Azure Functions Node.js 開発者ガイド
このガイドは、JavaScript または TypeScript を使った Azure Functions 開発の概要です。 この記事は、「Azure Functions の開発者向けガイド」を既に読んでいることを前提としています。
重要
このページの上部にあるセレクターで Node.js プログラミング モデルを選ぶと、この記事の内容は変わります。 実際のアプリで使っている @azure/functions npm パッケージのバージョンに合わせてバージョンを選んでください。 お使いの package.json にそのパッケージを記載していない場合、既定値は v3 です。 v3 と v4 の違いの詳細については、移行ガイドを参照してください。
Node.js 開発者は、次のいずれかの記事にも興味があるかもしれません。
| 作業の開始 | 概念 | ガイド付き学習 |
|---|---|---|
考慮事項
- Node.js のプログラミング モデルと Azure Functions のランタイムを混同しないでください。
- プログラミング モデル: コードの作成方法を定義します。JavaScript と TypeScript に固有です。
- ランタイム: Azure Functions の基本的な動作を定義します。すべての言語で共有されます。
- プログラミング モデルのバージョンは
@azure/functionsnpm パッケージのバージョンに厳密に関連付けられています。 ランタイムとは別にバージョン管理されます。 ランタイムとプログラミング モデルの両方で最新のメジャー バージョン番号として 4 が使用されていますが、これは偶然です。 - 同じ関数アプリ内で v3 と v4 のプログラミング モデルを混在させることはできません。 アプリに v4 関数を 1 つ登録するとすぐに、function.json ファイルに登録されているすべての v3 関数は無視されます。
サポートされているバージョン
次の表は、Node.js プログラミング モデルの各バージョンと、Azure Functions Runtime と Node.js のサポートされるバージョンを示しています。
| プログラミング モデルのバージョン | サポート レベル | Functions ランタイムのバージョン | Node.js のバージョン | 説明 |
|---|---|---|---|---|
| 4.x | GA | 4.25 以降 | 20.x、18.x | 柔軟なファイル構造と、トリガーとバインディングに対するコード中心のアプローチをサポートします。 |
| 3.x | GA | 4.x | 20.x、18.x、16.x、14.x | "function.json" ファイルで宣言したトリガーとバインディングを含む特定のファイル構造が必要です |
| 2.x | 該当なし | 3.x | 14.x、12.x、10.x | 2022 年 12 月 13 日にサポート終了になりました。 詳細については、Functions のバージョンに関する記事を参照してください。 |
| 1.x | 該当なし | 2.x | 10.x、8.x | 2022 年 12 月 13 日にサポート終了になりました。 詳細については、Functions のバージョンに関する記事を参照してください。 |
フォルダー構造
JavaScript プロジェクトでは、次の例のようなフォルダー構造が必要です。
<project_root>/
| - .vscode/
| - node_modules/
| - myFirstFunction/
| | - index.js
| | - function.json
| - mySecondFunction/
| | - index.js
| | - function.json
| - .funcignore
| - host.json
| - local.settings.json
| - package.json
メイン プロジェクト フォルダー <
- .vscode/: (省略可能) 格納されている Visual Studio Code 構成が含まれます。 詳細については、Visual Studio Code の設定に関するページを参照してください。
- myFirstFunction/function.json: 関数のトリガー、入力、出力の構成が含まれています。 ディレクトリの名前によって、関数の名前が決まります。
- myFirstFunction/index.js: 関数コードを保存します。 この既定のファイル パスを変更するには、「scriptFile の使用」を参照してください。
- .funcignore:(省略可能) Azure に発行しないファイルを宣言します。 通常、このファイルには、エディター設定を無視する場合は .vscode/、テスト ケースを無視する場合は tests/、ローカル アプリの設定を発行しない場合は local.settings.json が含まれます。
- host.json: 関数アプリ インスタンス内にあるすべての関数に影響する構成オプションが含まれます。 このファイルは Azure に公開されます。 ローカルで実行する場合は、すべてのオプションがサポートされるわけではありません。 詳細については、「host.json」に関するページを参照してください。
- local.settings.json: ローカルで実行するとき、アプリ設定と接続文字列を格納するために使用されます。 このファイルは Azure に公開されません。 詳細については、「local.settings.file」に関するページを参照してください。
- package.json: パッケージの依存関係の一覧、メイン エントリポイント、スクリプトなどの構成オプションを含めます。
JavaScript プロジェクトの推奨フォルダー構造は、次の例のようになります。
<project_root>/
| - .vscode/
| - node_modules/
| - src/
| | - functions/
| | | - myFirstFunction.js
| | | - mySecondFunction.js
| - test/
| | - functions/
| | | - myFirstFunction.test.js
| | | - mySecondFunction.test.js
| - .funcignore
| - host.json
| - local.settings.json
| - package.json
メイン プロジェクト フォルダー <
- .vscode/: (省略可能) 格納されている Visual Studio Code 構成が含まれます。 詳細については、Visual Studio Code の設定に関するページを参照してください。
- src/functions/: すべての関数とそれに関連するトリガーとバインドの既定の場所です。
- test/: (省略可能) 関数アプリのテスト ケースが含まれます。
- .funcignore:(省略可能) Azure に発行しないファイルを宣言します。 通常、このファイルには、エディター設定を無視する場合は .vscode/、テスト ケースを無視する場合は tests/、ローカル アプリの設定を発行しない場合は local.settings.json が含まれます。
- host.json: 関数アプリ インスタンス内にあるすべての関数に影響する構成オプションが含まれます。 このファイルは Azure に公開されます。 ローカルで実行する場合は、すべてのオプションがサポートされるわけではありません。 詳細については、「host.json」に関するページを参照してください。
- local.settings.json: ローカルで実行するとき、アプリ設定と接続文字列を格納するために使用されます。 このファイルは Azure に公開されません。 詳細については、「local.settings.file」に関するページを参照してください。
- package.json: パッケージの依存関係の一覧、メイン エントリポイント、スクリプトなどの構成オプションを含めます。
関数の登録
v3 モデルは、2 つのファイルの存在に基づいて関数を登録します。 まず、アプリのルートから 1 レベル下のフォルダーにある function.json ファイルが必要です。 次に、関数をエクスポートする JavaScript ファイルが必要です。 既定では、モデルは function.json と同じフォルダーで index.js ファイルを検索します。 TypeScript を使用している場合は、function.json の scriptFile プロパティを使用して、コンパイルされた JavaScript ファイルを指す必要があります。 関数のファイルの場所またはエクスポート名をカスタマイズする場合は、関数のエントリ ポイントの構成に関する記事を参照してください。
エクスポートする関数は、常に v3 モデルで async function として宣言する必要があります。 同期関数をエクスポートすることはできますが、context.done() を呼び出して関数が完了したことを通知する必要があります。これは非推奨であり、推奨されません。
関数には、最初の引数として呼び出し contextが渡され、残りの引数として入力が渡されます。
次の例は、トリガーされたことをログし、Hello, world! で応答する単純な関数です。
{
"bindings": [
{
"type": "httpTrigger",
"direction": "in",
"name": "req",
"authLevel": "anonymous",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "res"
}
]
}
module.exports = async function (context, request) {
context.log('Http function was triggered.');
context.res = { body: 'Hello, world!' };
};
プログラミング モデルにより、package.json の main フィールドに基づいて関数が読み込まれます。 1 つのファイル、glob パターンを使って複数のファイルに main フィールドを設定できます。 次の表に、main フィールドの値の例を示します。
| 例 | 説明 |
|---|---|
src/index.js |
1 つのルート ファイルから関数を登録します。 |
