i++) {
AnalyzedDocument analyzedInvoice = analyzeInvoiceResult.getDocuments().get(i);
Map < String, DocumentField > invoiceFields = analyzedInvoice.getFields();
System.out.printf("----------- Analyzing invoice %d -----------%n", i);
DocumentField vendorNameField = invoiceFields.get("VendorName");
if (vendorNameField != null) {
if (DocumentFieldType.STRING == vendorNameField.getType()) {
String merchantName = vendorNameField.getValueAsString();
System.out.printf("Vendor Name: %s, confidence: %.2f%n",
merchantName, vendorNameField.getConfidence());
}
}
DocumentField vendorAddressField = invoiceFields.get("VendorAddress");
if (vendorAddressField != null) {
if (DocumentFieldType.STRING == vendorAddressField.getType()) {
String merchantAddress = vendorAddressField.getValueAsString();
System.out.printf("Vendor address: %s, confidence: %.2f%n",
merchantAddress, vendorAddressField.getConfidence());
}
}
DocumentField customerNameField = invoiceFields.get("CustomerName");
if (customerNameField != null) {
if (DocumentFieldType.STRING == customerNameField.getType()) {
String merchantAddress = customerNameField.getValueAsString();
System.out.printf("Customer Name: %s, confidence: %.2f%n",
merchantAddress, customerNameField.getConfidence());
}
}
DocumentField customerAddressRecipientField = invoiceFields.get("CustomerAddressRecipient");
if (customerAddressRecipientField != null) {
if (DocumentFieldType.STRING == customerAddressRecipientField.getType()) {
String customerAddr = customerAddressRecipientField.getValueAsString();
System.out.printf("Customer Address Recipient: %s, confidence: %.2f%n",
customerAddr, customerAddressRecipientField.getConfidence());
}
}
DocumentField invoiceIdField = invoiceFields.get("InvoiceId");
if (invoiceIdField != null) {
if (DocumentFieldType.STRING == invoiceIdField.getType()) {
String invoiceId = invoiceIdField.getValueAsString();
System.out.printf("Invoice ID: %s, confidence: %.2f%n",
invoiceId, invoiceIdField.getConfidence());
}
}
DocumentField invoiceDateField = invoiceFields.get("InvoiceDate");
if (customerNameField != null) {
if (DocumentFieldType.DATE == invoiceDateField.getType()) {
LocalDate invoiceDate = invoiceDateField.getValueAsDate();
System.out.printf("Invoice Date: %s, confidence: %.2f%n",
invoiceDate, invoiceDateField.getConfidence());
}
}
DocumentField invoiceTotalField = invoiceFields.get("InvoiceTotal");
if (customerAddressRecipientField != null) {
if (DocumentFieldType.DOUBLE == invoiceTotalField.getType()) {
Double invoiceTotal = invoiceTotalField.getValueAsDouble();
System.out.printf("Invoice Total: %.2f, confidence: %.2f%n",
invoiceTotal, invoiceTotalField.getConfidence());
}
}
DocumentField invoiceItemsField = invoiceFields.get("Items");
if (invoiceItemsField != null) {
System.out.printf("Invoice Items: %n");
if (DocumentFieldType.LIST == invoiceItemsField.getType()) {
List < DocumentField > invoiceItems = invoiceItemsField.getValueAsList();
invoiceItems.stream()
.filter(invoiceItem -> DocumentFieldType.MAP == invoiceItem.getType())
.map(documentField -> documentField.getValueAsMap())
.forEach(documentFieldMap -> documentFieldMap.forEach((key, documentField) -> {
if ("Description".equals(key)) {
if (DocumentFieldType.STRING == documentField.getType()) {
String name = documentField.getValueAsString();
System.out.printf("Description: %s, confidence: %.2fs%n",
name, documentField.getConfidence());
}
}
if ("Quantity".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double quantity = documentField.getValueAsDouble();
System.out.printf("Quantity: %f, confidence: %.2f%n",
quantity, documentField.getConfidence());
}
}
if ("UnitPrice".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double unitPrice = documentField.getValueAsDouble();
System.out.printf("Unit Price: %f, confidence: %.2f%n",
unitPrice, documentField.getConfidence());
}
}
if ("ProductCode".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double productCode = documentField.getValueAsDouble();
System.out.printf("Product Code: %f, confidence: %.2f%n",
productCode, documentField.getConfidence());
}
}
}));
}
}
}
}
}
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
領収書モデルを使用する
import com.azure.ai.documentintelligence;
import com.azure.ai.documentintelligence.models.AnalyzeDocumentRequest;
import com.azure.ai.documentintelligence.models.AnalyzeResult;
import com.azure.ai.documentintelligence.models.AnalyzeResultOperation;
import com.azure.ai.documentintelligence.models.Document;
import com.azure.ai.documentintelligence.models.DocumentField;
import com.azure.ai.documentintelligence.models.DocumentFieldType;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
public class DocIntelligence {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
DocumentIntelligenceClient client = new DocumentIntelligenceClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
String receiptUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png";
String modelId = "prebuilt-receipt";
SyncPoller < OperationResult, AnalyzeResult > analyzeReceiptPoller =
client.beginAnalyzeDocument(modelId, receiptUrl);
AnalyzeResult receiptResults = analyzeReceiptPoller.getFinalResult().getAnalyzeResult();
for (int i = 0; i < receiptResults.getDocuments().size(); i++) {
AnalyzedDocument analyzedReceipt = receiptResults.getDocuments().get(i);
Map < String, DocumentField > receiptFields = analyzedReceipt.getFields();
System.out.printf("----------- Analyzing receipt info %d -----------%n", i);
DocumentField merchantNameField = receiptFields.get("MerchantName");
if (merchantNameField != null) {
if (DocumentFieldType.STRING == merchantNameField.getType()) {
String merchantName = merchantNameField.getValueAsString();
System.out.printf("Merchant Name: %s, confidence: %.2f%n",
merchantName, merchantNameField.getConfidence());
}
}
DocumentField merchantPhoneNumberField = receiptFields.get("MerchantPhoneNumber");
if (merchantPhoneNumberField != null) {
if (DocumentFieldType.PHONE_NUMBER == merchantPhoneNumberField.getType()) {
String merchantAddress = merchantPhoneNumberField.getValueAsPhoneNumber();
System.out.printf("Merchant Phone number: %s, confidence: %.2f%n",
merchantAddress, merchantPhoneNumberField.getConfidence());
}
}
DocumentField merchantAddressField = receiptFields.get("MerchantAddress");
if (merchantAddressField != null) {
if (DocumentFieldType.STRING == merchantAddressField.getType()) {
String merchantAddress = merchantAddressField.getValueAsString();
System.out.printf("Merchant Address: %s, confidence: %.2f%n",
merchantAddress, merchantAddressField.getConfidence());
}
}
DocumentField transactionDateField = receiptFields.get("TransactionDate");
if (transactionDateField != null) {
if (DocumentFieldType.DATE == transactionDateField.getType()) {
LocalDate transactionDate = transactionDateField.getValueAsDate();
System.out.printf("Transaction Date: %s, confidence: %.2f%n",
transactionDate, transactionDateField.getConfidence());
}
}
DocumentField receiptItemsField = receiptFields.get("Items");
if (receiptItemsField != null) {
System.out.printf("Receipt Items: %n");
if (DocumentFieldType.LIST == receiptItemsField.getType()) {
List < DocumentField > receiptItems = receiptItemsField.getValueAsList();
receiptItems.stream()
.filter(receiptItem -> DocumentFieldType.MAP == receiptItem.getType())
.map(documentField -> documentField.getValueAsMap())
.forEach(documentFieldMap -> documentFieldMap.forEach((key, documentField) -> {
if ("Name".equals(key)) {
if (DocumentFieldType.STRING == documentField.getType()) {
String name = documentField.getValueAsString();
System.out.printf("Name: %s, confidence: %.2fs%n",
name, documentField.getConfidence());
}
}
if ("Quantity".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double quantity = documentField.getValueAsDouble();
System.out.printf("Quantity: %f, confidence: %.2f%n",
quantity, documentField.getConfidence());
}
}
if ("Price".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double price = documentField.getValueAsDouble();
System.out.printf("Price: %f, confidence: %.2f%n",
price, documentField.getConfidence());
}
}
if ("TotalPrice".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double totalPrice = documentField.getValueAsDouble();
System.out.printf("Total Price: %f, confidence: %.2f%n",
totalPrice, documentField.getConfidence());
}
}
}));
}
}
}
}
}
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデルを使用する
import com.azure.ai.documentintelligence;
import com.azure.ai.documentintelligence.models.AnalyzeDocumentRequest;
import com.azure.ai.documentintelligence.models.AnalyzeResult;
import com.azure.ai.documentintelligence.models.AnalyzeResultOperation;
import com.azure.ai.documentintelligence.models.Document;
import com.azure.ai.documentintelligence.models.DocumentField;
import com.azure.ai.documentintelligence.models.DocumentFieldType;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.Map;
public class DocIntelligence {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
DocumentIntelligenceClient client = new DocumentIntelligenceClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String licenseUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png";
String modelId = "prebuilt-idDocument";
SyncPoller < OperationResult, AnalyzeResult > analyzeIdentityDocumentPoller = client.beginAnalyzeDocument(modelId, licenseUrl);
AnalyzeResult identityDocumentResults = analyzeIdentityDocumentPoller.getFinalResult().getAnalyzeResult();
for (int i = 0; i < identityDocumentResults.getDocuments().size(); i++) {
AnalyzedDocument analyzedIDDocument = identityDocumentResults.getDocuments().get(i);
Map < String, DocumentField > licenseFields = analyzedIDDocument.getFields();
System.out.printf("----------- Analyzed license info for page %d -----------%n", i);
DocumentField addressField = licenseFields.get("Address");
if (addressField != null) {
if (DocumentFieldType.STRING == addressField.getType()) {
String address = addressField.getValueAsString();
System.out.printf("Address: %s, confidence: %.2f%n",
address, addressField.getConfidence());
}
}
DocumentField countryRegionDocumentField = licenseFields.get("CountryRegion");
if (countryRegionDocumentField != null) {
if (DocumentFieldType.STRING == countryRegionDocumentField.getType()) {
String countryRegion = countryRegionDocumentField.getValueAsCountry();
System.out.printf("Country or region: %s, confidence: %.2f%n",
countryRegion, countryRegionDocumentField.getConfidence());
}
}
DocumentField dateOfBirthField = licenseFields.get("DateOfBirth");
if (dateOfBirthField != null) {
if (DocumentFieldType.DATE == dateOfBirthField.getType()) {
LocalDate dateOfBirth = dateOfBirthField.getValueAsDate();
System.out.printf("Date of Birth: %s, confidence: %.2f%n",
dateOfBirth, dateOfBirthField.getConfidence());
}
}
DocumentField dateOfExpirationField = licenseFields.get("DateOfExpiration");
if (dateOfExpirationField != null) {
if (DocumentFieldType.DATE == dateOfExpirationField.getType()) {
LocalDate expirationDate = dateOfExpirationField.getValueAsDate();
System.out.printf("Document date of expiration: %s, confidence: %.2f%n",
expirationDate, dateOfExpirationField.getConfidence());
}
}
DocumentField documentNumberField = licenseFields.get("DocumentNumber");
if (documentNumberField != null) {
if (DocumentFieldType.STRING == documentNumberField.getType()) {
String documentNumber = documentNumberField.getValueAsString();
System.out.printf("Document number: %s, confidence: %.2f%n",
documentNumber, documentNumberField.getConfidence());
}
}
DocumentField firstNameField = licenseFields.get("FirstName");
if (firstNameField != null) {
if (DocumentFieldType.STRING == firstNameField.getType()) {
String firstName = firstNameField.getValueAsString();
System.out.printf("First Name: %s, confidence: %.2f%n",
firstName, documentNumberField.getConfidence());
}
}
DocumentField lastNameField = licenseFields.get("LastName");
if (lastNameField != null) {
if (DocumentFieldType.STRING == lastNameField.getType()) {
String lastName = lastNameField.getValueAsString();
System.out.printf("Last name: %s, confidence: %.2f%n",
lastName, lastNameField.getConfidence());
}
}
DocumentField regionField = licenseFields.get("Region");
if (regionField != null) {
if (DocumentFieldType.STRING == regionField.getType()) {
String region = regionField.getValueAsString();
System.out.printf("Region: %s, confidence: %.2f%n",
region, regionField.getConfidence());
}
}
}
}
}
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
前提条件
Azure サブスクリプション。無料で作成できます。
Visual Studio Code または好みの IDE の最新バージョン。 「Java in Visual Studio Code」を参照してください。
- Visual Studio Code には、Windows および macOS 向けに Coding Pack for Javaが用意されています。 このコーディング パックは、
VS Code、Java Development Kit (JDK)、および Microsoft が推奨する拡張機能のコレクションのバンドルです。 コーディング パックを使用して、既存の開発環境を修正できます。 VS Codeと Coding Pack For Java を使用している場合は、Gradle for Java 拡張機能をインストールします。
Visual Studio Code を使用していない場合、開発環境に次のものがインストールされていることを確認してください。
- A Java Development Kit (JDK) バージョン 8 以降。 詳しくは、「Microsoft Build of OpenJDK」を参照してください。
- Gradle、バージョン 6.8 以降。
- Visual Studio Code には、Windows および macOS 向けに Coding Pack for Javaが用意されています。 このコーディング パックは、
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。ヒント
1 つのエンドポイントとキーを使用して複数の Azure AI サービスにアクセスする予定の場合は、Azure AI サービス リソースを作成します。 Document Intelligence へのアクセスのみの場合は、Document Intelligence リソースを作成します。 Microsoft Entra 認証を使用する場合は、単一サービス リソースが必要です。
アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定されたドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書 名刺モデル 事前構築された名刺 サンプル名刺
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
プログラミング環境を設定するには、Gradle プロジェクトを作成し、クライアント ライブラリをインストールします。
Gradle プロジェクトを作成する
コンソール ウィンドウで、アプリの新しいディレクトリを form-recognizer-app という名前で作成し、そのディレクトリに移動します。
mkdir form-recognizer-app cd form-recognizer-app作業ディレクトリから
gradle initコマンドを実行します。 このコマンドによって、Gradle 用の重要なビルド ファイルが作成されます。たとえば、実行時にアプリケーションを作成して構成するために使用される build.gradle.kts などです。gradle init --type basicDSL を選択するよう求められたら、Kotlin を選択します。
[Enter] を選択して、既定のプロジェクト名 form-recognizer-app をそのまま使用します。
クライアント ライブラリをインストールする
この記事では、Gradle 依存関係マネージャーを使用します。 クライアント ライブラリとその他の依存関係マネージャーの情報については、Maven Central Repository を参照してください。
IDE でプロジェクトの build.gradle.kts ファイルを開きます。 次のコードをコピーして貼り付け、必要なプラグインと設定と共に、クライアント ライブラリを
implementationステートメントとして含めます。plugins { java application } application { mainClass.set("FormRecognizer") } repositories { mavenCentral() } dependencies { implementation(group = "com.azure", name = "azure-ai-formrecognizer", version = "4.0.0") }
Java アプリケーションの作成
Document Intelligence サービスとやり取りするために、DocumentAnalysisClient クラスのインスタンスを作成します。 これを行うために、Azure portal の key を使用して AzureKeyCredential を作成し、その AzureKeyCredential と Document Intelligence の endpoint を使用して DocumentAnalysisClient インスタンスを作成します。
form-recognizer-app ディレクトリから、次のコマンドを実行します。
mkdir -p src/main/java次のディレクトリ構造を作成します。
javaディレクトリに移動し、FormRecognizer.java という名前のファイルを作成します。ヒント
PowerShell を使用して新しいファイルを作成できます。 Shift キーを押しながらフォルダーを右クリックして、プロジェクト ディレクトリで PowerShell ウィンドウを開き、次のコマンドを入力します。New-Item FormRecognizer.java。
FormRecognizer.java ファイルを開き、次のいずれかのコード サンプルを選択してコピーし、アプリケーションに貼り付けます。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
readモデルが使用されます。 - 事前構築済みレイアウト モデルは、ドキュメントと画像からテキストとテキストの場所、テーブル、選択マーク、構造体情報を抽出します。
- 事前構築済み tax.us.w2 モデルは、米国内国歳入庁 (IRS) の税フォームで報告された情報を抽出します。
- 事前構築済み請求書モデルは、さまざまな形式の売上請求書から主なフィールドと品目を抽出します。
- 事前構築済み領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
- 事前構築済み idDocument モデルは、米国の運転免許証、国際パスポートの略歴ページ、米国の州の ID、社会保障カード、永住者カードから重要な情報を抽出します。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
次のコマンドを入力します。
gradle build gradle -PmainClass=FormRecognizer run
読み取りモデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String documentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png";
String modelId = "prebuilt-read";
SyncPoller < OperationResult, AnalyzeResult > analyzeLayoutResultPoller =
client.beginAnalyzeDocumentFromUrl(modelId, documentUrl);
AnalyzeResult analyzeLayoutResult = analyzeLayoutResultPoller.getFinalResult();
// pages
analyzeLayoutResult.getPages().forEach(documentPage -> {
System.out.printf("Page has width: %.2f and height: %.2f, measured with unit: %s%n",
documentPage.getWidth(),
documentPage.getHeight(),
documentPage.getUnit());
// lines
documentPage.getLines().forEach(documentLine ->
System.out.printf("Line %s is within a bounding polygon %s.%n",
documentLine.getContent(),
documentLine.getBoundingPolygon().toString()));
// words
documentPage.getWords().forEach(documentWord ->
System.out.printf("Word '%s' has a confidence score of %.2f.%n",
documentWord.getContent(),
documentWord.getConfidence()));
});
}
}
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String layoutDocumentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png";
String modelId = "prebuilt-layout";
SyncPoller < OperationResult, AnalyzeResult > analyzeLayoutResultPoller =
client.beginAnalyzeDocumentFromUrl(modelId, layoutDocumentUrl);
AnalyzeResult analyzeLayoutResult = analyzeLayoutResultPoller.getFinalResult();
// pages
analyzeLayoutResult.getPages().forEach(documentPage -> {
System.out.printf("Page has width: %.2f and height: %.2f, measured with unit: %s%n",
documentPage.getWidth(),
documentPage.getHeight(),
documentPage.getUnit());
// lines
documentPage.getLines().forEach(documentLine ->
System.out.printf("Line %s is within a bounding polygon %s.%n",
documentLine.getContent(),
documentLine.getBoundingPolygon().toString()));
// words
documentPage.getWords().forEach(documentWord ->
System.out.printf("Word '%s' has a confidence score of %.2f%n",
documentWord.getContent(),
documentWord.getConfidence()));
// selection marks
documentPage.getSelectionMarks().forEach(documentSelectionMark ->
System.out.printf("Selection mark is '%s' and is within a bounding polygon %s with confidence %.2f.%n",
documentSelectionMark.getSelectionMarkState().toString(),
getBoundingCoordinates(documentSelectionMark.getBoundingPolygon()),
documentSelectionMark.getConfidence()));
});
// tables
List < DocumentTable > tables = analyzeLayoutResult.getTables();
for (int i = 0; i < tables.size(); i++) {
DocumentTable documentTables = tables.get(i);
System.out.printf("Table %d has %d rows and %d columns.%n", i, documentTables.getRowCount(),
documentTables.getColumnCount());
documentTables.getCells().forEach(documentTableCell -> {
System.out.printf("Cell '%s', has row index %d and column index %d.%n", documentTableCell.getContent(),
documentTableCell.getRowIndex(), documentTableCell.getColumnIndex());
});
System.out.println();
}
}
// Utility function to get the bounding polygon coordinates.
private static String getBoundingCoordinates(List < Point > boundingPolygon) {
return boundingPolygon.stream().map(point -> String.format("[%.2f, %.2f]", point.getX(),
point.getY())).collect(Collectors.joining(", "));
}
}
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
一般的なドキュメント モデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String generalDocumentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-layout.pdf";
String modelId = "prebuilt-document";
SyncPoller < OperationResult, AnalyzeResult > analyzeDocumentPoller =
client.beginAnalyzeDocumentFromUrl(modelId, generalDocumentUrl);
AnalyzeResult analyzeResult = analyzeDocumentPoller.getFinalResult();
// pages
analyzeResult.getPages().forEach(documentPage -> {
System.out.printf("Page has width: %.2f and height: %.2f, measured with unit: %s%n",
documentPage.getWidth(),
documentPage.getHeight(),
documentPage.getUnit());
// lines
documentPage.getLines().forEach(documentLine ->
System.out.printf("Line %s is within a bounding polygon %s.%n",
documentLine.getContent(),
documentLine.getBoundingPolygon().toString()));
// words
documentPage.getWords().forEach(documentWord ->
System.out.printf("Word %s has a confidence score of %.2f%n.",
documentWord.getContent(),
documentWord.getConfidence()));
});
// tables
List < DocumentTable > tab_les = analyzeResult.getTables();
for (int i = 0; i < tab_les.size(); i++) {
DocumentTable documentTable = tab_les.get(i);
System.out.printf("Table %d has %d rows and %d columns.%n", i, documentTable.getRowCount(),
documentTable.getColumnCount());
documentTable.getCells().forEach(documentTableCell -> {
System.out.printf("Cell '%s', has row index %d and column index %d.%n",
documentTableCell.getContent(),
documentTableCell.getRowIndex(), documentTableCell.getColumnIndex());
});
System.out.println();
}
// Key-value pairs
analyzeResult.getKeyValuePairs().forEach(documentKeyValuePair -> {
System.out.printf("Key content: %s%n", documentKeyValuePair.getKey().getContent());
System.out.printf("Key content bounding region: %s%n",
documentKeyValuePair.getKey().getBoundingRegions().toString());
if (documentKeyValuePair.getValue() != null) {
System.out.printf("Value content: %s%n", documentKeyValuePair.getValue().getContent());
System.out.printf("Value content bounding region: %s%n", documentKeyValuePair.getValue().getBoundingRegions().toString());
}
});
}
}
一般的なドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
W-2 税モデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
// sample document
String w2Url = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png";
String modelId = "prebuilt-tax.us.w2";
SyncPoller < OperationResult, AnalyzeResult > analyzeW2Poller =
client.beginAnalyzeDocumentFromUrl(modelId, w2Url);
AnalyzeResult analyzeTaxResult = analyzeW2Poller.getFinalResult();
for (int i = 0; i < analyzeTaxResult.getDocuments().size(); i++) {
AnalyzedDocument analyzedTaxDocument = analyzeTaxResult.getDocuments().get(i);
Map < String, DocumentField > taxFields = analyzedTaxDocument.getFields();
System.out.printf("----------- Analyzing Document %d -----------%n", i);
DocumentField w2FormVariantField = taxFields.get("W2FormVariant");
if (w2FormVariantField != null) {
if (DocumentFieldType.STRING == w2FormVariantField.getType()) {
String merchantName = w2FormVariantField.getValueAsString();
System.out.printf("Form variant: %s, confidence: %.2f%n",
merchantName, w2FormVariantField.getConfidence());
}
}
DocumentField employeeField = taxFields.get("Employee");
if (employeeField != null) {
System.out.println("Employee Data: ");
if (DocumentFieldType.MAP == employeeField.getType()) {
Map < String, DocumentField > employeeDataFieldMap = employeeField.getValueAsMap();
DocumentField employeeName = employeeDataFieldMap.get("Name");
if (employeeName != null) {
if (DocumentFieldType.STRING == employeeName.getType()) {
String employeesName = employeeName.getValueAsString();
System.out.printf("Employee Name: %s, confidence: %.2f%n",
employeesName, employeeName.getConfidence());
}
}
DocumentField employeeAddrField = employeeDataFieldMap.get("Address");
if (employeeAddrField != null) {
if (DocumentFieldType.STRING == employeeAddrField.getType()) {
String employeeAddress = employeeAddrField.getValueAsString();
System.out.printf("Employee Address: %s, confidence: %.2f%n",
employeeAddress, employeeAddrField.getConfidence());
}
}
}
}
DocumentField employerField = taxFields.get("Employer");
if (employerField != null) {
System.out.println("Employer Data: ");
if (DocumentFieldType.MAP == employerField.getType()) {
Map < String, DocumentField > employerDataFieldMap = employerField.getValueAsMap();
DocumentField employerNameField = employerDataFieldMap.get("Name");
if (employerNameField != null) {
if (DocumentFieldType.STRING == employerNameField.getType()) {
String employerName = employerNameField.getValueAsString();
System.out.printf("Employer Name: %s, confidence: %.2f%n",
employerName, employerNameField.getConfidence());
}
}
DocumentField employerIDNumberField = employerDataFieldMap.get("IdNumber");
if (employerIDNumberField != null) {
if (DocumentFieldType.STRING == employerIDNumberField.getType()) {
String employerIdNumber = employerIDNumberField.getValueAsString();
System.out.printf("Employee ID Number: %s, confidence: %.2f%n",
employerIdNumber, employerIDNumberField.getConfidence());
}
}
}
}
DocumentField taxYearField = taxFields.get("TaxYear");
if (taxYearField != null) {
if (DocumentFieldType.STRING == taxYearField.getType()) {
String taxYear = taxYearField.getValueAsString();
System.out.printf("Tax year: %s, confidence: %.2f%n",
taxYear, taxYearField.getConfidence());
}
}
DocumentField taxDateField = taxFields.get("TaxDate");
if (taxDateField != null) {
if (DocumentFieldType.DATE == taxDateField.getType()) {
LocalDate taxDate = taxDateField.getValueAsDate();
System.out.printf("Tax Date: %s, confidence: %.2f%n",
taxDate, taxDateField.getConfidence());
}
}
DocumentField socialSecurityTaxField = taxFields.get("SocialSecurityTaxWithheld");
if (socialSecurityTaxField != null) {
if (DocumentFieldType.DOUBLE == socialSecurityTaxField.getType()) {
Double socialSecurityTax = socialSecurityTaxField.getValueAsDouble();
System.out.printf("Social Security Tax withheld: %.2f, confidence: %.2f%n",
socialSecurityTax, socialSecurityTaxField.getConfidence());
}
}
}
}
}
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
// sample document
String invoiceUrl = "https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf";
String modelId = "prebuilt-invoice";
SyncPoller < OperationResult, AnalyzeResult > analyzeInvoicesPoller =
client.beginAnalyzeDocumentFromUrl(modelId, invoiceUrl);
AnalyzeResult analyzeInvoiceResult = analyzeInvoicesPoller.getFinalResult();
for (int i = 0; i < analyzeInvoiceResult.getDocuments().size(); i++) {
AnalyzedDocument analyzedInvoice = analyzeInvoiceResult.getDocuments().get(i);
Map < String, DocumentField > invoiceFields = analyzedInvoice.getFields();
System.out.printf("----------- Analyzing invoice %d -----------%n", i);
DocumentField vendorNameField = invoiceFields.get("VendorName");
if (vendorNameField != null) {
if (DocumentFieldType.STRING == vendorNameField.getType()) {
String merchantName = vendorNameField.getValueAsString();
System.out.printf("Vendor Name: %s, confidence: %.2f%n",
merchantName, vendorNameField.getConfidence());
}
}
DocumentField vendorAddressField = invoiceFields.get("VendorAddress");
if (vendorAddressField != null) {
if (DocumentFieldType.STRING == vendorAddressField.getType()) {
String merchantAddress = vendorAddressField.getValueAsString();
System.out.printf("Vendor address: %s, confidence: %.2f%n",
merchantAddress, vendorAddressField.getConfidence());
}
}
DocumentField customerNameField = invoiceFields.get("CustomerName");
if (customerNameField != null) {
if (DocumentFieldType.STRING == customerNameField.getType()) {
String merchantAddress = customerNameField.getValueAsString();
System.out.printf("Customer Name: %s, confidence: %.2f%n",
merchantAddress, customerNameField.getConfidence());
}
}
DocumentField customerAddressRecipientField = invoiceFields.get("CustomerAddressRecipient");
if (customerAddressRecipientField != null) {
if (DocumentFieldType.STRING == customerAddressRecipientField.getType()) {
String customerAddr = customerAddressRecipientField.getValueAsString();
System.out.printf("Customer Address Recipient: %s, confidence: %.2f%n",
customerAddr, customerAddressRecipientField.getConfidence());
}
}
DocumentField invoiceIdField = invoiceFields.get("InvoiceId");
if (invoiceIdField != null) {
if (DocumentFieldType.STRING == invoiceIdField.getType()) {
String invoiceId = invoiceIdField.getValueAsString();
System.out.printf("Invoice ID: %s, confidence: %.2f%n",
invoiceId, invoiceIdField.getConfidence());
}
}
DocumentField invoiceDateField = invoiceFields.get("InvoiceDate");
if (customerNameField != null) {
if (DocumentFieldType.DATE == invoiceDateField.getType()) {
LocalDate invoiceDate = invoiceDateField.getValueAsDate();
System.out.printf("Invoice Date: %s, confidence: %.2f%n",
invoiceDate, invoiceDateField.getConfidence());
}
}
DocumentField invoiceTotalField = invoiceFields.get("InvoiceTotal");
if (customerAddressRecipientField != null) {
if (DocumentFieldType.DOUBLE == invoiceTotalField.getType()) {
Double invoiceTotal = invoiceTotalField.getValueAsDouble();
System.out.printf("Invoice Total: %.2f, confidence: %.2f%n",
invoiceTotal, invoiceTotalField.getConfidence());
}
}
DocumentField invoiceItemsField = invoiceFields.get("Items");
if (invoiceItemsField != null) {
System.out.printf("Invoice Items: %n");
if (DocumentFieldType.LIST == invoiceItemsField.getType()) {
List < DocumentField > invoiceItems = invoiceItemsField.getValueAsList();
invoiceItems.stream()
.filter(invoiceItem -> DocumentFieldType.MAP == invoiceItem.getType())
.map(documentField -> documentField.getValueAsMap())
.forEach(documentFieldMap -> documentFieldMap.forEach((key, documentField) -> {
if ("Description".equals(key)) {
if (DocumentFieldType.STRING == documentField.getType()) {
String name = documentField.getValueAsString();
System.out.printf("Description: %s, confidence: %.2fs%n",
name, documentField.getConfidence());
}
}
if ("Quantity".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double quantity = documentField.getValueAsDouble();
System.out.printf("Quantity: %f, confidence: %.2f%n",
quantity, documentField.getConfidence());
}
}
if ("UnitPrice".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double unitPrice = documentField.getValueAsDouble();
System.out.printf("Unit Price: %f, confidence: %.2f%n",
unitPrice, documentField.getConfidence());
}
}
if ("ProductCode".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double productCode = documentField.getValueAsDouble();
System.out.printf("Product Code: %f, confidence: %.2f%n",
productCode, documentField.getConfidence());
}
}
}));
}
}
}
}
}
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
領収書モデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
String receiptUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png";
String modelId = "prebuilt-receipt";
SyncPoller < OperationResult, AnalyzeResult > analyzeReceiptPoller =
client.beginAnalyzeDocumentFromUrl(modelId, receiptUrl);
AnalyzeResult receiptResults = analyzeReceiptPoller.getFinalResult();
for (int i = 0; i < receiptResults.getDocuments().size(); i++) {
AnalyzedDocument analyzedReceipt = receiptResults.getDocuments().get(i);
Map < String, DocumentField > receiptFields = analyzedReceipt.getFields();
System.out.printf("----------- Analyzing receipt info %d -----------%n", i);
DocumentField merchantNameField = receiptFields.get("MerchantName");
if (merchantNameField != null) {
if (DocumentFieldType.STRING == merchantNameField.getType()) {
String merchantName = merchantNameField.getValueAsString();
System.out.printf("Merchant Name: %s, confidence: %.2f%n",
merchantName, merchantNameField.getConfidence());
}
}
DocumentField merchantPhoneNumberField = receiptFields.get("MerchantPhoneNumber");
if (merchantPhoneNumberField != null) {
if (DocumentFieldType.PHONE_NUMBER == merchantPhoneNumberField.getType()) {
String merchantAddress = merchantPhoneNumberField.getValueAsPhoneNumber();
System.out.printf("Merchant Phone number: %s, confidence: %.2f%n",
merchantAddress, merchantPhoneNumberField.getConfidence());
}
}
DocumentField merchantAddressField = receiptFields.get("MerchantAddress");
if (merchantAddressField != null) {
if (DocumentFieldType.STRING == merchantAddressField.getType()) {
String merchantAddress = merchantAddressField.getValueAsString();
System.out.printf("Merchant Address: %s, confidence: %.2f%n",
merchantAddress, merchantAddressField.getConfidence());
}
}
DocumentField transactionDateField = receiptFields.get("TransactionDate");
if (transactionDateField != null) {
if (DocumentFieldType.DATE == transactionDateField.getType()) {
LocalDate transactionDate = transactionDateField.getValueAsDate();
System.out.printf("Transaction Date: %s, confidence: %.2f%n",
transactionDate, transactionDateField.getConfidence());
}
}
DocumentField receiptItemsField = receiptFields.get("Items");
if (receiptItemsField != null) {
System.out.printf("Receipt Items: %n");
if (DocumentFieldType.LIST == receiptItemsField.getType()) {
List < DocumentField > receiptItems = receiptItemsField.getValueAsList();
receiptItems.stream()
.filter(receiptItem -> DocumentFieldType.MAP == receiptItem.getType())
.map(documentField -> documentField.getValueAsMap())
.forEach(documentFieldMap -> documentFieldMap.forEach((key, documentField) -> {
if ("Name".equals(key)) {
if (DocumentFieldType.STRING == documentField.getType()) {
String name = documentField.getValueAsString();
System.out.printf("Name: %s, confidence: %.2fs%n",
name, documentField.getConfidence());
}
}
if ("Quantity".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double quantity = documentField.getValueAsDouble();
System.out.printf("Quantity: %f, confidence: %.2f%n",
quantity, documentField.getConfidence());
}
}
if ("Price".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double price = documentField.getValueAsDouble();
System.out.printf("Price: %f, confidence: %.2f%n",
price, documentField.getConfidence());
}
}
if ("TotalPrice".equals(key)) {
if (DocumentFieldType.DOUBLE == documentField.getType()) {
Double totalPrice = documentField.getValueAsDouble();
System.out.printf("Total Price: %f, confidence: %.2f%n",
totalPrice, documentField.getConfidence());
}
}
}));
}
}
}
}
}
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String licenseUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png";
String modelId = "prebuilt-idDocument";
SyncPoller < OperationResult, AnalyzeResult > analyzeIdentityDocumentPoller = client.beginAnalyzeDocumentFromUrl(modelId, licenseUrl);
AnalyzeResult identityDocumentResults = analyzeIdentityDocumentPoller.getFinalResult();
for (int i = 0; i < identityDocumentResults.getDocuments().size(); i++) {
AnalyzedDocument analyzedIDDocument = identityDocumentResults.getDocuments().get(i);
Map < String, DocumentField > licenseFields = analyzedIDDocument.getFields();
System.out.printf("----------- Analyzed license info for page %d -----------%n", i);
DocumentField addressField = licenseFields.get("Address");
if (addressField != null) {
if (DocumentFieldType.STRING == addressField.getType()) {
String address = addressField.getValueAsString();
System.out.printf("Address: %s, confidence: %.2f%n",
address, addressField.getConfidence());
}
}
DocumentField countryRegionDocumentField = licenseFields.get("CountryRegion");
if (countryRegionDocumentField != null) {
if (DocumentFieldType.STRING == countryRegionDocumentField.getType()) {
String countryRegion = countryRegionDocumentField.getValueAsCountry();
System.out.printf("Country or region: %s, confidence: %.2f%n",
countryRegion, countryRegionDocumentField.getConfidence());
}
}
DocumentField dateOfBirthField = licenseFields.get("DateOfBirth");
if (dateOfBirthField != null) {
if (DocumentFieldType.DATE == dateOfBirthField.getType()) {
LocalDate dateOfBirth = dateOfBirthField.getValueAsDate();
System.out.printf("Date of Birth: %s, confidence: %.2f%n",
dateOfBirth, dateOfBirthField.getConfidence());
}
}
DocumentField dateOfExpirationField = licenseFields.get("DateOfExpiration");
if (dateOfExpirationField != null) {
if (DocumentFieldType.DATE == dateOfExpirationField.getType()) {
LocalDate expirationDate = dateOfExpirationField.getValueAsDate();
System.out.printf("Document date of expiration: %s, confidence: %.2f%n",
expirationDate, dateOfExpirationField.getConfidence());
}
}
DocumentField documentNumberField = licenseFields.get("DocumentNumber");
if (documentNumberField != null) {
if (DocumentFieldType.STRING == documentNumberField.getType()) {
String documentNumber = documentNumberField.getValueAsString();
System.out.printf("Document number: %s, confidence: %.2f%n",
documentNumber, documentNumberField.getConfidence());
}
}
DocumentField firstNameField = licenseFields.get("FirstName");
if (firstNameField != null) {
if (DocumentFieldType.STRING == firstNameField.getType()) {
String firstName = firstNameField.getValueAsString();
System.out.printf("First Name: %s, confidence: %.2f%n",
firstName, documentNumberField.getConfidence());
}
}
DocumentField lastNameField = licenseFields.get("LastName");
if (lastNameField != null) {
if (DocumentFieldType.STRING == lastNameField.getType()) {
String lastName = lastNameField.getValueAsString();
System.out.printf("Last name: %s, confidence: %.2f%n",
lastName, lastNameField.getConfidence());
}
}
DocumentField regionField = licenseFields.get("Region");
if (regionField != null) {
if (DocumentFieldType.STRING == regionField.getType()) {
String region = regionField.getValueAsString();
System.out.printf("Region: %s, confidence: %.2f%n",
region, regionField.getConfidence());
}
}
}
}
}
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
名刺モデルを使用する
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.documentanalysis.models.*;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClient;
import com.azure.ai.formrecognizer.documentanalysis.DocumentAnalysisClientBuilder;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.polling.SyncPoller;
import java.io.IOException;
import java.util.List;
import java.util.Arrays;
import java.time.LocalDate;
import java.util.Map;
import java.util.stream.Collectors;
public class FormRecognizer {
//use your `key` and `endpoint` environment variables
private static final String key = System.getenv("FR_KEY");
private static final String endpoint = System.getenv("FR_ENDPOINT");
public static void main(final String[] args) {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
DocumentAnalysisClient client = new DocumentAnalysisClientBuilder()
.credential(new AzureKeyCredential(key))
.endpoint(endpoint)
.buildClient();
//sample document
String businessCardUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/de5e0d8982ab754823c54de47a47e8e499351523/curl/form-recognizer/rest-api/business_card.jpg";
String modelId = "prebuilt-businessCard";
SyncPoller < OperationResult, AnalyzeResult > analyzeBusinessCardPoller = client.beginAnalyzeDocumentFromUrl(modelId, businessCardUrl);
AnalyzeResult businessCardPageResults = analyzeBusinessCardPoller.getFinalResult();
for (int i = 0; i < businessCardPageResults.getDocuments().size(); i++) {
System.out.printf("--------Analyzing business card %d -----------%n", i);
AnalyzedDocument analyzedBusinessCard = businessCardPageResults.getDocuments().get(i);
Map < String, DocumentField > businessCardFields = analyzedBusinessCard.getFields();
DocumentField contactNamesDocumentField = businessCardFields.get("ContactNames");
if (contactNamesDocumentField != null) {
if (DocumentFieldType.LIST == contactNamesDocumentField.getType()) {
List < DocumentField > contactNamesList = contactNamesDocumentField.getValueAsList();
contactNamesList.stream()
.filter(contactName -> DocumentFieldType.MAP == contactName.getType())
.map(contactName -> {
System.out.printf("Contact name: %s%n", contactName.getContent());
return contactName.getValueAsMap();
})
.forEach(contactNamesMap -> contactNamesMap.forEach((key, contactName) -> {
if ("FirstName".equals(key)) {
if (DocumentFieldType.STRING == contactName.getType()) {
String firstName = contactName.getValueAsString();
System.out.printf("\tFirst Name: %s, confidence: %.2f%n",
firstName, contactName.getConfidence());
}
}
if ("LastName".equals(key)) {
if (DocumentFieldType.STRING == contactName.getType()) {
String lastName = contactName.getValueAsString();
System.out.printf("\tLast Name: %s, confidence: %.2f%n",
lastName, contactName.getConfidence());
}
}
}));
}
}
DocumentField jobTitles = businessCardFields.get("JobTitles");
if (jobTitles != null) {
if (DocumentFieldType.LIST == jobTitles.getType()) {
List < DocumentField > jobTitlesItems = jobTitles.getValueAsList();
jobTitlesItems.forEach(jobTitlesItem -> {
if (DocumentFieldType.STRING == jobTitlesItem.getType()) {
String jobTitle = jobTitlesItem.getValueAsString();
System.out.printf("Job Title: %s, confidence: %.2f%n",
jobTitle, jobTitlesItem.getConfidence());
}
});
}
}
DocumentField departments = businessCardFields.get("Departments");
if (departments != null) {
if (DocumentFieldType.LIST == departments.getType()) {
List < DocumentField > departmentsItems = departments.getValueAsList();
departmentsItems.forEach(departmentsItem -> {
if (DocumentFieldType.STRING == departmentsItem.getType()) {
String department = departmentsItem.getValueAsString();
System.out.printf("Department: %s, confidence: %.2f%n",
department, departmentsItem.getConfidence());
}
});
}
}
DocumentField emails = businessCardFields.get("Emails");
if (emails != null) {
if (DocumentFieldType.LIST == emails.getType()) {
List < DocumentField > emailsItems = emails.getValueAsList();
emailsItems.forEach(emailsItem -> {
if (DocumentFieldType.STRING == emailsItem.getType()) {
String email = emailsItem.getValueAsString();
System.out.printf("Email: %s, confidence: %.2f%n", email, emailsItem.getConfidence());
}
});
}
}
DocumentField websites = businessCardFields.get("Websites");
if (websites != null) {
if (DocumentFieldType.LIST == websites.getType()) {
List < DocumentField > websitesItems = websites.getValueAsList();
websitesItems.forEach(websitesItem -> {
if (DocumentFieldType.STRING == websitesItem.getType()) {
String website = websitesItem.getValueAsString();
System.out.printf("Web site: %s, confidence: %.2f%n",
website, websitesItem.getConfidence());
}
});
}
}
DocumentField mobilePhones = businessCardFields.get("MobilePhones");
if (mobilePhones != null) {
if (DocumentFieldType.LIST == mobilePhones.getType()) {
List < DocumentField > mobilePhonesItems = mobilePhones.getValueAsList();
mobilePhonesItems.forEach(mobilePhonesItem -> {
if (DocumentFieldType.PHONE_NUMBER == mobilePhonesItem.getType()) {
String mobilePhoneNumber = mobilePhonesItem.getValueAsPhoneNumber();
System.out.printf("Mobile phone number: %s, confidence: %.2f%n",
mobilePhoneNumber, mobilePhonesItem.getConfidence());
}
});
}
}
DocumentField otherPhones = businessCardFields.get("OtherPhones");
if (otherPhones != null) {
if (DocumentFieldType.LIST == otherPhones.getType()) {
List < DocumentField > otherPhonesItems = otherPhones.getValueAsList();
otherPhonesItems.forEach(otherPhonesItem -> {
if (DocumentFieldType.PHONE_NUMBER == otherPhonesItem.getType()) {
String otherPhoneNumber = otherPhonesItem.getValueAsPhoneNumber();
System.out.printf("Other phone number: %s, confidence: %.2f%n",
otherPhoneNumber, otherPhonesItem.getConfidence());
}
});
}
}
DocumentField faxes = businessCardFields.get("Faxes");
if (faxes != null) {
if (DocumentFieldType.LIST == faxes.getType()) {
List < DocumentField > faxesItems = faxes.getValueAsList();
faxesItems.forEach(faxesItem -> {
if (DocumentFieldType.PHONE_NUMBER == faxesItem.getType()) {
String faxPhoneNumber = faxesItem.getValueAsPhoneNumber();
System.out.printf("Fax phone number: %s, confidence: %.2f%n",
faxPhoneNumber, faxesItem.getConfidence());
}
});
}
}
DocumentField addresses = businessCardFields.get("Addresses");
if (addresses != null) {
if (DocumentFieldType.LIST == addresses.getType()) {
List < DocumentField > addressesItems = addresses.getValueAsList();
addressesItems.forEach(addressesItem -> {
if (DocumentFieldType.STRING == addressesItem.getType()) {
String address = addressesItem.getValueAsString();
System.out
.printf("Address: %s, confidence: %.2f%n", address, addressesItem.getConfidence());
}
});
}
}
DocumentField companyName = businessCardFields.get("CompanyNames");
if (companyName != null) {
if (DocumentFieldType.LIST == companyName.getType()) {
List < DocumentField > companyNameItems = companyName.getValueAsList();
companyNameItems.forEach(companyNameItem -> {
if (DocumentFieldType.STRING == companyNameItem.getType()) {
String companyNameValue = companyNameItem.getValueAsString();
System.out.printf("Company name: %s, confidence: %.2f%n", companyNameValue,
companyNameItem.getConfidence());
}
});
}
}
}
}
}
名刺モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
クライアント ライブラリ | REST API リファレンス | パッケージ (npm) | サンプル |サポートされている REST API バージョン
前提条件
Azure サブスクリプション。無料で作成できます。
Visual Studio Code または好みの IDE の最新バージョン。 詳細については、「Visual Studio Code の Node.js」を参照してください
最新
LTSバージョンの Node.js。Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。ヒント
1 つのエンドポイントとキーを使用して複数の Azure AI サービスにアクセスする予定の場合は、Azure AI サービス リソースを作成します。 Document Intelligence へのアクセスのみの場合は、Document Intelligence リソースを作成します。 Microsoft Entra 認証を使用する場合は、単一サービス リソースが必要です。
アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定されたドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
Node.js Express アプリケーションを作成します。
コンソール ウィンドウで、アプリ用の新しいディレクトリを
doc-intel-appという名前で作成し、そこに移動します。mkdir doc-intel-app cd doc-intel-appnpm initコマンドを実行して、アプリケーションを初期化し、プロジェクトをスキャフォールディングします。npm initターミナルに表示されるプロンプトを使用して、プロジェクトの属性を指定します。
- 最も重要な属性は、名前、バージョン番号、およびエントリ ポイントです。
index.jsという名前は、エントリ ポイント名として取っておくことをお勧めします。 説明、テスト コマンド、GitHub リポジトリ、キーワード、作成者、ライセンス情報は省略可能な属性です。 このプロジェクトではスキップできます。- [Enter] を選択して、かっこ内の候補を受け入れます。
プロンプトが完了すると、コマンドによって
package.jsonファイルが doc-intel-app ディレクトリに作成されます。ai-document-intelligenceクライアント ライブラリとazure/identitynpm パッケージをインストールします。npm i @azure-rest/ai-document-intelligence@1.0.0-beta.3 @azure/identity
アプリの package.json ファイルはこの依存関係について更新されます。
index.js というファイルをアプリケーション ディレクトリ内に作成します。
ヒント
PowerShell を使用して新しいファイルを作成できます。 Shift キーを押しながらフォルダーを右クリックして、プロジェクト ディレクトリで PowerShell ウィンドウを開き、次のコマンドを入力します。New-Item index.js。
アプリケーションをビルドする
Document Intelligence サービスとやり取りするには、DocumentIntelligenceClient クラスのインスタンスを作成する必要があります。 これを行うために、Azure portal のキーを使用して AzureKeyCredential を作成し、その AzureKeyCredential と Document Intelligence のエンドポイントを使用して DocumentIntelligenceClient インスタンスを作成します。
Visual Studio Code または任意の IDE で index.js ファイルを開き、次のコード サンプルのいずれかを選択してコピーし、アプリケーションに貼り付けます。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
readモデルが使用されます。 - 事前構築済みレイアウト モデルは、ドキュメントと画像からテキストとテキストの場所、テーブル、選択マーク、構造体情報を抽出します。
- 事前構築済み tax.us.w2 モデルは、米国内国歳入庁 (IRS) の税フォームで報告された情報を抽出します。
- 事前構築済み請求書 モデルは、米国 Internal Revenue Service の税フォームで報告された情報を抽出します。
- 事前構築済み領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
- 事前構築済み idDocument モデルは、米国の運転免許証、国際パスポートの略歴ページ、米国の州の ID、社会保障カード、永住者カードから重要な情報を抽出します。
読み取りモデルを使用する
const { DocumentIntelligenceClient } = require("@azure-rest/ai-document-intelligence");
const { AzureKeyCredential } = require("@azure/core-auth");
//use your `key` and `endpoint` environment variables
const key = process.env['DI_KEY'];
const endpoint = process.env['DI_ENDPOINT'];
// sample document
const documentUrlRead = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png"
// helper function
function* getTextOfSpans(content, spans) {
for (const span of spans) {
yield content.slice(span.offset, span.offset + span.length);
}
}
async function main() {
// create your `DocumentIntelligenceClient` instance and `AzureKeyCredential` variable
const client = DocumentIntelligence(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-read", documentUrlRead);
const {
content,
pages,
languages,
styles
} = await poller.pollUntilDone();
if (pages.length <= 0) {
console.log("No pages were extracted from the document.");
} else {
console.log("Pages:");
for (const page of pages) {
console.log("- Page", page.pageNumber, `(unit: ${page.unit})`);
console.log(` ${page.width}x${page.height}, angle: ${page.angle}`);
console.log(` ${page.lines.length} lines, ${page.words.length} words`);
if (page.lines.length > 0) {
console.log(" Lines:");
for (const line of page.lines) {
console.log(` - "${line.content}"`);
// The words of the line can also be iterated independently. The words are computed based on their
// corresponding spans.
