Hadoop 分散ファイル システム (HDFS) は、汎用サーバーの大規模なクラスターにまたがることが可能な信頼性の高いスケーラブルなデータ ストレージを提供する、Java ベースの分散ファイル システムです。 この記事では、HDFS の概要と、それを Azure に移行するためのガイドを提供します。
Apache®、Apache Spark®、Apache Hadoop®、Apache Hive、および炎のロゴは、Apache Software Foundation の米国およびその他の国における登録商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
HDFS のアーキテクチャとコンポーネント
HDFS は、プライマリ/セカンダリの設計になっています。 次の図では、NameNode がプライマリで、DataNode がセカンダリです。
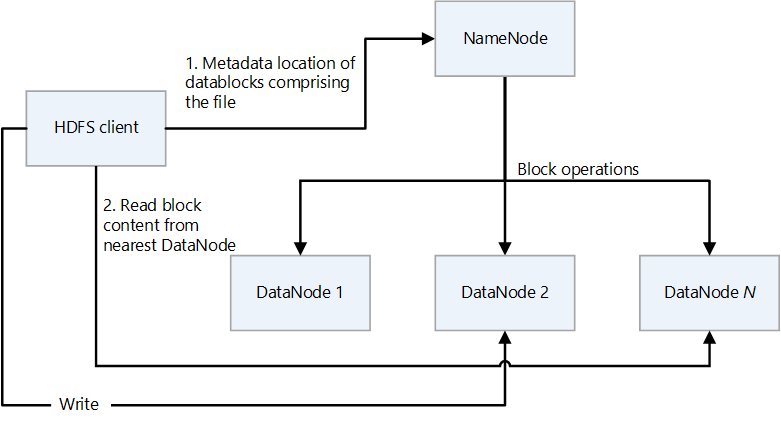
- NameNode は、ファイルと、ディレクトリの階層であるファイル システム名前空間へのアクセスを管理します。
- ファイルとディレクトリは NameNode 上のノードです。 これらには、アクセス許可、変更とアクセスの時間、名前空間とディスク領域のサイズ クォータなどの属性があります。
- ファイルは複数のブロックで構成されます。 既定のブロック サイズは 128 メガバイトです。 hdfs-site.xml ファイルを変更することで、クラスターの既定以外のブロック サイズを設定できます。
- ファイルの各ブロックは、複数の DataNode で個別にレプリケートされます。 レプリケーション係数の既定値は 3 ですが、クラスターごとに既定値以外の独自の値を設定できます。 レプリケーション係数はいつでも変更できます。 変更により、クラスターの再調整が発生します。
- NameNode では、名前空間ツリーと、DataNode へのファイル ブロックのマッピング (ファイル データの物理的な場所) が保持されます。
- HDFS クライアントがファイルを読み取る場合:
- ファイルのデータ ブロックの場所を NameNode に問い合わせます。
- 最も近い DataNode からブロックの内容を読み取ります。
- HDFS では名前空間全体が RAM に保持されます。
- DataNode は、ファイル システムに対して読み取り操作と書き込み操作を実行し、作成、レプリケーション、削除などのブロック操作を実行するセカンダリ ノードです。
- DataNode には、格納されているファイルのチェックサムを保持するメタデータ ファイルが含まれています。 DataNode によってホストされているブロック レプリカごとに、レプリカに関するメタデータ (そのチェックサム情報など) を含む対応するメタデータ ファイルがあります。 メタデータ ファイルのベース名はブロック ファイルと同じで、拡張子は .meta です。
- DataNode には、ブロックのデータを保持するデータ ファイルが含まれています。
- DataNode では、ファイルを読み取ると、NameNode からブロックの場所とレプリカの場所をフェッチし、最も近い場所からの読み取りを試みます。
- HDFS クラスターには、クラスターあたり数千の DataNode と数万の HDFS クライアントを含めることができます。 各 DataNode では、複数のアプリケーション タスクを同時に実行できます。
- ブロックが DataNodes に書き込まれると、HDFS 書き込みパイプラインの一部としてエンドツーエンドのチェックサム計算が実行されます。
- HDFS クライアントは、アプリケーションがファイルへのアクセスに使用するクライアントです。
- これは、HDFS ファイル システム インターフェイスをエクスポートするコード ライブラリです。
- これにより、ファイルの読み取り、書き込み、削除の操作と、ディレクトリを作成および削除する操作がサポートされます。
- アプリケーションでファイルを読み取ると、次の手順が実行されます。
- NameNode から、DataNode の一覧と、ファイル ブロックを保持する場所を取得します。 一覧にはレプリカが含まれます。
