IA com fluxos de dados
Este artigo mostra como você pode usar inteligência artificial (IA) com fluxos de dados. Este artigo descreve:
- Serviços Cognitivos
- Machine learning automatizado
- Integração do Azure Machine Learning
Importante
A criação de modelos do Power BI Automated Machine Learning (AutoML) para fluxos de dados v1 foi desativada e não está mais disponível. Os clientes são incentivados a migrar sua solução para o recurso AutoML no Microsoft Fabric. Para obter mais informações, consulte o anúncio de aposentadoria.
Serviços Cognitivos no Power BI
Com os Serviços Cognitivos no Power BI, você pode aplicar algoritmos diferentes dos Serviços Cognitivos do Azure para enriquecer seus dados na preparação de dados de autoatendimento para fluxos de dados.
Os serviços suportados atualmente são Análise de sentimento, Extração de frases-chave, Deteção de idioma e Marcação de imagem. As transformações são executadas no serviço do Power BI e não exigem uma assinatura dos Serviços Cognitivos do Azure. Esse recurso requer o Power BI Premium.
Ativar recursos de IA
Os serviços cognitivos são suportados para nós de capacidade Premium EM2, A2, P1 ou F64 e outros nós com mais recursos. Os serviços cognitivos também estão disponíveis com uma licença Premium Por Usuário (PPU). Uma carga de trabalho de IA separada na capacidade é usada para executar serviços cognitivos. Antes de usar os serviços cognitivos no Power BI, a carga de trabalho de IA precisa ser habilitada nas configurações de Capacidade do Portal de administração. Você pode ativar a carga de trabalho de IA na seção cargas de trabalho.
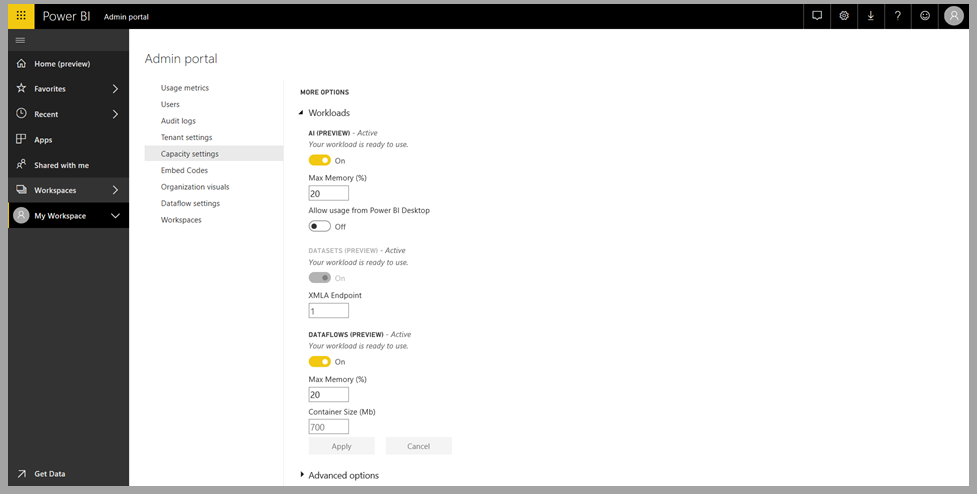
Introdução aos Serviços Cognitivos no Power BI
As transformações dos Serviços Cognitivos fazem parte do Self-Service Data Prep para fluxos de dados. Para enriquecer seus dados com os Serviços Cognitivos, comece editando um fluxo de dados.
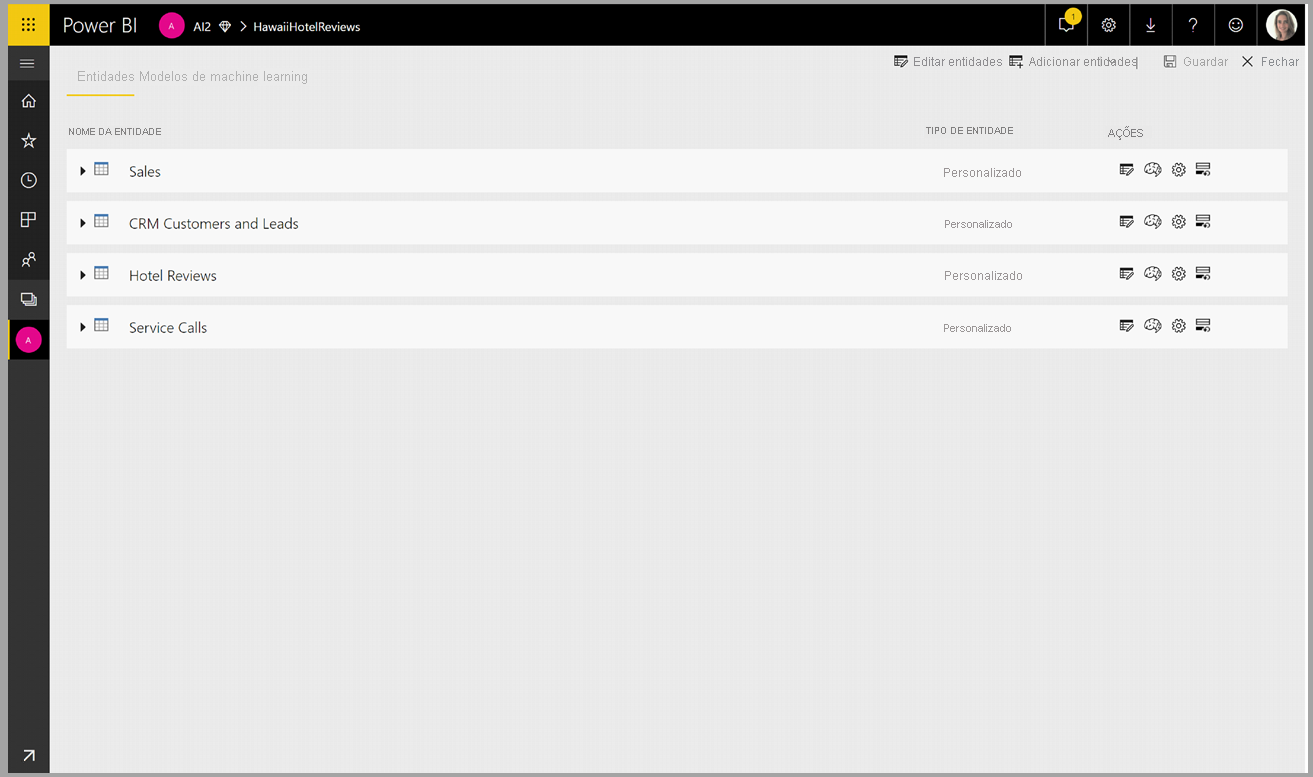
Selecione o botão AI Insights no friso superior do Editor do Power Query.
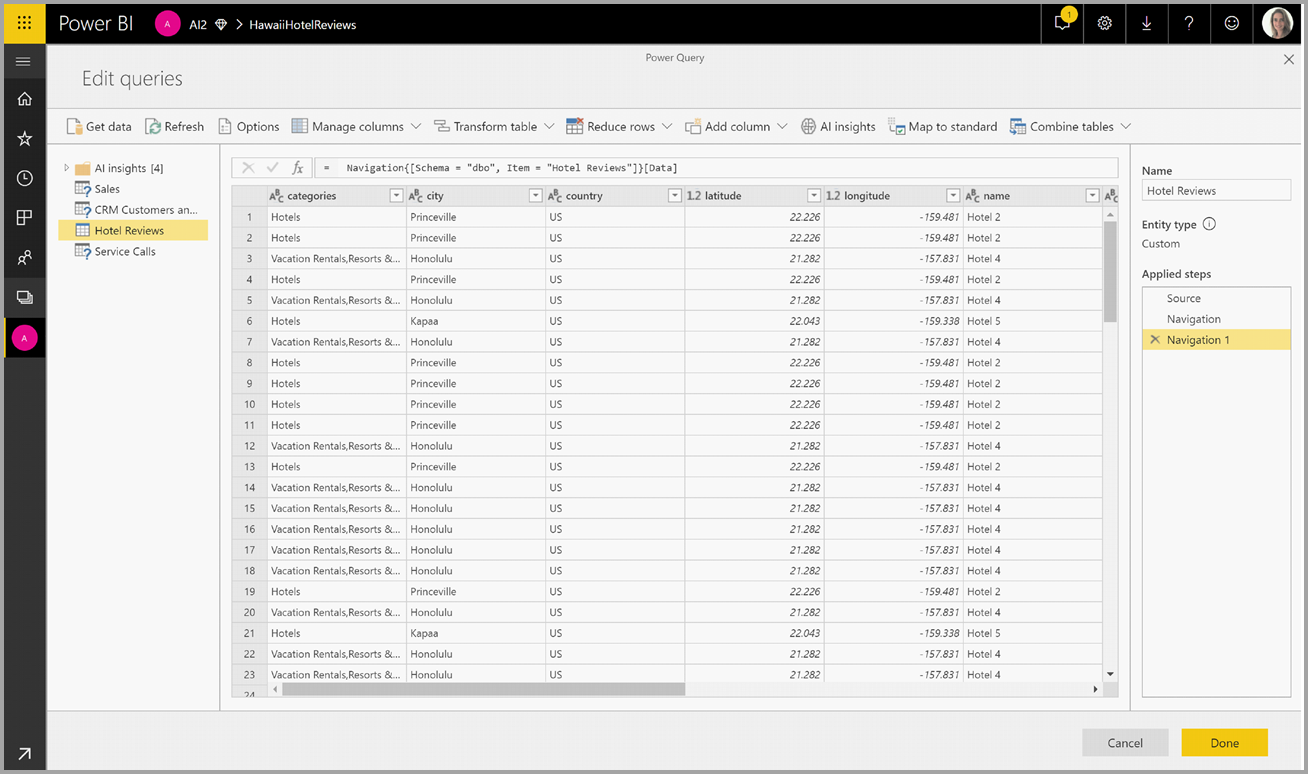
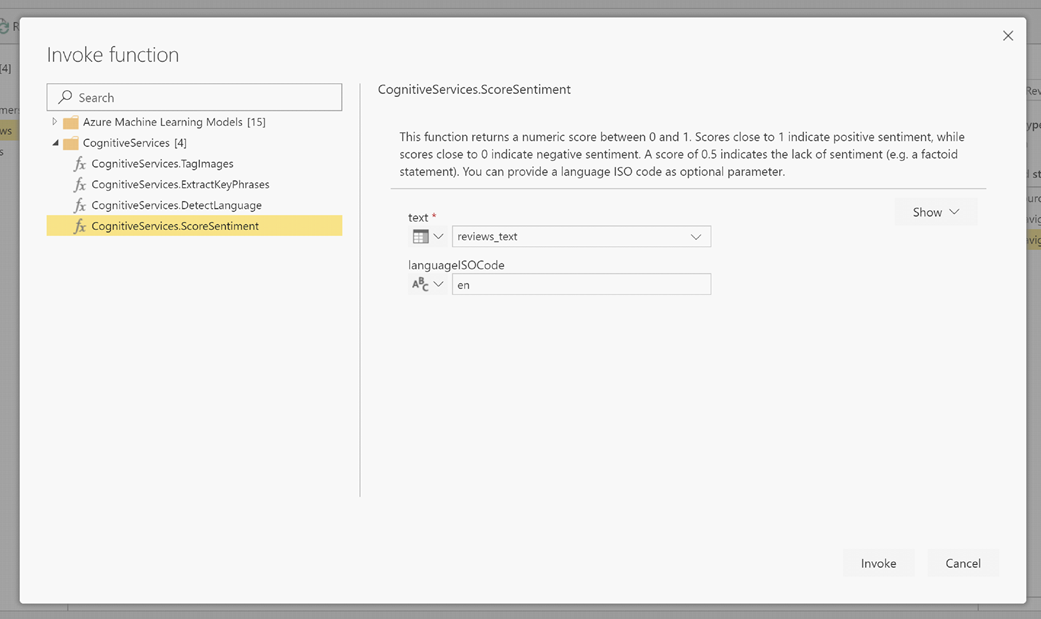
Na janela pop-up, selecione a função que deseja usar e os dados que deseja transformar. Este exemplo pontua o sentimento de uma coluna que contém texto de revisão.
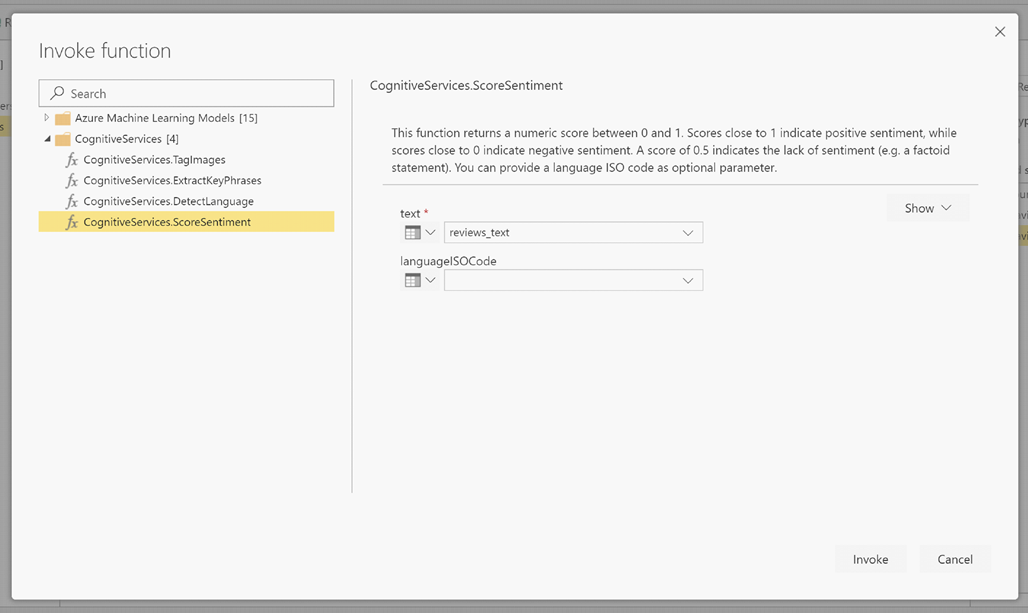
LanguageISOCode é uma entrada opcional para especificar o idioma do texto. Esta coluna espera um código ISO. Você pode usar uma coluna como entrada para LanguageISOCode, ou você pode usar uma coluna estática. Neste exemplo, o idioma é especificado como inglês (en) para toda a coluna. Se você deixar essa coluna em branco, o Power BI detetará automaticamente o idioma antes de aplicar a função. Em seguida, selecione Invocar.
Depois de invocar a função, o resultado é adicionado como uma nova coluna à tabela. A transformação também é adicionada como uma etapa aplicada na consulta.
