Копирование данных из Teradata Vantage с помощью Фабрики данных Azure и Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия копирования в Фабрике данных Azure и конвейерах Synapse Analytics копировать данные из Teradata Vantage. Она составлена на основе статьи Действие Copy в Фабрике данных Azure.
Поддерживаемые возможности
Соединитель Teradata предназначен для поддержки следующих возможностей.
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/-) | (1) (2) |
| Действие поиска | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования, приведен в таблице Поддерживаемые хранилища данных и форматы.
Этот соединитель Teradata поддерживает:
- Версия Teradata 14.10, 15.0, 15.10, 16.0, 16.10 и 16.20.
- Копирование данных с помощью проверки подлинности Обычная, Windows или LDAP.
- Параллельное копирование из источника Teradata. Дополнительные сведения см. в разделе Параллельное копирование из Teradata.
Необходимые компоненты
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешений.
Вы также можете использовать функцию среды выполнения интеграции в управляемой виртуальной сети в Фабрике данных Azure для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Если вы используете локальную среду выполнения интеграции, обратите внимание, что она предоставляет встроенный драйвер Teradata, начиная с версии 3.18. Для использования этого соединителя не нужно вручную устанавливать драйвер. Для драйвера требуется "Распространяемый компонент Visual C++ 2012 — обновление 4", устанавливаемый на компьютере с локальной средой выполнения интеграции. Если этот компонент не установлен, скачайте его на этой странице.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы с Teradata с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу с Teradata в пользовательском интерфейсе портала Azure.
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск Teradata и выберите соединитель Teradata.
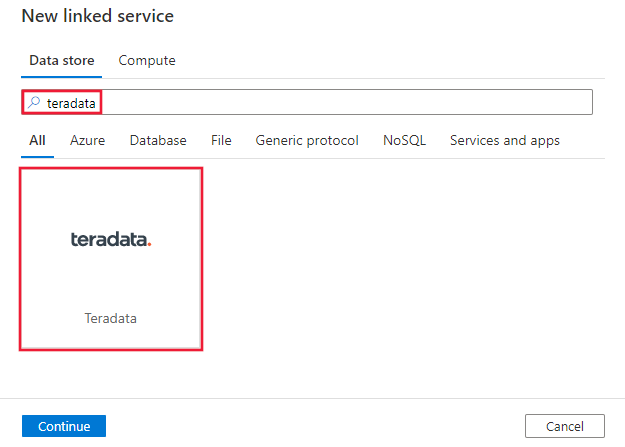
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
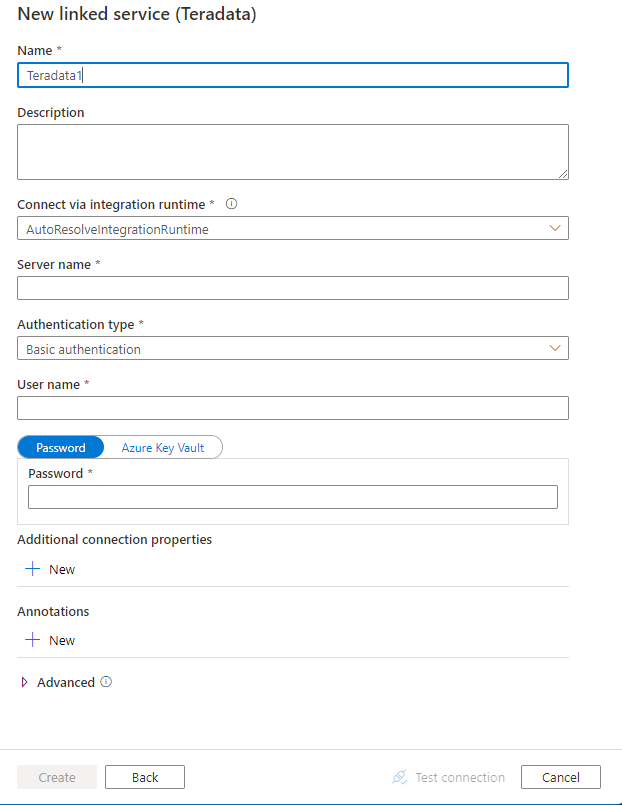
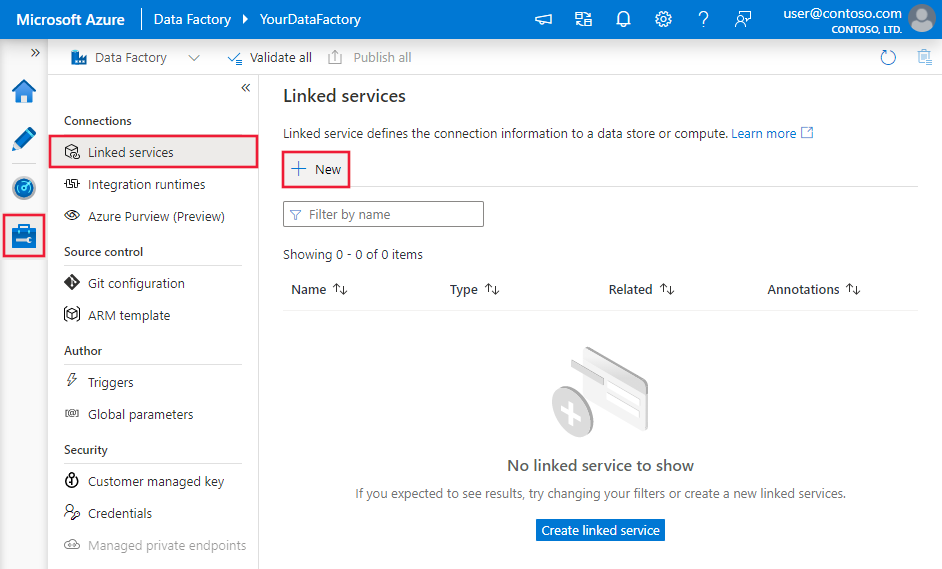
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения объектов Фабрики данных, относящихся к соединителю Teradata.
Свойства связанной службы
Связанная служба Teradata поддерживает следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение Teradata. | Да |
| connectionString | Указывает сведения, необходимые для подключения к экземпляру Teradata. Ознакомьтесь с приведенными ниже примерами. Вы можете также поместить пароль в Azure Key Vault и извлечь конфигурацию password из строки подключения. Дополнительные сведения см. в разделе Хранение учетных данных в Azure Key Vault. |
