Funcionalidades e terminologia nos Hubs de Eventos do Azure
Os Hubs de Eventos do Azure são um serviço de processamento de eventos escalável que ingere e processa grandes volumes de eventos e dados, com baixa latência e alta confiabilidade. Para obter uma visão geral de alto nível do serviço, consulte O que são Hubs de Eventos?.
Este artigo baseia-se nas informações do artigo de visão geral e fornece detalhes técnicos e de implementação sobre os componentes e recursos dos Hubs de Eventos.
Espaço de Nomes
Um namespace de Hubs de Eventos é um contêiner de gerenciamento para hubs de eventos (ou tópicos, no jargão Kafka). Ele fornece pontos de extremidade de rede integrados ao DNS e uma variedade de recursos de controle de acesso e gerenciamento de integração de rede, como filtragem de IP, ponto de extremidade de serviço de rede virtual e Link Privado.

Partições
Os Hubs de Eventos organizam sequências de eventos enviados para um hub de eventos em uma ou mais partições. À medida que novos eventos chegam, eles são adicionados ao final desta sequência.

Uma partição pode ser pensada como um log de confirmação. As partições contêm dados de eventos que contêm as seguintes informações:
- Corpo do evento
- Saco de propriedades definido pelo usuário descrevendo o evento
- Metadados, como seu deslocamento na partição, seu número na sequência de fluxo
- Carimbo de data/hora do lado do serviço no qual foi aceito

Vantagens de usar partições
Os Hubs de Eventos foram projetados para ajudar no processamento de grandes volumes de eventos, e o particionamento ajuda com isso de duas maneiras:
- Embora os Hubs de Eventos sejam um serviço de PaaS, há uma realidade física por baixo. A manutenção de um log que preserva a ordem dos eventos requer que esses eventos sejam mantidos juntos no armazenamento subjacente e em suas réplicas, o que resulta em um limite de taxa de transferência para esse log. O particionamento permite que vários logs paralelos sejam usados para o mesmo hub de eventos e, portanto, multiplicando a capacidade de taxa de transferência de entrada-saída (IO) bruta disponível.
- Seus próprios aplicativos devem ser capazes de acompanhar o processamento do volume de eventos que estão sendo enviados para um hub de eventos. Pode ser complexo e requer uma capacidade de processamento paralela substancial e escalonada. A capacidade de um único processo para lidar com eventos é limitada, portanto, você precisa de vários processos. As partições são como sua solução alimenta esses processos e ainda garante que cada evento tenha um proprietário de processamento claro.
Número de partições
O número de partições é especificado no momento da criação de um hub de eventos. Deve estar entre uma e a contagem máxima de partições permitida para cada nível de preço. Para o limite de contagem de partições para cada camada, consulte este artigo.
Recomendamos que você escolha pelo menos quantas partições forem necessárias durante o pico de carga do seu aplicativo para esse hub de eventos específico. Para camadas diferentes das camadas premium e dedicada, não é possível alterar a contagem de partições de um hub de eventos após sua criação. Para um hub de eventos em uma camada premium ou dedicada, você pode aumentar a contagem de partições após sua criação, mas não pode diminuí-las. A distribuição de fluxos entre partições mudará quando for feita à medida que o mapeamento de chaves de partição para partições mudar, então você deve se esforçar para evitar essas alterações se a ordem relativa dos eventos for importante em seu aplicativo.
Definir o número de partições para o valor máximo permitido é tentador, mas tenha sempre em mente que seus fluxos de eventos precisam ser estruturados de forma que você possa, de fato, tirar proveito de várias partições. Se você precisar de preservação de ordem absoluta em todos os eventos ou apenas um punhado de subfluxos, talvez não consiga aproveitar muitas partições. Além disso, muitas partições tornam o lado do processamento mais complexo.
Não importa quantas partições estão em um hub de eventos quando se trata de preços. Depende do número de unidades de preço (unidades de taxa de transferência (TUs) para a camada padrão, unidades de processamento (PUs) para a camada premium e unidades de capacidade (CUs) para a camada dedicada) para o namespace ou o cluster dedicado. Por exemplo, um hub de eventos da camada padrão com 32 partições ou com uma partição incorre exatamente no mesmo custo quando o namespace é definido como uma capacidade de TU. Além disso, você pode dimensionar TUs ou PUs em seu namespace ou CUs do cluster dedicado independentemente da contagem de partições.