for (const word of line.words()) {
console.log(` - "${word.content}"`);
}
}
}
}
}
if (languages.length <= 0) {
console.log("No language spans were extracted from the document.");
} else {
console.log("Languages:");
for (const languageEntry of languages) {
console.log(
`- Found language: ${languageEntry.languageCode} (confidence: ${languageEntry.confidence})`
);
for (const text of getTextOfSpans(content, languageEntry.spans)) {
const escapedText = text.replace(/\r?\n/g, "\\n").replace(/"/g, '\\"');
console.log(` - "${escapedText}"`);
}
}
}
if (styles.length <= 0) {
console.log("No text styles were extracted from the document.");
} else {
console.log("Styles:");
for (const style of styles) {
console.log(
`- Handwritten: ${style.isHandwritten ? "yes" : "no"} (confidence=${style.confidence})`
);
for (const word of getTextOfSpans(content, style.spans)) {
console.log(` - "${word}"`);
}
}
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
const { DocumentIntelligenceClient } = require("@azure-rest/ai-document-intelligence");
const { AzureKeyCredential } = require("@azure/core-auth");
//use your `key` and `endpoint` environment variables
const key = process.env['DI_KEY'];
const endpoint = process.env['DI_ENDPOINT'];
// sample document
const layoutUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png"
async function main() {
const client = DocumentIntelligence(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument(
"prebuilt-layout", layoutUrl);
// Layout extraction produces basic elements such as pages, words, lines, etc. as well as information about the
// appearance (styles) of textual elements.
const { pages, tables } = await poller.pollUntilDone();
if (!pages || pages.length <= 0) {
console.log("No pages were extracted from the document.");
} else {
console.log("Pages:");
for (const page of pages) {
console.log("- Page", page.pageNumber, `(unit: ${page.unit})`);
console.log(` ${page.width}x${page.height}, angle: ${page.angle}`);
console.log(
` ${page.lines && page.lines.length} lines, ${page.words && page.words.length} words`
);
if (page.lines && page.lines.length > 0) {
console.log(" Lines:");
for (const line of page.lines) {
console.log(` - "${line.content}"`);
// The words of the line can also be iterated independently. The words are computed based on their
// corresponding spans.
for (const word of line.words()) {
console.log(` - "${word.content}"`);
}
}
}
}
}
if (!tables || tables.length <= 0) {
console.log("No tables were extracted from the document.");
} else {
console.log("Tables:");
for (const table of tables) {
console.log(
`- Extracted table: ${table.columnCount} columns, ${table.rowCount} rows (${table.cells.length} cells)`
);
}
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
一般的なドキュメント モデルを使用する
const { DocumentIntelligenceClient } = require("@azure-rest/ai-document-intelligence");
const { AzureKeyCredential } = require("@azure/core-auth");
//use your `key` and `endpoint` environment variables
const key = process.env['DI_KEY'];
const endpoint = process.env['DI_ENDPOINT'];
// sample document
const documentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-layout.pdf"
async function main() {
const client = DocumentIntelligence(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-document", documentUrl);
const {
keyValuePairs
} = await poller.pollUntilDone();
if (!keyValuePairs || keyValuePairs.length <= 0) {
console.log("No key-value pairs were extracted from the document.");
} else {
console.log("Key-Value Pairs:");
for (const {
key,
value,
confidence
} of keyValuePairs) {
console.log("- Key :", `"${key.content}"`);
console.log(" Value:", `"${(value && value.content) || "<undefined>"}" (${confidence})`);
}
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
一般的なドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
W-2 税モデルを使用する
const { DocumentIntelligenceClient } = require("@azure-rest/ai-document-intelligence");
const { AzureKeyCredential } = require("@azure/core-auth");
//use your `key` and `endpoint` environment variables
const key = process.env['DI_KEY'];
const endpoint = process.env['DI_ENDPOINT'];
const w2DocumentURL = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png"
async function main() {
const client = DocumentIntelligence(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-tax.us.w2", w2DocumentURL);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
const { Employee, Employer, ControlNumber, TaxYear, AdditionalInfo } = result.fields;
if (Employee) {
const { Name, Address, SocialSecurityNumber } = Employee.properties;
console.log("Employee:");
console.log(" Name:", Name && Name.content);
console.log(" SSN/TIN:", SocialSecurityNumber && SocialSecurityNumber.content);
if (Address && Address.value) {
const { streetAddress, postalCode } = Address.value;
console.log(" Address:");
console.log(" Street Address:", streetAddress);
console.log(" Postal Code:", postalCode);
}
} else {
console.log("No employee information extracted.");
}
if (Employer) {
const { Name, Address, IdNumber } = Employer.properties;
console.log("Employer:");
console.log(" Name:", Name && Name.content);
console.log(" ID (EIN):", IdNumber && IdNumber.content);
if (Address && Address.value) {
const { streetAddress, postalCode } = Address.value;
console.log(" Address:");
console.log(" Street Address:", streetAddress);
console.log(" Postal Code:", postalCode);
}
} else {
console.log("No employer information extracted.");
}
console.log("Control Number:", ControlNumber && ControlNumber.content);
console.log("Tax Year:", TaxYear && TaxYear.content);
if (AdditionalInfo) {
console.log("Additional Info:");
for (const info of AdditionalInfo.values) {
const { LetterCode, Amount } = info.properties;
console.log(`- ${LetterCode && LetterCode.content}: ${Amount && Amount.content}`);
}
}
} else {
throw new Error("Expected at least one document in the result.");
}
}
main().catch((error) => {
console.error(error);
process.exit(1);
});
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
const { DocumentIntelligenceClient } = require("@azure-rest/ai-document-intelligence");
const { AzureKeyCredential } = require("@azure/core-auth");
//use your `key` and `endpoint` environment variables
const key = process.env['DI_KEY'];
const endpoint = process.env['DI_ENDPOINT'];
// sample url
const invoiceUrl = "https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf";
async function main() {
const client = DocumentIntelligence(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-invoice", invoiceUrl);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
const invoice = result.fields;
console.log("Vendor Name:", invoice.VendorName?.content);
console.log("Customer Name:", invoice.CustomerName?.content);
console.log("Invoice Date:", invoice.InvoiceDate?.content);
console.log("Due Date:", invoice.DueDate?.content);
console.log("Items:");
for (const {
properties: item
} of invoice.Items?.values ?? []) {
console.log("-", item.ProductCode?.content ?? "<no product code>");
console.log(" Description:", item.Description?.content);
console.log(" Quantity:", item.Quantity?.content);
console.log(" Date:", item.Date?.content);
console.log(" Unit:", item.Unit?.content);
console.log(" Unit Price:", item.UnitPrice?.content);
console.log(" Tax:", item.Tax?.content);
console.log(" Amount:", item.Amount?.content);
}
console.log("Subtotal:", invoice.SubTotal?.content);
console.log("Previous Unpaid Balance:", invoice.PreviousUnpaidBalance?.content);
console.log("Tax:", invoice.TotalTax?.content);
console.log("Amount Due:", invoice.AmountDue?.content);
} else {
throw new Error("Expected at least one receipt in the result.");
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レシート モデルを使用する
const { DocumentIntelligenceClient } = require("@azure-rest/ai-document-intelligence");
const { AzureKeyCredential } = require("@azure/core-auth");
//use your `key` and `endpoint` environment variables
const key = process.env['DI_KEY'];
const endpoint = process.env['DI_ENDPOINT'];
// sample url
const receiptUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png";
async function main() {
const client = DocumentIntelligence(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-receipt", receiptUrl);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
const {
MerchantName,
Items,
Total
} = result.fields;
console.log("=== Receipt Information ===");
console.log("Type:", result.docType);
console.log("Merchant:", MerchantName && MerchantName.content);
console.log("Items:");
for (const item of (Items && Items.values) || []) {
const {
Description,
TotalPrice
} = item.properties;
console.log("- Description:", Description && Description.content);
console.log(" Total Price:", TotalPrice && TotalPrice.content);
}
console.log("Total:", Total && Total.content);
} else {
throw new Error("Expected at least one receipt in the result.");
}
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデルを使用する
const { DocumentIntelligenceClient } = require("@azure-rest/ai-document-intelligence");
const { AzureKeyCredential } = require("@azure/core-auth");
//use your `key` and `endpoint` environment variables
const key = process.env['DI_KEY'];
const endpoint = process.env['DI_ENDPOINT'];
// sample document
const idDocumentURL = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png"
async function main() {
const client = DocumentIntelligence(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-idDocument", idDocumentURL);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
// The identity document model has multiple document types, so we need to know which document type was actually
extracted.
if (result.docType === "idDocument.driverLicense") {
const { FirstName, LastName, DocumentNumber, DateOfBirth, DateOfExpiration, Height, Weight, EyeColor, Endorsements, Restrictions, VehicleClassifications} = result.fields;
// For the sake of the example, we'll only show a few of the fields that are produced.
console.log("Extracted a Driver License:");
console.log(" Name:", FirstName && FirstName.content, LastName && LastName.content);
console.log(" License No.:", DocumentNumber && DocumentNumber.content);
console.log(" Date of Birth:", DateOfBirth && DateOfBirth.content);
console.log(" Expiration:", DateOfExpiration && DateOfExpiration.content);
console.log(" Height:", Height && Height.content);
console.log(" Weight:", Weight && Weight.content);
console.log(" Eye color:", EyeColor && EyeColor.content);
console.log(" Restrictions:", Restrictions && Restrictions.content);
console.log(" Endorsements:", Endorsements && Endorsements.content);
console.log(" Class:", VehicleClassifications && VehicleClassifications.content);
} else if (result.docType === "idDocument.passport") {
// The passport document type extracts and parses the Passport's machine-readable zone
if (!result.fields.machineReadableZone) {
throw new Error("No Machine Readable Zone extracted from passport.");
}
const {
FirstName,
LastName,
DateOfBirth,
Nationality,
DocumentNumber,
CountryRegion,
DateOfExpiration,
} = result.fields.machineReadableZone.properties;
console.log("Extracted a Passport:");
console.log(" Name:", FirstName && FirstName.content, LastName && LastName.content);
console.log(" Date of Birth:", DateOfBirth && DateOfBirth.content);
console.log(" Nationality:", Nationality && Nationality.content);
console.log(" Passport No.:", DocumentNumber && DocumentNumber.content);
console.log(" Issuer:", CountryRegion && CountryRegion.content);
console.log(" Expiration Date:", DateOfExpiration && DateOfExpiration.content);
} else {
// The only reason this would happen is if the client library's schema for the prebuilt identity document model is
out of date, and a new document type has been introduced.
console.error("Unknown document type in result:", result);
}
} else {
throw new Error("Expected at least one receipt in the result.");
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
前提条件
Azure サブスクリプション。無料で作成できます。
Visual Studio Code または好みの IDE の最新バージョン。 詳細については、「Visual Studio Code の Node.js」を参照してください
最新
LTSバージョンの Node.js。Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。ヒント
1 つのエンドポイントとキーを使用して複数の Azure AI サービスにアクセスする予定の場合は、Azure AI サービス リソースを作成します。 Document Intelligence へのアクセスのみの場合は、Document Intelligence リソースを作成します。 Microsoft Entra 認証を使用する場合は、単一サービス リソースが必要です。
アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定されたドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書 名刺モデル 事前構築された名刺 サンプル名刺
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
Node.js Express アプリケーションを作成します。
コンソール ウィンドウで、アプリ用の新しいディレクトリを
form-recognizer-appという名前で作成し、そこに移動します。mkdir form-recognizer-app cd form-recognizer-appnpm initコマンドを実行して、アプリケーションを初期化し、プロジェクトをスキャフォールディングします。npm initターミナルに表示されるプロンプトを使用して、プロジェクトの属性を指定します。
- 最も重要な属性は、名前、バージョン番号、およびエントリ ポイントです。
index.jsという名前は、エントリ ポイント名として取っておくことをお勧めします。 説明、テスト コマンド、GitHub リポジトリ、キーワード、作成者、ライセンス情報は省略可能な属性です。 このプロジェクトではスキップできます。- [Enter] を選択して、かっこ内の候補を受け入れます。
プロンプトが完了すると、コマンドによって
package.jsonファイルが form-recognizer-app ディレクトリに作成されます。ai-form-recognizerクライアント ライブラリとazure/identitynpm パッケージをインストールします。npm i @azure/ai-form-recognizer @azure/identity
アプリの package.json ファイルはこの依存関係について更新されます。
index.js というファイルをアプリケーション ディレクトリ内に作成します。
ヒント
PowerShell を使用して新しいファイルを作成できます。 Shift キーを押しながらフォルダーを右クリックして、プロジェクト ディレクトリで PowerShell ウィンドウを開き、次のコマンドを入力します。New-Item index.js。
アプリケーションをビルドする
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うために、Azure portal のキーを使用して AzureKeyCredential を作成し、その AzureKeyCredential と Document Intelligence のエンドポイントを使用して DocumentAnalysisClient インスタンスを作成します。
Visual Studio Code または任意の IDE で index.js ファイルを開き、次のコード サンプルのいずれかを選択してコピーし、アプリケーションに貼り付けます。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
readモデルが使用されます。 - 事前構築済みレイアウト モデルは、ドキュメントと画像からテキストとテキストの場所、テーブル、選択マーク、構造体情報を抽出します。
- 事前構築済み tax.us.w2 モデルは、米国内国歳入庁 (IRS) の税フォームで報告された情報を抽出します。
- 事前構築済み請求書 モデルは、米国 Internal Revenue Service の税フォームで報告された情報を抽出します。
- 事前構築済み領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
- 事前構築済み idDocument モデルは、米国の運転免許証、国際パスポートの略歴ページ、米国の州の ID、社会保障カード、永住者カードから重要な情報を抽出します。
読み取りモデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
// sample document
const documentUrlRead = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png"
// helper function
function* getTextOfSpans(content, spans) {
for (const span of spans) {
yield content.slice(span.offset, span.offset + span.length);
}
}
async function main() {
// create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-read", documentUrlRead);
const {
content,
pages,
languages,
styles
} = await poller.pollUntilDone();
if (pages.length <= 0) {
console.log("No pages were extracted from the document.");
} else {
console.log("Pages:");
for (const page of pages) {
console.log("- Page", page.pageNumber, `(unit: ${page.unit})`);
console.log(` ${page.width}x${page.height}, angle: ${page.angle}`);
console.log(` ${page.lines.length} lines, ${page.words.length} words`);
if (page.lines.length > 0) {
console.log(" Lines:");
for (const line of page.lines) {
console.log(` - "${line.content}"`);
// The words of the line can also be iterated independently. The words are computed based on their
// corresponding spans.
for (const word of line.words()) {
console.log(` - "${word.content}"`);
}
}
}
}
}
if (languages.length <= 0) {
console.log("No language spans were extracted from the document.");
} else {
console.log("Languages:");
for (const languageEntry of languages) {
console.log(
`- Found language: ${languageEntry.languageCode} (confidence: ${languageEntry.confidence})`
);
for (const text of getTextOfSpans(content, languageEntry.spans)) {
const escapedText = text.replace(/\r?\n/g, "\\n").replace(/"/g, '\\"');
console.log(` - "${escapedText}"`);
}
}
}
if (styles.length <= 0) {
console.log("No text styles were extracted from the document.");
} else {
console.log("Styles:");
for (const style of styles) {
console.log(
`- Handwritten: ${style.isHandwritten ? "yes" : "no"} (confidence=${style.confidence})`
);
for (const word of getTextOfSpans(content, style.spans)) {
console.log(` - "${word}"`);
}
}
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
// sample document
const layoutUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png"
async function main() {
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocumentFromUrl(
"prebuilt-layout", layoutUrl);
// Layout extraction produces basic elements such as pages, words, lines, etc. as well as information about the
// appearance (styles) of textual elements.
const { pages, tables } = await poller.pollUntilDone();
if (!pages || pages.length <= 0) {
console.log("No pages were extracted from the document.");
} else {
console.log("Pages:");
for (const page of pages) {
console.log("- Page", page.pageNumber, `(unit: ${page.unit})`);
console.log(` ${page.width}x${page.height}, angle: ${page.angle}`);
console.log(
` ${page.lines && page.lines.length} lines, ${page.words && page.words.length} words`
);
if (page.lines && page.lines.length > 0) {
console.log(" Lines:");
for (const line of page.lines) {
console.log(` - "${line.content}"`);
// The words of the line can also be iterated independently. The words are computed based on their
// corresponding spans.
for (const word of line.words()) {
console.log(` - "${word.content}"`);
}
}
}
}
}
if (!tables || tables.length <= 0) {
console.log("No tables were extracted from the document.");
} else {
console.log("Tables:");
for (const table of tables) {
console.log(
`- Extracted table: ${table.columnCount} columns, ${table.rowCount} rows (${table.cells.length} cells)`
);
}
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
一般的なドキュメント モデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
// sample document
const documentUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-layout.pdf"
async function main() {
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocumentFromUrl("prebuilt-document", documentUrl);
const {
keyValuePairs
} = await poller.pollUntilDone();
if (!keyValuePairs || keyValuePairs.length <= 0) {
console.log("No key-value pairs were extracted from the document.");
} else {
console.log("Key-Value Pairs:");
for (const {
key,
value,
confidence
} of keyValuePairs) {
console.log("- Key :", `"${key.content}"`);
console.log(" Value:", `"${(value && value.content) || "<undefined>"}" (${confidence})`);
}
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
一般的なドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
W-2 税モデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
const w2DocumentURL = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png"
async function main() {
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-tax.us.w2", w2DocumentURL);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
const { Employee, Employer, ControlNumber, TaxYear, AdditionalInfo } = result.fields;
if (Employee) {
const { Name, Address, SocialSecurityNumber } = Employee.properties;
console.log("Employee:");
console.log(" Name:", Name && Name.content);
console.log(" SSN/TIN:", SocialSecurityNumber && SocialSecurityNumber.content);
if (Address && Address.value) {
const { streetAddress, postalCode } = Address.value;
console.log(" Address:");
console.log(" Street Address:", streetAddress);
console.log(" Postal Code:", postalCode);
}
} else {
console.log("No employee information extracted.");
}
if (Employer) {
const { Name, Address, IdNumber } = Employer.properties;
console.log("Employer:");
console.log(" Name:", Name && Name.content);
console.log(" ID (EIN):", IdNumber && IdNumber.content);
if (Address && Address.value) {
const { streetAddress, postalCode } = Address.value;
console.log(" Address:");
console.log(" Street Address:", streetAddress);
console.log(" Postal Code:", postalCode);
}
} else {
console.log("No employer information extracted.");
}
console.log("Control Number:", ControlNumber && ControlNumber.content);
console.log("Tax Year:", TaxYear && TaxYear.content);
if (AdditionalInfo) {
console.log("Additional Info:");
for (const info of AdditionalInfo.values) {
const { LetterCode, Amount } = info.properties;
console.log(`- ${LetterCode && LetterCode.content}: ${Amount && Amount.content}`);
}
}
} else {
throw new Error("Expected at least one document in the result.");
}
}
main().catch((error) => {
console.error(error);
process.exit(1);
});
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
// sample url
const invoiceUrl = "https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf";
async function main() {
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-invoice", invoiceUrl);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
const invoice = result.fields;
console.log("Vendor Name:", invoice.VendorName?.content);
console.log("Customer Name:", invoice.CustomerName?.content);
console.log("Invoice Date:", invoice.InvoiceDate?.content);
console.log("Due Date:", invoice.DueDate?.content);
console.log("Items:");
for (const {
properties: item
} of invoice.Items?.values ?? []) {
console.log("-", item.ProductCode?.content ?? "<no product code>");
console.log(" Description:", item.Description?.content);
console.log(" Quantity:", item.Quantity?.content);
console.log(" Date:", item.Date?.content);
console.log(" Unit:", item.Unit?.content);
console.log(" Unit Price:", item.UnitPrice?.content);
console.log(" Tax:", item.Tax?.content);
console.log(" Amount:", item.Amount?.content);
}
console.log("Subtotal:", invoice.SubTotal?.content);
console.log("Previous Unpaid Balance:", invoice.PreviousUnpaidBalance?.content);
console.log("Tax:", invoice.TotalTax?.content);
console.log("Amount Due:", invoice.AmountDue?.content);
} else {
throw new Error("Expected at least one receipt in the result.");
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レシート モデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
// sample url
const receiptUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png";
async function main() {
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-receipt", receiptUrl);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
const {
MerchantName,
Items,
Total
} = result.fields;
console.log("=== Receipt Information ===");
console.log("Type:", result.docType);
console.log("Merchant:", MerchantName && MerchantName.content);
console.log("Items:");
for (const item of (Items && Items.values) || []) {
const {
Description,
TotalPrice
} = item.properties;
console.log("- Description:", Description && Description.content);
console.log(" Total Price:", TotalPrice && TotalPrice.content);
}
console.log("Total:", Total && Total.content);
} else {
throw new Error("Expected at least one receipt in the result.");
}
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
// sample document
const idDocumentURL = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png"
async function main() {
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-idDocument", idDocumentURL);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
// The identity document model has multiple document types, so we need to know which document type was actually
extracted.
if (result.docType === "idDocument.driverLicense") {
const { FirstName, LastName, DocumentNumber, DateOfBirth, DateOfExpiration, Height, Weight, EyeColor, Endorsements, Restrictions, VehicleClassifications} = result.fields;
// For the sake of the example, we'll only show a few of the fields that are produced.
console.log("Extracted a Driver License:");
console.log(" Name:", FirstName && FirstName.content, LastName && LastName.content);
console.log(" License No.:", DocumentNumber && DocumentNumber.content);
console.log(" Date of Birth:", DateOfBirth && DateOfBirth.content);
console.log(" Expiration:", DateOfExpiration && DateOfExpiration.content);
console.log(" Height:", Height && Height.content);
console.log(" Weight:", Weight && Weight.content);
console.log(" Eye color:", EyeColor && EyeColor.content);
console.log(" Restrictions:", Restrictions && Restrictions.content);
console.log(" Endorsements:", Endorsements && Endorsements.content);
console.log(" Class:", VehicleClassifications && VehicleClassifications.content);
} else if (result.docType === "idDocument.passport") {
// The passport document type extracts and parses the Passport's machine-readable zone
if (!result.fields.machineReadableZone) {
throw new Error("No Machine Readable Zone extracted from passport.");
}
const {
FirstName,
LastName,
DateOfBirth,
Nationality,
DocumentNumber,
CountryRegion,
DateOfExpiration,
} = result.fields.machineReadableZone.properties;
console.log("Extracted a Passport:");
console.log(" Name:", FirstName && FirstName.content, LastName && LastName.content);
console.log(" Date of Birth:", DateOfBirth && DateOfBirth.content);
console.log(" Nationality:", Nationality && natiNationalityonality.content);
console.log(" Passport No.:", DocumentNumber && DocumentNumber.content);
console.log(" Issuer:", CountryRegion && CountryRegion.content);
console.log(" Expiration Date:", DateOfExpiration && DateOfExpiration.content);
} else {
// The only reason this would happen is if the client library's schema for the prebuilt identity document model is
out of date, and a new document type has been introduced.
console.error("Unknown document type in result:", result);
}
} else {
throw new Error("Expected at least one receipt in the result.");
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
名刺モデルを使用する
const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer");
//use your `key` and `endpoint` environment variables
const key = process.env['FR_KEY'];
const endpoint = process.env['FR_ENDPOINT'];
// sample document
const businessCardURL = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/de5e0d8982ab754823c54de47a47e8e499351523/curl/form-recognizer/rest-api/business_card.jpg"
async function main() {
const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key));
const poller = await client.beginAnalyzeDocument("prebuilt-businessCard", businessCardURL);
const {
documents: [result]
} = await poller.pollUntilDone();
if (result) {
const businessCard = result.fields;
console.log("=== Business Card Information ===");
// There are more fields than just these few, and the model allows for multiple contact & company names as well as
// phone numbers, though we'll only show the first extracted values here.
