Azure Data Factory と Azure Synapse Analytics の Copy アクティビティ
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory と Synapse のパイプラインでは、Copy アクティビティを使用して、オンプレミスやクラウド内のデータ ストアの間でデータをコピーできます。 データをコピーした後は、他のアクティビティを使用してさらに変換および分析できます。 また、コピー アクティビティを使用して、変換や分析の結果を発行し、ビジネス インテリジェンス (BI) やアプリケーションで使用することもできます。
コピー アクティビティは、統合ランタイムで実行されます。 さまざまなデータ コピーのシナリオで、さまざまな種類の統合ランタイムを使用できます。
- 任意の IP からインターネット経由でパブリックにアクセスできる 2 つのデータ ストア間でデータをコピーする場合は、コピー アクティビティに Azure 統合ランタイムを使用できます。 この統合ランタイムは、セキュリティで保護され、信頼性が高く、スケーラブルで、グローバルに利用できます。
- オンプレミス、またはアクセス制御を使用するネットワーク (Azure 仮想ネットワークなど) に配置されているデータ ストアとの間でデータをコピーする場合は、セルフホステッド統合ランタイムを設定する必要があります。
統合ランタイムを各ソースおよびシンク データ ストアに関連付ける必要があります。 使用する統合ランタイムをコピー アクティビティで判別する方法の詳細については、「使用する IR の判別」を参照してください。
Note
同じ Copy アクティビティ内で複数のセルフホステッド統合ランタイムは使用できません。 このアクティビティのソースとシンクは、同じセルフホステッド統合ランタイムを使用して接続されている必要があります。
ソースからシンクにデータをコピーするために、コピー アクティビティを実行するサービスでは次の手順が実行されます。
- ソース データ ストアからデータを読み取る。
- シリアル化/逆シリアル化、圧縮/圧縮解除、列マッピングなどを実行する。 この操作は、入力データセット、出力データセット、およびコピー アクティビティの構成に基づいて実行されます。
- シンク/宛先データ ストアにデータを書き込む。

Note
Copy アクティビティ内でのソースまたはシンク データ ストアでセルフホステッド統合ランタイムが使用されている場合、コピー アクティビティを正常に実行するには、統合ランタイムをホストしているサーバーからソースとシンクの両方にアクセスできる必要があります。
サポートされるデータ ストアと形式
注意
"プレビュー" と記載されたコネクタは試用版です。フィードバックをお寄せください。 ソリューションでプレビュー版コネクタの依存関係を取得したい場合、Azure サポートにお問い合わせください。
サポートされるファイル形式
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
コピー アクティビティを使用すると、ファイル ベースの 2 つのデータ ストア間でファイルをそのままコピーできます。その場合、データはシリアル化または逆シリアル化なしで効率的にコピーされます。 また、特定の形式のファイルを解析または生成することもできます。たとえば、次のような操作を実行できます。
- SQL Server データベースからデータをコピーし、Parquet 形式で Azure Data Lake Storage Gen2 に書き込む。
- オンプレミスのファイル システムからテキスト (CSV) 形式でファイルをコピーし、Azure BLOB ストレージに Avro 形式で書き込む。
- オンプレミスのファイル システムから zip 形式のファイルをコピーし、その場で圧縮解除して、抽出されたファイルを Azure Data Lake Storage Gen2 に書き込む。
- Azure BLOB ストレージから Gzip 圧縮テキスト (CSV) 形式でデータをコピーし、Azure SQL Database に書き込む。
- シリアル化/逆シリアル化または圧縮/展開を必要とする他の多くのアクティビティ。
サポートされているリージョン
コピー アクティビティが有効なサービスは、「統合ランタイムの場所」に記載されているリージョンと場所でグローバルに使うことができます。 グローバルに使用できるトポロジでは効率的なデータ移動が保証されます。このデータ移動では、通常、リージョンをまたがるホップが回避されます。 特定のリージョンで Data Factory、Synapse ワークスペース、データ移動を利用できるかどうかを確認するには、リージョン別の製品に関する記事を参照してください。
構成
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
