Modeller för dokumentbearbetning
Viktigt!
- Versioner av den offentliga förhandsversionen av Document Intelligence ger tidig åtkomst till funktioner som är i aktiv utveckling. Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
- Den offentliga förhandsversionen av Dokumentinformationsklientbiblioteken är som standard REST API version 2024-07-31-preview.
- Den offentliga förhandsversionen 2024-07-31-preview är för närvarande endast tillgänglig i följande Azure-regioner. Observera att modellen för anpassad generativ (extrahering av dokumentfält) i AI Studio endast är tillgänglig i regionen USA, norra centrala:
- USA, östra
- USA, västra 2
- Europa, västra
- USA, norra centrala
Det här innehållet gäller för: ![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Det här innehållet gäller för: ![]() v3.1 (GA) | Senaste version:
v3.1 (GA) | Senaste version:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner: ![]() v3.0
v3.0![]() v2.1
v2.1
Det här innehållet gäller för: ![]() v3.0 (GA) | Senaste versioner:
v3.0 (GA) | Senaste versioner: ![]() v4.0 (förhandsversion)
v4.0 (förhandsversion) ![]() v3.1 | Tidigare version:
v3.1 | Tidigare version: ![]() v2.1
v2.1
Det här innehållet gäller för: ![]() v2.1 | Senaste version:
v2.1 | Senaste version: ![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)
Azure AI Document Intelligence stöder en mängd olika modeller som gör att du kan lägga till intelligent dokumentbearbetning i dina appar och flöden. Du kan använda en fördefinierad domänspecifik modell eller träna en anpassad modell som är anpassad efter dina specifika affärsbehov och användningsfall. Dokumentinformation kan användas med REST-API:et eller Python-, C#-, Java- och JavaScript-klientbiblioteken.
Kommentar
- Dokumentbearbetningsprojekt som omfattar finansiella data, skyddade hälsodata, personuppgifter eller mycket känsliga data kräver noggrann uppmärksamhet.
- Se till att uppfylla alla nationella/regionala och branschspecifika krav.
Översikt över modell
I följande tabell visas tillgängliga modeller för varje aktuell förhandsversion och ett stabilt API:
| Modelltyp | Modell | • 2024-02-29-preview • 2023-10-31-preview |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Modeller för dokumentanalys | Läs | ✔️ | ✔️ | ✔️ | saknas |
| Modeller för dokumentanalys | Layout | ✔️ | ✔️ | ✔️ | ✔️ |
| Modeller för dokumentanalys | Allmänt dokument | har flyttats till layout** | ✔️ | ✔️ | saknas |
| Inbyggda modeller | Bankkontroll | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Kontoutdrag | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Paystub | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Kontrakt | ✔️ | ✔️ | saknas | saknas |
| Inbyggda modeller | Sjukförsäkringskort | ✔️ | ✔️ | ✔️ | saknas |
| Inbyggda modeller | ID-dokument | ✔️ | ✔️ | ✔️ | ✔️ |
| Inbyggda modeller | Faktura | ✔️ | ✔️ | ✔️ | ✔️ |
| Inbyggda modeller | Kvitto | ✔️ | ✔️ | ✔️ | ✔️ |
| Inbyggda modeller | Enhetlig skatt för USA* | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | US 1040 Tax* | ✔️ | ✔️ | saknas | saknas |
| Inbyggda modeller | US 1098 Tax* | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | US 1099 Tax* | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | US W2-skatt | ✔️ | ✔️ | ✔️ | saknas |
| Inbyggda modeller | US Mortgage 1003 URLA | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | US Mortgage 1004 URAR | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | US Mortgage 1005 | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Us Mortgage 1008 Sammanfattning | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Information om stängning av amerikanska hypotekslån | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Vigselbevis | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Kreditkort | ✔️ | saknas | n/a | saknas |
| Inbyggda modeller | Visitkort | inaktuell | ✔️ | ✔️ | ✔️ |
| Anpassad klassificeringsmodell | Anpassad klassificerare | ✔️ | ✔️ | saknas | saknas |
| Anpassad generativ modell | Anpassad generativ modell | ✔️ | saknas | n/a | saknas |
| Anpassad extraheringsmodell | Anpassad neural | ✔️ | ✔️ | ✔️ | saknas |
| Customextraction-modell | Anpassad mall | ✔️ | ✔️ | ✔️ | ✔️ |
| Anpassad extraheringsmodell | Anpassad sammansatt | ✔️ | ✔️ | ✔️ | ✔️ |
| Alla modeller | Tilläggsfunktioner | ✔️ | ✔️ | saknas | saknas |
* - Innehåller undermodeller. Se modellspecifik information för varianter och undertyper som stöds.
Svarstid
Svarstiden är den tid det tar för en API-server att hantera och bearbeta en inkommande begäran och leverera det utgående svaret till klienten. Tiden för att analysera ett dokument beror på storleken (till exempel antalet sidor) och de associerade innehållet på varje sida. Dokumentinformation är en tjänst med flera klientorganisationer där svarstiden för liknande dokument är jämförbar men inte alltid identisk. Enstaka variationer i svarstid och prestanda är en naturlig del av alla mikrotjänstbaserade, tillståndslösa, asynkrona tjänster som bearbetar bilder och stora dokument i stor skala. Även om vi kontinuerligt skalar upp maskinvaru- och kapacitets- och skalningsfunktionerna kan du fortfarande ha problem med svarstiden vid körning.
| Tilläggsfunktion | Tillägg/kostnadsfritt | • 2024-02-29-preview &punkt [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-v4.0%20(2024-07-31-preview)&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Extrahering av teckensnittsegenskap | Tillägg | ✔️ | ✔️ | saknas | saknas |
| Formelextrahering | Tillägg | ✔️ | ✔️ | saknas | saknas |
| Högupplösningsextrahering | Tillägg | ✔️ | ✔️ | saknas | saknas |
| Extrahering av streckkod | Kostnadsfri | ✔️ | ✔️ | saknas | saknas |
| Språkidentifiering | Kostnadsfri | ✔️ | ✔️ | saknas | saknas |
| Nyckelvärdepar | Kostnadsfri | ✔️ | saknas | n/a | saknas |
| Frågefält | Tillägg* | ✔️ | saknas | n/a | saknas |
| Sökbar pdf | Tillägg* | ✔️ | saknas | n/a | saknas |
Modellanalysfunktioner
| Model ID | Extrahering av innehåll | Frågefält | Punkterna | Styckeroller | Markeringsmarkeringar | Tabeller | Nyckel/värde-par | Språk | Streckkoder | Dokumentanalys | Formler* | Formatmallsteckensnitt* | Högupplöst* | Sökbar PDF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| prebuilt-read | ✓ | O | O | O | O | O | ✓ | |||||||
| fördefinierad layout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |||
| prebuilt-document | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| prebuilt-businessCard | ✓ | ✓ | ✓ | |||||||||||
| prebuilt-contract | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| fördefinierad faktura | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
| fördefinierad kvitto | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-check.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-payStub.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-bankStatement | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1004 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1005 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099(variationer) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1040(variations) | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
√ - Aktiverad
O - Valfritt
* - Premium-funktioner medför extra kostnader
Tillägg* – Frågefält prissätts på ett annat sätt än de andra tilläggsfunktionerna. Mer information finns i priser .
Avgränsningslåda och polygonkoordinater
En avgränsningsruta (polygon i v3.0 och senare versioner) är en abstrakt rektangel som omger textelement i ett dokument som används som referenspunkt för objektidentifiering.
Avgränsningsrutan anger position med hjälp av ett x- och y-koordinatplan som visas i en matris med fyra numeriska par. Varje par representerar ett hörn av rutan i följande ordning: övre vänstra, övre högra, nedre högra, nedre vänstra.
Bildkoordinater visas i bildpunkter. För en PDF visas koordinater i tum.
För alla modeller, förutom visitkortsmodell, stöder Document Intelligence nu tilläggsfunktioner för att möjliggöra mer avancerad analys. Dessa valfria funktioner kan aktiveras och inaktiveras beroende på scenariot med dokumentextraheringen. Det finns sju tillgängliga tilläggsfunktioner för 2023-07-31 (GA) och senare API-version:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax modelssearchablePDF(2024-07-31-preview)Only available for Read Model
Språkstöd
De djupinlärningsbaserade universella modellerna i Dokumentinformation stöder många språk som kan extrahera flerspråkig text från dina bilder och dokument, inklusive textrader med blandade språk. Språkstöd varierar beroende på funktionerna i Document Intelligence-tjänsten. En fullständig lista finns i följande artiklar:
- Språkstöd: modeller för dokumentanalys
- Språkstöd: fördefinierade modeller
- Språkstöd: anpassade modeller
Regional tillgänglighet
Dokumentinformation är allmänt tillgänglig i många av de 60+ globala infrastrukturregionerna i Azure.
Mer information finns på sidan med azure-geografiska områden som hjälper dig att välja den region som passar dig och dina kunder bäst.
Modellinformation
I det här avsnittet beskrivs de utdata som du kan förvänta dig av varje modell. Du kan utöka utdata för de flesta modeller med tilläggsfunktioner.
Läsa OCR

