O que é a Análise de Imagem?
O serviço de Análise de Imagens do Visão de IA do Azure pode extrair uma ampla variedade de recursos visuais das suas imagens. Por exemplo, ele pode determinar se uma imagem apresenta conteúdo para adulto, localizar marcas ou objetos específicos ou encontrar rostos humanos.
A versão mais recente da Análise de Imagem, 4.0, que agora está em disponibilidade geral, tem novos recursos como OCR síncrono e detecção facial. Recomendamos que você use esta versão daqui para frente.
Use a Análise de Imagem por meio de um SDK da biblioteca de clientes ou chamando a API REST diretamente. Siga o guia de início rápido para obter uma introdução.
Você também pode experimentar as funcionalidades da Análise de Imagem de maneira rápida e fácil no navegador usando o Vision Studio.
Esta documentação contém os seguintes tipos de artigos:
- Os inícios rápidos são instruções passo a passo que permitem fazer chamadas para o serviço e obter resultados em um período curto.
- Os guias de instruções contêm instruções para usar o serviço de maneiras mais específicas ou personalizadas.
- Os artigos conceituais fornecem explicações detalhadas sobre a funcionalidade e os recursos do serviço.
Para obter uma abordagem mais estruturada, siga um módulo de treinamento de análise de imagem.
Versões da Análise de Imagem
Importante
Selecione a versão da API de Análise de Imagem mais adequada às suas necessidades.
| Versão | Recursos disponível | Recomendação |
|---|---|---|
| versão 4.0 | Leitura do texto, Legendas, Legendas densas, Marcas, Detecção de objetos, Classificação de imagem personalizada / detecção de objetos, Pessoas, Corte inteligente | Modelos melhores. Use a versão 4.0 se ela der suporte ao seu caso de uso. |
| versão 3.2 | Marcas, objetos, descrições, marcas comerciais, rostos, tipo de imagem, esquema de cores, pontos de Referência, celebridades, conteúdo para adulto, corte inteligente | Maior variedade de recursos. Use a versão 3.2 se o caso de uso ainda não tiver suporte na versão 4.0 |
Recomendamos que você use a API de Análise de Imagem 4.0 se ela der suporte ao seu caso de uso. Use a versão 3.2 se o caso de uso ainda não tiver suporte na versão 4.0.
Você também precisará usar a versão 3.2 se quiser criar legendas de imagem e seu recurso de Visão estiver fora das regiões do Azure com suporte. O recurso de legenda de imagem na Análise de Imagem 4.0 só tem suporte em determinadas regiões do Azure. A legenda da imagem na versão 3.2 está disponível em todas as regiões da Visão de IA do Azure. Confira a Disponibilidade de região.
Analisar a imagem
Analise imagens para fornecer insights sobre os recursos visuais e as características. Todos os recursos nesta tabela são fornecidos pela API de Análise de Imagem. Siga nosso início rápido para começar.
| Nome | Descrição | Página conceito |
|---|---|---|
| Personalização de modelo (somente versão prévia v4.0) (preterido) | Você pode criar e treinar modelos personalizados para fazer a classificação de imagem ou a detecção de objetos. Traga suas próprias imagens, rotule-as com marcas personalizadas e a Análise de Imagem treinará um modelo personalizado para seu caso de uso. | Personalização de modelo |
| Ler texto de imagens (somente v4.0) | A versão prévia da Versão 4.0 da Análise de imagem oferece o recurso de extrair texto legível de imagens. Em comparação com a API de Leitura assíncrona da Pesquisa Visual Computacional 3.2, a nova versão oferece o mecanismo OCR de leitura familiar em uma API síncrona unificada com aprimoramento de desempenho que facilita a obtenção de OCR junto com outros insights em uma só chamada à API. | OCR para imagens |
| Detectar pessoas em imagens (somente v4.0) | A versão 4.0 da Análise de Imagem oferece a capacidade de detectar pessoas que aparecem nas imagens. São retornadas as coordenadas da caixa delimitadora de cada pessoa detectada, juntamente com uma pontuação de confiança. | Detecção facial |
| Gerar legendas de imagem | Gere a legenda de uma imagem em uma linguagem compreendida por pessoas usando frases completas. Os algoritmos da Pesquisa Visual Computacional geram legendas com base nos objetos identificados na imagem. O modelo de legendagem de imagem da versão 4.0 é uma implementação mais avançada e funciona com uma gama mais ampla de imagens de entrada. Ele só está disponível em determinadas regiões geográficas. Confira a Disponibilidade de região. A versão 4.0 também permite que você use legendas densas, o que gera legendas detalhadas para objetos individuais encontrados na imagem. A API retorna as coordenadas da caixa delimitadora (em pixels) de cada objeto encontrado na imagem, além de uma legenda. Você pode usar essa funcionalidade para gerar descrições de partes separadas de uma imagem. 