- このリストを使用して、要求されたブロックを DataNode から取得します。
- HDFS には、ファイル ブロックの場所を公開する API が用意されています。 これにより、MapReduce フレームワークなどのアプリケーションで、読み取りパフォーマンスを最適化するために、データがある場所で実行するタスクをスケジュールできます。
機能マップ
Azure Blob Filesystem (ABFS) ドライバーには、Azure Data Lake Storage が HDFS ファイル システムとして機能できるようにするインターフェイスがあります。 次の表では、ABFS ドライバーと Data Lake Storage のコア機能を HDFS の機能と比較しています。
| 機能 | ABFS ドライバーと Data Lake Storage | HDFS |
|---|---|---|
| Hadoop と互換性のあるアクセス | HDFS を利用する場合と同様に、データの管理とアクセスを行うことができます。 ABFS ドライバーは、Azure HDInsight や Azure Databricks を含むすべての Apache Hadoop 環境で使用できます。 | MapR クラスターは、hdfs:// または webhdfs:// プロトコルを使用して外部 HDFS クラスターにアクセスできます |
| POSIX アクセス許可 | Data Lake Gen2 のセキュリティ モデルは、アクセス制御リスト (ACL) および POSIX のアクセス許可に加え、Data Lake Storage Gen2 固有の追加設定をサポートしています。 設定は、管理ツールまたはフレームワーク (Apache Hive や Apache Spark など) を使用して構成できます。 | 厳密にアトミックなディレクトリの名前変更、詳細な HDFS アクセス許可、HDFS シンボリック リンクなどのファイル システム機能を必要とするジョブは、HDFS でのみ動作します。 |
| コスト効率 | Data Lake Storage は、低コストのストレージ容量とトランザクションを備えています。 Azure Blob Storage のライフサイクルは、データのライフサイクルの進展に応じて請求金額を調整することで、コストの削減に役立ちます。 | |
| 最適化されたドライバー | ABFS ドライバーは、ビッグ データ分析のために最適化されています。 対応する REST API は、分散ファイル システム (DFS) エンドポイント dfs.core.windows.net を通じて提供されます。 |
|
| ブロック サイズ | ブロック は、単一の Append API 呼び出し ( Append API によって新しいブロックが作成されます) と同等であり、呼び出しあたり 100 MB に制限されます。 ただし、書き込みパターンでは、ファイルごとに (並列でも) Append を何度も呼び出し (最大 50,000 回)、その後 Flush (PutBlockList と同等) を呼び出すことができます。 これは、4.75 TB の最大ファイル サイズを実現する方法です。 | HDFS では、データはデータ ブロックに格納されます。 ブロック サイズを設定する場合は、Hadoop ディレクトリの hdfs-site.xml ファイルに値を設定します。 既定のサイズは 128 MB です。 |
| 既定の ACLS | ファイルには既定の ACL がなく、既定では有効になっていません。 | ファイルには既定の ACL がありません。 |