Läs-API:et analyserar och extraherar rader, ord, deras platser, identifierade språk och handskriven stil om det identifieras.
Exempeldokument som bearbetas med hjälp av Document Intelligence Studio:
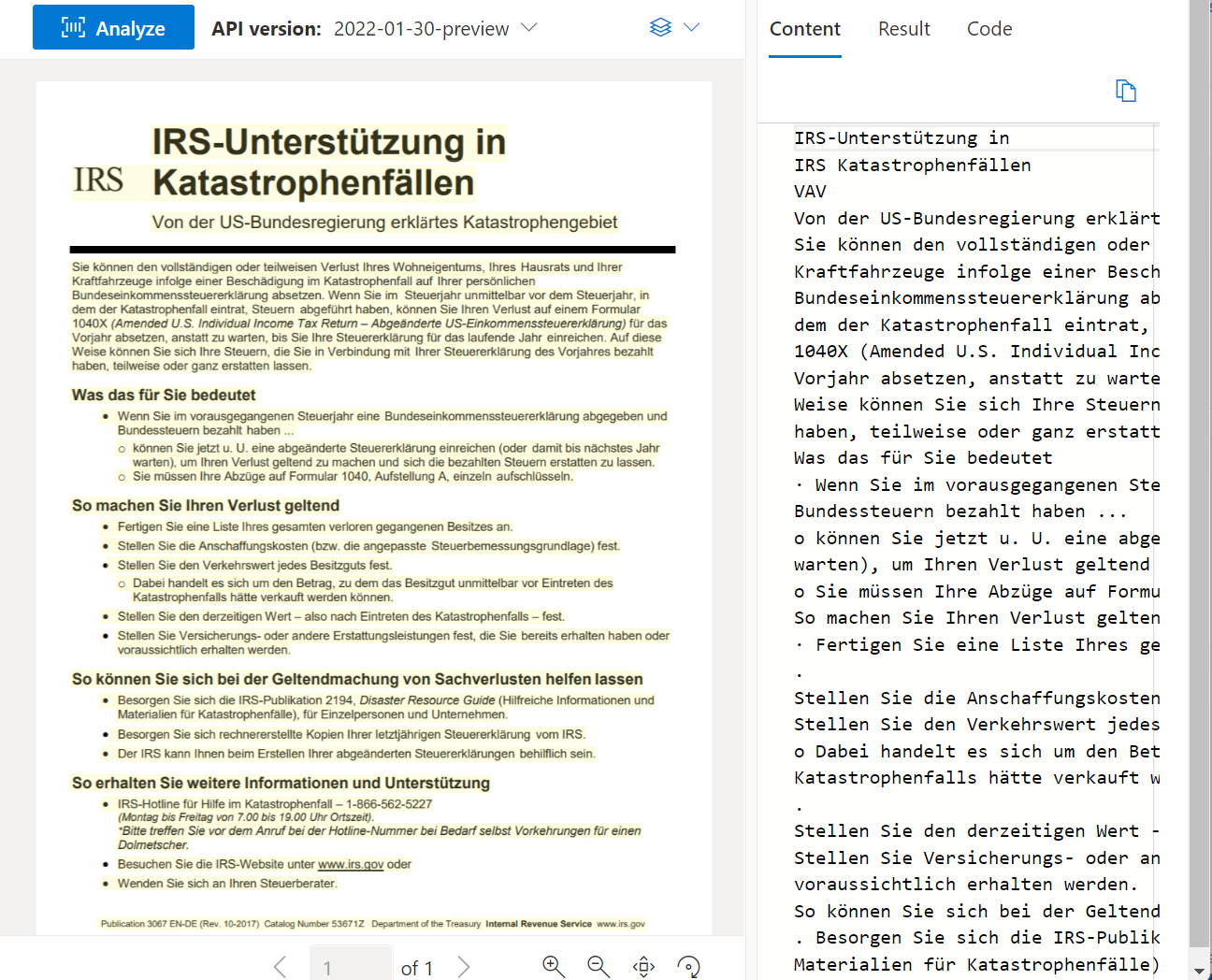
Layoutanalys