一般的に、Azure Data Factory または Synapse パイプラインで Copy アクティビティを使用するには、次のことを行う必要があります。
- ソース データ ストアとシンク データ ストアのリンクされたサービスを作成します。 サポートされるコネクタの一覧については、この記事の「サポートされるデータ ストアと形式」セクションを参照してください。 構成情報とサポートされるプロパティについては、コネクタの記事のリンクされたサービスのプロパティに関するセクションを参照してください。
- ソースとシンクのデータセットを作成します。 構成情報とサポートされるプロパティについては、ソースとシンク コネクタの記事のデータセットのプロパティに関するセクションを参照してください。
- コピー アクティビティを含むパイプラインを作成します。 次のセクションでは、例を示します。
構文
次のコピー アクティビティのテンプレートは、サポートされるすべてのプロパティの一覧を示しています。 実際のシナリオに適したものを指定してください。
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
構文の詳細
| プロパティ | 説明 | 必須 |
|---|---|---|
| type | コピー アクティビティの場合は、Copy に設定します。 |
はい |
| inputs | ソース データを指すように作成したデータセットを指定します。 コピー アクティビティは、1 つの入力のみをサポートします。 | はい |
| outputs | シンク データを指すように作成したデータセットを指定します。 コピー アクティビティは、1 つの出力のみをサポートします。 | はい |
| typeProperties | コピー アクティビティを構成するプロパティを指定します。 | はい |
| source | データを取得するためのコピー ソースの種類と対応するプロパティを指定します。 詳細については、「サポートされるデータ ストアと形式」に記載されているコネクタの記事のコピー アクティビティのプロパティに関するセクションを参照してください。 |
はい |
| sink | データを書き込むためのコピー シンクの種類と対応するプロパティを指定します。 詳細については、「サポートされるデータ ストアと形式」に記載されているコネクタの記事のコピー アクティビティのプロパティに関するセクションを参照してください。 |
はい |
| translator | ソースからシンクへの明示的な列マッピングを指定します。 このプロパティは、既定のコピー動作がニーズに合わない場合に適用されます。 詳細については、「コピー アクティビティでのスキーマ マッピング」を参照してください。 |
いいえ |
| dataIntegrationUnits | Azure 統合ランタイムがデータのコピーに使用する機能の量を表す単位を指定します。 これらの単位は、以前はクラウド データ移動単位 (DMU) と呼ばれていました。 詳細については、「データ統合単位」を参照してください。 |
いいえ |
| parallelCopies | ソースからのデータの読み取り時やシンクへのデータの書き込み時にコピー アクティビティで使用する並列処理を指定します。 詳細については、「並列コピー」を参照してください。 |
いいえ |
| preserve | データのコピー中にメタデータ/ACL を保存するかどうかを指定します。 詳細については、メタデータの保存に関する記事を参照してください。 |
いいえ |
| enableStaging stagingSettings |
ソースからシンクにデータを直接コピーするのではなく、BLOB ストレージに中間データをステージングするかどうかを指定します。 役に立つシナリオと構成の詳細については、「ステージング コピー」を参照してください。 |
いいえ |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
ソースからシンクにデータをコピーするときに互換性のない行を処理する方法を選択します。 詳細については、「フォールト トレランス」を参照してください。 |
いいえ |
監視
Azure Data Factory および Synapse パイプラインでは、Copy アクティビティの実行を、視覚的に監視することも、プログラムによって監視することも可能です。 詳細については、「コピー アクティビティを監視する」を参照してください。
増分コピー
Data Factory および Synapse パイプラインを使用すると、ソース データ ストアからシンク データ ストアに差分データを増分コピーできます。 詳細については、チュートリアルのデータの増分コピーに関する記事を参照してください。
パフォーマンスとチューニング
コピー アクティビティの監視エクスペリエンスは、コピー パフォーマンスの統計をアクティビティの実行ごとに示します。 「Copy アクティビティのパフォーマンスとスケーラビリティに関するガイド」では、Copy アクティビティによるデータ移動のパフォーマンスに影響する主な要因が説明されています。 また、テスト時に観察されるパフォーマンス値の一覧が示され、コピー アクティビティのパフォーマンスを最適化する方法も説明されます。
前回失敗した実行から再開する
コピー アクティビティでは、ファイル ベースのストア間でバイナリ形式を使用してサイズの大きいファイルをそのままコピーする場合に、ソースからシンクへのフォルダー/ファイル階層を保持することを選択した場合 (Amazon S3 から Azure Data Lake Storage Gen2 にデータを移行する場合など)、前回失敗した実行からの再開をサポートします。 これは、ファイルベースのコネクタ (Amazon S3、Amazon S3 Compatible Storage、Azure Blob、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure Files、ファイル システム、FTP、Google Cloud Storage、HDFS、Oracle Cloud Storage、SFTP) に適用されます。
コピー アクティビティの再開は、次の 2 つの方法で利用できます。
アクティビティ レベルの再試行: コピー アクティビティに再試行回数を設定できます。 パイプラインの実行中に、このコピー アクティビティの実行が失敗した場合、次の自動再試行は最後の試行の失敗ポイントから開始されます。
失敗したアクティビティから再実行する: パイプラインの実行完了後、ADF UI 監視ビューまたはプログラムによって失敗したアクティビティから再実行をトリガーすることもできます。 失敗したアクティビティがコピー アクティビティの場合、パイプラインはそのアクティビティから再実行されるだけでなく、前の実行の失敗ポイントからも再開されます。
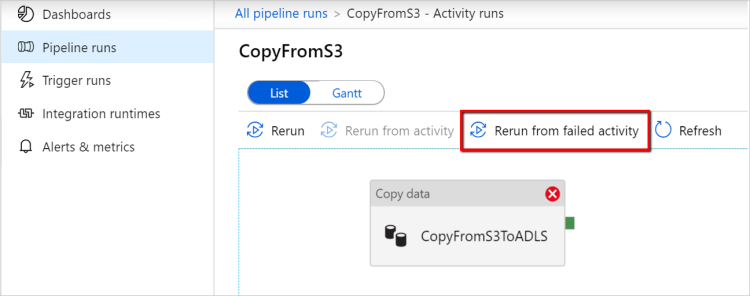
いくつかの注意点があります。
- 再開は、ファイル レベルで行われます。 ファイルのコピー時にコピー アクティビティが失敗した場合、次回の実行時に、この特定のファイルが再コピーされます。
- 再開が正常に機能するには、再実行の間でコピー アクティビティの設定を変更しないでください。
- Amazon S3、Azure BLOB、Azure Data Lake Storage Gen2、および Google Cloud Storage からデータをコピーする場合、コピー アクティビティは任意の数のコピーされたファイルから再開できます。 ソースとしてのその他のファイル ベースのコネクタの場合、現在のコピー アクティビティは、限られた数のファイルからの再開をサポートしています。通常は 1 万単位の範囲であり、ファイル パスの長さによって異なります。この数を超えるファイルが再実行中に再コピーされます。
バイナリ ファイル コピー以外の他のシナリオでは、コピー アクティビティの再実行は先頭から開始されます。
Note
セルフホステッド統合ランタイムによる最後に失敗した実行からの再開は、セルフホステッド統合ランタイム バージョン 5.43.8935.2 以降でのみサポートされるようになりました。
データと共にメタデータを保存する
ソースからシンクへデータをコピーするときに、データ レイクの移行のようなシナリオでは、コピー アクティビティを使用して、メタデータと ACL をデータと共に保存することも選択できます。 詳細については、メタデータの保存に関する記事を参照してください。
ファイル ベースのシンクにメタデータ タグを追加する
シンクが Azure Storage ベース (Azure Data Lake Storage または Azure Blob Storage) の場合は、ファイルにいくつかのメタデータを追加することを選択できます。 これらのメタデータは、ファイル プロパティの一部としてキーと値のペアで表示されます。 すべての種類のファイル ベースのシンクに対して、パイプライン パラメータ、システム変数、関数、変数を使用して、動的コンテンツを含むメタデータを追加できます。 これに加えて、バイナリ ファイル ベースのシンクでは、キーワード $$LASTMODIFIED を使用して (ソース ファイルの) Last Modified datetime を追加し、メタデータとしてカスタム値をシンク ファイルに追加することもできます。
スキーマとデータ型のマッピング
コピー アクティビティによってソース データがどのようにシンクにマップされるかについては、スキーマとデータ型のマッピングに関する記事を参照してください。
コピー中に列を追加する
ソース データ ストアからシンクにデータをコピーするだけでなく、シンクにコピーする追加データ列を追加するように構成することもできます。 次に例を示します。
- ファイルベースのソースからコピーする場合は、相対ファイル パスを、データの取得元ファイルをトレースするための追加列として保存します。
- 指定されたソース列を別の列として複製します。
- ADF 式を含む列を追加して、パイプライン名/パイプライン ID などの ADF システム変数をアタッチするか、上流アクティビティの出力から他の動的な値を保存します。
- 静的な値を持つ列を、下流の使用ニーズに応じて追加します。
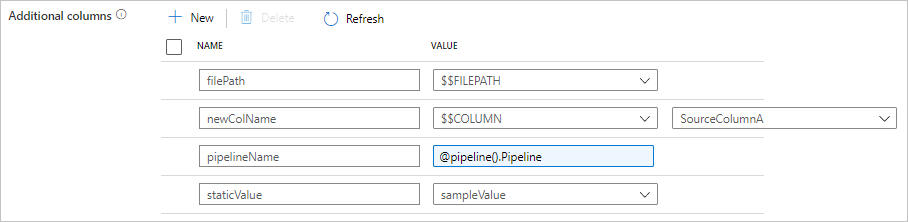
コピー アクティビティ ソース タブの構成は次のとおりです。また、定義されている列名を使用して、通常どおりのコピー アクティビティ スキーマ マッピングで追加の列をマッピングすることもできます。
ヒント
この機能は、最新のデータセット モデルで動作します。 UI にこのオプションが表示されない場合は、新しいデータセットを作成してみてください。
これをプログラムによって構成するには、コピー アクティビティ ソースに additionalColumns プロパティを追加します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| additionalColumns | シンクにコピーするデータ列を追加します。additionalColumns 配列の各オブジェクトは追加列を表します。 name は列名を定義します。また、value はその列のデータ値を示します。使用できるデータ値: - $$FILEPATH -予約済み変数。データセットで指定されたフォルダー パスへのソース ファイルの相対パスが格納されることを示します。 ファイルベースのソースに適用されます。- $$COLUMN:<source_column_name> - 予約変数パターンは、指定されたソース列を別の列として複製することを示します- 式 - 静的な値 |
いいえ |
例:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
ヒント
追加の列を構成した後、[マッピング] タブで、それらを宛先シンクにマップすることを忘れないでください。
シンク テーブルの自動作成
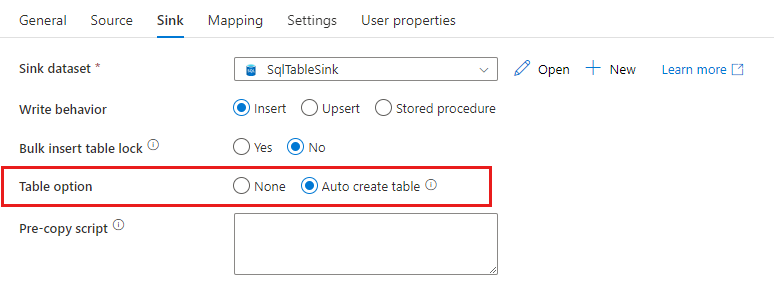
SQL データベースまたは Azure Synapse Analytics にデータをコピーするときに、コピー先のテーブルが存在しない場合、コピー アクティビティではソース データに基づいてデータが自動的に作成されます。 これは、データの読み込みと SQL データベース/Azure Synapse Analytics の評価をすぐに開始できるようにすることを目的としています。 データ インジェストが完了したら、必要に応じて、シンク テーブル スキーマを確認して調整できます。
この機能は、任意のソースから以下のシンク データ ストアにデータをコピーする際にサポートされます。 このオプションは、ADF のオーサリング UI ->コピー アクティビティ シンク ->[テーブル] オプション ->[Auto create table] (テーブルの自動作成) の順に選択するか、またはコピー アクティビティ シンク ペイロードの tableOption プロパティを使用して確認できます。
フォールト トレランス
既定では、ソース データ行がシンク データ行と互換性がない場合、コピー アクティビティでデータのコピーが停止され、エラーが返されます。 コピーを成功させるには、互換性のない行をスキップし、ログに記録し、互換性のあるデータのみをコピーするようにコピー アクティビティを構成します。 詳細については、コピー アクティビティのフォールト トレランスに関する記事を参照してください。
データ整合性の検証
ソースからコピー先ストアにデータを移動するとき、Copy アクティビティでは、データがソースからコピー先ストアに正常にコピーされただけでなく、ソースとコピー先ストアの間の整合性も確保されていることを確認するための、追加のデータ整合性検証を行うこともできます。 データの移動中に整合性のないファイルが検出されたら、コピー アクティビティを中止するか、またはフォールト トレランス設定を有効にして整合性のないファイルをスキップすることで、その他のデータをコピーし続けることができます。 スキップされたファイル名を取得するには、コピー アクティビティでセッション ログ設定を有効にします。 詳細については、「コピー アクティビティでのデータ整合性の検証」を参照してください。
セッション ログ
コピーされたファイル名をログに記録できます。これにより、コピー アクティビティのセッション ログを確認することで、データがコピー元からコピー先ストアに正常にコピーされたことだけでなく、コピー元とコピー先ストアの間で一貫していることも確認できます。 詳細については、「Copy アクティビティのセッション ログ」を参照してください。
関連するコンテンツ
次のクイック スタート、チュートリアル、およびサンプルを参照してください。