src/functions/*.js |
各関数を独自のファイルから登録します。 |
src/{index.js,functions/*.js} |
各関数を独自のファイルから登録するが、一般的なアプリ レベルのコード用のルート ファイルがある組み合わせ。 |
関数を登録するには、app オブジェクトを @azure/functions npm モジュールからインポートし、トリガーの型に固有のメソッドを呼び出す必要があります。 関数を登録するときの 1 つ目の引数は、関数名です。 2 目の引数は、トリガー、ハンドラー、その他の入力や出力の構成を指定する options オブジェクトです。 トリガーの構成が不要な場合は、options オブジェクトの代わりに、ハンドラーを 2 つ目の引数として直接渡すことができます。
package.json ファイルの main フィールドに基づいてファイルが (直接または間接的に) 読み込まれる限り、プロジェクト内の任意のファイルから関数の登録を実行できます。 実行の開始後は関数を登録できないので、関数はグローバル スコープで登録する必要があります。
次の例は、トリガーされたことをログし、Hello, world! で応答する単純な関数です。
const { app } = require('@azure/functions');
app.http('helloWorld1', {
methods: ['POST', 'GET'],
handler: async (request, context) => {
context.log('Http function was triggered.');
return { body: 'Hello, world!' };
}
});
入力と出力
関数には、トリガーというプライマリ入力を 1 つだけ指定する必要があります。 また、セカンダリ入力および/またはセカンダリ出力を指定することもできます。 入力と出力は function.json ファイルで構成され、バインディングとも呼ばれます。
入力
入力は、direction が in に設定されたバインディングです。 トリガーとセカンダリ入力の主な違いは、トリガーの type が Trigger で終わることです (例: 型 blobTrigger と型 blob)。 ほとんどの関数ではトリガーのみが使用され、多くのセカンダリ入力の型はサポートされていません。
入力には、いくつかの方法でアクセスできます。
[推奨] 関数に渡される引数として:
function.jsonで定義されているのと同じ順序で引数を使用します。function.jsonで定義されたnameプロパティは、引数の名前と一致する必要はありませんが、整理するために推奨されています。module.exports = async function (context, myTrigger, myInput, myOtherInput) { ... };context.bindingsのプロパティとして:function.jsonで定義されたnameプロパティと一致するキーを使用します。module.exports = async function (context) { context.log("This is myTrigger: " + context.bindings.myTrigger); context.log("This is myInput: " + context.bindings.myInput); context.log("This is myOtherInput: " + context.bindings.myOtherInput); };
出力
出力は、direction が out に設定されたバインディングであり、いくつかの方法で設定できます。
[出力が 1 つの場合に推奨] 値を直接返す: 非同期関数を使用している場合は、値を直接返すことができます。 次の例のように、
function.jsonで出力バインディングのnameプロパティを$returnに変更する必要があります。{ "name": "$return", "type": "http", "direction": "out" }module.exports = async function (context, request) { return { body: "Hello, world!" }; }[出力が複数の場合に推奨] すべての出力を含むオブジェクトを返す: 非同期関数を使用している場合、
function.jsonの各バインディングの名前と一致するプロパティを持つオブジェクトを返すことができます。 次の例では、"httpResponse" と "queueOutput" という名前の出力バインディングを使用します。{ "name": "httpResponse", "type": "http", "direction": "out" }, { "name": "queueOutput", "type": "queue", "direction": "out", "queueName": "helloworldqueue", "connection": "storage_APPSETTING" }module.exports = async function (context, request) { let message = 'Hello, world!'; return { httpResponse: { body: message }, queueOutput: message }; };context.bindingsに値を設定する: 非同期関数を使用していない場合、または前のオプションを使用しない場合は、context.bindingsに直接値を設定することができます。ここで、キーはバインディングの名前と一致します。 次の例では、"httpResponse" と "queueOutput" という名前の出力バインディングを使用します。{ "name": "httpResponse", "type": "http", "direction": "out" }, { "name": "queueOutput", "type": "queue", "direction": "out", "queueName": "helloworldqueue", "connection": "storage_APPSETTING" }module.exports = async function (context, request) { let message = 'Hello, world!'; context.bindings.httpResponse = { body: message }; context.bindings.queueOutput = message; };
バインドのデータ型
入力バインディングで dataType プロパティを使用して入力の種類を変更できますが、いくつかの制限があります。
- Node.js では、
stringとbinaryのみがサポートされています (streamはサポートされていません) - HTTP 入力の場合、
dataTypeプロパティは無視されます。 代わりに、requestオブジェクトのプロパティを使用して、目的のフォームで本文を取得します。 詳細については、「HTTP 要求」を参照してください。
ストレージ キュー トリガーの次の例では、myQueueItem の既定の型は string ですが、dataType を binary に設定すると、型は Node.js Buffer に変わります。
{
"name": "myQueueItem",
"type": "queueTrigger",
"direction": "in",
"queueName": "helloworldqueue",
"connection": "storage_APPSETTING",
"dataType": "binary"
}
const { Buffer } = require('node:buffer');
module.exports = async function (context, myQueueItem) {
if (typeof myQueueItem === 'string') {
context.log('myQueueItem is a string');
} else if (Buffer.isBuffer(myQueueItem)) {
context.log('myQueueItem is a buffer');
}
};
関数には、トリガーというプライマリ入力を 1 つだけ指定する必要があります。 また、セカンダリ入力、戻り値の出力というプライマリ出力、セカンダリ出力を指定することもできます。 Node.js プログラミング モデルのコンテキスト以外では、入力と出力はバインディングとも呼ばれます。 v4 より前のモデルでは、これらのバインディングは function.json ファイルで構成されていました。
トリガーの入力
トリガーは、唯一の必要な入力または出力です。 ほとんどのトリガーの型では、トリガーの型にちなんだ名前の app オブジェクトのメソッドを使って関数を登録します。 トリガーに固有の構成は、options 引数で直接指定できます。 たとえば、HTTP トリガーを使うと、ルートを指定できます。 実行中に、このトリガーに対応する値はハンドラーの 1 つ目の引数として渡されます。
const { app } = require('@azure/functions');
app.http('helloWorld1', {
route: 'hello/world',
handler: async (request, context) => {
...
}
});
出力を返す
戻り値の出力は省略可能であり、場合によっては既定で構成されます。 たとえば、app.http に登録された HTTP トリガーは、HTTP 応答出力を自動的に返すように構成されています。 ほとんどの戻り値の型では、@azure/functions モジュールからエクスポートされた output オブジェクトを利用して、options 引数の戻り値の構成を指定します。 実行中に、ハンドラーから返すことでこの出力を設定します。
次の例では、タイマー トリガーとストレージ キュー出力を使用します。
const { app, output } = require('@azure/functions');
app.timer('timerTrigger1', {
schedule: '0 */5 * * * *',
return: output.storageQueue({
connection: 'storage_APPSETTING',
...