Como partição é um mecanismo de organização de dados que permite publicar e consumir dados de forma paralela. Recomendamos que você equilibre unidades de dimensionamento (unidades de taxa de transferência para a camada padrão, unidades de processamento para a camada premium ou unidades de capacidade para a camada dedicada) e partições para obter a escala ideal. Em geral, recomendamos uma taxa de transferência máxima de 1 MB/s por partição. Portanto, uma regra prática para calcular o número de partições seria dividir a taxa de transferência máxima esperada por 1 MB/s. Por exemplo, se o seu caso de uso requer 20 MB/s, recomendamos que você escolha pelo menos 20 partições para alcançar a taxa de transferência ideal.
No entanto, se você tiver um modelo no qual seu aplicativo tenha afinidade com uma partição específica, aumentar o número de partições não é benéfico. Para obter mais informações, consulte disponibilidade e consistência.
Mapeamento de eventos para partições
Pode utilizar uma chave de partição para mapear dados de eventos recebidos em partições específicas para a finalidade de organização de dados. A chave de partição é um valor fornecido pelo remetente transmitido para um hub de eventos. É processado através de uma função de hash estática, que cria a atribuição de partição. Se não especificar uma chave de partição ao publicar um evento, é utilizada uma atribuição round robin.
O publicador de eventos apenas tem conhecimento da respetiva chave de partição, não da partição onde os eventos são publicados. Este desacoplamento da chave e da partição faz com que o remetente não tenha necessidade de saber muito sobre o processamento a jusante. Uma identidade por dispositivo ou utilizador exclusivo faz com que uma chave de partição seja segura, mas outros atributos como a geografia também podem ser utilizados para agrupar os eventos relacionados numa única partição.
Especificar uma chave de partição permite manter os eventos relacionados juntos na mesma partição e na ordem exata em que chegaram. A chave de partição é uma cadeia de caracteres derivada do contexto do aplicativo e identifica a inter-relação dos eventos. Uma sequência de eventos identificados por uma chave de partição é um fluxo. Uma partição é um armazenamento de log multiplexado para muitos desses fluxos.
Nota
Embora você possa enviar eventos diretamente para partições, não recomendamos isso, especialmente quando a alta disponibilidade é importante para você. Ele reduz a disponibilidade de um hub de eventos para o nível de partição. Para obter mais informações, consulte Disponibilidade e consistência.
Publicadores de eventos
Qualquer entidade que envia dados para um hub de eventos é um editor de eventos (sinônimo de produtor de eventos). Os editores de eventos podem publicar eventos usando HTTPS ou AMQP 1.0 ou o protocolo Kafka. Os editores de eventos usam a autorização baseada em ID do Microsoft Entra com tokens JWT emitidos pelo OAuth2 ou um token SAS (Assinatura de Acesso Compartilhado) específico do Hub de Eventos para obter acesso à publicação.
Você pode publicar um evento via AMQP 1.0, o protocolo Kafka ou HTTPS. O serviço Hubs de Eventos fornece API REST e bibliotecas de cliente .NET, Java, Python, JavaScript e Go para publicar eventos em um hub de eventos. Para outros tempos de execução e plataformas, pode utilizar qualquer cliente AMQP 1.0, como o Apache Qpid.
A opção para utilizar AMQP ou HTTPS é específica do cenário de utilização. O AMQP requer o estabelecimento de um socket bidirecional persistente, para além da segurança de nível do transporte (TLS) ou SSL/TLS. O AMQP tem custos de rede mais altos ao inicializar a sessão, no entanto, o HTTPS requer sobrecarga TLS extra para cada solicitação. O AMQP tem maior desempenho para editores frequentes e pode alcançar latências muito menores quando usado com código de publicação assíncrona.
Você pode publicar eventos individualmente ou em lotes. Uma única publicação tem um limite de 1 MB, independentemente de ser um único evento ou um lote. A publicação de eventos maiores que esse limite é rejeitada.
