Azure への Hadoop の移行
Apache Hadoop には、MapReduce 手法を使用して非常に大きなデータ セットを分析および変換するための分散ファイル システムとフレームワークが用意されています。 Hadoop の重要な特徴は、多数 (数千) のホストに渡ってデータと計算がパーティション分割されることです。 計算は、データの近くで並列に実行されます。 Hadoop クラスターでは、汎用ハードウェアを追加するだけで、計算容量、ストレージ容量、 I/O 帯域幅をスケーリングできます。
この記事では、Hadoop を Azure に移行する方法の概要について説明します。 このセクションの他の記事では、特定の Hadoop コンポーネントの移行ガイダンスを提供します。 これらは次のとおりです。
- Azure への Apache HDFS の移行
- Azure への Apache HBase の移行
- Azure への Apache Kafka の移行
- Azure への Apache Sqoop の移行
Hadoop では、サービスとフレームワークの広範なエコシステムを提供しています。 これらの記事では、Hadoop コンポーネントとその Azure 実装について詳しくは説明しません。 代わりに、オンプレミスとクラウドの Hadoop アプリケーションを Azure に移行するための開始点として機能する、大まかなガイダンスと考慮事項について説明します。
Apache®、Apache Spark®、Apache Hadoop®、Apache HBase、Apache Hive、Apache Ranger®、Apache Sentry®、Apache ZooKeeper®、Apache Storm®、Apache Sqoop®、Apache Flink®、Apache Kafka®、および炎のロゴは、Apache Software Foundation の米国およびその他の国における登録商標または商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
Hadoop コンポーネント
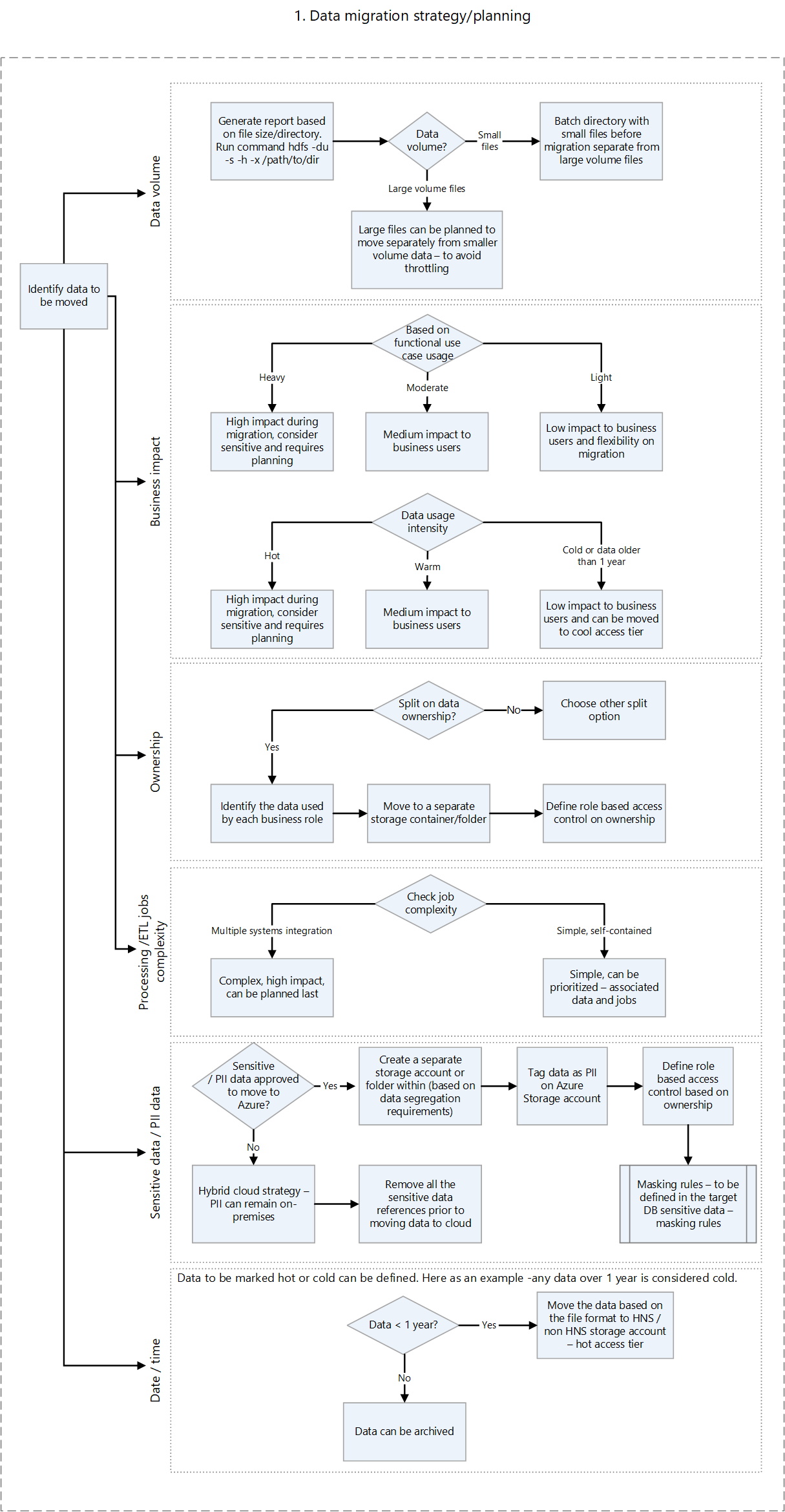
Hadoop システムの主要なコンポーネントを次の表に示します。 コンポーネントごとに、簡単な説明と次のような移行情報があります。
- 移行戦略を決定するための決定フローチャートへのリンク
- 使用可能な Azure ターゲット サービスの一覧
| コンポーネント | 説明 | 決定フローチャート | 対象となる Azure サービス |
|---|---|---|---|
| Apache HDFS | 分散ファイル システム | データ移行の計画、データ移行前の事前チェック | Azure Data Lake Storage |
| Apache HBase | 列指向テーブル サービス | Apache HBase のランディング ターゲットの選択、Azure での Apache HBase のストレージの選択 | 仮想マシン (VM) 上の HBase、Azure HDInsight の HBase、Azure Cosmos DB |
