Cenário de ponta a ponta do Lakehouse: visão geral e arquitetura
O Microsoft Fabric é uma solução de análise tudo-em-um para empresas que abrange tudo, desde a movimentação de dados até ciência de dados, análise em tempo real e business intelligence. Ele oferece um conjunto abrangente de serviços, incluindo data lake, engenharia de dados e integração de dados, tudo em um só lugar. Para obter mais informações, consulte O que é o Microsoft Fabric?
Este tutorial orienta você por um cenário de ponta a ponta, desde a aquisição de dados até o consumo de dados. Ele ajuda você a construir uma compreensão básica do Fabric, incluindo as diferentes experiências e como elas se integram, bem como as experiências de desenvolvedor profissional e cidadão que vêm com o trabalho nesta plataforma. Este tutorial não se destina a ser uma arquitetura de referência, uma lista exaustiva de recursos e funcionalidades ou uma recomendação de práticas recomendadas específicas.
Cenário de ponta a ponta Lakehouse
Tradicionalmente, as organizações têm construído armazéns de dados modernos para suas necessidades de análise de dados transacionais e estruturados. E data lakehouses para necessidades de análise de dados de big data (semi/não estruturados). Esses dois sistemas funcionavam em paralelo, criando silos, duplicação de dados e aumento do custo total de propriedade.
O Fabric com sua unificação de armazenamento de dados e padronização no formato Delta Lake permite eliminar silos, remover duplicação de dados e reduzir drasticamente o custo total de propriedade.
Com a flexibilidade oferecida pelo Fabric, você pode implementar arquiteturas lakehouse ou data warehouse ou combiná-las para obter o melhor de ambas com uma implementação simples. Neste tutorial, você vai pegar um exemplo de uma organização de varejo e construir sua casa do lago do início ao fim. Ele usa a arquitetura medalhão onde a camada de bronze tem os dados brutos, a camada de prata tem os dados validados e desduplicados e a camada de ouro tem dados altamente refinados. Você pode adotar a mesma abordagem para implementar uma casa de lago para qualquer organização de qualquer setor.
Este tutorial explica como um desenvolvedor da empresa fictícia Wide World Importers do domínio de varejo conclui as seguintes etapas:
Entre na sua conta do Power BI e inscreva-se para a avaliação gratuita do Microsoft Fabric. Se você não tiver uma licença do Power BI, inscreva-se para uma licença gratuita do Fabric e depois poderá iniciar a avaliação do Fabric.
Crie e implemente um lakehouse de ponta a ponta para sua organização:
- Crie um espaço de trabalho de malha.
- Crie uma casa no lago.
- Ingerir dados, transformá-los e carregá-los na casa do lago. Você também pode explorar o OneLake, uma cópia de seus dados no modo lakehouse e no modo de ponto de extremidade de análise SQL.
- Conecte-se à sua lakehouse usando o ponto de extremidade de análise SQL e Crie um relatório do Power BI usando o DirectLake para analisar dados de vendas em diferentes dimensões.
- Opcionalmente, você pode orquestrar e agendar o fluxo de ingestão e transformação de dados com um pipeline.
Limpe os recursos excluindo o espaço de trabalho e outros itens.
Arquitetura
A imagem a seguir mostra a arquitetura de ponta a ponta da casa do lago. Os componentes envolvidos são descritos na lista a seguir.
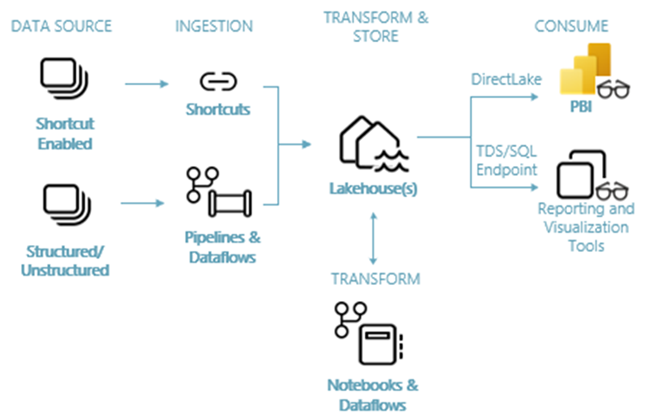
Fontes de dados: o Fabric torna rápida e fácil a conexão com os Serviços de Dados do Azure, bem como outras plataformas baseadas em nuvem e fontes de dados locais, para ingestão simplificada de dados.