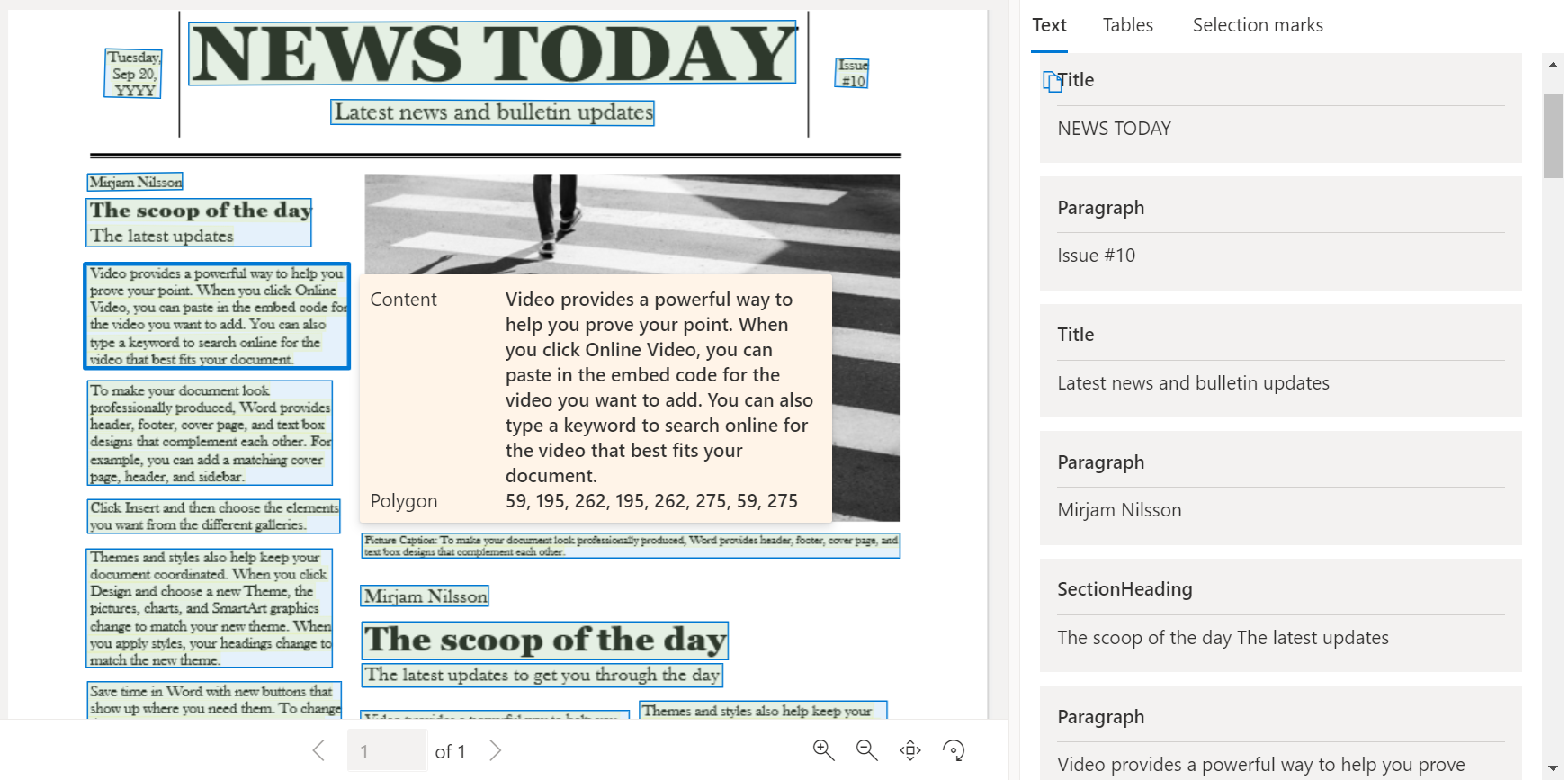
Analysmodellen Layout analyserar och extraherar text, tabeller, markeringsmarkeringar och andra strukturelement som rubriker, avsnittsrubriker, sidhuvuden, sidfötter med mera.
Exempeldokument som bearbetas med hjälp av Document Intelligence Studio:
Sjukförsäkringskort
![]()
Sjukförsäkringskortmodellen kombinerar kraftfulla OCR-funktioner (Optisk teckenigenkänning) med djupinlärningsmodeller för att analysera och extrahera viktig information från amerikanska sjukförsäkringskort.
Exempel på amerikanskt sjukförsäkringskort som bearbetas med Document Intelligence Studio:

Amerikanska skattedokument

De amerikanska skattedokumentmodellerna analyserar och extraherar nyckelfält och radobjekt från en utvald grupp med skattedokument. API:et stöder analys av engelskspråkiga amerikanska skattedokument av olika format och kvalitet, inklusive telefoninsamlade bilder, skannade dokument och digitala PDF-filer. Följande modeller stöds för närvarande:
| Modell | beskrivning | ModelID |
|---|---|---|
| US Tax W-2 | Extrahera information om beskattningsbar kompensation. | prebuilt-tax.us.w2 |
| Amerikansk skatt 1040 | Extrahera information om bolåneräntor. | prebuilt-tax.us.1040(variations) |
| Amerikansk skatt 1098 | Extrahera information om bolåneräntor. | prebuilt-tax.us.1098(variationer) |
| Amerikansk skatt 1099 | Utvinna inkomster från andra källor än arbetsgivaren. | prebuilt-tax.us.1099(variationer) |
Exempel på W-2-dokument som bearbetas med Document Intelligence Studio:
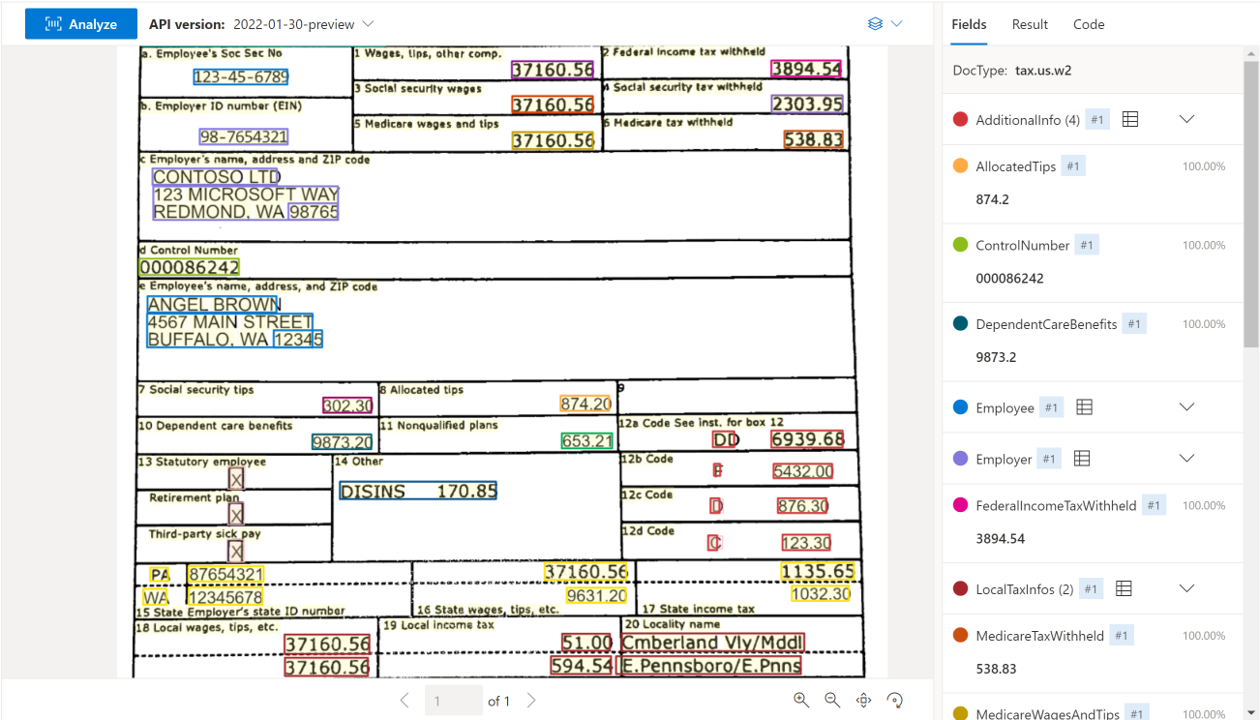
Amerikanska inteckningsdokument