}),
handler: (myTimer, context) => {
return { hello: 'world' }
}
});
追加の入力と出力
トリガーと戻り値に加えて、関数の登録時に options 引数に追加の入力または出力を指定できます。 @azure/functions モジュールからエクスポートされた input と output のオブジェクトには、構成を構築するのに役立つ型固有のメソッドが用意されています。 実行中に、context.extraInputs.get または context.extraOutputs.set を使って値を取得または設定し、元の構成オブジェクトを 1 つ目の引数として渡します。
次の例は、ストレージ キューによってトリガーされる関数です。追加のストレージ BLOB 入力が追加のストレージ BLOB 出力にコピーされます。 キュー メッセージはファイルの名前にする必要があり、バインディング式を使用して、{queueTrigger} をコピーする BLOB 名として置き換えます。
const { app, input, output } = require('@azure/functions');
const blobInput = input.storageBlob({
connection: 'storage_APPSETTING',
path: 'helloworld/{queueTrigger}',
});
const blobOutput = output.storageBlob({
connection: 'storage_APPSETTING',
path: 'helloworld/{queueTrigger}-copy',
});
app.storageQueue('copyBlob1', {
queueName: 'copyblobqueue',
connection: 'storage_APPSETTING',
extraInputs: [blobInput],
extraOutputs: [blobOutput],
handler: (queueItem, context) => {
const blobInputValue = context.extraInputs.get(blobInput);
context.extraOutputs.set(blobOutput, blobInputValue);
}
});
汎用の入力と出力
@azure/functions モジュールによってエクスポートされる app、trigger、input、output のオブジェクトは、ほとんどの型に対して型固有のメソッドが用意されています。 サポートされていないすべての型については、手動で構成を指定できる generic メソッドが用意されています。 また、generic メソッドは、型固有のメソッドに指定されている既定の設定を変更する場合にも使用できます。
次の例は、型固有のメソッドではなく、ジェネリック メソッドを使った簡単な HTTP トリガー関数です。
const { app, output, trigger } = require('@azure/functions');
app.generic('helloWorld1', {
trigger: trigger.generic({
type: 'httpTrigger',
methods: ['GET', 'POST']
}),
return: output.generic({
type: 'http'
}),
handler: async (request, context) => {
context.log(`Http function processed request for url "${request.url}"`);
return { body: `Hello, world!` };
}
});
呼び出しコンテキスト
関数の各呼び出しには、呼び出し context オブジェクトが渡され、入力の読み取り、出力の設定、ログへの書き込み、さまざまなメタデータの読み取りに使用されます。 v3 モデルでは、コンテキスト オブジェクトは常にハンドラーに渡される最初の引数です。
context オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
invocationId |
現在の関数呼び出しの ID です。 |
executionContext |
実行コンテキストに関するページを参照してください。 |
bindings |
バインディングに関するページを参照してください。 |
bindingData |
値そのものを含まない、この呼び出しのトリガー入力に関するメタデータ。 たとえば、イベント ハブ トリガーには enqueuedTimeUtc プロパティがあります。 |
traceContext |
分散トレース用のコンテキスト。 詳細については、「Trace Context」を参照してください。 |
bindingDefinitions |
function.json で定義されている入力と出力の構成。 |
req |
「HTTP 要求」を参照してください。 |
res |
「HTTP 応答」を参照してください。 |
context.executionContext
context.executionContext オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
invocationId |
現在の関数呼び出しの ID です。 |
functionName |
呼び出されている関数の名前。 function.json ファイルを含むフォルダーの名前によって、関数の名前が決まります。 |
functionDirectory |
function.json ファイルを含むフォルダー。 |
retryContext |
「再試行コンテキスト」を参照してください。 |
context.executionContext.retryContext
context.executionContext.retryContext オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
retryCount |
現在の再試行を表す数値。 |
maxRetryCount |
実行が再試行される回数の最大数。 値 -1 は、無制限に再試行することを意味します。 |
exception |
再試行の原因となった例外。 |
context.bindings
context.bindings オブジェクトは、入力の読み取りまたは出力の設定に使用されます。 次の例は、ストレージ キュー トリガーです。これは、context.bindings を使用して、ストレージ BLOB 入力をストレージ BLOB 出力にコピーします。 キュー メッセージのコンテンツは、バインド式を利用して、コピーするファイル名として {queueTrigger} を置き換えます。
{
"name": "myQueueItem",
"type": "queueTrigger",
"direction": "in",
"connection": "storage_APPSETTING",
"queueName": "helloworldqueue"
},
{
"name": "myInput",
"type": "blob",
"direction": "in",
"connection": "storage_APPSETTING",
"path": "helloworld/{queueTrigger}"
},
{
"name": "myOutput",
"type": "blob",
"direction": "out",
"connection": "storage_APPSETTING",
"path": "helloworld/{queueTrigger}-copy"
}
module.exports = async function (context, myQueueItem) {
const blobValue = context.bindings.myInput;
context.bindings.myOutput = blobValue;
};
context.done
context.done メソッドは非推奨です。 非同期関数がサポートされる前は、context.done() を呼び出して関数が完了したことを通知していました。
module.exports = function (context, request) {
context.log("this pattern is now deprecated");
context.done();
};
現在は、context.done() の呼び出しを削除し、関数を非同期としてマークして、(await していなくても) Promise を返すようにすることをお勧めします。 関数が終了すると (つまり、返された Promise が解決されると)、v3 モデルは関数が完了したことを認識します。
module.exports = async function (context, request) {
context.log("you don't need context.done or an awaited call")
};
関数の呼び出しごとに、呼び出しとログに使用されるメソッドに関する情報と共に、呼び出し context オブジェクトが渡されます。 v4 モデルでは、通常、context オブジェクトはハンドラーに渡される 2 つ目の引数です。
InvocationContext クラスには次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
invocationId |
現在の関数呼び出しの ID です。 |
functionName |
関数の名前です。 |
extraInputs |
追加の入力の値を取得するために使われます。 詳細については、「追加の入力と出力」を参照してください。 |
extraOutputs |
追加の出力の値を取得するために使われます。 詳細については、「追加の入力と出力」を参照してください。 |
retryContext |
「再試行コンテキスト」を参照してください。 |
traceContext |
分散トレース用のコンテキスト。 詳細については、「Trace Context」を参照してください。 |
triggerMetadata |
値そのものを含まない、この呼び出しのトリガー入力に関するメタデータ。 たとえば、イベント ハブ トリガーには enqueuedTimeUtc プロパティがあります。 |
options |
関数を登録するときに、検証後に使われるオプション。既定値が明示的に指定されています。 |
再試行コンテキスト
retryContext オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
retryCount |
現在の再試行を表す数値。 |
maxRetryCount |
実行が再試行される回数の最大数。 値 -1 は、無制限に再試行することを意味します。 |
exception |
再試行の原因となった例外。 |
詳細については、「retry-policies」を参照してください。
ログの記録
Azure Functions では、context.log() を使用してログを書き込むことをお勧めします。 Azure Functions は Azure Application Insights と統合されているため、関数アプリのログをより適切に取り込むことができます。 Azure Monitor の一部である Application Insights には、アプリケーション ログとトレース出力の両方を収集、視覚的にレンダリング、分析するための機能が用意されています。 詳細については、「Azure Functions の監視」を参照してください。
Note
代替の Node.js console.log メソッドを使う場合、これらのログはアプリレベルで追跡され、特定の関数に関連付けられることは "ありません"。 すべてのログが特定の関数に関連付けられるように、console ではなく context をログに使うことを "強くお勧めします"。
次の例では、既定の「情報」レベルで呼び出し ID を含む、ログを書き込んでいます。
context.log(`Something has happened. Invocation ID: "${context.invocationId}"`);
ログ レベル
既定の context.log メソッドに加えて、特定のレベルでログを書き込むことができる次のメソッドがあります。
| メソッド | 説明 |
|---|---|
context.log.error() |
ログにエラーレベルのイベントを書き込みます。 |
context.log.warn() |
警告レベルのイベントをログに書き込みます。 |
context.log.info() |
情報レベル イベントをログに書き込みます。 |
context.log.verbose() |
トレースレベル イベントをログに書き込みます。 |
| メソッド | 説明 |
|---|---|
context.trace() |
トレースレベル イベントをログに書き込みます。 |
context.debug() |
デバッグレベル イベントをログに書き込みます。 |
context.info() |
情報レベル イベントをログに書き込みます。 |
context.warn() |
警告レベルのイベントをログに書き込みます。 |
context.error() |
ログにエラーレベルのイベントを書き込みます。 |
ログ レベルの構成
Azure Functions では、ログの追跡と表示に使用するしきい値レベルを定義できます。 しきい値を設定するには、host.json ファイルの logging.logLevel プロパティを使用します。 このプロパティを使用すると、すべての関数に適用される既定のレベル、または個々の関数のしきい値を定義できます。 詳しくは、Azure Functions で監視を構成する方法に関するページを参照してください。
カスタム データを追跡する
既定では、Azure Functions によって出力がトレースとして Application Insights に書き込まれます。 より細かく制御する場合は、代わりに Application Insights Node.js SDK を使用して、Application Insights インスタンスにカスタム データを送信できます。
const appInsights = require("applicationinsights");
appInsights.setup();
const client = appInsights.defaultClient;
module.exports = async function (context, request) {
// Use this with 'tagOverrides' to correlate custom logs to the parent function invocation.