| バイナリ ファイル | バイナリ ファイルは、非階層型名前空間の Azure Blob Storage に移動できます。 Azure Storage REST API、Azure PowerShell、Azure CLI、または Azure Storage クライアント ライブラリを使用して、Blob Storage 内のオブジェクトにアクセスできます。 .NET、Java、Node.js、Python、Go、PHP、Ruby などのさまざまな言語のクライアント ライブラリを利用できます。 | Hadoop にはバイナリ ファイルの読み取りと書き込みを行う機能があります。 SequenceFile は、バイナリ キーと値のペアで構成されるフラット ファイルです。 SequenceFile には、書き込み、読み取り、並べ替えのための Writer、Reader、Sorter クラスが用意されています。 画像またはビデオ ファイルを SequenceFile に変換し、HDFS に格納します。 次に、HDFS SequenceFileReader/Writer メソッドまたは put コマンド bin/hadoop fs -put /src_image_file /dst_image_file を使用します。 |
| アクセス許可の継承 | Data Lake Storage では POSIX スタイルのモデルを使用し、ACL でオブジェクトへのアクセスを制御する場合は Hadoop と同じように動作します。 詳細については、Data Lake Storage Gen2 でのアクセス制御 (ACL) に関するページを参照してください。 | 項目のアクセス許可は項目自体に格納され、項目の存在後に継承されません。 子項目が作成される前に、親項目で既定のアクセス許可が設定されている場合にのみ、アクセス許可が継承されます。 |
| データのレプリケーション | Azure Storage アカウントのデータは、プライマリ リージョンで 3 回レプリケートされます。 推奨されるレプリケーション オプションは、ゾーン冗長ストレージです。 これにより、プライマリ リージョンの 3 つの Azure 可用性ゾーン間で同期的にレプリケートされます。 | 既定では、ファイルのレプリケーション係数は 3 です。 重要なファイルや頻繁にアクセスされるファイルの場合、レプリケーション係数が高いほどフォールト トレランスが向上し、読み取り帯域幅が増加します。 |
| スティッキー ビット | Data Lake Storage のコンテキストでは、スティッキー ビットが必要になることはあまりありません。 つまり、ディレクトリでスティッキー ビットが有効になっている場合、子項目を削除または名前変更できるのは、子項目を所有しているユーザーのみです。 スティッキー ビットは、Azure portal には表示されません。 | スティッキー ビットは、スーパーユーザー、ディレクトリ所有者、またはファイル所有者を除くすべてのユーザーがディレクトリ内のファイルを削除または移動できないように、ディレクトリに設定できます。 ファイルにスティッキー ビットを設定しても効果はありません。 |
オンプレミス HDFS の一般的な課題
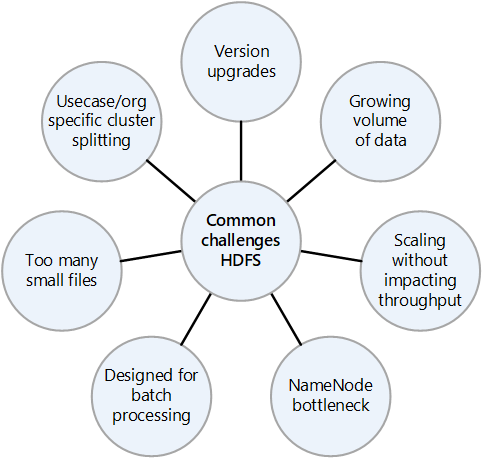
オンプレミスの HDFS 実装がもたらす多くの課題は、クラウドへの移行の利点を考慮する理由になることがあります。
- HDFS バージョンの頻繁なアップグレード
- 増え続けるデータ量
- クラスター内のすべてのファイルのメタデータを制御する NameNode の負荷を高める小さなファイルが多数存在すること。 多くの場合、ファイルが多いほど、クライアントがファイルを読み取るときに NameNode の読み取りトラフィックが増え、クライアントが書き込むときに呼び出しが増えます。
- 組織内の複数のチームが異なるデータセットを必要とする場合、HDFS クラスターをユース ケースまたは組織別に分割することはできません。 その結果、データの重複が増加することから、コストが増加し、効率が低下します。
- HDFS クラスターがスケールアップまたはスケールアウトされると、NameNode がパフォーマンスのボトルネックになる可能性があります。
- Hadoop 2.0 より前では、すべてのメタデータが 1 つの NameNode に格納されているため、HDFS クラスターに対するすべてのクライアント要求が最初に NameNode を通過していました。 この設計により、NameNode がボトルネックになり、単一障害点になる可能性があります。 NameNode に障害が発生した場合、クラスターが使用できなくなります。
移行に関する注意事項