const name = businessCard.ContactNames && businessCard.ContactNames.values[0];
if (name) {
const {
FirstName,
LastName
} = name.properties;
console.log("Name:", FirstName && FirstName.content, LastName && LastName.content);
}
const company = businessCard.CompanyNames && businessCard.CompanyNames.values[0];
if (company) {
console.log("Company:", company.content);
}
const address = businessCard.Addresses && businessCard.Addresses.values[0];
if (address) {
console.log("Address:", address.content);
}
const jobTitle = businessCard.JobTitles && businessCard.JobTitles.values[0];
if (jobTitle) {
console.log("Job title:", jobTitle.content);
}
const department = businessCard.Departments && businessCard.Departments.values[0];
if (department) {
console.log("Department:", department.content);
}
const email = businessCard.Emails && businessCard.Emails.values[0];
if (email) {
console.log("Email:", email.content);
}
const workPhone = businessCard.WorkPhones && businessCard.WorkPhones.values[0];
if (workPhone) {
console.log("Work phone:", workPhone.content);
}
const website = businessCard.Websites && businessCard.Websites.values[0];
if (website) {
console.log("Website:", website.content);
}
} else {
throw new Error("Expected at least one business card in the result.");
}
}
main().catch((error) => {
console.error("An error occurred:", error);
process.exit(1);
});
名刺モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
クライアント ライブラリ |SDK リファレンス | REST API リファレンス | パッケージ (PyPi) | サンプル | サポートされている REST API バージョン
前提条件
Azure サブスクリプション。無料で作成できます。
Python 3.7、またはそれ以降。 Python のインストールには、pip が含まれている必要があります。 pip がインストールされているかどうかを確認するには、コマンド ラインで
pip --versionを実行します。 最新バージョンの Python をインストールして pip を入手してください。Visual Studio Code または好みの IDE の最新バージョン。 「Visual Studio Code での Python の概要」を参照してください。
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定されたドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
ローカル環境でコンソール ウィンドウを開き、次のように pip を使用して Python 用の Azure AI Document Intelligence クライアント ライブラリをインストールします。
pip install azure-ai-documentintelligence==1.0.0b4
Python アプリケーションを作成する
Document Intelligence サービスとやり取りするには、DocumentIntelligenceClient クラスのインスタンスを作成する必要があります。 これを行うために、Azure portal のキーを使用して AzureKeyCredential を作成し、その AzureKeyCredential と Document Intelligence のエンドポイントを使用して DocumentIntelligenceClient インスタンスを作成します。
エディターまたは IDE で、form_recognizer_quickstart.py という名前の新しい Python ファイルを作成します。
form_recognizer_quickstart.py ファイルを開き、次のコード サンプルのいずれかを選択してコピーし、アプリケーションに貼り付けます。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
readモデルが使用されます。 - 事前構築済みレイアウト モデルは、ドキュメントと画像からテキストとテキストの場所、テーブル、選択マーク、構造体情報を抽出します。
- 事前構築済み tax.us.w2 モデルは、米国内国歳入庁 (IRS) の税フォームで報告された情報を抽出します。
- 事前構築済み請求書モデルは、さまざまな形式の売上請求書から主なフィールドと品目を抽出します。
- 事前構築済み領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
- 事前構築済み idDocument モデルは、米国の運転免許証、国際パスポートの略歴ページ、米国の州の ID、社会保障カード、永住者カードから重要な情報を抽出します。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
コマンド プロンプトから Python コードを実行します。
python form_recognizer_quickstart.py
読み取りモデルを使用する
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
# use your `key` and `endpoint` environment variables
key = os.environ.get('DI_KEY')
endpoint = os.environ.get('DI_ENDPOINT')
# helper functions
def get_words(page, line):
result = []
for word in page.words:
if _in_span(word, line.spans):
result.append(word)
return result
def _in_span(word, spans):
for span in spans:
if word.span.offset >= span.offset and (word.span.offset + word.span.length) <= (span.offset + span.length):
return True
return False
def analyze_read():
# sample document
formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png"
client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = client.begin_analyze_document(
"prebuilt-read", AnalyzeDocumentRequest(url_source=formUrl
))
result: AnalyzeResult = poller.result()
print("----Languages detected in the document----")
if result.languages is not None:
for language in result.languages:
print(f"Language code: '{language.locale}' with confidence {language.confidence}")
print("----Styles detected in the document----")
if result.styles:
for style in result.styles:
if style.is_handwritten:
print("Found the following handwritten content: ")
print(",".join([result.content[span.offset : span.offset + span.length] for span in style.spans]))
if style.font_style:
print(f"The document contains '{style.font_style}' font style, applied to the following text: ")
print(",".join([result.content[span.offset : span.offset + span.length] for span in style.spans]))
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"...Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.paragraphs:
print(f"----Detected #{len(result.paragraphs)} paragraphs in the document----")
for paragraph in result.paragraphs:
print(f"Found paragraph with role: '{paragraph.role}' within {paragraph.bounding_regions} bounding region")
print(f"...with content: '{paragraph.content}'")
result.paragraphs.sort(key=lambda p: (p.spans.sort(key=lambda s: s.offset), p.spans[0].offset))
print("-----Print sorted paragraphs-----")
for idx, paragraph in enumerate(result.paragraphs):
print(
f"...paragraph:{idx} with offset: {paragraph.spans[0].offset} and length: {paragraph.spans[0].length}"
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_read()
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
# use your `key` and `endpoint` environment variables
key = os.environ.get('DI_KEY')
endpoint = os.environ.get('DI_ENDPOINT')
def analyze_layout():
# sample document
formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png"
client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = client.begin_analyze_document(
"prebuilt-layout", AnalyzeDocumentRequest(url_source=formUrl
))
result: AnalyzeResult = poller.result()
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
print("----------------------------------------")
if __name__ == "__main__":
analyze_layout()
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
W-2 税モデルを使用する
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
# use your `key` and `endpoint` environment variables
key = os.environ.get('DI_KEY')
endpoint = os.environ.get('DI_ENDPOINT')
# formatting function
def format_address_value(address_value):
return f"\n......House/building number: {address_value.house_number}\n......Road: {address_value.road}\n......City: {address_value.city}\n......State: {address_value.state}\n......Postal code: {address_value.postal_code}"
def analyze_tax_us_w2():
# sample document
formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png"
client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = client.begin_analyze_document(
"prebuilt-tax.us.w2", AnalyzeDocumentRequest(url_source=formUrl
))
w2s: AnalyzeResult = poller.result()
if w2s.documents:
for idx, w2 in enumerate(w2s.documents):
print(f"--------Analyzing US Tax W-2 Form #{idx + 1}--------")
if w2.fields:
form_variant = w2.fields.get("W2FormVariant")
if form_variant:
print(
f"Form variant: {form_variant.get('valueString')} has confidence: " f"{form_variant.confidence}"
)
tax_year = w2.fields.get("TaxYear")
if tax_year:
print(f"Tax year: {tax_year.get('valueString')} has confidence: {tax_year.confidence}")
w2_copy = w2.fields.get("W2Copy")
if w2_copy:
print(f"W-2 Copy: {w2_copy.get('valueString')} has confidence: {w2_copy.confidence}")
employee = w2.fields.get("Employee")
if employee:
print("Employee data:")
employee_name = employee.get("valueObject").get("Name")
if employee_name:
f"confidence: {fed_income_tax_withheld.confidence}"
)
social_security_wages = w2.fields.get("SocialSecurityWages")
if social_security_wages:
print(
f"Social Security wages: {social_security_wages.get('valueNumber')} has confidence: "
f"{social_security_wages.confidence}"
)
social_security_tax_withheld = w2.fields.get("SocialSecurityTaxWithheld")
if social_security_tax_withheld:
print(
f"Social Security tax withheld: {social_security_tax_withheld.get('valueNumber')} "
f"has confidence: {social_security_tax_withheld.confidence}"
)
medicare_wages_tips = w2.fields.get("MedicareWagesAndTips")
if medicare_wages_tips:
print(
f"Medicare wages and tips: {medicare_wages_tips.get('valueNumber')} has confidence: "
f"{medicare_wages_tips.confidence}"
)
medicare_tax_withheld = w2.fields.get("MedicareTaxWithheld")
if medicare_tax_withheld:
print(
f"Medicare tax withheld: {medicare_tax_withheld.get('valueNumber')} has confidence: "
f"{medicare_tax_withheld.confidence}"
)
social_security_tips = w2.fields.get("SocialSecurityTips")
if social_security_tips:
print(
f"Social Security tips: {social_security_tips.get('valueNumber')} has confidence: "
f"{social_security_tips.confidence}"
)
allocated_tips = w2.fields.get("AllocatedTips")
if allocated_tips:
print(
f"Allocated tips: {allocated_tips.get('valueNumber')} has confidence: {allocated_tips.confidence}"
)
verification_code = w2.fields.get("VerificationCode")
if verification_code:
print(
f"Verification code: {verification_code.get('valueNumber')} has confidence: {verification_code.confidence}"
)
dependent_care_benefits = w2.fields.get("DependentCareBenefits")
if dependent_care_benefits:
print(
f"Dependent care benefits: {dependent_care_benefits.get('valueNumber')} has confidence: {dependent_care_benefits.confidence}"
)
non_qualified_plans = w2.fields.get("NonQualifiedPlans")
if non_qualified_plans:
print(
f"Non-qualified plans: {non_qualified_plans.get('valueNumber')} has confidence: {non_qualified_plans.confidence}"
)
additional_info = w2.fields.get("AdditionalInfo")
if additional_info:
print("Additional information:")
for item in additional_info.get("valueArray"):
letter_code = item.get("valueObject").get("LetterCode")
if letter_code:
print(
f"...Letter code: {letter_code.get('valueString')} has confidence: {letter_code.confidence}"
)
amount = item.get("valueObject").get("Amount")
if amount:
print(f"...Amount: {amount.get('valueNumber')} has confidence: {amount.confidence}")
is_statutory_employee = w2.fields.get("IsStatutoryEmployee")
if is_statutory_employee:
print(
f"Is statutory employee: {is_statutory_employee.get('valueString')} has confidence: {is_statutory_employee.confidence}"
)
is_retirement_plan = w2.fields.get("IsRetirementPlan")
if is_retirement_plan:
print(
f"Is retirement plan: {is_retirement_plan.get('valueString')} has confidence: {is_retirement_plan.confidence}"
)
third_party_sick_pay = w2.fields.get("IsThirdPartySickPay")
if third_party_sick_pay:
print(
f"Is third party sick pay: {third_party_sick_pay.get('valueString')} has confidence: {third_party_sick_pay.confidence}"
)
other_info = w2.fields.get("Other")
if other_info:
print(f"Other information: {other_info.get('valueString')} has confidence: {other_info.confidence}")
state_tax_info = w2.fields.get("StateTaxInfos")
if state_tax_info:
print("State Tax info:")
for tax in state_tax_info.get("valueArray"):
state = tax.get("valueObject").get("State")
if state:
print(f"...State: {state.get('valueString')} has confidence: {state.confidence}")
employer_state_id_number = tax.get("valueObject").get("EmployerStateIdNumber")
if employer_state_id_number:
print(
f"...Employer state ID number: {employer_state_id_number.get('valueString')} has "
f"confidence: {employer_state_id_number.confidence}"
)
state_wages_tips = tax.get("valueObject").get("StateWagesTipsEtc")
if state_wages_tips:
print(
f"...State wages, tips, etc: {state_wages_tips.get('valueNumber')} has confidence: "
f"{state_wages_tips.confidence}"
)
state_income_tax = tax.get("valueObject").get("StateIncomeTax")
if state_income_tax:
print(
f"...State income tax: {state_income_tax.get('valueNumber')} has confidence: "
f"{state_income_tax.confidence}"
)
local_tax_info = w2.fields.get("LocalTaxInfos")
if local_tax_info:
print("Local Tax info:")
for tax in local_tax_info.get("valueArray"):
local_wages_tips = tax.get("valueObject").get("LocalWagesTipsEtc")
if local_wages_tips:
print(
f"...Local wages, tips, etc: {local_wages_tips.get('valueNumber')} has confidence: "
f"{local_wages_tips.confidence}"
)
local_income_tax = tax.get("valueObject").get("LocalIncomeTax")
if local_income_tax:
print(
f"...Local income tax: {local_income_tax.get('valueNumber')} has confidence: "
f"{local_income_tax.confidence}"
)
locality_name = tax.get("valueObject").get("LocalityName")
if locality_name:
print(
f"...Locality name: {locality_name.get('valueString')} has confidence: "
f"{locality_name.confidence}"
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_tax_us_w2()
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
# use your `key` and `endpoint` environment variables
key = os.environ.get('DI_KEY')
endpoint = os.environ.get('DI_ENDPOINT')
def analyze_invoice():
invoiceUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-invoice.pdf"
client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = client.begin_analyze_document(
"prebuilt-invoice", AnalyzeDocumentRequest(url_source=formUrl), locale="en-US")
result: AnalyzeResult = poller.result()
if invoices.documents:
for idx, invoice in enumerate(invoices.documents):
print(f"--------Analyzing invoice #{idx + 1}--------")
if invoice.fields:
vendor_name = invoice.fields.get("VendorName")
if vendor_name:
print(f"Vendor Name: {vendor_name.get('content')} has confidence: {vendor_name.get('confidence')}")
vendor_address = invoice.fields.get("VendorAddress")
if vendor_address:
print(
f"Vendor Address: {vendor_address.get('content')} has confidence: {vendor_address.get('confidence')}"
)
vendor_address_recipient = invoice.fields.get("VendorAddressRecipient")
if vendor_address_recipient:
print(
f"Vendor Address Recipient: {vendor_address_recipient.get('content')} has confidence: {vendor_address_recipient.get('confidence')}"
)
customer_name = invoice.fields.get("CustomerName")
if customer_name:
print(
f"Customer Name: {customer_name.get('content')} has confidence: {customer_name.get('confidence')}"
)
customer_id = invoice.fields.get("CustomerId")
if invoice_id:
print(f"Invoice Id: {invoice_id.get('content')} has confidence: {invoice_id.get('confidence')}")
invoice_date = invoice.fields.get("InvoiceDate")
if invoice_date:
print(
f"Invoice Date: {invoice_date.get('content')} has confidence: {invoice_date.get('confidence')}"
)
invoice_total = invoice.fields.get("InvoiceTotal")
if invoice_total:
print(
f"Invoice Total: {invoice_total.get('content')} has confidence: {invoice_total.get('confidence')}"
)
due_date = invoice.fields.get("DueDate")
if due_date:
print(f"Due Date: {due_date.get('content')} has confidence: {due_date.get('confidence')}")
purchase_order = invoice.fields.get("PurchaseOrder")
if purchase_order:
print(
f"Purchase Order: {purchase_order.get('content')} has confidence: {purchase_order.get('confidence')}"
)
billing_address = invoice.fields.get("BillingAddress")
if billing_address:
print(
f"Billing Address: {billing_address.get('content')} has confidence: {billing_address.get('confidence')}"
)
billing_address_recipient = invoice.fields.get("BillingAddressRecipient")
if billing_address_recipient:
print(
f"Billing Address Recipient: {billing_address_recipient.get('content')} has confidence: {billing_address_recipient.get('confidence')}"
)
shipping_address = invoice.fields.get("ShippingAddress")
if shipping_address:
print(
f"Shipping Address: {shipping_address.get('content')} has confidence: {shipping_address.get('confidence')}"
)
shipping_address_recipient = invoice.fields.get("ShippingAddressRecipient")
if shipping_address_recipient:
print(
f"Shipping Address Recipient: {shipping_address_recipient.get('content')} has confidence: {shipping_address_recipient.get('confidence')}"
)
print("Invoice items:")
items = invoice.fields.get("Items")
if items:
for idx, item in enumerate(items.get("valueArray")):
print(f"...Item #{idx + 1}")
item_description = item.get("valueObject").get("Description")
if item_description:
print(
f"......Description: {item_description.get('content')} has confidence: {item_description.get('confidence')}"
)
item_quantity = item.get("valueObject").get("Quantity")
if item_quantity:
print(
f"......Quantity: {item_quantity.get('content')} has confidence: {item_quantity.get('confidence')}"
)
unit = item.get("valueObject").get("Unit")
if unit:
print(f"......Unit: {unit.get('content')} has confidence: {unit.get('confidence')}")
unit_price = item.get("valueObject").get("UnitPrice")
if unit_price:
unit_price_code = (
unit_price.get("valueCurrency").get("currencyCode")
if unit_price.get("valueCurrency").get("currencyCode")
else ""
)
print(
f"......Unit Price: {unit_price.get('content')}{unit_price_code} has confidence: {unit_price.get('confidence')}"
)
product_code = item.get("valueObject").get("ProductCode")
if product_code:
print(
f"......Product Code: {product_code.get('content')} has confidence: {product_code.get('confidence')}"
)
item_date = item.get("valueObject").get("Date")
if item_date:
print(
f"......Date: {item_date.get('content')} has confidence: {item_date.get('confidence')}"
)
tax = item.get("valueObject").get("Tax")
if tax:
print(f"......Tax: {tax.get('content')} has confidence: {tax.get('confidence')}")
amount = item.get("valueObject").get("Amount")
if amount:
print(f"......Amount: {amount.get('content')} has confidence: {amount.get('confidence')}")
subtotal = invoice.fields.get("SubTotal")
if subtotal:
print(f"Subtotal: {subtotal.get('content')} has confidence: {subtotal.get('confidence')}")
total_tax = invoice.fields.get("TotalTax")
if total_tax:
print(f"Total Tax: {total_tax.get('content')} has confidence: {total_tax.get('confidence')}")
previous_unpaid_balance = invoice.fields.get("PreviousUnpaidBalance")
if previous_unpaid_balance:
print(
f"Previous Unpaid Balance: {previous_unpaid_balance.get('content')} has confidence: {previous_unpaid_balance.get('confidence')}"
)
amount_due = invoice.fields.get("AmountDue")
if amount_due:
print(f"Amount Due: {amount_due.get('content')} has confidence: {amount_due.get('confidence')}")
service_start_date = invoice.fields.get("ServiceStartDate")
if service_start_date:
print(
f"Service Start Date: {service_start_date.get('content')} has confidence: {service_start_date.get('confidence')}"
)
service_end_date = invoice.fields.get("ServiceEndDate")
if service_end_date:
print(
f"Service End Date: {service_end_date.get('content')} has confidence: {service_end_date.get('confidence')}"
)
service_address = invoice.fields.get("ServiceAddress")
if service_address:
print(
f"Service Address: {service_address.get('content')} has confidence: {service_address.get('confidence')}"
)
service_address_recipient = invoice.fields.get("ServiceAddressRecipient")
if service_address_recipient:
print(
f"Service Address Recipient: {service_address_recipient.get('content')} has confidence: {service_address_recipient.get('confidence')}"
)
remittance_address = invoice.fields.get("RemittanceAddress")
if remittance_address:
print(
f"Remittance Address: {remittance_address.get('content')} has confidence: {remittance_address.get('confidence')}"
)
remittance_address_recipient = invoice.fields.get("RemittanceAddressRecipient")
if remittance_address_recipient:
print(
f"Remittance Address Recipient: {remittance_address_recipient.get('content')} has confidence: {remittance_address_recipient.get('confidence')}"
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_invoice()
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レシート モデルを使用する
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
# use your `key` and `endpoint` environment variables
key = os.environ.get('DI_KEY')
endpoint = os.environ.get('DI_ENDPOINT')
def analyze_receipts():
# sample document
receiptUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png"
client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = client.begin_analyze_document(
"prebuilt-receipt", AnalyzeDocumentRequest(url_source=receiptUrl), locale="en-US"
)
receipts: AnalyzeResult = poller.result()
if receipts.documents:
for idx, receipt in enumerate(receipts.documents):
print(f"--------Analysis of receipt #{idx + 1}--------")
print(f"Receipt type: {receipt.doc_type if receipt.doc_type else 'N/A'}")
if receipt.fields:
merchant_name = receipt.fields.get("MerchantName")
if merchant_name:
print(
f"Merchant Name: {merchant_name.get('valueString')} has confidence: "
f"{merchant_name.confidence}"
)
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
print(
f"Transaction Date: {transaction_date.get('valueDate')} has confidence: "
f"{transaction_date.confidence}"
)
items = receipt.fields.get("Items")
if items:
print("Receipt items:")
for idx, item in enumerate(items.get("valueArray")):
print(f"...Item #{idx + 1}")
item_description = item.get("valueObject").get("Description")
if item_description:
print(
f"......Item Description: {item_description.get('valueString')} has confidence: "
f"{item_description.confidence}"
)
item_quantity = item.get("valueObject").get("Quantity")
if item_quantity:
print(
f"......Item Quantity: {item_quantity.get('valueString')} has confidence: "
f"{item_quantity.confidence}"
)
item_total_price = item.get("valueObject").get("TotalPrice")
if item_total_price:
print(
f"......Total Item Price: {format_price(item_total_price.get('valueCurrency'))} has confidence: "
f"{item_total_price.confidence}"
)
subtotal = receipt.fields.get("Subtotal")
if subtotal:
print(
f"Subtotal: {format_price(subtotal.get('valueCurrency'))} has confidence: {subtotal.confidence}"
)
tax = receipt.fields.get("TotalTax")
if tax:
print(f"Total tax: {format_price(tax.get('valueCurrency'))} has confidence: {tax.confidence}")
tip = receipt.fields.get("Tip")
if tip:
print(f"Tip: {format_price(tip.get('valueCurrency'))} has confidence: {tip.confidence}")
total = receipt.fields.get("Total")
if total:
print(f"Total: {format_price(total.get('valueCurrency'))} has confidence: {total.confidence}")
print("--------------------------------------")
if __name__ == "__main__":
analyze_receipts()
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデルを使用する
import os
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
# use your `key` and `endpoint` environment variables
key = os.environ.get('DI_KEY')
endpoint = os.environ.get('DI_ENDPOINT')
def analyze_identity_documents():
# sample document
identityUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png"
client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller =client.begin_analyze_document(
"prebuilt-idDocument", AnalyzeDocumentRequest(url_source=identityUrl)
)
id_documents: AnalyzeResult = poller.result()
if id_documents.documents:
for idx, id_document in enumerate(id_documents.documents):
print(f"--------Analyzing ID document #{idx + 1}--------")
if id_document.fields:
first_name = id_document.fields.get("FirstName")
if first_name:
print(f"First Name: {first_name.get('valueString')} has confidence: {first_name.confidence}")
last_name = id_document.fields.get("LastName")
if last_name:
print(f"Last Name: {last_name.get('valueString')} has confidence: {last_name.confidence}")
document_number = id_document.fields.get("DocumentNumber")
if document_number:
print(
f"Document Number: {document_number.get('valueString')} has confidence: {document_number.confidence}"
)
dob = id_document.fields.get("DateOfBirth")
if dob:
print(f"Date of Birth: {dob.get('valueDate')} has confidence: {dob.confidence}")
doe = id_document.fields.get("DateOfExpiration")
if doe:
print(f"Date of Expiration: {doe.get('valueDate')} has confidence: {doe.confidence}")
sex = id_document.fields.get("Sex")
if sex:
print(f"Sex: {sex.get('valueString')} has confidence: {sex.confidence}")
address = id_document.fields.get("Address")
if address:
print(f"Address: {address.get('valueString')} has confidence: {address.confidence}")
country_region = id_document.fields.get("CountryRegion")
if country_region:
print(
f"Country/Region: {country_region.get('valueCountryRegion')} has confidence: {country_region.confidence}"
)
region = id_document.fields.get("Region")
if region:
print(f"Region: {region.get('valueString')} has confidence: {region.confidence}")
print("--------------------------------------")
if __name__ == "__main__":
analyze_identity_documents()
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
前提条件
Azure サブスクリプション。無料で作成できます。
Python 3.7、またはそれ以降。 Python のインストールには、pip が含まれている必要があります。 pip がインストールされているかどうかを確認するには、コマンド ラインで
pip --versionを実行します。 最新バージョンの Python をインストールして pip を入手してください。Visual Studio Code または好みの IDE の最新バージョン。 「Visual Studio Code での Python の概要」を参照してください。
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
URL で指定されたドキュメント ファイル。 このプロジェクトでは、各機能について、次の表に示すサンプル フォームを使用できます。
機能 modelID document-url 読み取りモデル prebuilt-read サンプル パンフレット レイアウト モデル 事前構築済みレイアウト 予約確認のサンプル W-2 フォーム モデル prebuilt-tax.us.w2 サンプル W-2 フォーム 請求書モデル prebuilt-invoice サンプル請求書 レシート モデル prebuilt-receipt サンプル レシート 身分証明書モデル prebuilt-idDocument サンプル身分証明書 名刺モデル 事前構築された名刺 サンプル名刺
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
プログラミング環境のセットアップ
ローカル環境でコンソール ウィンドウを開き、次のように pip を使用して Python 用の Azure AI Document Intelligence クライアント ライブラリをインストールします。
pip install azure-ai-formrecognizer==3.2.0
Python アプリケーションを作成する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うために、Azure portal のキーを使用して AzureKeyCredential を作成し、その AzureKeyCredential と Document Intelligence のエンドポイントを使用して DocumentAnalysisClient インスタンスを作成します。
エディターまたは IDE で、form_recognizer_quickstart.py という名前の新しい Python ファイルを作成します。
form_recognizer_quickstart.py ファイルを開き、次のコード サンプルのいずれかを選択してコピーし、アプリケーションに貼り付けます。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
readモデルが使用されます。 - 事前構築済みレイアウト モデルは、ドキュメントと画像からテキストとテキストの場所、テーブル、選択マーク、構造体情報を抽出します。
- 事前構築済み tax.us.w2 モデルは、米国内国歳入庁 (IRS) の税フォームで報告された情報を抽出します。
- 事前構築済み請求書モデルは、さまざまな形式の売上請求書から主なフィールドと品目を抽出します。
- 事前構築済み領収書モデルでは、印刷された領収書と手書きのレシートから重要な情報を分析して抽出します。
- 事前構築済み idDocument モデルは、米国の運転免許証、国際パスポートの略歴ページ、米国の州の ID、社会保障カード、永住者カードから重要な情報を抽出します。
- 事前構築済みの読み取り モデルは、すべての ドキュメントインテリジェンス モデルの中核であり、行、単語、場所、言語を検出できます。 レイアウト、一般的なドキュメント、事前構築済み、カスタムの各モデルでは、ドキュメントからテキストを抽出するための基盤として
コマンド プロンプトから Python コードを実行します。
python form_recognizer_quickstart.py
読み取りモデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
# formatting function
def format_polygon(polygon):
if not polygon:
return "N/A"
return ", ".join(["[{}, {}]".format(p.x, p.y) for p in polygon])
def analyze_read():
# sample document
formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-read", formUrl
)
result = poller.result()
print("Document contains content: ", result.content)
for idx, style in enumerate(result.styles):
print(
"Document contains {} content".format(
"handwritten" if style.is_handwritten else "no handwritten"
)
)
for page in result.pages:
print("----Analyzing Read from page #{}----".format(page.page_number))
print(
"Page has width: {} and height: {}, measured with unit: {}".format(
page.width, page.height, page.unit
)
)
for line_idx, line in enumerate(page.lines):
print(
"...Line # {} has text content '{}' within bounding box '{}'".format(
line_idx,
line.content,
format_polygon(line.polygon),
)
)
for word in page.words:
print(
"...Word '{}' has a confidence of {}".format(
word.content, word.confidence
)
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_read()
read読み取りモデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レイアウト モデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
# formatting function
def format_polygon(polygon):
if not polygon:
return "N/A"
return ", ".join(["[{}, {}]".format(p.x, p.y) for p in polygon])
def analyze_layout():
# sample document
formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", formUrl
)
result = poller.result()
for idx, style in enumerate(result.styles):
print(
"Document contains {} content".format(
"handwritten" if style.is_handwritten else "no handwritten"
)
)
for page in result.pages:
print("----Analyzing layout from page #{}----".format(page.page_number))
print(
"Page has width: {} and height: {}, measured with unit: {}".format(
page.width, page.height, page.unit
)
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
"...Line # {} has word count {} and text '{}' within bounding box '{}'".format(
line_idx,
len(words),
line.content,
format_polygon(line.polygon),
)
)
for word in words:
print(
"......Word '{}' has a confidence of {}".format(
word.content, word.confidence
)
)
for selection_mark in page.selection_marks:
print(
"...Selection mark is '{}' within bounding box '{}' and has a confidence of {}".format(
selection_mark.state,
format_polygon(selection_mark.polygon),
selection_mark.confidence,
)
)
for table_idx, table in enumerate(result.tables):
print(
"Table # {} has {} rows and {} columns".format(
table_idx, table.row_count, table.column_count
)
)
for region in table.bounding_regions:
print(
"Table # {} location on page: {} is {}".format(
table_idx,
region.page_number,
format_polygon(region.polygon),
)
)
for cell in table.cells:
print(
"...Cell[{}][{}] has content '{}'".format(
cell.row_index,
cell.column_index,
cell.content,
)
)
for region in cell.bounding_regions:
print(
"...content on page {} is within bounding box '{}'".format(
region.page_number,
format_polygon(region.polygon),
)
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_layout()
GitHub の Azure サンプル リポジトリにアクセスし、 レイアウト モデルの出力を表示します。
一般的なドキュメント モデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
# formatting function
def format_bounding_region(bounding_regions):
if not bounding_regions:
return "N/A"
return ", ".join("Page #{}: {}".format(region.page_number, format_polygon(region.polygon)) for region in bounding_regions)
# formatting function
def format_polygon(polygon):
if not polygon:
return "N/A"
return ", ".join(["[{}, {}]".format(p.x, p.y) for p in polygon])
def analyze_general_documents():
# sample document
docUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-layout.pdf"
# create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable
document_analysis_client = DocumentAnalysisClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-document", docUrl)
result = poller.result()
for style in result.styles:
if style.is_handwritten:
print("Document contains handwritten content: ")
print(",".join([result.content[span.offset:span.offset + span.length] for span in style.spans]))
print("----Key-value pairs found in document----")
for kv_pair in result.key_value_pairs:
if kv_pair.key:
print(
"Key '{}' found within '{}' bounding regions".format(
kv_pair.key.content,
format_bounding_region(kv_pair.key.bounding_regions),
)
)
if kv_pair.value:
print(
"Value '{}' found within '{}' bounding regions\n".format(
kv_pair.value.content,
format_bounding_region(kv_pair.value.bounding_regions),
)
)
for page in result.pages:
print("----Analyzing document from page #{}----".format(page.page_number))
print(
"Page has width: {} and height: {}, measured with unit: {}".format(
page.width, page.height, page.unit
)
)
for line_idx, line in enumerate(page.lines):
print(
"...Line # {} has text content '{}' within bounding box '{}'".format(
line_idx,
line.content,
format_polygon(line.polygon),
)
)
for word in page.words:
print(
"...Word '{}' has a confidence of {}".format(
word.content, word.confidence
)
)
for selection_mark in page.selection_marks:
print(
"...Selection mark is '{}' within bounding box '{}' and has a confidence of {}".format(
selection_mark.state,
format_polygon(selection_mark.polygon),
selection_mark.confidence,
)
)
for table_idx, table in enumerate(result.tables):
print(
"Table # {} has {} rows and {} columns".format(
table_idx, table.row_count, table.column_count
)
)
for region in table.bounding_regions:
print(
"Table # {} location on page: {} is {}".format(
table_idx,
region.page_number,
format_polygon(region.polygon),
)
)
for cell in table.cells:
print(
"...Cell[{}][{}] has content '{}'".format(
cell.row_index,
cell.column_index,
cell.content,
)
)
for region in cell.bounding_regions:
print(
"...content on page {} is within bounding box '{}'\n".format(
region.page_number,
format_polygon(region.polygon),
)
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_general_documents()
一般的なドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
W-2 税モデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
# formatting function
def format_address_value(address_value):
return f"\n......House/building number: {address_value.house_number}\n......Road: {address_value.road}\n......City: {address_value.city}\n......State: {address_value.state}\n......Postal code: {address_value.postal_code}"
def analyze_tax_us_w2():
# sample document
formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-tax.us.w2", formUrl
)
w2s = poller.result()
for idx, w2 in enumerate(w2s.documents):
print("--------Analyzing US Tax W-2 Form #{}--------".format(idx 1))
form_variant = w2.fields.get("W2FormVariant")
if form_variant:
print(
"Form variant: {} has confidence: {}".format(
form_variant.value, form_variant.confidence
)
)
tax_year = w2.fields.get("TaxYear")
if tax_year:
print(
"Tax year: {} has confidence: {}".format(
tax_year.value, tax_year.confidence
)
)
w2_copy = w2.fields.get("W2Copy")
if w2_copy:
print(
"W-2 Copy: {} has confidence: {}".format(
w2_copy.value,
w2_copy.confidence,
)
)
employee = w2.fields.get("Employee")
if employee:
print("Employee data:")
employee_name = employee.value.get("Name")
if employee_name:
print(
"...Name: {} has confidence: {}".format(
employee_name.value, employee_name.confidence
)
)
employee_ssn = employee.value.get("SocialSecurityNumber")
if employee_ssn:
print(
"...SSN: {} has confidence: {}".format(
employee_ssn.value, employee_ssn.confidence
)
)
employee_address = employee.value.get("Address")
if employee_address:
print(
"...Address: {}\n......has confidence: {}".format(
format_address_value(employee_address.value),
employee_address.confidence,
)
)
employee_zipcode = employee.value.get("ZipCode")
if employee_zipcode:
print(
"...Zipcode: {} has confidence: {}".format(
employee_zipcode.value, employee_zipcode.confidence
)
)
control_number = w2.fields.get("ControlNumber")
if control_number:
print(
"Control Number: {} has confidence: {}".format(
control_number.value, control_number.confidence
)
)
employer = w2.fields.get("Employer")
if employer:
print("Employer data:")
employer_name = employer.value.get("Name")
if employer_name:
print(
"...Name: {} has confidence: {}".format(
employer_name.value, employer_name.confidence
)
)
employer_id = employer.value.get("IdNumber")
if employer_id:
print(
"...ID Number: {} has confidence: {}".format(
employer_id.value, employer_id.confidence
)
)
employer_address = employer.value.get("Address")
if employer_address:
print(
"...Address: {}\n......has confidence: {}".format(
format_address_value(employer_address.value),
employer_address.confidence,
)
)
employer_zipcode = employer.value.get("ZipCode")
if employer_zipcode:
print(
"...Zipcode: {} has confidence: {}".format(
employer_zipcode.value, employer_zipcode.confidence
)
)
wages_tips = w2.fields.get("WagesTipsAndOtherCompensation")
if wages_tips:
print(
"Wages, tips, and other compensation: {} has confidence: {}".format(
wages_tips.value,
wages_tips.confidence,
)
)
fed_income_tax_withheld = w2.fields.get("FederalIncomeTaxWithheld")
if fed_income_tax_withheld:
print(
"Federal income tax withheld: {} has confidence: {}".format(
fed_income_tax_withheld.value, fed_income_tax_withheld.confidence
)
)
social_security_wages = w2.fields.get("SocialSecurityWages")
if social_security_wages:
print(
"Social Security wages: {} has confidence: {}".format(
social_security_wages.value, social_security_wages.confidence
)
)
social_security_tax_withheld = w2.fields.get("SocialSecurityTaxWithheld")
if social_security_tax_withheld:
print(
"Social Security tax withheld: {} has confidence: {}".format(
social_security_tax_withheld.value,
social_security_tax_withheld.confidence,
)
)
medicare_wages_tips = w2.fields.get("MedicareWagesAndTips")
if medicare_wages_tips:
print(
"Medicare wages and tips: {} has confidence: {}".format(
medicare_wages_tips.value, medicare_wages_tips.confidence
)
)
medicare_tax_withheld = w2.fields.get("MedicareTaxWithheld")
if medicare_tax_withheld:
print(
"Medicare tax withheld: {} has confidence: {}".format(
medicare_tax_withheld.value, medicare_tax_withheld.confidence
)
)
social_security_tips = w2.fields.get("SocialSecurityTips")
if social_security_tips:
print(
"Social Security tips: {} has confidence: {}".format(
social_security_tips.value, social_security_tips.confidence
)
)
allocated_tips = w2.fields.get("AllocatedTips")
if allocated_tips:
print(
"Allocated tips: {} has confidence: {}".format(
allocated_tips.value,
allocated_tips.confidence,
)
)
verification_code = w2.fields.get("VerificationCode")
if verification_code:
print(
"Verification code: {} has confidence: {}".format(
verification_code.value, verification_code.confidence
)
)
dependent_care_benefits = w2.fields.get("DependentCareBenefits")
if dependent_care_benefits:
print(
"Dependent care benefits: {} has confidence: {}".format(
dependent_care_benefits.value,
dependent_care_benefits.confidence,
)
)
non_qualified_plans = w2.fields.get("NonQualifiedPlans")
if non_qualified_plans:
print(
"Non-qualified plans: {} has confidence: {}".format(
non_qualified_plans.value,
non_qualified_plans.confidence,
)
)
additional_info = w2.fields.get("AdditionalInfo")
if additional_info:
print("Additional information:")
for item in additional_info.value:
letter_code = item.value.get("LetterCode")
if letter_code:
print(
"...Letter code: {} has confidence: {}".format(
letter_code.value, letter_code.confidence
)
)
amount = item.value.get("Amount")
if amount:
print(
"...Amount: {} has confidence: {}".format(
amount.value, amount.confidence
)
)
is_statutory_employee = w2.fields.get("IsStatutoryEmployee")
if is_statutory_employee:
print(
"Is statutory employee: {} has confidence: {}".format(
is_statutory_employee.value, is_statutory_employee.confidence
)
)
is_retirement_plan = w2.fields.get("IsRetirementPlan")
if is_retirement_plan:
print(
"Is retirement plan: {} has confidence: {}".format(
is_retirement_plan.value, is_retirement_plan.confidence
)
)
third_party_sick_pay = w2.fields.get("IsThirdPartySickPay")
if third_party_sick_pay:
print(
"Is third party sick pay: {} has confidence: {}".format(
third_party_sick_pay.value, third_party_sick_pay.confidence
)
)
other_info = w2.fields.get("Other")
if other_info:
print(
"Other information: {} has confidence: {}".format(
other_info.value,
other_info.confidence,
)
)
state_tax_info = w2.fields.get("StateTaxInfos")
if state_tax_info:
print("State Tax info:")
for tax in state_tax_info.value:
state = tax.value.get("State")
if state:
print(
"...State: {} has confidence: {}".format(
state.value, state.confidence
)
)
employer_state_id_number = tax.value.get("EmployerStateIdNumber")
if employer_state_id_number:
print(
"...Employer state ID number: {} has confidence: {}".format(
employer_state_id_number.value,
employer_state_id_number.confidence,
)
)
state_wages_tips = tax.value.get("StateWagesTipsEtc")
if state_wages_tips:
print(
"...State wages, tips, etc: {} has confidence: {}".format(
state_wages_tips.value, state_wages_tips.confidence
)
)
state_income_tax = tax.value.get("StateIncomeTax")
if state_income_tax:
print(
"...State income tax: {} has confidence: {}".format(
state_income_tax.value, state_income_tax.confidence
)
)
local_tax_info = w2.fields.get("LocalTaxInfos")
if local_tax_info:
print("Local Tax info:")
for tax in local_tax_info.value:
local_wages_tips = tax.value.get("LocalWagesTipsEtc")
if local_wages_tips:
print(
"...Local wages, tips, etc: {} has confidence: {}".format(
local_wages_tips.value, local_wages_tips.confidence
)
)
local_income_tax = tax.value.get("LocalIncomeTax")
if local_income_tax:
print(
"...Local income tax: {} has confidence: {}".format(
local_income_tax.value, local_income_tax.confidence
)
)
locality_name = tax.value.get("LocalityName")
if locality_name:
print(
"...Locality name: {} has confidence: {}".format(
locality_name.value, locality_name.confidence
)
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_tax_us_w2()
W-2 税モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
請求書モデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
# formatting function
def format_bounding_region(bounding_regions):
if not bounding_regions:
return "N/A"
return ", ".join("Page #{}: {}".format(region.page_number, format_polygon(region.polygon)) for region in bounding_regions)
# formatting function
def format_polygon(polygon):
if not polygon:
return "N/A"
return ", ".join(["[{}, {}]".format(p.x, p.y) for p in polygon])
def analyze_invoice():
invoiceUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/sample-invoice.pdf"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-invoice", invoiceUrl)
invoices = poller.result()
for idx, invoice in enumerate(invoices.documents):
print("--------Recognizing invoice #{}--------".format(idx + 1))
vendor_name = invoice.fields.get("VendorName")
if vendor_name:
print(
"Vendor Name: {} has confidence: {}".format(
vendor_name.value, vendor_name.confidence
)
)
vendor_address = invoice.fields.get("VendorAddress")
if vendor_address:
print(
"Vendor Address: {} has confidence: {}".format(
vendor_address.value, vendor_address.confidence
)
)
vendor_address_recipient = invoice.fields.get("VendorAddressRecipient")
if vendor_address_recipient:
print(
"Vendor Address Recipient: {} has confidence: {}".format(
vendor_address_recipient.value, vendor_address_recipient.confidence
)
)
customer_name = invoice.fields.get("CustomerName")
if customer_name:
print(
"Customer Name: {} has confidence: {}".format(
customer_name.value, customer_name.confidence
)
)
customer_id = invoice.fields.get("CustomerId")
if customer_id:
print(
"Customer Id: {} has confidence: {}".format(
customer_id.value, customer_id.confidence
)
)
customer_address = invoice.fields.get("CustomerAddress")
if customer_address:
print(
"Customer Address: {} has confidence: {}".format(
customer_address.value, customer_address.confidence
)
)
customer_address_recipient = invoice.fields.get("CustomerAddressRecipient")
if customer_address_recipient:
print(
"Customer Address Recipient: {} has confidence: {}".format(
customer_address_recipient.value,
customer_address_recipient.confidence,
)
)
invoice_id = invoice.fields.get("InvoiceId")
if invoice_id:
print(
"Invoice Id: {} has confidence: {}".format(
invoice_id.value, invoice_id.confidence
)
)
invoice_date = invoice.fields.get("InvoiceDate")
if invoice_date:
print(
"Invoice Date: {} has confidence: {}".format(
invoice_date.value, invoice_date.confidence
)
)
invoice_total = invoice.fields.get("InvoiceTotal")
if invoice_total:
print(
"Invoice Total: {} has confidence: {}".format(
invoice_total.value, invoice_total.confidence
)
)
due_date = invoice.fields.get("DueDate")
if due_date:
print(
"Due Date: {} has confidence: {}".format(
due_date.value, due_date.confidence
)
)
purchase_order = invoice.fields.get("PurchaseOrder")
if purchase_order:
print(
"Purchase Order: {} has confidence: {}".format(
purchase_order.value, purchase_order.confidence
)
)
billing_address = invoice.fields.get("BillingAddress")
if billing_address:
print(
"Billing Address: {} has confidence: {}".format(
billing_address.value, billing_address.confidence
)
)
billing_address_recipient = invoice.fields.get("BillingAddressRecipient")
if billing_address_recipient:
print(
"Billing Address Recipient: {} has confidence: {}".format(
billing_address_recipient.value,
billing_address_recipient.confidence,
)
)
shipping_address = invoice.fields.get("ShippingAddress")
if shipping_address:
print(
"Shipping Address: {} has confidence: {}".format(
shipping_address.value, shipping_address.confidence
)
)
shipping_address_recipient = invoice.fields.get("ShippingAddressRecipient")
if shipping_address_recipient:
print(
"Shipping Address Recipient: {} has confidence: {}".format(
shipping_address_recipient.value,
shipping_address_recipient.confidence,
)
)
print("Invoice items:")
for idx, item in enumerate(invoice.fields.get("Items").value):
print("...Item #{}".format(idx + 1))
item_description = item.value.get("Description")
if item_description:
print(
"......Description: {} has confidence: {}".format(
item_description.value, item_description.confidence
)
)
item_quantity = item.value.get("Quantity")
if item_quantity:
print(
"......Quantity: {} has confidence: {}".format(
item_quantity.value, item_quantity.confidence
)
)
unit = item.value.get("Unit")
if unit:
print(
"......Unit: {} has confidence: {}".format(
unit.value, unit.confidence
)
)
unit_price = item.value.get("UnitPrice")
if unit_price:
print(
"......Unit Price: {} has confidence: {}".format(
unit_price.value, unit_price.confidence
)
)
product_code = item.value.get("ProductCode")
if product_code:
print(
"......Product Code: {} has confidence: {}".format(
product_code.value, product_code.confidence
)
)
item_date = item.value.get("Date")
if item_date:
print(
"......Date: {} has confidence: {}".format(
item_date.value, item_date.confidence
)
)
tax = item.value.get("Tax")
if tax:
print(
"......Tax: {} has confidence: {}".format(tax.value, tax.confidence)
)
amount = item.value.get("Amount")
if amount:
print(
"......Amount: {} has confidence: {}".format(
amount.value, amount.confidence
)
)
subtotal = invoice.fields.get("SubTotal")
if subtotal:
print(
"Subtotal: {} has confidence: {}".format(
subtotal.value, subtotal.confidence
)
)
total_tax = invoice.fields.get("TotalTax")
if total_tax:
print(
"Total Tax: {} has confidence: {}".format(
total_tax.value, total_tax.confidence
)
)
previous_unpaid_balance = invoice.fields.get("PreviousUnpaidBalance")
if previous_unpaid_balance:
print(
"Previous Unpaid Balance: {} has confidence: {}".format(
previous_unpaid_balance.value, previous_unpaid_balance.confidence
)
)
amount_due = invoice.fields.get("AmountDue")
if amount_due:
print(
"Amount Due: {} has confidence: {}".format(
amount_due.value, amount_due.confidence
)
)
service_start_date = invoice.fields.get("ServiceStartDate")
if service_start_date:
print(
"Service Start Date: {} has confidence: {}".format(
service_start_date.value, service_start_date.confidence
)
)
service_end_date = invoice.fields.get("ServiceEndDate")
if service_end_date:
print(
"Service End Date: {} has confidence: {}".format(
service_end_date.value, service_end_date.confidence
)
)
service_address = invoice.fields.get("ServiceAddress")
if service_address:
print(
"Service Address: {} has confidence: {}".format(
service_address.value, service_address.confidence
)
)
service_address_recipient = invoice.fields.get("ServiceAddressRecipient")
if service_address_recipient:
print(
"Service Address Recipient: {} has confidence: {}".format(
service_address_recipient.value,
service_address_recipient.confidence,
)
)
remittance_address = invoice.fields.get("RemittanceAddress")