| Apache Spark | データ処理フレームワーク | Azure での Apache Spark のランディング ターゲットの選択 | HDInsight の Spark、Azure Synapse Analytics、Azure Databricks |
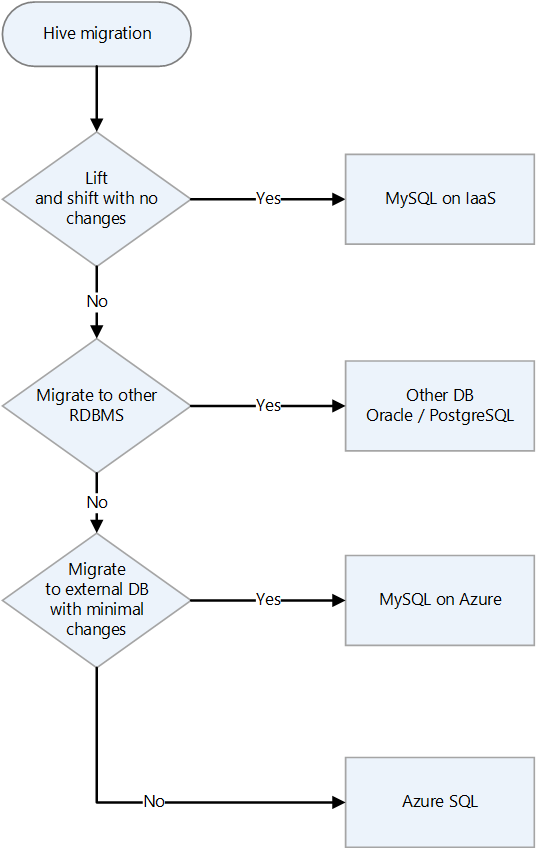
| Apache Hive | データ ウェアハウス インフラストラクチャ | Hive のランディング ターゲットの選択、Hive メタデータのターゲット DB の選択 | VM 上の Hive、HDInsight の Hive、Azure Synapse Analytics |
| Apache Ranger | データ セキュリティを監視および管理するためのフレームワーク | HDInsight 用の Enterprise セキュリティ パッケージ、Microsoft Entra ID、VM 上の Ranger | |
| Apache Sentry | データ セキュリティを監視および管理するためのフレームワーク | Azure での Apache Sentry のランディング ターゲットの選択 | VM 上の Sentry と Ranger、HDInsight 用の Enterprise セキュリティ パッケージ、Microsoft Entra ID |
| Apache MapReduce | 分散計算フレームワーク | MapReduce、Spark | |
| Apache Zookeeper | 分散調整サービス | VM 上の ZooKeeper、サービスとしてのプラットフォーム (PaaS) 内の組み込みソリューション | |
| Apache YARN | Hadoop エコシステムのリソース マネージャー | VM 上の YARN、PaaS 内の組み込みソリューション | |
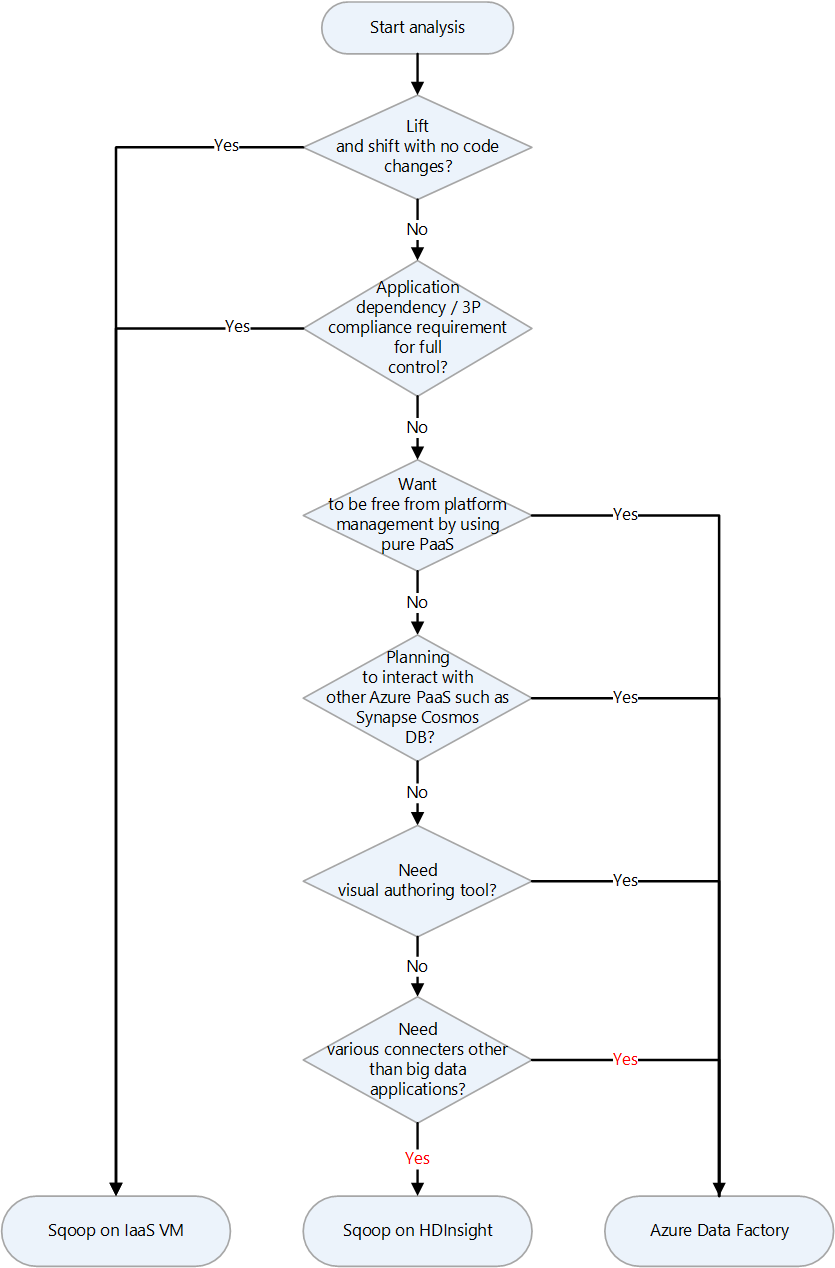
| Apache Sqoop | Apache Hadoop クラスターとリレーショナル データベースの間でデータを転送するためのコマンド ライン インターフェイス ツール | Azure での Apache Sqoop のランディング ターゲットの選択 | VM 上の Sqoop、HDInsight の Sqoop、Azure Data Factory |
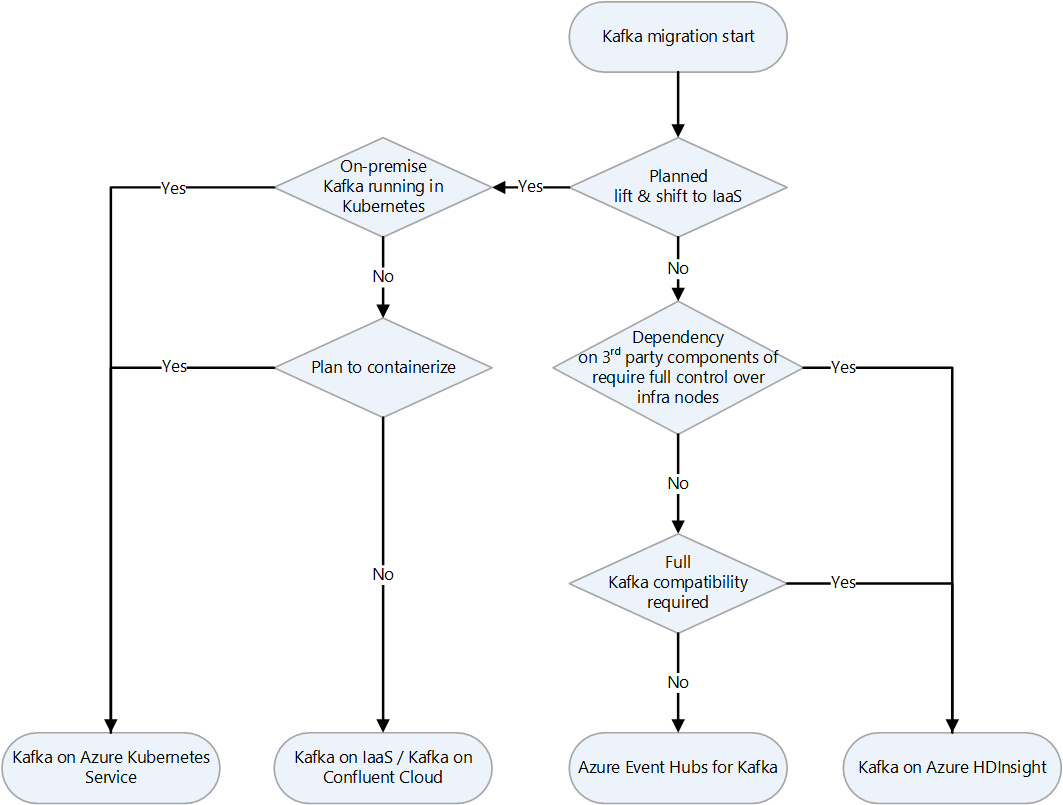
| Apache Kafka | 高度にスケーラブルなフォールト トレラント分散メッセージング システム | Azure での Apache Kafka のランディング ターゲットの選択 | VM 上の Kafka、Kafka 用の Event Hubs、HDInsight 上の Kafka |
| Apache Atlas | データ ガバナンスとメタデータ管理のためのオープン ソース フレームワーク | Azure Purview |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
移行方法
次の図は、Hadoop アプリケーションを移行するための 3 つの方法を示しています。

このアーキテクチャの Visio ファイルをダウンロードします。
アプローチは次のとおりです。