A taxa de transferência dos Hubs de Eventos é dimensionada usando partições e alocações de unidades de taxa de transferência. É uma prática recomendada para os editores permanecerem inconscientes do modelo de particionamento específico escolhido para um hub de eventos e especificarem apenas uma chave de partição que é usada para atribuir consistentemente eventos relacionados à mesma partição.
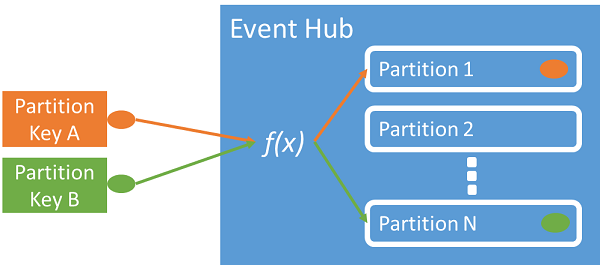
Os Hubs de Eventos garantem que todos os eventos que compartilham um valor de chave de partição sejam armazenados juntos e entregues em ordem de chegada. Se as chaves de partição forem utilizadas com as políticas do publicador, a identidade do publicador e o valor da chave de partição devem coincidir. Caso contrário, ocorrerá um erro.
Retenção de eventos
Os eventos publicados são removidos de um hub de eventos com base em uma política de retenção configurável e cronometrada. Aqui estão alguns pontos importantes:
- O valor padrão e o menor período de retenção possível é de 1 hora.
- Para Hubs de Eventos Padrão, o período máximo de retenção é de 7 dias.
- Para Hubs de Eventos Premium e Dedicado, o período máximo de retenção é de 90 dias.
- Se você alterar o período de retenção, ele se aplicará a todos os eventos, incluindo eventos que já estão no hub de eventos.
Os Hubs de Eventos retêm eventos para um tempo de retenção configurado que se aplica a todas as partições. Os eventos são removidos automaticamente quando o período de retenção é atingido. Se você especificou um período de retenção de um dia (24 horas), o evento ficará indisponível exatamente 24 horas após ter sido aceito. Não é possível excluir explicitamente eventos.
Se você precisar arquivar eventos além do período de retenção permitido, poderá armazená-los automaticamente no Armazenamento do Azure ou no Azure Data Lake ativando o recurso Captura de Hubs de Eventos. Se precisar pesquisar ou analisar esses arquivos profundos, você pode importá-los facilmente para o Azure Synapse ou outras lojas e plataformas de análise semelhantes.
A razão para o limite de retenção de dados dos Hubs de Eventos com base no tempo é evitar que grandes volumes de dados históricos de clientes fiquem presos em um armazenamento profundo que é indexado apenas por um carimbo de data/hora e só permite acesso sequencial. A filosofia arquitetônica aqui é que os dados históricos precisam de indexação mais rica e acesso mais direto do que a interface de eventos em tempo real que os Hubs de Eventos ou Kafka fornecem. Os mecanismos de streaming de eventos não são adequados para desempenhar o papel de data lakes ou arquivos de longo prazo para fornecimento de eventos.
Nota
Os Hubs de Eventos são um mecanismo de fluxo de eventos em tempo real e não foram projetados para serem usados em vez de um banco de dados e/ou como um armazenamento permanente para fluxos de eventos realizados infinitamente.
Quanto mais profunda for a história de um fluxo de eventos, mais você precisará de índices auxiliares para encontrar uma fatia histórica específica de um determinado fluxo. A inspeção de cargas úteis de eventos e a indexação não estão dentro do escopo de recursos dos Hubs de Eventos (ou Apache Kafka). Bancos de dados e mecanismos e armazenamentos de análise especializados, como o Azure Data Lake Store, o Azure Data Lake Analytics e o Azure Synapse, são, portanto, muito mais adequados para armazenar eventos históricos.
O Event Hubs Capture integra-se diretamente com o Armazenamento de Blobs do Azure e o Armazenamento do Azure Data Lake e, por meio dessa integração, também permite o fluxo de eventos diretamente para o Azure Synapse.