if remittance_address:
print(
"Remittance Address: {} has confidence: {}".format(
remittance_address.value, remittance_address.confidence
)
)
remittance_address_recipient = invoice.fields.get("RemittanceAddressRecipient")
if remittance_address_recipient:
print(
"Remittance Address Recipient: {} has confidence: {}".format(
remittance_address_recipient.value,
remittance_address_recipient.confidence,
)
)
print("----------------------------------------")
if __name__ == "__main__":
analyze_invoice()
請求書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
レシート モデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
def analyze_receipts():
# sample document
receiptUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-receipt", receiptUrl, locale="en-US"
)
receipts = poller.result()
for idx, receipt in enumerate(receipts.documents):
print("--------Analysis of receipt #{}--------".format(idx 1))
print("Receipt type: {}".format(receipt.doc_type or "N/A"))
merchant_name = receipt.fields.get("MerchantName")
if merchant_name:
print(
"Merchant Name: {} has confidence: {}".format(
merchant_name.value, merchant_name.confidence
)
)
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
print(
"Transaction Date: {} has confidence: {}".format(
transaction_date.value, transaction_date.confidence
)
)
if receipt.fields.get("Items"):
print("Receipt items:")
for idx, item in enumerate(receipt.fields.get("Items").value):
print("...Item #{}".format(idx 1))
item_description = item.value.get("Description")
if item_description:
print(
"......Item Description: {} has confidence: {}".format(
item_description.value, item_description.confidence
)
)
item_quantity = item.value.get("Quantity")
if item_quantity:
print(
"......Item Quantity: {} has confidence: {}".format(
item_quantity.value, item_quantity.confidence
)
)
item_price = item.value.get("Price")
if item_price:
print(
"......Individual Item Price: {} has confidence: {}".format(
item_price.value, item_price.confidence
)
)
item_total_price = item.value.get("TotalPrice")
if item_total_price:
print(
"......Total Item Price: {} has confidence: {}".format(
item_total_price.value, item_total_price.confidence
)
)
subtotal = receipt.fields.get("Subtotal")
if subtotal:
print(
"Subtotal: {} has confidence: {}".format(
subtotal.value, subtotal.confidence
)
)
tax = receipt.fields.get("TotalTax")
if tax:
print("Total tax: {} has confidence: {}".format(tax.value, tax.confidence))
tip = receipt.fields.get("Tip")
if tip:
print("Tip: {} has confidence: {}".format(tip.value, tip.confidence))
total = receipt.fields.get("Total")
if total:
print("Total: {} has confidence: {}".format(total.value, total.confidence))
print("--------------------------------------")
if __name__ == "__main__":
analyze_receipts()
領収書モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
身分証明書モデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
def analyze_identity_documents():
# sample document
identityUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-idDocument", identityUrl
)
id_documents = poller.result()
for idx, id_document in enumerate(id_documents.documents):
print("--------Analyzing ID document #{}--------".format(idx + 1))
first_name = id_document.fields.get("FirstName")
if first_name:
print(
"First Name: {} has confidence: {}".format(
first_name.value, first_name.confidence
)
)
last_name = id_document.fields.get("LastName")
if last_name:
print(
"Last Name: {} has confidence: {}".format(
last_name.value, last_name.confidence
)
)
document_number = id_document.fields.get("DocumentNumber")
if document_number:
print(
"Document Number: {} has confidence: {}".format(
document_number.value, document_number.confidence
)
)
dob = id_document.fields.get("DateOfBirth")
if dob:
print(
"Date of Birth: {} has confidence: {}".format(dob.value, dob.confidence)
)
doe = id_document.fields.get("DateOfExpiration")
if doe:
print(
"Date of Expiration: {} has confidence: {}".format(
doe.value, doe.confidence
)
)
sex = id_document.fields.get("Sex")
if sex:
print("Sex: {} has confidence: {}".format(sex.value, sex.confidence))
address = id_document.fields.get("Address")
if address:
print(
"Address: {} has confidence: {}".format(
address.value, address.confidence
)
)
country_region = id_document.fields.get("CountryRegion")
if country_region:
print(
"Country/Region: {} has confidence: {}".format(
country_region.value, country_region.confidence
)
)
region = id_document.fields.get("Region")
if region:
print(
"Region: {} has confidence: {}".format(region.value, region.confidence)
)
print("--------------------------------------")
if __name__ == "__main__":
analyze_identity_documents()
ID ドキュメント モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
名刺モデルを使用する
import os
from azure.ai.formrecognizer import DocumentAnalysisClient
from azure.core.credentials import AzureKeyCredential
# use your `key` and `endpoint` environment variables
key = os.environ.get('FR_KEY')
endpoint = os.environ.get('FR_ENDPOINT')
def analyze_business_card():
# sample document
businessCardUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/de5e0d8982ab754823c54de47a47e8e499351523/curl/form-recognizer/rest-api/business_card.jpg"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-businessCard", businessCardUrl, locale="en-US"
)
business_cards = poller.result()
for idx, business_card in enumerate(business_cards.documents):
print("--------Analyzing business card #{}--------".format(idx + 1))
contact_names = business_card.fields.get("ContactNames")
if contact_names:
for contact_name in contact_names.value:
print(
"Contact First Name: {} has confidence: {}".format(
contact_name.value["FirstName"].value,
contact_name.value[
"FirstName"
].confidence,
)
)
print(
"Contact Last Name: {} has confidence: {}".format(
contact_name.value["LastName"].value,
contact_name.value[
"LastName"
].confidence,
)
)
company_names = business_card.fields.get("CompanyNames")
if company_names:
for company_name in company_names.value:
print(
"Company Name: {} has confidence: {}".format(
company_name.value, company_name.confidence
)
)
departments = business_card.fields.get("Departments")
if departments:
for department in departments.value:
print(
"Department: {} has confidence: {}".format(
department.value, department.confidence
)
)
job_titles = business_card.fields.get("JobTitles")
if job_titles:
for job_title in job_titles.value:
print(
"Job Title: {} has confidence: {}".format(
job_title.value, job_title.confidence
)
)
emails = business_card.fields.get("Emails")
if emails:
for email in emails.value:
print(
"Email: {} has confidence: {}".format(email.value, email.confidence)
)
websites = business_card.fields.get("Websites")
if websites:
for website in websites.value:
print(
"Website: {} has confidence: {}".format(
website.value, website.confidence
)
)
addresses = business_card.fields.get("Addresses")
if addresses:
for address in addresses.value:
print(
"Address: {} has confidence: {}".format(
address.value, address.confidence
)
)
mobile_phones = business_card.fields.get("MobilePhones")
if mobile_phones:
for phone in mobile_phones.value:
print(
"Mobile phone number: {} has confidence: {}".format(
phone.content, phone.confidence
)
)
faxes = business_card.fields.get("Faxes")
if faxes:
for fax in faxes.value:
print(
"Fax number: {} has confidence: {}".format(
fax.content, fax.confidence
)
)
work_phones = business_card.fields.get("WorkPhones")
if work_phones:
for work_phone in work_phones.value:
print(
"Work phone number: {} has confidence: {}".format(
work_phone.content, work_phone.confidence
)
)
other_phones = business_card.fields.get("OtherPhones")
if other_phones:
for other_phone in other_phones.value:
print(
"Other phone number: {} has confidence: {}".format(
other_phone.value, other_phone.confidence
)
)
print("--------------------------------------")
if __name__ == "__main__":
analyze_business_card()
名刺モデルの出力を表示するには、GitHub 上の Azure サンプル リポジトリにアクセスします。
Note
このプロジェクトでは、cURL コマンド ライン ツールを使って REST API 呼び出しを行います。
| Document Intelligence REST API | サポートされている Azure SDKs
前提条件
Azure サブスクリプション。無料で作成できます。
cURL コマンド ライン ツールがインストールされている。 Windows 10 と Windows 11 には cURL が含まれています。 コマンド プロンプトで、次の cURL コマンドを入力します。 ヘルプ オプションが表示される場合は、Windows 環境に cURL がインストールされます。
curl -helpcURLがインストールされていない場合は、ここで入手できます。
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
ドキュメントを分析して結果を取得する
POST 要求は、事前構築済みまたはカスタムのモデルを使用してドキュメントを分析するために使用されます。 GET 要求は、ドキュメント分析呼び出しの結果を取得するために使用されます。 modelId は POST 操作で使用され、resultId は GET 操作で使用されます。
次の表を参照してください。 <modelId> と <document-url> を目的の値に置き換えます。
| モデル | modelId | description | document-url |
|---|---|---|---|
| 読み取りモデル | prebuilt-read | サンプル パンフレット | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png |
| レイアウト モデル | 事前構築済みレイアウト | 予約確認のサンプル | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png |
| W-2 フォーム モデル | prebuilt-tax.us.w2 | サンプル W-2 フォーム | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png |
| 請求書モデル | prebuilt-invoice | サンプル請求書 | https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf |
| レシート モデル | prebuilt-receipt | サンプル レシート | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png |
| 身分証明書モデル | prebuilt-idDocument | サンプル身分証明書 | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png |
POST 要求
コンソール ウィンドウを開き、次の cURL コマンドを実行します。 コマンドには、「環境変数を設定する」セクションで先ほど作成したエンドポイントと主要な環境変数が含まれています。 変数名が異なる場合は、これらの変数を置き換えます。 <modelId> パラメーターと <document-url> パラメーターは必ず置き換えてください。
curl -i -X POST "%DI_ENDPOINT%/documentintelligence/documentModels/{modelId}:analyze?api-version=2024-02-29-preview" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: %DI_KEY%" --data-ascii "{'urlSource': '<document-url>'}"
アドオン機能を有効にするには、POST 要求で features クエリ パラメーターを使用します。 2023-07-31 (GA) 以降のリリースには、ocr.highResolution、ocr.formula、ocr.font、queryFields.premium の 4 つのアドオン機能があります。 各機能の詳細については、「カスタム モデル」を参照してください。
読み取りモデルとレイアウト モデルでは highResolution、formula、および font 機能のみを呼び出すことができ、一般ドキュメント モデルでは queryFields 機能のみを呼び出すことができます。 次の例は、レイアウト モデルの highResolution、formula、および font 機能を呼び出す方法を示しています。
curl -i -X POST "%DI_ENDPOINT%documentintelligence/documentModels/prebuilt-layout:analyze?features=ocr.highResolution,ocr.formula,ocr.font?api-version=2024-02-29-preview" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: %DI_KEY%" --data-ascii "{'urlSource': '<document-url>'}"
POST 応答
Operation-location ヘッダーを含む 202 (Success) 応答を受信します。 このヘッダーの値を使用して、応答の結果を取得します。

Get analyze result (GET 要求)
Analyze documentAPI を呼び出したら、[Get analyze result}(/rest/api/aiservices/document-models/get-analyze-result?view=rest-aiservices-2024-02-29-preview&preserve-view=true&tabs=HTTP) API を呼び出して、操作の状態と抽出されたデータを取得します。
cURL コマンド ライン ツールでは、JSON コンテンツを含む API 応答の書式が設定されないため、コンテンツの読み取りが困難になる場合があります。 JSON 応答の書式を設定するには、GET 要求に、パイプ文字に続けて JSON 書式設定ツールを含めます。
NodeJS "json ツール" を cURL の JSON フォーマッタとして使用します。 Node.js がインストールされていない場合は、最新バージョンをダウンロードしてインストールします。
コンソール ウィンドウを開き、次のコマンドを使用して json ツールをインストールします。
npm install -g jsontoolGET 要求にパイプ文字
| jsonを含めて、JSON 出力を適切に出力します。curl -i -X GET "<endpoint>documentintelligence/documentModels/prebuilt-read/analyzeResults/0e49604a-2d8e-4b15-b6b8-bb456e5d3e0a?api-version=2024-02-29-preview"-H "Ocp-Apim-Subscription-Key: <subscription key>" | json
GET 要求
次のコマンドを実行する前に、これらの変更を行います。
- <POST response> を POST 応答の
Operation-locationヘッダーと置き換えます。 - <DI_KEY がコード内の名前と異なる場合は、ご自分の環境変数の変数で置き換えます。
- *<json-tool> をご自分の JSON 書式設定ツールで置き換えます。
curl -i -X GET "<POST response>" -H "Ocp-Apim-Subscription-Key: %DI_KEY%" | `<json-tool>`
結果の確認
JSON 出力で 200 (Success) 応答を受信します。 最初のフィールド status は、操作の状態を示します。 操作が完了していない場合、status の値は running または notStartedです。 手動またはスクリプトを使用して、API をもう一度呼び出します。 呼び出しの間隔は 1 秒以上あけることをお勧めします。
GitHub の Azure サンプル リポジトリにアクセスして、各 Document Intelligence モデルの GET 応答を表示します。
| モデル | 出力 URL |
|---|---|
| 読み取りモデル | 読み取りモデルの出力 |
| レイアウト モデル | レイアウト モデルの出力 |
| W-2 税モデル | W-2 税モデルの出力 |
| 請求書モデル | 請求書モデルの出力 |
| レシート モデル | 領収書モデルの出力 |
| 身分証明書モデル | ID ドキュメント モデルの出力 |
Note
このプロジェクトでは、cURL コマンド ライン ツールを使って REST API 呼び出しを行います。
前提条件
Azure サブスクリプション。無料で作成できます。
cURL コマンド ライン ツールがインストールされている。 Windows 10 と Windows 11 には cURL が含まれています。 コマンド プロンプトで、次の cURL コマンドを入力します。 ヘルプ オプションが表示される場合は、Windows 環境に cURL がインストールされます。
curl -helpcURLがインストールされていない場合は、ここで入手できます。
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
環境変数を設定する
Document Intelligence サービスとやり取りするには、DocumentAnalysisClient クラスのインスタンスを作成する必要があります。 これを行うには、Azure portal から key と endpoint を使用してクライアントをインスタンス化します。 このプロジェクトでは、資格情報の格納とアクセスに環境変数を使用します。
重要
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
ドキュメントインテリジェンスリソース キーの環境変数を設定するには、コンソール ウィンドウを開き、オペレーティング システムと開発環境の指示に従います。 <yourKey> と <yourEndpoint> を、Azure portal 内のご自分のリソースの値に置き換えます。
Windows の環境変数では大文字と小文字は区別されません。 通常は大文字で宣言され、単語はアンダースコアで結合されます。 コマンド プロンプトで、次のコマンドを実行します。
キー変数を設定します。
setx DI_KEY <yourKey>エンドポイント変数を設定する
setx DI_ENDPOINT <yourEndpoint>環境変数を設定したら、[コマンド プロンプト] ウィンドウを閉じます。 値は、もう一度変更するまで保持されます。
環境変数を読み取る実行中のプログラムを再起動します。 たとえば、Visual Studio または Visual Studio Code をエディターとして使用している場合、サンプル コードを実行する前に再起動する必要があります。
環境変数で使用するのに役立つコマンドをいくつか次に示します。
| コマンド | アクション | 例 |
|---|---|---|
setx VARIABLE_NAME= |
値を空の文字列に設定して、環境変数を削除します。 | setx DI_KEY= |
setx VARIABLE_NAME=value |
環境変数の値を設定または変更します | setx DI_KEY=<yourKey> |
set VARIABLE_NAME |
特定の環境変数の値を表示します。 | set DI_KEY |
set |
すべての環境変数を表示します。 | set |
ドキュメントを分析して結果を取得する
POST 要求は、事前構築済みまたはカスタムのモデルを使用してドキュメントを分析するために使用されます。 GET 要求は、ドキュメント分析呼び出しの結果を取得するために使用されます。 modelId は POST 操作で使用され、resultId は GET 操作で使用されます。
次の表を参照してください。 <modelId> と <document-url> を目的の値に置き換えます。
| モデル | modelId | description | document-url |
|---|---|---|---|
| 読み取りモデル | prebuilt-read | サンプル パンフレット | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png |
| レイアウト モデル | 事前構築済みレイアウト | 予約確認のサンプル | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/layout.png |
| W-2 フォーム モデル | prebuilt-tax.us.w2 | サンプル W-2 フォーム | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/w2.png |
| 請求書モデル | prebuilt-invoice | サンプル請求書 | https://github.com/Azure-Samples/cognitive-services-REST-api-samples/raw/master/curl/form-recognizer/rest-api/invoice.pdf |
| レシート モデル | prebuilt-receipt | サンプル レシート | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/receipt.png |
| 身分証明書モデル | prebuilt-idDocument | サンプル身分証明書 | https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/identity_documents.png |
POST 要求
コンソール ウィンドウを開き、次の cURL コマンドを実行します。 コマンドには、「環境変数を設定する」セクションで先ほど作成したエンドポイントと主要な環境変数が含まれています。 変数名が異なる場合は、これらの変数を置き換えます。 <modelId> パラメーターと <document-url> パラメーターは必ず置き換えてください。
curl -i -X POST "%FR_ENDPOINT%formrecognizer/documentModels/<modelId>:analyze?api-version=2023-07-31" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: %FR_KEY%" --data-ascii "{'urlSource': '<document-url>'}"
アドオン機能を有効にするには、POST 要求で features クエリ パラメーターを使用します。 2023-07-31 (GA) リリースには、ocr.highResolution、ocr.formula、ocr.font、queryFields.premium の 4 つのアドオン機能があります。 各機能の詳細については、「カスタム モデル」を参照してください。
読み取りモデルとレイアウト モデルでは highResolution、formula、および font 機能のみを呼び出すことができ、一般ドキュメント モデルでは queryFields 機能のみを呼び出すことができます。 次の例は、レイアウト モデルの highResolution、formula、および font 機能を呼び出す方法を示しています。
curl -i -X POST "%FR_ENDPOINT%formrecognizer/documentModels/prebuilt-layout:analyze?features=ocr.highResolution,ocr.formula,ocr.font?api-version=2023-07-31" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: %FR_KEY%" --data-ascii "{'urlSource': '<document-url>'}"
POST 応答
Operation-location ヘッダーを含む 202 (Success) 応答を受信します。 このヘッダーの値を使用して、応答の結果を取得します。
Get analyze result (GET 要求)
Analyze documentAPI を呼び出したら、[Get analyze result}(/rest/api/aiservices/document-models/get-analyze-result?view=rest-aiservices-2023-07-31&preserve-view=true&tabs=HTTP) API を呼び出して、操作の状態と抽出されたデータを取得します。
cURL コマンド ライン ツールでは、JSON コンテンツを含む API 応答の書式が設定されないため、コンテンツの読み取りが困難になる場合があります。 JSON 応答の書式を設定するには、GET 要求に、パイプ文字に続けて JSON 書式設定ツールを含めます。
NodeJS "json ツール" を cURL の JSON フォーマッタとして使用します。 Node.js がインストールされていない場合は、最新バージョンをダウンロードしてインストールします。
コンソール ウィンドウを開き、次のコマンドを使用して json ツールをインストールします。
npm install -g jsontoolGET 要求にパイプ文字
| jsonを含めて、JSON 出力を適切に出力します。curl -i -X GET "<endpoint>formrecognizer/documentModels/prebuilt-read/analyzeResults/0e49604a-2d8e-4b15-b6b8-bb456e5d3e0a?api-version=2023-07-31"-H "Ocp-Apim-Subscription-Key: <subscription key>" | json
GET 要求
次のコマンドを実行する前に、これらの変更を行います。
- <POST response> を POST 応答の
Operation-locationヘッダーと置き換えます。 - <FR_KEY がコード内の名前と異なる場合は、ご自分の環境変数の変数で置き換えます。
- *<json-tool> をご自分の JSON 書式設定ツールで置き換えます。
curl -i -X GET "<POST response>" -H "Ocp-Apim-Subscription-Key: %FR_KEY%" | `<json-tool>`
結果の確認
JSON 出力で 200 (Success) 応答を受信します。 最初のフィールド status は、操作の状態を示します。 操作が完了していない場合、status の値は running または notStartedです。 手動またはスクリプトを使用して、API をもう一度呼び出します。 呼び出しの間隔は 1 秒以上あけることをお勧めします。
GitHub の Azure サンプル リポジトリにアクセスして、各 Document Intelligence モデルの GET 応答を表示します。
| モデル | 出力 URL |
|---|---|
| 読み取りモデル | 読み取りモデルの出力 |
| レイアウト モデル | レイアウト モデルの出力 |
| W-2 税モデル | W-2 税モデルの出力 |
| 請求書モデル | 請求書モデルの出力 |
| レシート モデル | 領収書モデルの出力 |
| 身分証明書モデル | ID ドキュメント モデルの出力 |
次のステップ
お疲れさまでした。 Document Intelligence モデルを使用して、さまざまな方法でさまざまなドキュメントを分析する方法を学習しました。 次は、Document Intelligence Studio とリファレンス ドキュメントを確認します。
この攻略ガイドでは、アプリケーションとワークフローに Document Intelligence を追加する方法について説明します。 任意のプログラミング言語または REST API を使用します。 Azure AI Document Intelligence は、機械学習を使用してドキュメントからキーと値のペア、テキスト、テーブルを抽出するクラウドベースの Azure AI サービスです。 このテクノロジを学習している間は、無料のサービスを使用することをお勧めします。 無料のページは 1 か月あたり 500 ページに制限されていることに注意してください。
次の API を使用して、フォームとドキュメントから構造化データを抽出します。
重要
このプロジェクトは、ドキュメントインテリジェンス REST API v2.1 を対象としています。
この記事のコードでは、同期メソッドと、セキュリティで保護されていない資格情報ストレージを使用しています。
リファレンスのドキュメント | ライブラリのソース コード | パッケージ (NuGet) | サンプル
前提条件
Azure サブスクリプション。無料で作成できます。
Visual Studio IDE または現在のバージョンの .NET Core。
トレーニング データのセットを含む Azure Storage Blob。 トレーニング データセットをまとめるためのヒントとオプションについては、「カスタム モデルを構築してトレーニング データする」を参照してください。 このプロジェクトでは、サンプル データ セットの Train フォルダーにあるファイルを使用できます。 sample_data.zip をダウンロードして展開します。
Intelligence リソース。 Free 価格レベル (
F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
プログラミング環境のセットアップ
コンソール ウィンドウで、dotnet new コマンドを使用し、formrecognizer-project という名前で新しいコンソール アプリを作成します。 このコマンドにより、1 つのソース ファイル (program.cs) を使用する単純な "Hello World" C# プロジェクトが作成されます。
dotnet new console -n formrecognizer-project
新しく作成されたアプリ フォルダーにディレクトリを変更します。 次のコマンドでアプリケーションをビルドします。
dotnet build
ビルドの出力に警告やエラーが含まれないようにする必要があります。
...
Build succeeded.
0 Warning(s)
0 Error(s)
...
クライアント ライブラリをインストールする
次のコマンドを使用して、アプリケーション ディレクトリ内に .NET 用 Face クライアント ライブラリをインストールします:
dotnet add package Azure.AI.FormRecognizer --version 3.1.1
プロジェクト ディレクトリから、エディターまたは IDE で program.cs ファイルを開きます。 次の using ディレクティブを追加します。
using Azure;
using Azure.AI.FormRecognizer;
using Azure.AI.FormRecognizer.Models;
using Azure.AI.FormRecognizer.Training;
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
アプリケーションの Program クラスに、リソースのキーとエンドポイントの変数を作成します。
重要
Azure Portal にアクセスします。 「前提条件」セクションで作成した Document Intelligence リソースが正常にデプロイされた場合、[次の手順] の下にある [リソースに移動] ボタンをクリックします。 左側のナビゲーション メニューの [リソース管理] で、[キーとエンドポイント] を選択します。
終わったらコードからキーを必ず削除してください。 決して公開しないよう注意してください。 運用環境では、セキュリティで保護された方法を使用して資格情報を格納し、アクセスします。 詳しくは、「Azure AI サービスのセキュリティ」をご覧ください。
private static readonly string endpoint = "PASTE_YOUR_FORM_RECOGNIZER_ENDPOINT_HERE";
private static readonly string apiKey = "PASTE_YOUR_FORM_RECOGNIZER_SUBSCRIPTION_KEY_HERE";
private static readonly AzureKeyCredential credential = new AzureKeyCredential(apiKey);
アプリケーションの Main メソッドで、このプロジェクトで使用する非同期タスクの呼び出しを追加します。
static void Main(string[] args) {
// new code:
var recognizeContent = RecognizeContent(recognizerClient);
Task.WaitAll(recognizeContent);
var analyzeReceipt = AnalyzeReceipt(recognizerClient, receiptUrl);
Task.WaitAll(analyzeReceipt);
var analyzeBusinessCard = AnalyzeBusinessCard(recognizerClient, bcUrl);
Task.WaitAll(analyzeBusinessCard);
var analyzeInvoice = AnalyzeInvoice(recognizerClient, invoiceUrl);
Task.WaitAll(analyzeInvoice);
var analyzeId = AnalyzeId(recognizerClient, idUrl);
Task.WaitAll(analyzeId);
var trainModel = TrainModel(trainingClient, trainingDataUrl);
Task.WaitAll(trainModel);
var trainModelWithLabels = TrainModelWithLabels(trainingClient, trainingDataUrl);
Task.WaitAll(trainModel);
var analyzeForm = AnalyzePdfForm(recognizerClient, modelId, formUrl);
Task.WaitAll(analyzeForm);
var manageModels = ManageModels(trainingClient, trainingDataUrl);
Task.WaitAll(manageModels);
}
オブジェクト モデルを使用する
Document Intelligence で作成できるクライアントは 2 種類あります。 1 つ目の FormRecognizerClient はサービスに対しクエリを実行しフォーム フィールドとコンテンツを認識します。 もう 1 つは FormTrainingClient であり、認識精度を高めるためのカスタム モデルを作成および管理します。
FormRecognizerClient を使用すると、次の処理を実行できます。
- 対象のカスタム フォームを分析するようトレーニングされたカスタム モデルを使用して、フォームのフィールドやコンテンツを認識する。 これらの値は、
RecognizedFormオブジェクトのコレクションとして返されます。 「カスタム モデルを使用してフォームを分析する」を参照してください。 - モデルをトレーニングせずにフォームのコンテンツ (表、行、単語など) を認識する。 フォームのコンテンツは、
FormPageオブジェクトのコレクションとして返されます。 「レイアウトを分析する」を参照してください。 - Document Intelligence サービスの事前トレーニング済みのモデルを使用して、米国の領収書、名刺、請求書、および身分証明書から一般的なフィールドを認識する。
FormTrainingClient には、以下を目的とした操作が用意されています。
- カスタム モデルをトレーニングして、対象のカスタム フォームにあるすべてのフィールドと値を分析する。 モデルによって分析されるフォームの種類とそれぞれのフォームの種類で抽出されるフィールドを示す
CustomFormModelが返されます。 - 対象のカスタム フォームにラベル付けすることによって指定した特定のフィールドと値を分析するように、カスタム モデルをトレーニングする。 モデルによって抽出されるフィールドと各フィールドの推定精度を示す
CustomFormModelが返されます。 - アカウントに作成されたモデルを管理する。
- Document Intelligence リソース間でカスタム モデルをコピーする。
例については、「モデルのトレーニング」と「カスタム モデルの管理」を参照してください。
Note
モデルのトレーニングは、サンプル ラベル付けツールなどのグラフィカル ユーザー インターフェイスを使用して行うこともできます。
クライアントを認証する
Main で、AuthenticateClient というメソッドを作成します。 このメソッドは、他のタスクで Document Intelligence サービスへの要求を認証するために使用します。 このメソッドには AzureKeyCredential オブジェクトが使用されているため、新しいクライアント オブジェクトを作成しなくても必要に応じてキーを更新することができます。
private static FormRecognizerClient AuthenticateClient()
{
var credential = new AzureKeyCredential(apiKey);
var client = new FormRecognizerClient(new Uri(endpoint), credential);
return client;
}
トレーニング クライアントを認証する新しいメソッドに対して、この手順を繰り返します。
static private FormTrainingClient AuthenticateTrainingClient()
{
var credential = new AzureKeyCredential(apiKey);
var client = new FormTrainingClient(new Uri(endpoint), credential);
return client;
}
テスト用のアセットを取得する
また、トレーニングとテスト データの URL への参照を追加する必要もあります。 これらの参照を Program クラスのルートに追加します。
カスタム モデルのトレーニング データの SAS URL を取得するには、Azure portal のストレージ リソースに移動し、[データ ストレージ]>[コンテナー] を選択します。
ご自分のコンテナーに移動し、右クリックして [SAS の生成] を選択します。
ストレージ アカウント自体ではなく、ご自分のコンテナー用の SAS を取得することが重要です。
[読み取り]、[書き込み]、[削除]、[リスト] の各アクセス許可が選択されていることを確認し、[SAS トークンと URL の生成] を選択します。
URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。
前述の手順を繰り返して、Blob Storage コンテナー内の個々のドキュメントの SAS URL を取得します。 その SAS URL も一時的な場所に保存します。
含まれているサンプル イメージの URL を保存します。 そのイメージは、GitHub でも入手できます。
string trainingDataUrl = "PASTE_YOUR_SAS_URL_OF_YOUR_FORM_FOLDER_IN_BLOB_STORAGE_HERE";
string formUrl = "PASTE_YOUR_FORM_RECOGNIZER_FORM_URL_HERE";
string receiptUrl = "https://docs.microsoft.com/azure/cognitive-services/form-recognizer/media" + "/contoso-allinone.jpg";
string bcUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/samples/sample_forms/business_cards/business-card-english.jpg";
string invoiceUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/simple-invoice.png";
string idUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/id-license.jpg";
レイアウトを分析する
Document Intelligence を使用すると、ドキュメント内の表、行、および単語を分析できます。モデルをトレーニングする必要はありません。 返される値は、FormPage オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 レイアウト抽出の詳細については、「Document Intelligence レイアウト モデル」を参照してください。
指定された URL にあるファイルの内容を分析するには、StartRecognizeContentFromUri メソッドを使用します。
private static async Task RecognizeContent(FormRecognizerClient recognizerClient)
{
var invoiceUri = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/simple-invoice.png";
FormPageCollection formPages = await recognizerClient
.StartRecognizeContentFromUri(new Uri(invoiceUri))
.WaitForCompletionAsync();
ヒント
また、ローカルのファイルから内容を取得することもできます。 FormRecognizerClient のメソッドを参照してください (StartRecognizeContent など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
このタスクの残りの部分では、コンテンツ情報をコンソールに出力します。
foreach (FormPage page in formPages)
{
Console.WriteLine($"Form Page {page.PageNumber} has {page.Lines.Count} lines.");
for (int i = 0; i < page.Lines.Count; i++)
{
FormLine line = page.Lines[i];
Console.WriteLine($" Line {i} has {line.Words.Count} word{(line.Words.Count > 1 ? "s" : "")}, and text: '{line.Text}'.");
}
for (int i = 0; i < page.Tables.Count; i++)
{
FormTable table = page.Tables[i];
Console.WriteLine($"Table {i} has {table.RowCount} rows and {table.ColumnCount} columns.");
foreach (FormTableCell cell in table.Cells)
{
Console.WriteLine($" Cell ({cell.RowIndex}, {cell.ColumnIndex}) contains text: '{cell.Text}'.");
}
}
}
}
結果は次の出力のようになります。
Form Page 1 has 18 lines.
Line 0 has 1 word, and text: 'Contoso'.
Line 1 has 1 word, and text: 'Address:'.
Line 2 has 3 words, and text: 'Invoice For: Microsoft'.
Line 3 has 4 words, and text: '1 Redmond way Suite'.
Line 4 has 3 words, and text: '1020 Enterprise Way'.
Line 5 has 3 words, and text: '6000 Redmond, WA'.
Line 6 has 3 words, and text: 'Sunnayvale, CA 87659'.
Line 7 has 1 word, and text: '99243'.
Line 8 has 2 words, and text: 'Invoice Number'.
Line 9 has 2 words, and text: 'Invoice Date'.
Line 10 has 3 words, and text: 'Invoice Due Date'.
Line 11 has 1 word, and text: 'Charges'.
Line 12 has 2 words, and text: 'VAT ID'.
Line 13 has 1 word, and text: '34278587'.
Line 14 has 1 word, and text: '6/18/2017'.
Line 15 has 1 word, and text: '6/24/2017'.
Line 16 has 1 word, and text: '$56,651.49'.
Line 17 has 1 word, and text: 'PT'.
Table 0 has 2 rows and 6 columns.
Cell (0, 0) contains text: 'Invoice Number'.
Cell (0, 1) contains text: 'Invoice Date'.
Cell (0, 2) contains text: 'Invoice Due Date'.
Cell (0, 3) contains text: 'Charges'.
Cell (0, 5) contains text: 'VAT ID'.
Cell (1, 0) contains text: '34278587'.
Cell (1, 1) contains text: '6/18/2017'.
Cell (1, 2) contains text: '6/24/2017'.
Cell (1, 3) contains text: '$56,651.49'.
Cell (1, 5) contains text: 'PT'.
領収書を分析する
このセクションでは、事前トレーニング済みの領収書モデルを使用して、米国の領収書から共通フィールドを分析、抽出する方法を示します。 領収書分析の詳細については、「Document Intelligence 領収書モデル」を参照してください。
URL からレシートを分析するには、StartRecognizeReceiptsFromUri メソッドを使用します。
private static async Task AnalyzeReceipt(
FormRecognizerClient recognizerClient, string receiptUri)
{
RecognizedFormCollection receipts = await recognizerClient.StartRecognizeReceiptsFromUri(new Uri(receiptUrl)).WaitForCompletionAsync();
ヒント
ローカルにあるレシートの画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (StartRecognizeReceipts など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
返される値は、RecognizedForm オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 次のコードでは、指定された URI にある領収書を処理し、主要なフィールドと値をコンソールに出力します。
foreach (RecognizedForm receipt in receipts)
{
FormField merchantNameField;
if (receipt.Fields.TryGetValue("MerchantName", out merchantNameField))
{
if (merchantNameField.Value.ValueType == FieldValueType.String)
{
string merchantName = merchantNameField.Value.AsString();
Console.WriteLine($"Merchant Name: '{merchantName}', with confidence {merchantNameField.Confidence}");
}
}
FormField transactionDateField;
if (receipt.Fields.TryGetValue("TransactionDate", out transactionDateField))
{
if (transactionDateField.Value.ValueType == FieldValueType.Date)
{
DateTime transactionDate = transactionDateField.Value.AsDate();
Console.WriteLine($"Transaction Date: '{transactionDate}', with confidence {transactionDateField.Confidence}");
}
}
FormField itemsField;
if (receipt.Fields.TryGetValue("Items", out itemsField))
{
if (itemsField.Value.ValueType == FieldValueType.List)
{
foreach (FormField itemField in itemsField.Value.AsList())
{
Console.WriteLine("Item:");
if (itemField.Value.ValueType == FieldValueType.Dictionary)
{
IReadOnlyDictionary<string, FormField> itemFields = itemField.Value.AsDictionary();
FormField itemNameField;
if (itemFields.TryGetValue("Name", out itemNameField))
{
if (itemNameField.Value.ValueType == FieldValueType.String)
{
string itemName = itemNameField.Value.AsString();
Console.WriteLine($" Name: '{itemName}', with confidence {itemNameField.Confidence}");
}
}
FormField itemTotalPriceField;
if (itemFields.TryGetValue("TotalPrice", out itemTotalPriceField))
{
if (itemTotalPriceField.Value.ValueType == FieldValueType.Float)
{
float itemTotalPrice = itemTotalPriceField.Value.AsFloat();
Console.WriteLine($" Total Price: '{itemTotalPrice}', with confidence {itemTotalPriceField.Confidence}");
}
}
}
}
}
}
FormField totalField;
if (receipt.Fields.TryGetValue("Total", out totalField))
{
if (totalField.Value.ValueType == FieldValueType.Float)
{
float total = totalField.Value.AsFloat();
Console.WriteLine($"Total: '{total}', with confidence '{totalField.Confidence}'");
}
}
}
}
結果は次の出力のようになります。
Form Page 1 has 18 lines.
Line 0 has 1 word, and text: 'Contoso'.
Line 1 has 1 word, and text: 'Address:'.
Line 2 has 3 words, and text: 'Invoice For: Microsoft'.
Line 3 has 4 words, and text: '1 Redmond way Suite'.
Line 4 has 3 words, and text: '1020 Enterprise Way'.
Line 5 has 3 words, and text: '6000 Redmond, WA'.
Line 6 has 3 words, and text: 'Sunnayvale, CA 87659'.
Line 7 has 1 word, and text: '99243'.
Line 8 has 2 words, and text: 'Invoice Number'.
Line 9 has 2 words, and text: 'Invoice Date'.
Line 10 has 3 words, and text: 'Invoice Due Date'.
Line 11 has 1 word, and text: 'Charges'.
Line 12 has 2 words, and text: 'VAT ID'.
Line 13 has 1 word, and text: '34278587'.
Line 14 has 1 word, and text: '6/18/2017'.
Line 15 has 1 word, and text: '6/24/2017'.
Line 16 has 1 word, and text: '$56,651.49'.
Line 17 has 1 word, and text: 'PT'.
Table 0 has 2 rows and 6 columns.
Cell (0, 0) contains text: 'Invoice Number'.
Cell (0, 1) contains text: 'Invoice Date'.
Cell (0, 2) contains text: 'Invoice Due Date'.
Cell (0, 3) contains text: 'Charges'.
Cell (0, 5) contains text: 'VAT ID'.
Cell (1, 0) contains text: '34278587'.
Cell (1, 1) contains text: '6/18/2017'.
Cell (1, 2) contains text: '6/24/2017'.
Cell (1, 3) contains text: '$56,651.49'.
Cell (1, 5) contains text: 'PT'.
Merchant Name: 'Contoso Contoso', with confidence 0.516
Transaction Date: '6/10/2019 12:00:00 AM', with confidence 0.985
Item:
Name: '8GB RAM (Black)', with confidence 0.916
Total Price: '999', with confidence 0.559
Item:
Name: 'SurfacePen', with confidence 0.858
Total Price: '99.99', with confidence 0.386
Total: '1203.39', with confidence '0.774'
名刺を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、英語の名刺から共通フィールドを分析、抽出する方法を示します。 名刺分析の詳細については、「Document Intelligence 名刺モデル」を参照してください。
URL から名刺を分析するには、StartRecognizeBusinessCardsFromUriAsync メソッドを使用します。
private static async Task AnalyzeBusinessCard(
FormRecognizerClient recognizerClient, string bcUrl) {
RecognizedFormCollection businessCards = await recognizerClient.StartRecognizeBusinessCardsFromUriAsync(bcUrl).WaitForCompletionAsync();
ヒント
ローカルにある名刺の画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (StartRecognizeBusinessCards など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
次のコードでは、指定された URI にある名刺を処理し、主要なフィールドと値をコンソールに出力します。
foreach(RecognizedForm businessCard in businessCards) {
FormField ContactNamesField;
if (businessCard.Fields.TryGetValue("ContactNames", out ContactNamesField)) {
if (ContactNamesField.Value.ValueType == FieldValueType.List) {
foreach(FormField contactNameField in ContactNamesField.Value.AsList()) {
Console.WriteLine($ "Contact Name: {contactNameField.ValueData.Text}");
if (contactNameField.Value.ValueType == FieldValueType.Dictionary) {
IReadOnlyDictionary < string,
FormField > contactNameFields = contactNameField.Value.AsDictionary();
FormField firstNameField;
if (contactNameFields.TryGetValue("FirstName", out firstNameField)) {
if (firstNameField.Value.ValueType == FieldValueType.String) {
string firstName = firstNameField.Value.AsString();
Console.WriteLine($ " First Name: '{firstName}', with confidence {firstNameField.Confidence}");
}
}
FormField lastNameField;
if (contactNameFields.TryGetValue("LastName", out lastNameField)) {
if (lastNameField.Value.ValueType == FieldValueType.String) {
string lastName = lastNameField.Value.AsString();
Console.WriteLine($ " Last Name: '{lastName}', with confidence {lastNameField.Confidence}");
}
}
}
}
}
}
FormField jobTitlesFields;
if (businessCard.Fields.TryGetValue("JobTitles", out jobTitlesFields)) {
if (jobTitlesFields.Value.ValueType == FieldValueType.List) {
foreach(FormField jobTitleField in jobTitlesFields.Value.AsList()) {
if (jobTitleField.Value.ValueType == FieldValueType.String) {
string jobTitle = jobTitleField.Value.AsString();
Console.WriteLine($ " Job Title: '{jobTitle}', with confidence {jobTitleField.Confidence}");
}
}
}
}
FormField departmentFields;
if (businessCard.Fields.TryGetValue("Departments", out departmentFields)) {
if (departmentFields.Value.ValueType == FieldValueType.List) {
foreach(FormField departmentField in departmentFields.Value.AsList()) {
if (departmentField.Value.ValueType == FieldValueType.String) {
string department = departmentField.Value.AsString();
Console.WriteLine($ " Department: '{department}', with confidence {departmentField.Confidence}");
}
}
}
}
FormField emailFields;
if (businessCard.Fields.TryGetValue("Emails", out emailFields)) {
if (emailFields.Value.ValueType == FieldValueType.List) {
foreach(FormField emailField in emailFields.Value.AsList()) {
if (emailField.Value.ValueType == FieldValueType.String) {
string email = emailField.Value.AsString();
Console.WriteLine($ " Email: '{email}', with confidence {emailField.Confidence}");
}
}
}
}
FormField websiteFields;
if (businessCard.Fields.TryGetValue("Websites", out websiteFields)) {
if (websiteFields.Value.ValueType == FieldValueType.List) {
foreach(FormField websiteField in websiteFields.Value.AsList()) {
if (websiteField.Value.ValueType == FieldValueType.String) {
string website = websiteField.Value.AsString();
Console.WriteLine($ " Website: '{website}', with confidence {websiteField.Confidence}");
}
}
}
}
FormField mobilePhonesFields;
if (businessCard.Fields.TryGetValue("MobilePhones", out mobilePhonesFields)) {
if (mobilePhonesFields.Value.ValueType == FieldValueType.List) {
foreach(FormField mobilePhoneField in mobilePhonesFields.Value.AsList()) {
if (mobilePhoneField.Value.ValueType == FieldValueType.PhoneNumber) {
string mobilePhone = mobilePhoneField.Value.AsPhoneNumber();
Console.WriteLine($ " Mobile phone number: '{mobilePhone}', with confidence {mobilePhoneField.Confidence}");
}
}
}
}
FormField otherPhonesFields;
if (businessCard.Fields.TryGetValue("OtherPhones", out otherPhonesFields)) {
if (otherPhonesFields.Value.ValueType == FieldValueType.List) {
foreach(FormField otherPhoneField in otherPhonesFields.Value.AsList()) {
if (otherPhoneField.Value.ValueType == FieldValueType.PhoneNumber) {
string otherPhone = otherPhoneField.Value.AsPhoneNumber();
Console.WriteLine($ " Other phone number: '{otherPhone}', with confidence {otherPhoneField.Confidence}");
}
}
}
}
FormField faxesFields;
if (businessCard.Fields.TryGetValue("Faxes", out faxesFields)) {
if (faxesFields.Value.ValueType == FieldValueType.List) {
foreach(FormField faxField in faxesFields.Value.AsList()) {
if (faxField.Value.ValueType == FieldValueType.PhoneNumber) {
string fax = faxField.Value.AsPhoneNumber();
Console.WriteLine($ " Fax phone number: '{fax}', with confidence {faxField.Confidence}");
}
}
}
}
FormField addressesFields;
if (businessCard.Fields.TryGetValue("Addresses", out addressesFields)) {
if (addressesFields.Value.ValueType == FieldValueType.List) {
foreach(FormField addressField in addressesFields.Value.AsList()) {
if (addressField.Value.ValueType == FieldValueType.String) {
string address = addressField.Value.AsString();
Console.WriteLine($ " Address: '{address}', with confidence {addressField.Confidence}");
}
}
}
}
FormField companyNamesFields;
if (businessCard.Fields.TryGetValue("CompanyNames", out companyNamesFields)) {
if (companyNamesFields.Value.ValueType == FieldValueType.List) {
foreach(FormField companyNameField in companyNamesFields.Value.AsList()) {
if (companyNameField.Value.ValueType == FieldValueType.String) {
string companyName = companyNameField.Value.AsString();
Console.WriteLine($ " Company name: '{companyName}', with confidence {companyNameField.Confidence}");
}
}
}
}
}
}
請求書を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、売上請求書から共通フィールドを分析、抽出する方法を示します。 請求書分析の詳細については、「Document Intelligence の請求書モデル」を参照してください。
URL から請求書を分析するには、StartRecognizeInvoicesFromUriAsync メソッドを使用します。
private static async Task AnalyzeInvoice(
FormRecognizerClient recognizerClient, string invoiceUrl) {
var options = new RecognizeInvoicesOptions() {
Locale = "en-US"
};
RecognizedFormCollection invoices = await recognizerClient.StartRecognizeInvoicesFromUriAsync(invoiceUrl, options).WaitForCompletionAsync();
ヒント
ローカルの請求書画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (StartRecognizeInvoices など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
次のコードでは、指定された URI にある請求書を処理し、主要なフィールドと値をコンソールに出力します。
RecognizedForm invoice = invoices.Single();
FormField invoiceIdField;
if (invoice.Fields.TryGetValue("InvoiceId", out invoiceIdField)) {
if (invoiceIdField.Value.ValueType == FieldValueType.String) {
string invoiceId = invoiceIdField.Value.AsString();
Console.WriteLine($ " Invoice Id: '{invoiceId}', with confidence {invoiceIdField.Confidence}");
}
}
FormField invoiceDateField;
if (invoice.Fields.TryGetValue("InvoiceDate", out invoiceDateField)) {
if (invoiceDateField.Value.ValueType == FieldValueType.Date) {
DateTime invoiceDate = invoiceDateField.Value.AsDate();
Console.WriteLine($ " Invoice Date: '{invoiceDate}', with confidence {invoiceDateField.Confidence}");
}
}
FormField dueDateField;
if (invoice.Fields.TryGetValue("DueDate", out dueDateField)) {
if (dueDateField.Value.ValueType == FieldValueType.Date) {
DateTime dueDate = dueDateField.Value.AsDate();
Console.WriteLine($ " Due Date: '{dueDate}', with confidence {dueDateField.Confidence}");
}
}
FormField vendorNameField;
if (invoice.Fields.TryGetValue("VendorName", out vendorNameField)) {
if (vendorNameField.Value.ValueType == FieldValueType.String) {
string vendorName = vendorNameField.Value.AsString();
Console.WriteLine($ " Vendor Name: '{vendorName}', with confidence {vendorNameField.Confidence}");
}
}
FormField vendorAddressField;
if (invoice.Fields.TryGetValue("VendorAddress", out vendorAddressField)) {
if (vendorAddressField.Value.ValueType == FieldValueType.String) {
string vendorAddress = vendorAddressField.Value.AsString();
Console.WriteLine($ " Vendor Address: '{vendorAddress}', with confidence {vendorAddressField.Confidence}");
}
}
FormField customerNameField;
if (invoice.Fields.TryGetValue("CustomerName", out customerNameField)) {
if (customerNameField.Value.ValueType == FieldValueType.String) {
string customerName = customerNameField.Value.AsString();
Console.WriteLine($ " Customer Name: '{customerName}', with confidence {customerNameField.Confidence}");
}
}
FormField customerAddressField;
if (invoice.Fields.TryGetValue("CustomerAddress", out customerAddressField)) {
if (customerAddressField.Value.ValueType == FieldValueType.String) {
string customerAddress = customerAddressField.Value.AsString();
Console.WriteLine($ " Customer Address: '{customerAddress}', with confidence {customerAddressField.Confidence}");
}
}
FormField customerAddressRecipientField;
if (invoice.Fields.TryGetValue("CustomerAddressRecipient", out customerAddressRecipientField)) {
if (customerAddressRecipientField.Value.ValueType == FieldValueType.String) {
string customerAddressRecipient = customerAddressRecipientField.Value.AsString();
Console.WriteLine($ " Customer address recipient: '{customerAddressRecipient}', with confidence {customerAddressRecipientField.Confidence}");
}
}
FormField invoiceTotalField;
if (invoice.Fields.TryGetValue("InvoiceTotal", out invoiceTotalField)) {
if (invoiceTotalField.Value.ValueType == FieldValueType.Float) {
float invoiceTotal = invoiceTotalField.Value.AsFloat();
Console.WriteLine($ " Invoice Total: '{invoiceTotal}', with confidence {invoiceTotalField.Confidence}");
}
}
}
身分証明書を分析する
このセクションでは、Document Intelligence の事前構築済み ID モデルを使用して、政府発行の身分証明書 (世界各国のパスポートと米国の運転免許証) から重要な情報を分析および抽出する方法を示します。 ID ドキュメント分析の詳細については、「Document Intelligence ID ドキュメント モデル」を参照してください。
URI から身分証明書を分析するには、StartRecognizeIdentityDocumentsFromUriAsync メソッドを使用します。
private static async Task AnalyzeId(
FormRecognizerClient recognizerClient, string idUrl) {
RecognizedFormCollection identityDocument = await recognizerClient.StartRecognizeIdDocumentsFromUriAsync(idUrl).WaitForCompletionAsync();
ヒント
ローカルにある身分証明書の画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (StartRecognizeIdentityDocumentsAsync など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
次のコードでは、指定された URI にある身分証明書を処理し、主要なフィールドと値をコンソールに出力します。
RecognizedForm identityDocument = identityDocuments.Single();
if (identityDocument.Fields.TryGetValue("Address", out FormField addressField)) {
if (addressField.Value.ValueType == FieldValueType.String) {
string address = addressField.Value.AsString();
Console.WriteLine($ "Address: '{address}', with confidence {addressField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("CountryRegion", out FormField countryRegionField)) {
if (countryRegionField.Value.ValueType == FieldValueType.CountryRegion) {
string countryRegion = countryRegionField.Value.AsCountryRegion();
Console.WriteLine($ "CountryRegion: '{countryRegion}', with confidence {countryRegionField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfBirth", out FormField dateOfBirthField)) {
if (dateOfBirthField.Value.ValueType == FieldValueType.Date) {
DateTime dateOfBirth = dateOfBirthField.Value.AsDate();
Console.WriteLine($ "Date Of Birth: '{dateOfBirth}', with confidence {dateOfBirthField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfExpiration", out FormField dateOfExpirationField)) {
if (dateOfExpirationField.Value.ValueType == FieldValueType.Date) {
DateTime dateOfExpiration = dateOfExpirationField.Value.AsDate();
Console.WriteLine($ "Date Of Expiration: '{dateOfExpiration}', with confidence {dateOfExpirationField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DocumentNumber", out FormField documentNumberField)) {
if (documentNumberField.Value.ValueType == FieldValueType.String) {
string documentNumber = documentNumberField.Value.AsString();
Console.WriteLine($ "Document Number: '{documentNumber}', with confidence {documentNumberField.Confidence}");
}
RecognizedForm identityDocument = identityDocuments.Single();
if (identityDocument.Fields.TryGetValue("Address", out FormField addressField)) {
if (addressField.Value.ValueType == FieldValueType.String) {
string address = addressField.Value.AsString();
Console.WriteLine($ "Address: '{address}', with confidence {addressField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("CountryRegion", out FormField countryRegionField)) {
if (countryRegionField.Value.ValueType == FieldValueType.CountryRegion) {
string countryRegion = countryRegionField.Value.AsCountryRegion();
Console.WriteLine($ "CountryRegion: '{countryRegion}', with confidence {countryRegionField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfBirth", out FormField dateOfBirthField)) {
if (dateOfBirthField.Value.ValueType == FieldValueType.Date) {
DateTime dateOfBirth = dateOfBirthField.Value.AsDate();
Console.WriteLine($ "Date Of Birth: '{dateOfBirth}', with confidence {dateOfBirthField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DateOfExpiration", out FormField dateOfExpirationField)) {
if (dateOfExpirationField.Value.ValueType == FieldValueType.Date) {
DateTime dateOfExpiration = dateOfExpirationField.Value.AsDate();
Console.WriteLine($ "Date Of Expiration: '{dateOfExpiration}', with confidence {dateOfExpirationField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("DocumentNumber", out FormField documentNumberField)) {
if (documentNumberField.Value.ValueType == FieldValueType.String) {
string documentNumber = documentNumberField.Value.AsString();
Console.WriteLine($ "Document Number: '{documentNumber}', with confidence {documentNumberField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("FirstName", out FormField firstNameField)) {
if (firstNameField.Value.ValueType == FieldValueType.String) {
string firstName = firstNameField.Value.AsString();
Console.WriteLine($ "First Name: '{firstName}', with confidence {firstNameField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("LastName", out FormField lastNameField)) {
if (lastNameField.Value.ValueType == FieldValueType.String) {
string lastName = lastNameField.Value.AsString();
Console.WriteLine($ "Last Name: '{lastName}', with confidence {lastNameField.Confidence}");
}
}
if (identityDocument.Fields.TryGetValue("Region", out FormField regionfield)) {
if (regionfield.Value.ValueType == FieldValueType.String) {
string region = regionfield.Value.AsString();
Console.WriteLine($ "Region: '{region}', with confidence {regionfield.Confidence}");
}
}
カスタム モデルをトレーニングする
このセクションでは、独自のデータを使用してモデルをトレーニングする方法を示します。 トレーニング済みのモデルは、元のフォーム ドキュメント内のキー/値の関係を含む構造化データを出力できます。 モデルをトレーニングした後、モデルをテスト、再トレーニングでき、最終的にはモデルを使用して、ニーズに従ってより多くのフォームから正確にデータを抽出できます。
Note
また、Document Intelligence のサンプル ラベル付けツールなどのグラフィカル ユーザー インターフェイスを使用してモデルをトレーニングすることもできます。
ラベルなしでモデルをトレーニングする
カスタム モデルをトレーニングして、トレーニング ドキュメントに手動でラベルを付けることなく、カスタム フォームにあるすべてのフィールドと値を分析できるようにします。 次のメソッドは、指定された一連のドキュメントでモデルをトレーニングし、モデルの状態をコンソールに出力します。
private static async Task<String> TrainModel(
FormTrainingClient trainingClient, string trainingDataUrl)
{
CustomFormModel model = await trainingClient
.StartTrainingAsync(new Uri(trainingDataUrl), useTrainingLabels: false)
.WaitForCompletionAsync();
Console.WriteLine($"Custom Model Info:");
Console.WriteLine($" Model Id: {model.ModelId}");
Console.WriteLine($" Model Status: {model.Status}");
Console.WriteLine($" Training model started on: {model.TrainingStartedOn}");
Console.WriteLine($" Training model completed on: {model.TrainingCompletedOn}");
返される CustomFormModel オブジェクトには、モデルが分析できるフォームの種類と、それぞれのフォームの種類から抽出できるフィールドに関する情報が含まれています。 次のコード ブロックは、この情報をコンソールに出力します。
foreach (CustomFormSubmodel submodel in model.Submodels)
{
Console.WriteLine($"Submodel Form Type: {submodel.FormType}");
foreach (CustomFormModelField field in submodel.Fields.Values)
{
Console.Write($" FieldName: {field.Name}");
if (field.Label != null)
{
Console.Write($", FieldLabel: {field.Label}");
}
Console.WriteLine("");
}
}
最後に、後の手順で使用するために、トレーニング済みモデルの ID を返します。
return model.ModelId;
}
この出力は、読みやすくするために一部が省略されています。
Merchant Name: 'Contoso Contoso', with confidence 0.516
Transaction Date: '6/10/2019 12:00:00 AM', with confidence 0.985
Item:
Name: '8GB RAM (Black)', with confidence 0.916
Total Price: '999', with confidence 0.559
Item:
Name: 'SurfacePen', with confidence 0.858
Total Price: '99.99', with confidence 0.386
Total: '1203.39', with confidence '0.774'
Form Page 1 has 18 lines.