var operationIdOverride = {"ai.operation.id":context.traceContext.traceparent};
client.trackEvent({name: "my custom event", tagOverrides:operationIdOverride, properties: {customProperty2: "custom property value"}});
client.trackException({exception: new Error("handled exceptions can be logged with this method"), tagOverrides:operationIdOverride});
client.trackMetric({name: "custom metric", value: 3, tagOverrides:operationIdOverride});
client.trackTrace({message: "trace message", tagOverrides:operationIdOverride});
client.trackDependency({target:"http://dbname", name:"select customers proc", data:"SELECT * FROM Customers", duration:231, resultCode:0, success: true, dependencyTypeName: "ZSQL", tagOverrides:operationIdOverride});
client.trackRequest({name:"GET /customers", url:"http://myserver/customers", duration:309, resultCode:200, success:true, tagOverrides:operationIdOverride});
};
tagOverrides パラメーターにより、関数の呼び出し ID に operation_Id を設定します。 この設定により、特定の関数呼び出しに関するすべての自動生成およびカスタムのログを関連付けることができます。
HTTP トリガー
HTTP および webhook トリガーでは、要求オブジェクトと応答オブジェクトを使用して HTTP メッセージを表します。
HTTP および webhook トリガーでは、HttpRequest オブジェクトと HttpResponse オブジェクトを使用して HTTP メッセージを表します。 これらのクラスは、Node.js の undici パッケージを使って、fetch 標準のサブセットを表しています。
HTTP 要求
要求には、次のいくつかの方法でアクセスできます。
関数の 2 番目の引数として:
module.exports = async function (context, request) { context.log(`Http function processed request for url "${request.url}"`);context.reqプロパティから:module.exports = async function (context, request) { context.log(`Http function processed request for url "${context.req.url}"`);名前付き入力バインドから: このオプションは、HTTP バインド以外のバインドと同じように機能します。
function.jsonのバインド名は、context.bindingsのキー、または次の例の「request1」と一致している必要があります。{ "name": "request1", "type": "httpTrigger", "direction": "in", "authLevel": "anonymous", "methods": [ "get", "post" ] }module.exports = async function (context, request) { context.log(`Http function processed request for url "${context.bindings.request1.url}"`);
HttpRequest オブジェクトには、次のプロパティがあります。
| プロパティ | タイプ | 説明 |
|---|---|---|
method |
string |
この関数を呼び出すために使われる HTTP 要求メソッド。 |
url |
string |
要求 URL。 |
headers |
Record<string, string> |
HTTP 要求ヘッダー。 このオブジェクトでは、大文字と小文字が区別されます。 代わりに request.getHeader('header-name') を使用することをお勧めします。大文字と小文字は区別されません。 |
query |
Record<string, string> |
URL の文字列パラメーター キーと値のクエリを実行します。 |
params |
Record<string, string> |
ルート パラメーター キーと値。 |
user |
HttpRequestUser | null |
ログインしたユーザーを表すオブジェクト。Functions の認証、SWA 認証、またはそのようなユーザーがログインしていない場合は null。 |
body |
Buffer | string | any |
メディアの種類が "application/octet-stream" または "multipart/*" の場合、body はバッファーです。 値が JSON 解析可能な文字列の場合、body は解析されたオブジェクトです。 それ以外の場合、body は文字列です。 |
rawBody |
string |
文字列としての本文。 名前にもかかわらず、このプロパティは Buffer を返しません。 |
bufferBody |
Buffer |
バッファーとしての本文。 |
この要求には、HTTP トリガー関数のハンドラーの 1 つ目の引数としてアクセスできます。
async (request, context) => {
context.log(`Http function processed request for url "${request.url}"`);
HttpRequest オブジェクトには、次のプロパティがあります。
| プロパティ | タイプ | 説明 |
|---|---|---|
method |
string |
この関数を呼び出すために使われる HTTP 要求メソッド。 |
url |
string |
要求 URL。 |
headers |
Headers |
HTTP 要求ヘッダー。 |
query |
URLSearchParams |
URL の文字列パラメーター キーと値のクエリを実行します。 |
params |
Record<string, string> |
ルート パラメーター キーと値。 |
user |
HttpRequestUser | null |
ログインしたユーザーを表すオブジェクト。Functions の認証、SWA 認証、またはそのようなユーザーがログインしていない場合は null。 |
body |
ReadableStream | null |
読み取り可能なストリームとしての本文。 |
bodyUsed |
boolean |
本文が既読かどうかを示すブール値。 |
要求または応答の本文にアクセスするには、次のメソッドを使用できます。
| メソッド | 戻り値の型 |
|---|---|
arrayBuffer() |
Promise<ArrayBuffer> |
blob() |
Promise<Blob> |
formData() |
Promise<FormData> |
json() |
Promise<unknown> |
text() |
Promise<string> |
Note
本文の関数は一度しか実行できません。後続の呼び出しは、空の文字列または ArrayBuffer で解決されます。
HTTP 応答
応答は、いくつかの方法で設定できます。
context.resプロパティを設定する:module.exports = async function (context, request) { context.res = { body: `Hello, world!` };応答を返す: 関数が非同期で、