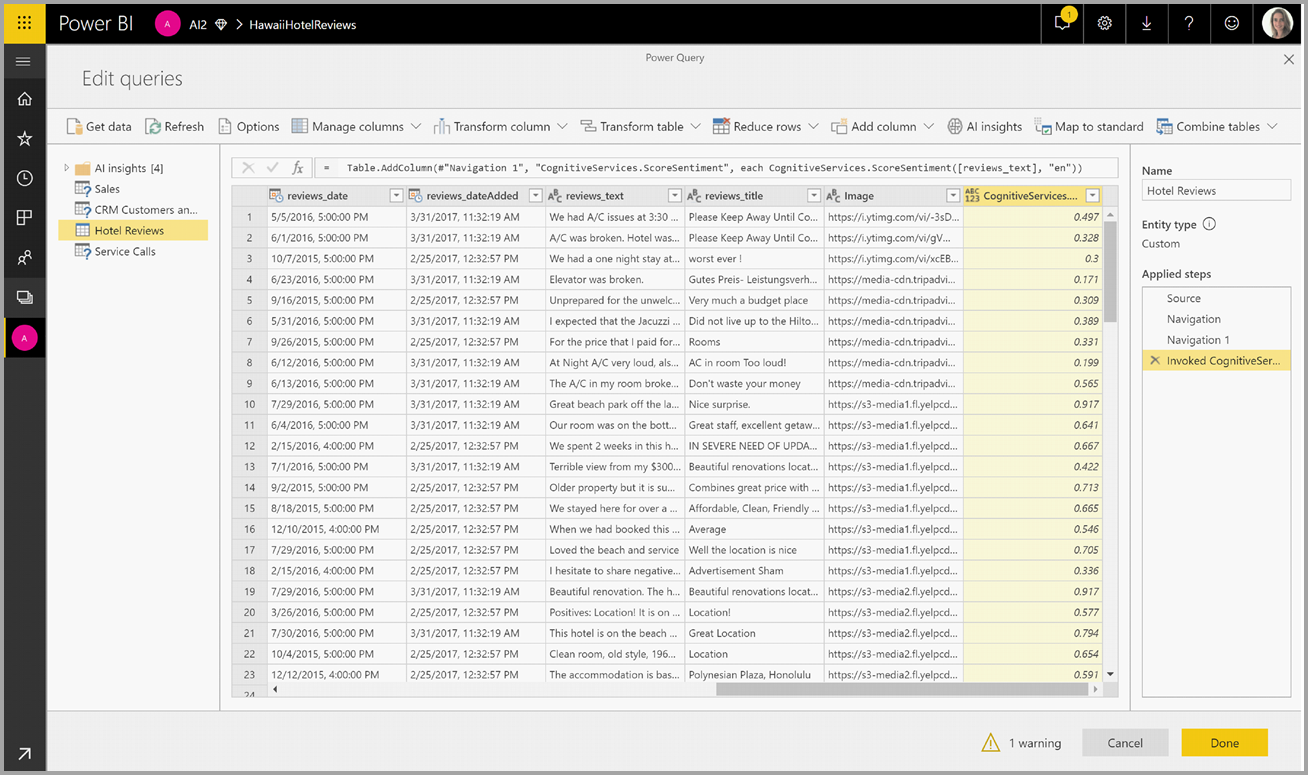
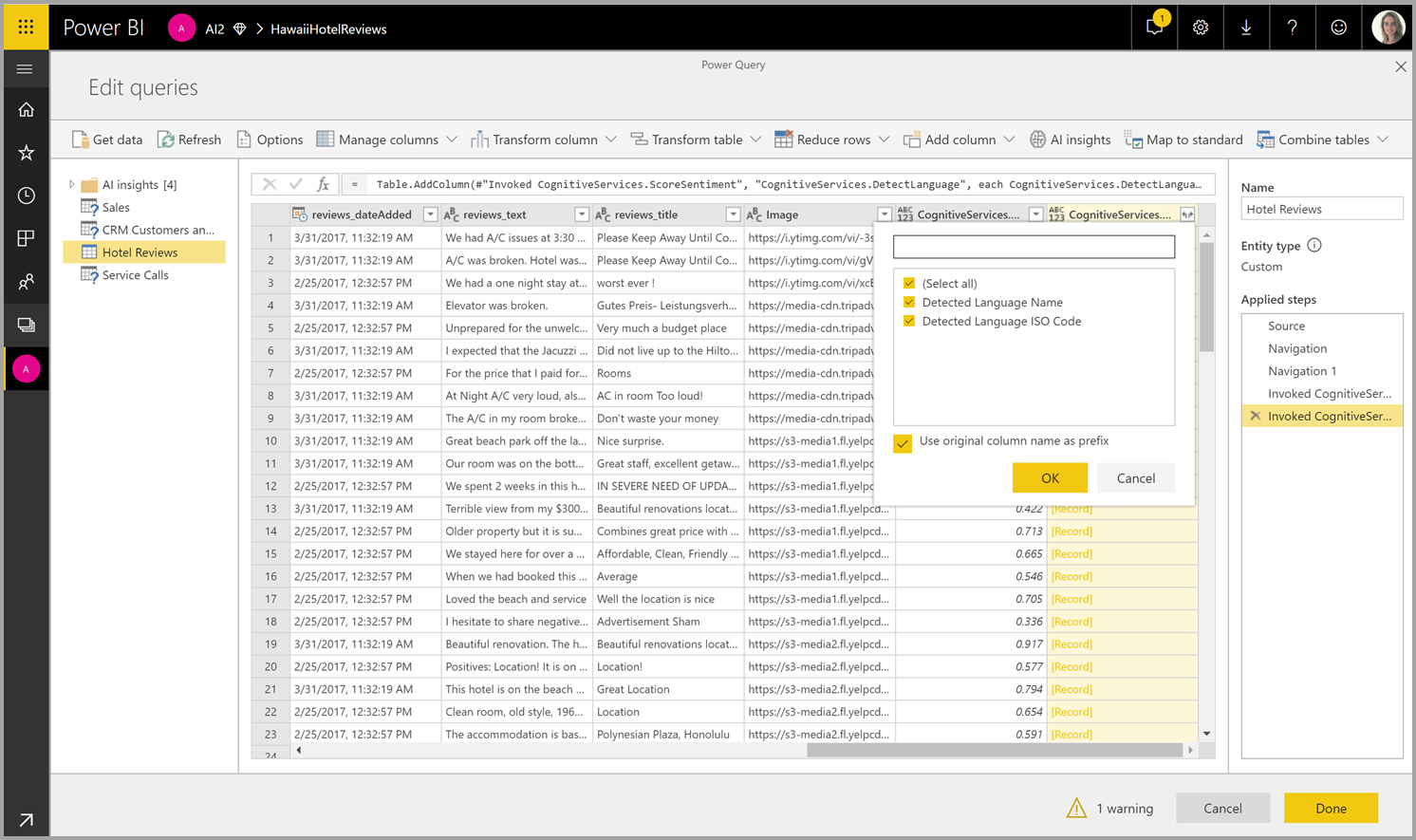
Se a função retornar várias colunas de saída, invocar a função adicionará uma nova coluna com uma linha das várias colunas de saída.
Use a opção expandir para adicionar um ou ambos os valores como colunas aos seus dados.
Funções disponíveis
Esta seção descreve as funções disponíveis nos Serviços Cognitivos no Power BI.
Detetar idioma
A função de deteção de idioma avalia a entrada de texto e, para cada coluna, retorna o nome do idioma e o identificador ISO. Esta função é útil para colunas de dados que coletam texto arbitrário, onde o idioma é desconhecido. A função espera dados em formato de texto como entrada.
A Análise de Texto reconhece até 120 idiomas. Para obter mais informações, consulte O que é deteção de idioma no Serviço Cognitivo do Azure para Idioma.
Extrair frases-chave
A função Extração de Frase-Chave avalia texto não estruturado e, para cada coluna de texto, retorna uma lista de frases-chave. A função requer uma coluna de texto como entrada e aceita uma entrada opcional para LanguageISOCode. Para obter mais informações, consulte Introdução.
A extração de frases-chave funciona melhor quando você dá a ela pedaços maiores de texto para trabalhar, ao contrário da análise de sentimento. A análise de sentimento tem melhor desempenho em blocos menores de texto. Para obter os melhores resultados com as duas operações, pondere reestruturar as entradas em conformidade.
Sentimento de pontuação
A função Sentimento de pontuação avalia a entrada de texto e retorna uma pontuação de sentimento para cada documento, variando de 0 (negativo) a 1 (positivo). Esta função é útil para detetar sentimentos positivos e negativos nas redes sociais, avaliações de clientes e fóruns de discussão.
A Análise de Texto utiliza um algoritmo de classificação de aprendizagem automática para gerar uma pontuação de sentimento entre 0 e 1. Pontuações mais próximas de 1 indicam sentimento positivo. Pontuações mais próximas de 0 indicam sentimento negativo. O modelo é pré-treinado com um extenso corpo de texto com associações de sentimento. Atualmente, não é possível fornecer seus próprios dados de treinamento. O modelo utiliza uma combinação de técnicas durante a análise de texto, incluindo o processamento de texto, a análise de parte do discurso, posicionamento de palavras e associações de palavras. Para obter mais informações sobre o algoritmo, consulte Machine Learning e Text Analytics.
A análise de sentimento é realizada em toda a coluna de entrada, em oposição à extração de sentimento para uma tabela específica no texto. Na prática, há uma tendência de melhorar a precisão da pontuação quando os documentos contêm uma ou duas frases, em vez de um grande bloco de texto. Durante uma fase de avaliação da objetividade, o modelo determina se uma coluna de entrada como um todo é objetiva ou contém sentimento. Uma coluna de entrada que é principalmente objetiva não progride para a frase de deteção de sentimento, resultando em uma pontuação de 0,50, sem processamento adicional. Para colunas de entrada que continuam no pipeline, a próxima fase gera uma pontuação maior ou menor que 0,50, dependendo do grau de sentimento detetado na coluna de entrada.
Atualmente, a Análise de Sentimentos suporta os seguintes idiomas: inglês, alemão, espanhol e francês. Os outros idiomas estão em pré-visualização. Para obter mais informações, consulte O que é deteção de idioma no Serviço Cognitivo do Azure para Idioma.
Marcar imagens
A função Imagens de tags retorna tags baseadas em mais de 2.000 objetos reconhecíveis, seres vivos, cenários e ações. Quando as tags são ambíguas ou não são de conhecimento comum, a saída fornece 'dicas' para esclarecer o significado da tag no contexto de uma configuração conhecida. As tags não são organizadas como uma taxonomia e não existem hierarquias de herança. Uma coleção de etiquetas de conteúdos é a base da "descrição" de uma imagem apresentada como um idioma legível por humanos e formatada em frases completas.
Depois de carregar uma imagem ou especificar um URL de imagem, os algoritmos da Visão Computacional produzem tags com base nos objetos, seres vivos e ações identificadas na imagem. A identificação não se limita ao motivo principal, por exemplo, uma pessoa em primeiro plano, mas também inclui o cenário (interior ou exterior), mobiliário, ferramentas, plantas, animais, acessórios, gadgets, etc.
Esta função requer um URL de imagem ou coluna abase-64 como entrada. No momento, a marcação de imagem suporta inglês, espanhol, japonês, português e chinês simplificado. Para obter mais informações, consulte ComputerVision Interface.
Aprendizagem automática de máquina no Power BI
O aprendizado de máquina automatizado (AutoML) para fluxos de dados permite que os analistas de negócios treinem, validem e invoquem modelos de aprendizado de máquina (ML) diretamente no Power BI. Ele inclui uma experiência simples para criar um novo modelo de ML onde os analistas podem usar seus fluxos de dados para especificar os dados de entrada para treinar o modelo. O serviço extrai automaticamente os recursos mais relevantes, seleciona um algoritmo apropriado e ajusta e valida o modelo de ML. Depois que um modelo é treinado, o Power BI gera automaticamente um relatório de desempenho que inclui os resultados da validação. O modelo pode então ser invocado em quaisquer dados novos ou atualizados dentro do fluxo de dados.
O aprendizado de máquina automatizado está disponível apenas para fluxos de dados hospedados no Power BI Premium e nas capacidades incorporadas.
Trabalhar com AutoML
O aprendizado de máquina e a IA estão vendo um aumento sem precedentes na popularidade das indústrias e campos de pesquisa científica. As empresas também estão procurando maneiras de integrar essas novas tecnologias em suas operações.
Os fluxos de dados oferecem preparação de dados de autoatendimento para big data. O AutoML é integrado em fluxos de dados e permite que você use seu esforço de preparação de dados para criar modelos de aprendizado de máquina, diretamente no Power BI.
O AutoML no Power BI permite que os analistas de dados usem fluxos de dados para criar modelos de aprendizado de máquina com uma experiência simplificada usando apenas as habilidades do Power BI. O Power BI automatiza a maior parte da ciência de dados por trás da criação dos modelos de ML. Possui guarda-corpos para garantir que o modelo produzido tenha boa qualidade e forneça visibilidade sobre o processo usado para criar seu modelo de ML.
O AutoML suporta a criação de modelos binários de previsão, classificação e regressão para fluxos de dados. Esses recursos são tipos de técnicas supervisionadas de aprendizado de máquina, o que significa que eles aprendem com os resultados conhecidos de observações passadas para prever os resultados de outras observações. O modelo semântico de entrada para treinar um modelo AutoML é um conjunto de linhas que são rotuladas com os resultados conhecidos.
O AutoML no Power BI integra ML automatizado do Azure Machine Learning para criar seus modelos de ML. No entanto, você não precisa de uma assinatura do Azure para usar o AutoML no Power BI. O serviço Power BI gerencia inteiramente o processo de treinamento e hospedagem dos modelos de ML.
Depois que um modelo de ML é treinado, o AutoML gera automaticamente um relatório do Power BI que explica o desempenho provável do seu modelo de ML. O AutoML enfatiza a explicabilidade destacando os principais influenciadores entre suas entradas que influenciam as previsões retornadas pelo seu modelo. O relatório também inclui métricas-chave para o modelo.
Outras páginas do relatório gerado mostram o resumo estatístico do modelo e os detalhes do treinamento. O resumo estatístico é de interesse para os usuários que gostariam de ver as medidas padrão de ciência de dados do desempenho do modelo. Os detalhes do treinamento resumem todas as iterações que foram executadas para criar seu modelo, com os parâmetros de modelagem associados. Ele também descreve como cada entrada foi usada para criar o modelo de ML.
Em seguida, você pode aplicar seu modelo de ML aos seus dados para pontuação. Quando o fluxo de dados é atualizado, seus dados são atualizados com previsões do seu modelo de ML. O Power BI também inclui uma explicação individualizada para cada previsão específica que o modelo de ML produz.
Criar um modelo de aprendizagem automática
Esta seção descreve como criar um modelo AutoML.
Preparação de dados para criar um modelo de ML
Para criar um modelo de aprendizado de máquina no Power BI, você deve primeiro criar um fluxo de dados para os dados que contêm as informações de resultado histórico, que são usadas para treinar o modelo de ML. Você também deve adicionar colunas calculadas para quaisquer métricas de negócios que possam ser fortes preditores para o resultado que você está tentando prever. Para obter detalhes sobre como configurar seu fluxo de dados, consulte Configurar e consumir um fluxo de dados.
O AutoML tem requisitos de dados específicos para treinar um modelo de aprendizado de máquina. Esses requisitos são descritos nas seções a seguir, com base nos respetivos tipos de modelo.
Configurar as entradas do modelo de ML
Para criar um modelo de AutoML, selecione o ícone ML na coluna Ações da tabela de fluxo de dados e selecione Adicionar um modelo de aprendizado de máquina.