Ingestão: Você pode criar rapidamente insights para sua organização usando mais de 200 conectores nativos. Esses conectores são integrados ao pipeline de malha e utilizam a transformação de dados de arrastar e soltar fácil de usar com fluxo de dados. Além disso, com o recurso Atalho no Fabric, você pode se conectar a dados existentes, sem precisar copiá-los ou movê-los.
Transformar e armazenar: o tecido padroniza no formato Delta Lake. O que significa que todos os mecanismos de malha podem acessar e manipular o mesmo conjunto de dados armazenado no OneLake sem duplicar dados. Esse sistema de armazenamento oferece a flexibilidade de construir lakehouses usando uma arquitetura medallion ou uma malha de dados, dependendo de sua necessidade organizacional. Você pode escolher entre uma experiência low-code ou no-code para transformação de dados, utilizando pipelines/fluxos de dados ou notebook/Spark para uma experiência code-first.
Consumo: o Power BI pode consumir dados do Lakehouse para geração de relatórios e visualização. Cada Lakehouse tem um ponto de extremidade TDS integrado chamado ponto de extremidade de análise SQL para facilitar a conectividade e a consulta de dados nas tabelas Lakehouse a partir de outras ferramentas de relatório. O ponto de extremidade de análise SQL fornece aos usuários a funcionalidade de conexão SQL.
Conjunto de dados de exemplo
Este tutorial usa o banco de dados de exemplo Wide World Importers (WWI) que, você importará para a casa do lago no próximo tutorial. Para o cenário de ponta a ponta do lakehouse, geramos dados suficientes para explorar os recursos de escala e desempenho da plataforma Fabric.
A Wide World Importers (WWI) é uma importadora e distribuidora de produtos de novidade por atacado que opera a partir da área da Baía de São Francisco. Como grossista, os clientes da Primeira Guerra Mundial incluem maioritariamente empresas que revendem a particulares. A Primeira Guerra Mundial vende para clientes de varejo nos Estados Unidos, incluindo lojas especializadas, supermercados, lojas de informática, lojas de atrações turísticas e alguns indivíduos. A WWI também vende a outros grossistas através de uma rede de agentes que promovem os produtos em nome da WWI. Para saber mais sobre o perfil e a operação da empresa, consulte Bancos de dados de exemplo da Wide World Importers para Microsoft SQL.
Em geral, os dados são trazidos de sistemas transacionais ou aplicativos de linha de negócios para uma casa de lago. No entanto, por uma questão de simplicidade neste tutorial, usamos o modelo dimensional fornecido pela WWI como nossa fonte de dados inicial. Nós o usamos como fonte para ingerir os dados em uma casa de lago e transformá-los através de diferentes estágios (Bronze, Prata e Ouro) de uma arquitetura medalhão.
Modelo de dados
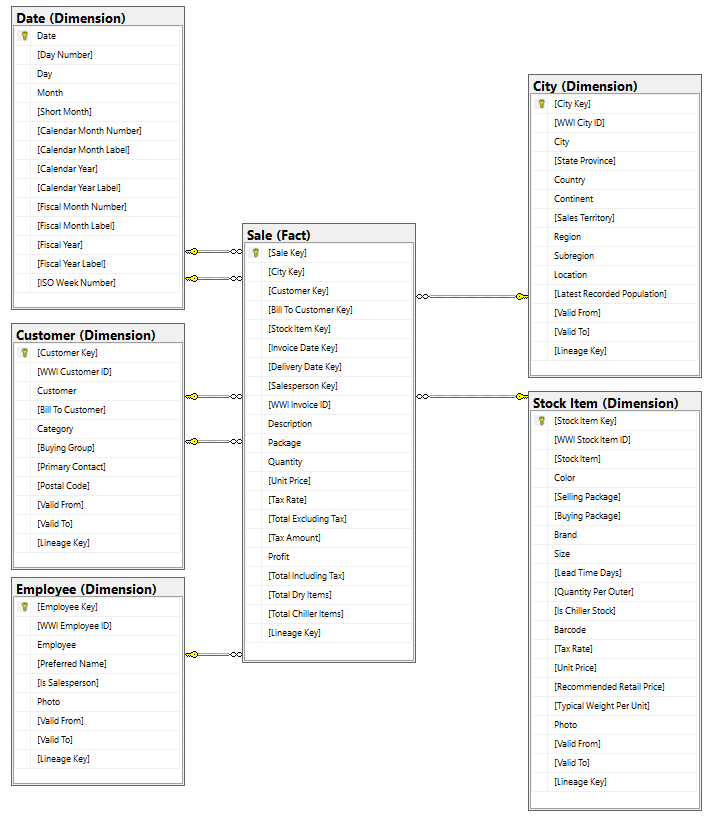
Embora o modelo dimensional da Primeira Guerra Mundial contenha inúmeras tabelas de fatos, para este tutorial, usamos a tabela de fatos Sale e suas dimensões correlacionadas. O exemplo a seguir ilustra o modelo de dados WWI:
Dados e fluxo de transformação
Conforme descrito anteriormente, estamos usando os dados de exemplo da Wide World Importers (WWI) para construir esta casa de lago de ponta a ponta. Nessa implementação, os dados de exemplo são armazenados em uma conta de armazenamento de Dados do Azure no formato de arquivo Parquet para todas as tabelas. No entanto, em cenários do mundo real, os dados normalmente teriam origem em várias fontes e em diversos formatos.