function.jsonでバインド名を$returnに設定している場合、contextに設定するのではなく、応答を直接返すことができます。{ "type": "http", "direction": "out", "name": "$return" }module.exports = async function (context, request) { return { body: `Hello, world!` };名前付き出力バインドを設定する: このオプションは、HTTP バインド以外のバインドと同じように機能します。
function.jsonのバインド名は、context.bindingsのキー、または次の例の「response1」と一致している必要があります。{ "type": "http", "direction": "out", "name": "response1" }module.exports = async function (context, request) { context.bindings.response1 = { body: `Hello, world!` };context.res.send()を呼び出す: このオプションは非推奨です。 これは暗黙的にcontext.done()を呼び出し、非同期関数では使用できません。module.exports = function (context, request) { context.res.send(`Hello, world!`);
応答を設定するときに新しいオブジェクトを作成する場合、そのオブジェクトはインターフェイスと HttpResponseSimple 一致している必要があります。このインターフェイスには、次のプロパティがあります。
| プロパティ | タイプ | 説明 |
|---|---|---|
headers |
Record<string, string> (省略可) |
HTTP 応答ヘッダー。 |
cookies |
Cookie[] (省略可) |
HTTP 応答の Cookie。 |
body |
any (省略可) |
HTTP 応答の本文。 |
statusCode |
number (省略可) |
HTTP 応答状態コード. 設定しない場合の既定値は 200 です。 |
status |
number (省略可) |
statusCode と同じです。 statusCode を設定した場合、このプロパティは無視されます。 |
context.res オブジェクトは、上書きせずに変更することもできます。 既定の context.res オブジェクトでは、HttpResponseFull インターフェイスが使用されます。このインターフェイスでは、HttpResponseSimple プロパティに加えて次のメソッドがサポートされています。
| メソッド | 説明 |
|---|---|
status() |
状態を設定します。 |
setHeader() |
ヘッダー フィールドを設定します。 注: res.set() と res.header() もサポートされており、同じことを行います。 |
getHeader() |
ヘッダー フィールドを取得します。 注: res.get() もサポートされており、同じことを行います。 |
removeHeader() |
ヘッダーを削除します。 |
type() |
"content-type" ヘッダーを設定します。 |
send() |
このメソッドは非推奨とされます。 本文を設定し、context.done() を呼び出して、同期関数が終了したことを示します。 注: res.end() もサポートされており、同じことを行います。 |
sendStatus() |
このメソッドは非推奨とされます。 状態コードを設定し、context.done() を呼び出して、同期関数が完了したことを示します。 |
json() |
このメソッドは非推奨とされます。 "content-type" を "application/json" に設定し、本文を設定し、context.done() を呼び出して、同期関数が完了したことを示します。 |
応答は、いくつかの方法で設定できます。
型
HttpResponseInitを使う単純なインターフェイスとして: このオプションは、応答を返す方法として最も簡潔です。return { body: `Hello, world!` };HttpResponseInitインターフェイスには次のプロパティがあります。プロパティ タイプ 説明 bodyBodyInit(省略可)ArrayBuffer、AsyncIterable<Uint8Array>、Blob、FormData、Iterable<Uint8Array>、NodeJS.ArrayBufferView、URLSearchParams、null、stringのいずれかの HTTP 応答本文。jsonBodyany(省略可)JSON でシリアル化可能な HTTP 応答の本文。 設定した場合、このプロパティが優先され、 HttpResponseInit.bodyプロパティは無視されます。statusnumber(省略可)HTTP 応答状態コード. 設定しない場合の既定値は 200です。headersHeadersInit(省略可)HTTP 応答ヘッダー。 cookiesCookie[](省略可)HTTP 応答の Cookie。 型
HttpResponseのクラスのクラスとして: このオプションの場合、ヘッダーのような応答のさまざまな部分を読み取り、変更するヘルパー メソッドを利用できます。const response = new HttpResponse({ body: `Hello, world!` }); response.headers.set('content-type', 'application/json'); return response;HttpResponseクラスは、コンストラクターの引数として省略可能なHttpResponseInitを受け取ります。また、次のプロパティがあります。プロパティ タイプ 説明 statusnumberHTTP 応答状態コード. headersHeadersHTTP 応答ヘッダー。 cookiesCookie[]HTTP 応答の Cookie。 bodyReadableStream | null読み取り可能なストリームとしての本文。 bodyUsedboolean本文が既に読み取られているかどうかを示すブール値。
HTTP ストリーム
HTTP ストリームは、大規模なデータの処理、OpenAI 応答のストリーミング、動的コンテンツの配信、その他のコア HTTP シナリオのサポートを容易にする機能です。 これにより、Node.js 関数アプリの HTTP エンドポイントへの要求と HTTP エンドポイントからの応答をストリーミングできます。 アプリで、HTTP を経由してクライアントとサーバー間でリアルタイムの交換や対話を行う必要があるシナリオでは、HTTP ストリームを使用します。 また、HTTP ストリームを使用すると、HTTP を使用するときにアプリのパフォーマンスと信頼性を最大限に高めることができます。
重要
HTTP ストリームは、v3 モデルではサポートされていません。 HTTP ストリーム機能を使用するには、v4 モデルにアップグレードしてください。
プログラミング モデル v4 の既存の HttpRequest 型と HttpResponse 型では、ストリームとして処理するなど、メッセージ本文を処理するさまざまな方法が既にサポートされています。
前提条件
@azure/functionsnpm パッケージ バージョン 4.3.0 以降。- Azure Functions ランタイム バージョン 4.28 以降。
- Azure Functions Core Tools バージョン 4.0.5530 以降。これには、適切なランタイム バージョンが含まれています。
ストリームを有効にする
Azure の関数アプリとローカル プロジェクトで HTTP ストリームを有効にするには、次の手順を使用します。
大量のデータをストリーミングする予定であれば、Azure の
FUNCTIONS_REQUEST_BODY_SIZE_LIMIT設定を変更します。 本文の許可されている既定の最大サイズは104857600です。これにより、要求のサイズは 100 MB 以下に制限されます。ローカル開発の場合は、さらに、
FUNCTIONS_REQUEST_BODY_SIZE_LIMITを local.settings.json ファイルに追加します。アプリのメイン フィールドに含まれる任意のファイル内のアプリに次のコードを追加します。
const { app } = require('@azure/functions'); app.setup({ enableHttpStream: true });
ストリームの例
次の例は、HTTP によってトリガーされ、HTTP POST 要求を介してデータを受信する関数を示しています。この関数は、このデータを指定された出力ファイルにストリーミングします。
const { app } = require('@azure/functions');