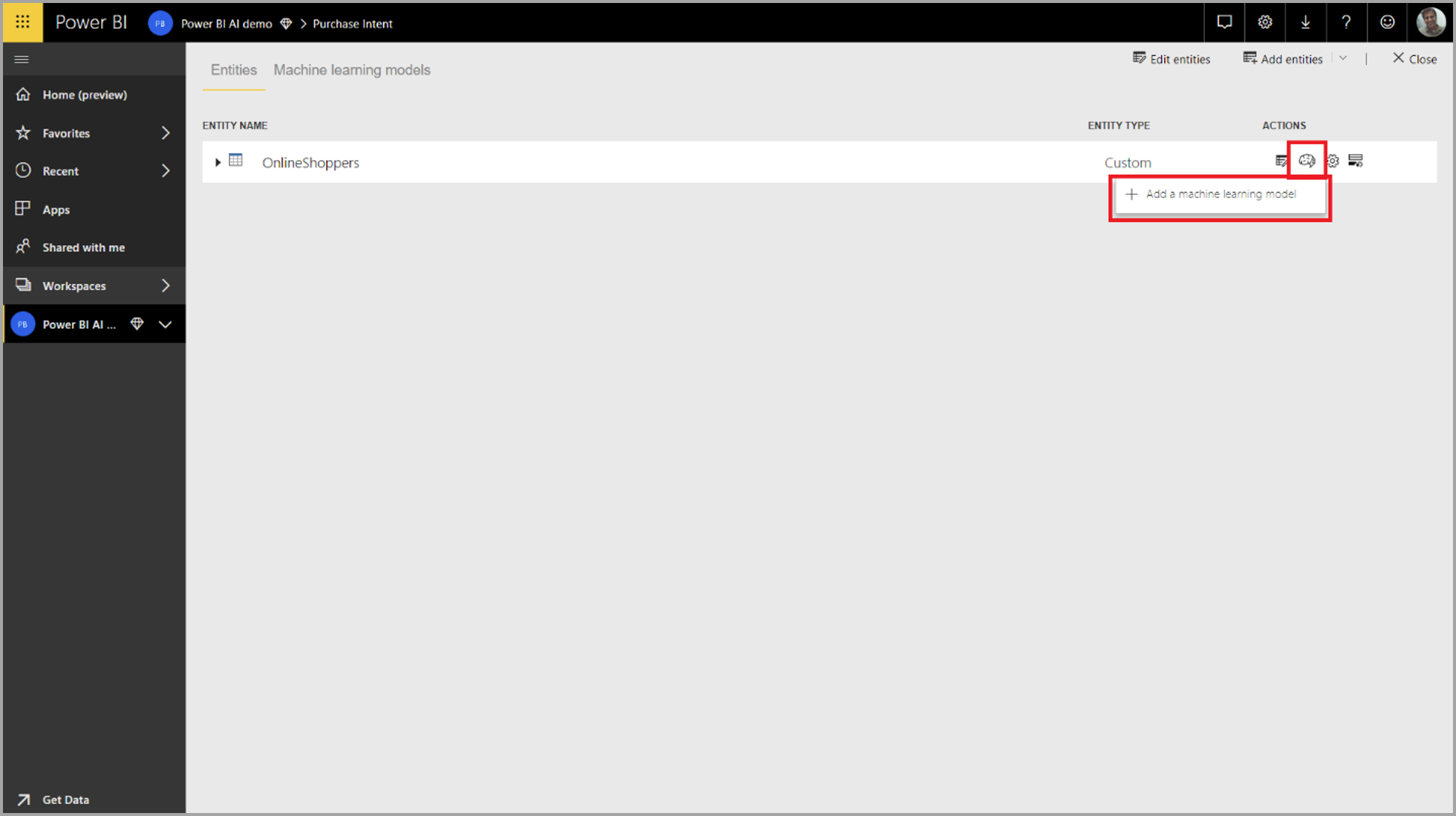
Uma experiência simplificada é iniciada, consistindo em um assistente que o orienta pelo processo de criação do modelo de ML. O assistente inclui as seguintes etapas simples.
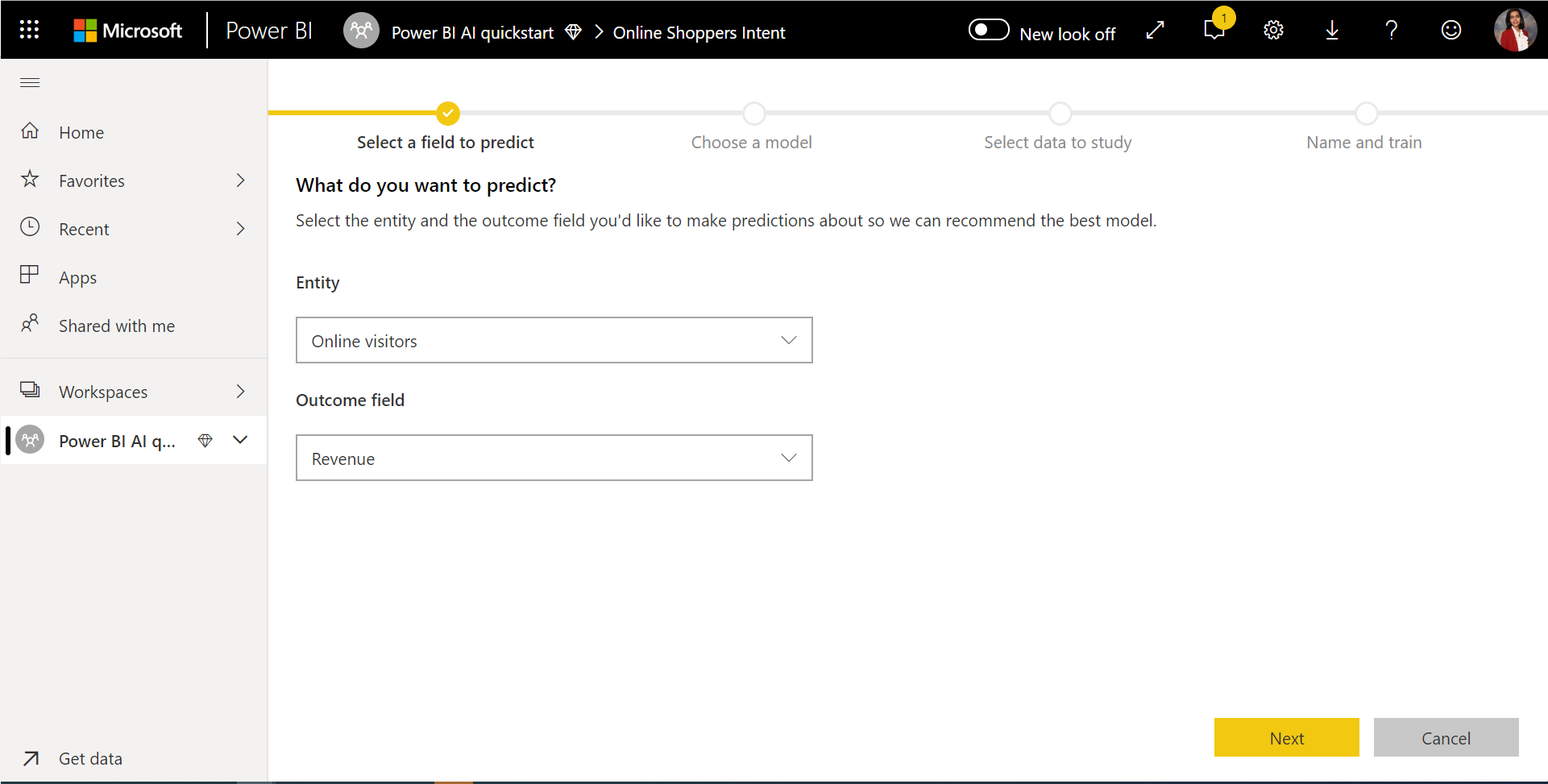
1. Selecione a tabela com os dados históricos e escolha a coluna de resultados para a qual deseja uma previsão
A coluna de resultado identifica o atributo label para treinar o modelo de ML, mostrado na imagem a seguir.
2. Escolha um tipo de modelo
Quando você especifica a coluna de resultado, o AutoML analisa os dados do rótulo para recomendar o tipo de modelo de ML mais provável que pode ser treinado. Você pode escolher um tipo de modelo diferente, conforme mostrado na imagem a seguir, clicando em Escolher um modelo.
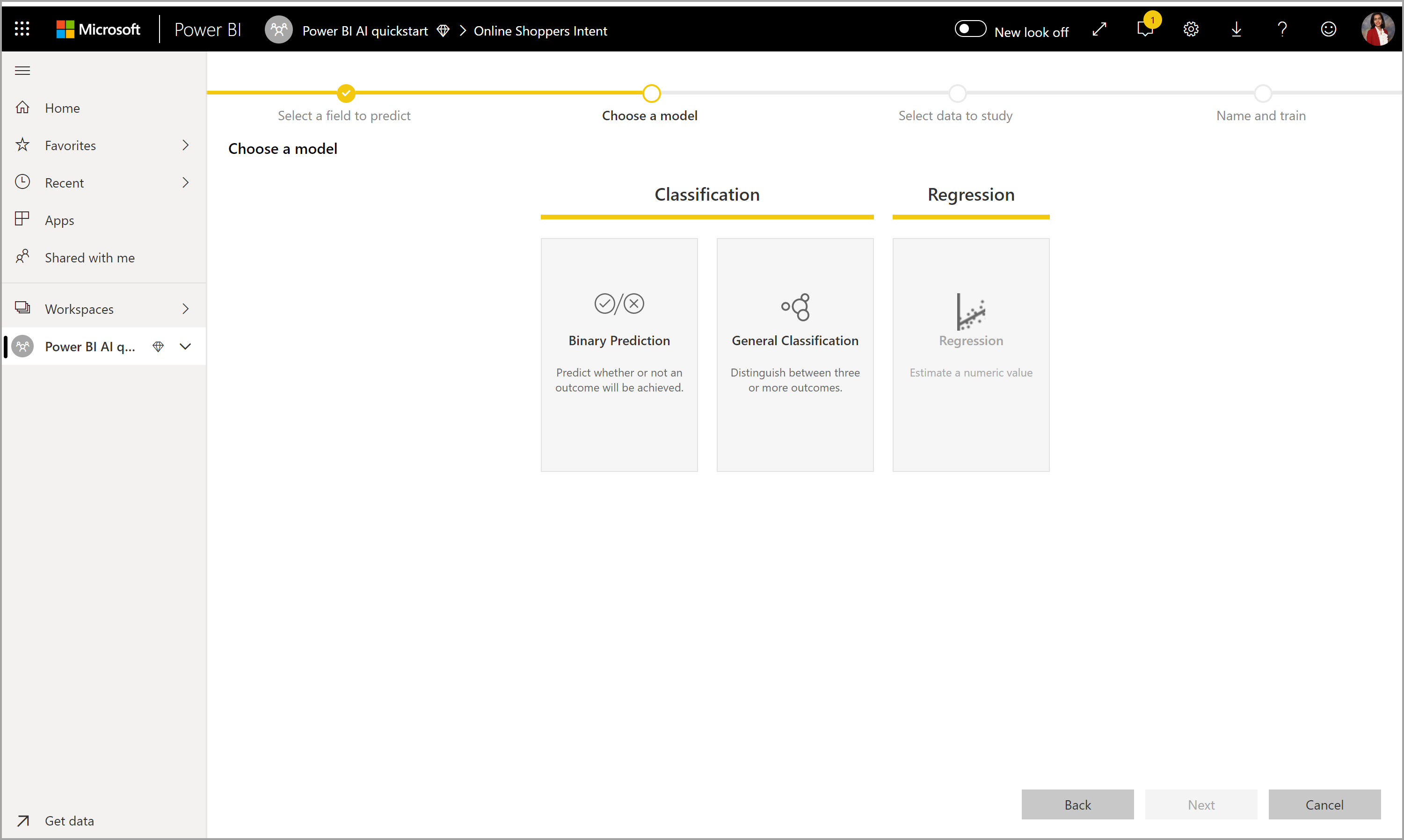
Nota
Alguns tipos de modelo podem não ser suportados para os dados que você selecionou e, portanto, ele seria desabilitado. No exemplo anterior, Regressão está desabilitada, porque uma coluna de texto é selecionada como coluna de resultado.
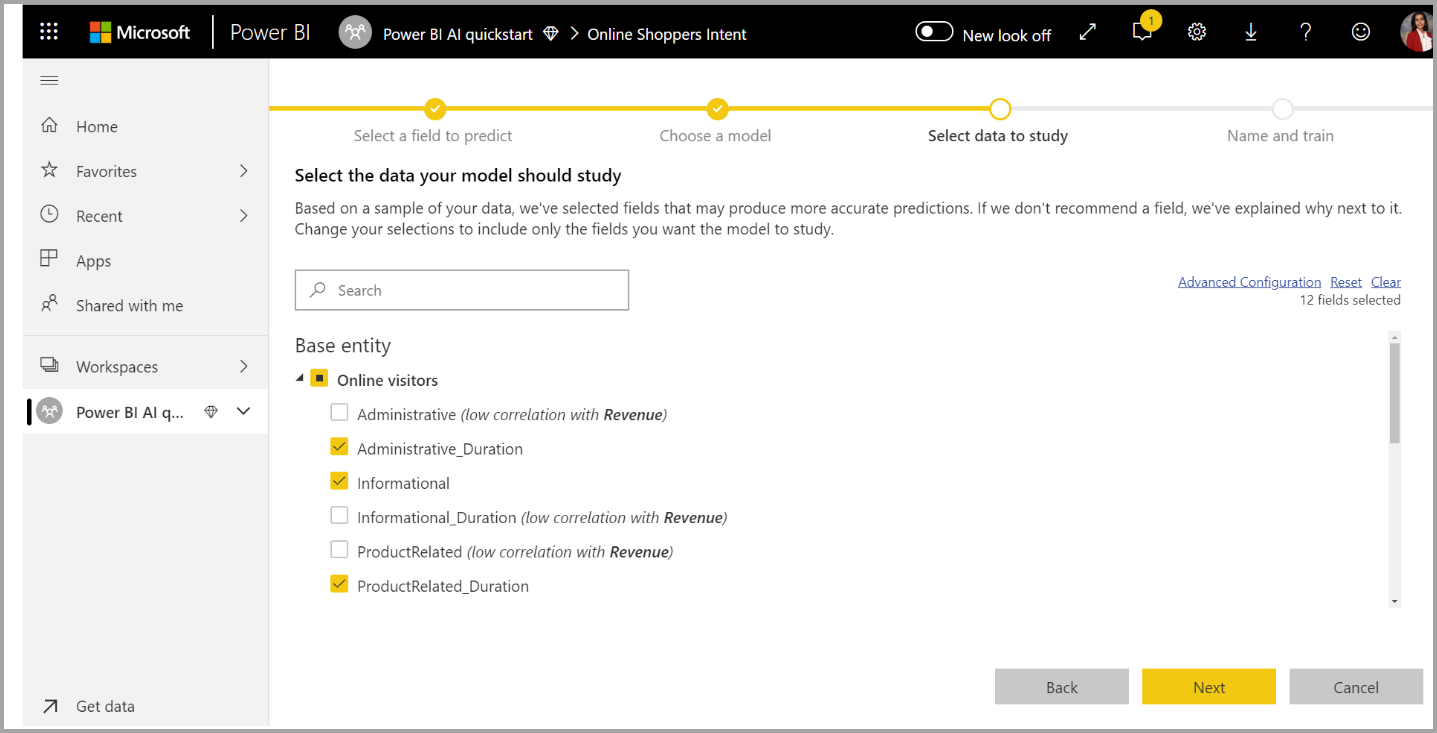
3. Selecione as entradas que você deseja que o modelo use como sinais preditivos
O AutoML analisa uma amostra da tabela selecionada para sugerir as entradas que podem ser usadas para treinar o modelo de ML. As explicações são fornecidas ao lado das colunas que não estão selecionadas. Se uma coluna específica tiver muitos valores distintos ou apenas um valor, ou correlação baixa ou alta com a coluna de saída, isso não é recomendado.