|
Gerar legendas de imagem (v3.2) (v4.0) |
| Detectar objetos | A detecção de objetos é semelhante à marcação, mas a API retorna as coordenadas da caixa delimitadora para cada tag aplicada. Por exemplo, se uma imagem contiver um cachorro, um gato e uma pessoa, a operação Detect listará esses objetos junto com as coordenadas na imagem. Você pode usar essa funcionalidade para processar ainda mais as relações entre os objetos em uma imagem. Também permite que você saiba quando há várias instâncias da mesma tag em uma imagem. 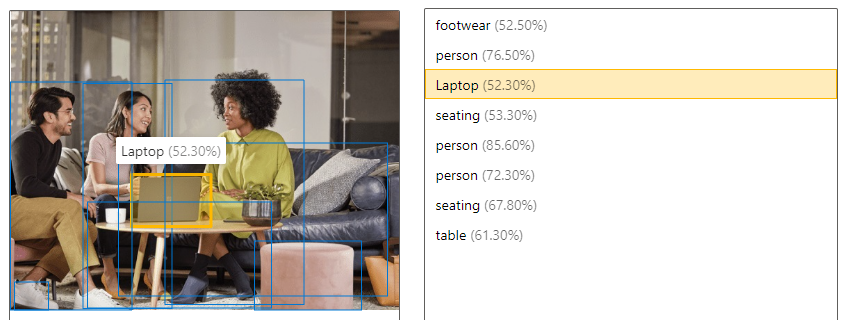
|
Detectar objetos (v3.2) (v4.0) |
| Marcar recursos visuais | Identificar e marcar recursos visuais em uma imagem, de um conjunto de milhares de objetos reconhecíveis, seres vivos, cenários e ações. Quando as marcas forem ambíguas ou não pertencerem a um conhecimento comum, a resposta da API fornecerá dicas para esclarecer o contexto da tag. A marcação não está limitada ao assunto principal, como uma pessoa em primeiro plano, mas também inclui cenário (interno ou externo), móveis, ferramentas, plantas, animais, acessórios, gadgets e outros.
|
Marcar recursos visuais (v3.2) (v4.0) |
| Obter a área de interesse/corte inteligente | Analise o conteúdo de uma imagem para retornar as coordenadas da área de interesse que corresponde a uma taxa de proporção especificada. A Pesquisa Visual Computacional retorna as coordenadas da caixa delimitadora da região, de modo que o aplicativo de chamada possa modificar a imagem original conforme desejado. O modelo de corte inteligente da versão 4.0 é uma implementação mais avançada e funciona com uma gama maior de imagens de entrada. Ele só está disponível em determinadas regiões geográficas. Confira a Disponibilidade de região. |
Gerar uma miniatura (v3.2) (Versão prévia v4.0) |
| Detectar marcas (somente v3.2) | Identifique as marcas comerciais em imagens ou vídeos de um banco de dados de milhares de logotipos globais. Você pode usar esse recurso, por exemplo, para descobrir quais marcas são mais populares em mídia social ou mais predominantes no posicionamento de produto de mídia. | Detectar marcas |
| Categorizar uma imagem (somente v3.2) | Identifique e categorize uma imagem inteira usando uma taxonomia de categoria com hierarquias hereditárias de pai/filho. As categorias podem ser usadas autonomamente ou com nossos novos modelos de marcação. Atualmente, o inglês é o único idioma com suporte para a marcação e categorização de imagens. |
Categorizar uma imagem |
| Detectar rostos (somente v3.2) | Detecte rostos em uma imagem e forneça informações sobre cada rosto detectado. A Visão de IA do Azure retorna as coordenadas, o retângulo, o gênero e a idade de cada rosto detectado. Você também pode usar a API de Detecção Facial dedicada para essas finalidades. Ela fornece uma análise mais detalhada, como identificação facial e detecção de pose. |
Detectar faces |
| Detectar tipos de imagem (somente v3.2) | Detecte características sobre uma imagem, por exemplo, se uma imagem é um desenho de linha se é, possivelmente, um clip-art. | Detectar tipos de imagem |
| Detectar conteúdo específico do domínio (somente v3.2) | Use modelos de domínio para detectar e identificar conteúdo específico de um assunto em uma imagem, como celebridades e pontos turísticos. Por exemplo, se uma imagem contiver pessoas, a Visão de IA do Azure poderá usar um modelo de domínio para celebridades para determinar se as pessoas detectadas na imagem são celebridades conhecidas. | Detectar conteúdo específico de um domínio |
| Detectar o esquema de cores (somente v3.2) | Analise o uso de cores em uma imagem. A Visão de IA do Azure pode determinar se uma imagem é preta e branca ou colorida e, para imagens coloridas, identificar as cores dominantes e de destaque. | Detectar o esquema de cores |
| Moderar o conteúdo em imagens (somente v3.2) | Você pode usar a Visão de IA do Azure para detectar conteúdo adulto em uma imagem e retornar pontuações de confiança para diferentes classificações. O limite para a sinalização de conteúdo pode ser definido em uma escala deslizante para acomodar suas preferências. | Detectar conteúdo para adultos |
Reconhecimento de Produto (somente versão prévia v4.0) (preterido)
Importante
Esse recurso agora está preterido. Em 10 de janeiro de 2025, a Análise de Imagem de IA do Azure 4.0, a Detecção personalizada de objetos e a API de visualização do Reconhecimento de Produto serão desativadas. Após essa data, as chamadas de API para esses serviços falharão.