HDFS から Data Lake Storage への移行を計画する際に考慮する必要があるいくつかの点を次に示します。
- 小さなファイル内のデータを、Data Lake Storage 上の 1 つのファイルに集計することを検討してください。
- HDFS 内のすべてのディレクトリ構造を一覧表示し、Data Lake Storage で同様のゾーニングをレプリケートします。 HDFS のディレクトリ構造を取得するには、
hdfs -lsコマンドを使用できます。 - ターゲット環境でレプリケートできるように、HDFS クラスターで定義されているすべてのロールを一覧表示します。
- HDFS に格納されているファイルのデータ ライフサイクル ポリシーに注意してください。
- 次のような HDFS の一部のシステム機能は、Data Lake Storage で使用できないことに注意してください。
- 厳密にアトミックなディレクトリの名前変更
- 詳細な HDFS アクセス許可
- HDFS シンボリックリンク
- Azure Storage には geo 冗長レプリケーションがありますが、それを使用することが常に賢明とは限りません。 これによって、データの冗長性が高まり、災害発生時には別の拠点でデータを回復できますが、より離れた場所へのフェールオーバーによってパフォーマンスが大幅に低下し、追加のコストが発生する可能性があります。 データの可用性を高めるだけの価値があるか検討してください。
- ファイルに同じプレフィックスを持つ名前がある場合、HDFS はそれらを 1 つのパーティションとして扱います。 したがって、Azure Data Factory を使用する場合は、すべてのデータ移動単位 (DTU) が 1 つのパーティションに書き込まれます。
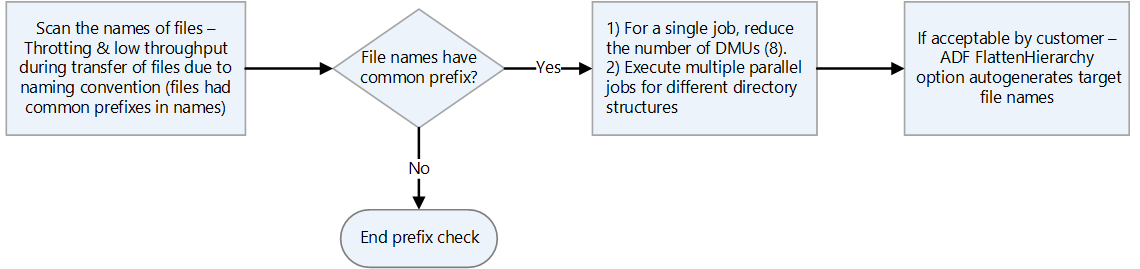
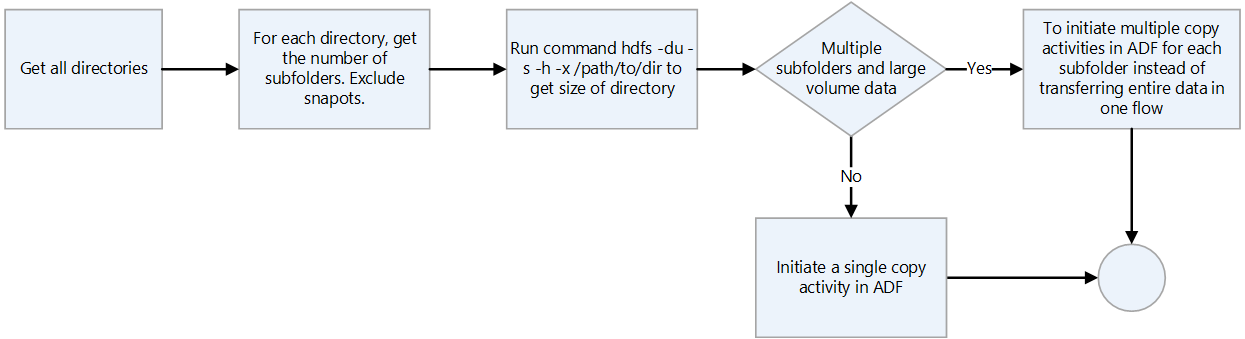
- データ転送に Data Factory を使用する場合は、スナップショットを除く各ディレクトリをスキャンし、
hdfs duコマンドを使用してディレクトリ サイズを確認します。 複数のサブディレクトリと大量のデータがある場合は、Data Factory で複数のコピー アクティビティを開始します。 たとえば、1 つのコピー アクティビティを使用してディレクトリ全体を転送するのではなく、サブディレクトリごとに 1 つのコピーを使用します。
- データ プラットフォームは、記録システムから削除された可能性のある情報の長期的な保持のためによく使用されます。 アーカイブされたデータのテープ バックアップまたはスナップショットを作成する計画を立てる必要があります。 復旧サイトに情報をレプリケートすることを検討してください。 通常、データはコンプライアンスまたは履歴データの目的でアーカイブされます。 データをアーカイブする前に、データを保持する明確な理由が必要です。 また、アーカイブされたデータを削除するタイミングを決定し、その時点で削除するプロセスを確立します。
- Data Lake Storage のアーカイブ アクセス層は低コストであるため、データをアーカイブするための魅力的なオプションになります。 詳しくは、「アーカイブ アクセス層」をご覧ください。
- HDFS クライアントが ABFS ドライバーを使用して Blob Storage にアクセスする場合、クライアントによって使用されるメソッドがサポートされておらず、AzureNativeFileSystem が UnsupportedOperationException をスローする事例が発生する可能性があります。 たとえば、
append(Path f, int bufferSize, Progressable progress)は現在サポートされていません。 ABFS ドライバーに関連する問題を確認するには、 Hadoop の機能と修正を参照してください。 - 古い Hadoop クラスターで使用する ABFS ドライバーのバックポート バージョンがあります。 詳細については、「ABFS ドライバーのバックポート」を参照してください。