Да |
| username | Укажите имя пользователя для подключения к Teradata. Применяется при использовании проверки подлинности Windows. | No |
| password | Введите пароль для учетной записи пользователя, указанной для выбранного имени пользователя. Также можно указать ссылку на секрет, хранящийся в Azure Key Vault. Применяется при использовании проверки подлинности Windows или при создании ссылки на пароль в Key Vault для обычной проверки подлинности. |
No |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано другое, по умолчанию используется интегрированная среда выполнения Azure. | No |
Дополнительные свойства подключения, которые можно задать в строке подключения в зависимости от сценария
| Свойство | Описание: | Default value |
|---|---|---|
| TdmstPortNumber | Номер порта, используемый для доступа к базе данных Teradata. Не изменяйте это значение, если это не рекомендовано службой технической поддержки. |
1025 |
| UseDataEncryption | Указывает, следует ли шифровать все каналы связи с базой данных Teradata. Допустимые значения: 0 или 1. - 0 (отключено, по умолчанию): шифрует только данные о проверке подлинности. - 1 (включено): шифрует все данные, передаваемые между драйвером и базой данных. |
0 |
| CharacterSet | Кодировка, используемая для сеанса. Пример: CharacterSet=UTF16.Это значение может быть определяемым пользователем набором символов или одним из следующих предварительно определенных наборов символов: — ASCII — UTF8 — UTF16 — LATIN1252_0A — LATIN9_0A — LATIN1_0A — Shift-JIS (Windows, совместимые с DOS, KANJISJIS_0S) — EUC (совместимые с Unix, KANJIEC_0U) — Мэйнфрейм IBM (KANJIEBCDIC5035_0I) — KANJI932_1S0 — BIG5 (TCHBIG5_1R0) — GB (SCHGB2312_1T0) — SCHINESE936_6R0 — TCHINESE950_8R0 — NetworkKorean (HANGULKSC5601_2R4) — HANGUL949_7R0 — ARABIC1256_6A0 — CYRILLIC1251_2A0 — HEBREW1255_5A0 — LATIN1250_1A0 — LATIN1254_7A0 — LATIN1258_8A0 — THAI874_4A0 |
ASCII |
| MaxRespSize | Максимальный размер буфера ответов для запросов SQL в килобайтах (КБ). Пример: MaxRespSize=10485760.Для базы данных Teradata версии 16.00 или более поздней максимальное значение равно 7 361 536. Для соединений, использующих более ранние версии, максимальное значение — 1 048 576. |
65536 |
| MechanismName | Чтобы использовать протокол LDAP для проверки подлинности подключения, укажите MechanismName=LDAP. |
Н/П |
Пример: использование обычной проверки подлинности
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: использование проверки подлинности Windows
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: использование проверки подлинности LDAP
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Примечание.
