Spark プールを Azure Synapse から Fabric に移行する
Azure Synapse には Spark プールが用意され、Fabric にはスターター プールとカスタム プールが用意されています。 Azure Synapse にカスタム構成もライブラリもない単一のプールがある場合、および中程度のノード サイズが要件を満たしている場合は、スターター プールをお勧めします。 ただし、Spark プール構成の柔軟性を高める場合は、"カスタム プール" の使用をお勧めします。 次の 2 つのオプションがあります。
- オプション 1: Spark プールをワークスペースの既定のプールに移動します。
- オプション 2: Spark プールを Fabric のカスタム環境に移動します。
複数の Spark プールがあり、それらを同じ Fabric ワークスペースに移動する予定の場合は、オプション 2 を使用して、複数のカスタム環境とプールを作成することをお勧めします。
Spark プールの考慮事項については、Azure Synapse Spark と Fabric の違いに関するページを参照してください。
前提条件
まだ持っていない場合は、テナントに Fabric ワークスペースを作成します。
オプション 1: Spark プールからワークスペースの既定のプールに
Fabric ワークスペースからカスタム Spark プールを作成し、ワークスペースの既定のプールとして使用できます。 既定のプールは、同じワークスペース内のすべてのノートブックと Spark ジョブ定義で使用されます。
既存の Spark プールを Azure Synapse からワークスペースの既定のプールに移動するには、次のようにします。
- Azure Synapse ワークスペースにアクセスする: Azure にサインインします。 Azure Synapse ワークスペースに移動し、Analytics プールに進み、Apache Spark プールを選択します。
- Spark プールを見つける: Apache Spark プールから、ファブリックに移動する Spark プールを見つけて、プールのプロパティを確認します。
- プロパティを取得する: Apache Spark のバージョン、ノード サイズ ファミリ、ノード サイズ、自動スケールなどの Spark プールのプロパティを取得します。 違いを確認するには、Spark プールの考慮事項に関するページを参照してください。
- Fabric でカスタム Spark プールを作成する:
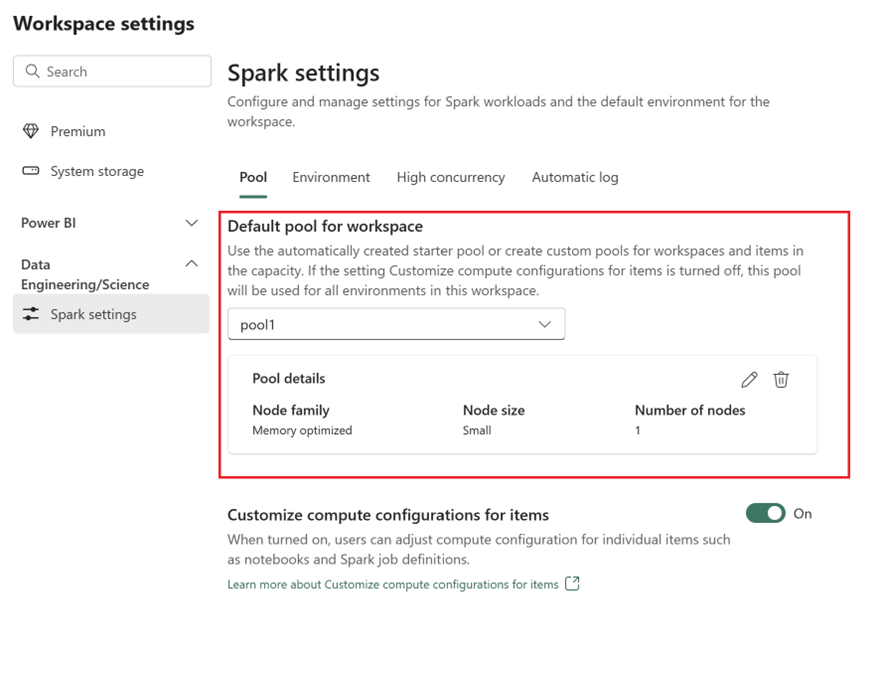
- Fabric ワークスペースに移動し、[ワークスペース設定] を選択します。
- [Data Engineering/Science] に進み、[Spark の設定] を選択します。
- [プール] タブと [ワークスペースの既定のプール] セクションで、ドロップダウン メニューを展開し、[新しいプール] の作成を選択します。
- 対応するターゲット値を使用してカスタム プールを作成します。 名前、ノード ファミリ、ノード サイズ、自動スケール、動的 Executor 割り当てオプションを入力します。
- ランタイム バージョンを選択する:
- [環境] タブに移動し、必要なランタイム バージョンを選択します。 ここで利用可能なランタイムを参照してください。
- [既定の環境の設定] オプションを無効にします。
Note
このオプションでは、プール レベルのライブラリまたは構成はサポートされません。 ただし、ノートブックや Spark ジョブ定義などの個々の項目のコンピューティング構成を調整したり、インライン ライブラリを追加したりできます。 カスタム ライブラリと構成を環境に追加する必要がある場合は、カスタム環境を検討してください。
オプション 2: Spark プールからカスタム環境へ
カスタム環境では、カスタム Spark のプロパティとライブラリを設定できます。 カスタム環境を作成するには、次のようにします。
- Azure Synapse ワークスペースにアクセスする: Azure にサインインします。 Azure Synapse ワークスペースに移動し、Analytics プールに進み、Apache Spark プールを選択します。
- Spark プールを見つける: Apache Spark プールから、ファブリックに移動する Spark プールを見つけて、プールのプロパティを確認します。
- プロパティを取得する: Apache Spark のバージョン、ノード サイズ ファミリ、ノード サイズ、自動スケールなどの Spark プールのプロパティを取得します。 違いを確認するには、Spark プールの考慮事項に関するページを参照してください。
- カスタム Spark プールを作成する:
- Fabric ワークスペースに移動し、[ワークスペース設定] を選択します。
- [Data Engineering/Science] に進み、[Spark の設定] を選択します。
- [プール] タブと [ワークスペースの既定のプール] セクションで、ドロップダウン メニューを展開し、[新しいプール] の作成を選択します。
- 対応するターゲット値を使用してカスタム プールを作成します。 名前、ノード ファミリ、ノード サイズ、自動スケール、動的 Executor 割り当てオプションを入力します。
- ない場合は、環境項目を作成します。
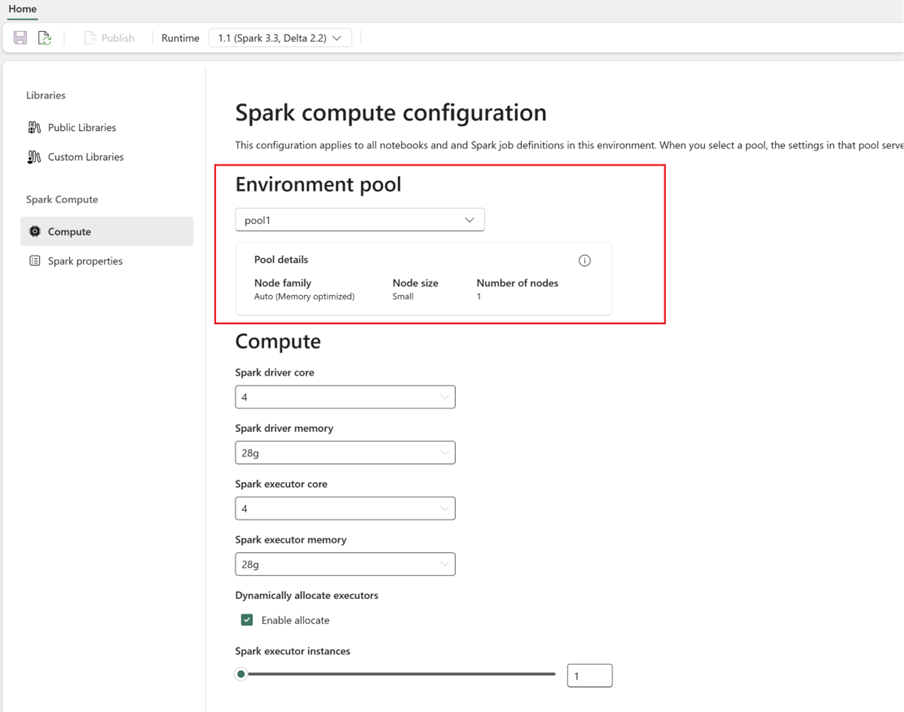
- Spark コンピューティングを構成する:
- 環境内で、[Spark コンピューティング]>[コンピューティング] に移動します。
- 新しい環境用に新たに作成されたプールを選択します。
- ドライバーと Executor のコアとメモリを構成できます。
- 環境のランタイム バージョンを選択します。 ここで利用可能なランタイムを参照してください。
- [保存] をクリックして変更を [発行] します。
環境の作成と使用の詳細を参照してください。