- Azure 仮想ネットワーク環境では、DistCp ツールは、Azure Storage 仮想ネットワーク エンドポイントとの Azure ExpressRoute プライベート ピアリングがサポートされていません。 詳細については、「Azure Data Factory を使用してオンプレミスの Hadoop クラスターから Azure Storage にデータを移行する」を参照してください。
移行のアプローチ
HDFS を Data Lake Storage に移行する一般的な方法では、次の手順を使用します。

HDFS の評価
オンプレミスの評価スクリプトでは、Azure に移行できるワークロードと、データを一度にすべて移行するか、一度に 1 つずつ移行するかを判断するのに役立つ情報が提供されます。 Unravel などのサードパーティ製ツールでは、メトリックが提供され、オンプレミスの HDFS の自動評価をサポートできます。 計画する際に考慮すべき重要な要素には、次のようなものがあります。
- データ ボリューム
- ビジネスへの影響
- データの所有権
- 処理の複雑さ
- 抽出、変換、読み込み (ETL) の複雑さ
- 個人を特定できる情報 (PII) およびその他の機密データ
このような要素に基づいて、ダウンタイムとビジネスの中断を最小限に抑える Azure にデータを移動する計画を作成できます。 おそらく機密データはオンプレミスのままになります。 増分読み込みを移動する前に、履歴データを移動してテストできます。
次の決定フローは、適切な情報を取得するための条件と実行するコマンドを決定するのに役立ちます。
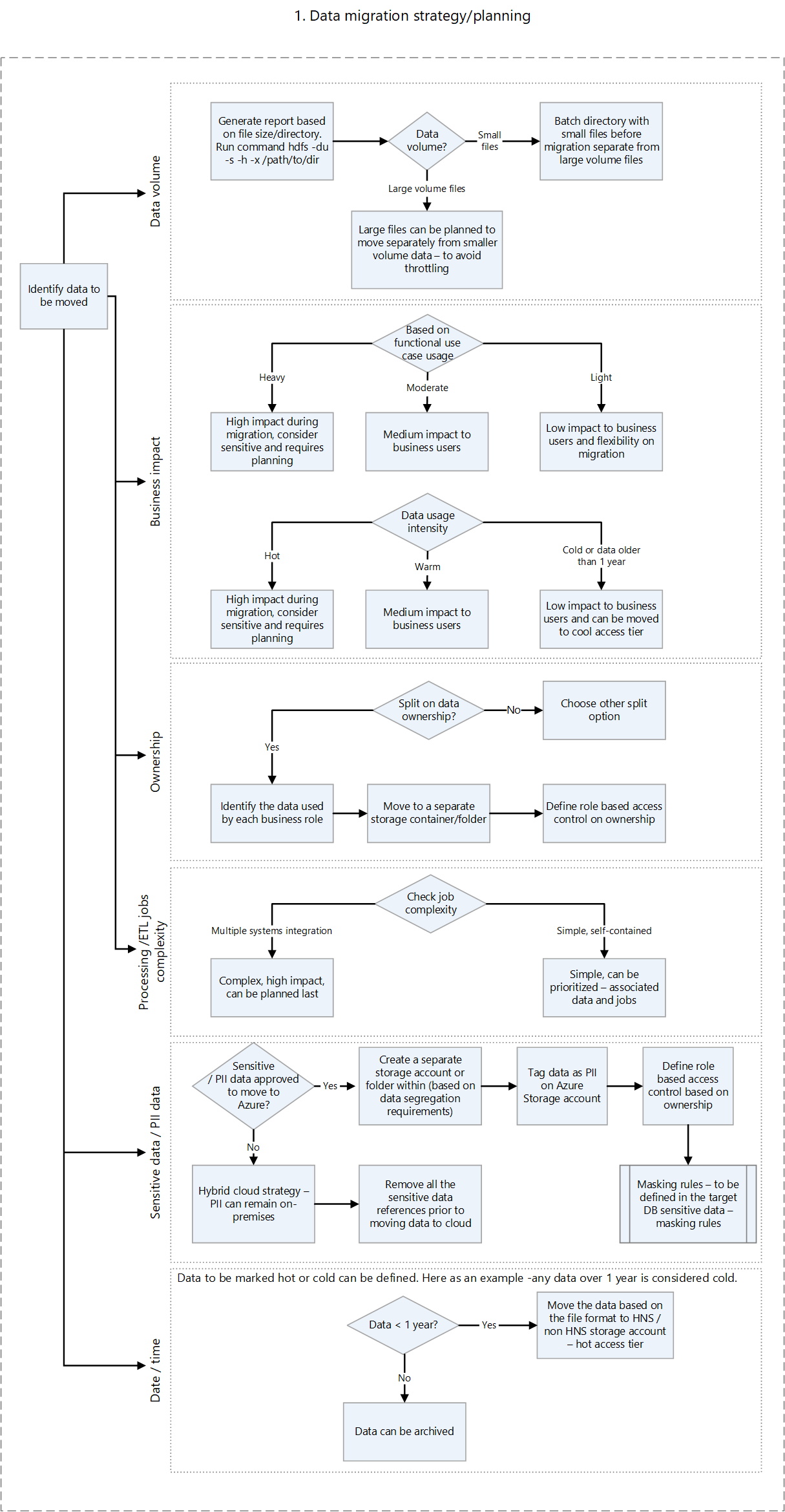
HDFS から評価メトリックを取得するための HDFS コマンドは次のとおりです。
ある場所のすべてのディレクトリを一覧表示します。
hdfs dfs -ls booksある場所のすべてのファイルを再帰的に一覧表示します。
hdfs dfs -ls -R booksHDFS ディレクトリとファイルのサイズを取得します。
hadoop fs -du -s -h commandhadoop fs -du -s -hこのコマンドは、HDFS ファイルとディレクトリのサイズを表示します。 Hadoop ファイル システムではすべてのファイルがレプリケートされるため、ファイルの実際の物理サイズは、ファイル レプリカの数に 1 つのレプリカのサイズを乗算したものです。ACL が有効になっているかどうかを確認します。 これを行うには、Hdfs-site.xml の
dfs.namenode.acls.enabledの値を取得します。 この値を知ることは、Azure Storage アカウントのアクセス制御を計画する上で役立ちます。 このファイルの内容については、既定のファイル設定を参照してください。
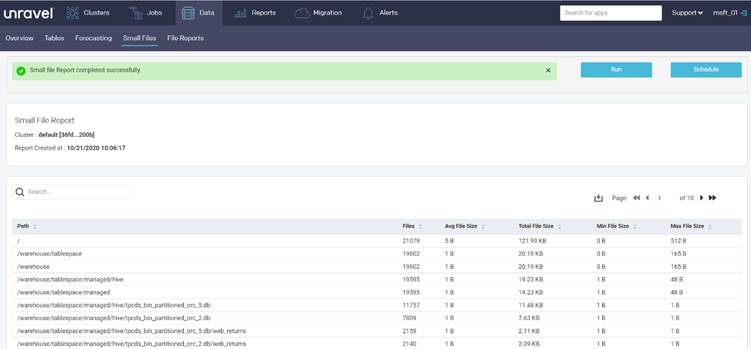
Unravel などのパートナー ツールは、データ移行を計画するための評価レポートを提供します。 このツールは、オンプレミス環境で実行するか、Hadoop クラスターに接続してレポートを生成する必要があります。
次の Unravel レポートは、ディレクトリ内の小さなファイルに関する統計情報をディレクトリごとに提供します。
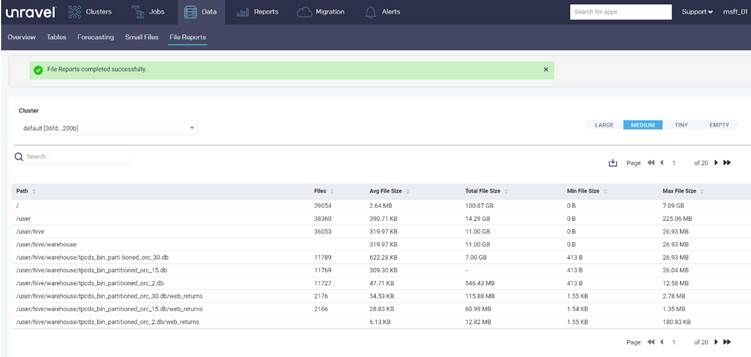
次のレポートは、ディレクトリ内のファイルに関する統計情報をディレクトリごとに提供します。
データの転送
移行計画に記載されているように、データを Azure に転送する必要があります。 転送には、次のアクティビティが必要です。
すべてのインジェスト ポイントを特定する。
セキュリティ要件のために、データをクラウドに直接配置できない場合、オンプレミスを中間ランディング ゾーンとして機能させることができます。 Data Factory でパイプラインを構築してオンプレミス システムからデータをプルするか、AZCopy スクリプトを使用して Azure Storage アカウントにデータをプッシュできます。
共通インジェストソースには次のものが含まれます。
- SFTP サーバー
- ファイル インジェスト
- データベース インジェスト
- データベース ダンプ
- 変更データ キャプチャ
