SAP データ抽出のパフォーマンスとトラブルシューティング
この記事は、「SAP データの拡張とイノベーション: ベスト プラクティス」シリーズの一部です。
- SAP データ ソースを特定する
- 最適な SAP コネクタの選択
- SAP データ抽出のパフォーマンスとトラブルシューティング
- SAP on Azure のデータ統合セキュリティ
- SAP データ統合の汎用アーキテクチャ
データ統合のために SAP システムに接続する方法は多数あります。 以下のセクションでは、コネクタ固有の一般的な考慮事項と推奨事項について説明します。
パフォーマンス
データの抽出と処理中にベスト パフォーマンスを実現できるように、ソースとターゲットに最適な設定を構成することが重要です。
一般的な考慮事項
- 最大コンカレント接続に対して正しい SAP パラメーターが設定されていることを確認します。
- パフォーマンスと負荷分散を向上させるには、SAP グループのログオンの種類を使用することを検討してください。
- セルフホステッド統合ランタイム (SHIR) 仮想マシンのサイズが適切であり、高可用性が確保されていることを確認します。
- 大規模なデータセットを操作する場合は、使用しているコネクタでパーティション分割機能が提供されているかどうかを確認します。 SAP コネクタの多くは、データ読み込みを高速化するためのパーティション分割と並列化機能をサポートしています。 このメソッドを使用すると、複数の並列プロセスを使用して読み込むことができる小さなチャンクにデータがパッケージ化されます。 詳細については、コネクタ固有のドキュメントを参照してください。
一般的な推奨事項
SAP トランザクション RZ12 を使用して、最大コンカレント接続の値を変更します。
RFC - RZ12 の SAP パラメーター: 次のパラメーターは、1 人のユーザーまたは 1 つのアプリケーションで許可される RFC 呼び出しの数を制限できるため、この制限によってボトルネックが発生しないようにします。
![[インスタンス依存プロパティ] セクションを示すスクリーンショット。個別のログオンの最大数が強調表示されています。](media/sap-rfc.png)
![[パフォーマンス アシスタント] ウィンドウの ARFC クォータを示すスクリーンショット。](media/sap-rfc-quotas.png)
ログオン グループを使用した SAP への接続: SHIR (セルフホステッド統合ランタイム) は、特定のアプリケーション サーバーではなく SAP ログオン グループ (メッセージ サーバー経由) を使用して SAP に接続し、使用可能なすべてのアプリケーション サーバーにワークロードを分散させる必要があります。
注意
データフロー Spark クラスターと SHIR は強力です。 内部 SAP コピー アクティビティ を、多数 (16 など) トリガーして実行できます。 ただし、SAP サーバーのコンカレント接続数が小さい場合 (8 など)、パフォーマンスは SAP 側からデータを読み取ります。
SHIR 用の 4vCPU と 16 GB の VM から始めます。 次の手順は、SAP と SHIR のダイアログ ワーク プロセスの接続を示しています。
- お客様が不適切な物理マシンを使用して SHIR を設定してインストールし、内部 SAP コピーを実行しているかどうかを確認します。
- Azure Data Factory ポータルに移動し、データ フローで使用されている関連する SAP CDC のリンクされたサービスを見つけます。 参照されている SHIR 名を確認します。
- SHIR がインストールされている物理マシンの CPU、メモリ、ネットワーク、ディスクの設定を確認します。
- SHIR マシンで実行されている