const { createWriteStream } = require('fs');
const { Writable } = require('stream');
app.http('httpTriggerStreamRequest', {
methods: ['POST'],
authLevel: 'anonymous',
handler: async (request, context) => {
const writeStream = createWriteStream('<output file path>');
await request.body.pipeTo(Writable.toWeb(writeStream));
return { body: 'Done!' };
},
});
次の例は、HTTP によってトリガーされ、受信した HTTP GET 要求への応答としてファイルの内容をストリーミングする関数を示しています。
const { app } = require('@azure/functions');
const { createReadStream } = require('fs');
app.http('httpTriggerStreamResponse', {
methods: ['GET'],
authLevel: 'anonymous',
handler: async (request, context) => {
const body = createReadStream('<input file path>');
return { body };
},
});
すぐに実行できるストリーム使用サンプル アプリについては、GitHub のこちらの例を確認してください。
ストリームに関する考慮事項
- ストリームの使用によって最大限のメリットを得るには、
request.bodyを使用します。 本文を常に文字列として返すrequest.text()などのメソッドも引き続き使用できます。
フック
フックは v3 モデルではサポートされていません。 フックを使用するには、v4 モデル にアップグレードします。
フックを使用して、Azure Functions ライフサイクルのさまざまなポイントでコードを実行します。 フックは登録された順序で実行され、アプリ内の任意のファイルから登録できます。 現在、フックには、"アプリ" レベルと "呼び出し" レベルの 2 つのスコープがあります。
呼び出しフック
呼び出しフックは、関数の呼び出しごとに 1 回、preInvocation フックで呼び出し前に、または postInvocation フックで呼び出し後に実行されます。 既定では、フックはすべてのトリガーの種類に対して実行されますが、種類でフィルター処理することもできます。 次の例は、呼び出しフックを登録し、トリガーの種類でフィルター処理する方法を示しています。
const { app } = require('@azure/functions');
app.hook.preInvocation((context) => {
if (context.invocationContext.options.trigger.type === 'httpTrigger') {
context.invocationContext.log(
`preInvocation hook executed for http function ${context.invocationContext.functionName}`
);
}
});
app.hook.postInvocation((context) => {
if (context.invocationContext.options.trigger.type === 'httpTrigger') {
context.invocationContext.log(
`postInvocation hook executed for http function ${context.invocationContext.functionName}`
);
}
});
フック ハンドラーの最初の引数は、そのフックの種類に固有のコンテキスト オブジェクトです。
PreInvocationContext オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
inputs |
呼び出しに渡される引数。 |
functionHandler |
呼び出しの関数ハンドラー。 この値を変更すると、関数自体に影響します。 |
invocationContext |
関数に渡される呼び出しコンテキスト オブジェクト。 |
hookData |
同じスコープ内のフック間でデータを格納および共有するための推奨される場所。 他のフックのデータと競合しないように、一意のプロパティ名を使用する必要があります。 |
PostInvocationContext オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
inputs |
呼び出しに渡される引数。 |
result |
関数の結果。 この値に対する変更は、関数の全体的な結果に影響します。 |
error |
関数によってスローされたエラー。エラーがない場合は null または undefined。 この値に対する変更は、関数の全体的な結果に影響します。 |
invocationContext |
関数に渡される呼び出しコンテキスト オブジェクト。 |
hookData |
同じスコープ内のフック間でデータを格納および共有するための推奨される場所。 他のフックのデータと競合しないように、一意のプロパティ名を使用する必要があります。 |
アプリ フック
アプリ フックは、アプリのインスタンスごとに 1 回、起動時に appStart フックで、または終了時に appTerminate フックで実行されます。 アプリ終了フックの実行時間は限られており、すべてのシナリオで実行されるわけではありません。
現在、Azure Functions ランタイムは、呼び出しの外部でのコンテキスト ログ記録をサポートしていません。 Application Insights の npm パッケージを使用して、アプリ レベルのフック中にデータをログに記録します。
次の例では、アプリ フックを登録します。
const { app } = require('@azure/functions');
app.hook.appStart((context) => {
// add your logic here
});
app.hook.appTerminate((context) => {
// add your logic here
});
フック ハンドラーの最初の引数は、そのフックの種類に固有のコンテキスト オブジェクトです。
AppStartContext オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
hookData |
同じスコープ内のフック間でデータを格納および共有するための推奨される場所。 他のフックのデータと競合しないように、一意のプロパティ名を使用する必要があります。 |
AppTerminateContext オブジェクトには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
hookData |
同じスコープ内のフック間でデータを格納および共有するための推奨される場所。 他のフックのデータと競合しないように、一意のプロパティ名を使用する必要があります。 |
スケーリングと同時性
既定では、Azure Functions は、アプリケーションの負荷を自動的に監視し、必要に応じて Node.js 用のホスト インスタンスをさらに作成します。 Azure Functions は、さまざまなトリガーの種類の組み込み(ユーザーが構成できない) しきい値 (メッセージの経過時間や QueueTrigger のキュー サイズなど) を使用して、インスタンスを追加するタイミングを決定します。 詳細については、「従量課金プランと Premium プランのしくみ」をご覧ください。
ほとんどの Node.js アプリケーションでは、このスケーリング動作で十分です。 CPUにバインドされたアプリケーションの場合、複数の言語ワーカープロセスを使用して、パフォーマンスをさらに向上させることができます。 FUNCTIONS_WORKER_PROCESS_COUNT アプリケーション設定を使用して、ホストあたりのワーカー プロセスの数を既定の 1 から最大 10 まで増やすことができます。 次に、Azure Functions は、これらのワーカー間で同時関数呼び出しを均等に分散しようとします。 この動作により、CPU を集中的に使用する関数が、他の関数の実行をブロックする可能性が低くなります。 この設定は、需要に合わせてアプリケーションをスケールアウトするときに Azure Functions が作成する各ホストに適用されます。