- Azure PaaS を使用したリプラットフォーム: 詳細については、「Azure Synapse Analytics と Databricks を使用した最新化」を参照してください。
- HDInsight へのリフト アンド シフト: 詳細については、「HDInsight へのリフト アンド シフト」を参照してください。
- IaaS へのリフトアンドシフト: 詳細については、「サービスとしての Azure インフラストラクチャ (IaaS) へのリフト アンド シフト」を参照してください。
Azure Synapse Analytics と Databricks を使用した最新化
この手法を次の図に示します。

このアーキテクチャの Visio ファイルをダウンロードします。
HDInsight へのリフト アンド シフト
この手法を次の図に示します。

このアーキテクチャの Visio ファイルをダウンロードします。
詳細については、「オンプレミスの Apache Hadoop クラスターを Azure HDInsight に移行する」を参照してください。
サービスとしての Azure インフラストラクチャ (IaaS) へのリフト アンド シフト
次のパターンは、Active Directory、ドメイン コントローラー、DNS などのオンプレミス システムに緊密に統合された OSS を Azure IaaS にデプロイする方法に関する観点を示しています。 このデプロイは、Microsoft のエンタープライズ規模のランディング ゾーン ガイダンスに従います。 監視、セキュリティ、ガバナンス、ネットワークなどの管理機能は、管理サブスクリプション内でホストされます。 すべての IaaS ベースのワークロードは、別のサブスクリプションでホストされます。 エンタープライズ規模のランディング ゾーンの詳細については、「Azure ランディング ゾーンとは」を参照してください。

このアーキテクチャの Visio ファイルをダウンロードします。
- オンプレミスの Active Directory は、オンプレミスでホストされている Microsoft Entra Connect を使用することで Microsoft Entra ID と同期します。
- Azure ExpressRoute は、オンプレミスと Azure の間のセキュリティで保護されたプライベート ネットワーク接続を提供します。
- 管理 (またはハブ) サブスクリプションは、デプロイのネットワーク機能と管理機能を提供します。 このパターンは、Microsoft のエンタープライズ規模のランディング ゾーン ガイダンスに沿っています。
- ハブ サブスクリプション内でホストされるサービスは、ネットワーク接続機能と管理機能を提供します。
- NTP (Azure VM でホストされている) は、すべての仮想マシン間で時刻の同期を維持するために必要となります。 HBase や ZooKeeper などの複数のアプリケーションを実行する場合は、クラスターでネットワーク タイム プロトコル (NTP) サービスまたは別の時刻同期メカニズムを実行する必要があります。 すべてのノードで、時刻同期に同じサービスを使用する必要があります。 Linux で NTP を設定する手順については、14.6 NTP の基本的な構成を参照してください。