diawp.exeの数を確認します。 1 つのdiawp.exeが、1 つのコピー アクティビティを実行できます。diawp.exeの数は、マシンの CPU、メモリ、ネットワーク、ディスクの設定に基づいています。
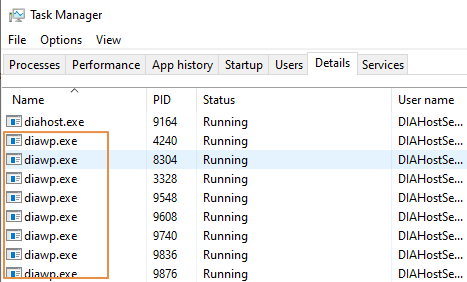
SHIR で複数のパーティションを同時に並列に実行する場合は、強力な仮想マシンを使用して SHIR を設定します。 または、SHIR の高可用性とスケーラビリティ機能を使用してスケールアウトし、複数のノードを持ちます。 詳細については、「高可用性とスケーラビリティ」を参照してください。
メジャー グループ
次のセクションでは、SAP CDC コネクタのパーティション分割プロセスについて説明します。 このプロセスは、SAP テーブル と SAP BW オープン ハブ コネクタでも同じです。

スケーリングは、パフォーマンス要件に応じて、セルフホステッド IR または Azure IR で実行できます。 SHIR の CPU 消費量を確認してメトリックを表示すると、スケーリング アプローチを決定するのに役立ちます。 SHIR は、ニーズに応じて垂直方向または水平方向にスケーリングできます。 より低い SKU で Azure IR をデプロイすることをお勧めします。 不必要に上位から開始するのではなく、ロード テストによって決定されたパフォーマンス要件を満たすようにスケールアップします。
注意
容量の 70% に到達しそうな場合は、SHIR をスケールアップまたはスケールアウトします。

パーティション分割は、初期または大規模な完全読み込みに役立ち、通常は差分読み込みには必要ありません。 パーティションを指定しない場合、既定では、SAP システムの 1 つの "プロデューサー" (通常は 1 つのバッチ プロセス) によってソース データがオペレーショナル データ キュー (ODQ) にフェッチされ、SHIR は ODQ からデータをフェッチします。 既定では、SHIR は 4 つのスレッドを使用して ODQ からデータをフェッチするため、その時点で SAP で 4 つのダイアログ プロセスが占有される可能性があります。
パーティション分割の考え方は、大きな初期データセットを、理想的にはサイズが等しく、並列で処理できる複数の小さな分離されたサブセットに分割することです。 このメソッドは、ソース テーブルから ODQ へのデータの生成にかかる時間を直線的に短縮します。 この方法では、負荷を処理するのに十分なリソースが SAP 側にあることを前提としています。
注意
- 並列で実行されるパーティションの数は、Azure IR のドライバー コアの数によって制限されます。 この制限の解決は現在進行中です。
- SAP トランザクション ODQMON の各ユニットまたはパッケージは、ステージング フォルダー内の 1 つのファイルです。
CDC を使用してパイプラインを実行するときの設計上の考慮事項
SAP のステージ期間を確認します。
シンクのランタイム パフォーマンスを確認します。
スループット向上のために、パーティション分割機能を使用してパフォーマンスを高めることを検討してください。
SAP のステージ期間が遅い場合は、SHIR のサイズを高い仕様に変更することを検討してください。
![[ストリーム情報] ダイアログの SAP のステージ期間を示すスクリーンショット。](media/sap-to-stage.png)
シンク処理時間が遅すぎないか確認します。
![[ストリーム情報] ダイアログのシンク処理時間を示すスクリーンショット。](media/sink-processing.png)
小さなクラスターを使用してマッピング データ フローを実行すると、シンクのパフォーマンスに影響する可能性があります。 パフォーマンスがステージからデータを読み取り、シンクに書き込むように、16 + 256 コアなどの大規模なクラスターを使用します。