Política do publicador
Os Event Hubs permitem um controlo granular sobre os publicadores de eventos através de políticas do publicador. As políticas do publicador são funcionalidades de tempo de execução concebidas para facilitar um elevado número de publicadores de eventos independentes. Com as políticas do publicador, cada publicador utiliza o seu próprio identificador exclusivo quando publica eventos num hub de eventos, utilizando o mecanismo seguinte:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Não precisa de criar os nomes dos publicadores com antecedência, mas devem corresponder ao token SAS utilizado ao publicar um evento, para garantir identidades do publicador independentes. Quando você usa políticas de editor, o valor PartitionKey precisa ser definido como o nome do editor. Para que funcionem corretamente, estes valores têm de corresponder.
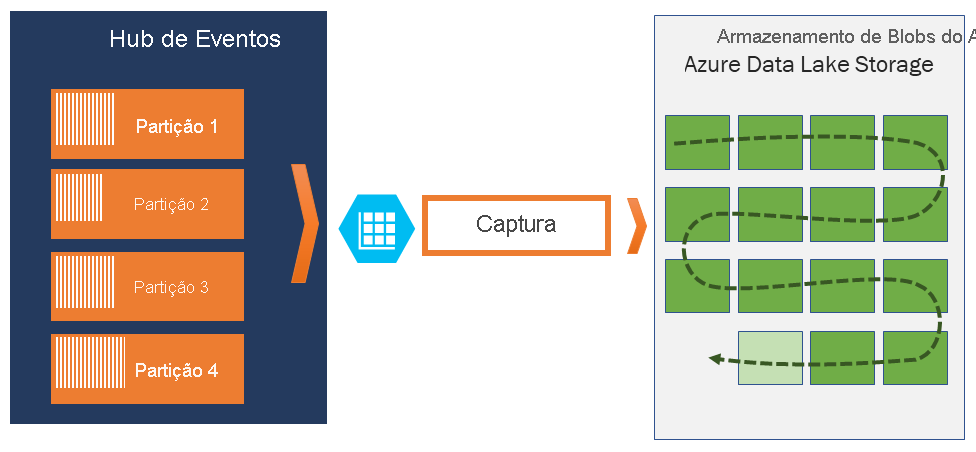
Capture
A Captura de Hubs de Eventos permite capturar automaticamente os dados de streaming em Hubs de Eventos e salvá-los em sua escolha de uma conta de armazenamento de Blob ou uma conta de Armazenamento do Azure Data Lake. Você pode habilitar a captura no portal do Azure e especificar um tamanho mínimo e uma janela de tempo para executar a captura. Usando a Captura de Hubs de Eventos, você especifica sua própria conta e contêiner do Armazenamento de Blobs do Azure ou a conta do Armazenamento do Azure Data Lake, uma das quais é usada para armazenar os dados capturados. Os dados capturados são gravados no formato Apache Avro.
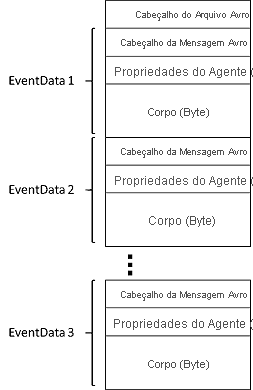
Os arquivos produzidos pelo Event Hubs Capture têm o seguinte esquema Avro:
Nota
Quando você não usa nenhum editor de código no portal do Azure, pode capturar dados de streaming em Hubs de Eventos em uma conta do Azure Data Lake Storage Gen2 no formato Parquet . Para obter mais informações, consulte Como capturar dados de Hubs de Eventos no formato Parquet e Tutorial: capturar dados de Hubs de Eventos no formato Parquet e analisar com o Azure Synapse Analytics.
Tokens SAS
Os Hubs de Eventos utilizam Assinaturas de Acesso Partilhado, que estão disponíveis no espaço de nomes e ao nível do hub de eventos. Um token SAS é gerado a partir de uma chave SAS e é um hash SHA de um URL, codificado num formato específico. Os Hubs de Eventos podem regenerar o hash usando o nome da chave (política) e do token e, assim, autenticar o remetente. Normalmente, os tokens SAS de publicadores de eventos são criados apenas com privilégios de envio num hub de eventos específico. Este mecanismo de URLs do token SAS é a base para a identificação do publicador apresentada na política do publicador. Para obter mais informações sobre como trabalhar com SAS, consulte Autenticação da Assinatura de Acesso Partilhado com o Service Bus.