Line 0 has 1 word, and text: 'Contoso'.
Line 1 has 1 word, and text: 'Address:'.
Line 2 has 3 words, and text: 'Invoice For: Microsoft'.
Line 3 has 4 words, and text: '1 Redmond way Suite'.
Line 4 has 3 words, and text: '1020 Enterprise Way'.
...
Table 0 has 2 rows and 6 columns.
Cell (0, 0) contains text: 'Invoice Number'.
Cell (0, 1) contains text: 'Invoice Date'.
Cell (0, 2) contains text: 'Invoice Due Date'.
Cell (0, 3) contains text: 'Charges'.
...
Custom Model Info:
Model Id: 95035721-f19d-40eb-8820-0c806b42798b
Model Status: Ready
Training model started on: 8/24/2020 6:36:44 PM +00:00
Training model completed on: 8/24/2020 6:36:50 PM +00:00
Submodel Form Type: form-95035721-f19d-40eb-8820-0c806b42798b
FieldName: CompanyAddress
FieldName: CompanyName
FieldName: CompanyPhoneNumber
...
Custom Model Info:
Model Id: e7a1181b-1fb7-40be-bfbe-1ee154183633
Model Status: Ready
Training model started on: 8/24/2020 6:36:44 PM +00:00
Training model completed on: 8/24/2020 6:36:52 PM +00:00
Submodel Form Type: form-0
FieldName: field-0, FieldLabel: Additional Notes:
FieldName: field-1, FieldLabel: Address:
FieldName: field-2, FieldLabel: Company Name:
FieldName: field-3, FieldLabel: Company Phone:
FieldName: field-4, FieldLabel: Dated As:
FieldName: field-5, FieldLabel: Details
FieldName: field-6, FieldLabel: Email:
FieldName: field-7, FieldLabel: Hero Limited
FieldName: field-8, FieldLabel: Name:
FieldName: field-9, FieldLabel: Phone:
...
ラベルを使用してモデルをトレーニングする
トレーニング ドキュメントに手動でラベルを付けて、カスタム モデルをトレーニングすることもできます。 ラベルを使用してトレーニングを行うと、一部のシナリオでパフォーマンスの向上につながります。 ラベルを使用してトレーニングするには、トレーニング ドキュメントと共に、BLOB ストレージ コンテナーに特別なラベル情報ファイル (<filename>.pdf.labels.json) を用意する必要があります。 Document Intelligence のサンプル ラベル付けツールでは、これらのラベル ファイルの作成を支援するユーザー インターフェイスが提供されています。 それらを用意できたら、uselabels パラメーターを true に設定して StartTrainingAsync メソッドを呼び出すことができます。
private static async Task<Guid> TrainModelWithLabelsAsync(
FormRecognizerClient trainingClient, string trainingDataUrl)
{
CustomFormModel model = await trainingClient
.StartTrainingAsync(new Uri(trainingDataUrl), useTrainingLabels: true)
.WaitForCompletionAsync();
Console.WriteLine($"Custom Model Info:");
Console.WriteLine($" Model Id: {model.ModelId}");
Console.WriteLine($" Model Status: {model.Status}");
Console.WriteLine($" Training model started on: {model.TrainingStartedOn}");
Console.WriteLine($" Training model completed on: {model.TrainingCompletedOn}");
返される CustomFormModel は、モデルが抽出できるフィールドを、各フィールドの予測精度と共に示します。 次のコード ブロックは、この情報をコンソールに出力します。
foreach (CustomFormSubmodel submodel in model.Submodels)
{
Console.WriteLine($"Submodel Form Type: {submodel.FormType}");
foreach (CustomFormModelField field in submodel.Fields.Values)
{
Console.Write($" FieldName: {field.Name}");
if (field.Label != null)
{
Console.Write($", FieldLabel: {field.Label}");
}
Console.WriteLine("");
}
}
return model.ModelId;
}
この出力は、読みやすくするために一部が省略されています。
Form Page 1 has 18 lines.
Line 0 has 1 word, and text: 'Contoso'.
Line 1 has 1 word, and text: 'Address:'.
Line 2 has 3 words, and text: 'Invoice For: Microsoft'.
Line 3 has 4 words, and text: '1 Redmond way Suite'.
Line 4 has 3 words, and text: '1020 Enterprise Way'.
Line 5 has 3 words, and text: '6000 Redmond, WA'.
...
Table 0 has 2 rows and 6 columns.
Cell (0, 0) contains text: 'Invoice Number'.
Cell (0, 1) contains text: 'Invoice Date'.
Cell (0, 2) contains text: 'Invoice Due Date'.
...
Merchant Name: 'Contoso Contoso', with confidence 0.516
Transaction Date: '6/10/2019 12:00:00 AM', with confidence 0.985
Item:
Name: '8GB RAM (Black)', with confidence 0.916
Total Price: '999', with confidence 0.559
Item:
Name: 'SurfacePen', with confidence 0.858
Total Price: '99.99', with confidence 0.386
Total: '1203.39', with confidence '0.774'
Custom Model Info:
Model Id: 63c013e3-1cab-43eb-84b0-f4b20cb9214c
Model Status: Ready
Training model started on: 8/24/2020 6:42:54 PM +00:00
Training model completed on: 8/24/2020 6:43:01 PM +00:00
Submodel Form Type: form-63c013e3-1cab-43eb-84b0-f4b20cb9214c
FieldName: CompanyAddress
FieldName: CompanyName
FieldName: CompanyPhoneNumber
FieldName: DatedAs
FieldName: Email
FieldName: Merchant
...
カスタム モデルを使用してフォームを分析する
このセクションでは、独自のフォームでトレーニングしたモデルを使用して、カスタムのテンプレートの種類からキー/値の情報やその他のコンテンツを抽出する方法について説明します。
重要
このシナリオを実装するには、モデルのトレーニングが完了している必要があります。それにより、次のメソッドにその ID を渡すことができます。
StartRecognizeCustomFormsFromUri メソッドを使用します。
// Analyze PDF form data
private static async Task AnalyzePdfForm(
FormRecognizerClient recognizerClient, String modelId, string formUrl)
{
RecognizedFormCollection forms = await recognizerClient
.StartRecognizeCustomFormsFromUri(modelId, new Uri(formUrl))
.WaitForCompletionAsync();
ヒント
ローカルのファイルを分析することもできます。 FormRecognizerClient のメソッドを参照してください (StartRecognizeCustomForms など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
返される値は、RecognizedForm オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 次のコードは、分析結果をコンソールに出力します。 認識された各フィールドと対応する値が、信頼度スコアと共に出力されます。
foreach (RecognizedForm form in forms)
{
Console.WriteLine($"Form of type: {form.FormType}");
foreach (FormField field in form.Fields.Values)
{
Console.WriteLine($"Field '{field.Name}: ");
if (field.LabelData != null)
{
Console.WriteLine($" Label: '{field.LabelData.Text}");
}
Console.WriteLine($" Value: '{field.ValueData.Text}");
Console.WriteLine($" Confidence: '{field.Confidence}");
}
Console.WriteLine("Table data:");
foreach (FormPage page in form.Pages)
{
for (int i = 0; i < page.Tables.Count; i++)
{
FormTable table = page.Tables[i];
Console.WriteLine($"Table {i} has {table.RowCount} rows and {table.ColumnCount} columns.");
foreach (FormTableCell cell in table.Cells)
{
Console.WriteLine($" Cell ({cell.RowIndex}, {cell.ColumnIndex}) contains {(cell.IsHeader ? "header" : "text")}: '{cell.Text}'");
}
}
}
}
}
この出力応答は、読みやすくするために一部が省略されています。
Custom Model Info:
Model Id: 9b0108ee-65c8-450e-b527-bb309d054fc4
Model Status: Ready
Training model started on: 8/24/2020 7:00:31 PM +00:00
Training model completed on: 8/24/2020 7:00:32 PM +00:00
Submodel Form Type: form-9b0108ee-65c8-450e-b527-bb309d054fc4
FieldName: CompanyAddress
FieldName: CompanyName
FieldName: CompanyPhoneNumber
...
Form Page 1 has 18 lines.
Line 0 has 1 word, and text: 'Contoso'.
Line 1 has 1 word, and text: 'Address:'.
Line 2 has 3 words, and text: 'Invoice For: Microsoft'.
Line 3 has 4 words, and text: '1 Redmond way Suite'.
...
Table 0 has 2 rows and 6 columns.
Cell (0, 0) contains text: 'Invoice Number'.
Cell (0, 1) contains text: 'Invoice Date'.
Cell (0, 2) contains text: 'Invoice Due Date'.
...
Merchant Name: 'Contoso Contoso', with confidence 0.516
Transaction Date: '6/10/2019 12:00:00 AM', with confidence 0.985
Item:
Name: '8GB RAM (Black)', with confidence 0.916
Total Price: '999', with confidence 0.559
Item:
Name: 'SurfacePen', with confidence 0.858
Total Price: '99.99', with confidence 0.386
Total: '1203.39', with confidence '0.774'
Custom Model Info:
Model Id: dc115156-ce0e-4202-bbe4-7426e7bee756
Model Status: Ready
Training model started on: 8/24/2020 7:00:31 PM +00:00
Training model completed on: 8/24/2020 7:00:41 PM +00:00
Submodel Form Type: form-0
FieldName: field-0, FieldLabel: Additional Notes:
FieldName: field-1, FieldLabel: Address:
FieldName: field-2, FieldLabel: Company Name:
FieldName: field-3, FieldLabel: Company Phone:
FieldName: field-4, FieldLabel: Dated As:
...
Form of type: custom:form
Field 'Azure.AI.FormRecognizer.Models.FieldValue:
Value: '$56,651.49
Confidence: '0.249
Field 'Azure.AI.FormRecognizer.Models.FieldValue:
Value: 'PT
Confidence: '0.245
Field 'Azure.AI.FormRecognizer.Models.FieldValue:
Value: '99243
Confidence: '0.114
...
カスタム モデルを管理する
このセクションでは、アカウントに格納されているカスタム モデルを管理する方法について説明します。 次のメソッド内で複数の操作を完了します。
private static async Task ManageModels(
FormTrainingClient trainingClient, string trainingFileUrl)
{
FormRecognizer リソース アカウント内のモデルの数を確認する
次のコード ブロックは、Document Intelligence アカウントに保存したモデルの数を確認し、アカウントの制限と比較します。
// Check number of models in the FormRecognizer account,
// and the maximum number of models that can be stored.
AccountProperties accountProperties = trainingClient.GetAccountProperties();
Console.WriteLine($"Account has {accountProperties.CustomModelCount} models.");
Console.WriteLine($"It can have at most {accountProperties.CustomModelLimit} models.");
出力
Account has 20 models.
It can have at most 5000 models.
リソース アカウントに現在格納されているモデルを一覧表示する
次のコード ブロックは、アカウント内の現在のモデルを一覧表示し、その詳細をコンソールに出力します。
Pageable<CustomFormModelInfo> models = trainingClient.GetCustomModels();
foreach (CustomFormModelInfo modelInfo in models)
{
Console.WriteLine($"Custom Model Info:");
Console.WriteLine($" Model Id: {modelInfo.ModelId}");
Console.WriteLine($" Model Status: {modelInfo.Status}");
Console.WriteLine($" Training model started on: {modelInfo.TrainingStartedOn}");
Console.WriteLine($" Training model completed on: {modelInfo.TrainingCompletedOn}");
}
この出力は、読みやすくするために一部が省略されています。
Custom Model Info:
Model Id: 05932d5a-a2f8-4030-a2ef-4e5ed7112515
Model Status: Creating
Training model started on: 8/24/2020 7:35:02 PM +00:00
Training model completed on: 8/24/2020 7:35:02 PM +00:00
Custom Model Info:
Model Id: 150828c4-2eb2-487e-a728-60d5d504bd16
Model Status: Ready
Training model started on: 8/24/2020 7:33:25 PM +00:00
Training model completed on: 8/24/2020 7:33:27 PM +00:00
Custom Model Info:
Model Id: 3303e9de-6cec-4dfb-9e68-36510a6ecbb2
Model Status: Ready
Training model started on: 8/24/2020 7:29:27 PM +00:00
Training model completed on: 8/24/2020 7:29:36 PM +00:00
モデルの ID を使用して特定のモデルを取得する
次のコード ブロックは、「ラベルなしでモデルをトレーニングする」セクションと同様に新しいモデルをトレーニングし、その後、新しいモデルの ID を使用して、それへの 2 番目の参照を取得します。
// Create a new model to store in the account
CustomFormModel model = await trainingClient.StartTrainingAsync(
new Uri(trainingFileUrl)).WaitForCompletionAsync();
// Get the model that was just created
CustomFormModel modelCopy = trainingClient.GetCustomModel(model.ModelId);
Console.WriteLine($"Custom Model {modelCopy.ModelId} recognizes the following form types:");
foreach (CustomFormSubmodel submodel in modelCopy.Submodels)
{
Console.WriteLine($"Submodel Form Type: {submodel.FormType}");
foreach (CustomFormModelField field in submodel.Fields.Values)
{
Console.Write($" FieldName: {field.Name}");
if (field.Label != null)
{
Console.Write($", FieldLabel: {field.Label}");
}
Console.WriteLine("");
}
}
この出力は、読みやすくするために一部が省略されています。
Custom Model Info:
Model Id: 150828c4-2eb2-487e-a728-60d5d504bd16
Model Status: Ready
Training model started on: 8/24/2020 7:33:25 PM +00:00
Training model completed on: 8/24/2020 7:33:27 PM +00:00
Submodel Form Type: form-150828c4-2eb2-487e-a728-60d5d504bd16
FieldName: CompanyAddress
FieldName: CompanyName
FieldName: CompanyPhoneNumber
FieldName: DatedAs
FieldName: Email
FieldName: Merchant
FieldName: PhoneNumber
FieldName: PurchaseOrderNumber
FieldName: Quantity
FieldName: Signature
FieldName: Subtotal
FieldName: Tax
FieldName: Total
FieldName: VendorName
FieldName: Website
...
リソース アカウントからモデルを削除する
ID を参照して、アカウントからモデルを削除することもできます。 この手順により、メソッドも終了します。
// Delete the model from the account.
trainingClient.DeleteModel(model.ModelId);
}
アプリケーションの実行
アプリケーション ディレクトリから dotnet run コマンドを使用してアプリケーションを実行します。
dotnet run
リソースをクリーンアップする
Azure AI サービス サブスクリプションをクリーンアップして削除したい場合は、リソースまたはリソース グループを削除することができます。 リソース グループを削除すると、それに関連付けられている他のリソースも削除されます。
トラブルシューティング
.NET SDK を使用して Azure AI Document Intelligence クライアント ライブラリを操作すると、サービスから返されたエラーによって RequestFailedException が発生します。 これには、REST API 要求が返すのと同じ HTTP 状態コードが含まれます。
たとえば、無効な URI を含む領収書の画像を送信すると、"Bad Request" (無効な要求) を示す 400 エラーが返されます。
try
{
RecognizedReceiptCollection receipts = await client.StartRecognizeReceiptsFromUri(new Uri(receiptUri)).WaitForCompletionAsync();
}
catch (RequestFailedException e)
{
Console.WriteLine(e.ToString());
}
操作のクライアント要求 ID などの追加情報がログに記録されます。
Message:
Azure.RequestFailedException: Service request failed.
Status: 400 (Bad Request)
Content:
{"error":{"code":"FailedToDownloadImage","innerError":
{"requestId":"8ca04feb-86db-4552-857c-fde903251518"},
"message":"Failed to download image from input URL."}}
Headers:
Transfer-Encoding: chunked
x-envoy-upstream-service-time: REDACTED
apim-request-id: REDACTED
Strict-Transport-Security: REDACTED
X-Content-Type-Options: REDACTED
Date: Mon, 20 Apr 2020 22:48:35 GMT
Content-Type: application/json; charset=utf-8
次のステップ
このプロジェクトでは、Document Intelligence .NET クライアント ライブラリを使用してモデルをトレーニングし、さまざまな方法でフォームを分析しました。 次に、より適切なトレーニング データ セットを作成し、より正確なモデルを生成するためのヒントについて学習します。
このプロジェクトのサンプル コードは、GitHub で入手できます。
重要
このプロジェクトは、ドキュメントインテリジェンス REST API バージョン 2.1 を対象としています。
リファレンスのドキュメント | ライブラリのソース コード | パッケージ (Maven) | サンプル
前提条件
Azure サブスクリプション。無料で作成できます。
最新バージョンの Java Development Kit (JDK)。
Gradle ビルド ツール、または別の依存関係マネージャー。
Document Intelligence リソース。 Free 価格レベル (
F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
トレーニング データのセットを含む Azure Storage Blob。 トレーニング データセットをまとめるためのヒントとオプションについては、「カスタム モデルを構築してトレーニング データする」を参照してください。 このプロジェクトでは、サンプル データセットの Train フォルダーにあるファイルを使用できます。 sample_data.zip をダウンロードして展開します。
プログラミング環境のセットアップ
プログラミング環境を設定するには、Gradle プロジェクトを作成し、クライアント ライブラリをインストールします。
新しい Gradle プロジェクトを作成する
コンソール ウィンドウで、アプリ用の新しいディレクトリを作成し、そのディレクトリに移動します。
mkdir myapp
cd myapp
作業ディレクトリから gradle init コマンドを実行します。 このコマンドによって、Gradle 用の重要なビルド ファイルが作成されます。たとえば、実行時にアプリケーションを作成して構成するために使用される build.gradle.kts などです。
gradle init --type basic
DSL を選択するよう求められたら、Kotlin を選択します。
クライアント ライブラリをインストールする
このプロジェクトでは、Gradle 依存関係マネージャーを使用します。 クライアント ライブラリとその他の依存関係マネージャーの情報については、Maven Central Repository を参照してください。
プロジェクトの build.gradle.kts ファイルに、必要なプラグインと設定と共に、クライアント ライブラリを implementation ステートメントとして含めます。
plugins {
java
application
}
application {
mainClass.set("FormRecognizer")
}
repositories {
mavenCentral()
}
dependencies {
implementation(group = "com.azure", name = "azure-ai-formrecognizer", version = "3.1.1")
}
Java ファイルを作成する
作業ディレクトリから、次のコマンドを実行します。
mkdir -p src/main/java
新しいフォルダーに移動し、FormRecognizer.java という名前のファイルを作成します。 それをエディターまたは IDE で開き、以下の import ステートメントを追加します。
import com.azure.ai.formrecognizer.*;
import com.azure.ai.formrecognizer.training.*;
import com.azure.ai.formrecognizer.models.*;
import com.azure.ai.formrecognizer.training.models.*;
import java.util.concurrent.atomic.AtomicReference;
import java.util.List;
import java.util.Map;
import java.time.LocalDate;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.http.rest.PagedIterable;
import com.azure.core.util.Context;
import com.azure.core.util.polling.SyncPoller;
アプリケーションの FormRecognizer クラスで、対象のリソースのキーとエンドポイントの変数を作成します。
static final String key = "PASTE_YOUR_FORM_RECOGNIZER_SUBSCRIPTION_KEY_HERE";
static final String endpoint = "PASTE_YOUR_FORM_RECOGNIZER_ENDPOINT_HERE";
重要
Azure Portal にアクセスします。 「前提条件」 セクションで作成した Document Intelligence リソースが正常にデプロイされた場合、[次の手順] の下にある [リソースに移動] ボタンをクリックします。 キーとエンドポイントは、[キーとエンドポイント] ページの [リソース管理] にあります。
終わったらコードからキーを必ず削除してください。 決して公開しないよう注意してください。 運用環境では、セキュリティで保護された方法を使用して資格情報を格納し、アクセスします。 詳しくは、「Azure AI サービスのセキュリティ」をご覧ください。
アプリケーションの main メソッドで、このプロジェクトで使用するメソッドの呼び出しを追加します。 これらの呼び出しは後で定義します。 また、トレーニングとテスト データの URL への参照を追加する必要もあります。
カスタム モデルのトレーニング データの SAS URL を取得するには、Azure portal のストレージ リソースに移動し、[データ ストレージ]>[コンテナー] を選択します。
ご自分のコンテナーに移動し、右クリックして [SAS の生成] を選択します。
ストレージ アカウント自体ではなく、ご自分のコンテナー用の SAS を取得することが重要です。
[読み取り]、[書き込み]、[削除]、[リスト] の各アクセス許可が選択されていることを確認し、[SAS トークンと URL の生成] を選択します。
URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。
テストするフォームの URL を取得するには、上記の手順を使用して、BLOB ストレージ内の個々のドキュメントの SAS URL を取得できます。 または、別の場所にあるドキュメントの URL を取得します。
上記のメソッドを使用して、領収書の画像の URL も取得します。
String trainingDataUrl = "PASTE_YOUR_SAS_URL_OF_YOUR_FORM_FOLDER_IN_BLOB_STORAGE_HERE";
String formUrl = "PASTE_YOUR_FORM_RECOGNIZER_FORM_URL_HERE";
String receiptUrl = "https://docs.microsoft.com/azure/cognitive-services/form-recognizer/media" + "/contoso-allinone.jpg";
String bcUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/samples/sample_forms/business_cards/business-card-english.jpg";
String invoiceUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/samples/sample_forms/forms/Invoice_1.pdf";
String idUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/id-license.jpg"
// Call Form Recognizer scenarios:
System.out.println("Get form content...");
GetContent(recognizerClient, formUrl);
System.out.println("Analyze receipt...");
AnalyzeReceipt(recognizerClient, receiptUrl);
System.out.println("Analyze business card...");
AnalyzeBusinessCard(recognizerClient, bcUrl);
System.out.println("Analyze invoice...");
AnalyzeInvoice(recognizerClient, invoiceUrl);
System.out.println("Analyze id...");
AnalyzeId(recognizerClient, idUrl);
System.out.println("Train Model with training data...");
String modelId = TrainModel(trainingClient, trainingDataUrl);
System.out.println("Analyze PDF form...");
AnalyzePdfForm(recognizerClient, modelId, formUrl);
System.out.println("Manage models...");
ManageModels(trainingClient, trainingDataUrl);
オブジェクト モデルを使用する
Document Intelligence で作成できるクライアントは 2 種類あります。 1 つ目の FormRecognizerClient はサービスに対しクエリを実行しフォーム フィールドとコンテンツを認識します。 もう 1 つは FormTrainingClient であり、認識精度を高めるためのカスタム モデルを作成および管理します。
FormRecognizerClient では、次のタスクの操作について説明します。
- 対象のカスタム フォームを分析するようトレーニングされたカスタム モデルを使用して、フォームのフィールドやコンテンツを認識する。 これらの値は、
RecognizedFormオブジェクトのコレクションとして返されます。 「カスタム フォームを分析する」を参照してください。 - モデルをトレーニングせずにフォームのコンテンツ (表、行、単語など) を認識する。 フォームのコンテンツは、
FormPageオブジェクトのコレクションとして返されます。 「レイアウトを分析する」を参照してください。 - Document Intelligence サービスの事前トレーニング済みのモデルを使用して、米国の領収書、名刺、請求書、および身分証明書から一般的なフィールドを認識する。
FormTrainingClient には、以下を目的とした操作が用意されています。
- カスタム モデルをトレーニングして、対象のカスタム フォームにあるすべてのフィールドと値を分析する。 モデルによって分析されるフォームの種類とそれぞれのフォームの種類で抽出されるフィールドを示す
CustomFormModelが返されます。 - 対象のカスタム フォームにラベル付けすることによって指定した特定のフィールドと値を分析するように、カスタム モデルをトレーニングする。 モデルによって抽出されるフィールドと各フィールドの推定精度を示す
CustomFormModelが返されます。 - アカウントに作成されたモデルを管理する。
- Document Intelligence リソース間でカスタム モデルをコピーする。
Note
モデルのトレーニングは、サンプル ラベル付けツールなどのグラフィカル ユーザー インターフェイスを使用して行うこともできます。
クライアントを認証する
main メソッドの先頭に、次のコードを追加します。 先ほど定義したサブスクリプション変数を使用して 2 つのクライアント オブジェクトを認証します。 新しいクライアント オブジェクトを作成せずに、必要に応じてキーを更新できるように、AzureKeyCredential オブジェクトを使用します。
FormRecognizerClient recognizerClient = new FormRecognizerClientBuilder()
.credential(new AzureKeyCredential(key)).endpoint(endpoint).buildClient();
FormTrainingClient trainingClient = new FormTrainingClientBuilder().credential(new AzureKeyCredential(key))
.endpoint(endpoint).buildClient();
レイアウトを分析する
Document Intelligence を使用すると、ドキュメント内の表、行、および単語を分析できます。モデルをトレーニングする必要はありません。 レイアウト抽出の詳細については、「Document Intelligence レイアウト モデル」を参照してください。
指定された URL にあるファイルの内容を分析するには、beginRecognizeContentFromUrl メソッドを使用します。
private static void GetContent(FormRecognizerClient recognizerClient, String invoiceUri) {
String analyzeFilePath = invoiceUri;
SyncPoller<FormRecognizerOperationResult, List<FormPage>> recognizeContentPoller = recognizerClient
.beginRecognizeContentFromUrl(analyzeFilePath);
List<FormPage> contentResult = recognizeContentPoller.getFinalResult();
ヒント
また、ローカルのファイルから内容を取得することもできます。 FormRecognizerClient のメソッドを参照してください (beginRecognizeContent など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
返される値は、FormPage オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 次のコードでは、これらのオブジェクトを反復処理し、抽出されたキー/値のペアとテーブル データを出力します。
contentResult.forEach(formPage -> {
// Table information
System.out.println("----Recognizing content ----");
System.out.printf("Has width: %f and height: %f, measured with unit: %s.%n", formPage.getWidth(),
formPage.getHeight(), formPage.getUnit());
formPage.getTables().forEach(formTable -> {
System.out.printf("Table has %d rows and %d columns.%n", formTable.getRowCount(),
formTable.getColumnCount());
formTable.getCells().forEach(formTableCell -> {
System.out.printf("Cell has text %s.%n", formTableCell.getText());
});
System.out.println();
});
});
}
結果は次の出力のようになります。
Get form content...
----Recognizing content ----
Has width: 8.500000 and height: 11.000000, measured with unit: inch.
Table has 2 rows and 6 columns.
Cell has text Invoice Number.
Cell has text Invoice Date.
Cell has text Invoice Due Date.
Cell has text Charges.
Cell has text VAT ID.
Cell has text 458176.
Cell has text 3/28/2018.
Cell has text 4/16/2018.
Cell has text $89,024.34.
Cell has text ET.
領収書を分析する
このセクションでは、事前トレーニング済みの領収書モデルを使用して、米国の領収書から共通フィールドを分析、抽出する方法を示します。 領収書分析の詳細については、「Document Intelligence 領収書モデル」を参照してください。
URI からレシートを分析するには、beginRecognizeReceiptsFromUrl メソッドを使用します。
private static void AnalyzeReceipt(FormRecognizerClient recognizerClient, String receiptUri) {
SyncPoller<FormRecognizerOperationResult, List<RecognizedForm>> syncPoller = recognizerClient
.beginRecognizeReceiptsFromUrl(receiptUri);
List<RecognizedForm> receiptPageResults = syncPoller.getFinalResult();
ヒント
ローカルにあるレシートの画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (beginRecognizeReceipts など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
返される値は、RecognizedReceipt オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 次のコード ブロックは、領収書を反復処理し、その詳細をコンソールに出力します。
for (int i = 0; i < receiptPageResults.size(); i++) {
RecognizedForm recognizedForm = receiptPageResults.get(i);
Map<String, FormField> recognizedFields = recognizedForm.getFields();
System.out.printf("----------- Recognized Receipt page %d -----------%n", i);
FormField merchantNameField = recognizedFields.get("MerchantName");
if (merchantNameField != null) {
if (FieldValueType.STRING == merchantNameField.getValue().getValueType()) {
String merchantName = merchantNameField.getValue().asString();
System.out.printf("Merchant Name: %s, confidence: %.2f%n", merchantName,
merchantNameField.getConfidence());
}
}
FormField merchantAddressField = recognizedFields.get("MerchantAddress");
if (merchantAddressField != null) {
if (FieldValueType.STRING == merchantAddressField.getValue().getValueType()) {
String merchantAddress = merchantAddressField.getValue().asString();
System.out.printf("Merchant Address: %s, confidence: %.2f%n", merchantAddress,
merchantAddressField.getConfidence());
}
}
FormField transactionDateField = recognizedFields.get("TransactionDate");
if (transactionDateField != null) {
if (FieldValueType.DATE == transactionDateField.getValue().getValueType()) {
LocalDate transactionDate = transactionDateField.getValue().asDate();
System.out.printf("Transaction Date: %s, confidence: %.2f%n", transactionDate,
transactionDateField.getConfidence());
}
}
次のコード ブロックは、領収書で検出された個々の項目を反復処理し、その詳細をコンソールに出力します。
FormField receiptItemsField = recognizedFields.get("Items");
if (receiptItemsField != null) {
System.out.printf("Receipt Items: %n");
if (FieldValueType.LIST == receiptItemsField.getValue().getValueType()) {
List<FormField> receiptItems = receiptItemsField.getValue().asList();
receiptItems.stream()
.filter(receiptItem -> FieldValueType.MAP == receiptItem.getValue().getValueType())
.map(formField -> formField.getValue().asMap())
.forEach(formFieldMap -> formFieldMap.forEach((key, formField) -> {
if ("Name".equals(key)) {
if (FieldValueType.STRING == formField.getValue().getValueType()) {
String name = formField.getValue().asString();
System.out.printf("Name: %s, confidence: %.2fs%n", name,
formField.getConfidence());
}
}
if ("Quantity".equals(key)) {
if (FieldValueType.FLOAT == formField.getValue().getValueType()) {
Float quantity = formField.getValue().asFloat();
System.out.printf("Quantity: %f, confidence: %.2f%n", quantity,
formField.getConfidence());
}
}
if ("Price".equals(key)) {
if (FieldValueType.FLOAT == formField.getValue().getValueType()) {
Float price = formField.getValue().asFloat();
System.out.printf("Price: %f, confidence: %.2f%n", price,
formField.getConfidence());
}
}
if ("TotalPrice".equals(key)) {
if (FieldValueType.FLOAT == formField.getValue().getValueType()) {
Float totalPrice = formField.getValue().asFloat();
System.out.printf("Total Price: %f, confidence: %.2f%n", totalPrice,
formField.getConfidence());
}
}
}));
}
}
}
}
結果は次の出力のようになります。
Analyze receipt...