De amerikanska inteckningsdokumentmodellerna analyserar och extraherar viktiga fält, inklusive låntagare, lån och egendomsinformation från en utvald grupp av inteckningsdokument. API:et stöder analys av engelskspråkiga amerikanska inteckningsdokument av olika format och kvalitet, inklusive telefoninsamlade bilder, skannade dokument och digitala PDF-filer. Följande modeller stöds för närvarande:
| Modell | beskrivning | ModelID |
|---|---|---|
| 1003 Licensavtal för slutanvändare (EULA) | Extrahera lån, låntagare, fastighetsinformation. | prebuilt-mortgage.us.1003 |
| Sammanfattningsdokument för 1008 | Extrahera låntagare, säljare, egendom, inteckning och försäkringsinformation. | prebuilt-mortgage.us.1008 |
| Avslutande avslöjande | Extrahera stängning, transaktionskostnader och låneinformation. | prebuilt-mortgage.us.closingDisclosure |
| Vigselbevis | Extrahera information om äktenskap för gemensamma lånesökande. | prebuilt-marriageCertificate |
| US Tax W-2 | Extrahera information om beskattningsbar kompensation för inkomstverifiering. | prebuilt-tax.us.w2 |
Exempel på dokument för avslutande av avslöjande som bearbetas med Document Intelligence Studio:
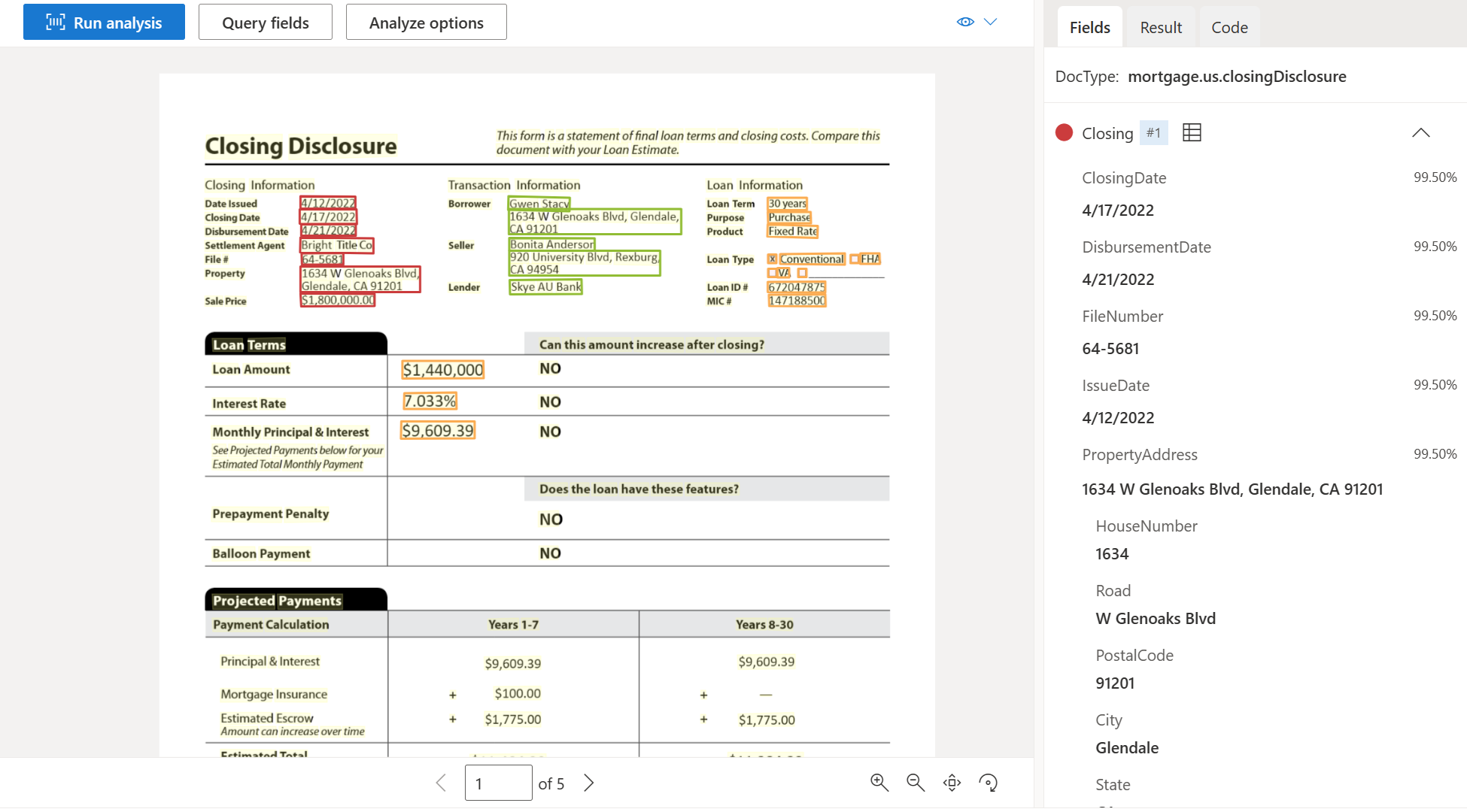
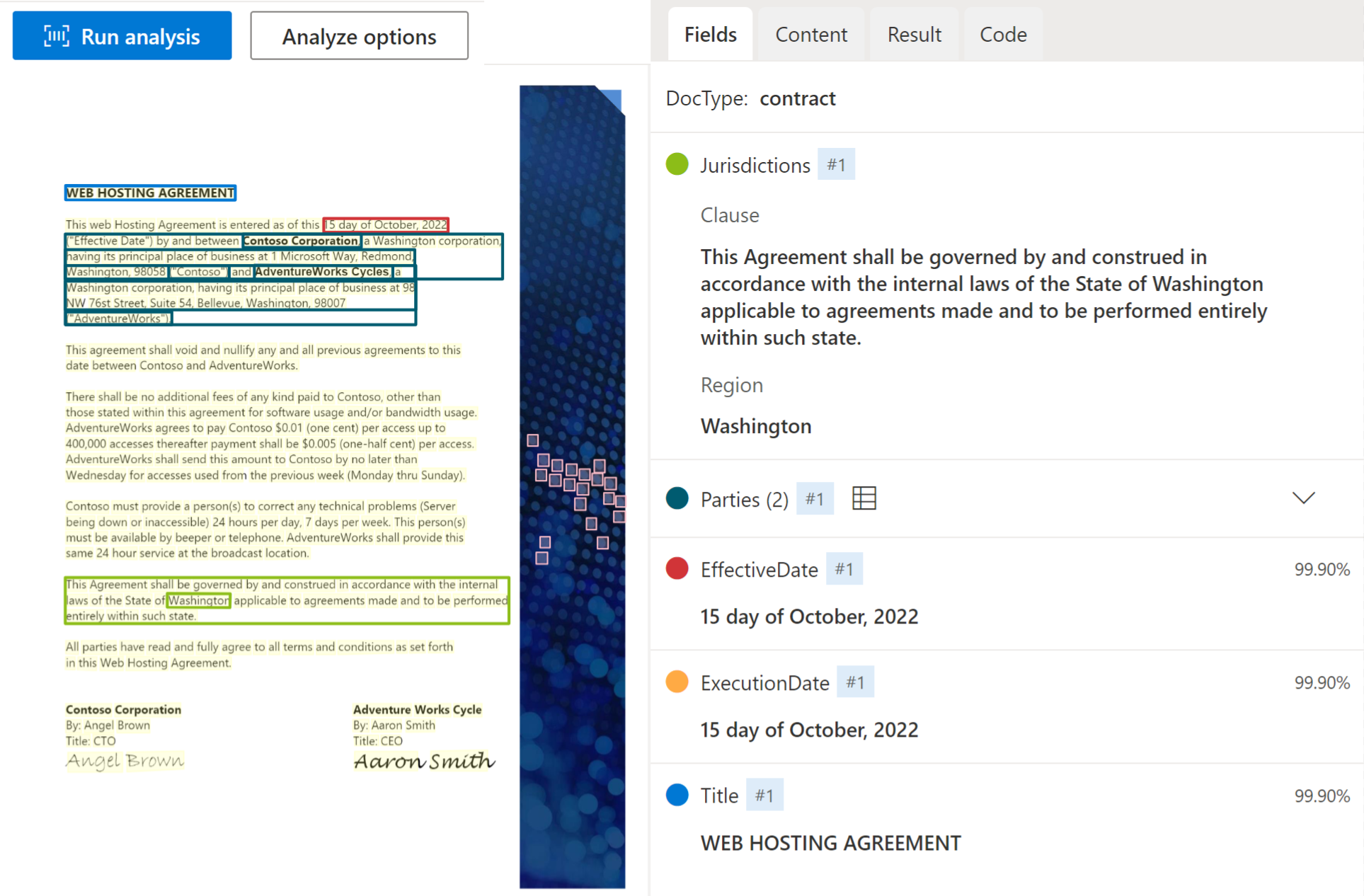
Contract
![]()
Kontraktsmodellen analyserar och extraherar nyckelfält och radobjekt från avtalsavtal, inklusive parter, jurisdiktioner, kontrakts-ID och titel. Modellen stöder för närvarande engelskspråkiga kontraktsdokument.
Exempelkontrakt som bearbetas med Document Intelligence Studio:
Faktura