Consumidores de eventos
Qualquer entidade que leia os dados de eventos de um hub de eventos é um consumidor de eventos. Os consumidores ou recetores usam AMQP ou Apache Kafka para receber eventos de um hub de eventos. Os Hubs de Eventos suportam apenas o modelo pull para que os consumidores recebam eventos dele. Mesmo quando você usa manipuladores de eventos para manipular eventos de um hub de eventos, o processador de eventos usa internamente o modelo pull para receber eventos do hub de eventos.
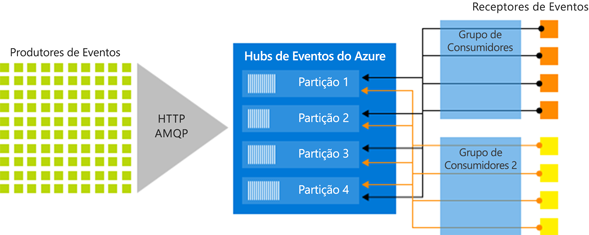
Grupos de consumidores
O mecanismo de publicação/subscrição de Hubs de Eventos é ativado através de grupos de consumidores. Um grupo de consumidores é um agrupamento lógico de consumidores que lêem dados de um hub de eventos ou tópico de Kafka. Ele permite que vários aplicativos consumidores leiam os mesmos dados de streaming em um hub de eventos de forma independente, em seu próprio ritmo com seus deslocamentos. Ele permite paralelizar o consumo de mensagens e distribuir a carga de trabalho entre vários consumidores, mantendo a ordem das mensagens dentro de cada partição.
Recomendamos que haja apenas um recetor ativo em uma partição dentro de um grupo de consumidores. No entanto, em determinados cenários, você pode usar até cinco consumidores ou recetores por partição, onde todos os recetores obtêm todos os eventos da partição. Se você tiver vários leitores na mesma partição, processará eventos duplicados. Você precisa lidar com isso em seu código, o que não é trivial. No entanto, é uma abordagem válida em alguns cenários.
Na arquitetura de processamento de transmissão, cada aplicação a jusante equaciona um grupo de consumidores. Se pretender escrever dados de eventos para armazenamento de longa duração, essa aplicação de escrita de armazenamento é um grupo de consumidores. O processamento de eventos complexos pode ser efetuado por outro grupo de consumidores, em separado. Só pode aceder a partições através de um grupo de consumidores. Há sempre um grupo de consumidores padrão em um hub de eventos e você pode criar até o número máximo de grupos de consumidores para a camada de preços correspondente.
Alguns clientes oferecidos pelos SDKs do Azure são agentes de consumidor inteligentes que gerenciam automaticamente os detalhes para garantir que cada partição tenha um único leitor e que todas as partições de um hub de eventos estejam sendo lidas. Ele permite que seu código se concentre no processamento dos eventos que estão sendo lidos do hub de eventos para que ele possa ignorar muitos dos detalhes das partições. Para obter mais informações, consulte Conectar-se a uma partição.
Os exemplos a seguir mostram a convenção URI do grupo de consumidores:
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
A imagem seguinte mostra a arquitetura do processamento de fluxos dos Hubs de Eventos:
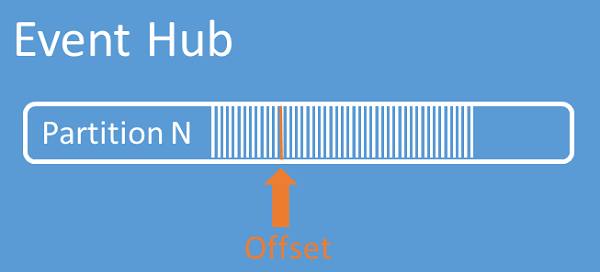
Desvios de fluxo
Um desvio é a posição de um evento numa partição. Pode considerar um desvio igual a um cursor do lado do cliente. O desvio é uma numeração de bytes do evento. Este desvio permite que um consumidor de eventos (leitor) especifique um ponto no fluxo de eventos a partir do qual pretende começar a ler eventos. Pode especificar o desvio como um carimbo de data/hora ou como um valor de desvio. Os consumidores são responsáveis por armazenarem os seus próprios valores de desvio fora do serviço dos Event Hubs. Dentro de uma partição, cada evento inclui um desvio.
