Руководство. Создание приложения машинного обучения Apache Spark в Azure HDInsight
Из этого руководства вы узнаете, как с помощью Jupyter Notebook создать приложение машинного обучения Apache Spark для Azure HDInsight.
MLlib — это библиотека машинного обучения Apache Spark, состоящая из общих алгоритмов и служебных программ обучения (Классификация, регрессия, кластеризация, совместная фильтрация и уменьшение размерности, а также базовые примитивы оптимизации.)
В этом руководстве описано следующее:
- разработка приложения машинного обучения Apache Spark.
Необходимые компоненты
Кластер Apache Spark в HDInsight. Ознакомьтесь со статьей Краткое руководство. Создание кластера Apache Spark в HDInsight с помощью шаблона.
Опыт работы с записными книжками Jupyter и Spark в HDInsight. Дополнительные сведения см. в статье Руководство. Загрузка данных и выполнение запросов в кластере Apache Spark в Azure HDInsight.
Общие сведения о наборе данных
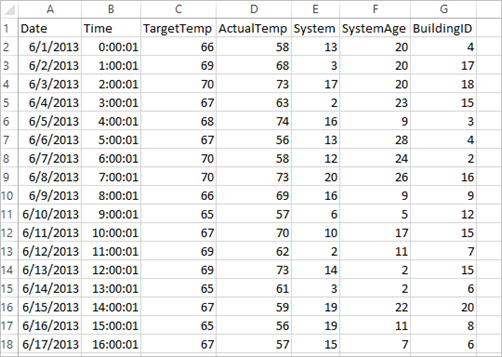
Приложение использует данные из примера файла HVAC.csv, который по умолчанию доступен на всех кластерах. Файл находится в папке \HdiSamples\HdiSamples\SensorSampleData\hvac. Это данные о целевой температуре и фактической температуре некоторых зданий, в которых установлена система кондиционирования воздуха. В столбце System указан идентификатор системы, а в столбце SystemAge — срок эксплуатации системы кондиционирования в годах. Вы можете спрогнозировать, будет ли температура здания выше или ниже относительно целевой температуры на основе идентификатора системы и срока ее эксплуатации.
Разработка приложения машинного обучения Spark с помощью Spark MLlib
В этом приложении используется конвейер машинного обучения Spark для выполнения классификации документов. Конвейеры машинного обучения предоставляют универсальный набор интерфейсов API высокого уровня, построенных на основе DataFrames. DataFrames позволяют создавать и настраивать практичные конвейеры машинного обучения. В конвейере вы разобьете документ на слова, преобразуете слова в вектор числового признака и, наконец, создадите модель прогнозирования с помощью вектора и меток признаков. Выполните следующие действия, чтобы создать приложение.
Создайте записную книжку Jupyter Notebook с помощью ядра PySpark. Инструкции см. в разделе Создание файла записной книжки Jupyter Notebook.
Импортируйте типы, необходимые для этого сценария. Вставьте следующий фрагмент кода в пустую ячейку и нажмите клавиши SHIFT + ВВОД.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayЗагрузите данные (hvac.csv), проанализируйте их и используйте эти данные для обучения модели.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()В фрагменте кода определите функцию, которая сравнивает фактическую температуру с целевой. Если фактическая температура больше, то здание горячее (значение 1.0). В противном случае в здании холодно (значение 0,0).
Настройте конвейер машинного обучения Spark, состоящий из трех этапов:
tokenizerиlrhashingTF.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])См. дополнительные сведения о конвейере машинного обучения Apache Spark и том, как он работает.
Впишите конвейер в документ для обучения.
model = pipeline.fit(training)Проверьте, чтобы в документе для обучения имелась контрольная точка хода выполнения для приложения.
training.show()Выходные данные должны иметь следующий вид:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Сравнение выходных данных со сведениями в необработанном CSV-файле. Например, в первой строке CSV-файла содержатся следующие данные:

Обратите внимание на то, насколько фактическая температура меньше целевой, что свидетельствует о том, что здание холодное. Значение в первой строке столбца label составляет 0,0. Это означает, что в здании не жарко.
Подготовьте набор данных, в отношении которого необходимо выполнить обученную модель. Для этого передайте идентификатор системы и данные о сроке эксплуатации системы (обозначается как SystemInfo в выходных данных обучения). Модель прогнозирует, будет ли здание, оборудованное системой с этим идентификатором и сроком эксплуатации, теплее (значение 1,0) или холоднее (значение 0,0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Наконец, создайте прогнозы на основе тестовых данных.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Выходные данные должны иметь следующий вид:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Изучите первую строку прогноза. При использовании системы кондиционирования с идентификатором 20 и сроком эксплуатации 25 лет температура в здании будет высокая (значение прогноза 1,0). Первое значение параметра DenseVector (0,49999) соответствует прогнозу 0,0, а второе значение (0,5001) — прогнозу 1,0. В выходных данных видно, что, даже если второе значение лишь незначительно выше, модель показывает прогноз = 1.0.
Завершите работу записной книжки для освобождения ресурсов. Для этого в меню File (Файл) записной книжки выберите пункт Close and Halt (Закрыть и остановить). Записная книжка завершит работу и закроется.
Использование библиотеки scikit-learn Anaconda для машинного обучения Spark
Кластеры Apache Spark в HDInsight включают библиотеки Anaconda. Они также включают библиотеку scikit-learn для машинного обучения. Кроме того, библиотека включает различные наборы данных, которые можно использовать для создания примеров приложений прямо в записной книжке Jupyter Notebook. Примеры использования библиотеки scikit-learn см. здесь: https://scikit-learn.org/stable/auto_examples/index.html.
Очистка ресурсов
Если вы не собираетесь использовать это приложение в дальнейшем, удалите созданный кластер, сделав следующее:
Войдите на портал Azure.
В поле Поиск в верхней части страницы введите HDInsight.
Выберите Кластеры HDInsight в разделе Службы.
В списке кластеров HDInsight, который отобразится, выберите ... рядом с кластером, созданным при работе с этим учебником.
Выберите команду Удалить. Выберите Да.
Следующие шаги
Из этого руководства вы узнали, как с помощью Jupyter Notebook создать приложение машинного обучения Apache Spark для Azure HDInsight. Перейдите к следующему руководству, чтобы научиться использовать IntelliJ IDEA для заданий Spark.