- ストリーミング インジェスト
必要なストレージ アカウントの数を計画する。
必要なストレージ アカウントの数を計画するには、現在の HDFS の全体の負荷を理解します。 TotalLoad メトリックを使用できます。これは、すべての DataNode での現在の同時ファイル アクセス数です。 オンプレミスの TotalLoad 値と Azure で予想される増加に応じて、リージョン内のストレージ アカウントの制限を設定します。 制限を増加できる場合は、1 つのストレージ アカウントで十分な場合もあります。 ただし、データ レイクの場合は、将来のデータ ボリュームの増加に備えて、ゾーンごとに別々のストレージ アカウントを保持することをお勧めします。 別々のストレージ アカウントを保持するその他の理由は次のとおりです。
- アクセス制御
- 回復性の要件
- データ レプリケーションの要件
- パブリック使用のためのデータの公開
ストレージ アカウントで階層型名前空間を有効にした場合、フラット型名前空間に戻すことはできません。 バックアップや VM イメージ ファイルなどのワークロードには、階層型名前空間の利点はありません。
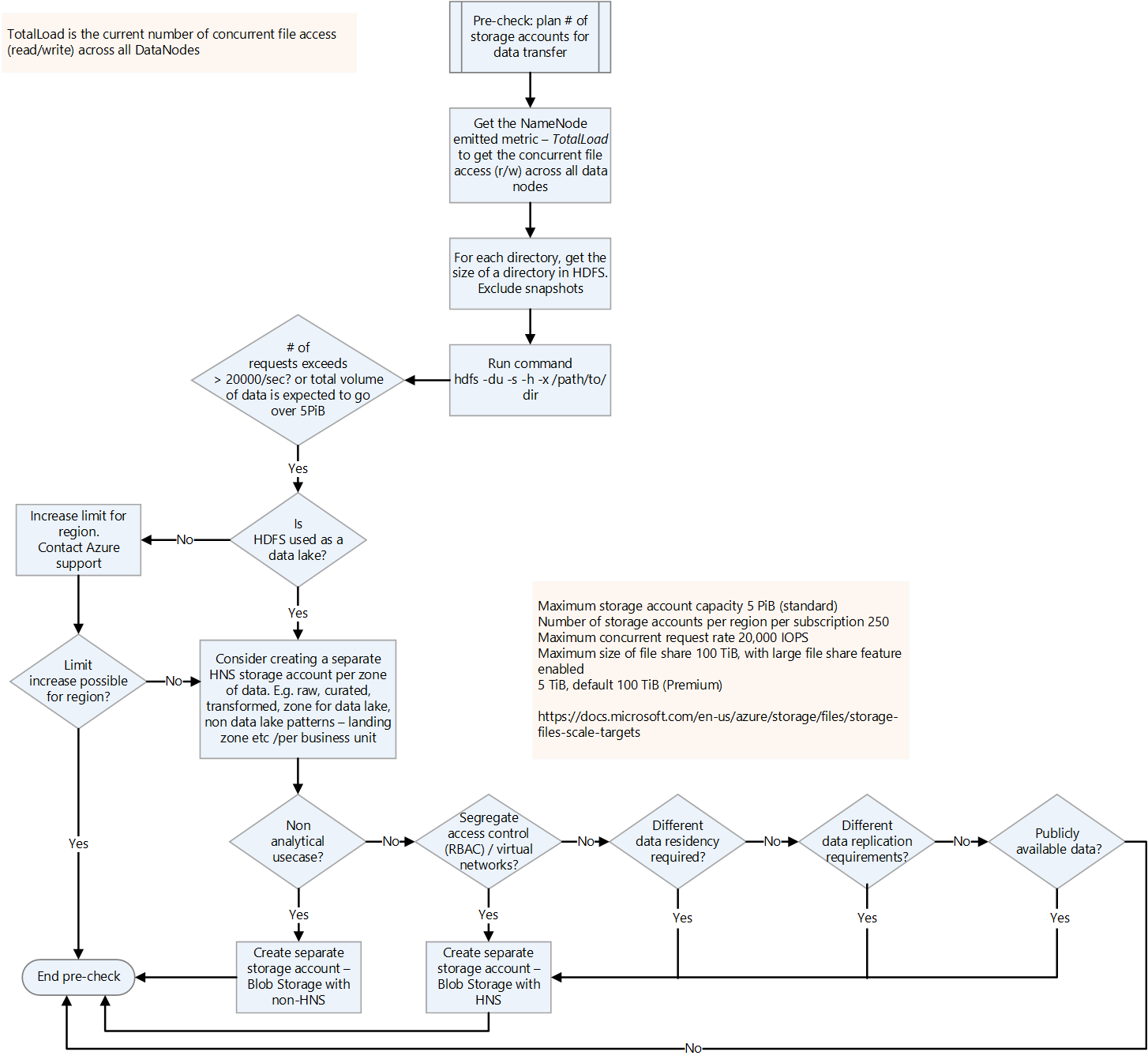
プライベート リンク上の仮想ネットワークとストレージ アカウントの間のトラフィックをセキュリティで保護する方法については、ストレージ アカウントのセキュリティ保護に関する記事を参照してください。
Azure ストレージ アカウントの既定の上限の詳細については、「Standard Storage アカウントのスケーラビリティとパフォーマンスのターゲット」を参照してください。 "受信制限" は、ストレージ アカウントに送信されるデータに適用されます。 "送信制限" は、ストレージ アカウントから受信されるデータに適用されます。
可用性の要件を決定する。
Hadoop プラットフォームのレプリケーション係数を hdfs-site.xml で指定することも、ファイルごとに指定することもできます。 データの性質に応じて、Data Lake Storage のレプリケーションを構成できます。 アプリケーションで、損失が発生した場合にデータを再構築する必要がある場合は、ゾーン冗長ストレージ (ZRS) がオプションとなります。 Data Lake Storage ZRS では、データはプライマリ リージョンの 3 つの可用性ゾーン間で、同期的にコピーされます。 高可用性を必要とし、複数のリージョンで実行できるアプリケーションの場合は、データをセカンダリ リージョンにコピーします。 これは geo 冗長レプリケーションです。
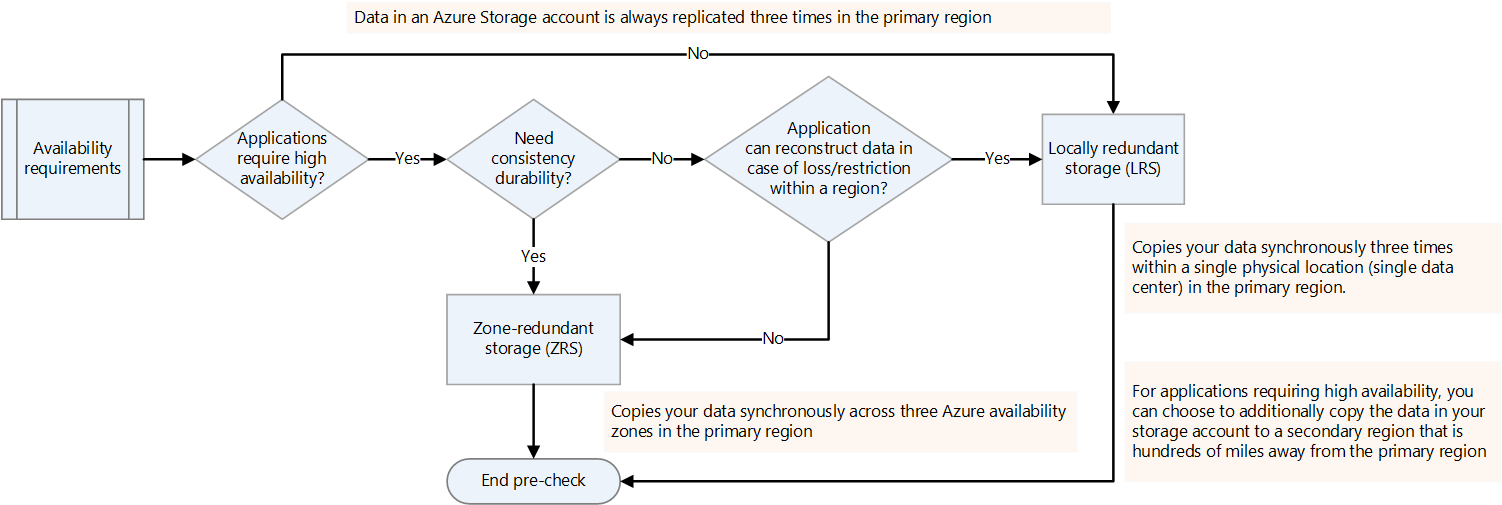
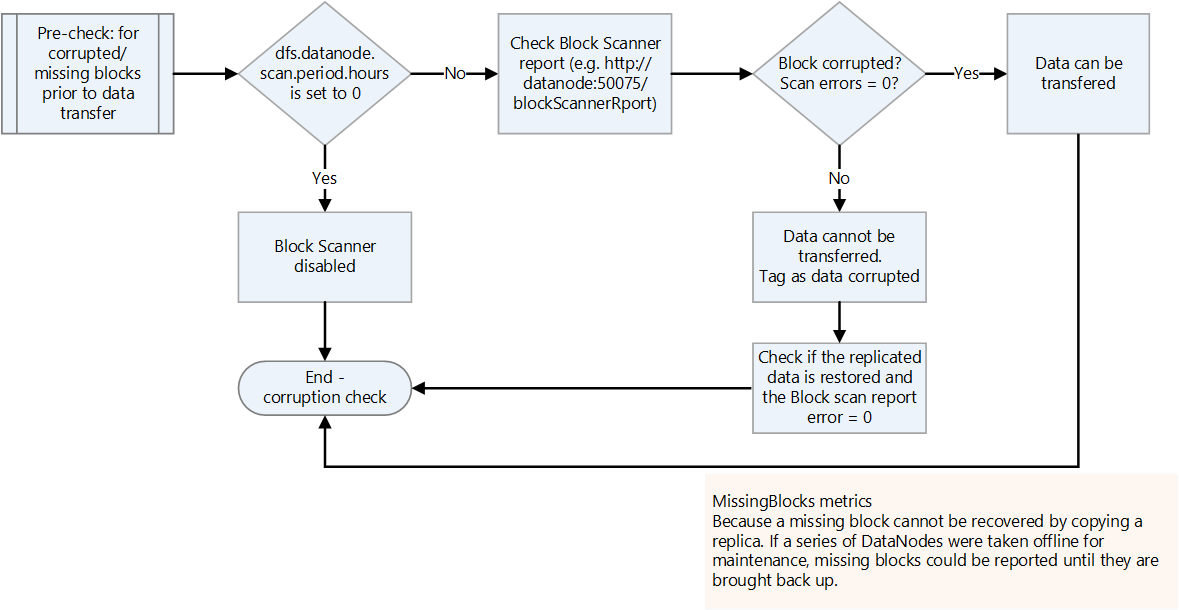
破損または不足しているブロックを確認する。
ブロック スキャナー レポートで、破損または不足しているブロックがないか確認します。 ある場合は、ファイルが復元されるのを待ってから転送します。
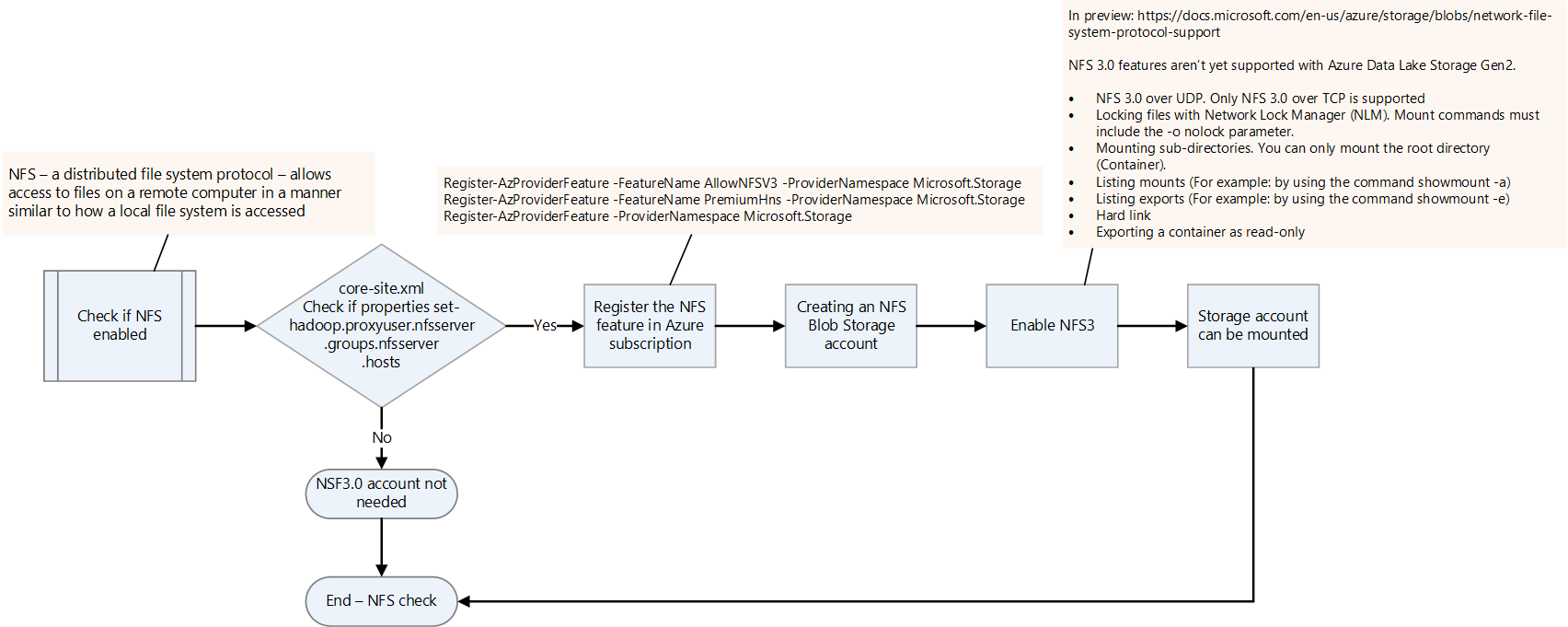
NFS が有効になっているかどうかを確認する。
core-site.xml ファイルを確認して、オンプレミスの Hadoop プラットフォームで NFS が有効になっているかどうかを確認します。 これには nfsserver.groups と nfsserver.hosts のプロパティがあります。
Data Lake Storage では NFS 3.0 機能はプレビュー段階です。 いくつかの機能はまだサポートされていない場合があります。 詳細については、「Azure Blob Storage でのネットワーク ファイル システム (NFS) 3.0 プロトコル サポート」を参照してください。
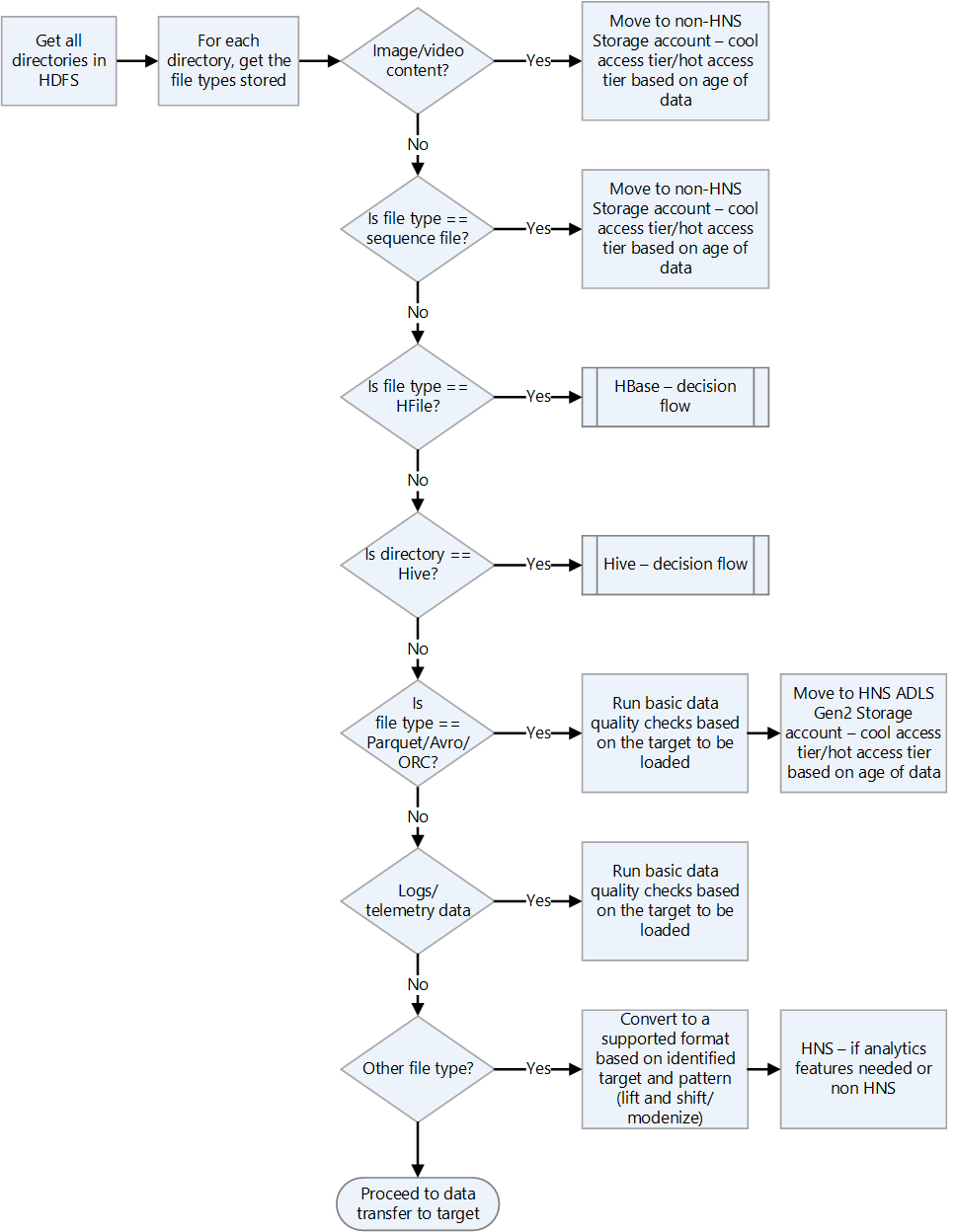
Hadoop ファイル形式を確認する。
ファイル形式を処理する方法のガイダンスについては、次の決定フロー チャートを使用します。
データ転送用の Azure ソリューションを選択する。