警告
FUNCTIONS_WORKER_PROCESS_COUNT 設定を使用するときには注意が必要です。 同じインスタンスで複数のプロセスを実行すると、予期しない動作が発生し、関数の読み込み時間が長くなる可能性があります。 この設定を使用する場合は、パッケージ ファイルから実行してこれらの欠点を補うことを強くお勧めします。
Node バージョン
ランタイムが使用している現在のバージョンを確認するには、任意の関数から process.version をログに記録します。 各プログラミング モデルでサポートされる Node.js バージョンの一覧については supported versions を参照してください。
Node のバージョンを設定する
Node.js バージョンをアップグレードする方法は、関数アプリを実行する OS によって異なります。
Windows で実行する場合、Node.js バージョンは WEBSITE_NODE_DEFAULT_VERSION アプリケーション設定によって設定されます。 この設定は、Azure CLI を使用するか、Azure portal で更新できます。
Node.js バージョンの詳細については、「使用可能なバージョン」を参照してください。
Node.js バージョンをアップグレードする前に、関数アプリが最新バージョンの Azure Functions ランタイムで実行されていることを確認してください。 ランタイム バージョンをアップグレードする必要がある場合は、「Azure Functions バージョン 3.x からバージョン 4.x にアプリを移行する」を参照してください。
Azure CLI az functionapp config appsettings set コマンドを実行して、Windows で実行されている関数アプリの Node.js バージョンを更新します。
az functionapp config appsettings set --settings WEBSITE_NODE_DEFAULT_VERSION=~20 \
--name <FUNCTION_APP_NAME> --resource-group <RESOURCE_GROUP_NAME>
これにより、WEBSITE_NODE_DEFAULT_VERSION アプリケーション設定がサポートされている LTS バージョン ~20 に設定されます。
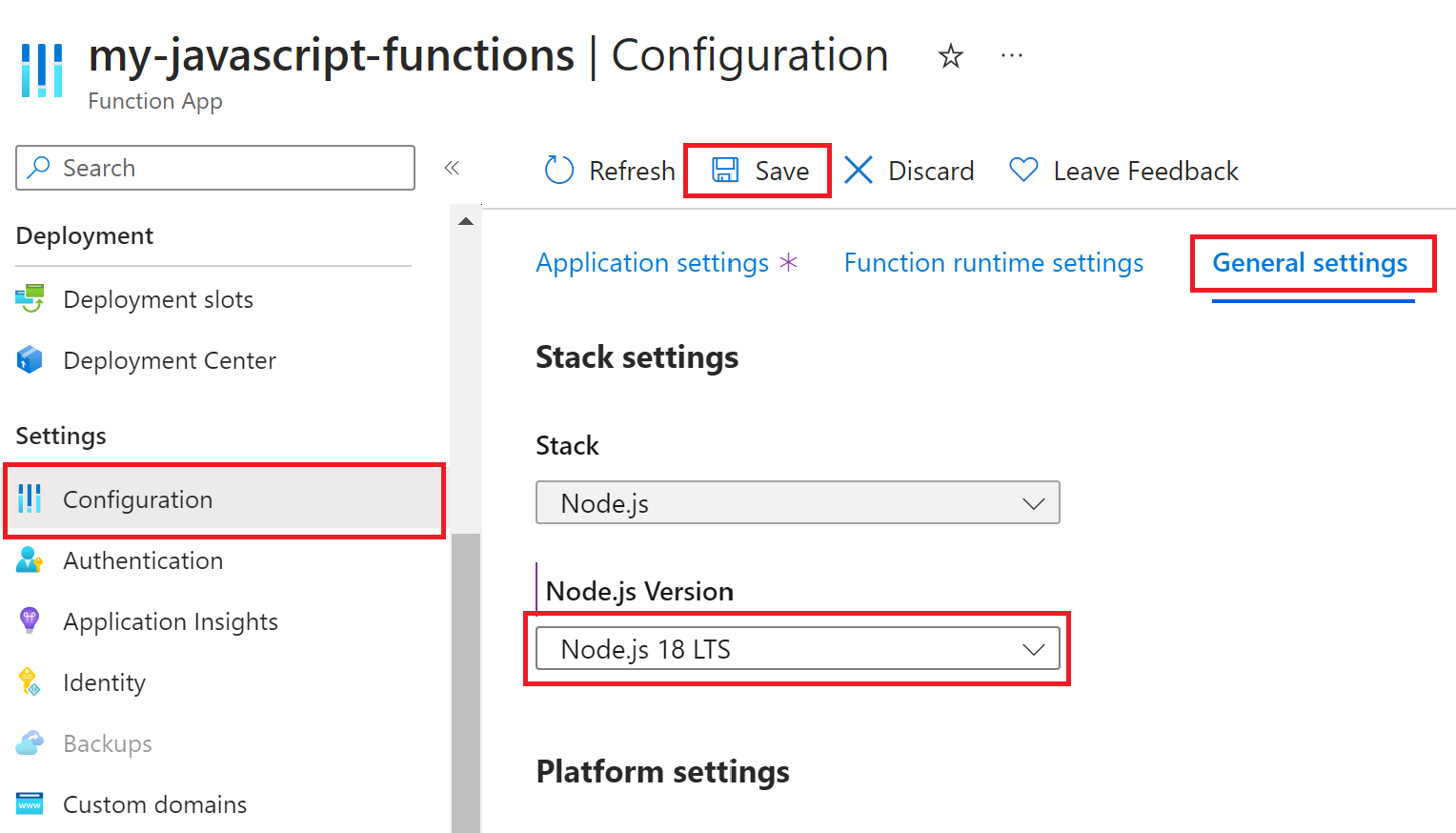
変更が行われた後、関数アプリが再起動します。 Functions の Node.js サポートの詳細については、「言語ランタイム サポート ポリシー」を参照してください。
環境変数
環境変数は、運用上の秘密 (接続文字列、キー、エンドポイントなど) やプロファイリング変数などの環境設定に役立ちます。 ローカル環境とクラウド環境の両方に環境変数を追加し、関数コードで process.env を介してアクセスできます。
次の例では、WEBSITE_SITE_NAME 環境変数をログに記録します。
module.exports = async function (context) {
context.log(`WEBSITE_SITE_NAME: ${process.env["WEBSITE_SITE_NAME"]}`);
}
async function timerTrigger1(myTimer, context) {
context.log(`WEBSITE_SITE_NAME: ${process.env["WEBSITE_SITE_NAME"]}`);
}
ローカル開発環境
ローカルで実行する場合は、関数プロジェクトに local.settings.json ファイルが含まれています。ここに Values オブジェクトの環境変数を格納します。
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "",
"FUNCTIONS_WORKER_RUNTIME": "node",
"CUSTOM_ENV_VAR_1": "hello",
"CUSTOM_ENV_VAR_2": "world"
}
}
Azure クラウド環境
Azure で実行する場合は、関数アプリでアプリケーション設定 (サービス接続文字列など) を設定して使用し、実行時にこれらの設定を環境変数として公開できます。
関数アプリの設定は、いくつかの方法で追加、更新、削除できます。
関数アプリの設定に変更を加えるためには、関数アプリを再起動する必要があります。
worker 環境変数
Node.js に固有の Functions 環境変数がいくつかあります。
languageWorkers__node__arguments
この設定では、Node.js プロセスを開始するときにカスタム引数を指定できます。 これは、デバッグ モードで worker を開始するためにローカルで使用されることが最も多いですが、カスタム引数が必要な場合は Azure でも使用できます。
警告
コールド スタート時間に悪影響を及ぼす可能性があるため、可能であれば、Azure では languageWorkers__node__arguments を使用しないでください。 事前ウォーミングされた worker を使用するのではなく、ランタイムはカスタム引数を使用して新しい worker を最初から開始する必要があります。
logging__logLevel__Worker
この設定では、Node.js 固有の worker ログの既定のログ レベルを調整します。 既定では、警告またはエラー ログのみが表示されますが、Node.js worker の問題を診断するのに役立つように information または debug に設定できます。 詳細については、「ログ レベルを構成する」を参照してください。
ECMAScript モジュール (プレビュー)
Note
現在、ECMAScript モジュールは Node.js 14 以降の Azure Functions のプレビュー機能です。
ECMAScript モジュール (ES モジュール) は、Node.js 用の新しい公式標準モジュール システムです。 これまで、この記事のコード サンプルは、CommonJS 構文を使用しています。 Node.js 14 以降で Azure Functions を実行するときに、ES モジュール構文を使用して関数を記述することを選択できます。
関数で ES モジュールを使用するには、.mjs 拡張子を使用するようにファイル名を変更します。 次の index.mjs ファイルの例は、ES モジュール構文を使用して uuid ライブラリをインポートし、値を返す、HTTP によってトリガーされる関数です。
import { v4 as uuidv4 } from 'uuid';
async function httpTrigger1(context, request) {
context.res.body = uuidv4();
};
export default httpTrigger;
import { v4 as uuidv4 } from 'uuid';
async function httpTrigger1(request, context) {
return { body: uuidv4() };
};
app.http('httpTrigger1', {
methods: ['GET', 'POST'],
handler: httpTrigger1
});
関数のエントリ ポイントを構成する
function.json のプロパティ scriptFile と entryPoint を使用して、エクスポートされた関数の名前と場所を構成できます。 scriptFile プロパティは、TypeScript を使用する場合に必要で、コンパイルされた JavaScript を指す必要があります。
scriptFile の使用
既定では、JavaScript 関数は index.js から実行されます。これは、対応する function.json と同じ親ディレクトリを共有するファイルです。
scriptFile を使用すると、次の例のようなフォルダー構造を取得できます。
<project_root>/
| - node_modules/
| - myFirstFunction/
| | - function.json
| - lib/
| | - sayHello.js
| - host.json
| - package.json
myFirstFunction に対する function.json には、エクスポートされた関数を実行するファイルを指し示す scriptFile プロパティが含まれている必要があります。
{
"scriptFile": "../lib/sayHello.js",
"bindings": [
...