大規模なデータ ボリュームの場合は、並列ジョブを実行するために負荷をパーティション分割することをお勧めしますが、パーティションの数は Azure IR コア (Spark クラスター コアとも呼ばれます) 以下にしてください。
[最適化] タブを使用してパーティションを定義します。 CDC コネクタでは、ソース パーティション分割を使用できます。
![[最適化] タブのソース パーティション分割を示すスクリーンショット。](media/sap-partition-azure-ir.png)
注意
- SHIR コアを持つパーティションと Azure IR ノードの数の間には直接的な相関関係があります。
- SAP CDC コネクタは、SAP システムの ODQMON の下に "オペレーショナル データ プロビジョニング用の Odata アクセス" という Odata サブスクライバーの種類として一覧表示されます。
Table コネクタを使用する場合の設計上の考慮事項
- パフォーマンスを向上させるためにパーティション分割を最適化します。
- SAP テーブルからの並列処理の次数を考慮します。
- ターゲット シンクの 1 つのファイル設計を検討します。
- 大規模なデータ ボリュームを使用する場合のスループットをベンチマークします。
Table コネクタを使用する場合の設計に関する推奨事項
パーティション: SAP Table コネクタでパーティション分割すると、カーディナリティの高いフィールドなど、適切なフィールドで where 句を使用することで、基になる 1 つの select ステートメントが複数に分割されます。 SAP テーブルに大量のデータがある場合は、パーティション分割を有効にして、データをより小さいパーティションに分割します。 パーティションの数 (パラメーター
maxPartitionsNumber) を最適化して、パーティションが SAP のメモリ ダンプを回避するのに十分なほど小さく、抽出を高速化するのに十分なほど大きくなるようにします。並列処理: コピー並列処理の次数 (パラメーター
parallelCopies) はパーティション分割と連携して機能し、SAP システムに対して並列 RFC 呼び出しを行うよう SHIR に指示します。 たとえば、このパラメーターを 4 に設定した場合、サービスでは、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。 各クエリは、SAP テーブルからデータの一部を取得します。最適な結果を得るには、パーティションの数をコピー並列処理の次数の倍数にする必要があります。
SAP テーブルからバイナリ シンクにデータをコピーすると、SHIR で使用できるメモリの量に基づいて、実際の並列数が自動的に調整されます。 各テスト サイクルの SHIR VM サイズ、コピーの並列処理の次数、パーティションの数を記録します。 SHIR VM のパフォーマンス、ソース SAP システムのパフォーマンス、および必要な並列処理と実際の並列処理の次数を確認します。 反復プロセスを使用して、SHIR VM の最適な設定と理想的なサイズを特定します。 1 つまたは複数の SAP システムから同時にデータを読み込むすべてのインジェスト パイプラインを検討します。
構成された並列処理の次数に対する SAP への呼び出しの観測数に注意してください。 SAP への RFC 呼び出しの数が並列処理の次数より少ない場合は、SHIR VM に十分なメモリと CPU リソースがあることを確認します。 必要に応じて、より大きな仮想マシンを選択します。 ソース SAP システムは、並列接続の数を制限するように構成されています。 詳細については、この記事の「一般的な推奨事項」セクションを参照してください。
ファイルの数: ファイル ベースのデータ ストアにデータをコピーし、ターゲット シンクがフォルダーとして構成されている場合、既定では複数のファイルが生成されます。 シンクで