データ転送は、ネットワーク経由でオンラインにすることも、物理デバイスを使用してオフラインにすることもできます。 どの方法を使用するかは、データ ボリューム、ネットワーク帯域幅、データ転送の頻度によって異なります。 履歴データは 1 回だけ転送する必要があります。 増分読み込みでは、継続的な転送を繰り返す必要があります。
データ転送方法については、次の一覧で説明します。 データ転送の種類を選択することにの詳細については、「データ転送用の Azure ソリューションを選択する」を参照してください。
Azcopy
AzCopy は、HDFS からストレージ アカウントにファイルをコピーできるコマンドライン ユーティリティです。 これは、(1 GBPS を超える) 高帯域幅転送のオプションです。
HDFS ディレクトリを移動するサンプル コマンドを次に示します。
*azcopy copy "C:\local\path" "https://account.blob.core.windows.net/mycontainer1/?sv=2018-03-28&ss=bjqt&srt=sco&sp=rwddgcup&se=2019-05-01T05:01:17Z&st=2019-04-30T21:01:17Z&spr=https&sig=MGCXiyEzbtttkr3ewJIh2AR8KrghSy1DGM9ovN734bQF4%3D" --recursive=true*DistCp
DistCp は、Hadoop クラスターで分散コピー操作を実行できる Hadoop のコマンド ライン ユーティリティです。 DistCp では、Hadoop クラスターに複数のマップ タスクを作成し、ソースからシンクにデータをコピーします。 このプッシュ アプローチは、十分なネットワーク帯域幅があり、データ移行のために追加のコンピューティング リソースをプロビジョニングする必要がない場合に適しています。 ただし、ソース HDFS クラスターの容量が既に不足していて、コンピューティングを追加できない場合は、ファイルをプッシュするのではなく、Data Factory を使用して DistCp コピー アクティビティでプルすることを検討してください。
*hadoop distcp -D fs.azure.account.key.<account name>.blob.core.windows.net=<Key> wasb://<container>@<account>.blob.core.windows.net<path to wasb file> hdfs://<hdfs path>*大規模なデータ転送のための Azure Data Box
Azure Data Box は、Microsoft から注文できる物理デバイスです。 これは大規模なデータ転送機能を提供するもので、ネットワーク帯域幅が制限され、データ ボリュームが多い (たとえば、ボリュームが数テラバイトからペタバイトの場合など) 場合のオフライン データ転送オプションです。
Data Box を LAN に接続して、これにデータを転送します。 その後、これを Microsoft データ センターに返送し、ここで Microsoft のエンジニアによって、データは構成されたストレージ アカウントに転送されます。
Data Box には、処理できるデータ ボリュームによって異なる複数のオプションがあります。 Data Box のアプローチの詳細については、「Azure Data Box のドキュメント - オフライン転送」を参照してください。
Data Factory
Data Factory は、データ移動とデータ変換を調整および自動化するデータドリブン ワークフローの作成に役立つデータ統合サービスです。 これは十分なネットワーク帯域幅があり、データ移行を調整して監視する必要がある場合に使用できます。 Data Factory は、増分データが最初のホップとしてオンプレミス システムに到着し、セキュリティ制限のために Azure ストレージ アカウントに直接転送できない場合に、データの定期的な増分読み込みのために使用できます。
さまざまな転送アプローチの詳細については、「中程度から高いネットワーク帯域幅を使用した大規模なデータセットのデータ転送」を参照してください。