Pontos de verificação
O ponto de verificação é um processo pelo qual os leitores marcam ou confirmam a respetiva posição dentro de uma sequência de eventos da partição. O ponto de verificação é da responsabilidade do consumidor e ocorre numa base por partição dentro de um grupo de consumidores. Esta responsabilidade significa que para cada grupo de consumidores, cada leitor da partição tem de manter um controlo da respetiva posição atual no fluxo de eventos e pode informar o serviço quando considera o fluxo de dados completo.
Se um leitor for desligado de uma partição, quando voltar a ser ligado, começa a leitura no ponto de verificação que foi previamente submetido pelo último leitor dessa partição nesse grupo de consumidores. Quando o leitor se conecta, ele passa o deslocamento para o hub de eventos para especificar o local no qual iniciar a leitura. Desta forma, pode utilizar o ponto de verificação para marcar os eventos como “concluídos” pelas aplicações a jusante e para fornecer resiliência se ocorrer uma ativação pós-falha entre os leitores em execução em computadores diferentes. É possível retornar a dados mais antigos especificando um deslocamento menor desse processo de ponto de verificação. Através deste mecanismo, o ponto de verificação ativa a resiliência pós-falha e a repetição do fluxo de eventos.
Importante
As compensações são fornecidas pelo serviço Hubs de Eventos. É responsabilidade do consumidor verificar o ponto de verificação à medida que os eventos são processados.
Siga estas recomendações ao usar o Armazenamento de Blobs do Azure como um armazenamento de ponto de verificação:
- Use um contêiner separado para cada grupo de consumidores. Você pode usar a mesma conta de armazenamento, mas usar um contêiner por cada grupo.
- Não use o contêiner para mais nada e não use a conta de armazenamento para mais nada.
- A conta de armazenamento deve estar na mesma região em que o aplicativo implantado está localizado. Se o aplicativo for local, tente escolher a região mais próxima possível.
Na página Conta de armazenamento no portal do Azure, na seção Serviço de Blob, verifique se as configurações a seguir estão desabilitadas.
- Espaço de nomes hierárquico
- Eliminação de forma recuperável de blobs
- Controlo de Versão
Compactação de toros
Os Hubs de Eventos do Azure dão suporte à compactação do log de eventos para reter os eventos mais recentes de uma determinada chave de evento. Com hubs de eventos compactados/tópico Kafka, você pode usar a retenção baseada em chave em vez de usar a retenção baseada no tempo mais grosseira.
Para obter mais informações sobre compactação de log, consulte Compactação de log.
Tarefas comuns do consumidor
Todos os consumidores de Hubs de Eventos se conectam por meio de uma sessão AMQP 1.0, um canal de comunicação bidirecional com reconhecimento de estado. Cada partição tem uma sessão do AMQP 1.0 que facilita o transporte de eventos segregados pela partição.
Ligar a uma partição
Ao conectar-se a partições, é prática comum usar um mecanismo de leasing para coordenar conexões de leitor com partições específicas. Dessa forma, é possível que cada partição em um grupo de consumidores tenha apenas um leitor ativo. Checkpointing, locação e gerenciamento de leitores são simplificados usando os clientes dentro dos SDKs de Hubs de Eventos, que atuam como agentes de consumo inteligentes. Eles são:
- O EventProcessorClient para .NET
- O EventProcessorClient para Java
- O EventHubConsumerClient para Python
- O EventHubConsumerClient para JavaScript/TypeScript
Ler eventos
Depois de abrir uma sessão AMQP 1.0 e uma ligação para uma partição específica, os eventos são entregues para o cliente AMQP 1.0 pelo serviço de Event Hubs. Este mecanismo de entrega permite um maior débito e uma latência inferior do que os mecanismos baseados na solicitação como HTTP GET. Como os eventos são enviados para o cliente, cada instância de dados de eventos contém metadados importantes, como o número de sequência e desvio que são utilizados para facilitar o ponto de verificação numa sequência de eventos.