Para manter uma operação suave de seus modelos, faça a transição para a Visão Personalizada da IA do Azure, que agora está em disponibilidade geral. A Visão Personalizada oferece funcionalidade semelhante a esses recursos de desativação.
As APIs de Reconhecimento de Produto permitem analisar fotos de prateleiras em uma loja de varejo. Você pode detectar a presença e a ausência de produtos, e obter as coordenadas da caixa delimitadora. Use junto com a personalização do modelo para treinar um modelo para identificar seus produtos específicos. Você também pode comparar os resultados do Reconhecimento de Produtos com o documento de planograma da sua loja.
Inserções multimodal (somente v4.0)
As APIs de inserções multimodais permitem a vetorização de imagens e consultas de texto. Elas convertem imagens em coordenadas em um espaço de vetor multidimensional. Depois, as consultas de texto de entrada também podem ser convertidas em vetores e as imagens podem ser correspondidas ao texto com base na proximidade semântica. Isso permite que o usuário pesquise um conjunto de imagens usando texto, sem precisar usar marcas de imagem ou outros metadados. A proximidade semântica geralmente produz melhores resultados na pesquisa.
A API 2024-02-01 inclui um modelo multilíngue que dá suporte à pesquisa de texto em 102 idiomas. O modelo original somente em inglês ainda está disponível, mas não pode ser combinado com o novo modelo no mesmo índice de pesquisa. Se você vetorizou texto e imagens usando o modelo somente inglês, esses vetores não serão compatíveis com vetores de texto e imagem multilíngues.
Essas APIs só estão disponíveis em determinadas regiões geográficas. Confira a Disponibilidade de região.
Remoção de tela de fundo (somente versão prévia v4.0)
Importante
Esse recurso agora está preterido. Em 10 de janeiro de 2025, a API de Segmento da Análise de Imagem 4.0 da IA do Azure e o serviço de remoção de plano de fundo serão desativados. Todas as solicitações para esse serviço falharão após essa data.
Para manter uma operação suave de seus modelos, instale o modelo de software livre Florence 2 e use o seu recurso Região para segmentação, o que permite uma operação de Remoção de Plano de Fundo semelhante.
A Análise de Imagem 4.0 (versão prévia) oferece a capacidade de remover a tela de fundo de uma imagem. Esse recurso pode gerar uma imagem do objeto em primeiro plano detectado com uma tela de fundo transparente ou uma imagem fosca alfa em escala de cinza mostrando a opacidade do objeto detectado em primeiro plano.
| Imagem original | Com o plano de fundo removido | Alfa fosco |
|---|---|---|

|

|

|
Limites de serviço
Requisitos de entrada
A Análise de Imagem funciona em imagens que atendem aos seguintes requisitos:
- A imagem deve ser apresentada nos formatos JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF ou MPO
- O tamanho do arquivo da imagem deve ser menor que 20 MB (megabytes)
- As dimensões da imagem devem ser maiores que 50 x 50 pixels e menores que 16.000 x 16.000 pixels
Dica
Os requisitos de entrada para inserções multimodais são diferentes e estão listados em inserções multimodais
Suporte ao idioma
Diferentes recursos da Análise de Imagem estão disponíveis para diferentes idiomas. Confira a página de Suporte de idioma.
Disponibilidade de região
Para usar as APIs da Análise de Imagem, você deve criar seu recurso da Visão de IA do Azure em uma região com suporte. Os recursos da Análise de Imagem estão disponíveis nas seguintes regiões:
| Region | Analisar a imagem (não inclui Legendas 4.0) |
Analisar a imagem (inclui Legendas 4.0) |
Reconhecimento de Produto | Inserções multimodal | Remoção de Plano de Fundo |
|---|---|---|---|---|---|
| Leste dos EUA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Oeste dos EUA | ✅ | ✅ | ✅ | ✅ | |
| Oeste dos EUA 2 | ✅ | ✅ | ✅ | ||
| França Central | ✅ | ✅ | ✅ | ✅ | |
| Norte da Europa | ✅ | ✅ | ✅ | ✅ | |
| Europa Ocidental | ✅ | ✅ | ✅ | ✅ | |
| Suécia Central | ✅ | ✅ | |||
| Norte da Suíça | ✅ | ✅ | |||
| Leste da Austrália | ✅ | ✅ | |||
| Sudeste Asiático | ✅ | ✅ | ✅ | ✅ | |
| Leste da Ásia | ✅ | ✅ | |||
| Coreia Central | ✅ | ✅ | ✅ | ✅ | |
| Leste do Japão | ✅ | ✅ |
Segurança e privacidade de dados
Como em todos os serviços de IA do Azure, os desenvolvedores que usam o serviço do Visão de IA do Azure devem estar cientes das políticas da Microsoft sobre dados de clientes. Consulte a página de serviços de IA do Azure na Central de Confiabilidade da Microsoft para saber mais.
Próximas etapas
Comece a usar a Análise de Imagem seguindo o guia de início rápido em sua linguagem de programação e versão de API preferenciais: