マルチエンジン同期
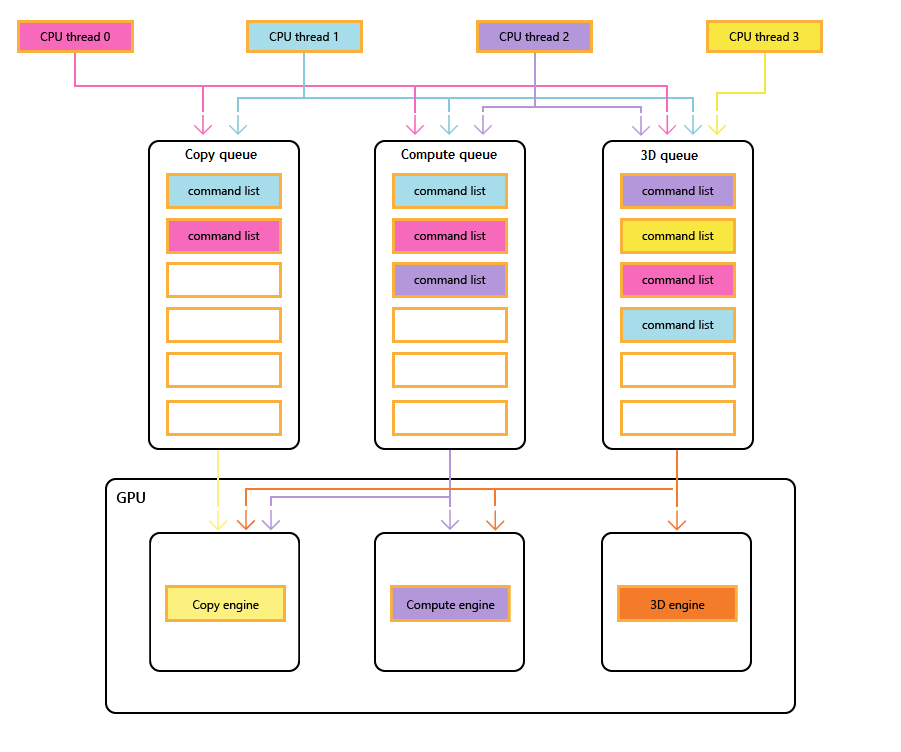
ほとんどの最新の GPU には、特殊な機能を提供する複数の独立したエンジンが含まれています。 多くに 1 つ以上の専用のコピー エンジンと、3D エンジンとは通常別になっているコンピューティング エンジンがあります。 これらの各エンジンでは、互いに並列にコマンドを実行できます。 Direct3D 12では、キューとコマンド リストを使用して、3D、コンピューティング、コピー の各エンジンにきめ細かくアクセスできます。
GPU のエンジン
次の図は、タイトルの CPU スレッドを示しています。それぞれに 1 つ以上のコピー、コンピューティング、3D キューが設定されています。 3D キューは、3 つの GPU エンジンすべてを駆動できます。コンピューティング キューは、コンピューティング エンジンとコピー エンジンを駆動できます。コピー キューは単にコピー エンジンです。
異なるスレッドによってキューが設定されるため、実行順序を簡単に保証することはできません。そのため、タイトルで必要な場合は同期メカニズムが必要です。
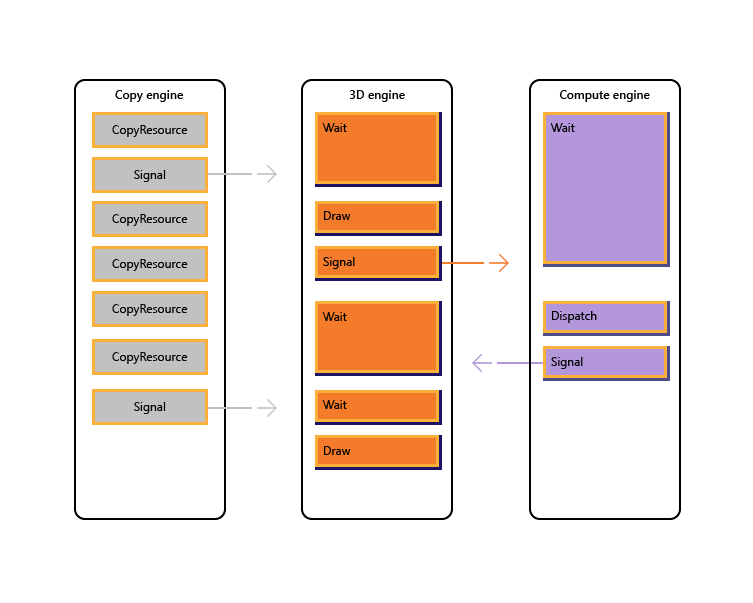
次の画像は、必要に応じたエンジン間の同期を含め、ゲームで複数の GPU エンジン全体にわたり作業のスケジュールが設定される流れを表したものです。ここでは、エンジンごとのワークロードとエンジン間の依存関係を合わせて示しています。 この例では、まず、コピー エンジンがレンダリングに必要なジオメトリをコピーします。 3D エンジンはこれらのコピーが完了するまで待ってから、ジオメトリの上にプリパスをレンダリングします。 これはその後、コンピューティング エンジンで使用されます。 コンピューティング エンジンの Dispatch の結果は、コピー エンジンにおける複数回のテクスチャのコピー操作とあわせて、3D エンジンの最後の Draw 呼び出しで使用されます。
以下の疑似コードは、ゲームでこのようなワークロードを送信する方法を示しています。
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
以下の疑似コードは、コピー エンジンと 3D エンジンの間の同期により、リング バッファーを介してヒープに似たメモリ割り当てを実現する方法を示しています。 ゲームでは、(大きなバッファーを使用した) 並列処理の最大化と、(小さなバッファーを使用した) メモリ使用量および待ち時間の削減について、適切なバランスを柔軟に選択することができます。
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
マルチエンジン シナリオ
Direct3D 12を使用すると、予期しない同期の遅延が原因で誤って非効率性に陥らないようにすることができます。 また、必要な同期をより確実に決定できる、より高いレベルで同期を導入することもできます。 マルチエンジンにより解決できる 2 つ目の問題は、負荷の高い操作をより明示的にすることです。こうした操作には、従来は複数のカーネル コンテキスト間で同期が行われるため高コストであった、3D と動画の間の遷移などがあります。
特に、次のシナリオは、Direct3D 12で対処できます。
- 非同期的な低優先度の GPU 作業。 優先度の低い GPU 作業を同時に実行できるようになり、特定の GPU スレッドで別の非同期スレッドの結果をブロックすることなく使用する不可分操作が可能になります。
- 高優先度のコンピューティング作業。 バックグラウンド コンピューティングを使用することで、3D レンダリングに割り込んで、高優先度のコンピューティング作業を少量だけ実行できます。 この作業の結果を早期に取得して、CPU で追加の処理を実行できます。
- バックグラウンドのコンピューティング作業。 コンピューティング ワークロード用に個別の低優先度キューを使用することで、アプリケーションで予備の GPU サイクルを活用して、主要なレンダリング (またはその他の) タスクに悪影響を与えることなく、バックグラウンドで計算を実行できます。 バックグラウンド タスクには、リソースの展開や、シミュレーションまたはアクセラレーション構造の更新などが含まれます。 CPU 上でのバックグラウンド タスクの同期は、フォアグラウンドの作業を停止、失速させないように、低頻度 (1 フレームあたり 1 回程度) で行う必要があります。
- データのストリーム配信とアップロード。 D3D11 の初期データとリソース更新という概念の代わりとして、個別のコピー キューが導入されました。 アプリケーションは、Direct3D 12 モデルの詳細を担当しますが、この責任には力が伴います。 アップロード データのバッファー処理に充てるシステム メモリの量を、アプリケーションで制御できます。 アプリで同期のタイミングと方法 (CPU か GPU、ブロックか非ブロック) を選択して、進行状況を追跡しながら、キューに入れる作業の量を管理することができます。
- 並列処理の強化。 アプリケーションにフォアグラウンド作業用の個別のキューがある場合は、バックグラウンドのワークロード (動画のデコードなど) により深いキューを使用できます。
Direct3D 12コマンド キューの概念は、アプリケーションによって送信されるほぼ連続した作業シーケンスの API 表現です。 こうした作業は、バリアやその他の手法を用いることでパイプライン内で実行することも、順不同で実行することもできますが、アプリケーションには単一の完了タイムラインしか認識されません。 これは、D3D11 のインティミデイト コンテキストに相当します。
同期 API
デバイスとキュー
Direct3D 12 デバイスには、さまざまな種類と優先順位のコマンド キューを作成および取得するメソッドがあります。 既定のコマンド キューは別のコンポーネントとの共用に対応しているため、ほとんどのアプリケーションではこちらのキューを使用することをお勧めします。 同時開催について特別な要件があるアプリケーションの場合は、追加のキューを作成してください。 キューは、そのキューで使用するコマンド リストのタイプで指定します。
ID3D12Device の次の作成方法を参照してください。
- CreateCommandQueue : Direct3D 12_COMMAND_QUEUE_DESC 構造体の情報に基づいてコマンド キューを作成します。
- CreateCommandList : Direct3D 12_COMMAND_LIST_TYPE型のコマンド リストを作成します。
- CreateFence : Direct3D 12_FENCE_FLAGSのフラグを示すフェンスを作成します。 フェンスは、キューを同期するためのものです。
すべてのタイプ (3D、コンピューティング、およびコピー) のキューは同じインターフェイスを共有しており、コマンドリストに基づいています。
ID3D12CommandQueue の次のメソッドを参照してください。
- ExecuteCommandLists: コマンド リストの配列を実行用に送信します。 各コマンド リストは、ID3D12CommandList で定義します。
- Signal: (GPU 上で実行されている) キューが特定のポイントに到達したときにフェンスの値を設定します。
- Wait: 指定したフェンスが指定値に到達するまで、キューを待機させます。
バンドルはいずれのキューでも使用されないため、このタイプを使用してキューを作成することはできません。
フェンス
マルチエンジン API には、フェンスを使用した作成と同期のための明示的な API が備わっています。 フェンスは、UINT64 値によって制御される同期コンストラクトです。 フェンスの値は、アプリケーションによって設定されます。 シグナル操作によってフェンス値が変更され、フェンスが要求された値以上に達するまで待機操作がブロックされます。 フェンスが特定の値に達したときに、イベントを発生させることができます。
ID3D12Fence インターフェイスのメソッドを参照してください。
- GetCompletedValue: フェンスの現在の値を返します。
- SetEventOnCompletion: フェンスが指定値に達したときにイベントを発生させます。
- Signal: 指定した値にフェンスを設定します。
フェンスにより CPU は現在のフェンス値にアクセスでき、待機操作とシグナル操作を行います。
ID3D12Fence インターフェイスの Signal メソッドは、CPU の側からフェンスを更新します。 この更新は直ちに行われます。 ID3D12CommandQueue の Signal メソッドは、GPU の側からフェンスを更新します。 この更新は、コマンド キューに対する他のすべての操作が完了した後に発生します。
マルチエンジン環境のすべてのノードが、適切な値に達したあらゆるフェンスを読み取り、対応できます。
アプリケーションで独自のフェンス値を設定することになりますが、初めは 1 フレームごとにフェンス値を 1 増やすことをお勧めします。
フェンスは巻き戻される場合があります。 つまり、フェンス値だけをインクリメントする必要はありません。 Signal 操作が 2 つの異なるコマンド キューにエンキューされている場合、または 2 つの CPU スレッドが両方ともフェンスで Signal を呼び出している場合、最後に完了した Signal と、残るフェンス値を判断する競合が発生する可能性があります。 フェンスが巻き戻された場合、新しい待機 ( SetEventOnCompletion 要求を含む) は新しい低いフェンス値と比較されるため、フェンス値が満たすのに十分な高さであったとしても、満たされない可能性があります。 未処理の待機を満たす値と満たされない小さい値の間で競合が発生した場合、後で残っている値に関係 なく待機が 満たされます。
フェンス API には強力な同期機能が備わっていますが、これを使用すると問題のデバッグが困難になる可能性があります。 各フェンスは、シグナリング間の競合を防ぐために、1 つのタイムラインの進行状況を示すためにのみ使用することをお勧めします。
コマンド リストのコピーと計算
3 タイプのコマンド リストすべてで ID3D12GraphicsCommandList インターフェイスを使用しますが、コピーおよびコンピューティングではこれらのメソッドの一部のみサポートされます。
コマンド リストのコピーと計算には、次の方法を使用できます。
コンピューティング コマンド リストでは、次のメソッドを使用することもできます。
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
コンピューティング コマンド リストで SetPipelineState を呼び出す場合、コンピューティング PSO を設定する必要があります。
コンピューティングまたはコピーのコマンド リストおよびキューと、バンドルを併用することはできません。
コンピューティングとグラフィックスのパイプライン化の例
この例では、フェンス同期を使用して、キューでグラフィックスによって使用される (によって pComputeQueue参照される) キューでコンピューティング作業のパイプラインを作成する方法を pGraphicsQueue示します。 コンピューティングとグラフィックスの作業は、複数のフレームから計算作業の結果を消費するグラフィックス キューとパイプライン化され、CPU イベントを使用して、キューに登録された全体の作業の合計を調整します。
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
このパイプライン処理をサポートするには、コンピューティング キューからグラフィックス キューに渡されるデータの異なるコピーのバッファー ComputeGraphicsLatency+1 が存在する必要があります。 コマンド リストでは、UAV と間接参照を使用して、バッファー内の適切な "バージョン" のデータを対象に読み取りと書き込みを行う必要があります。 コンピューティング キューは、フレーム N+ComputeGraphicsLatency に書き込む前に、グラフィックス キューでフレーム N のデータの読み取りが完了するまで待機しなければなりません。
CPU に対して実行されるコンピューティング キューの量は、必要なバッファリングの量に直接依存しないことに注意してください。ただし、使用可能なバッファー領域の量を超える GPU のキュー処理の価値は低くなります。
間接参照を使用しない別のメカニズムとしては、データの各 "名前変更後" バージョンに相当するコマンド リストを複数作成することが考えられます。 次の例では、上記の例を拡張してこの手法を用いることで、コンピューティング キューとグラフィックス キューをより非同期的に実行します。
非同期コンピューティングおよびグラフィックスの例
次の例では、コンピューティング キューとは非同期的にグラフィックスでレンダリングを行えます。 依然として 2 つのステージ間にはバッファー処理対象のデータが一定量存在しますが、今回のグラフィックス作業は独立的に進行し、キューへのグラフィックス作業の登録時点で CPU において最も新しいコンピューティング ステージの結果が使用されます。 これは、グラフィックス作業が別のソース (ユーザーによる入力など) によって更新される場合に役立ちます。 グラフィックス作業の ComputeGraphicsLatency 個のフレームを一度に転送できるように、コマンド リストを複数使用する必要があります。また、UpdateGraphicsCommandList 関数がコマンド リストの更新に相当しており、最新の入力データを格納して適切なバッファーからコンピューティング データを読み取っています。
ここでも、コンピューティング キューはグラフィックス キューによるパイプ バッファーの使用が終わるまで待機する必要がありますが、3 番目のフェンス (pGraphicsComputeFence) が追加されているので、グラフィックスによるコンピューティング作業の読み取りの進行状況と、一般的なグラフィックスの進行状況を比較して追跡できます。 これは、ここでは連続したグラフィックス フレームで同じコンピューティング結果が読み取られるか、コンピューティング結果をスキップされる可能性があることを考慮したものです。 若干複雑ではあるものの効率を高める設計としては、単一のグラフィックス フェンスのみを使用し、各グラフィックス フレームで使用するコンピューティング フレームへのマッピングを格納する方法も考えられます。
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
複数のキュー上にあるリソースへのアクセス
複数のキュー上にあるリソースにアクセスする場合、アプリケーションでは以下の規則を守る必要があります。
リソース アクセス ( Direct3D 12_RESOURCE_STATESを参照) は、キュー オブジェクトではなくキューの種類クラスによって決定されます。 キューには 2 種類のクラスがあります。Compute/3D キューは 1 つの型クラス、Copy は 2 番目の型クラスです。 そのため、1 つの 3D キューのNON_PIXEL_SHADER_RESOURCE状態に対する障壁を持つリソースは、ほとんどの書き込みをシリアル化する必要がある同期要件に従って、任意の 3D またはコンピューティング キューでその状態で使用できます。 2 つの型クラス (COPY_SOURCE と COPY_DEST) の間で共有されるリソースの状態は、型クラスごとに異なる状態と見なされます。 そのため、リソースがコピー キューのCOPY_DESTに移行した場合、3D またはコンピューティング キューからのコピー先としてアクセスできなくなります。その逆も同様です。
要約します。
- キュー "オブジェクト" は単一のキューである。
- キュー "type" は、Compute、3D、Copy の 3 つのいずれかです。
- キュー "type class" は、Compute/3D と Copy の 2 つのいずれかです。
初期状態として使用される COPY フラグ (COPY_DESTおよびCOPY_SOURCE) は、3D/Compute 型クラスの状態を表します。 初めからコピー キューでリソースを使用するには、COMMON 状態で開始する必要があります。 暗黙的な状態遷移を使用することで、COMMON 状態はコピー キュー上のあらゆる用途に利用できます。
リソースの状態はすべてのコンピューティング キューと 3D キューで共有されますが、異なるキュー上にあるリソースに同時に書き込みを行うことはできません。 ここで言う "同時に" とは非同期のことを指しており、一部のハードウェアでは非同期実行は許可されません。 次の規則が適用されます。
- リソースへの書き込みを行えるキューは一度に 1 つのみです。
- ライターにより変更中のバイトを読み取らない限り、複数のキューで 1 つのリソースから読み取ることができます (同時書き込み中のバイトを読み取ると、未定義の結果が生じます)。
- 書き込み完了後、別のキューで書き込み済みのバイトを読み取るか書き込みアクセスを行う前に、フェンスを使用して同期を実行する必要があります。
表示されるバック バッファーは、Direct3D 12_RESOURCE_STATE_COMMON状態である必要があります。