Data Factory を使用して HDFS からデータをコピーする方法については、「Azure Data Factory または Synapse Analytics を使用して HDFS サーバーからデータをコピーする」を参照してください。
WANdisco LiveData 移行などのパートナー ソリューション
WANdisco LiveData Platform for Azure は、Hadoop から Azure への移行に関する Microsoft が推奨するソリューションの 1 つです。 機能にアクセスするには、Azure portal と Azure CLI を使用します。 詳細については、「WANdisco LiveData Platform for Azure を使用して Hadoop データ レイクを移行する」を参照してください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- Namrata Maheshwary | シニア クラウド ソリューション アーキテクト
- Raja N | ディレクター、カスタマー サクセス
- Hideo Takagi | クラウド ソリューション アーキテクト
- Ram Yerrabotu | シニア クラウド ソリューション アーキテクト
その他の共同作成者:
- Ram Baskaran | シニア クラウド ソリューション アーキテクト
- Jason Bouska | シニア ソフトウェア エンジニア
- Eugene Chung | シニア クラウド ソリューション アーキテクト
- Pawan Hosatti | シニア クラウド ソリューション アーキテクト - エンジニアリング
- Daman Kaur | クラウド ソリューション アーキテクト
- Danny Liu | シニア クラウド ソリューション アーキテクト - エンジニアリング
- Jose Mendez | シニア クラウド ソリューション アーキテクト
- Ben Sadeghi | シニア スペシャリスト
- Sunil Sattiraju | シニア クラウド ソリューション アーキテクト
- Amanjeet Singh | プリンシパル プログラム マネージャー
- Nagaraj Seeplapudur Venkatesan | シニア クラウド ソリューション アーキテクト - エンジニアリング
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次の手順
Azure 製品の概要
- Azure Data Lake Storage Gen2 の概要
- Apache Spark とは - Azure HDInsight
- Azure HDInsight の Apache Hadoop の概要
- Azure HDInsight での Apache HBase の概要
- Azure HDInsight での Apache Kafka の概要
Azure 製品のリファレンス
- Microsoft Entra のドキュメント
- Azure Cosmos DB のドキュメント
- Azure Data Factory のドキュメント
- Azure Databricks のドキュメント
- Azure Event Hubs のドキュメント
- Azure Functions のドキュメント
- Azure HDInsight のドキュメント
- Microsoft Purview データ ガバナンスに関するドキュメント
- Azure Stream Analytics のドキュメント
- Azure Synapse Analytics
その他
- Azure HDInsight 用の Enterprise セキュリティ パッケージ
- HDInsight 上の Apache Hadoop 用の Java MapReduce プログラムを開発する
- HDInsight の Hadoop での Apache Sqoop の使用
- Apache Spark ストリーミングの概要
- 構造化ストリーミングのチュートリアル
- Apache Kafka アプリケーションから Azure Event Hubs を使用する