Quaisquer entradas que dependam da coluna de resultados (ou da coluna de rótulo) não devem ser usadas para treinar o modelo de ML, pois afetam seu desempenho. Tais colunas são sinalizadas como tendo "correlação suspeitamente alta com a coluna de saída". A introdução dessas colunas nos dados de treinamento causa vazamento de rótulo, em que o modelo tem um bom desempenho nos dados de validação ou teste, mas não pode igualar esse desempenho quando usado na produção para pontuação. O vazamento de etiquetas pode ser uma possível preocupação em modelos AutoML quando o desempenho do modelo de treinamento é bom demais para ser verdade.
Essa recomendação de recurso é baseada em uma amostra de dados, portanto, você deve revisar as entradas usadas. Você pode alterar as seleções para incluir apenas as colunas que deseja que o modelo estude. Você também pode selecionar todas as colunas marcando a caixa de seleção ao lado do nome da tabela.
4. Nomeie seu modelo e salve sua configuração
Na etapa final, você pode nomear o modelo, selecionar Salvar e escolher qual começa a treinar o modelo de ML. Você pode optar por reduzir o tempo de treinamento para ver resultados rápidos ou aumentar a quantidade de tempo gasto no treinamento para obter o melhor modelo.
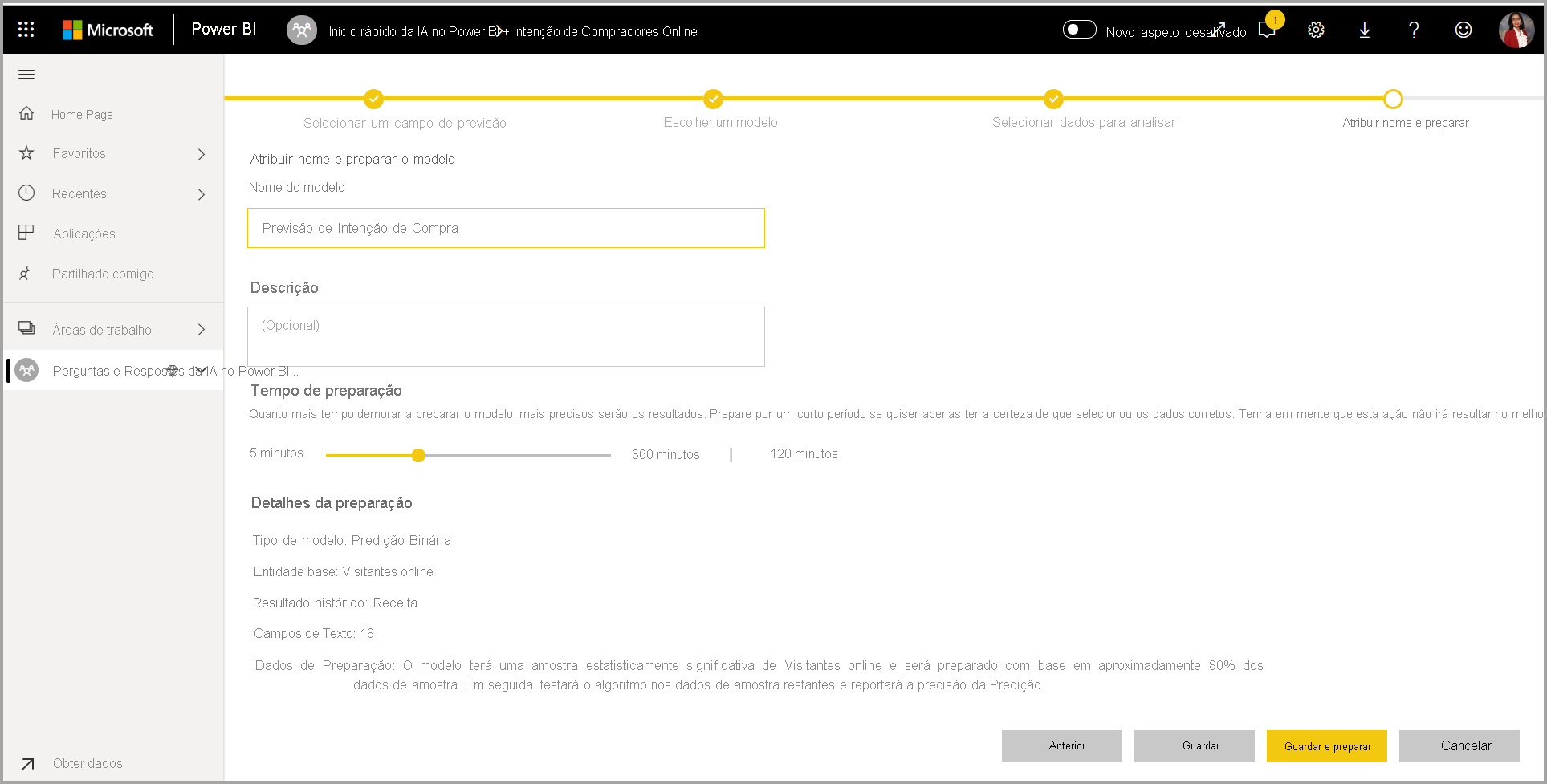
Treinamento de modelo de ML
O treinamento de modelos AutoML faz parte da atualização do fluxo de dados. O AutoML primeiro prepara seus dados para treinamento. O AutoML divide os dados históricos fornecidos em modelos semânticos de treinamento e teste. O modelo semântico de teste é um conjunto de retenção que é usado para validar o desempenho do modelo após o treinamento. Esses conjuntos são realizados como tabelas de treinamento e teste no fluxo de dados. O AutoML usa validação cruzada para a validação do modelo.
Em seguida, cada coluna de entrada é analisada e a imputação é aplicada, que substitui quaisquer valores ausentes por valores substituídos. Algumas estratégias de imputação diferentes são usadas pelo AutoML. Para atributos de entrada tratados como características numéricas, a média dos valores de coluna é usada para imputação. Para atributos de entrada tratados como recursos categóricos, o AutoML usa o modo dos valores de coluna para imputação. A estrutura AutoML calcula a média e o modo de valores usados para imputação no modelo semântico de treinamento subamostrado.
Em seguida, a amostragem e a normalização são aplicadas aos seus dados, conforme necessário. Para modelos de classificação, o AutoML executa os dados de entrada por amostragem estratificada e equilibra as classes para garantir que as contagens de linhas sejam iguais para todos.
O AutoML aplica várias transformações em cada coluna de entrada selecionada com base em seu tipo de dados e propriedades estatísticas. O AutoML usa essas transformações para extrair recursos para uso no treinamento de seu modelo de ML.
O processo de treinamento para modelos AutoML consiste em até 50 iterações com diferentes algoritmos de modelagem e configurações de hiperparâmetros para encontrar o modelo com o melhor desempenho. O treinamento pode terminar cedo com iterações menores se o AutoML notar que não há nenhuma melhoria de desempenho sendo observada. O AutoML avalia o desempenho de cada um desses modelos validando com o modelo semântico de teste de holdout. Durante esta etapa de treinamento, o AutoML cria vários pipelines para treinamento e validação dessas iterações. O processo de avaliação do desempenho dos modelos pode levar tempo, de vários minutos a algumas horas, até o tempo de treinamento configurado no assistente. O tempo necessário depende do tamanho do seu modelo semântico e dos recursos de capacidade disponíveis.
Em alguns casos, o modelo final gerado pode usar a aprendizagem de conjunto, onde vários modelos são usados para oferecer um melhor desempenho preditivo.
Explicação do modelo AutoML
Depois que o modelo foi treinado, o AutoML analisa a relação entre os recursos de entrada e a saída do modelo. Ele avalia a magnitude da alteração na saída do modelo para o modelo semântico de teste de holdout para cada recurso de entrada. Essa relação é conhecida como a importância do recurso. Esta análise acontece como parte da atualização após a conclusão do treinamento. Portanto, sua atualização pode levar mais tempo do que o tempo de treinamento configurado no assistente.
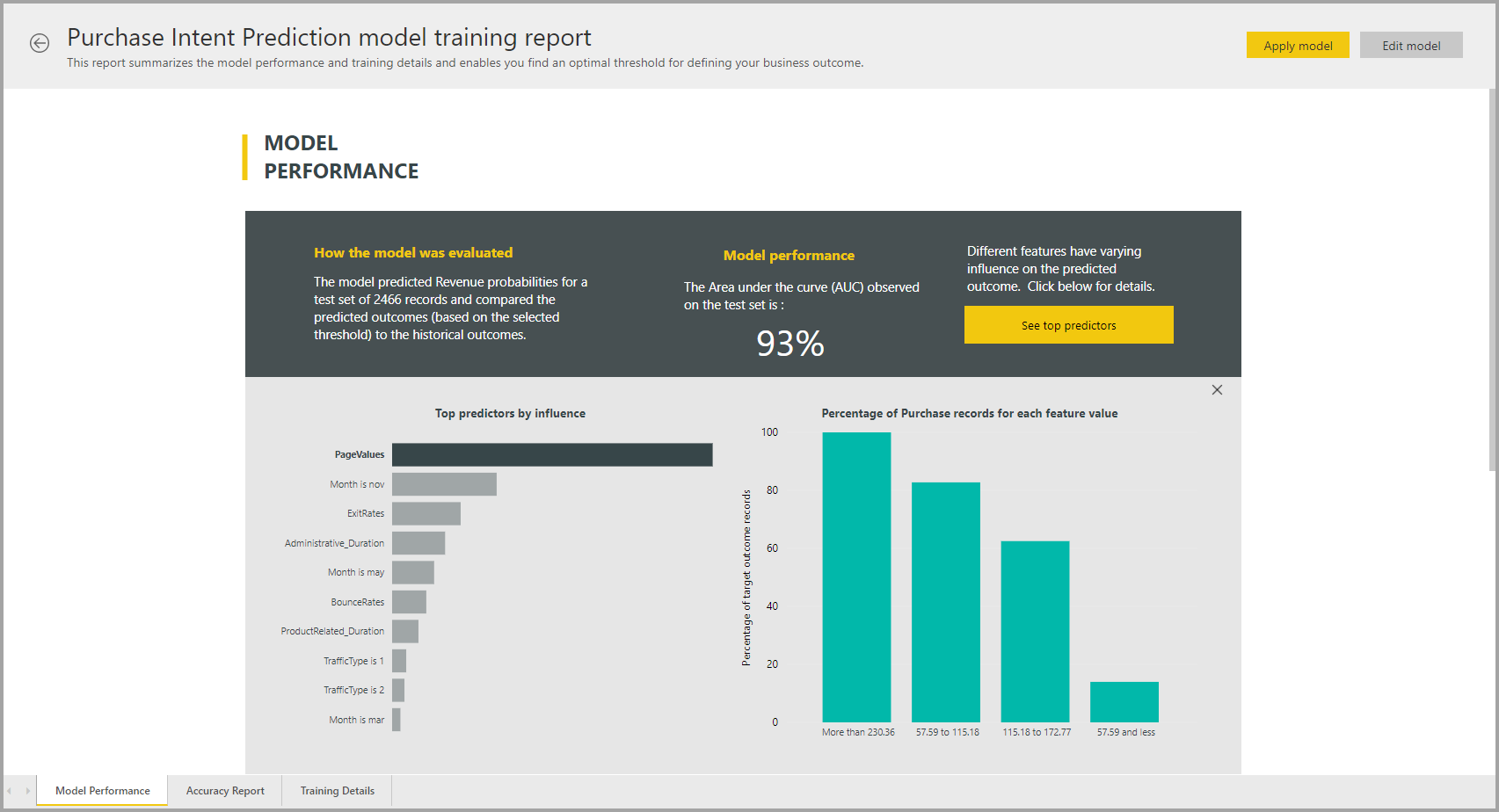
Relatório de modelo AutoML
O AutoML gera um relatório do Power BI que resume o desempenho do modelo durante a validação, juntamente com a importância global do recurso. Esse relatório pode ser acessado na guia Modelos de Aprendizado de Máquina após a atualização do fluxo de dados ser bem-sucedida. O relatório resume os resultados da aplicação do modelo de ML aos dados do teste de holdout e compara as previsões com os valores de resultado conhecidos.
Você pode revisar o relatório de modelo para entender seu desempenho. Você também pode validar se os principais influenciadores do modelo estão alinhados com os insights de negócios sobre os resultados conhecidos.
Os gráficos e medidas usados para descrever o desempenho do modelo no relatório dependem do tipo de modelo. Esses gráficos e medidas de desempenho são descritos nas seções a seguir.
Outras páginas do relatório podem descrever medidas estatísticas sobre o modelo de uma perspetiva de ciência de dados. Por exemplo, o relatório de previsão binária inclui um gráfico de ganho e a curva ROC para o modelo.
Os relatórios também incluem uma página Detalhes de treinamento que inclui uma descrição de como o modelo foi treinado e um gráfico descrevendo o desempenho do modelo em cada uma das iterações executadas.
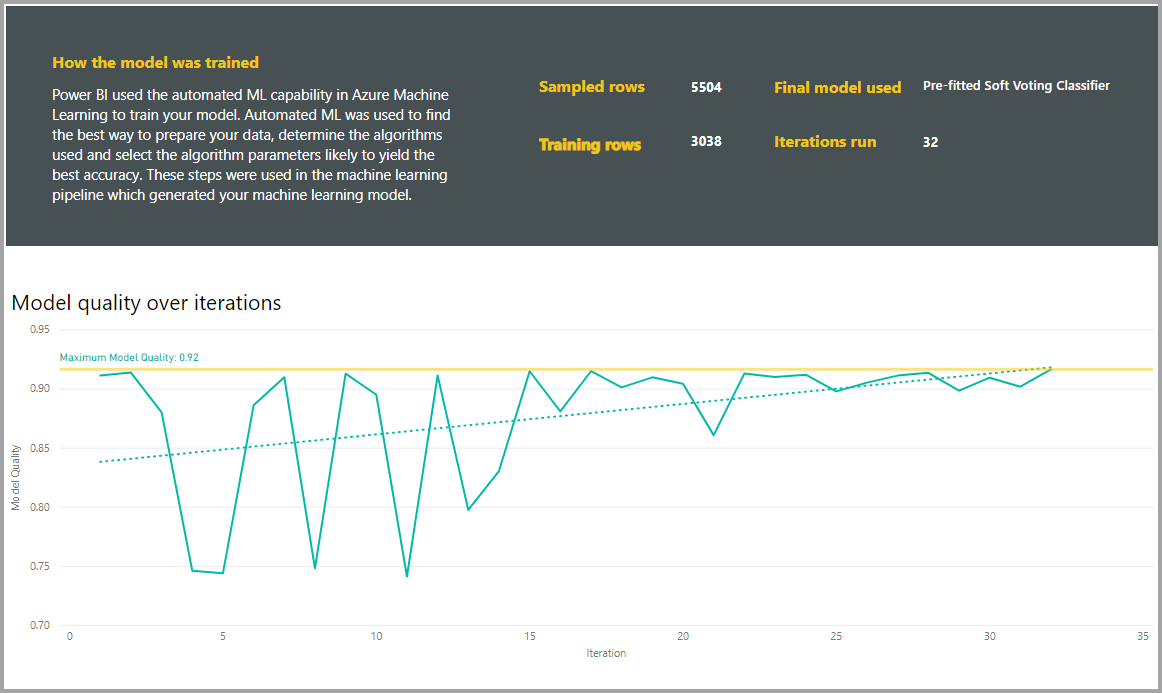
Outra seção nesta página descreve o tipo detetado da coluna de entrada e o método de imputação usado para preencher os valores ausentes. Inclui também os parâmetros utilizados pelo modelo final.