----------- Recognized Receipt page 0 -----------
Merchant Name: Contoso Contoso, confidence: 0.62
Merchant Address: 123 Main Street Redmond, WA 98052, confidence: 0.99
Transaction Date: 2020-06-10, confidence: 0.90
Receipt Items:
Name: Cappuccino, confidence: 0.96s
Quantity: null, confidence: 0.957s]
Total Price: 2.200000, confidence: 0.95
Name: BACON & EGGS, confidence: 0.94s
Quantity: null, confidence: 0.927s]
Total Price: null, confidence: 0.93
名刺を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、英語の名刺から共通フィールドを分析、抽出する方法を示します。 名刺分析の詳細については、「Document Intelligence 名刺モデル」を参照してください。
URL から名刺を分析するには、beginRecognizeBusinessCardsFromUrl メソッドを使用します。
private static void AnalyzeBusinessCard(FormRecognizerClient recognizerClient, String bcUrl) {
SyncPoller < FormRecognizerOperationResult,
List < RecognizedForm >> recognizeBusinessCardPoller = client.beginRecognizeBusinessCardsFromUrl(businessCardUrl);
List < RecognizedForm > businessCardPageResults = recognizeBusinessCardPoller.getFinalResult();
ヒント
ローカルにある名刺の画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (beginRecognizeBusinessCards など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
返される値は、RecognizedForm オブジェクトのコレクションです。 ドキュメント内のカードごとに 1 つのオブジェクトがあります。 次のコードでは、指定された URI にある名刺を処理し、主要なフィールドと値をコンソールに出力します。
for (int i = 0; i < businessCardPageResults.size(); i++) {
RecognizedForm recognizedForm = businessCardPageResults.get(i);
Map < String,
FormField > recognizedFields = recognizedForm.getFields();
System.out.printf("----------- Recognized business card info for page %d -----------%n", i);
FormField contactNamesFormField = recognizedFields.get("ContactNames");
if (contactNamesFormField != null) {
if (FieldValueType.LIST == contactNamesFormField.getValue().getValueType()) {
List < FormField > contactNamesList = contactNamesFormField.getValue().asList();
contactNamesList.stream().filter(contactName - >FieldValueType.MAP == contactName.getValue().getValueType()).map(contactName - >{
System.out.printf("Contact name: %s%n", contactName.getValueData().getText());
return contactName.getValue().asMap();
}).forEach(contactNamesMap - >contactNamesMap.forEach((key, contactName) - >{
if ("FirstName".equals(key)) {
if (FieldValueType.STRING == contactName.getValue().getValueType()) {
String firstName = contactName.getValue().asString();
System.out.printf("\tFirst Name: %s, confidence: %.2f%n", firstName, contactName.getConfidence());
}
}
if ("LastName".equals(key)) {
if (FieldValueType.STRING == contactName.getValue().getValueType()) {
String lastName = contactName.getValue().asString();
System.out.printf("\tLast Name: %s, confidence: %.2f%n", lastName, contactName.getConfidence());
}
}
}));
}
}
FormField jobTitles = recognizedFields.get("JobTitles");
if (jobTitles != null) {
if (FieldValueType.LIST == jobTitles.getValue().getValueType()) {
List < FormField > jobTitlesItems = jobTitles.getValue().asList();
jobTitlesItems.stream().forEach(jobTitlesItem - >{
if (FieldValueType.STRING == jobTitlesItem.getValue().getValueType()) {
String jobTitle = jobTitlesItem.getValue().asString();
System.out.printf("Job Title: %s, confidence: %.2f%n", jobTitle, jobTitlesItem.getConfidence());
}
});
}
}
FormField departments = recognizedFields.get("Departments");
if (departments != null) {
if (FieldValueType.LIST == departments.getValue().getValueType()) {
List < FormField > departmentsItems = departments.getValue().asList();
departmentsItems.stream().forEach(departmentsItem - >{
if (FieldValueType.STRING == departmentsItem.getValue().getValueType()) {
String department = departmentsItem.getValue().asString();
System.out.printf("Department: %s, confidence: %.2f%n", department, departmentsItem.getConfidence());
}
});
}
}
FormField emails = recognizedFields.get("Emails");
if (emails != null) {
if (FieldValueType.LIST == emails.getValue().getValueType()) {
List < FormField > emailsItems = emails.getValue().asList();
emailsItems.stream().forEach(emailsItem - >{
if (FieldValueType.STRING == emailsItem.getValue().getValueType()) {
String email = emailsItem.getValue().asString();
System.out.printf("Email: %s, confidence: %.2f%n", email, emailsItem.getConfidence());
}
});
}
}
FormField websites = recognizedFields.get("Websites");
if (websites != null) {
if (FieldValueType.LIST == websites.getValue().getValueType()) {
List < FormField > websitesItems = websites.getValue().asList();
websitesItems.stream().forEach(websitesItem - >{
if (FieldValueType.STRING == websitesItem.getValue().getValueType()) {
String website = websitesItem.getValue().asString();
System.out.printf("Web site: %s, confidence: %.2f%n", website, websitesItem.getConfidence());
}
});
}
}
FormField mobilePhones = recognizedFields.get("MobilePhones");
if (mobilePhones != null) {
if (FieldValueType.LIST == mobilePhones.getValue().getValueType()) {
List < FormField > mobilePhonesItems = mobilePhones.getValue().asList();
mobilePhonesItems.stream().forEach(mobilePhonesItem - >{
if (FieldValueType.PHONE_NUMBER == mobilePhonesItem.getValue().getValueType()) {
String mobilePhoneNumber = mobilePhonesItem.getValue().asPhoneNumber();
System.out.printf("Mobile phone number: %s, confidence: %.2f%n", mobilePhoneNumber, mobilePhonesItem.getConfidence());
}
});
}
}
FormField otherPhones = recognizedFields.get("OtherPhones");
if (otherPhones != null) {
if (FieldValueType.LIST == otherPhones.getValue().getValueType()) {
List < FormField > otherPhonesItems = otherPhones.getValue().asList();
otherPhonesItems.stream().forEach(otherPhonesItem - >{
if (FieldValueType.PHONE_NUMBER == otherPhonesItem.getValue().getValueType()) {
String otherPhoneNumber = otherPhonesItem.getValue().asPhoneNumber();
System.out.printf("Other phone number: %s, confidence: %.2f%n", otherPhoneNumber, otherPhonesItem.getConfidence());
}
});
}
}
FormField faxes = recognizedFields.get("Faxes");
if (faxes != null) {
if (FieldValueType.LIST == faxes.getValue().getValueType()) {
List < FormField > faxesItems = faxes.getValue().asList();
faxesItems.stream().forEach(faxesItem - >{
if (FieldValueType.PHONE_NUMBER == faxesItem.getValue().getValueType()) {
String faxPhoneNumber = faxesItem.getValue().asPhoneNumber();
System.out.printf("Fax phone number: %s, confidence: %.2f%n", faxPhoneNumber, faxesItem.getConfidence());
}
});
}
}
FormField addresses = recognizedFields.get("Addresses");
if (addresses != null) {
if (FieldValueType.LIST == addresses.getValue().getValueType()) {
List < FormField > addressesItems = addresses.getValue().asList();
addressesItems.stream().forEach(addressesItem - >{
if (FieldValueType.STRING == addressesItem.getValue().getValueType()) {
String address = addressesItem.getValue().asString();
System.out.printf("Address: %s, confidence: %.2f%n", address, addressesItem.getConfidence());
}
});
}
}
FormField companyName = recognizedFields.get("CompanyNames");
if (companyName != null) {
if (FieldValueType.LIST == companyName.getValue().getValueType()) {
List < FormField > companyNameItems = companyName.getValue().asList();
companyNameItems.stream().forEach(companyNameItem - >{
if (FieldValueType.STRING == companyNameItem.getValue().getValueType()) {
String companyNameValue = companyNameItem.getValue().asString();
System.out.printf("Company name: %s, confidence: %.2f%n", companyNameValue, companyNameItem.getConfidence());
}
});
}
}
}
}
請求書を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、売上請求書から共通フィールドを分析、抽出する方法を示します。 請求書分析の詳細については、「Document Intelligence の請求書モデル」を参照してください。
URL から請求書を分析するには、beginRecognizeInvoicesFromUrl メソッドを使用します。
private static void AnalyzeInvoice(FormRecognizerClient recognizerClient, String invoiceUrl) {
SyncPoller < FormRecognizerOperationResult,
List < RecognizedForm >> recognizeInvoicesPoller = client.beginRecognizeInvoicesFromUrl(invoiceUrl);
List < RecognizedForm > recognizedInvoices = recognizeInvoicesPoller.getFinalResult();
ヒント
ローカルの請求書を分析することもできます。 FormRecognizerClient のメソッドを参照してください (beginRecognizeInvoices など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
返される値は、RecognizedForm オブジェクトのコレクションです。 ドキュメント内の請求書ごとに 1 つのオブジェクトがあります。 次のコードでは、指定された URI にある請求書を処理し、主要なフィールドと値をコンソールに出力します。
for (int i = 0; i < recognizedInvoices.size(); i++) {
RecognizedForm recognizedInvoice = recognizedInvoices.get(i);
Map < String,
FormField > recognizedFields = recognizedInvoice.getFields();
System.out.printf("----------- Recognized invoice info for page %d -----------%n", i);
FormField vendorNameField = recognizedFields.get("VendorName");
if (vendorNameField != null) {
if (FieldValueType.STRING == vendorNameField.getValue().getValueType()) {
String merchantName = vendorNameField.getValue().asString();
System.out.printf("Vendor Name: %s, confidence: %.2f%n", merchantName, vendorNameField.getConfidence());
}
}
FormField vendorAddressField = recognizedFields.get("VendorAddress");
if (vendorAddressField != null) {
if (FieldValueType.STRING == vendorAddressField.getValue().getValueType()) {
String merchantAddress = vendorAddressField.getValue().asString();
System.out.printf("Vendor address: %s, confidence: %.2f%n", merchantAddress, vendorAddressField.getConfidence());
}
}
FormField customerNameField = recognizedFields.get("CustomerName");
if (customerNameField != null) {
if (FieldValueType.STRING == customerNameField.getValue().getValueType()) {
String merchantAddress = customerNameField.getValue().asString();
System.out.printf("Customer Name: %s, confidence: %.2f%n", merchantAddress, customerNameField.getConfidence());
}
}
FormField customerAddressRecipientField = recognizedFields.get("CustomerAddressRecipient");
if (customerAddressRecipientField != null) {
if (FieldValueType.STRING == customerAddressRecipientField.getValue().getValueType()) {
String customerAddr = customerAddressRecipientField.getValue().asString();
System.out.printf("Customer Address Recipient: %s, confidence: %.2f%n", customerAddr, customerAddressRecipientField.getConfidence());
}
}
FormField invoiceIdField = recognizedFields.get("InvoiceId");
if (invoiceIdField != null) {
if (FieldValueType.STRING == invoiceIdField.getValue().getValueType()) {
String invoiceId = invoiceIdField.getValue().asString();
System.out.printf("Invoice Id: %s, confidence: %.2f%n", invoiceId, invoiceIdField.getConfidence());
}
}
FormField invoiceDateField = recognizedFields.get("InvoiceDate");
if (customerNameField != null) {
if (FieldValueType.DATE == invoiceDateField.getValue().getValueType()) {
LocalDate invoiceDate = invoiceDateField.getValue().asDate();
System.out.printf("Invoice Date: %s, confidence: %.2f%n", invoiceDate, invoiceDateField.getConfidence());
}
}
FormField invoiceTotalField = recognizedFields.get("InvoiceTotal");
if (customerAddressRecipientField != null) {
if (FieldValueType.FLOAT == invoiceTotalField.getValue().getValueType()) {
Float invoiceTotal = invoiceTotalField.getValue().asFloat();
System.out.printf("Invoice Total: %.2f, confidence: %.2f%n", invoiceTotal, invoiceTotalField.getConfidence());
}
}
}
}
身分証明書を分析する
このセクションでは、Document Intelligence の事前構築済み ID モデルを使用して、政府発行の身分証明書 (世界各国のパスポートと米国の運転免許証) から重要な情報を分析および抽出する方法を示します。 ID ドキュメント分析の詳細については、「Document Intelligence ID ドキュメント モデル」を参照してください。
URI から身分証明書を分析するには、beginRecognizeIdentityDocumentsFromUrl メソッドを使用します。
private static void AnalyzeId(FormRecognizerClient client, String idUrl) {
SyncPoller < FormRecognizerOperationResult,
List < RecognizedForm >> analyzeIdentityDocumentPoller = client.beginRecognizeIdentityDocumentsFromUrl(licenseDocumentUrl);
List < RecognizedForm > identityDocumentResults = analyzeIdentityDocumentPoller.getFinalResult();
ヒント
ローカルにある身分証明書の画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (beginRecognizeIdentityDocuments など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
次のコードでは、指定された URI にある身分証明書を処理し、主要なフィールドと値をコンソールに出力します。
for (int i = 0; i < identityDocumentResults.size(); i++) {
RecognizedForm recognizedForm = identityDocumentResults.get(i);
Map < String,
FormField > recognizedFields = recognizedForm.getFields();
System.out.printf("----------- Recognized license info for page %d -----------%n", i);
FormField addressField = recognizedFields.get("Address");
if (addressField != null) {
if (FieldValueType.STRING == addressField.getValue().getValueType()) {
String address = addressField.getValue().asString();
System.out.printf("Address: %s, confidence: %.2f%n", address, addressField.getConfidence());
}
}
FormField countryRegionFormField = recognizedFields.get("CountryRegion");
if (countryRegionFormField != null) {
if (FieldValueType.STRING == countryRegionFormField.getValue().getValueType()) {
String countryRegion = countryRegionFormField.getValue().asCountryRegion();
System.out.printf("Country or region: %s, confidence: %.2f%n", countryRegion, countryRegionFormField.getConfidence());
}
}
FormField dateOfBirthField = recognizedFields.get("DateOfBirth");
if (dateOfBirthField != null) {
if (FieldValueType.DATE == dateOfBirthField.getValue().getValueType()) {
LocalDate dateOfBirth = dateOfBirthField.getValue().asDate();
System.out.printf("Date of Birth: %s, confidence: %.2f%n", dateOfBirth, dateOfBirthField.getConfidence());
}
}
FormField dateOfExpirationField = recognizedFields.get("DateOfExpiration");
if (dateOfExpirationField != null) {
if (FieldValueType.DATE == dateOfExpirationField.getValue().getValueType()) {
LocalDate expirationDate = dateOfExpirationField.getValue().asDate();
System.out.printf("Document date of expiration: %s, confidence: %.2f%n", expirationDate, dateOfExpirationField.getConfidence());
}
}
FormField documentNumberField = recognizedFields.get("DocumentNumber");
if (documentNumberField != null) {
if (FieldValueType.STRING == documentNumberField.getValue().getValueType()) {
String documentNumber = documentNumberField.getValue().asString();
System.out.printf("Document number: %s, confidence: %.2f%n", documentNumber, documentNumberField.getConfidence());
}
}
FormField firstNameField = recognizedFields.get("FirstName");
if (firstNameField != null) {
if (FieldValueType.STRING == firstNameField.getValue().getValueType()) {
String firstName = firstNameField.getValue().asString();
System.out.printf("First Name: %s, confidence: %.2f%n", firstName, documentNumberField.getConfidence());
}
}
FormField lastNameField = recognizedFields.get("LastName");
if (lastNameField != null) {
if (FieldValueType.STRING == lastNameField.getValue().getValueType()) {
String lastName = lastNameField.getValue().asString();
System.out.printf("Last name: %s, confidence: %.2f%n", lastName, lastNameField.getConfidence());
}
}
FormField regionField = recognizedFields.get("Region");
if (regionField != null) {
if (FieldValueType.STRING == regionField.getValue().getValueType()) {
String region = regionField.getValue().asString();
System.out.printf("Region: %s, confidence: %.2f%n", region, regionField.getConfidence());
}
}
}
カスタム モデルをトレーニングする
このセクションでは、独自のデータを使用してモデルをトレーニングする方法を示します。 トレーニング済みのモデルは、元のフォーム ドキュメント内のキー/値の関係を含む構造化データを出力できます。 モデルをトレーニングした後、モデルをテスト、再トレーニングでき、最終的にはモデルを使用して、ニーズに従ってより多くのフォームから正確にデータを抽出できます。
Note
また、Document Intelligence のサンプル ラベル付けツールなどのグラフィカル ユーザー インターフェイスを使用してモデルをトレーニングすることもできます。
ラベルなしでモデルをトレーニングする
カスタム モデルをトレーニングして、トレーニング ドキュメントに手動でラベルを付けることなく、カスタム フォームにあるすべてのフィールドと値を分析できるようにします。
次のメソッドは、指定された一連のドキュメントでモデルをトレーニングし、モデルの状態をコンソールに出力します。
private static String TrainModel(FormTrainingClient trainingClient, String trainingDataUrl) {
SyncPoller<FormRecognizerOperationResult, CustomFormModel> trainingPoller = trainingClient
.beginTraining(trainingDataUrl, false);
CustomFormModel customFormModel = trainingPoller.getFinalResult();
// Model Info
System.out.printf("Model Id: %s%n", customFormModel.getModelId());
System.out.printf("Model Status: %s%n", customFormModel.getModelStatus());
System.out.printf("Training started on: %s%n", customFormModel.getTrainingStartedOn());
System.out.printf("Training completed on: %s%n%n", customFormModel.getTrainingCompletedOn());
返される CustomFormModel オブジェクトには、モデルが分析できるフォームの種類と、それぞれのフォームの種類から抽出できるフィールドに関する情報が含まれています。 次のコード ブロックは、この情報をコンソールに出力します。
System.out.println("Recognized Fields:");
// looping through the subModels, which contains the fields they were trained on
// Since the given training documents are unlabeled, we still group them but
// they do not have a label.
customFormModel.getSubmodels().forEach(customFormSubmodel -> {
// Since the training data is unlabeled, we are unable to return the accuracy of
// this model
System.out.printf("The subModel has form type %s%n", customFormSubmodel.getFormType());
customFormSubmodel.getFields().forEach((field, customFormModelField) -> System.out
.printf("The model found field '%s' with label: %s%n", field, customFormModelField.getLabel()));
});
最後に、このメソッドはモデルの一意の ID を返します。
return customFormModel.getModelId();
}
結果は次の出力のようになります。
Train Model with training data...
Model Id: 20c3544d-97b4-49d9-b39b-dc32d85f1358
Model Status: ready
Training started on: 2020-08-31T16:52:09Z
Training completed on: 2020-08-31T16:52:23Z
Recognized Fields:
The subModel has form type form-0
The model found field 'field-0' with label: Address:
The model found field 'field-1' with label: Charges
The model found field 'field-2' with label: Invoice Date
The model found field 'field-3' with label: Invoice Due Date
The model found field 'field-4' with label: Invoice For:
The model found field 'field-5' with label: Invoice Number
The model found field 'field-6' with label: VAT ID
ラベルを使用してモデルをトレーニングする
トレーニング ドキュメントに手動でラベルを付けて、カスタム モデルをトレーニングすることもできます。 ラベルを使用してトレーニングを行うと、一部のシナリオでパフォーマンスの向上につながります。 ラベルを使用してトレーニングするには、トレーニング ドキュメントと共に、BLOB ストレージ コンテナーに特別なラベル情報ファイル (<filename>.pdf.labels.json) を用意する必要があります。 Document Intelligence のサンプル ラベル付けツールでは、これらのラベル ファイルの作成を支援するユーザー インターフェイスが提供されています。 それらを用意できたら、useTrainingLabels パラメーターを true に設定して beginTraining メソッドを呼び出すことができます。
private static String TrainModelWithLabels(FormTrainingClient trainingClient, String trainingDataUrl) {
// Train custom model
String trainingSetSource = trainingDataUrl;
SyncPoller<FormRecognizerOperationResult, CustomFormModel> trainingPoller = trainingClient
.beginTraining(trainingSetSource, true);
CustomFormModel customFormModel = trainingPoller.getFinalResult();
// Model Info
System.out.printf("Model Id: %s%n", customFormModel.getModelId());
System.out.printf("Model Status: %s%n", customFormModel.getModelStatus());
System.out.printf("Training started on: %s%n", customFormModel.getTrainingStartedOn());
System.out.printf("Training completed on: %s%n%n", customFormModel.getTrainingCompletedOn());
返される CustomFormModel は、モデルが抽出できるフィールドを、各フィールドの予測精度と共に示します。 次のコード ブロックは、この情報をコンソールに出力します。
// looping through the subModels, which contains the fields they were trained on
// The labels are based on the ones you gave the training document.
System.out.println("Recognized Fields:");
// Since the data is labeled, we are able to return the accuracy of the model
customFormModel.getSubmodels().forEach(customFormSubmodel -> {
System.out.printf("The subModel with form type %s has accuracy: %.2f%n", customFormSubmodel.getFormType(),
customFormSubmodel.getAccuracy());
customFormSubmodel.getFields()
.forEach((label, customFormModelField) -> System.out.printf(
"The model found field '%s' to have name: %s with an accuracy: %.2f%n", label,
customFormModelField.getName(), customFormModelField.getAccuracy()));
});
return customFormModel.getModelId();
}
結果は次の出力のようになります。
Train Model with training data...
Model Id: 20c3544d-97b4-49d9-b39b-dc32d85f1358
Model Status: ready
Training started on: 2020-08-31T16:52:09Z
Training completed on: 2020-08-31T16:52:23Z
Recognized Fields:
The subModel has form type form-0
The model found field 'field-0' with label: Address:
The model found field 'field-1' with label: Charges
The model found field 'field-2' with label: Invoice Date
The model found field 'field-3' with label: Invoice Due Date
The model found field 'field-4' with label: Invoice For:
The model found field 'field-5' with label: Invoice Number
The model found field 'field-6' with label: VAT ID
カスタム モデルを使用してフォームを分析する
このセクションでは、独自のフォームでトレーニングしたモデルを使用して、カスタムのテンプレートの種類からキー/値の情報やその他のコンテンツを抽出する方法について説明します。
重要
このシナリオを実装するには、モデルのトレーニングが完了している必要があります。それにより、メソッド操作にその ID を渡すことができます。 「ラベルを使用してモデルをトレーニングする」を参照してください。
beginRecognizeCustomFormsFromUrl メソッドを使用します。
// Analyze PDF form data
private static void AnalyzePdfForm(FormRecognizerClient formClient, String modelId, String pdfFormUrl) {
SyncPoller<FormRecognizerOperationResult, List<RecognizedForm>> recognizeFormPoller = formClient
.beginRecognizeCustomFormsFromUrl(modelId, pdfFormUrl);
List<RecognizedForm> recognizedForms = recognizeFormPoller.getFinalResult();
ヒント
ローカルのファイルを分析することもできます。 FormRecognizerClient のメソッドを参照してください (beginRecognizeCustomForms など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
返される値は、RecognizedForm オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 次のコードは、分析結果をコンソールに出力します。 認識された各フィールドと対応する値が、信頼度スコアと共に出力されます。
for (int i = 0; i < recognizedForms.size(); i++) {
final RecognizedForm form = recognizedForms.get(i);
System.out.printf("----------- Recognized custom form info for page %d -----------%n", i);
System.out.printf("Form type: %s%n", form.getFormType());
form.getFields().forEach((label, formField) ->
// label data is populated if you are using a model trained with unlabeled data,
// since the service needs to make predictions for labels if not explicitly
// given to it.
System.out.printf("Field '%s' has label '%s' with a confidence " + "score of %.2f.%n", label,
formField.getLabelData().getText(), formField.getConfidence()));
}
}
結果は次の出力のようになります。
Analyze PDF form...
----------- Recognized custom template info for page 0 -----------
Form type: form-0
Field 'field-0' has label 'Address:' with a confidence score of 0.91.
Field 'field-1' has label 'Invoice For:' with a confidence score of 1.00.
Field 'field-2' has label 'Invoice Number' with a confidence score of 1.00.
Field 'field-3' has label 'Invoice Date' with a confidence score of 1.00.
Field 'field-4' has label 'Invoice Due Date' with a confidence score of 1.00.
Field 'field-5' has label 'Charges' with a confidence score of 1.00.
Field 'field-6' has label 'VAT ID' with a confidence score of 1.00.
カスタム モデルを管理する
このセクションでは、アカウントに格納されているカスタム モデルを管理する方法について説明します。 次のコードは、例として、1 つのメソッドですべてのモデル管理タスクを実行します。 まず、次のメソッド シグネチャをコピーします。
private static void ManageModels(FormTrainingClient trainingClient, String trainingFileUrl) {
FormRecognizer リソース アカウント内のモデルの数を確認する
次のコード ブロックは、Document Intelligence アカウントに保存したモデルの数を確認し、アカウントの制限と比較します。
AtomicReference<String> modelId = new AtomicReference<>();
// First, we see how many custom models we have, and what our limit is
AccountProperties accountProperties = trainingClient.getAccountProperties();
System.out.printf("The account has %s custom models, and we can have at most %s custom models",
accountProperties.getCustomModelCount(), accountProperties.getCustomModelLimit());
結果は次の出力のようになります。
The account has 12 custom models, and we can have at most 250 custom models
リソース アカウントに現在格納されているモデルを一覧表示する
次のコード ブロックは、アカウント内の現在のモデルを一覧表示し、その詳細をコンソールに出力します。
// Next, we get a paged list of all of our custom models
PagedIterable<CustomFormModelInfo> customModels = trainingClient.listCustomModels();
System.out.println("We have following models in the account:");
customModels.forEach(customFormModelInfo -> {
System.out.printf("Model Id: %s%n", customFormModelInfo.getModelId());
// get custom model info
modelId.set(customFormModelInfo.getModelId());
CustomFormModel customModel = trainingClient.getCustomModel(customFormModelInfo.getModelId());
System.out.printf("Model Id: %s%n", customModel.getModelId());
System.out.printf("Model Status: %s%n", customModel.getModelStatus());
System.out.printf("Training started on: %s%n", customModel.getTrainingStartedOn());
System.out.printf("Training completed on: %s%n", customModel.getTrainingCompletedOn());
customModel.getSubmodels().forEach(customFormSubmodel -> {
System.out.printf("Custom Model Form type: %s%n", customFormSubmodel.getFormType());
System.out.printf("Custom Model Accuracy: %.2f%n", customFormSubmodel.getAccuracy());
if (customFormSubmodel.getFields() != null) {
customFormSubmodel.getFields().forEach((fieldText, customFormModelField) -> {
System.out.printf("Field Text: %s%n", fieldText);
System.out.printf("Field Accuracy: %.2f%n", customFormModelField.getAccuracy());
});
}
});
});
結果は次の出力のようになります。
この応答は、読みやすくするために一部が省略されています。
We have following models in the account:
Model Id: 0b048b60-86cc-47ec-9782-ad0ffaf7a5ce
Model Id: 0b048b60-86cc-47ec-9782-ad0ffaf7a5ce
Model Status: ready
Training started on: 2020-06-04T18:33:08Z
Training completed on: 2020-06-04T18:33:10Z
Custom Model Form type: form-0b048b60-86cc-47ec-9782-ad0ffaf7a5ce
Custom Model Accuracy: 1.00
Field Text: invoice date
Field Accuracy: 1.00
Field Text: invoice number
Field Accuracy: 1.00
...
リソース アカウントからモデルを削除する
ID を参照して、アカウントからモデルを削除することもできます。
// Delete Custom Model
System.out.printf("Deleted model with model Id: %s, operation completed with status: %s%n", modelId.get(),
trainingClient.deleteModelWithResponse(modelId.get(), Context.NONE).getStatusCode());
}
アプリケーションの実行
メイン プロジェクト ディレクトリに戻ります。 次に、次のコマンドを使用してアプリをビルドします。
gradle build
run ゴールを使用してアプリケーションを実行します。
gradle run
リソースをクリーンアップする
Azure AI サービス サブスクリプションをクリーンアップして削除したい場合は、リソースまたはリソース グループを削除することができます。 リソース グループを削除すると、それに関連付けられている他のリソースも削除されます。
トラブルシューティング
Document Intelligence クライアントでは ErrorResponseException 例外が発生します。 たとえば、無効なファイル ソースの URL を指定しようとすると、失敗の原因を示すエラーと共に ErrorResponseException が発生します。 次のコード スニペットでは、例外をキャッチし、エラーに関する追加情報を表示することで、エラーが適切に処理されます。
try {
formRecognizerClient.beginRecognizeContentFromUrl("invalidSourceUrl");
} catch (ErrorResponseException e) {
System.out.println(e.getMessage());
}
クライアントのログ記録を有効にする
Java 用の Azure SDK では、アプリケーション エラーをトラブルシューティングしてその解決を促進するために、一貫したログ記録が提供されます。 生成されたログにより、最終状態に達する前のアプリケーションのフローが取得され、根本原因を特定するのに役立ちます。 ログを有効にする方法の詳細については、ログの Wiki を参照してください。
次のステップ
このプロジェクトでは、Document Intelligence Java クライアント ライブラリを使用してモデルをトレーニングし、さまざまな方法でフォームを分析しました。 次に、より適切なトレーニング データ セットを作成し、より正確なモデルを生成するためのヒントについて学習します。
このプロジェクトのサンプル コードについては、 GitHub を参照してください。
重要
このプロジェクトは、ドキュメントインテリジェンス REST API バージョン 2.1 を対象としています。
リファレンスのドキュメント | ライブラリのソース コード | パッケージ (npm) | サンプル
前提条件
Azure サブスクリプション。無料で作成できます。
最新バージョンの Visual Studio Code。
最新 LTS バージョンの Node.js。
トレーニング データのセットを含む Azure Storage Blob。 トレーニング データセットをまとめるためのヒントとオプションについては、「カスタム モデルを構築してトレーニング データする」を参照してください。 このプロジェクトでは、サンプル データ セットの Train フォルダーにあるファイルを使用できます。 sample_data.zip をダウンロードして展開します。
Azure AI サービスまたは Document Intelligence リソース。 Document Intelligence リソースを作成する。 Free 価格レベル (
F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
プログラミング環境のセットアップ
アプリケーションを作成し、クライアント ライブラリをインストールします。
新しい Node.js アプリケーションを作成する
コンソール ウィンドウで、アプリの新しいディレクトリを作成し、そのディレクトリに移動します。
mkdir myapp cd myapp次に、
npm initコマンドを実行し、package.json ファイルを使用してノード アプリケーションを作成します。npm init
クライアント ライブラリをインストールする
ai-form-recognizernpm パッケージをインストールします。npm install @azure/ai-form-recognizerアプリの package.json ファイルはこの依存関係について更新されます。
index.js という名前のファイルを作成し、次のライブラリをインポートします。
const { FormRecognizerClient, FormTrainingClient, AzureKeyCredential } = require("@azure/ai-form-recognizer"); const fs = require("fs");自分のリソースの Azure エンドポイントおよびキー用の変数を作成します。
const apiKey = "PASTE_YOUR_FORM_RECOGNIZER_SUBSCRIPTION_KEY_HERE"; const endpoint = "PASTE_YOUR_FORM_RECOGNIZER_ENDPOINT_HERE";
重要
Azure Portal にアクセスします。 「前提条件」 セクションで作成した Document Intelligence リソースが正常にデプロイされた場合、[次の手順] の下にある [リソースに移動] ボタンをクリックします。 キーとエンドポイントは、[キーとエンドポイント] ページの [リソース管理] にあります。
終わったらコードからキーを必ず削除してください。 決して公開しないよう注意してください。 運用環境では、セキュリティで保護された方法を使用して資格情報を格納し、アクセスします。 詳しくは、「Azure AI サービスのセキュリティ」をご覧ください。
オブジェクト モデルを使用する
Document Intelligence で作成できるクライアントは 2 種類あります。 1 つ目の FormRecognizerClient はサービスに対しクエリを実行しフォーム フィールドとコンテンツを認識します。 もう 1 つは FormTrainingClient であり、認識精度を高めるためのカスタム モデルを作成および管理します。
FormRecognizerClient を使用すると、次の処理を実行できます。
- 対象のカスタム フォームを分析するようトレーニングされたカスタム モデルを使用して、フォームのフィールドやコンテンツを認識する。 これらの値は、
RecognizedFormオブジェクトのコレクションとして返されます。 - モデルをトレーニングせずにフォームのコンテンツ (表、行、単語など) を認識する。 フォームのコンテンツは、
FormPageオブジェクトのコレクションとして返されます。 - Document Intelligence サービスの事前トレーニング済みのモデルを使用して、米国の領収書、名刺、請求書、および身分証明書から一般的なフィールドを認識する。
FormTrainingClient には、以下を目的とした操作が用意されています。
- カスタム モデルをトレーニングして、対象のカスタム フォームにあるすべてのフィールドと値を分析する。 モデルによって分析されるフォームの種類とそれぞれのフォームの種類で抽出されるフィールドを示す
CustomFormModelが返されます。 詳細については、ラベル付けなしのモデル トレーニングに関するサービスのドキュメントを参照してください。 - 対象のカスタム フォームにラベル付けすることによって指定した特定のフィールドと値を分析するように、カスタム モデルをトレーニングする。 モデルによって抽出されるフィールドと各フィールドの推定精度を示す
CustomFormModelが返されます。 詳細については、この記事内の「ラベルを使用してモデルをトレーニングする」を参照してください。 - アカウントに作成されたモデルを管理する。
- Document Intelligence リソース間でカスタム モデルをコピーする。
Note
モデルのトレーニングは、サンプル ラベル付けツールなどのグラフィカル ユーザー インターフェイスを使用して行うこともできます。
クライアントを認証する
定義したサブスクリプション変数を使用してクライアント オブジェクトを認証します。 新しいクライアント オブジェクトを作成せずに、必要に応じてキーを更新できるように、AzureKeyCredential オブジェクトを使用します。 また、トレーニング クライアント オブジェクトも作成します。
const trainingClient = new FormTrainingClient(endpoint, new AzureKeyCredential(apiKey));
const client = new FormRecognizerClient(endpoint, new AzureKeyCredential(apiKey));
テスト用のアセットを取得する
また、トレーニングとテスト データの URL への参照を追加する必要もあります。
カスタム モデルのトレーニング データの SAS URL を取得するには、Azure portal のストレージ リソースに移動し、[データ ストレージ]>[コンテナー] を選択します。
ご自分のコンテナーに移動し、右クリックして [SAS の生成] を選択します。
ストレージ アカウント自体ではなく、ご自分のコンテナー用の SAS を取得することが重要です。
[読み取り]、[書き込み]、[削除]、[リスト] の各アクセス許可が選択されていることを確認し、[SAS トークンと URL の生成] を選択します。
URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。
サンプルに含まれるフォームや領収書のサンプル画像を使用します。 これらは GitHubからも入手できます。 前述の手順を使用して、Blob Storage 内の個々のドキュメントの SAS URL を取得できます。
レイアウトを分析する
Document Intelligence を使用すると、ドキュメント内の表、行、および単語を分析できます。モデルをトレーニングする必要はありません。 レイアウト抽出の詳細については、「Document Intelligence レイアウト モデル」を参照してください。 指定された URI にあるファイルの内容を分析するには、beginRecognizeContentFromUrl メソッドを使用します。
async function recognizeContent() {
const formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/simple-invoice.png";
const poller = await client.beginRecognizeContentFromUrl(formUrl);
const pages = await poller.pollUntilDone();
if (!pages || pages.length === 0) {
throw new Error("Expecting non-empty list of pages!");
}
for (const page of pages) {
console.log(
`Page ${page.pageNumber}: width ${page.width} and height ${page.height} with unit ${page.unit}`
);
for (const table of page.tables) {
for (const cell of table.cells) {
console.log(`cell [${cell.rowIndex},${cell.columnIndex}] has text ${cell.text}`);
}
}
}
}
recognizeContent().catch((err) => {
console.error("The sample encountered an error:", err);
});
ヒント
beginRecognizeContent などの FormRecognizerClient メソッドを使用して、ローカル ファイルからコンテンツを取得することもできます。
Page 1: width 8.5 and height 11 with unit inch
cell [0,0] has text Invoice Number
cell [0,1] has text Invoice Date
cell [0,2] has text Invoice Due Date
cell [0,3] has text Charges
cell [0,5] has text VAT ID
cell [1,0] has text 34278587
cell [1,1] has text 6/18/2017
cell [1,2] has text 6/24/2017
cell [1,3] has text $56,651.49
cell [1,5] has text PT
領収書を分析する
このセクションでは、事前トレーニング済みの領収書モデルを使用して、米国のレシートから共通フィールドを分析、抽出する方法を示します。 領収書分析の詳細については、「Document Intelligence 領収書モデル」を参照してください。
URI からレシートを分析するには、beginRecognizeReceiptsFromUrl メソッドを使用します。 次のコードは、指定された URI で領収書を処理し、主要なフィールドと値をコンソールに出力します。
async function recognizeReceipt() {
receiptUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/tests/sample_forms/receipt/contoso-receipt.png";
const poller = await client.beginRecognizeReceiptsFromUrl(receiptUrl, {
onProgress: (state) => { console.log(`status: ${state.status}`); }
});
const receipts = await poller.pollUntilDone();
if (!receipts || receipts.length <= 0) {
throw new Error("Expecting at lease one receipt in analysis result");
}
const receipt = receipts[0];
console.log("First receipt:");
const receiptTypeField = receipt.fields["ReceiptType"];
if (receiptTypeField.valueType === "string") {
console.log(` Receipt Type: '${receiptTypeField.value || "<missing>"}', with confidence of ${receiptTypeField.confidence}`);
}
const merchantNameField = receipt.fields["MerchantName"];
if (merchantNameField.valueType === "string") {
console.log(` Merchant Name: '${merchantNameField.value || "<missing>"}', with confidence of ${merchantNameField.confidence}`);
}
const transactionDate = receipt.fields["TransactionDate"];
if (transactionDate.valueType === "date") {
console.log(` Transaction Date: '${transactionDate.value || "<missing>"}', with confidence of ${transactionDate.confidence}`);
}
const itemsField = receipt.fields["Items"];
if (itemsField.valueType === "array") {
for (const itemField of itemsField.value || []) {
if (itemField.valueType === "object") {
const itemNameField = itemField.value["Name"];
if (itemNameField.valueType === "string") {
console.log(` Item Name: '${itemNameField.value || "<missing>"}', with confidence of ${itemNameField.confidence}`);
}
}
}
}
const totalField = receipt.fields["Total"];
if (totalField.valueType === "number") {
console.log(` Total: '${totalField.value || "<missing>"}', with confidence of ${totalField.confidence}`);
}
}
recognizeReceipt().catch((err) => {
console.error("The sample encountered an error:", err);
});
ヒント
beginRecognizeReceipts などの FormRecognizerClient メソッドを使用して、ローカルにある領収書の画像を分析することもできます。
status: notStarted
status: running
status: succeeded
First receipt:
Receipt Type: 'Itemized', with confidence of 0.659
Merchant Name: 'Contoso Contoso', with confidence of 0.516
Transaction Date: 'Sun Jun 09 2019 17:00:00 GMT-0700 (Pacific Daylight Time)', with confidence of 0.985
Item Name: '8GB RAM (Black)', with confidence of 0.916
Item Name: 'SurfacePen', with confidence of 0.858
Total: '1203.39', with confidence of 0.774
名刺を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、英語の名刺から一般的なフィールドを分析、抽出する方法を示します。 名刺分析の詳細については、「Document Intelligence 名刺モデル」を参照してください。
URL から名刺を分析するには、beginRecognizeBusinessCardsFromURL メソッドを使用します。
async function recognizeBusinessCards() {
bcUrl = "https://github.com/Azure-Samples/cognitive-services-REST-api-samples/curl/form-recognizer/businessCard.png";
const poller = await client.beginRecognizeBusinessCardsFromUrl(bcUrl, {
onProgress: (state) => {
console.log(`status: ${state.status}`);
}
});
const [businessCard] = await poller.pollUntilDone();
if (businessCard === undefined) {
throw new Error("Failed to extract data from at least one business card.");
}
const contactNames = businessCard.fields["ContactNames"].value;
if (Array.isArray(contactNames)) {
console.log("- Contact Names:");
for (const contactName of contactNames) {
if (contactName.valueType === "object") {
const firstName = contactName.value?.["FirstName"].value ?? "<no first name>";
const lastName = contactName.value?.["LastName"].value ?? "<no last name>";
console.log(` - ${firstName} ${lastName} (${contactName.confidence} confidence)`);
}
}
}
printSimpleArrayField(businessCard, "CompanyNames");
printSimpleArrayField(businessCard, "Departments");
printSimpleArrayField(businessCard, "JobTitles");
printSimpleArrayField(businessCard, "Emails");
printSimpleArrayField(businessCard, "Websites");
printSimpleArrayField(businessCard, "Addresses");
printSimpleArrayField(businessCard, "MobilePhones");
printSimpleArrayField(businessCard, "Faxes");
printSimpleArrayField(businessCard, "WorkPhones");
printSimpleArrayField(businessCard, "OtherPhones");
}
// Helper function to print array field values.
function printSimpleArrayField(businessCard, fieldName) {
const fieldValues = businessCard.fields[fieldName]?.value;
if (Array.isArray(fieldValues)) {
console.log(`- ${fieldName}:`);
for (const item of fieldValues) {
console.log(` - ${item.value ?? "<no value>"} (${item.confidence} confidence)`);
}
} else if (fieldValues === undefined) {
console.log(`No ${fieldName} were found in the document.`);
} else {
console.error(
`Error: expected field "${fieldName}" to be an Array, but it was a(n) ${businessCard.fields[fieldName].valueType}`
);
}
}
recognizeBusinessCards().catch((err) => {
console.error("The sample encountered an error:", err);
});
ヒント
beginRecognizeBusinessCards などの FormRecognizerClient メソッドを使用して、ローカルにある名刺の画像を分析することもできます。
請求書を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、売上請求書から共通フィールドを分析、抽出する方法を示します。 請求書分析の詳細については、「Document Intelligence の請求書モデル」を参照してください。
URL から請求書を分析するには、beginRecognizeInvoicesFromUrl メソッドを使用します。
async function recognizeInvoices() {
invoiceUrl = "https://github.com/Azure-Samples/cognitive-services-REST-api-samples/curl/form-recognizer/invoice_sample.jpg";
const poller = await client.beginRecognizeInvoicesFromUrl(invoiceUrl, {
onProgress: (state) => {
console.log(`status: ${state.status}`);
}
});
const [invoice] = await poller.pollUntilDone();
if (invoice === undefined) {
throw new Error("Failed to extract data from at least one invoice.");
}
// Helper function to print fields.
function fieldToString(field) {
const {
name,
valueType,
value,
confidence
} = field;
return `${name} (${valueType}): '${value}' with confidence ${confidence}'`;
}
console.log("Invoice fields:");
for (const [name, field] of Object.entries(invoice.fields)) {
if (field.valueType !== "array" && field.valueType !== "object") {
console.log(`- ${name} ${fieldToString(field)}`);
}
}
let idx = 0;
console.log("- Items:");
const items = invoice.fields["Items"]?.value;
for (const item of items ?? []) {
const value = item.value;
const subFields = [
"Description",
"Quantity",
"Unit",
"UnitPrice",
"ProductCode",
"Date",
"Tax",
"Amount"
]
.map((fieldName) => value[fieldName])
.filter((field) => field !== undefined);
console.log(
[
` - Item #${idx}`,
// Now we will convert those fields into strings to display
...subFields.map((field) => ` - ${fieldToString(field)}`)
].join("\n")
);
}
}
recognizeInvoices().catch((err) => {
console.error("The sample encountered an error:", err);
});
ヒント
beginRecognizeInvoices などの FormRecognizerClient メソッドを使用して、ローカルにある領収書の画像を分析することもできます。
身分証明書を分析する
このセクションでは、Document Intelligence の事前構築済み ID モデルを使用して、政府発行の身分証明書 (世界各国のパスポートと米国の運転免許証を含む) から重要な情報を分析および抽出する方法を示します。 ID ドキュメント分析の詳細については、「Document Intelligence ID ドキュメント モデル」を参照してください。
URL から身分証明書を分析するには、beginRecognizeIdDocumentsFromUrl メソッドを使用します。
async function recognizeIdDocuments() {
idUrl = "https://github.com/Azure-Samples/cognitive-services-REST-api-samples/curl/form-recognizer/id-license.jpg";
const poller = await client.beginRecognizeIdDocumentsFromUrl(idUrl, {
onProgress: (state) => {
console.log(`status: ${state.status}`);
}
});
const [idDocument] = await poller.pollUntilDone();
if (idDocument === undefined) {
throw new Error("Failed to extract data from at least one identity document.");
}
console.log("Document Type:", idDocument.formType);
console.log("Identity Document Fields:");
function printField(fieldName) {
// Fields are extracted from the `fields` property of the document result
const field = idDocument.fields[fieldName];
console.log(
`- ${fieldName} (${field?.valueType}): '${field?.value ?? "<missing>"}', with confidence ${field?.confidence
}`
);
}
printField("FirstName");
printField("LastName");
printField("DocumentNumber");
printField("DateOfBirth");
printField("DateOfExpiration");
printField("Sex");
printField("Address");
printField("Country");
printField("Region");
}
recognizeIdDocuments().catch((err) => {
console.error("The sample encountered an error:", err);
});
カスタム モデルをトレーニングする
このセクションでは、独自のデータを使用してモデルをトレーニングする方法を示します。 トレーニング済みのモデルは、元のフォーム ドキュメント内のキー/値の関係を含む構造化データを出力できます。 モデルをトレーニングした後、モデルをテスト、再トレーニングでき、最終的にはモデルを使用して、ニーズに従ってより多くのフォームから正確にデータを抽出できます。
Note
また、Document Intelligence Sample Labeling ツール などのグラフィカル ユーザー インターフェイス (GUI) を使用してモデルをトレーニングすることもできます。
ラベルなしでモデルをトレーニングする
カスタム モデルをトレーニングして、トレーニング ドキュメントに手動でラベルを付けることなく、カスタム フォームにあるすべてのフィールドと値を分析できるようにします。
次の関数は、指定された一連のドキュメントでモデルをトレーニングし、モデルの状態をコンソールに出力します。
async function trainModel() {
const containerSasUrl = "<SAS-URL-of-your-form-folder-in-blob-storage>";
const poller = await trainingClient.beginTraining(containerSasUrl, false, {
onProgress: (state) => { console.log(`training status: ${state.status}`); }
});
const model = await poller.pollUntilDone();
if (!model) {
throw new Error("Expecting valid training result!");
}
console.log(`Model ID: ${model.modelId}`);
console.log(`Status: ${model.status}`);
console.log(`Training started on: ${model.trainingStartedOn}`);
console.log(`Training completed on: ${model.trainingCompletedOn}`);
if (model.submodels) {
for (const submodel of model.submodels) {
// since the training data is unlabeled, we are unable to return the accuracy of this model
console.log("We have recognized the following fields");
for (const key in submodel.fields) {
const field = submodel.fields[key];
console.log(`The model found field '${field.name}'`);
}
}
}
// Training document information
if (model.trainingDocuments) {
for (const doc of model.trainingDocuments) {
console.log(`Document name: ${doc.name}`);
console.log(`Document status: ${doc.status}`);
console.log(`Document page count: ${doc.pageCount}`);
console.log(`Document errors: ${doc.errors}`);
}
}
}
trainModel().catch((err) => {
console.error("The sample encountered an error:", err);
});
これは、JavaScript SDK から入手できるトレーニング データを使用してトレーニングされたモデルの出力です。 このサンプル結果は、読みやすくするために一部が省略されています。
training status: creating
training status: ready
Model ID: 9d893595-1690-4cf2-a4b1-fbac0fb11909
Status: ready
Training started on: Thu Aug 20 2020 20:27:26 GMT-0700 (Pacific Daylight Time)
Training completed on: Thu Aug 20 2020 20:27:37 GMT-0700 (Pacific Daylight Time)
We have recognized the following fields
The model found field 'field-0'
The model found field 'field-1'
The model found field 'field-2'
The model found field 'field-3'
The model found field 'field-4'
The model found field 'field-5'
The model found field 'field-6'
The model found field 'field-7'
...