Следующие полезные данные по-прежнему поддерживаются. Однако в дальнейшем следует использовать новые данные.
Предыдущие полезные данные:
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
В этом разделе содержится список свойств, поддерживаемых набором данных Teradata. Полный список разделов и свойств, доступных для определения наборов данных, см. в разделе Наборы данных в фабрике данных Azure.
Для копирования данных из Teradata поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type набора данных необходимо задать значение TeradataTable. |
Да |
| database | Имя экземпляра Teradata. | Нет (если свойство query указано в источнике действия) |
| table | Имя таблицы в экземпляре базы данных Teradata. | Нет (если свойство query указано в источнике действия) |
Пример:
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
Примечание.
Набор данных типа RelationalTable по-прежнему поддерживается. Однако рекомендуется использовать новый набор данных.
Предыдущие полезные данные:
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Свойства действия копирования
В этом разделе содержится список свойств, поддерживаемых Teradata в качестве источника. Полный список разделов и свойств, доступных для определения действий, см. в разделе Конвейеры и действия в фабрике данных Azure.
Teradata в качестве источника
Совет
Чтобы эффективно загружать данные из Teradata с использованием секционирования данных, ознакомьтесь с дополнительными сведениями в разделе Параллельное копирование из Teradata.
Для копирования данных из Teradata в поле "Действие копирования" раздела Источник поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойству type источника действия копирования необходимо задать значение TeradataSource. |
Да |
| query | Используйте пользовательский SQL-запрос для чтения данных. Например, "SELECT * FROM MyTable".При включении секционированной нагрузки необходимо привязать все соответствующие встроенные параметры раздела в запросе. Примеры см. в разделе Параллельное копирование из Teradata. |
Нет (если указывается таблица в наборе данных) |
| partitionOptions | Задает параметры секционирования данных, используемые для загрузки данных из Teradata. Следующие значения являются допустимыми: Нет (по умолчанию), Хэш или DynamicRange. Если параметр секции включен (любое значение кроме None), степень параллелизма для параллельной загрузки данных из Teradata задается параметром parallelCopies в действии копирования. |
No |
| partitionSettings | Позволяет указать группу параметров для секционирования данных. Применяется, если параметр секционирования имеет значение, отличное от None. |
No |
| partitionColumnName | Укажите имя столбца источника, который будет использоваться секцией диапазона или секцией Хэша для параллельного копирования. Если значение не указано, автоматически определяется первичный индекс таблицы и используется в качестве столбца секции. Применяется, если параметр секции имеет значение Hash или DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfHashPartitionCondition или ?AdfRangePartitionColumnName в операторе WHERE. Пример см. в разделе Параллельное копирование из Teradata. |
No |
| partitionUpperBound | Максимальное значение столбца секционирования для копирования данных. Применяется, если параметр секционирования имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionUpbound в предложении WHERE. Например, можно найти в разделе Параллельное копирование из Teradata. |
No |
| partitionLowerBound | Минимальное значение столбца секционирования для копирования данных. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionLowbound в предложении WHERE. Например, можно найти в разделе Параллельное копирование из Teradata. |
No |
Примечание.
Источник копирования типа RelationalSource по-прежнему поддерживается, но не поддерживает новую встроенную параллельную загрузку из Teradata (параметры секции). Однако рекомендуется использовать новый набор данных.
Пример: копирование данных с помощью простого запроса без секции
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Параллельное копирование из Teradata
Соединитель Teradata предоставляет встроенную функцию секционирования данных для параллельного копирования данных из Teradata. Параметры секционирования данных можно найти в исходной таблице для действия копирования.