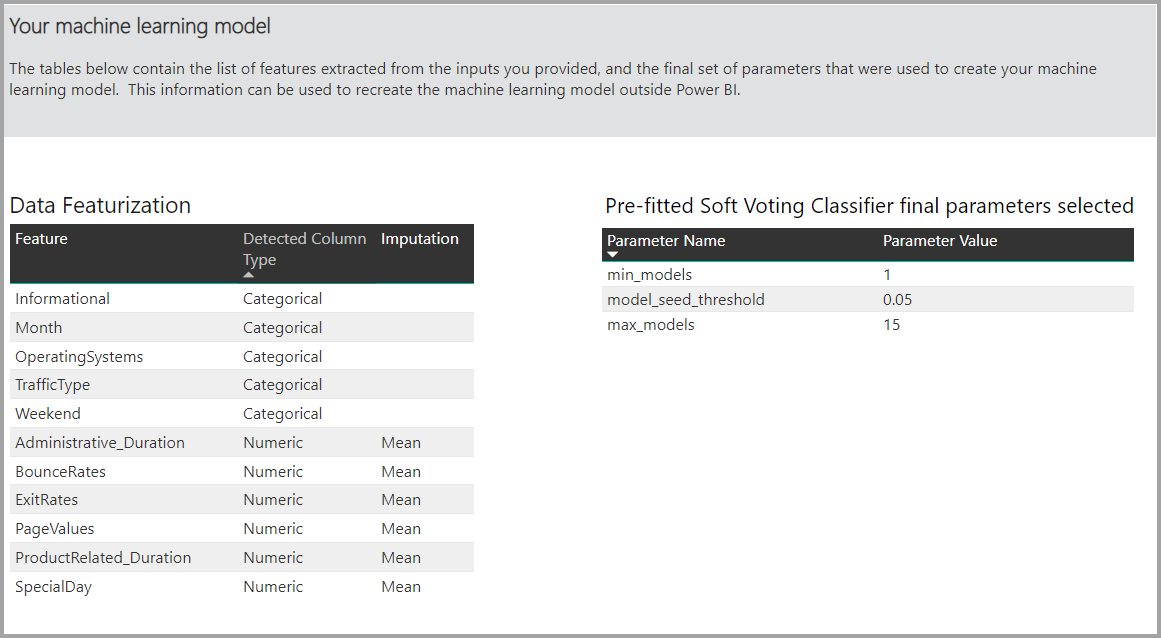
Se o modelo produzido usa aprendizagem de conjunto, então a página Detalhes do treinamento também inclui um gráfico mostrando o peso de cada modelo constituinte no conjunto e seus parâmetros.
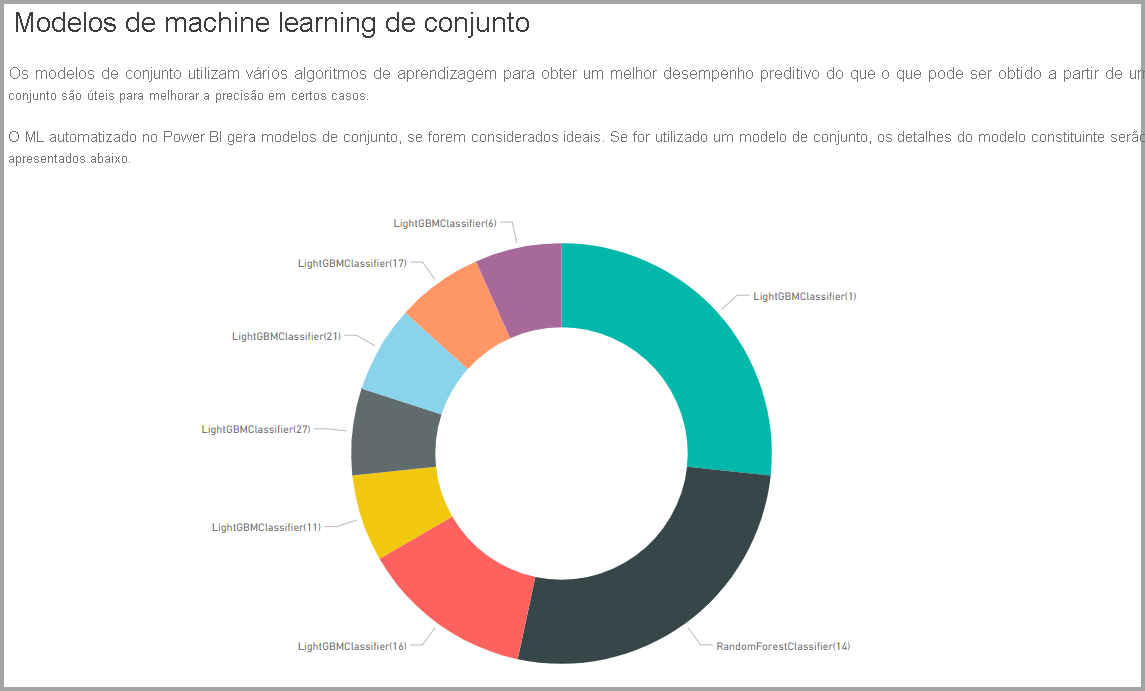
Aplicar o modelo AutoML
Se estiver satisfeito com o desempenho do modelo de ML criado, você poderá aplicá-lo a dados novos ou atualizados quando o fluxo de dados for atualizado. No relatório do modelo, selecione o botão Aplicar no canto superior direito ou o botão Aplicar Modelo de ML em ações na guia Modelos de Aprendizado de Máquina .
Para aplicar o modelo ML, você deve especificar o nome da tabela à qual ele deve ser aplicado e um prefixo para as colunas que serão adicionadas a essa tabela para a saída do modelo. O prefixo padrão para os nomes das colunas é o nome do modelo. A função Apply pode incluir mais parâmetros específicos para o tipo de modelo.
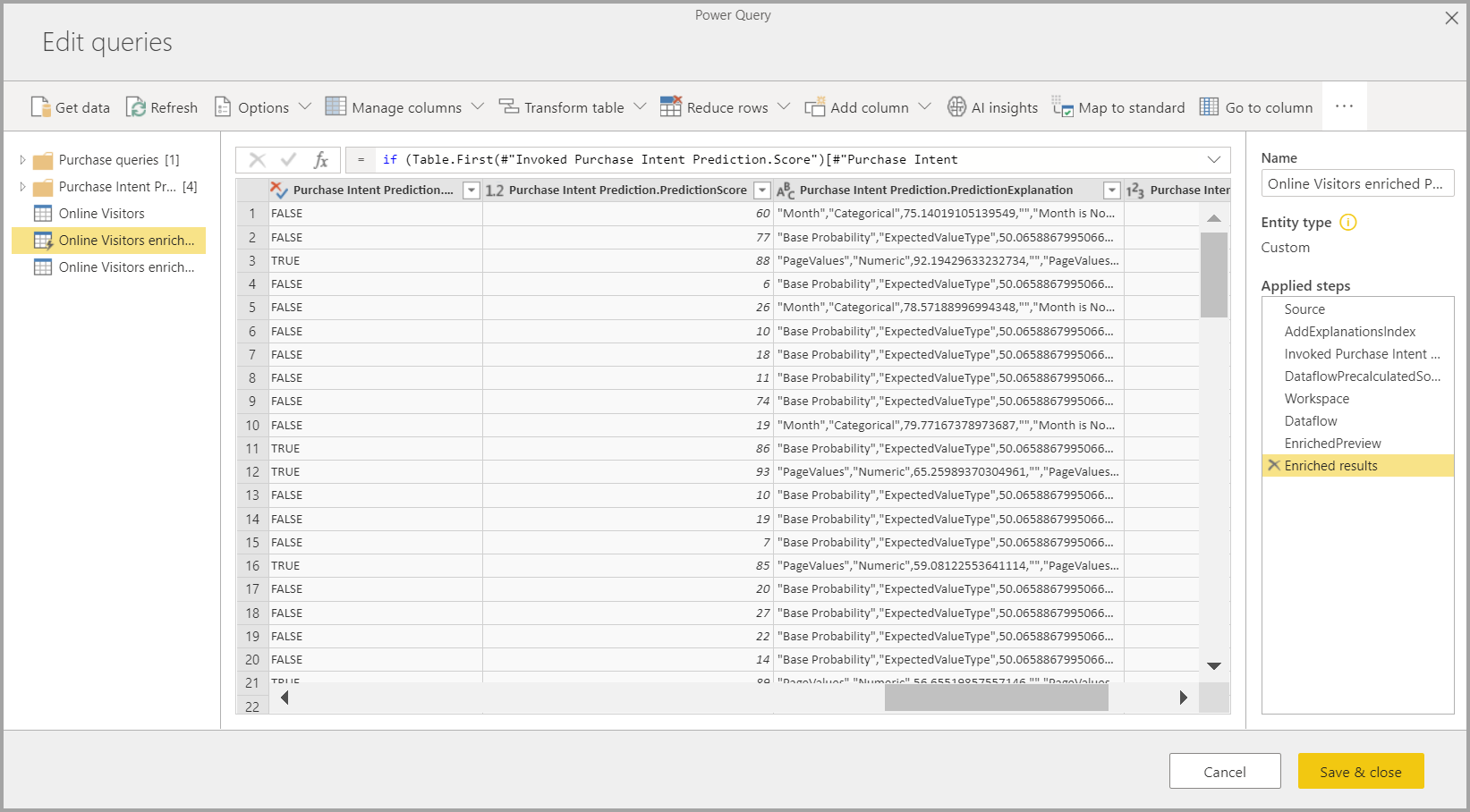
A aplicação do modelo de ML cria duas novas tabelas de fluxo de dados que contêm as previsões e explicações individualizadas para cada linha que ele pontua na tabela de saída. Por exemplo, se você aplicar o modelo PurchaseIntent à tabela OnlineShoppers, a saída gerará as tabelas de explicações PurchaseIntent enriquecidas OnlineShoppers e PurchaseIntent enriquecidas OnlineShoppers. Para cada linha na tabela enriquecida, As explicações são divididas em várias linhas na tabela de explicações enriquecidas com base no recurso de entrada. Um ExplanationIndex ajuda a mapear as linhas da tabela de explicações enriquecida para a linha na tabela enriquecida.
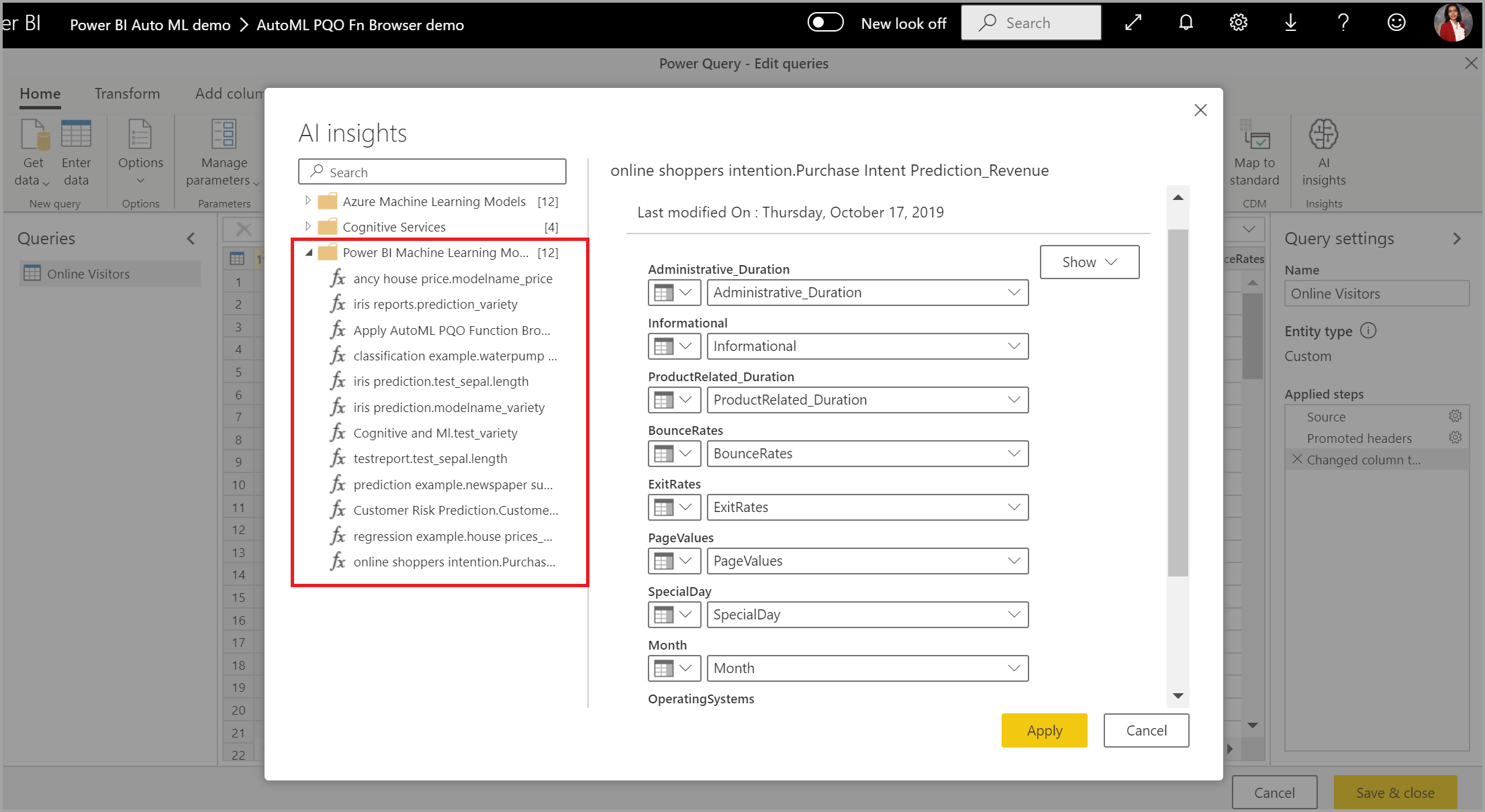
Você também pode aplicar qualquer modelo do Power BI AutoML a tabelas em qualquer fluxo de dados no mesmo espaço de trabalho usando o AI Insights no navegador de função PQO. Dessa forma, você pode usar modelos criados por outras pessoas no mesmo espaço de trabalho sem necessariamente ser um proprietário do fluxo de dados que tem o modelo. O Power Query deteta todos os modelos de ML do Power BI na área de trabalho e expõe-os como funções dinâmicas do Power Query. Pode invocar essas funções acedendo às mesmas a partir do friso no Power Query Editor ou invocando diretamente a função M. Atualmente, esta funcionalidade só é suportada para fluxos de dados do Power BI e para o Power Query Online no serviço do Power BI. Esse processo é diferente da aplicação de modelos de ML em um fluxo de dados usando o assistente AutoML. Não há nenhuma tabela de explicações criada usando esse método. A menos que você seja o proprietário do fluxo de dados, não poderá acessar relatórios de treinamento do modelo ou treinar novamente o modelo. Além disso, se o modelo de origem for editado adicionando ou removendo colunas de entrada ou se o modelo ou o fluxo de dados de origem for excluído, esse fluxo de dados dependente será interrompido.