fileNameプロパティを設定すると、データは 1 つのファイルに書き込まれます。 1 つのファイルへの書き込みに比べて書き込みスループットが高くなるため、フォルダーに複数のファイルとして書き込むことをお勧めします。パフォーマンス ベンチマーク: 大量のデータを取り込むには、パフォーマンス ベンチマークの演習を使用することをお勧めします。 このメソッドは、パーティション分割、並列処理の次数、ファイルの数などのパラメーターを変更して、特定のアーキテクチャ、ボリューム、データの種類に最適な設定を決定します。 次の形式でテストからデータを収集します。


トラブルシューティング
SAP システムからの抽出が遅い、または失敗する場合は、SM37 からの SAP ログを使用し、Data Factory の読み取り値と照合します。
1 つのバッチ ジョブのみがトリガーされた場合は、Data Factory のマッピング データ フローでパフォーマンスが向上するように SAP ソース パーティションを設定します。 詳細については、「マッピング データ フローのプロパティ」の手順 6 を参照してください。
SAP システムで複数のバッチ ジョブがトリガーされ、各バッチ ジョブの開始時刻に大きな違いがある場合は、Azure IR のサイズを変更します。 Azure IR でドライバー ノードの数を増やすと、SAP 側のバッチ ジョブの並列処理が増加します。
注意
Azure IR のドライバー ノードの最大数は 16 です。 各ドライバー ノードは、1 つのバッチ プロセスのみをトリガーできます。
SHIR のログを確認します。 ログを表示するには、SHIR VM に移動します。 [イベント ビューアー ] > [アプリケーションとサービス ログ] > [コネクタ] > [統合ランタイム] を開きます。
サポートにログを送信するには、SHIR VM に移動します。 [Integration Runtime 構成マネージャー] > [診断] > [送信ログ] を開きます。 このアクションにより、過去 7 日間のログが送信され、レポート ID が提供されます。 このレポート ID と実行の RunId が必要です。 今後参照できるようにレポート ID を文書化します。
SLT シナリオで SAP CDC コネクタを使用する場合:
前提条件が満たされていることを確認します。 SAP Landscape Transformation (SLT) ユーザーにはロールが必要です。たとえば、OLTP システムの ADFSLTUSER や、SLT レプリケーションが機能するための ECC です。 詳細については、「必要な承認とロール」を参照してください。
SLT シナリオでエラーが発生した場合は、分析のために推奨事項を参照してください。 まず、SAP ソリューション内でシナリオを分離してテストします。 たとえば、SE38 で SAP
RODPS_REPL_TESTによって提供されるテスト プログラムを実行して、Data Factory の外部でテストします。 問題が SAP 側にある場合は、レポートを使用すると同じエラーが発生します。 トランザクション コードODQMONを使用して、SAP のデータ抽出を分析できます。このテスト レポートを使用するときにレプリケーションが機能するが、Data Factory では機能しない場合は、Azure または Data Factory サポートにお問い合わせください。
次の例は、SE38 の
RODPS_REPL_TESTのレポートを示しています。![[データの抽出] ダイアログの [ODP コンテキスト] ドロップダウンを示すスクリーンショット。](media/rodps-repl-test.png)
![[データの抽出] ダイアログの設定を示すスクリーンショット。](media/rodps-repl-test-1.png)