]
}
entryPoint の使用
v3 モデルでは、関数が発見されて実行されるためには、module.exports を使用して関数をエクスポートする必要があります。 既定では、トリガーされたときに実行される関数は、そのファイルからの唯一のエクスポートです (run という名前のエクスポート、または index という名前のエクスポート)。 次の例では、function.json の entryPoint をカスタム値 "logHello" に設定します。
{
"entryPoint": "logHello",
"bindings": [
...
]
}
async function logHello(context) {
context.log('Hello, world!');
}
module.exports = { logHello };
ローカル デバッグ
ローカル デバッグには VS Code を使用することをお勧めします。これにより、Node.js プロセスがデバッグ モードで自動的に開始され、プロセスにアタッチされます。 詳細については、「関数のローカル実行」を参照してください。
デバッグに別のツールを使用している場合、または Node.js プロセスをデバッグ モードで手動で開始する場合は、local.settings.json の Values の下に "languageWorkers__node__arguments": "--inspect" を追加します。 --inspect 引数は、既定でポート 9229 でデバッグ クライアントをリッスンするように Node.js に指示します。 詳細については、「Node.js デバッグ モード」を参照してください。
Recommendations
このセクションでは、従うことをお勧めする Node.js アプリのいくつかの影響力のあるパターンについて説明します。
シングル vCPU App Service プランを選択する
App Service プランを使用する関数アプリを作成するときは、複数の vCPU を持つプランではなく、シングル vCPU プランを選択することをお勧めします。 今日では、関数を使用して、シングル vCPU VM で Node.js 関数をより効率的に実行できるようになりました。そのため、大規模な VM を使用しても、期待以上にパフォーマンスが向上することはありません。 必要な場合は、シングル vCPU VM インスタンスを追加することで手動でスケールアウトするか、自動スケーリングを有効にすることができます。 詳細については、「手動または自動によるインスタンス数のスケール変更」を参照してください。
パッケージ ファイルから実行する
サーバーレス ホスティング モデルで Azure Functions 開発を行う場合、コールド スタートとなるのが現実です。 "コールド スタート" とは、非アクティブな期間の後で初めて関数アプリが起動するとき、起動に時間がかかることを意味します。 特に、大きな依存関係ツリーを持つ Node.js アプリの場合は、コールド スタートが重要になる可能性があります。 コールド スタート プロセスをスピードアップするには、可能な場合、パッケージ ファイルとして関数を実行します。 多くのデプロイ方法では既定でこのモデルが使用されますが、大規模なコールド スタートが発生している場合は、確実にこの方法で実行していることを確認する必要があります。
1 つの静的クライアントを使用する
Azure Functions アプリケーションでサービス固有のクライアントを使用する場合は、接続の制限に達する可能性があるため、関数呼び出しごとに新しいクライアントを作成しないでください。 代わりに、グローバル スコープに 1 つの静的クライアントを作成してください。 詳細については、Azure Functions での接続の管理に関するページを参照してください。
async と await を使用する
Azure Functions を Node.js で記述する場合、async と await のキーワードを使用してコードを記述することをお勧めします。 コールバックや Promise の .then および .catch の代わりに async と await を使用してコードを記述することにより、2 つの一般的な問題を回避できます。
- Node.js プロセスをクラッシュさせる、キャッチされない例外のスロー。他の関数の実行に影響する可能性があります。
- 適切に待機しない非同期呼び出しによって発生する、
context.logからのログの欠落などの予期しない動作。
次の例では、非同期メソッド fs.readFile が、その 2 番目のパラメーターとしてエラーファースト コールバック関数を使用して呼び出されています。 このコードは、前述した両方の問題の原因となります。 正しいスコープでは明示的にキャッチされない例外によって、プロセス全体がクラッシュする可能性があります (問題 1)。 コールバックが完了したことを確認せずに戻ると、http 応答の本文が空になる場合があります (issue #2)。
// DO NOT USE THIS CODE
const { app } = require('@azure/functions');
const fs = require('fs');
app.http('httpTriggerBadAsync', {
methods: ['GET', 'POST'],
authLevel: 'anonymous',
handler: async (request, context) => {
let fileData;
fs.readFile('./helloWorld.txt', (err, data) => {
if (err) {
context.error(err);
// BUG #1: This will result in an uncaught exception that crashes the entire process
throw err;
}
fileData = data;
});
// BUG #2: fileData is not guaranteed to be set before the invocation ends
return { body: fileData };
},
});
次の例では、非同期メソッド fs.readFile が、その 2 番目のパラメーターとしてエラーファースト コールバック関数を使用して呼び出されています。 このコードは、前述した両方の問題の原因となります。 正しいスコープでは明示的にキャッチされない例外によって、プロセス全体がクラッシュする可能性があります (問題 1)。 コールバックのスコープ外で非推奨の context.done() メソッドを呼び出すことによって、ファイルが読み取られる前に関数が終了したことを通知できます (問題 2)。 この例では、context.done() の呼び出しが早すぎるため、結果として Data from file: で始まるログ エントリが欠落します。
// NOT RECOMMENDED PATTERN
const fs = require('fs');
module.exports = function (context) {
fs.readFile('./hello.txt', (err, data) => {
if (err) {
context.log.error('ERROR', err);
// BUG #1: This will result in an uncaught exception that crashes the entire process
throw err;
}
context.log(`Data from file: ${data}`);
// context.done() should be called here
});
// BUG #2: Data is not guaranteed to be read before the Azure Function's invocation ends
context.done();
}
これらの両方の問題を回避するには、async キーワードと await キーワードを使用します。 Node.js エコシステムのほとんどの API は、何らかの形で promise をサポートするように変換されています。 たとえば、v14 以降、Node.js は fs コールバック API を置き換える fs/promises API を提供します。
次の例では、関数の実行中にスローされたハンドルされない例外により、例外を発生させた個々の呼び出しのみが失敗します。 await キーワードは、readFile に続くステップが、完了後にのみ実行されることを意味しています。
// Recommended pattern
const { app } = require('@azure/functions');
const fs = require('fs/promises');
app.http('httpTriggerGoodAsync', {
methods: ['GET', 'POST'],
authLevel: 'anonymous',
handler: async (request, context) => {
try {
const fileData = await fs.readFile('./helloWorld.txt');
return { body: fileData };
} catch (err) {
context.error(err);
// This rethrown exception will only fail the individual invocation, instead of crashing the whole process
throw err;
}
},
});
async と await を使用することで、context.done() コールバックを呼び出す必要もありません。
// Recommended pattern
const fs = require('fs/promises');
module.exports = async function (context) {
let data;
try {
data = await fs.readFile('./hello.txt');
} catch (err) {
context.log.error('ERROR', err);
// This rethrown exception will be handled by the Functions Runtime and will only fail the individual invocation
throw err;
}
context.log(`Data from file: ${data}`);
}
トラブルシューティング
Node.js のトラブルシューティング ガイドを参照してください。
次のステップ
詳細については、次のリソースを参照してください。