Depois de aplicar o modelo, o AutoML sempre mantém suas previsões atualizadas sempre que o fluxo de dados é atualizado.
Para usar as informações e previsões do modelo de ML em um relatório do Power BI, você pode se conectar à tabela de saída do Power BI Desktop usando o conector de fluxos de dados.
Modelos de previsão binária
Os modelos de previsão binária, mais formalmente conhecidos como modelos de classificação binária, são usados para classificar um modelo semântico em dois grupos. Eles são usados para prever eventos que podem ter um resultado binário. Por exemplo, se uma oportunidade de venda será convertida, se uma conta será churn, se uma fatura será paga no prazo, se uma transação é fraudulenta e assim por diante.
A saída de um modelo de Previsão Binária é uma pontuação de probabilidade, que identifica a probabilidade de que o resultado alvo seja alcançado.
Treinar um modelo de previsão binária
Pré-requisitos:
- É necessário um mínimo de 20 linhas de dados históricos para cada classe de resultados
O processo de criação de um modelo de Previsão Binária segue as mesmas etapas de outros modelos AutoML, descritas na seção anterior, Configurar as entradas do modelo de ML. A única diferença está na etapa Escolha um modelo, onde você pode selecionar o valor de resultado de destino no qual está mais interessado. Você também pode fornecer rótulos amigáveis para os resultados a serem usados no relatório gerado automaticamente que resume os resultados da validação do modelo.
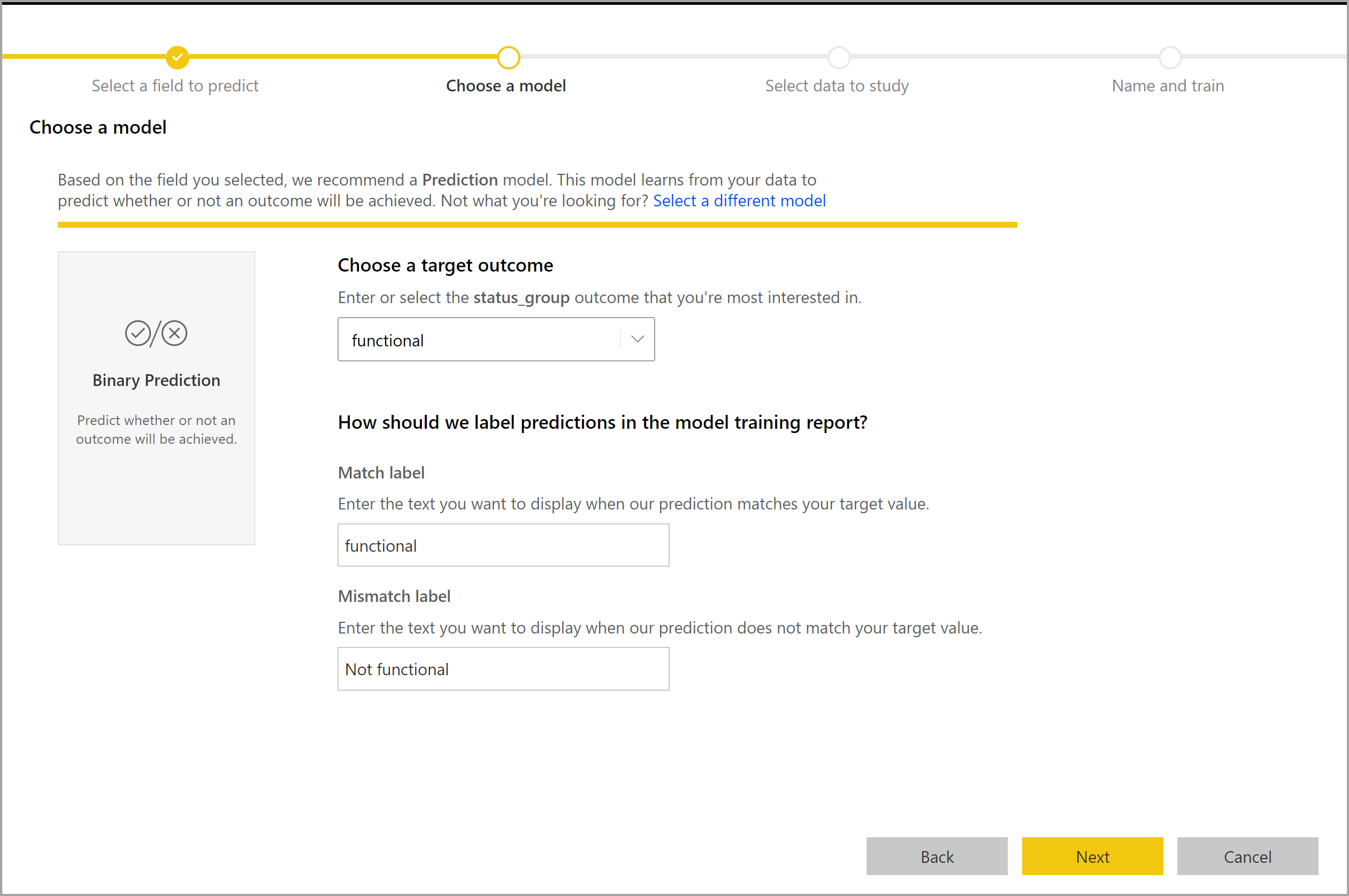
Relatório de modelo de previsão binária
O modelo de Previsão Binária produz como saída uma probabilidade de que uma linha atinja o resultado pretendido. O relatório inclui uma segmentação de dados para o limiar de probabilidade, que influencia a forma como as pontuações maiores e inferiores ao limiar de probabilidade são interpretadas.
O relatório descreve o desempenho do modelo em termos de Verdadeiros Positivos, Falsos Positivos, Verdadeiros Negativos e Falso Negativos. Verdadeiros Positivos e Verdadeiros Negativos são resultados corretamente previstos para as duas classes nos dados de resultados. Os falsos positivos são linhas que se previa terem o resultado do Alvo, mas na verdade não o fizeram. Por outro lado, os Falsos Negativos são linhas que tinham resultados alvo, mas foram previstos como não eles.
Medidas, como Precisão e Recordação, descrevem o efeito do limiar de probabilidade sobre os resultados previstos. Você pode usar a segmentação de dados de limite de probabilidade para selecionar um limite que atinja um compromisso equilibrado entre Precisão e Recordação.

O relatório também inclui uma ferramenta de análise de custo-benefício para ajudar a identificar o subconjunto da população que deve ser direcionado para obter o maior lucro. Dado um custo unitário estimado de segmentação e um benefício unitário de alcançar um resultado alvo, a análise de custo-benefício tenta maximizar o lucro. Você pode usar essa ferramenta para escolher seu limite de probabilidade com base no ponto máximo no gráfico para maximizar o lucro. Você também pode usar o gráfico para calcular o lucro ou custo para sua escolha de limite de probabilidade.
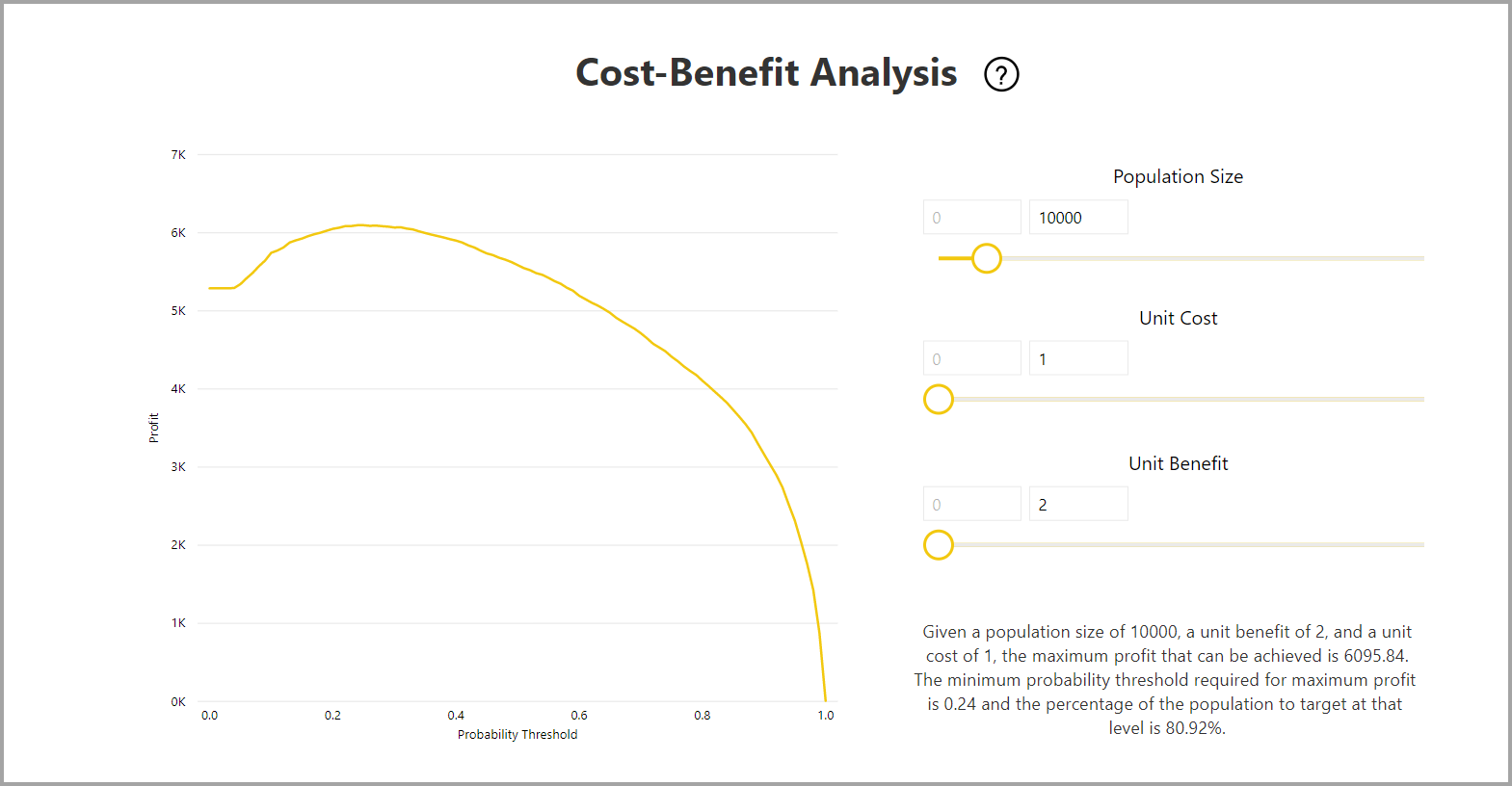
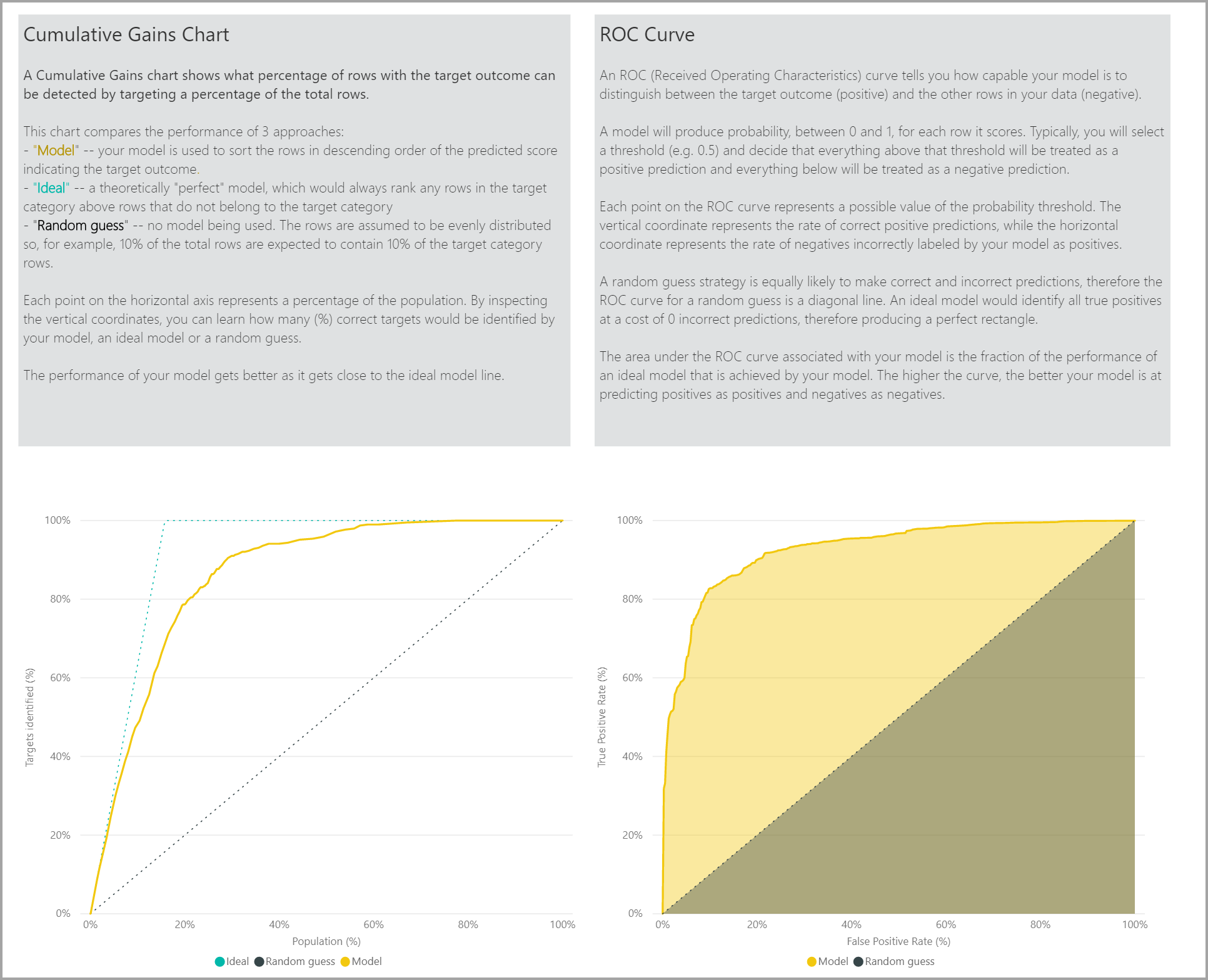
A página Relatório de Precisão do relatório do modelo inclui o gráfico de Ganhos Acumulados e a curva ROC do modelo. Estes dados fornecem medidas estatísticas do desempenho do modelo. Os relatórios incluem descrições dos gráficos mostrados.