![[データの抽出] ダイアログを示すスクリーンショット。](media/rodps-repl-test-2.png)
次の例では、トランザクション コード
ODQMONを示します。![[デルタ キュー データ ユニットの監視] ウィンドウを示すスクリーンショット。](media/odqmon.png)
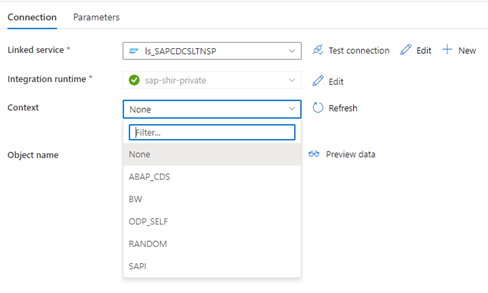
Data Factory リンク サービスが SLT システムに接続すると、[コンテキスト] フィールドを更新しても SLT 一括転送 ID は表示されません。
SAP LT レプリケーション サーバーの ODP/ODQ レプリケーション シナリオを実行するには、次のビジネス アドイン (BAdI) 実装をアクティブ化します。
BAdI:
BADI_ODQ_QUEUE_MODEL機能強化の実装:
ODQ_ENH_SLT_REPLICATIONトランザクション LTRC で、[エキスパート関数] タブに移動し、[BAdI 実装のアクティブ化/非アクティブ化] を選択して実装をアクティブ化します。
![[エキスパート関数] タブを示すスクリーンショット。](media/ltrc-1.png)
[はい] を選択します。
![[BADI 実装のカスタマイズ] ダイアログを示すスクリーンショット。](media/ltrc-2.png)
[ODQ/ODP 固有の関数] フォルダーで、[BAdI 実装がアクティブかどうかを確認する] を選択します。
![ODQ ODP 固有の関数フォルダーを示すスクリーンショット。[BADI 実装がアクティブかどうかを確認する] が選択されています。](media/ltrc-3.png)
ダイアログには、プログラム アクティビティが表示されます。
サブスクリプションをリセットします。 新しい抽出を開始するか、レプリケーション データを停止するには、ODQMON のサブスクリプションを削除します。 このアクションにより、LTRC からエントリも削除されます。 サブスクリプションをリセットした後、LTRC に効果が表示されるまでに数分かかる場合があります。 デルタキューをクリーンな状態に保つために、運用データプロビジョニング (ODP) ハウスキーピングジョブをスケジュールします (例:
ODQ_CLEANUP_CLIENT_004)CDS_VIEW (DHCDCMON トランザクション)。 S/4HANA 1909 以降、SAP は日付列の代わりにデータベースのトリガーを使用する CDS ビューからデータをレプリケートします。 概念は SLT に似ていますが、LTRC トランザクションを使用して監視する代わりに、DHCDCMON トランザクションを使用します。
SLT のトラブルシューティング
SLT Replication Server は、SAP ソースおよび/または非 SAP ソースから SAP ターゲットおよび/または非 SAP ターゲットへのリアルタイム データ レプリケーションを提供します。 SLT から Azure への抽出を監視するツールセットには 3 種類があります。
- ODQMON は、データ抽出のための総合的な監視ツールです。 ODQMON で分析を開始し、データの不整合、初期パフォーマンス分析、オープン サブスクリプションおよび抽出リクエストを追跡します。
- LTRC は、パフォーマンス分析を確認するために使用するトランザクションです。 データフローを監視して不整合を見つけることができるため、ソース システムから ODP へのデータ レプリケーションの問題がある場合に役立ちます。
- SM37 は、SLT 抽出の各ステップを詳細に監視します。
通常のハウスキーピングは、サブスクリプションを直接管理できる ODQMON を使用して実行する必要があり、同じ目的で LTRC を使用しないでください。
SLT からデータを抽出するときに、次のような問題が発生する可能性があります。
抽出が実行されません。 SAP CDC 接続が ODQMON で接続を作成したかどうかを確認し、サブスクリプションが存在するかどうかを確認します。
データの不一致。 ODQMON をチェックして個々のデータ要求を確認し、そこにデータが表示されることを確認します。 ODQMON ではデータが表示されるが、Azure Synapse または Data Factory ではデータが表示されない場合は、Azure 側で調査を行う必要があります。 ODQMON でデータが表示されない場合は、LTRC を使用して SLT フレームワークの分析を実行します。
パフォーマンスの問題。 データ抽出は 2 段階のアプローチです。 まず、SLT はソース システムからデータを読み取り、ODP に転送します。 次に、SAP CDC コネクタは ODP からデータを取得し、選択したデータ ストアに転送します。 LTRC トランザクションを使用すると、抽出プロセスの最初の部分を分析できます。 ODP から Azure へのデータ抽出を分析するには、ODQMON と Data Factory または Synapse 監視ツールを使用します。
Note
詳細については、次のリソースを参照してください。
SLT のパフォーマンス
初期ロード モード (ODPSLT) では、SLT から ODP にデータを抽出するための 3 つの手順があります。
- 移行オブジェクトを作成します。 このプロセスには数秒しかかかりません。
- ソーステーブルをより小さなチャンクに分割するプラン計算にアクセスします。 この手順は、SLT 構成時に選択した初期ロード モードとテーブルのサイズによって異なります。 リソース最適化オプションをお勧めします。
- データ読み込みにより、データがソースシステムから ODP に転送されます。
各手順はバックグラウンド ジョブによって制御されます。 SM37 および LTRC トランザクションを使用して期間を監視できます。 システムが過剰に使用されている場合、十分な空きバッチ ワーク プロセスがないため、バックグラウンド ジョブが後で開始される可能性があります。 タスクがアイドル状態になると、パフォーマンスが低下します。
アクセス プランの計算に時間がかかり、初期ロード モードが "パフォーマンス最適化" に設定されている場合は、"リソース最適化" に変更して抽出を再実行します。 データの読み込みに時間がかかる場合は、構成内の並列スレッドの数を増やします。
SLT レプリケーションにスタンドアロン アーキテクチャ (専用 SLT レプリケーション サーバー) を使用する場合、ソース システムとレプリケーション サーバー間のネットワーク スループットが抽出パフォーマンスに影響を与える可能性があります。
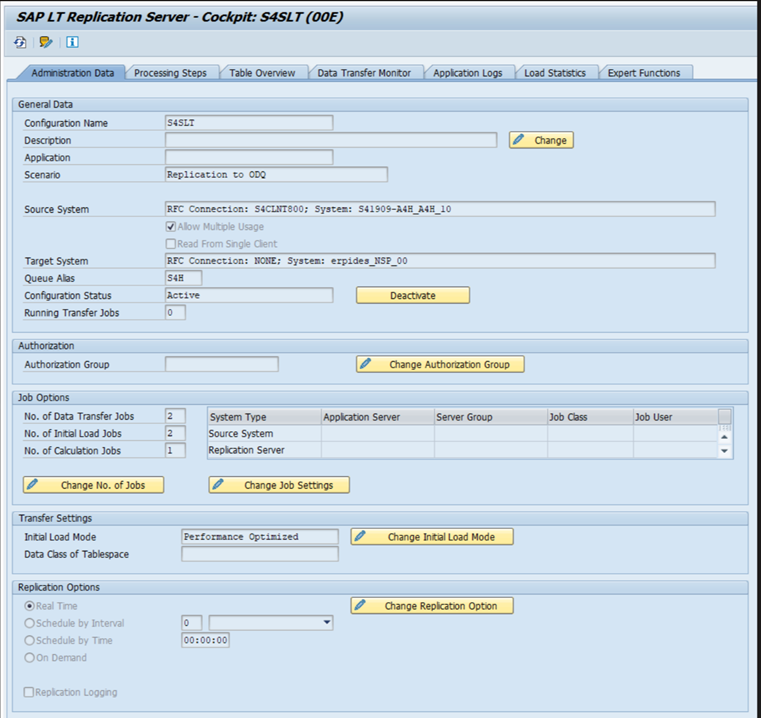
レプリケーション用:
- 初期読み込み用に予約されていない十分なデータ転送ジョブがあることを確認します。
- 読み込み統計に未処理のロギング テーブル レコードがないことを確認します。
- レプリケーション オプションがリアルタイムに設定されていることを確認します。
高度なレプリケーション設定は LTRS で使用できます。 詳細については、SLT のトラブルシューティング ガイドを参照してください。
SAP リリースが異なれば、LTRC ユーザー インターフェイスも異なります。 次のスクリーンショットは、2 つの異なるリリースの同じページを示しています。
SAP S/4HANA:
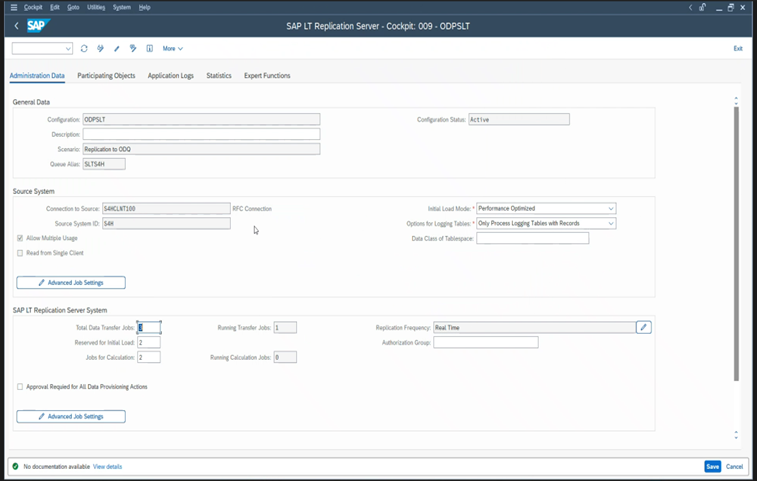
SAP ECC:


Monitor
SAP データ抽出の監視については、次のリソースを参照してください。
次の手順
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示