Dados do evento:
- Desvio
- Número de sequência
- Corpo
- Propriedades do utilizador
- Propriedades do sistema
É da sua responsabilidade gerir a compensação.
Grupos de aplicações
Um grupo de aplicativos é uma coleção de aplicativos cliente que se conectam a um namespace de Hubs de Eventos compartilhando uma condição de identificação exclusiva, como o contexto de segurança - política de acesso compartilhado ou ID do aplicativo Microsoft Entra.
Os Hubs de Eventos do Azure permitem definir políticas de acesso a recursos, como políticas de limitação para um determinado grupo de aplicativos, e controla o streaming de eventos (publicação ou consumo) entre aplicativos cliente e Hubs de Eventos.
Para obter mais informações, consulte Governança de recursos para aplicativos cliente com grupos de aplicativos.
Suporte Apache Kafka
O suporte de protocolo para clientes Apache Kafka (versões >=1.0) fornece pontos de extremidade que permitem que aplicativos Kafka existentes usem Hubs de Eventos. A maioria dos aplicativos Kafka existentes pode ser reconfigurada para apontar para um namespace s em vez de um servidor de bootstrap de cluster Kafka.
Do ponto de vista do custo, do esforço operacional e da confiabilidade, os Hubs de Eventos do Azure são uma ótima alternativa para implantar e operar seus próprios clusters Kafka e Zookeeper e para ofertas Kafka-as-a-Service não nativas do Azure.
Além de obter a mesma funcionalidade principal do agente Apache Kafka, você também tem acesso aos recursos dos Hubs de Eventos do Azure, como processamento em lote e arquivamento automáticos por meio da Captura de Hubs de Eventos, dimensionamento e balanceamento automáticos, recuperação de desastres, suporte a zona de disponibilidade neutra em termos de custo, integração de rede flexível e segura e suporte a vários protocolos, incluindo o protocolo AMQP-over-WebSockets amigável ao firewall.
Protocolos
Os produtores ou remetentes podem usar protocolos AMQP (Advanced Messaging Queuing Protocol), Kafka ou HTTPS para enviar eventos para um hub de eventos.
Os consumidores ou recetores usam AMQP ou Kafka para receber eventos de um hub de eventos. Os Hubs de Eventos suportam apenas o modelo pull para que os consumidores recebam eventos dele. Mesmo quando você usa manipuladores de eventos para manipular eventos de um hub de eventos, o processador de eventos usa internamente o modelo pull para receber eventos do hub de eventos.
AMQP
Você pode usar o protocolo AMQP 1.0 para enviar e receber eventos dos Hubs de Eventos do Azure. O AMQP fornece comunicação confiável, eficiente e segura para enviar e receber eventos. Você pode usá-lo para streaming de alto desempenho e em tempo real e é suportado pela maioria dos SDKs de Hubs de Eventos do Azure.
HTTPS/REST API
Você só pode enviar eventos para Hubs de Eventos usando solicitações HTTP POST. Os Hubs de Eventos não suportam o recebimento de eventos por HTTPS. É adequado para clientes leves onde uma conexão TCP direta não é viável.
Apache Kafka
Os Hubs de Eventos do Azure têm um ponto de extremidade Kafka incorporado que suporta produtores e consumidores Kafka. Os aplicativos criados usando Kafka podem usar o protocolo Kafka (versão 1.0 ou posterior) para enviar e receber eventos de Hubs de Eventos sem alterações de código.
Os SDKs do Azure abstraem os protocolos de comunicação subjacentes e fornecem uma maneira simplificada de enviar e receber eventos de Hubs de Eventos usando linguagens como C#, Java, Python, JavaScript, etc.
Próximos passos
Para obter mais informações sobre os Hubs de Eventos, visite as seguintes ligações:
- Introdução aos Hubs de Eventos