Document name: Form_1.jpg
Document status: succeeded
Document page count: 1
Document errors:
Document name: Form_2.jpg
Document status: succeeded
Document page count: 1
Document errors:
Document name: Form_3.jpg
Document status: succeeded
Document page count: 1
Document errors:
...
ラベルを使用してモデルをトレーニングする
トレーニング ドキュメントに手動でラベルを付けて、カスタム モデルをトレーニングすることもできます。 ラベルを使用してトレーニングを行うと、一部のシナリオでパフォーマンスの向上につながります。 ラベルを使用してトレーニングするには、トレーニング ドキュメントと共に、BLOB ストレージ コンテナーに特別なラベル情報ファイル (<filename>.pdf.labels.json) を用意する必要があります。 Document Intelligence のサンプル ラベル付けツールでは、これらのラベル ファイルの作成を支援する UI が提供されています。 それらを用意できたら、uselabels パラメーターを true に設定して beginTraining メソッドを呼び出すことができます。
async function trainModelLabels() {
const containerSasUrl = "<SAS-URL-of-your-form-folder-in-blob-storage>";
const poller = await trainingClient.beginTraining(containerSasUrl, true, {
onProgress: (state) => { console.log(`training status: ${state.status}`); }
});
const model = await poller.pollUntilDone();
if (!model) {
throw new Error("Expecting valid training result!");
}
console.log(`Model ID: ${model.modelId}`);
console.log(`Status: ${model.status}`);
console.log(`Training started on: ${model.trainingStartedOn}`);
console.log(`Training completed on: ${model.trainingCompletedOn}`);
if (model.submodels) {
for (const submodel of model.submodels) {
// since the training data is unlabeled, we are unable to return the accuracy of this model
console.log("We have recognized the following fields");
for (const key in submodel.fields) {
const field = submodel.fields[key];
console.log(`The model found field '${field.name}'`);
}
}
}
// Training document information
if (model.trainingDocuments) {
for (const doc of model.trainingDocuments) {
console.log(`Document name: ${doc.name}`);
console.log(`Document status: ${doc.status}`);
console.log(`Document page count: ${doc.pageCount}`);
console.log(`Document errors: ${doc.errors}`);
}
}
}
trainModelLabels().catch((err) => {
console.error("The sample encountered an error:", err);
});
これは、JavaScript SDK から入手できるトレーニング データを使用してトレーニングされたモデルの出力です。 このサンプル結果は、読みやすくするために一部が省略されています。
training status: creating
training status: ready
Model ID: 789b1b37-4cc3-4e36-8665-9dde68618072
Status: ready
Training started on: Thu Aug 20 2020 20:30:37 GMT-0700 (Pacific Daylight Time)
Training completed on: Thu Aug 20 2020 20:30:43 GMT-0700 (Pacific Daylight Time)
We have recognized the following fields
The model found field 'CompanyAddress'
The model found field 'CompanyName'
The model found field 'CompanyPhoneNumber'
The model found field 'DatedAs'
...
Document name: Form_1.jpg
Document status: succeeded
Document page count: 1
Document errors: undefined
Document name: Form_2.jpg
Document status: succeeded
Document page count: 1
Document errors: undefined
Document name: Form_3.jpg
Document status: succeeded
Document page count: 1
Document errors: undefined
...
カスタム モデルを使用してフォームを分析する
このセクションでは、独自のフォームでトレーニングしたモデルを使用して、カスタムのテンプレートの種類からキー/値の情報やその他のコンテンツを抽出する方法について説明します。
重要
このシナリオを実装するには、モデルのトレーニングが完了している必要があります。それにより、メソッド操作にその ID を渡すことができます。 モデルのトレーニングに関するセクションを参照してください。
beginRecognizeCustomFormsFromUrl メソッドを使用します。 返される値は、RecognizedForm オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。
async function recognizeCustom() {
// Model ID from when you trained your model.
const modelId = "<modelId>";
const formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/simple-invoice.png";
const poller = await client.beginRecognizeCustomForms(modelId, formUrl, {
onProgress: (state) => { console.log(`status: ${state.status}`); }
});
const forms = await poller.pollUntilDone();
console.log("Forms:");
for (const form of forms || []) {
console.log(`${form.formType}, page range: ${form.pageRange}`);
console.log("Pages:");
for (const page of form.pages || []) {
console.log(`Page number: ${page.pageNumber}`);
console.log("Tables");
for (const table of page.tables || []) {
for (const cell of table.cells) {
console.log(`cell (${cell.rowIndex},${cell.columnIndex}) ${cell.text}`);
}
}
}
console.log("Fields:");
for (const fieldName in form.fields) {
// each field is of type FormField
const field = form.fields[fieldName];
console.log(
`Field ${fieldName} has value '${field.value}' with a confidence score of ${field.confidence}`
);
}
}
}
recognizeCustom().catch((err) => {
console.error("The sample encountered an error:", err);
});
ヒント
beginRecognizeCustomForms などの FormRecognizerClient メソッドを使用して、ローカルにあるファイルを分析することもできます。
status: notStarted
status: succeeded
Forms:
custom:form, page range: [object Object]
Pages:
Page number: 1
Tables
cell (0,0) Invoice Number
cell (0,1) Invoice Date
cell (0,2) Invoice Due Date
cell (0,3) Charges
cell (0,5) VAT ID
cell (1,0) 34278587
cell (1,1) 6/18/2017
cell (1,2) 6/24/2017
cell (1,3) $56,651.49
cell (1,5) PT
Fields:
Field Merchant has value 'Invoice For:' with a confidence score of 0.116
Field CompanyPhoneNumber has value '$56,651.49' with a confidence score of 0.249
Field VendorName has value 'Charges' with a confidence score of 0.145
Field CompanyAddress has value '1 Redmond way Suite 6000 Redmond, WA' with a confidence score of 0.258
Field CompanyName has value 'PT' with a confidence score of 0.245
Field Website has value '99243' with a confidence score of 0.114
Field DatedAs has value 'undefined' with a confidence score of undefined
Field Email has value 'undefined' with a confidence score of undefined
Field PhoneNumber has value 'undefined' with a confidence score of undefined
Field PurchaseOrderNumber has value 'undefined' with a confidence score of undefined
Field Quantity has value 'undefined' with a confidence score of undefined
Field Signature has value 'undefined' with a confidence score of undefined
Field Subtotal has value 'undefined' with a confidence score of undefined
Field Tax has value 'undefined' with a confidence score of undefined
Field Total has value 'undefined' with a confidence score of undefined
カスタム モデルを管理する
このセクションでは、アカウントに格納されているカスタム モデルを管理する方法について説明します。 次のコードは、例として、1 つの関数ですべてのモデル管理タスクを実行します。
モデルの数を取得する
次のコード ブロックは、現在アカウントに存在するモデルの数を取得するものです。
async function countModels() {
// First, we see how many custom models we have, and what our limit is
const accountProperties = await trainingClient.getAccountProperties();
console.log(
`Our account has ${accountProperties.customModelCount} custom models, and we can have at most ${accountProperties.customModelLimit} custom models`
);
}
countModels().catch((err) => {
console.error("The sample encountered an error:", err);
});
アカウントにあるモデルの一覧を取得する
次のコード ブロックを使用すると、モデルが作成された時期とモデルの現在の状態に関する情報を含め、自分のアカウントにある利用可能なモデルの全一覧を出力できます。
async function listModels() {
// returns an async iteratable iterator that supports paging
const result = trainingClient.listCustomModels();
let i = 0;
for await (const modelInfo of result) {
console.log(`model ${i++}:`);
console.log(modelInfo);
}
}
listModels().catch((err) => {
console.error("The sample encountered an error:", err);
});
結果は次の出力のようになります。
model 0:
{
modelId: '453cc2e6-e3eb-4e9f-aab6-e1ac7b87e09e',
status: 'invalid',
trainingStartedOn: 2020-08-20T22:28:52.000Z,
trainingCompletedOn: 2020-08-20T22:28:53.000Z
}
model 1:
{
modelId: '628739de-779c-473d-8214-d35c72d3d4f7',
status: 'ready',
trainingStartedOn: 2020-08-20T23:16:51.000Z,
trainingCompletedOn: 2020-08-20T23:16:59.000Z
}
model 2:
{
modelId: '789b1b37-4cc3-4e36-8665-9dde68618072',
status: 'ready',
trainingStartedOn: 2020-08-21T03:30:37.000Z,
trainingCompletedOn: 2020-08-21T03:30:43.000Z
}
model 3:
{
modelId: '9d893595-1690-4cf2-a4b1-fbac0fb11909',
status: 'ready',
trainingStartedOn: 2020-08-21T03:27:26.000Z,
trainingCompletedOn: 2020-08-21T03:27:37.000Z
}
モデル ID の一覧をページ分割して取得する
このコード ブロックを使用すると、モデルとモデル ID の一覧をページ分割して出力できます。
async function listModelsByPage() {
// using `byPage()`
i = 1;
for await (const response of trainingClient.listCustomModels().byPage()) {
for (const modelInfo of response.modelList) {
console.log(`model ${i++}: ${modelInfo.modelId}`);
}
}
}
listModelsByPage().catch((err) => {
console.error("The sample encountered an error:", err);
});
結果は次の出力のようになります。
model 1: 453cc2e6-e3eb-4e9f-aab6-e1ac7b87e09e
model 2: 628739de-779c-473d-8214-d35c72d3d4f7
model 3: 789b1b37-4cc3-4e36-8665-9dde68618072
ID でモデルを取得する
次の関数は、モデル ID を受け取り、一致するモデル オブジェクトを取得します。 この関数は、既定では呼び出されません。
async function getModel(modelId) {
// Now we'll get the first custom model in the paged list
const model = await client.getCustomModel(modelId);
console.log("--- First Custom Model ---");
console.log(`Model Id: ${model.modelId}`);
console.log(`Status: ${model.status}`);
console.log("Documents used in training:");
for (const doc of model.trainingDocuments || []) {
console.log(`- ${doc.name}`);
}
}
リソース アカウントからモデルを削除する
ID を参照して、アカウントからモデルを削除することもできます。 この関数は、指定された ID のモデルを削除します。 この関数は、既定では呼び出されません。
async function deleteModel(modelId) {
await client.deleteModel(modelId);
try {
const deleted = await client.getCustomModel(modelId);
console.log(deleted);
} catch (err) {
// Expected
console.log(`Model with id ${modelId} has been deleted`);
}
}
結果は次の出力のようになります。
Model with id 789b1b37-4cc3-4e36-8665-9dde68618072 has been deleted
アプリケーションの実行
プロジェクト ファイルで node コマンドを使用して、アプリケーションを実行します。
node index.js
リソースをクリーンアップする
Azure AI サービス サブスクリプションをクリーンアップして削除したい場合は、リソースまたはリソース グループを削除することができます。 リソース グループを削除すると、それに関連付けられている他のリソースも削除されます。
トラブルシューティング
このライブラリの使用時にデバッグ ログを表示するには、次の環境変数を設定します。
export DEBUG=azure*
ログを有効にする方法の詳細については、@azure/logger パッケージに関するドキュメントを参照してください。
次のステップ
このプロジェクトでは、Document Intelligence JavaScript クライアント ライブラリを使用してモデルをトレーニングし、さまざまな方法でフォームを分析しました。 次に、より適切なトレーニング データ セットを作成し、より正確なモデルを生成するためのヒントについて学習します。
このプロジェクトのサンプルコードについては、 GitHub を参照してください。
重要
このプロジェクトは、ドキュメントインテリジェンス REST API バージョン 2.1 を対象としています。
リファレンス ドキュメント | ライブラリのソース コード | パッケージ (PyPi) | サンプル
前提条件
Azure サブスクリプション。無料で作成できます。
Python 3.x。 Python のインストールには、pip が含まれている必要があります。 pip がインストールされているかどうかを確認するには、コマンド ラインで
pip --versionを実行します。 最新バージョンの Python をインストールして pip を入手してください。トレーニング データのセットを含む Azure Storage Blob。 トレーニング データセットをまとめるためのヒントとオプションについては、「カスタム モデルを構築してトレーニング データする」を参照してください。 このプロジェクトでは、サンプル データ セットの Train フォルダーにあるファイルを使用できます。 sample_data.zip をダウンロードして展開します。
Document Intelligence リソース。 Azure portal で Document Intelligence リソースを作成します。 Free 価格レベル (
F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
プログラミング環境のセットアップ
クライアント ライブラリをインストールし、Python アプリケーションを作成します。
クライアント ライブラリをインストールする
Python をインストールしたら、次のコマンドを使用して最新バージョンの Document Intelligence クライアント ライブラリをインストールすることができます:
pip install azure-ai-formrecognizer
Python アプリケーションを作成する
エディターまたは IDE で、form-recognizer.py という名前の Python アプリケーションを作成します。
その後で、次のライブラリをインポートします。
import os from azure.core.exceptions import ResourceNotFoundError from azure.ai.formrecognizer import FormRecognizerClient from azure.ai.formrecognizer import FormTrainingClient from azure.core.credentials import AzureKeyCredential自分のリソースの Azure エンドポイントおよびキー用の変数を作成します。
endpoint = "PASTE_YOUR_FORM_RECOGNIZER_ENDPOINT_HERE" key = "PASTE_YOUR_FORM_RECOGNIZER_SUBSCRIPTION_KEY_HERE"
オブジェクト モデルを使用する
Document Intelligence で作成できるクライアントは 2 種類あります。 1 つ目の form_recognizer_client はサービスに対しクエリを実行しフォーム フィールドとコンテンツを認識します。 もう 1 つは form_training_client であり、認識精度を高めるためのカスタム モデルを作成および管理します。
form_recognizer_client を使用すると、次の処理を実行できます。
- 対象のカスタム フォームを分析するようトレーニングされたカスタム モデルを使用して、フォームのフィールドやコンテンツを認識する。
- モデルをトレーニングせずにフォームのコンテンツ (表、行、単語など) を認識する。
- Document Intelligence サービスの事前トレーニング済みの領収書モデルを使用して、領収書から一般的なフィールドを認識する。
form_training_client には、以下を目的とした操作が用意されています。
- カスタム モデルをトレーニングして、対象のカスタム フォームにあるすべてのフィールドと値を分析する。 この記事内の「ラベルなしでモデルをトレーニング する」を参照してください。
- 対象のカスタム フォームにラベル付けすることによって指定した特定のフィールドと値を分析するように、カスタム モデルをトレーニングする。 この記事内の「ラベルを使用してモデルをトレーニングする」を参照してください。
- アカウントに作成されたモデルを管理する。
- Document Intelligence リソース間でカスタム モデルをコピーする。
Note
モデルのトレーニングは、Document Intelligence のラベル付けツール など、グラフィカル ユーザー インターフェイスを使用して行うこともできます。
クライアントを認証する
ここでは、先ほど定義したサブスクリプション変数を使用して 2 つのクライアント オブジェクトを認証します。 新しいクライアント オブジェクトを作成せずに、必要に応じてキーを更新できるように、AzureKeyCredential オブジェクトを使用します。
form_recognizer_client = FormRecognizerClient(endpoint, AzureKeyCredential(key))
form_training_client = FormTrainingClient(endpoint, AzureKeyCredential(key))
テスト用のアセットを取得する
トレーニングとテスト データの URL への参照を追加する必要があります。
カスタム モデルのトレーニング データの SAS URL を取得するには、Azure portal のストレージ リソースに移動し、[データ ストレージ]>[コンテナー] を選択します。
ご自分のコンテナーに移動し、右クリックして [SAS の生成] を選択します。
ストレージ アカウント自体ではなく、ご自分のコンテナー用の SAS を取得することが重要です。
[読み取り]、[書き込み]、[削除]、[リスト] の各アクセス許可が選択されていることを確認し、[SAS トークンと URL の生成] を選択します。
URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。
サンプルに含まれるフォームや領収書のサンプル画像を使用します。これは GitHub でも入手できます。 あるいは、上記の手順を使用して、Blob Storage 内の個々のドキュメントの SAS URL を取得できます。
Note
このプロジェクトのコード スニペットでは、URL でアクセスされるリモート フォームが使用されます。 ローカル フォーム ドキュメントを代わりに処理する場合は、リファレンス ドキュメント と サンプル の関連するメソッドを参照してください。
レイアウトを分析する
Document Intelligence を使用すると、ドキュメント内の表、行、および単語を分析できます。モデルをトレーニングする必要はありません。 レイアウト抽出の詳細については、「Document Intelligence レイアウト モデル」を参照してください。
指定された URL にあるファイルの内容を分析するには、begin_recognize_content_from_url メソッドを使用します。 返される値は、FormPage オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 次のコードでは、これらのオブジェクトを反復処理し、抽出されたキー/値のペアとテーブル データを出力します。
formUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/tests/sample_forms/forms/Form_1.jpg"
poller = form_recognizer_client.begin_recognize_content_from_url(formUrl)
page = poller.result()
table = page[0].tables[0] # page 1, table 1
print("Table found on page {}:".format(table.page_number))
for cell in table.cells:
print("Cell text: {}".format(cell.text))
print("Location: {}".format(cell.bounding_box))
print("Confidence score: {}\n".format(cell.confidence))
ヒント
begin_recognize_content などの FormRecognizerClient メソッドを使用して、ローカルにある画像からコンテンツを取得することもできます。
Table found on page 1:
Cell text: Invoice Number
Location: [Point(x=0.5075, y=2.8088), Point(x=1.9061, y=2.8088), Point(x=1.9061, y=3.3219), Point(x=0.5075, y=3.3219)]
Confidence score: 1.0
Cell text: Invoice Date
Location: [Point(x=1.9061, y=2.8088), Point(x=3.3074, y=2.8088), Point(x=3.3074, y=3.3219), Point(x=1.9061, y=3.3219)]
Confidence score: 1.0
Cell text: Invoice Due Date
Location: [Point(x=3.3074, y=2.8088), Point(x=4.7074, y=2.8088), Point(x=4.7074, y=3.3219), Point(x=3.3074, y=3.3219)]
Confidence score: 1.0
Cell text: Charges
Location: [Point(x=4.7074, y=2.8088), Point(x=5.386, y=2.8088), Point(x=5.386, y=3.3219), Point(x=4.7074, y=3.3219)]
Confidence score: 1.0
...
領収書を分析する
このセクションでは、事前トレーニング済みの領収書モデルを使用して、米国の領収書から共通フィールドを分析、抽出する方法を示します。 領収書分析の詳細については、「Document Intelligence 領収書モデル」を参照してください。 URL からレシートを分析するには、begin_recognize_receipts_from_url メソッドを使用します。
receiptUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/tests/sample_forms/receipt/contoso-receipt.png"
poller = form_recognizer_client.begin_recognize_receipts_from_url(receiptUrl)
result = poller.result()
for receipt in result:
for name, field in receipt.fields.items():
if name == "Items":
print("Receipt Items:")
for idx, items in enumerate(field.value):
print("...Item #{}".format(idx + 1))
for item_name, item in items.value.items():
print("......{}: {} has confidence {}".format(item_name, item.value, item.confidence))
else:
print("{}: {} has confidence {}".format(name, field.value, field.confidence))
ヒント
begin_recognize_receipts などの FormRecognizerClient メソッドを使用して、ローカルにあるレシートの画像を分析することもできます。
ReceiptType: Itemized has confidence 0.659
MerchantName: Contoso Contoso has confidence 0.516
MerchantAddress: 123 Main Street Redmond, WA 98052 has confidence 0.986
MerchantPhoneNumber: None has confidence 0.99
TransactionDate: 2019-06-10 has confidence 0.985
TransactionTime: 13:59:00 has confidence 0.968
Receipt Items:
...Item #1
......Name: 8GB RAM (Black) has confidence 0.916
......TotalPrice: 999.0 has confidence 0.559
...Item #2
......Quantity: None has confidence 0.858
......Name: SurfacePen has confidence 0.858
......TotalPrice: 99.99 has confidence 0.386
Subtotal: 1098.99 has confidence 0.964
Tax: 104.4 has confidence 0.713
Total: 1203.39 has confidence 0.774
名刺を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、英語の名刺から共通フィールドを分析、抽出する方法を示します。 名刺分析の詳細については、「Document Intelligence 名刺モデル」を参照してください。
URL から名刺を分析するには、begin_recognize_business_cards_from_url メソッドを使用します。
bcUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/samples/sample_forms/business_cards/business-card-english.jpg"
poller = form_recognizer_client.begin_recognize_business_cards_from_url(bcUrl)
business_cards = poller.result()
for idx, business_card in enumerate(business_cards):
print("--------Recognizing business card #{}--------".format(idx+1))
contact_names = business_card.fields.get("ContactNames")
if contact_names:
for contact_name in contact_names.value:
print("Contact First Name: {} has confidence: {}".format(
contact_name.value["FirstName"].value, contact_name.value["FirstName"].confidence
))
print("Contact Last Name: {} has confidence: {}".format(
contact_name.value["LastName"].value, contact_name.value["LastName"].confidence
))
company_names = business_card.fields.get("CompanyNames")
if company_names:
for company_name in company_names.value:
print("Company Name: {} has confidence: {}".format(company_name.value, company_name.confidence))
departments = business_card.fields.get("Departments")
if departments:
for department in departments.value:
print("Department: {} has confidence: {}".format(department.value, department.confidence))
job_titles = business_card.fields.get("JobTitles")
if job_titles:
for job_title in job_titles.value:
print("Job Title: {} has confidence: {}".format(job_title.value, job_title.confidence))
emails = business_card.fields.get("Emails")
if emails:
for email in emails.value:
print("Email: {} has confidence: {}".format(email.value, email.confidence))
websites = business_card.fields.get("Websites")
if websites:
for website in websites.value:
print("Website: {} has confidence: {}".format(website.value, website.confidence))
addresses = business_card.fields.get("Addresses")
if addresses:
for address in addresses.value:
print("Address: {} has confidence: {}".format(address.value, address.confidence))
mobile_phones = business_card.fields.get("MobilePhones")
if mobile_phones:
for phone in mobile_phones.value:
print("Mobile phone number: {} has confidence: {}".format(phone.value, phone.confidence))
faxes = business_card.fields.get("Faxes")
if faxes:
for fax in faxes.value:
print("Fax number: {} has confidence: {}".format(fax.value, fax.confidence))
work_phones = business_card.fields.get("WorkPhones")
if work_phones:
for work_phone in work_phones.value:
print("Work phone number: {} has confidence: {}".format(work_phone.value, work_phone.confidence))
other_phones = business_card.fields.get("OtherPhones")
if other_phones:
for other_phone in other_phones.value:
print("Other phone number: {} has confidence: {}".format(other_phone.value, other_phone.confidence))
ヒント
begin_recognize_business_cards などの FormRecognizerClient メソッドを使用して、ローカルにある名刺の画像を分析することもできます。
請求書を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、売上請求書から共通フィールドを分析、抽出する方法を示します。 請求書分析の詳細については、「Document Intelligence の請求書モデル」を参照してください。
URL から請求書を分析するには、begin_recognize_invoices_from_url メソッドを使用します。
invoiceUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/simple-invoice.png"
poller = form_recognizer_client.begin_recognize_invoices_from_url(invoiceUrl)
invoices = poller.result()
for idx, invoice in enumerate(invoices):
print("--------Recognizing invoice #{}--------".format(idx+1))
vendor_name = invoice.fields.get("VendorName")
if vendor_name:
print("Vendor Name: {} has confidence: {}".format(vendor_name.value, vendor_name.confidence))
vendor_address = invoice.fields.get("VendorAddress")
if vendor_address:
print("Vendor Address: {} has confidence: {}".format(vendor_address.value, vendor_address.confidence))
customer_name = invoice.fields.get("CustomerName")
if customer_name:
print("Customer Name: {} has confidence: {}".format(customer_name.value, customer_name.confidence))
customer_address = invoice.fields.get("CustomerAddress")
if customer_address:
print("Customer Address: {} has confidence: {}".format(customer_address.value, customer_address.confidence))
customer_address_recipient = invoice.fields.get("CustomerAddressRecipient")
if customer_address_recipient:
print("Customer Address Recipient: {} has confidence: {}".format(customer_address_recipient.value, customer_address_recipient.confidence))
invoice_id = invoice.fields.get("InvoiceId")
if invoice_id:
print("Invoice Id: {} has confidence: {}".format(invoice_id.value, invoice_id.confidence))
invoice_date = invoice.fields.get("InvoiceDate")
if invoice_date:
print("Invoice Date: {} has confidence: {}".format(invoice_date.value, invoice_date.confidence))
invoice_total = invoice.fields.get("InvoiceTotal")
if invoice_total:
print("Invoice Total: {} has confidence: {}".format(invoice_total.value, invoice_total.confidence))
due_date = invoice.fields.get("DueDate")
if due_date:
print("Due Date: {} has confidence: {}".format(due_date.value, due_date.confidence))
ヒント
begin_recognize_invoices などの FormRecognizerClient メソッドを使用して、ローカルにある請求書の画像を分析することもできます。
身分証明書を分析する
このセクションでは、Document Intelligence の事前構築済み ID モデルを使用して、政府発行の身分証明書 (世界各国のパスポートと米国の運転免許証を含む) から重要な情報を分析および抽出する方法を示します。 ID ドキュメント分析の詳細については、「Document Intelligence ID ドキュメント モデル」を参照してください。
URL から身分証明書を分析するには、begin_recognize_id_documents_from_url メソッドを使用します。
idURL = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/id-license.jpg"
for idx, id_document in enumerate(id_documents):
print("--------Recognizing ID document #{}--------".format(idx+1))
first_name = id_document.fields.get("FirstName")
if first_name:
print("First Name: {} has confidence: {}".format(first_name.value, first_name.confidence))
last_name = id_document.fields.get("LastName")
if last_name:
print("Last Name: {} has confidence: {}".format(last_name.value, last_name.confidence))
document_number = id_document.fields.get("DocumentNumber")
if document_number:
print("Document Number: {} has confidence: {}".format(document_number.value, document_number.confidence))
dob = id_document.fields.get("DateOfBirth")
if dob:
print("Date of Birth: {} has confidence: {}".format(dob.value, dob.confidence))
doe = id_document.fields.get("DateOfExpiration")
if doe:
print("Date of Expiration: {} has confidence: {}".format(doe.value, doe.confidence))
sex = id_document.fields.get("Sex")
if sex:
print("Sex: {} has confidence: {}".format(sex.value, sex.confidence))
address = id_document.fields.get("Address")
if address:
print("Address: {} has confidence: {}".format(address.value, address.confidence))
country_region = id_document.fields.get("CountryRegion")
if country_region:
print("Country/Region: {} has confidence: {}".format(country_region.value, country_region.confidence))
region = id_document.fields.get("Region")
if region:
print("Region: {} has confidence: {}".format(region.value, region.confidence))
ヒント
begin_recognize_identity_documents などの FormRecognizerClient メソッドを使用して、身分証明書の画像を分析することもできます。
カスタム モデルをトレーニングする
このセクションでは、独自のデータを使用してモデルをトレーニングする方法を示します。 トレーニング済みのモデルは、元のフォーム ドキュメント内のキー/値の関係を含む構造化データを出力できます。 モデルをトレーニングした後、モデルをテスト、再トレーニングでき、最終的にはモデルを使用して、ニーズに従ってより多くのフォームから正確にデータを抽出できます。
Note
また、Document Intelligence のサンプル ラベル付けツールなどのグラフィカル ユーザー インターフェイスを使用してモデルをトレーニングすることもできます。
ラベルなしでモデルをトレーニングする
カスタム モデルをトレーニングして、トレーニング ドキュメントに手動でラベルを付けることなく、カスタム フォームにあるすべてのフィールドと値を分析できるようにします。
次のコードは、トレーニング クライアントを begin_training 関数と共に使用して、特定のドキュメント セットでモデルをトレーニングします。 返される CustomFormModel オブジェクトには、モデルが分析できるフォームの種類と、それぞれのフォームの種類から抽出できるフィールドに関する情報が含まれています。 次のコード ブロックは、この情報をコンソールに出力します。
# To train a model you need an Azure Storage account.
# Use the SAS URL to access your training files.
trainingDataUrl = "PASTE_YOUR_SAS_URL_OF_YOUR_FORM_FOLDER_IN_BLOB_STORAGE_HERE"
poller = form_training_client.begin_training(trainingDataUrl, use_training_labels=False)
model = poller.result()
print("Model ID: {}".format(model.model_id))
print("Status: {}".format(model.status))
print("Training started on: {}".format(model.training_started_on))
print("Training completed on: {}".format(model.training_completed_on))
print("\nRecognized fields:")
for submodel in model.submodels:
print(
"The submodel with form type '{}' has recognized the following fields: {}".format(
submodel.form_type,
", ".join(
[
field.label if field.label else name
for name, field in submodel.fields.items()
]
),
)
)
# Training result information
for doc in model.training_documents:
print("Document name: {}".format(doc.name))
print("Document status: {}".format(doc.status))
print("Document page count: {}".format(doc.page_count))
print("Document errors: {}".format(doc.errors))
Python SDK から入手できるトレーニング データを使用してトレーニングされたモデルの出力を次に示します。
Model ID: 628739de-779c-473d-8214-d35c72d3d4f7
Status: ready
Training started on: 2020-08-20 23:16:51+00:00
Training completed on: 2020-08-20 23:16:59+00:00
Recognized fields:
The submodel with form type 'form-0' has recognized the following fields: Additional Notes:, Address:, Company Name:, Company Phone:, Dated As:, Details, Email:, Hero Limited, Name:, Phone:, Purchase Order, Purchase Order #:, Quantity, SUBTOTAL, Seattle, WA 93849 Phone:, Shipped From, Shipped To, TAX, TOTAL, Total, Unit Price, Vendor Name:, Website:
Document name: Form_1.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_2.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_3.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_4.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_5.jpg
Document status: succeeded
Document page count: 1
Document errors: []
ラベルを使用してモデルをトレーニングする
トレーニング ドキュメントに手動でラベルを付けて、カスタム モデルをトレーニングすることもできます。 ラベルを使用してトレーニングを行うと、一部のシナリオでパフォーマンスの向上につながります。 返される CustomFormModel は、モデルが抽出できるフィールドを、各フィールドの予測精度と共に示します。 次のコード ブロックは、この情報をコンソールに出力します。
重要
ラベルを使用してトレーニングするには、トレーニング ドキュメントと共に、BLOB ストレージ コンテナーに特別なラベル情報ファイル (<filename>.pdf.labels.json) を用意する必要があります。 Document Intelligence のサンプル ラベル付けツールでは、これらのラベル ファイルの作成を支援する UI が提供されています。 それらを用意できたら、use_training_labels パラメーターを true に設定して begin_training 関数を呼び出すことができます。
# To train a model you need an Azure Storage account.
# Use the SAS URL to access your training files.
trainingDataUrl = "PASTE_YOUR_SAS_URL_OF_YOUR_FORM_FOLDER_IN_BLOB_STORAGE_HERE"
poller = form_training_client.begin_training(trainingDataUrl, use_training_labels=True)
model = poller.result()
trained_model_id = model.model_id
print("Model ID: {}".format(trained_model_id))
print("Status: {}".format(model.status))
print("Training started on: {}".format(model.training_started_on))
print("Training completed on: {}".format(model.training_completed_on))
print("\nRecognized fields:")
for submodel in model.submodels:
print(
"The submodel with form type '{}' has recognized the following fields: {}".format(
submodel.form_type,
", ".join(
[
field.label if field.label else name
for name, field in submodel.fields.items()
]
),
)
)
# Training result information
for doc in model.training_documents:
print("Document name: {}".format(doc.name))
print("Document status: {}".format(doc.status))
print("Document page count: {}".format(doc.page_count))
print("Document errors: {}".format(doc.errors))
Python SDK から入手できるトレーニング データを使用してトレーニングされたモデルの出力を次に示します。
Model ID: ae636292-0b14-4e26-81a7-a0bfcbaf7c91
Status: ready
Training started on: 2020-08-20 23:20:56+00:00
Training completed on: 2020-08-20 23:20:57+00:00
Recognized fields:
The submodel with form type 'form-ae636292-0b14-4e26-81a7-a0bfcbaf7c91' has recognized the following fields: CompanyAddress, CompanyName, CompanyPhoneNumber, DatedAs, Email, Merchant, PhoneNumber, PurchaseOrderNumber, Quantity, Signature, Subtotal, Tax, Total, VendorName, Website
Document name: Form_1.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_2.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_3.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_4.jpg
Document status: succeeded
Document page count: 1
Document errors: []
Document name: Form_5.jpg
Document status: succeeded
Document page count: 1
Document errors: []
カスタム モデルを使用してフォームを分析する
このセクションでは、独自のフォームでトレーニングしたモデルを使用して、カスタムのテンプレートの種類からキー/値の情報やその他のコンテンツを抽出する方法について説明します。
重要
このシナリオを実装するには、モデルのトレーニングが完了している必要があります。それにより、メソッド操作にその ID を渡すことができます。 モデルのトレーニングに関するセクションを参照してください。
begin_recognize_custom_forms_from_url メソッドを使用します。 返される値は、RecognizedForm オブジェクトのコレクションです。 送信されたドキュメント内のページごとに 1 つのオブジェクトがあります。 次のコードは、分析結果をコンソールに出力します。 認識された各フィールドと対応する値が、信頼度スコアと共に出力されます。
poller = form_recognizer_client.begin_recognize_custom_forms_from_url(
model_id=trained_model_id, form_url=formUrl)
result = poller.result()
for recognized_form in result:
print("Form type: {}".format(recognized_form.form_type))
for name, field in recognized_form.fields.items():
print("Field '{}' has label '{}' with value '{}' and a confidence score of {}".format(
name,
field.label_data.text if field.label_data else name,
field.value,
field.confidence
))
ヒント
ローカルの画像を分析することもできます。 FormRecognizerClient のメソッドを参照してください (begin_recognize_custom_forms など)。 また、ローカルの画像に関連したシナリオについては、GitHub 上のサンプル コードを参照してください。
前の例のモデルでは、次の出力が返されます。
Form type: form-ae636292-0b14-4e26-81a7-a0bfcbaf7c91
Field 'Merchant' has label 'Merchant' with value 'Invoice For:' and a confidence score of 0.116
Field 'CompanyAddress' has label 'CompanyAddress' with value '1 Redmond way Suite 6000 Redmond, WA' and a confidence score of 0.258
Field 'Website' has label 'Website' with value '99243' and a confidence score of 0.114
Field 'VendorName' has label 'VendorName' with value 'Charges' and a confidence score of 0.145
Field 'CompanyPhoneNumber' has label 'CompanyPhoneNumber' with value '$56,651.49' and a confidence score of 0.249
Field 'CompanyName' has label 'CompanyName' with value 'PT' and a confidence score of 0.245
Field 'DatedAs' has label 'DatedAs' with value 'None' and a confidence score of None
Field 'Email' has label 'Email' with value 'None' and a confidence score of None
Field 'PhoneNumber' has label 'PhoneNumber' with value 'None' and a confidence score of None
Field 'PurchaseOrderNumber' has label 'PurchaseOrderNumber' with value 'None' and a confidence score of None
Field 'Quantity' has label 'Quantity' with value 'None' and a confidence score of None
Field 'Signature' has label 'Signature' with value 'None' and a confidence score of None
Field 'Subtotal' has label 'Subtotal' with value 'None' and a confidence score of None
Field 'Tax' has label 'Tax' with value 'None' and a confidence score of None
Field 'Total' has label 'Total' with value 'None' and a confidence score of None
カスタム モデルを管理する
このセクションでは、アカウントに格納されているカスタム モデルを管理する方法について説明します。
FormRecognizer リソース アカウント内のモデルの数を確認する
次のコード ブロックは、Document Intelligence アカウントに保存したモデルの数を確認し、アカウントの制限と比較します。
account_properties = form_training_client.get_account_properties()
print("Our account has {} custom models, and we can have at most {} custom models".format(
account_properties.custom_model_count, account_properties.custom_model_limit
))
結果は次の出力のようになります。
Our account has 5 custom models, and we can have at most 5000 custom models
リソース アカウントに現在格納されているモデルを一覧表示する
次のコード ブロックは、アカウント内の現在のモデルを一覧表示し、その詳細をコンソールに出力します。 また、最初のモデルへの参照も保存します。
# Next, we get a paged list of all of our custom models
custom_models = form_training_client.list_custom_models()
print("We have models with the following ids:")
# Let's pull out the first model
first_model = next(custom_models)
print(first_model.model_id)
for model in custom_models:
print(model.model_id)
結果は次の出力のようになります。
テスト アカウントのサンプル出力を次に示します。
We have models with the following ids:
453cc2e6-e3eb-4e9f-aab6-e1ac7b87e09e
628739de-779c-473d-8214-d35c72d3d4f7
ae636292-0b14-4e26-81a7-a0bfcbaf7c91
b4b5df77-8538-4ffb-a996-f67158ecd305
c6309148-6b64-4fef-aea0-d39521452699
モデルの ID を使用して特定のモデルを取得する
次のコード ブロックは、前のセクションで保存したモデル ID を使用して、モデルに関する詳細を取得します。
custom_model = form_training_client.get_custom_model(model_id=trained_model_id)
print("Model ID: {}".format(custom_model.model_id))
print("Status: {}".format(custom_model.status))
print("Training started on: {}".format(custom_model.training_started_on))
print("Training completed on: {}".format(custom_model.training_completed_on))
前の例で作成したカスタム モデルのサンプル出力を次に示します。
Model ID: ae636292-0b14-4e26-81a7-a0bfcbaf7c91
Status: ready
Training started on: 2020-08-20 23:20:56+00:00
Training completed on: 2020-08-20 23:20:57+00:00
リソース アカウントからモデルを削除する
ID を参照して、アカウントからモデルを削除することもできます。 このコードは、前のセクションで使用したモデルを削除します。
form_training_client.delete_model(model_id=custom_model.model_id)
try:
form_training_client.get_custom_model(model_id=custom_model.model_id)
except ResourceNotFoundError:
print("Successfully deleted model with id {}".format(custom_model.model_id))
アプリケーションの実行
python コマンドを使用してアプリケーションを実行します。
python form-recognizer.py
リソースをクリーンアップする
Azure AI サービス サブスクリプションをクリーンアップして削除したい場合は、リソースまたはリソース グループを削除することができます。 リソース グループを削除すると、それに関連付けられている他のリソースも削除されます。
トラブルシューティング
これらの問題は、トラブルシューティングに役立つ場合があります。
全般
Document Intelligence クライアント ライブラリにより、Azure Core で定義されている例外が発生します。
ログ記録
このライブラリでは、ログ記録に標準のログ ライブラリを使用します。 HTTP セッション (URL、ヘッダーなど) に関する基本的な情報は、INFO レベルでログに記録されます。
要求/応答本文と編集されていないヘッダーを含む詳細なデバッグ レベルのログ記録は、次のように logging_enable キーワード引数を使用してクライアントで有効にすることができます。
import sys
import logging
from azure.ai.formrecognizer import FormRecognizerClient
from azure.core.credentials import AzureKeyCredential
# Create a logger for the 'azure' SDK
logger = logging.getLogger('azure')
logger.setLevel(logging.DEBUG)
# Configure a console output
handler = logging.StreamHandler(stream=sys.stdout)
logger.addHandler(handler)
endpoint = "PASTE_YOUR_FORM_RECOGNIZER_ENDPOINT_HERE"
credential = AzureKeyCredential("PASTE_YOUR_FORM_RECOGNIZER_SUBSCRIPTION_KEY_HERE")
# This client will log detailed information about its HTTP sessions, at DEBUG level
form_recognizer_client = FormRecognizerClient(endpoint, credential, logging_enable=True)
同様に、logging_enable は、詳細なログ記録がクライアントで有効になっていない場合でも、1 回の操作のために有効にすることができます。
receiptUrl = "https://raw.githubusercontent.com/Azure/azure-sdk-for-python/master/sdk/formrecognizer/azure-ai-formrecognizer/tests/sample_forms/receipt/contoso-receipt.png"
poller = form_recognizer_client.begin_recognize_receipts_from_url(receiptUrl, logging_enable=True)
GitHub の REST サンプル
- ドキュメントからテキスト、選択マーク、テーブル構造を抽出する: レイアウト データを抽出する - Python
- カスタム モデルをトレーニングしてカスタム フォーム データを抽出する
- 請求書からデータを抽出する: 請求書データを抽出する - Python
- 売上領収書からデータを抽出する: 領収書データを抽出する - Python
- 名刺からデータを抽出する: 名刺データを抽出する - Python
次のステップ
このプロジェクトでは、Document Intelligence Python クライアント ライブラリを使用してモデルをトレーニングし、さまざまな方法でフォームを分析しました。 次に、より適切なトレーニング データ セットを作成し、より正確なモデルを生成するためのヒントについて学習します。
このプロジェクトのサンプル コードについては、 GitHub を参照してください。
Note
このプロジェクトでは、cURL を使用して REST API 呼び出しを実行する、Azure AI Document Intelligence API バージョン 2.1 を対象としています。
Document Intelligence REST API | Azure REST API リファレンス
前提条件
Azure サブスクリプション。無料で作成できます。
cURL コマンド ライン ツールがインストールされている。 Windows 10 と Windows 11 には cURL が含まれています。 コマンド プロンプトで、次の cURL コマンドを入力します。 ヘルプ オプションが表示される場合は、Windows 環境に cURL がインストールされます。
curl -helpcURLがインストールされていない場合は、ここで入手できます。
PowerShell バージョン 6.0 以降、または同様のコマンド ライン アプリケーション。
トレーニング データのセットを含む Azure Storage Blob。 トレーニング データセットをまとめるためのヒントとオプションについては、「カスタム モデルを構築してトレーニング データする」を参照してください。 サンプル データ セットの Train フォルダーにあるファイルを使用できます。 sample_data.zip をダウンロードして展開します。
Azure AI サービスまたは Document Intelligence リソース。 単一サービスまたはマルチサービスを作成します。 Free 価格レベル (
`F0` ) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。アプリケーションを Document Intelligence API に接続するために作成したリソースのキーとエンドポイント。
- リソースがデプロイされたら、 [リソースに移動] を選択します。
- 左側のナビゲーション メニューで、[キーとエンドポイント] を選択します。
- この記事の後半で使用するために、いずれかのキーとエンドポイントをコピーします。
レシートの画像の URL。 サンプル画像を使用できます。
名刺の画像の URL。 サンプル画像を使用できます。
請求書の画像の URL。 サンプル ドキュメントを使用できます。
身分証明書の画像の URL。 サンプル画像を使用できます。
{kind=link}
{kind=link}
レイアウトを分析する
Document Intelligence を使用すると、モデルをトレーニングする必要なく、ドキュメント内の表、選択マーク、テキスト、構造を分析して抽出できます。 レイアウト抽出の詳細については、「Document Intelligence レイアウト モデル」を参照してください。
コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
- <your-document-url> を、URL 例のうちの 1 つに置き換えます。
curl -v -i POST "https://<endpoint>/formrecognizer/v2.1/layout/analyze" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" --data-ascii "{'source': '<your-document-url>'}"
読み取り専用 Operation-Location ヘッダーを含む 202 (Success) 応答を受信します。 このヘッダーの値には resultId が含まれており、クエリを実行して非同期操作の状態を取得し、同じリソース サブスクリプション キーで GET 要求を使用して結果を取得できます。
https://cognitiveservice/formrecognizer/v2.1/layout/analyzeResults/<resultId>
次の例では、URL の一部として、analyzeResults/ の後の文字列が結果 ID になります。
https://cognitiveservice/formrecognizer/v2/layout/analyzeResults/54f0b076-4e38-43e5-81bd-b85b8835fdfb
レイアウトの結果を取得する
Analyze Layout API を呼び出した後に Get Analyze Layout Result API を呼び出して、操作の状態と抽出されたデータを取得します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
- <resultId> を、前の手順の結果 ID に置き換えます。
curl -v -X GET "https://<endpoint>/formrecognizer/v2.1/layout/analyzeResults/<resultId>" -H "Ocp-Apim-Subscription-Key: <key>"
JSON コンテンツを含む 200 (success) 応答が返されます。
次の請求書の画像とそれに対応する JSON 出力をご覧ください。
"readResults"ノードには、あらゆるテキスト行が、ページ上の対応する境界ボックスの配置と共に表示されます。selectionMarksノードには、すべての選択マーク (チェック ボックス、ラジオ マーク) と、その状態がselectedとunselectedのどちらであるかが示されます。- 抽出された表は、
"pageResults"セクションに含まれています。 それぞれの表について、テキスト、行インデックス、列インデックス、行スパン、列スパン、境界ボックスなどが抽出されます。
この応答本文の出力は、簡素化するために一部省略されています。 GitHub で完全なサンプル出力を参照してください。
{
"status": "succeeded",
"createdDateTime": "2020-08-20T20:40:50Z",
"lastUpdatedDateTime": "2020-08-20T20:40:55Z",
"analyzeResult": {
"version": "2.1.0",
"readResults": [
{
"page": 1,
"angle": 0,
"width": 8.5,
"height": 11,
"unit": "inch",
"lines": [
{
"boundingBox": [
0.5826,
0.4411,
2.3387,
0.4411,
2.3387,
0.7969,
0.5826,
0.7969
],
"text": "Contoso, Ltd.",
"words": [
{
"boundingBox": [
0.5826,
0.4411,
1.744,
0.4411,
1.744,
0.7969,
0.5826,
0.7969
],
"text": "Contoso,",
"confidence": 1
},
{
"boundingBox": [
1.8448,
0.4446,
2.3387,
0.4446,
2.3387,
0.7631,
1.8448,
0.7631
],
"text": "Ltd.",
"confidence": 1
}
]
},
...