Aplicar um modelo de previsão binária
Para aplicar um modelo de previsão binária, você deve especificar a tabela com os dados aos quais deseja aplicar as previsões do modelo de ML. Outros parâmetros incluem o prefixo do nome da coluna de saída e o limiar de probabilidade para classificar o resultado previsto.
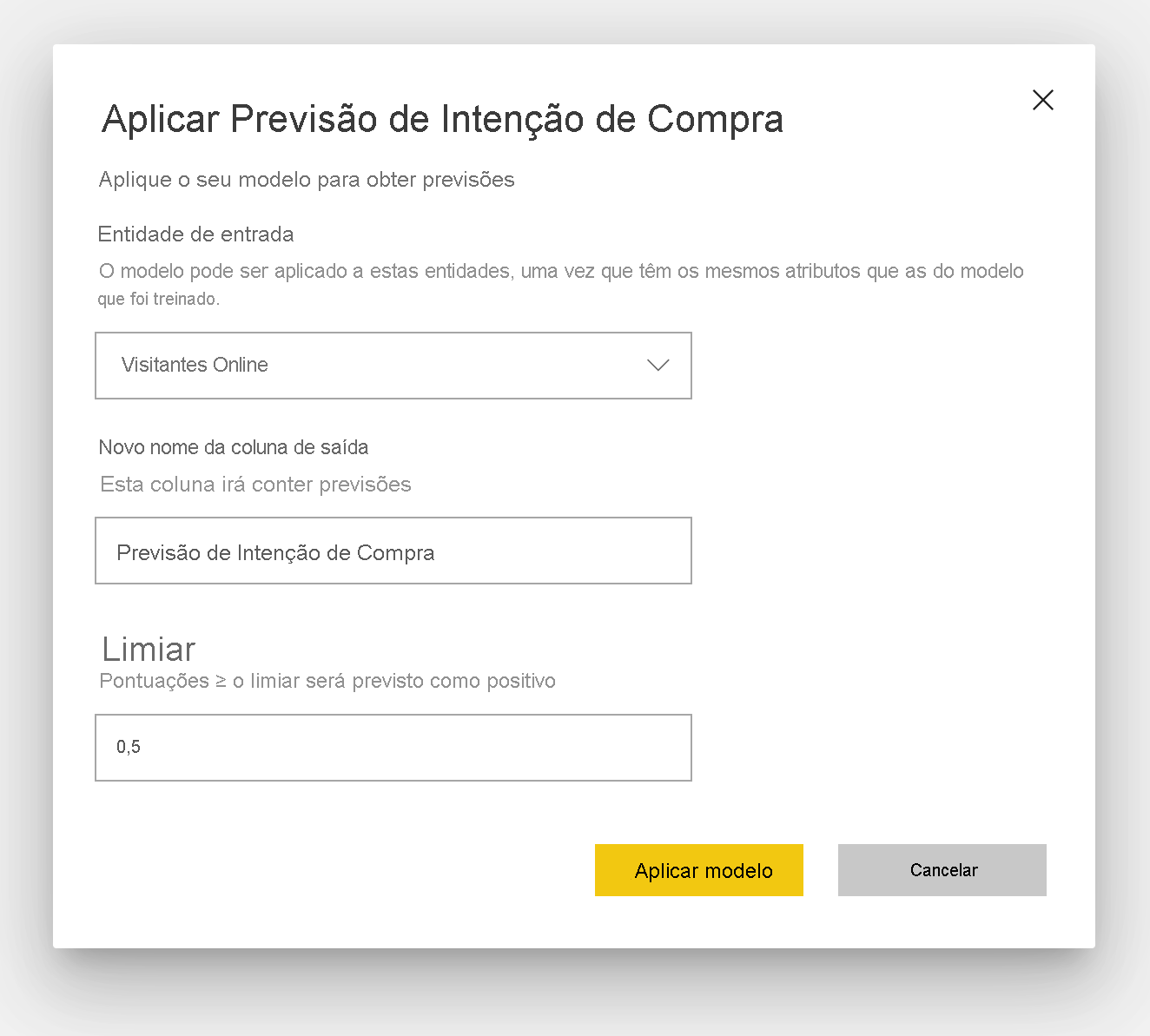
Quando um modelo de previsão binária é aplicado, ele adiciona quatro colunas de saída à tabela de saída enriquecida: Outcome, PredictionScore, PredictionExplanation e ExplanationIndex. Os nomes das colunas na tabela têm o prefixo especificado quando o modelo é aplicado.
PredictionScore é uma probabilidade percentual, que identifica a probabilidade de que o resultado pretendido seja alcançado.
A coluna Resultado contém o rótulo de resultado previsto. Os registros com probabilidades superiores ao limite são previstos como prováveis de atingir o resultado desejado e são rotulados como Verdadeiros. Registros menores que o limite são previstos como improváveis de alcançar o resultado e são rotulados como Falsos.
A coluna PredictionExplanation contém uma explicação com a influência específica que os recursos de entrada tiveram no PredictionScore.
Modelos de classificação
Os modelos de classificação são usados para classificar um modelo semântico em vários grupos ou classes. Eles são usados para prever eventos que podem ter um dos múltiplos resultados possíveis. Por exemplo, se é provável que um cliente tenha um valor vitalício alto, médio ou baixo. Eles também podem prever se o risco de inadimplência é alto, moderado, baixo e assim por diante.
O resultado de um modelo de classificação é uma pontuação de probabilidade, que identifica a probabilidade de uma linha atingir os critérios para uma determinada classe.
Treinar um modelo de classificação
A tabela de entrada que contém seus dados de treinamento para um modelo de classificação deve ter uma cadeia de caracteres ou coluna de número inteiro como a coluna de resultado, que identifica os resultados conhecidos passados.
Pré-requisitos:
- É necessário um mínimo de 20 linhas de dados históricos para cada classe de resultados
O processo de criação de um modelo de classificação segue as mesmas etapas de outros modelos AutoML, descritas na seção anterior, Configurar as entradas do modelo de ML.
Relatório do modelo de classificação
O Power BI cria o relatório do modelo de classificação aplicando o modelo de ML aos dados de teste de holdout. Em seguida, ele compara a classe prevista para uma linha com a classe conhecida real.
O relatório de modelo inclui um gráfico que inclui a divisão das linhas classificadas corretamente e incorretamente para cada classe conhecida.
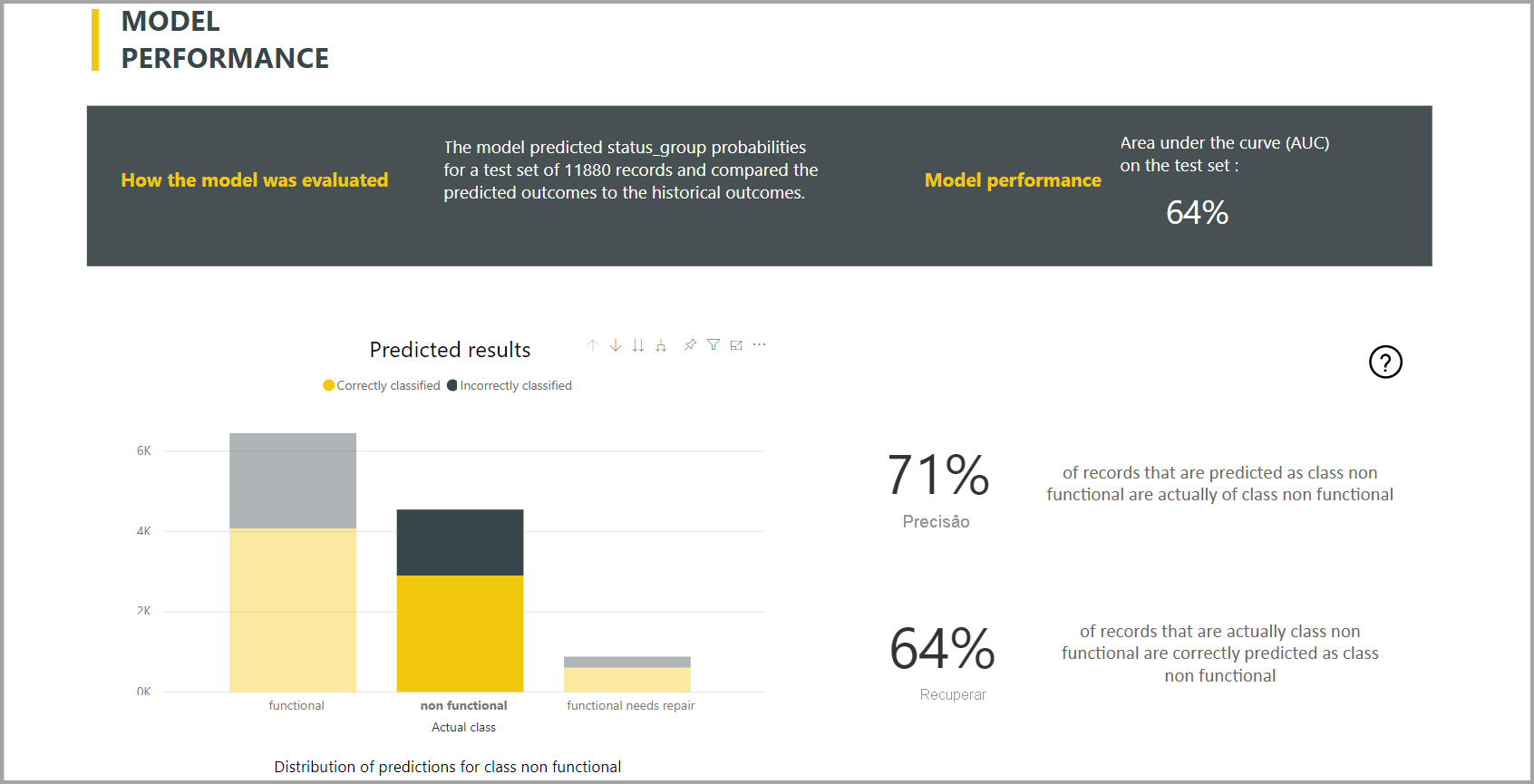
Uma outra ação de detalhamento específica da classe permite uma análise de como as previsões para uma classe conhecida são distribuídas. Esta análise mostra as outras classes em que as linhas dessa classe conhecida são suscetíveis de ser mal classificadas.
A explicação do modelo no relatório também inclui os principais preditores para cada classe.
O relatório do modelo de classificação também inclui uma página Detalhes do treinamento semelhante às páginas para outros tipos de modelo, conforme descrito anteriormente, no relatório de modelo AutoML.
Aplicar um modelo de classificação
Para aplicar um modelo de ML de classificação, você deve especificar a tabela com os dados de entrada e o prefixo do nome da coluna de saída.
Quando um modelo de classificação é aplicado, ele adiciona cinco colunas de saída à tabela de saída enriquecida: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities e ExplanationIndex. Os nomes das colunas na tabela têm o prefixo especificado quando o modelo é aplicado.
A coluna ClassProbabilities contém a lista de pontuações de probabilidade para a linha para cada classe possível.
O ClassificationScore é a probabilidade percentual, que identifica a probabilidade de uma linha atingir os critérios para uma determinada classe.
A coluna ClassificationResult contém a classe prevista mais provável para a linha.
A coluna ClassificationExplanation contém uma explicação com a influência específica que os recursos de entrada tiveram no ClassificationScore.
Modelos de regressão
Os modelos de regressão são usados para prever um valor numérico e podem ser usados em cenários como determinar:
- A receita que provavelmente será realizada a partir de um acordo de venda.
- O valor vitalício de uma conta.
- O valor de uma fatura a receber que provavelmente será paga
- A data em que uma fatura pode ser paga, e assim por diante.
A saída de um modelo de regressão é o valor previsto.
Treinando um modelo de regressão
A tabela de entrada que contém os dados de treinamento para um modelo de regressão deve ter uma coluna numérica como a coluna de resultado, que identifica os valores de resultado conhecidos.
Pré-requisitos:
- Um mínimo de 100 linhas de dados históricos é necessário para um modelo de regressão.
O processo de criação de um modelo de regressão segue as mesmas etapas de outros modelos AutoML, descritas na seção anterior, Configurar as entradas do modelo de ML.
Relatório do modelo de regressão
Como os outros relatórios de modelo AutoML, o relatório de regressão é baseado nos resultados da aplicação do modelo aos dados de teste de holdout.
O relatório de modelo inclui um gráfico que compara os valores previstos com os valores reais. Neste gráfico, a distância da diagonal indica o erro na previsão.
O gráfico de erro residual mostra a distribuição da percentagem de erro médio para diferentes valores no modelo semântico do teste de holdout. O eixo horizontal representa a média do valor real para o grupo. O tamanho da bolha mostra a frequência ou contagem de valores nesse intervalo. O eixo vertical é o erro residual médio.
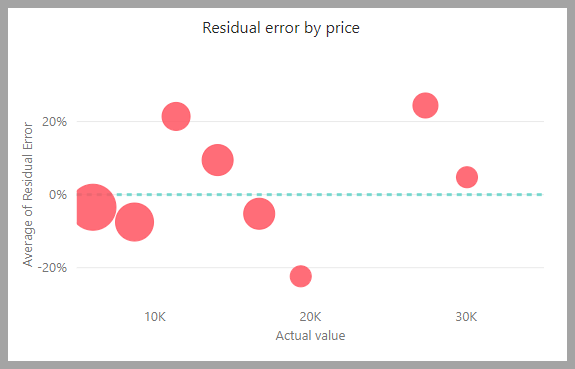
O relatório de modelo de regressão também inclui uma página Detalhes de treinamento, como os relatórios para outros tipos de modelo, conforme descrito na seção anterior, Relatório de modelo AutoML.
Aplicar um modelo de regressão
Para aplicar um modelo de ML de regressão, você deve especificar a tabela com os dados de entrada e o prefixo do nome da coluna de saída.
Quando um modelo de regressão é aplicado, ele adiciona três colunas de saída à tabela de saída enriquecida: RegressionResult, RegressionExplanation e ExplanationIndex. Os nomes das colunas na tabela têm o prefixo especificado quando o modelo é aplicado.
A coluna RegressionResult contém o valor previsto para a linha com base nas colunas de entrada. A coluna RegressionExplanation contém uma explicação com a influência específica que os recursos de entrada tiveram no RegressionResult.