- Azure Network Watcher には、Azure 仮想ネットワーク内のリソースを監視、診断、管理するためのツールが用意されています。 Network Watcher は、VM、仮想ネットワーク、アプリケーション ゲートウェイ、ロード バランサーなどの IaaS 製品のネットワーク正常性を監視および修復するように設計されています。
- Azure Advisor では、リソースの構成と使用状況のテレメトリを分析し、Azure リソースの費用対効果、パフォーマンス、信頼性、セキュリティを向上させるためのソリューションを推奨します。
- Azure Monitor により、クラウドおよびオンプレミス環境のテレメトリを収集、分析、処理する包括的なソリューションが提供されます。 アプリケーションの実行状態を把握し、アプリケーションやその依存リソースに影響を及ぼす問題を事前に突き止めることができます。
- Log Analytics ワークスペースは、Azure Monitor ログ データ用の固有の環境です。 各ワークスペースには、独自のデータ リポジトリと構成があります。 データ ソースとソリューションは、特定のワークスペースにデータを格納するように構成されます。 次のソースからデータを収集しようとする場合は、Log Analytics ワークスペースが必要です。
- サブスクリプション内の Azure リソース
- System Center Operations Manager によって監視されているオンプレミスのコンピューター
- System Center Configuration Manager のデバイス コレクション
- Azure Storage からの診断またはログ データ
- Azure 仮想マシン スケール セットでホストされる Azure DevOps Self-Hosted エージェントは、エージェントが実行されるマシンのサイズとイメージに対する柔軟性を提供します。 仮想マシン スケール セット、スタンバイ状態を維持するエージェントの数、スケール セット内の仮想マシンの最大数を指定します。 エージェントのスケーリングは Azure Pipelines によって自動的に管理されます。
- Microsoft Entra ID テナントは、Microsoft Entra Connect 同期サービスを介してオンプレミスの Active Directory と同期されます。 詳細については、「Microsoft Entra Connect Sync: 同期を理解してカスタマイズする」を参照してください。
- Microsoft Entra Domain Services (Microsoft Entra Domain Services) は、Azure で LDAP と Kerberos の機能を提供します。 Microsoft Entra Domain Services を初めてデプロイするときに、Microsoft Entra ID からオブジェクトをレプリケートするための一方向の自動同期が構成されます。 この一方向の同期は、Microsoft Entra ID からのすべての変更を反映して Microsoft Entra Domain Services マネージド ドメインを最新の状態に保つために、バックグラウンドで実行され続けます。 Microsoft Entra Domain Services から Microsoft Entra ID への同期は行われません。