]
}
],
"selectionMarks": [
{
"boundingBox": [
3.9737,
3.7475,
4.1693,
3.7475,
4.1693,
3.9428,
3.9737,
3.9428
],
"confidence": 0.989,
"state": "selected"
},
...
]
}
],
"pageResults": [
{
"page": 1,
"tables": [
{
"rows": 5,
"columns": 5,
"cells": [
{
"rowIndex": 0,
"columnIndex": 0,
"text": "Training Date",
"boundingBox": [
0.5133,
4.2167,
1.7567,
4.2167,
1.7567,
4.4492,
0.5133,
4.4492
],
"elements": [
"#/readResults/0/lines/12/words/0",
"#/readResults/0/lines/12/words/1"
]
},
...
]
},
...
]
}
]
}
}
領収書を分析する
このセクションでは、事前トレーニング済みの領収書モデルを使用して、米国のレシートから共通フィールドを分析、抽出する方法を示します。 領収書分析の詳細については、「Document Intelligence 領収書モデル」を参照してください。 レシートの分析を開始するには、この cURL コマンドを使用して Analyze Receipt API を呼び出します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <your receipt URL> を、レシートの画像の URL アドレスに置き換えます。
- <key>` を、前の手順からコピーしたキーに置き換えます。
curl -i -X POST "https://<endpoint>/formrecognizer/v2.1/prebuilt/receipt/analyze" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" --data-ascii "{ 'source': '<your receipt URL>'}"
Operation-Location ヘッダーを含む 202 (Success) 応答を受信します。 このヘッダーの値に含まれる結果 ID を使用して、非同期操作の状態のクエリを実行し、結果を取得できます。
https://cognitiveservice/formrecognizer/v2.1/prebuilt/receipt/analyzeResults/<resultId>
次の例では、operations/ の後の文字列が結果 ID です。
https://cognitiveservice/formrecognizer/v2.1/prebuilt/receipt/operations/aeb13e15-555d-4f02-ba47-04d89b487ed5
レシートの結果を取得する
Analyze Receipt API を呼び出した後に Get Analyze Receipt Result API を呼び出して、操作の状態と抽出されたデータを取得します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence キーで取得したエンドポイントで置き換えます。
- <resultId> を、前の手順の結果 ID に置き換えます。
- <key> をご自分のキーに置き換えます
curl -X GET "https://<endpoint>/formrecognizer/v2.1/prebuilt/receipt/analyzeResults/<resultId>" -H "Ocp-Apim-Subscription-Key: <key>"
JSON 出力で 200 (Success) 応答を受信します。 最初のフィールド "status" は、操作の状態を示します。 操作が完了していない場合、"status" の値は "running" または "notStarted" であり、手動またはスクリプトでもう一度 API を呼び出す必要があります。 呼び出しの間隔は 1 秒以上あけることをお勧めします。
オプションの includeTextDetails パラメーターを true に設定した場合、"readResults" ノードには、認識されたすべてのテキストが格納されます。 応答は、テキストをページごとに、次に行ごとに、次に個々の単語ごとに整理します。 "documentResults" ノードには、モデルによって検出されたレシート固有の値が格納されます。 "documentResults" ノードは、税、合計、店舗の住所など、大切なキーと値のペアが存在する場所です。
次のレシートの画像とそれに対応する JSON 出力をご覧ください。

この応答本文の出力は、読みやすくするために一部省略されています。 GitHub で完全なサンプル出力を参照してください。
{
"status":"succeeded",
"createdDateTime":"2019-12-17T04:11:24Z",
"lastUpdatedDateTime":"2019-12-17T04:11:32Z",
"analyzeResult":{
"version":"2.1.0",
"readResults":[
{
"page":1,
"angle":0.6893,
"width":1688,
"height":3000,
"unit":"pixel",
"language":"en",
"lines":[
{
"text":"Contoso",
"boundingBox":[
635,
510,
1086,
461,
1098,
558,
643,
604
],
"words":[
{
"text":"Contoso",
"boundingBox":[
639,
510,
1087,
461,
1098,
551,
646,
604
],
"confidence":0.955
}
]
},
...
]
}
],
"documentResults":[
{
"docType":"prebuilt:receipt",
"pageRange":[
1,
1
],
"fields":{
"ReceiptType":{
"type":"string",
"valueString":"Itemized",
"confidence":0.692
},
"MerchantName":{
"type":"string",
"valueString":"Contoso Contoso",
"text":"Contoso Contoso",
"boundingBox":[
378.2,
292.4,
1117.7,
468.3,
1035.7,
812.7,
296.3,
636.8
],
"page":1,
"confidence":0.613,
"elements":[
"#/readResults/0/lines/0/words/0",
"#/readResults/0/lines/1/words/0"
]
},
"MerchantAddress":{
"type":"string",
"valueString":"123 Main Street Redmond, WA 98052",
"text":"123 Main Street Redmond, WA 98052",
"boundingBox":[
302,
675.8,
848.1,
793.7,
809.9,
970.4,
263.9,
852.5
],
"page":1,
"confidence":0.99,
"elements":[
"#/readResults/0/lines/2/words/0",
"#/readResults/0/lines/2/words/1",
"#/readResults/0/lines/2/words/2",
"#/readResults/0/lines/3/words/0",
"#/readResults/0/lines/3/words/1",
"#/readResults/0/lines/3/words/2"
]
},
"MerchantPhoneNumber":{
"type":"phoneNumber",
"valuePhoneNumber":"+19876543210",
"text":"987-654-3210",
"boundingBox":[
278,
1004,
656.3,
1054.7,
646.8,
1125.3,
268.5,
1074.7
],
"page":1,
"confidence":0.99,
"elements":[
"#/readResults/0/lines/4/words/0"
]
},
"TransactionDate":{
"type":"date",
"valueDate":"2019-06-10",
"text":"6/10/2019",
"boundingBox":[
265.1,
1228.4,
525,
1247,
518.9,
1332.1,
259,
1313.5
],
"page":1,
"confidence":0.99,
"elements":[
"#/readResults/0/lines/5/words/0"
]
},
"TransactionTime":{
"type":"time",
"valueTime":"13:59:00",
"text":"13:59",
"boundingBox":[
541,
1248,
677.3,
1261.5,
668.9,
1346.5,
532.6,
1333
],
"page":1,
"confidence":0.977,
"elements":[
"#/readResults/0/lines/5/words/1"
]
},
"Items":{
"type":"array",
"valueArray":[
{
"type":"object",
"valueObject":{
"Quantity":{
"type":"number",
"text":"1",
"boundingBox":[
245.1,
1581.5,
300.9,
1585.1,
295,
1676,
239.2,
1672.4
],
"page":1,
"confidence":0.92,
"elements":[
"#/readResults/0/lines/7/words/0"
]
},
"Name":{
"type":"string",
"valueString":"Cappuccino",
"text":"Cappuccino",
"boundingBox":[
322,
1586,
654.2,
1601.1,
650,
1693,
317.8,
1678
],
"page":1,
"confidence":0.923,
"elements":[
"#/readResults/0/lines/7/words/1"
]
},
"TotalPrice":{
"type":"number",
"valueNumber":2.2,
"text":"$2.20",
"boundingBox":[
1107.7,
1584,
1263,
1574,
1268.3,
1656,
1113,
1666
],
"page":1,
"confidence":0.918,
"elements":[
"#/readResults/0/lines/8/words/0"
]
}
}
},
...
]
},
"Subtotal":{
"type":"number",
"valueNumber":11.7,
"text":"11.70",
"boundingBox":[
1146,
2221,
1297.3,
2223,
1296,
2319,
1144.7,
2317
],
"page":1,
"confidence":0.955,
"elements":[
"#/readResults/0/lines/13/words/1"
]
},
"Tax":{
"type":"number",
"valueNumber":1.17,
"text":"1.17",
"boundingBox":[
1190,
2359,
1304,
2359,
1304,
2456,
1190,
2456
],
"page":1,
"confidence":0.979,
"elements":[
"#/readResults/0/lines/15/words/1"
]
},
"Tip":{
"type":"number",
"valueNumber":1.63,
"text":"1.63",
"boundingBox":[
1094,
2479,
1267.7,
2485,
1264,
2591,
1090.3,
2585
],
"page":1,
"confidence":0.941,
"elements":[
"#/readResults/0/lines/17/words/1"
]
},
"Total":{
"type":"number",
"valueNumber":14.5,
"text":"$14.50",
"boundingBox":[
1034.2,
2617,
1387.5,
2638.2,
1380,
2763,
1026.7,
2741.8
],
"page":1,
"confidence":0.985,
"elements":[
"#/readResults/0/lines/19/words/0"
]
}
}
}
]
}
}
名刺を分析する
このセクションでは、事前トレーニング済みのモデルを使用して、英語の名刺から共通フィールドを分析、抽出する方法を示します。 名刺分析の詳細については、「Document Intelligence 名刺モデル」を参照してください。 名刺の分析を開始するには、この cURL コマンドを使用して Analyze Business Card API を呼び出します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <your business card URL> を、名刺の画像の URL アドレスに置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
curl -i -X POST "https://<endpoint>/formrecognizer/v2.1/prebuilt/businessCard/analyze" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" --data-ascii "{ 'source': '<your receipt URL>'}"
Operation-Location ヘッダーを含む 202 (Success) 応答を受信します。 このヘッダーの値に含まれる結果 ID を使用して、非同期操作の状態のクエリを実行し、結果を取得できます。
https://cognitiveservice/formrecognizer/v2.1/prebuilt/businessCard/analyzeResults/<resultId>
次の例では、URL の一部として、analyzeResults/ の後の文字列が結果 ID になります。
https://cognitiveservice/formrecognizer/v2.1/prebuilt/businessCard/analyzeResults/54f0b076-4e38-43e5-81bd-b85b8835fdfb
Analyze Business Card API を呼び出した後に Get Analyze Business Card Result API を呼び出して、操作の状態と抽出されたデータを取得します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence キーで取得したエンドポイントで置き換えます。
- <resultId> を、前の手順の結果 ID に置き換えます。
- <key> をご自分のキーに置き換えます
curl -v -X GET https://<endpoint>/formrecognizer/v2.1/prebuilt/businessCard/analyzeResults/<resultId>"
-H "Ocp-Apim-Subscription-Key: <key>"
JSON 出力で 200 (Success) 応答を受信します。
"readResults" ノードには、認識されたすべてのテキストが格納されます。 応答は、テキストをページごとに、次に行ごとに、次に個々の単語ごとに整理します。 "documentResults" ノードには、モデルによって検出された名刺固有の値が格納されます。 "documentResults" ノードは、会社名、名、姓、電話番号など、有益な連絡先情報が表示される場所です。

このサンプル JSON 出力は、読みやすくするために一部省略されています。 GitHub で完全なサンプル出力を参照してください。
{
"status": "succeeded",
"createdDateTime":"2021-02-09T18:14:05Z",
"lastUpdatedDateTime":"2021-02-09T18:14:10Z",
"analyzeResult": {
"version": "2.1.0",
"readResults": [
{
"page":1,
"angle":-16.6836,
"width":4032,
"height":3024,
"unit":"pixel"
}
],
"documentResults": [
{
"docType": "prebuilt:businesscard",
"pageRange": [
1,
1
],
"fields": {
"ContactNames": {
"type": "array",
"valueArray": [
{
"type": "object",
"valueObject": {
"FirstName": {
"type": "string",
"valueString": "Avery",
"text": "Avery",
"boundingBox": [
703,
1096,
1134,
989,
1165,
1109,
733,
1206
],
"page": 1
},
"text": "Dr. Avery Smith",
"boundingBox": [
419.3,
1154.6,
1589.6,
877.9,
1618.9,
1001.7,
448.6,
1278.4
],
"confidence": 0.993
}
]
},
"Emails": {
"type": "array",
"valueArray": [
{
"type": "string",
"valueString": "avery.smith@contoso.com",
"text": "avery.smith@contoso.com",
"boundingBox": [
2107,
934,
2917,
696,
2935,
764,
2126,
995
],
"page": 1,
"confidence": 0.99
}
]
},
"Websites": {
"type": "array",
"valueArray": [
{
"type": "string",
"valueString": "https://www.contoso.com/",
"text": "https://www.contoso.com/",
"boundingBox": [
2121,
1002,
2992,
755,
3014,
826,
2143,
1077
],
"page": 1,
"confidence": 0.995
}
]
}
}
}
]
}
}
このスクリプトでは、Analyze Business Card 操作が完了するまで、コンソールに応答が出力されます。
請求書を分析する
Document Intelligence を使用して、指定された請求書ドキュメントからフィールド テキストとセマンティック値を抽出できます。 請求書の分析を開始するには、この cURL コマンドを使用します。 請求書の分析の詳細については、請求書の概念ガイドを参照してください。 請求書の分析を開始するには、この cURL コマンドを使用して Analyze Invoice API を呼び出します。
コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <your invoice URL> を、請求書ドキュメントの URL アドレスで置き換えます。
- <key> をご自分のキーに置き換えます
curl -v -i POST https://<endpoint>/formrecognizer/v2.1/prebuilt/invoice/analyze" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" --data-ascii "{'source': '<your invoice URL>'}"
Operation-Location ヘッダーを含む 202 (Success) 応答を受信します。 このヘッダーの値に含まれる結果 ID を使用して、非同期操作の状態のクエリを実行し、結果を取得できます。
https://cognitiveservice/formrecognizer/v2.1/prebuilt/receipt/analyzeResults/<resultId>
次の例では、URL の一部として、analyzeResults/ の後の文字列が結果 ID になります。
https://cognitiveservice/formrecognizer/v2.1/prebuilt/invoice/analyzeResults/54f0b076-4e38-43e5-81bd-b85b8835fdfb
Analyze Invoice API を呼び出した後に Get Analyze Invoice Result API を呼び出して、操作の状態と抽出されたデータを取得します。
コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence キーで取得したエンドポイントで置き換えます。
- <resultId> を、前の手順の結果 ID に置き換えます。
- <key> をご自分のキーに置き換えます
curl -v -X GET "https://<endpoint>/formrecognizer/v2.1/prebuilt/invoice/analyzeResults/<resultId>" -H "Ocp-Apim-Subscription-Key: <key>"
JSON 出力で 200 (Success) 応答を受信します。
"readResults"フィールドには、請求書から抽出された各テキスト行が含まれます。"pageResults"には、請求書から抽出されたテーブルと選択マークが含まれます。"documentResults"フィールドには、請求書の最も重要な部分のキーと値の情報が含まれます。
次の請求書ドキュメントとそれに対応する JSON 出力をご覧ください。
この応答本文 JSON コンテンツは、読みやすくするために一部省略されています。 GitHub で完全なサンプル出力を参照してください。
{
"status": "succeeded",
"createdDateTime": "2020-11-06T23:32:11Z",
"lastUpdatedDateTime": "2020-11-06T23:32:20Z",
"analyzeResult": {
"version": "2.1.0",
"readResults": [{
"page": 1,
"angle": 0,
"width": 8.5,
"height": 11,
"unit": "inch"
}],
"pageResults": [{
"page": 1,
"tables": [{
"rows": 3,
"columns": 4,
"cells": [{
"rowIndex": 0,
"columnIndex": 0,
"text": "QUANTITY",
"boundingBox": [0.4953,
5.7306,
1.8097,
5.7306,
1.7942,
6.0122,
0.4953,
6.0122]
},
{
"rowIndex": 0,
"columnIndex": 1,
"text": "DESCRIPTION",
"boundingBox": [1.8097,
5.7306,
5.7529,
5.7306,
5.7452,
6.0122,
1.7942,
6.0122]
},
...
],
"boundingBox": [0.4794,
5.7132,
8.0158,
5.714,
8.0118,
6.5627,
0.4757,
6.5619]
},
{
"rows": 2,
"columns": 6,
"cells": [{
"rowIndex": 0,
"columnIndex": 0,
"text": "SALESPERSON",
"boundingBox": [0.4979,
4.963,
1.8051,
4.963,
1.7975,
5.2398,
0.5056,
5.2398]
},
{
"rowIndex": 0,
"columnIndex": 1,
"text": "P.O. NUMBER",
"boundingBox": [1.8051,
4.963,
3.3047,
4.963,
3.3124,
5.2398,
1.7975,
5.2398]
},
...
],
"boundingBox": [0.4976,
4.961,
7.9959,
4.9606,
7.9959,
5.5204,
0.4972,
5.5209]
}]
}],
"documentResults": [{
"docType": "prebuilt:invoice",
"pageRange": [1,
1],
"fields": {
"AmountDue": {
"type": "number",
"valueNumber": 610,
"text": "$610.00",
"boundingBox": [7.3809,
7.8153,
7.9167,
7.8153,
7.9167,
7.9591,
7.3809,
7.9591],
"page": 1,
"confidence": 0.875
},
"BillingAddress": {
"type": "string",
"valueString": "123 Bill St, Redmond WA, 98052",
"text": "123 Bill St, Redmond WA, 98052",
"boundingBox": [0.594,
4.3724,
2.0125,
4.3724,
2.0125,
4.7125,
0.594,
4.7125],
"page": 1,
"confidence": 0.997
},
"BillingAddressRecipient": {
"type": "string",
"valueString": "Microsoft Finance",
"text": "Microsoft Finance",
"boundingBox": [0.594,
4.1684,
1.7907,
4.1684,
1.7907,
4.2837,
0.594,
4.2837],
"page": 1,
"confidence": 0.998
},
...
}
}]
}
}
身分証明書を分析する
身分証明書 (ID ドキュメント) の分析を開始するには、この cURL コマンドを使用します。 ID ドキュメント分析の詳細については、「Document Intelligence ID ドキュメント モデル」を参照してください。 身分証明書の分析を開始するには、この cURL コマンドを使用して Analyze ID Document API を呼び出します。
コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <your ID document URL> を、ID ドキュメントの画像の URL アドレスに置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
curl -i -X POST "https://<endpoint>/formrecognizer/v2.1/prebuilt/idDocument/analyze" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" --data-ascii "{ 'source': '<your ID document URL>'}"
Operation-Location ヘッダーを含む 202 (Success) 応答を受信します。 このヘッダーの値に含まれる結果 ID を使用して、非同期操作の状態のクエリを実行し、結果を取得できます。
https://cognitiveservice/formrecognizer/v2.1/prebuilt/documentId/analyzeResults/<resultId>
次の例では、analyzeResults/ の後の文字列が結果 ID です。
https://westus.api.cognitive.microsoft.com/formrecognizer/v2.1/prebuilt/idDocument/analyzeResults/3bc1d6e0-e24c-41d2-8c50-14e9edc336d1
Analyze ID Document の結果を取得する
Analyze ID Document API を呼び出した後に Get Analyze ID Document Result API を呼び出して、操作の状態と抽出されたデータを取得します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence キーで取得したエンドポイントで置き換えます。
- <resultId> を、前の手順の結果 ID に置き換えます。
- <key> をご自分のキーに置き換えます
curl -X GET "https://<endpoint>/formrecognizer/v2.1/prebuilt/idDocument/analyzeResults/<resultId>" -H "Ocp-Apim-Subscription-Key: <key>"
JSON 出力で 200 (Success) 応答を受信します。 最初のフィールド "status" は、操作の状態を示します。 操作が完了していない場合、"status" の値は "running" または "notStarted"です。 succeeded の値を受け取るまで、手動またはスクリプトを使用して、API をもう一度呼び出します。 呼び出しの間隔は 1 秒以上あけることをお勧めします。
"readResults"フィールドには、身分証明書から抽出されたすべてのテキスト行が含まれます。"documentResults"フィールドには、入力ドキュメント内で検出された身分証明書をそれぞれ表すオブジェクトの配列が含まれます。
サンプルの身分証明書とそれに対応する JSON 出力を以下に示します

応答本文を次に示します。
{
"status": "succeeded",
"createdDateTime": "2021-04-13T17:24:52Z",
"lastUpdatedDateTime": "2021-04-13T17:24:55Z",
"analyzeResult": {
"version": "2.1.0",
"readResults": [
{
"page": 1,
"angle": -0.2823,
"width": 450,
"height": 294,
"unit": "pixel"
}
],
"documentResults": [
{
"docType": "prebuilt:idDocument:driverLicense",
"docTypeConfidence": 0.995,
"pageRange": [
1,
1
],
"fields": {
"Address": {
"type": "string",
"valueString": "123 STREET ADDRESS YOUR CITY WA 99999-1234",
"text": "123 STREET ADDRESS YOUR CITY WA 99999-1234",
"boundingBox": [
158,
151,
326,
151,
326,
177,
158,
177
],
"page": 1,
"confidence": 0.965
},
"CountryRegion": {
"type": "countryRegion",
"valueCountryRegion": "USA",
"confidence": 0.99
},
"DateOfBirth": {
"type": "date",
"valueDate": "1958-01-06",
"text": "01/06/1958",
"boundingBox": [
187,
133,
272,
132,
272,
148,
187,
149
],
"page": 1,
"confidence": 0.99
},
"DateOfExpiration": {
"type": "date",
"valueDate": "2020-08-12",
"text": "08/12/2020",
"boundingBox": [
332,
230,
414,
228,
414,
244,
332,
245
],
"page": 1,
"confidence": 0.99
},
"DocumentNumber": {
"type": "string",
"valueString": "LICWDLACD5DG",
"text": "LIC#WDLABCD456DG",
"boundingBox": [
162,
70,
307,
68,
307,
84,
163,
85
],
"page": 1,
"confidence": 0.99
},
"FirstName": {
"type": "string",
"valueString": "LIAM R.",
"text": "LIAM R.",
"boundingBox": [
158,
102,
216,
102,
216,
116,
158,
116
],
"page": 1,
"confidence": 0.985
},
"LastName": {
"type": "string",
"valueString": "TALBOT",
"text": "TALBOT",
"boundingBox": [
160,
86,
213,
85,
213,
99,
160,
100
],
"page": 1,
"confidence": 0.987
},
"Region": {
"type": "string",
"valueString": "Washington",
"confidence": 0.99
},
"Sex": {
"type": "string",
"valueString": "M",
"text": "M",
"boundingBox": [
226,
190,
232,
190,
233,
201,
226,
201
],
"page": 1,
"confidence": 0.99
}
}
}
]
}
}
カスタム モデルをトレーニングする
カスタム モデルをトレーニングするには、Azure Storage BLOB 内にトレーニング データのセットが必要です。 同じ種類または構造の入力済みフォーム (PDF ドキュメントや画像) が少なくとも 5 つ必要です。 トレーニング データをまとめるためのヒントとオプションについては、「カスタム モデルを構築してトレーニング データする」を参照してください。
ラベル付けされたデータを使用しないトレーニングが既定の操作であり、その方が単純です。 トレーニング データの一部またはすべてにあらかじめ手動でラベルを付けることもできます。 手動のラベル付けは複雑なプロセスですが、トレーニングされたモデルの精度が向上します。
Note
また、Document Intelligence のサンプル ラベル付けツールなどのグラフィカル ユーザー インターフェイスを使用してモデルをトレーニングすることもできます。
ラベルなしでモデルをトレーニングする
Azure BLOB コンテナー内のドキュメントを使用して Document Intelligence モデルをトレーニングするには、次の cURL コマンドを実行して、[Train Custom Model] API を呼び出します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
- <SAS URL> を Azure Blob ストレージ コンテナーの共有アクセス署名 (SAS) URL に置き換えます。
カスタム モデル トレーニング データの SAS URL を取得するには、
Azure portal のストレージ リソースに移動し、[データ ストレージ]>[コンテナー] を選択します。
ご自分のコンテナーに移動し、右クリックして [SAS の生成] を選択します。
ストレージ アカウント自体ではなく、ご自分のコンテナー用の SAS を取得することが重要です。
[読み取り]、[書き込み]、[削除]、[リスト] の各アクセス許可が選択されていることを確認し、[SAS トークンと URL の生成] を選択します。
URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。
変更を行い、コマンドを実行します。
curl -i -X POST "https://<endpoint>/formrecognizer/v2.1/custom/models" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" --data-ascii "{ 'source': '<SAS URL>'}"
Location ヘッダーのある 201 (Success) 応答を受信します。 このヘッダーの値に含まれる、新しくトレーニングされたモデルのモデル ID を使用して、操作の状態のクエリを実行し、結果を取得できます。
https://<endpoint>/formrecognizer/v2.1/custom/models/<modelId>
次の例では、URL の一部として、models/ の後の文字列がモデル ID になります。
https://westus.api.cognitive.microsoft.com/formrecognizer/v2.1/custom/models/77d8ecad-b8c1-427e-ac20-a3fe4af503e9
ラベルを使用してモデルをトレーニングする
ラベルを使用してトレーニングするには、トレーニング ドキュメントと共に、BLOB ストレージ コンテナーに特別なラベル情報ファイル (<filename>.pdf.labels.json) を用意する必要があります。 Document Intelligence のサンプル ラベル付けツールでは、これらのラベル ファイルの作成を支援する UI が提供されています。 それらを用意したら、Train Custom Model API を呼び出します。JSON 本文で "useLabelFile" パラメーターを true に設定してください。
コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
- <SAS URL> を Azure Blob ストレージ コンテナーの共有アクセス署名 (SAS) URL に置き換えます。
カスタム モデル トレーニング データの SAS URL を取得するには、
Azure portal のストレージ リソースに移動し、[データ ストレージ]>[コンテナー] を選択します。 ご自分のコンテナーに移動し、右クリックして [SAS の生成] を選択します。
ストレージ アカウント自体ではなく、ご自分のコンテナー用の SAS を取得することが重要です。
[読み取り]、[書き込み]、[削除]、[リスト] の各アクセス許可が選択されていることを確認し、[SAS トークンと URL の生成] を選択します。
URL セクションの値を一時的な場所にコピーします。 それは次の書式になります
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>。
変更を行い、コマンドを実行します。
curl -i -X POST "https://<endpoint>/formrecognizer/v2.1/custom/models" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" --data-ascii "{ 'source': '<SAS URL>', 'useLabelFile':true}"
Location ヘッダーのある 201 (Success) 応答を受信します。 このヘッダーの値に含まれる、新しくトレーニングされたモデルのモデル ID を使用して、操作の状態のクエリを実行し、結果を取得できます。
https://<endpoint>/formrecognizer/v2.1/custom/models/<modelId>
次の例では、URL の一部として、models/ の後の文字列がモデル ID になります。
https://westus.api.cognitive.microsoft.com/formrecognizer/v2.1/custom/models/62e79d93-78a7-4d18-85be-9540dbb8e792
トレーニング操作の開始後、Get Custom Model を使用して、トレーニングの状態を確認します。 この API 要求にモデル ID を渡して、トレーニングの状態を確認します。
- <endpoint> を、Document Intelligence キーで取得したエンドポイントで置き換えます。
- <key> をご自分のキーに置き換えます
- <model ID> を、前の手順で受信したモデル ID で置き換えます
curl -X GET "https://<endpoint>/formrecognizer/v2.1/custom/models/<modelId>" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>"
カスタム モデルを使用してフォームを分析する
次に、新しくトレーニングしたモデルを使用してドキュメントを分析し、そこからフィールドおよびテーブルを抽出します。 次の cURL コマンドを実行して、 Analyze Form API を呼び出します。 コマンドを実行する前に、次の変更を行います。
- <endpoint> を、Document Intelligence キーで取得したエンドポイントで置き換えます。
- <model ID> を、前のセクションで受信したモデル ID で置き換えます。
- <SAS URL> を、Azure Storage にあるご自分のファイルの SAS URL に置き換えます。 「トレーニング」セクションの手順に従いますが、取得するのは、BLOB コンテナー全体の SAS URL ではなく、分析対象となる特定のファイルの SAS URL です。
- <key> をご自分のキーに置き換えます
curl -v "https://<endpoint>/formrecognizer/v2.1/custom/models/<modelId>/analyze?includeTextDetails=true" -H "Content-Type: application/json" -H "Ocp-Apim-Subscription-Key: <key>" -d "{ 'source': '<SAS URL>' } "
Operation-Location ヘッダーのある 202 (Success) 応答を受信します。 このヘッダーの値は、分析操作の結果を追跡するために使用する結果 ID を含みます。
https://cognitiveservice/formrecognizer/v2.1/custom/models/<modelId>/analyzeResults/<resultId>
次の例では、URL の一部として、analyzeResults/ の後の文字列が結果 ID になります。
https://cognitiveservice/formrecognizer/v2/layout/analyzeResults/e175e9db-d920-4c7d-bc44-71d1653cdd06
次の手順で使用できるように、この結果 ID を保存します。
分析操作の結果を照会するには、Analyze Form Result API を呼び出します。
- <endpoint> を、Document Intelligence キーで取得したエンドポイントで置き換えます。
- <result ID> を、前のセクションで受信した ID で置き換えます。
- <key> をご自分のキーに置き換えます
curl -X GET "https://<endpoint>/formrecognizer/v2.1/custom/models/<modelId>/analyzeResults/<resultId>" -H "Ocp-Apim-Subscription-Key: <key>"
次の形式の JSON 本文を含む 200 (Success) 応答が送られてきます。 出力は、簡素化するために一部省略されています。 下部の近くにある "status" フィールドにご注意ください。 分析操作が完了すると、このフィールドに "succeeded" 値が表示されます。 分析操作が完了していない場合は、コマンドを再実行して、サービスに対して再度クエリを実行する必要があります。 呼び出しの間隔は 1 秒以上あけることをお勧めします。
ラベル付けを使用せずにトレーニングしたカスタム モデルでは、キーと値のペアの関連付けとテーブルが JSON 出力の "pageResults" ノードに存在します。 ラベル付けを使用してトレーニングしたカスタム モデルでは、キーと値のペアの関連付けが "documentResults" ノードに存在します。 includeTextDetails URL パラメーターを使用してプレーンテキスト抽出を指定した場合、"readResults" ノードには、ドキュメント内のすべてのテキストの内容と位置が表示されます。
このサンプル JSON 出力は、簡素化するために一部省略されています。 GitHub で完全なサンプル出力を参照してください。
{
"status": "succeeded",
"createdDateTime": "2020-08-21T01:13:28Z",
"lastUpdatedDateTime": "2020-08-21T01:13:42Z",
"analyzeResult": {
"version": "2.1.0",
"readResults": [
{
"page": 1,
"angle": 0,
"width": 8.5,
"height": 11,
"unit": "inch",
"lines": [
{
"text": "Project Statement",
"boundingBox": [
5.0444,
0.3613,
8.0917,
0.3613,
8.0917,
0.6718,
5.0444,
0.6718
],
"words": [
{
"text": "Project",
"boundingBox": [
5.0444,
0.3587,
6.2264,
0.3587,
6.2264,
0.708,
5.0444,
0.708
]
},
{
"text": "Statement",
"boundingBox": [
6.3361,
0.3635,
8.0917,
0.3635,
8.0917,
0.6396,
6.3361,
0.6396
]
}
]
},
...
]
}
],
"pageResults": [
{
"page": 1,
"keyValuePairs": [
{
"key": {
"text": "Date:",
"boundingBox": [
6.9833,
1.0615,
7.3333,
1.0615,
7.3333,
1.1649,
6.9833,
1.1649
],
"elements": [
"#/readResults/0/lines/2/words/0"
]
},
"value": {
"text": "9/10/2020",
"boundingBox": [
7.3833,
1.0802,
7.925,
1.0802,
7.925,
1.174,
7.3833,
1.174
],
"elements": [
"#/readResults/0/lines/3/words/0"
]
},
"confidence": 1
},
...
],
"tables": [
{
"rows": 5,
"columns": 5,
"cells": [
{
"text": "Training Date",
"rowIndex": 0,
"columnIndex": 0,
"boundingBox": [
0.6944,
4.2779,
1.5625,
4.2779,
1.5625,
4.4005,
0.6944,
4.4005
],
"confidence": 1,
"rowSpan": 1,
"columnSpan": 1,
"elements": [
"#/readResults/0/lines/15/words/0",
"#/readResults/0/lines/15/words/1"
],
"isHeader": true,
"isFooter": false
},
...
]
}
],
"clusterId": 0
}
],
"documentResults": [],
"errors": []
}
}
結果を改善する
"pageResults" ノードの下で、キーと値形式の結果ごとに "confidence" 値を調べます。 また、"readResults" ノード内の信頼度スコアにも注目してください。こちらはテキスト読み取り操作に対応します。 読み取り結果の信頼度は、キーと値の抽出結果の信頼度には影響しません。したがって両方を確認する必要があります。
- 読み取り操作の信頼度スコアが低い場合は、入力ドキュメントの品質の改善を試みてください。 詳細については、「入力の要件」を参照してください。
- キーと値の抽出操作の信頼度スコアが低い場合は、分析対象となるドキュメントの種類が、トレーニング セットで使用されているドキュメントと同じであることを確認してください。 トレーニング セットに含まれるドキュメントの体裁にばらつきがある場合は、別々のフォルダーに分けて、バリエーションごとに 1 つのモデルをトレーニングすることを検討してください。
目標とする信頼度スコアは、実際のユース ケースによって異なりますが、一般には、80% 以上のスコアを目標にするのがよいでしょう。 医療記録や請求書の読み取りなど、もっと正確さが要求されるケースでは、100% のスコアが推奨されます。
カスタム モデルを管理する
次のコマンドでは、 List Custom Models API を使用して、サブスクリプションに属しているすべてのカスタム モデルのリストを返します。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
curl -v -X GET "https://<endpoint>/formrecognizer/v2.1/custom/models?op=full"
-H "Ocp-Apim-Subscription-Key: <key>"
次のような JSON データを含む 200 成功応答が返されます。 "modelList" 要素には、作成したすべてのモデルとその情報が含まれています。
{
"summary": {
"count": 0,
"limit": 0,
"lastUpdatedDateTime": "string"
},
"modelList": [
{
"modelId": "string",
"status": "creating",
"createdDateTime": "string",
"lastUpdatedDateTime": "string"
}
],
"nextLink": "string"
}
特定のモデルを取得する
特定のカスタム モデルに関する詳細情報を取得するために、次のコマンドでは、 Get Custom Model API を使用します。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
- <modelId> を、検索するカスタム モデルの ID で置き換えます。
curl -v -X GET "https://<endpoint>/formrecognizer/v2.1/custom/models/<modelId>" -H "Ocp-Apim-Subscription-Key: <key>"
次のような要求本文 JSON データを含む 200 成功応答が返されます。
{
"modelInfo": {
"modelId": "string",
"status": "creating",
"createdDateTime": "string",
"lastUpdatedDateTime": "string"
},
"keys": {
"clusters": {}
},
"trainResult": {
"trainingDocuments": [
{
"documentName": "string",
"pages": 0,
"errors": [
"string"
],
"status": "succeeded"
}
],
"fields": [
{
"fieldName": "string",
"accuracy": 0.0
}
],
"averageModelAccuracy": 0.0,
"errors": [
{
"message": "string"
}
]
}
}
リソース アカウントからモデルを削除する
ID を参照して、アカウントからモデルを削除することもできます。 このコマンドは Delete Custom Model API を呼び出して、前のセクションで使用したモデルを削除します。
- <endpoint> を、Document Intelligence サブスクリプションで取得したエンドポイントで置き換えます。
- <key> を、前の手順からコピーしたキーに置き換えます。
- <modelId> を、検索するカスタム モデルの ID で置き換えます。
curl -v -X DELETE "https://<endpoint>/formrecognizer/v2.1/custom/models/<modelId>" -H "Ocp-Apim-Subscription-Key: <key>"
モデルが削除対象としてマークされたことを示す 204 成功応答が返されます。 モデル成果物は、48 時間以内に削除されます。
次のステップ
このプロジェクトでは、Document Intelligence REST API を使用して、さまざまな方法でフォームを分析しました。 次に、Document Intelligence API の詳細を把握するためにリファレンス ドキュメントを探索します。