Integração do Azure Machine Learning no Power BI
Várias organizações usam modelos de aprendizado de máquina para melhores insights e previsões sobre seus negócios. Você pode usar o aprendizado de máquina com seus relatórios, painéis e outras análises para obter esses insights. A capacidade de visualizar e invocar insights desses modelos pode ajudar a disseminar esses insights para os usuários corporativos que mais precisam. O Power BI agora simplifica a incorporação de informações de modelos hospedados no Aprendizado de Máquina do Azure, usando gestos simples de apontar e clicar.
Para usar esse recurso, um cientista de dados pode conceder acesso ao modelo do Azure Machine Learning ao analista de BI usando o portal do Azure. Em seguida, no início de cada sessão, o Power Query descobre todos os modelos do Azure Machine Learning aos quais o utilizador tem acesso e expõe-os como funções dinâmicas do Power Query. Em seguida, o utilizador pode invocar essas funções acedendo-as a partir do friso no Power Query Editor ou invocando diretamente a função M. O Power BI também agrupa automaticamente as solicitações de acesso ao invocar o modelo do Azure Machine Learning para um conjunto de linhas para obter um melhor desempenho.
Atualmente, esta funcionalidade só tem suporte para fluxos de dados do Power BI e para o Power Query online no serviço do Power BI.
Para saber mais sobre fluxos de dados, consulte Introdução aos fluxos de dados e preparação de dados de autoatendimento.
Para saber mais sobre o Azure Machine Learning, consulte:
- Visão geral: O que é o Azure Machine Learning?
- Inícios rápidos e tutoriais para o Azure Machine Learning: Documentação do Azure Machine Learning
Conceder acesso ao modelo do Azure Machine Learning a um utilizador do Power BI
Para acessar um modelo do Azure Machine Learning do Power BI, o usuário deve ter acesso de Leitura à assinatura do Azure e ao espaço de trabalho do Aprendizado de Máquina.
As etapas neste artigo descrevem como conceder a um usuário do Power BI acesso a um modelo hospedado no serviço Azure Machine Learning para acessar esse modelo como uma função do Power Query. Para obter mais informações, consulte Atribuir funções do Azure utilizando o portal do Azure.
Inicie sessão no portal do Azure.
Aceda à página Subscrições . Pode encontrar a página Subscrições através da lista Todos os Serviços no menu do painel de navegação do portal do Azure.
Selecione a sua subscrição.

Selecione Controle de acesso (IAM) e, em seguida, escolha o botão Adicionar .
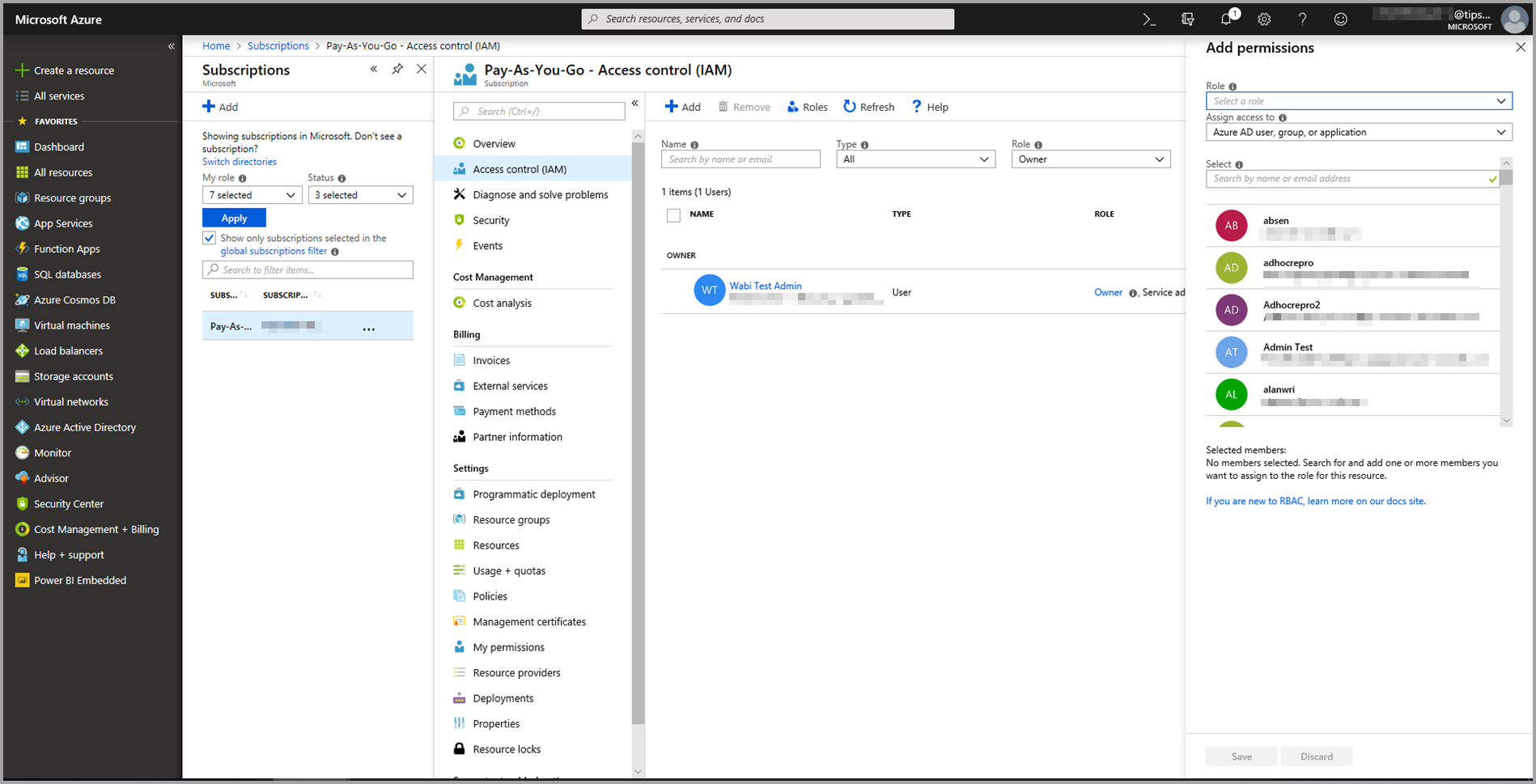
Selecione Leitor como a função. Em seguida, escolha o usuário do Power BI ao qual você deseja conceder acesso ao modelo do Azure Machine Learning.
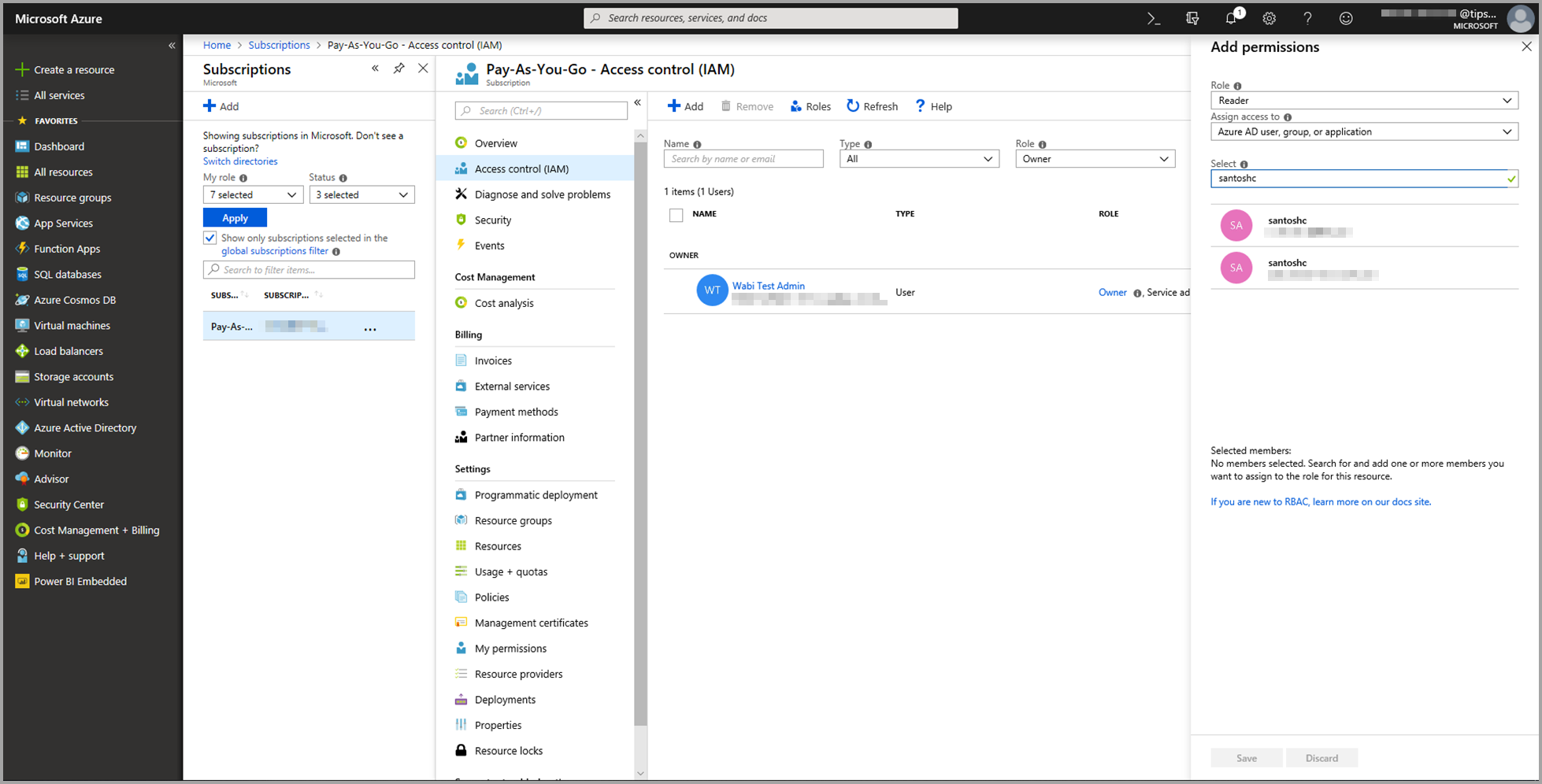
Selecione Guardar.
Repita as etapas de três a seis para conceder ao usuário acesso ao Reader para o espaço de trabalho de aprendizado de máquina específico que hospeda o modelo.




Descoberta de esquema para modelos de aprendizado de máquina
Os cientistas de dados usam principalmente Python para desenvolver, e até mesmo implantar, seus modelos de aprendizado de máquina para aprendizado de máquina. O cientista de dados deve gerar explicitamente o arquivo de esquema usando Python.
Esse arquivo de esquema deve ser incluído no serviço Web implantado para modelos de aprendizado de máquina. Para gerar automaticamente o esquema para o serviço Web, você deve fornecer uma amostra da entrada/saída no script de entrada para o modelo implantado. Para obter mais informações, consulte Implantar e pontuar um modelo de aprendizado de máquina usando um ponto de extremidade online. O link inclui o script de entrada de exemplo com as instruções para a geração do esquema.
Especificamente, as funções @input_schema e @output_schema no script de entrada fazem referência aos formatos de amostra de entrada e saída nas variáveis input_sample e output_sample . As funções usam esses exemplos para gerar uma especificação OpenAPI (Swagger) para o serviço Web durante a implantação.
Estas instruções para a geração de esquema atualizando o script de entrada também devem ser aplicadas a modelos criados usando experimentos automatizados de aprendizado de máquina com o SDK do Azure Machine Learning.
Nota
Atualmente, os modelos criados usando a interface visual do Aprendizado de Máquina do Azure não oferecem suporte à geração de esquema, mas serão exibidos em versões subsequentes.
Invocando o modelo do Azure Machine Learning no Power BI
Pode invocar qualquer modelo do Azure Machine Learning ao qual lhe tenha sido concedido acesso, diretamente a partir do Editor do Power Query no seu fluxo de dados. Para acessar os modelos do Azure Machine Learning, selecione o botão Editar Tabela para a tabela que você deseja enriquecer com informações do seu modelo do Azure Machine Learning, conforme mostrado na imagem a seguir.

Selecionar o botão Editar Tabela abre o Editor do Power Query para as tabelas no seu fluxo de dados.

Selecione o botão AI Insights no friso e, em seguida, selecione a pasta Modelos de Aprendizagem de Máquina do Azure no menu do painel de navegação. Todos os modelos do Azure Machine Learning aos quais você tem acesso são listados aqui como funções do Power Query. Além disso, os parâmetros de entrada para o modelo do Azure Machine Learning são mapeados automaticamente como parâmetros da função Power Query correspondente.
Para invocar um modelo do Azure Machine Learning, você pode especificar qualquer uma das colunas da tabela selecionada como uma entrada da lista suspensa. Você também pode especificar um valor constante a ser usado como entrada alternando o ícone de coluna à esquerda da caixa de diálogo de entrada.

Selecione Invocar para exibir a visualização da saída do modelo do Azure Machine Learning como uma nova coluna na tabela. A invocação do modelo aparece como uma etapa aplicada para a consulta.

Se o modelo retornar vários parâmetros de saída, eles serão agrupados como uma linha na coluna de saída. Você pode expandir a coluna para produzir parâmetros de saída individuais em colunas separadas.

Depois de salvar o fluxo de dados, o modelo é invocado automaticamente quando o fluxo de dados é atualizado, para quaisquer linhas novas ou atualizadas na tabela.
Considerações e limitações
- Atualmente, o Dataflows Gen2 não se integra ao aprendizado de máquina automatizado.
- Os insights de IA (Serviços Cognitivos e modelos do Azure Machine Learning) não são suportados em máquinas com configuração de autenticação de proxy.
- Os modelos do Azure Machine Learning não são suportados para utilizadores convidados.
- Existem alguns problemas conhecidos com o uso do Gateway com AutoML e Serviços Cognitivos. Se você precisar usar um gateway, recomendamos criar um fluxo de dados que importe os dados necessários via gateway primeiro. Em seguida, crie outro fluxo de dados que faça referência ao primeiro fluxo de dados para criar ou aplicar esses modelos e funções de IA.
- Se o seu trabalho de IA com fluxos de dados falhar, talvez seja necessário ativar o Fast Combine ao usar IA com fluxos de dados. Depois de importar sua tabela e antes de começar a adicionar recursos de IA, selecione Opções na faixa de opções Página Inicial e, na janela exibida, marque a caixa de seleção ao lado de Permitir a combinação de dados de várias fontes para habilitar o recurso e, em seguida, selecione OK para salvar sua seleção. Em seguida, você pode adicionar recursos de IA ao seu fluxo de dados.
Conteúdos relacionados
Este artigo forneceu uma visão geral do Aprendizado de Máquina Automatizado para Fluxos de Dados no serviço do Power BI. Os seguintes artigos também podem ser úteis.
- Tutorial: Criar um modelo de Aprendizagem de Máquina no Power BI
- Tutorial: Usar os Serviços Cognitivos no Power BI
Os seguintes artigos fornecem mais informações sobre fluxos de dados e o Power BI:
- Introdução aos fluxos de dados e preparação de dados de autoatendimento
- Criando um fluxo de dados
- Configurar e consumir um fluxo de dados
- Configurar o armazenamento de fluxo de dados para usar o Azure Data Lake Gen 2
- Recursos premium de fluxos de dados
- Considerações e limitações dos fluxos de dados
- Práticas recomendadas de fluxos de dados