A imagem a seguir mostra a origem, o destino e a transformação de dados:
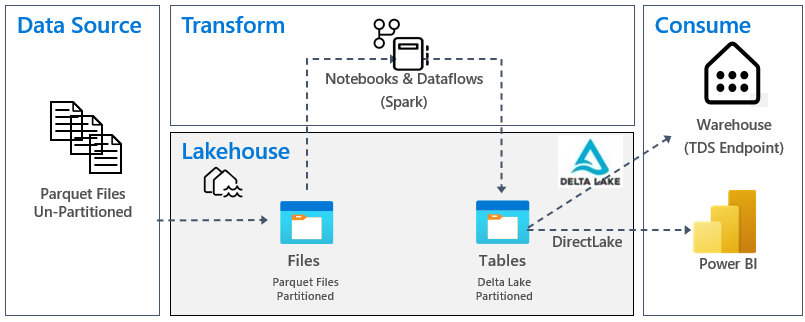
Fonte de dados: Os dados de origem estão no formato de arquivo Parquet e em uma estrutura não particionada. Ele é armazenado em uma pasta para cada tabela. Neste tutorial, configuramos um pipeline para ingerir os dados históricos completos ou únicos para a casa do lago.
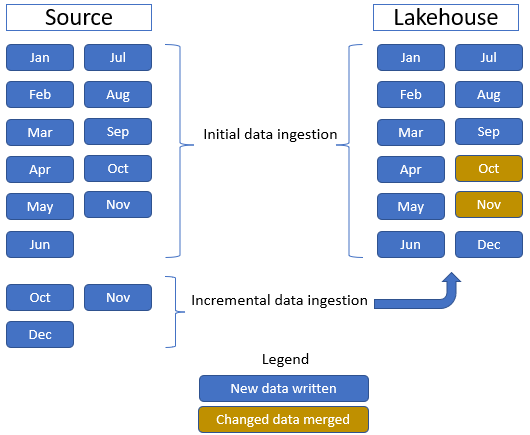
Neste tutorial, usamos a tabela de fatos de venda , que tem uma pasta pai com dados históricos por 11 meses (com uma subpasta para cada mês) e outra pasta contendo dados incrementais por três meses (uma subpasta para cada mês). Durante a ingestão inicial de dados, 11 meses de dados são ingeridos na tabela lakehouse. No entanto, quando os dados incrementais chegam, eles incluem dados atualizados para outubro e novembro, e novos dados para dados de outubro e novembro são mesclados com os dados existentes e os novos dados de dezembro são gravados na tabela lakehouse, conforme mostrado na imagem a seguir:
Lakehouse: Neste tutorial, você cria uma lakehouse, ingere dados na seção de arquivos da lakehouse e, em seguida, cria tabelas delta lake na seção Tables da lakehouse.
Transformar: para preparação e transformação de dados, você vê duas abordagens diferentes. Demonstramos o uso de Notebooks/Spark para usuários que preferem uma experiência code-first e usamos pipelines/dataflow para usuários que preferem uma experiência low-code ou no-code.
Consumir: para demonstrar o consumo de dados, você vê como pode usar o recurso DirectLake do Power BI para criar relatórios, painéis e consultar dados diretamente da casa do lago. Além disso, demonstramos como você pode disponibilizar seus dados para ferramentas de relatórios de terceiros usando o ponto de extremidade de análise TDS/SQL. Esse ponto de extremidade permite que você se conecte ao depósito e execute consultas SQL para análise.