- Azure DNS、Microsoft Defender for Cloud、Azure Key Vault などのサービスは、管理サブスクリプション内に配置され、それぞれサービス/IP アドレス解決、統合インフラストラクチャのセキュリティ管理、証明書機能とキー管理機能を提供します。
- Virtual Network ピアリングは、管理 (ハブ) とワークロード (スポーク) の 2 つのサブスクリプションにデプロイされた仮想ネットワーク間の接続を提供します。
- エンタープライズ規模のランディング ゾーンに合わせて、アプリケーションのワークロードをホストするためにワークロード サブスクリプションが使用されます。
- Azure Data Lake Storage は、ビッグ データ分析を行うために Azure Blob Storage に構築された一連の機能です。 ビッグ データ ワークロードのコンテキストでは、Data Lake Storage を Hadoop のセカンダリ ストレージとして使用できます。 Data Lake Storage に書き込まれたデータは、Hadoop フレームワークの外部にある他の Azure サービスで使用できます。
- ビッグ データ ワークロードは、独立した一連の Azure 仮想マシンでホストされます。 詳細については、Azure IaaS 上の HdFS、HBase、Hive、Ranger、Spark のガイダンスを参照してください。
- Azure DevOps は、サービスとしてのソフトウェア (SaaS) オファリングであり、計画と開発からテストとデプロイまで、ソフトウェア プロジェクトを管理するためのサービスとツールの統合セットを提供します。
最終状態の参照アーキテクチャ
オンプレミスの Hadoop から Azure にワークロードを移行する場合の課題の 1 つは、望ましい最終状態のアーキテクチャとアプリケーションを実現するためにデプロイすることです。 「Azure PaaS での Hadoop の移行」で説明されているプロジェクトは、PaaS サービスとアプリケーションをデプロイするために通常必要な多大な労力を削減することを目的としています。
このプロジェクトでは、Azure 上のビッグ データ ワークロードの最終状態のアーキテクチャを確認し、Bicep テンプレートのデプロイで使用されるコンポーネントの一覧を示します。 Bicep では、アーキテクチャをデプロイするために必要なモジュールのみがデプロイされます。 テンプレートの前提条件と、ワンクリック、Azure CLI、GitHub Actions、Azure DevOps Pipeline など、Azure にリソースをデプロイするためのさまざまな方法について説明します。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- Namrata Maheshwary | シニア クラウド ソリューション アーキテクト
- Raja N | ディレクター、カスタマー サクセス
- Hideo Takagi | クラウド ソリューション アーキテクト
- Ram Yerrabotu | シニア クラウド ソリューション アーキテクト
その他の共同作成者:
- Ram Baskaran | シニア クラウド ソリューション アーキテクト
- Jason Bouska | シニア ソフトウェア エンジニア
- Eugene Chung | シニア クラウド ソリューション アーキテクト
- Pawan Hosatti | シニア クラウド ソリューション アーキテクト - エンジニアリング
- Daman Kaur | クラウド ソリューション アーキテクト
- Danny Liu | シニア クラウド ソリューション アーキテクト - エンジニアリング
- Jose Mendez | シニア クラウド ソリューション アーキテクト
- Ben Sadeghi | シニア スペシャリスト
- Sunil Sattiraju | シニア クラウド ソリューション アーキテクト
- Amanjeet Singh | プリンシパル プログラム マネージャー
- Nagaraj Seeplapudur Venkatesan | シニア クラウド ソリューション アーキテクト - エンジニアリング
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次の手順
Azure 製品の概要
- Azure Data Lake Storage Gen2 の概要
- Apache Spark とは - Azure HDInsight
- Azure HDInsight の Apache Hadoop の概要
- Azure HDInsight での Apache HBase の概要
- Azure HDInsight での Apache Kafka の概要
- Azure HDInsight のエンタープライズ セキュリティの概要
Azure 製品のリファレンス
- Microsoft Entra のドキュメント
- Azure Cosmos DB のドキュメント
- Azure Data Factory のドキュメント
- Azure Databricks のドキュメント
- Azure Event Hubs のドキュメント
- Azure Functions のドキュメント
- Azure HDInsight のドキュメント
- Microsoft Purview データ ガバナンスに関するドキュメント
- Azure Stream Analytics のドキュメント
- Azure Synapse Analytics
その他
- Azure HDInsight 用の Enterprise セキュリティ パッケージ
- HDInsight 上の Apache Hadoop 用の Java MapReduce プログラムを開発する
- HDInsight の Hadoop での Apache Sqoop の使用
- Apache Spark ストリーミングの概要
- 構造化ストリーミングのチュートリアル
- Apache Kafka アプリケーションから Azure Event Hubs を使用する