Если включено копирование с секционированием, служба выполняет параллельные запросы к источнику Teradata для загрузки данных по секциям. Степень параллелизма определяется с помощью параметра parallelCopies для действия копирования. Например, если задать для parallelCopies значение 4, служба одновременно генерирует и запускает четыре запроса на основе указанного вами варианта и настроек раздела, и каждый запрос извлекает часть данных из Teradata.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при загрузке большого объема данных из Teradata. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Сценарий | Предлагаемые параметры |
|---|---|
| Полная загрузка из большой таблицы. | Параметр секции: Хэш. Во время выполнения служба автоматически обнаруживает столбец с первичным индексом, применяет к нему хэш и копирует данные по секциям. |
| Для загрузки больших объемов данных используйте пользовательский запрос. | Параметр секции: Хэш. Запрос: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>.Столбец секции: укажите столбец для применения секции хэша. Если не указано, служба автоматически обнаруживает столбец PK таблицы, указанной в наборе данных Teradata. Во время выполнения служба заменяет ?AdfHashPartitionCondition на логику хэш-секции и передает в Teradata. |
| Для загрузки большого объема данных используйте пользовательский запрос с целочисленным столбцом, значения которого распределены равномерно для поддержки секционирования по диапазонам. | Параметры секции: секция динамического диапазона. Запрос: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. Секционирование можно выполнять по столбцу с целочисленным типом данных. Верхняя граница секции и нижняя граница секции. Укажите, следует ли фильтровать столбец секции только между нижним и верхним диапазоном. Во время выполнения служба заменяет ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound и ?AdfRangePartitionLowbound фактическим именем столбца и диапазонами значений для каждой секции, а затем отправляет их в Teradata. Например, если указан столбец секционирования ID с нижней границей 1 и верхней границей 80 при этом для параллельного копирования указано значение 4, служба будет извлекать данные по 4 секциям. Для них будут применены следующие диапазоны значений идентификаторов: [1, 20], [21, 40], [41, 60] и [61, 80]. |
Пример: запрос с хэш-секцией
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
Пример: запрос с секционированием по динамическому диапазону
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Сопоставление типов для Teradata
При копировании данных из Teradata к внутренним типам данных, используемым службой, применяются следующие сопоставления из типов данных Teradata. Дополнительные сведения о том, как действие копирования сопоставляет исходную схему и типы данных для приемника, см. в статье Сопоставление схем в действии копирования.
| Тип данных Teradata | Промежуточный тип данных службы |
|---|---|
| BigInt | Int64 |
| BLOB-объект | Byte[] |
| Байт | Byte[] |
| Тип ByteInt | Int16 |
| Char | Строка |
| Clob | Строка |
| Дата | Дата/время |
| Decimal | Decimal |
| Двойной | Двойной |
| GRAPHIC | Не поддерживается. Применить явное приведение в исходном запросе. |
| Целое | Int32 |
| Interval Day | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Day To Hour | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Day To Minute | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Day To Second | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Hour | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Hour To Minute | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Hour To Second | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Minute | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Minute To Second | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Month | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Second | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Year | Не поддерживается. Применить явное приведение в исходном запросе. |
| Interval Year To Month | Не поддерживается. Применить явное приведение в исходном запросе. |
| Число | Двойной |
| Период (дата) | Не поддерживается. Применить явное приведение в исходном запросе. |
| Период (время) | Не поддерживается. Применить явное приведение в исходном запросе. |
| Период (время с часовым поясом) | Не поддерживается. Применить явное приведение в исходном запросе. |
| Period (Timestamp) | Не поддерживается. Применить явное приведение в исходном запросе. |
| Период (метка времени с часовым поясом) | Не поддерживается. Применить явное приведение в исходном запросе. |
| SmallInt | Int16 |
| Время | TimeSpan |
| Time With Time Zone | TimeSpan |
| Метка времени | Дата/время |
| Timestamp With Time Zone | Дата/время |
| VarByte | Byte[] |
| VarChar | Строка |
| VarGraphic | Не поддерживается. Применить явное приведение в исходном запросе. |
| Xml | Не поддерживается. Применить явное приведение в исходном запросе. |
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Связанный контент
Список хранилищ данных, поддерживаемых в рамках функции копирования в качестве источников и приемников, см. в разделе Поддерживаемые хранилища данных.