Fakturamodellen automatiserar bearbetningen av fakturor för att extrahera kundens namn, faktureringsadress, förfallodatum och förfallodatum, radobjekt och andra nyckeldata. För närvarande stöder modellen fakturor på engelska, spanska, tyska, franska, italienska, portugisiska och nederländska.
Exempelfaktura som bearbetas med Document Intelligence Studio:

Kvitto

Använd kvittomodellen för att skanna försäljningskvitton efter försäljningsnamn, datum, radobjekt, kvantiteter och summor från tryckta och handskrivna kvitton. Version v3.0 stöder också ensidesbehandling av hotellkvitton.
Exempelkvitto som bearbetas med Document Intelligence Studio:

Identitetsdokument (ID)

Använd ID-modellen (ID) för att bearbeta amerikanska körkort (alla 50 delstater och District of Columbia) och biografiska sidor från internationella pass (exklusive visum och andra resedokument) för att extrahera nyckelfält.
Exempel på U.S. Driver's License som bearbetas med Document Intelligence Studio:

Vigselbevis
![]()
Använd modellen för äktenskapscertifikat för att bearbeta amerikanska äktenskapscertifikat för att extrahera nyckelfält, inklusive individer, datum och plats.
Exempel på amerikanskt äktenskapscertifikat som bearbetas med Document Intelligence Studio:

Kreditkort
![]()
Använd kreditkortsmodellen för att bearbeta kredit- och debetkort för att extrahera nyckelfält.
Exempel på kreditkort som bearbetas med Document Intelligence Studio:

Anpassade modeller

Anpassade modeller kan klassificeras brett i två typer. Anpassade klassificeringsmodeller som stöder klassificering av en "dokumenttyp" och anpassade extraheringsmodeller som kan extrahera ett definierat schema från en viss dokumenttyp.
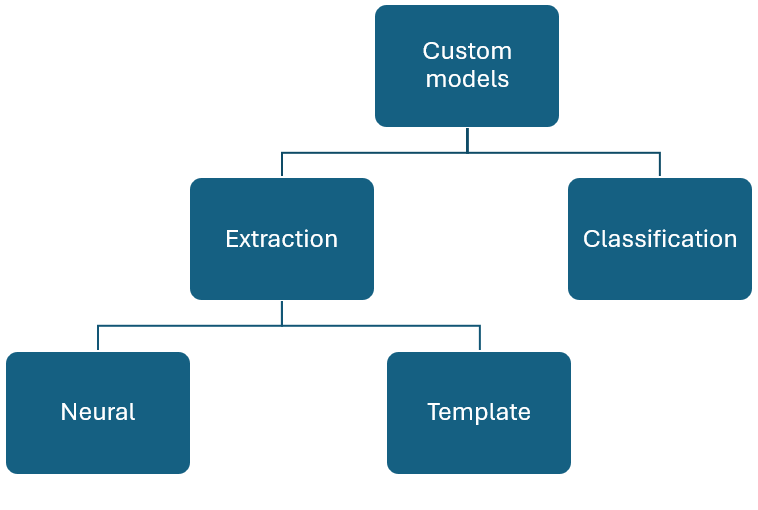
Anpassade dokumentmodeller analyserar och extraherar data från formulär och dokument som är specifika för din verksamhet. De känner igen formulärfält i ditt distinkta innehåll och extraherar nyckel/värde-par och tabelldata. Du behöver bara ett exempel på formulärtypen för att komma igång.
Version v3.0 och senare anpassade modeller stöder signaturidentifiering i anpassade mallar (formulär) och korssidetabeller i både mallar och neurala modeller. Signaturidentifiering söker efter förekomsten av en signatur, inte identiteten för den person som signerar dokumentet. Om modellen returnerar osignerad för signaturidentifiering hittade modellen ingen signatur i det definierade fältet.
Exempel på anpassad mall som bearbetas med Document Intelligence Studio:
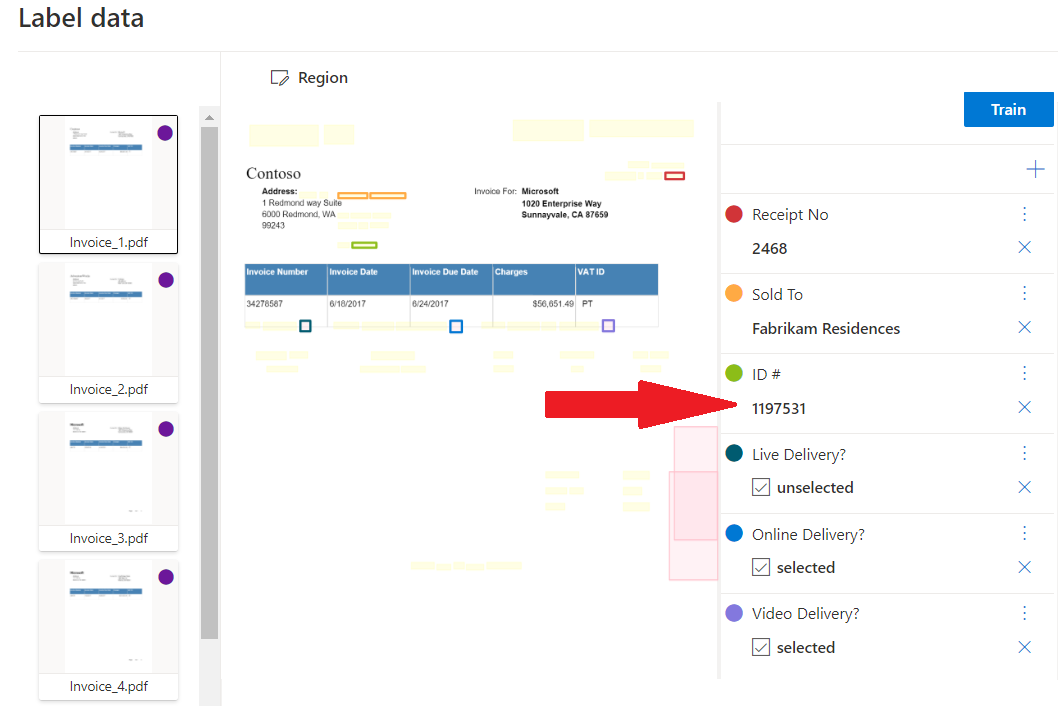
Anpassad extrahering

Anpassad extraheringsmodell kan vara en av två typer, anpassad mall eller anpassad neural. Skapa en anpassad extraheringsmodell genom att märka en datamängd med dokument med de värden som du vill extrahera och träna modellen på den märkta datamängden. Du behöver bara fem exempel av samma formulär- eller dokumenttyp för att komma igång.
Exempel på anpassad extrahering som bearbetas med Document Intelligence Studio:

Anpassad klassificerare

Med den anpassade klassificeringsmodellen kan du identifiera dokumenttypen innan du anropar extraheringsmodellen. Klassificeringsmodellen är tillgänglig från och med API:et 2023-07-31 (GA) . Träning av en anpassad klassificeringsmodell kräver minst två distinkta klasser och minst fem exempel per klass.
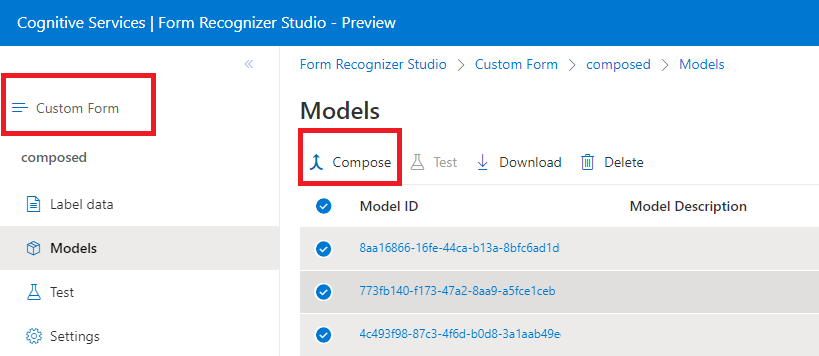
Sammansatta modeller
En sammansatt modell skapas genom att ta en samling anpassade modeller och tilldela dem till en enda modell som skapats från dina formulärtyper. Du kan tilldela flera anpassade modeller till en sammansatt modell som heter med ett enda modell-ID. Du kan tilldela upp till 200 tränade anpassade modeller till en enda sammansatt modell.
Dialogrutan Skapad modell i Document Intelligence Studio:
Indatakrav
Filformat som stöds:
Modell PDF Bild: JPEG/JPG,PNG,BMP, ,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLästa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för betald (S0) nivå och
4MB för den kostnadsfria nivån (F0).Bilddimensioner måste vara mellan 50 bildpunkter x 50 bildpunkter och 10 000 bildpunkter x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar om
8punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och
1GB för den neurala modellen.För anpassad klassificeringsmodellträning är
1den totala storleken på träningsdata GB med högst 10 000 sidor. För förhandsversionen 2024-07-31 och senare är2den totala storleken på träningsdata GB med högst 10 000 sidor.
Kommentar
Verktyget Exempeletiketter stöder inte BMP-filformatet. Det här är en begränsning för verktyget, inte dokumentunderrättelsetjänsten.
Versionsmigrering
Lär dig hur du använder Document Intelligence v3.0 i dina program genom att följa migreringsguiden för Document Intelligence v3.1
| Modell | Beskrivning |
|---|---|
| Dokumentanalys | |
| Layout | Extrahera text- och layoutinformation från dokument. |
| Fördefinierad | |
| Faktura | Extrahera viktig information från fakturor på engelska och spanska. |
| Kvitto | Extrahera viktig information från engelska kvitton. |
| ID-dokument | Extrahera viktig information från amerikanska körkort och internationella pass. |
| Visitkort | Extrahera viktig information från engelska visitkort. |
| Egen | |
| Egen | Extrahera data från formulär och dokument som är specifika för ditt företag. Anpassade modeller tränas för dina distinkta data och användningsfall. |
| Lugn | Skapa en samling anpassade modeller och tilldela dem till en enda modell som skapats från dina formulärtyper. |
Layout
Layout-API:et analyserar och extraherar text, tabeller och rubriker, markeringsmarkeringar och strukturinformation från dokument.
Exempeldokument som bearbetas med hjälp av verktyget Exempeletiketter:
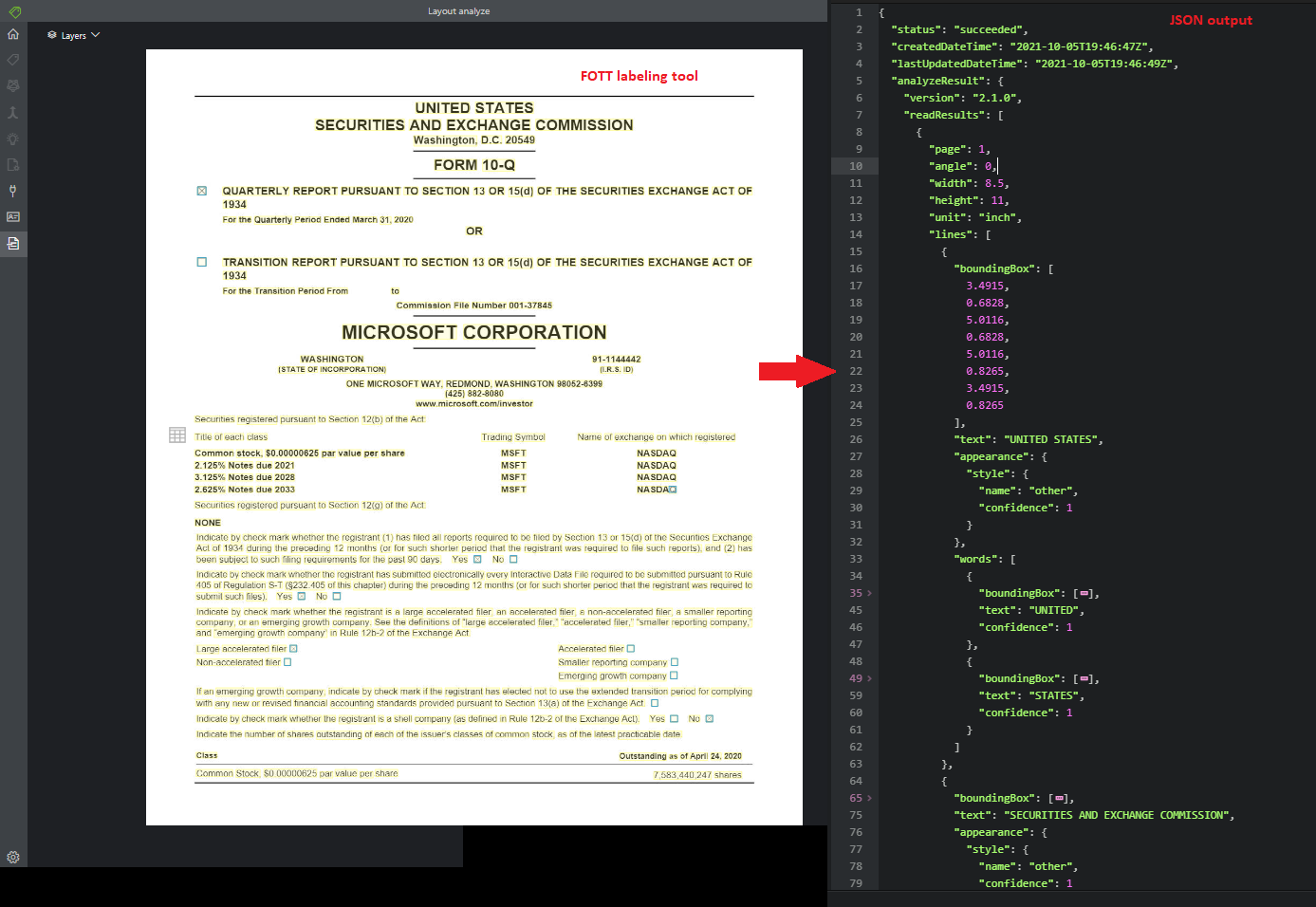
Faktura
Fakturamodellen analyserar och extraherar viktig information från försäljningsfakturor. API:et analyserar fakturor i olika format och extraherar viktig information, till exempel kundnamn, faktureringsadress, förfallodatum och förfallobelopp.
Exempelfaktura som bearbetas med hjälp av verktyget Exempeletiketter:

Kvitto
- Kvittomodellen analyserar och extraherar viktig information från tryckta och handskrivna försäljningskvitton.
Exempelkvitto som bearbetas med hjälp av exempeletikettverktyget:
ID-dokument
ID-dokumentmodellen analyserar och extraherar viktig information från följande dokument:
Amerikanska körkort (alla 50 delstater och District of Columbia)
Biografiska sidor från internationella pass (exklusive visum och andra resehandlingar). API:et analyserar identitetsdokument och extraherar
Exempel på U.S. Driver's License som bearbetas med hjälp av exempeletikettverktyget:
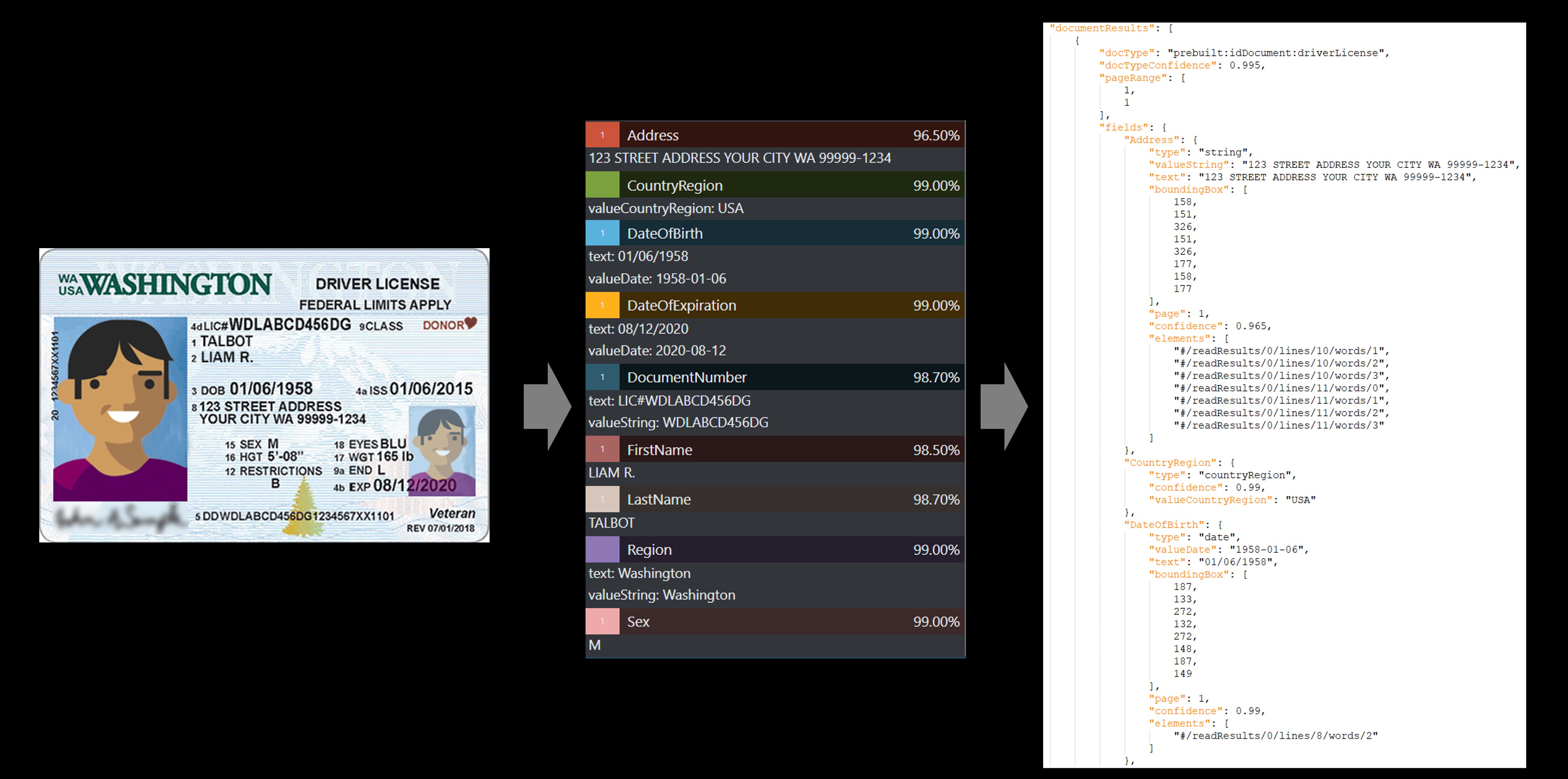
Visitkort
Visitkortsmodellen analyserar och extraherar viktig information från visitkortsbilder.
Exempel på visitkort som bearbetas med hjälp av verktyget Exempeletiketter:
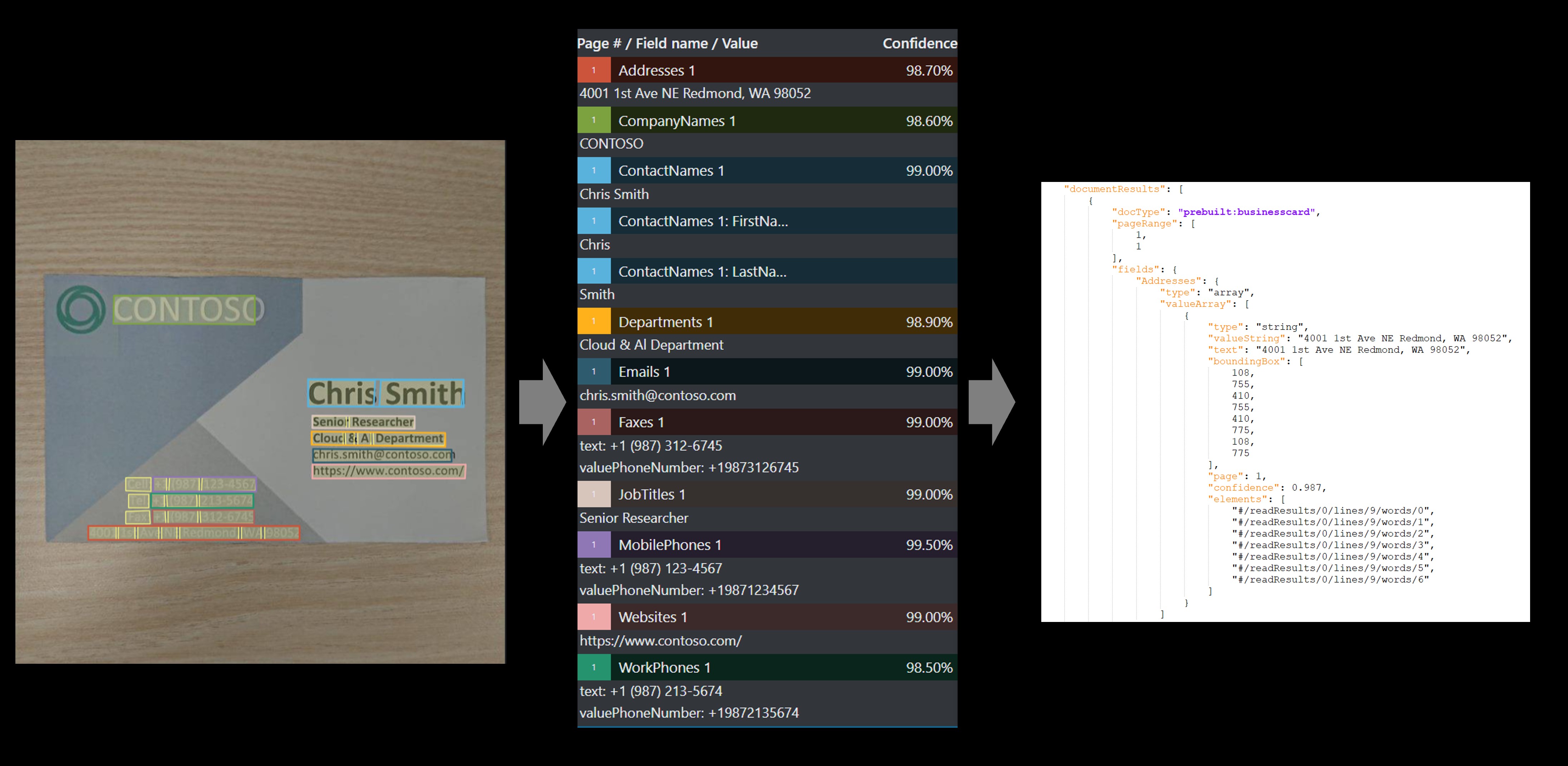
Anpassat
- Anpassade modeller analyserar och extraherar data från formulär och dokument som är specifika för din verksamhet. API:et är ett maskininlärningsprogram som tränats att identifiera formulärfält i ditt distinkta innehåll och extrahera nyckel/värde-par och tabelldata. Du behöver bara fem exempel av samma formulärtyp för att komma igång och din anpassade modell kan tränas med eller utan etiketterade datauppsättningar.
Exempel på anpassad modellbearbetning med hjälp av exempeletikettverktyget:
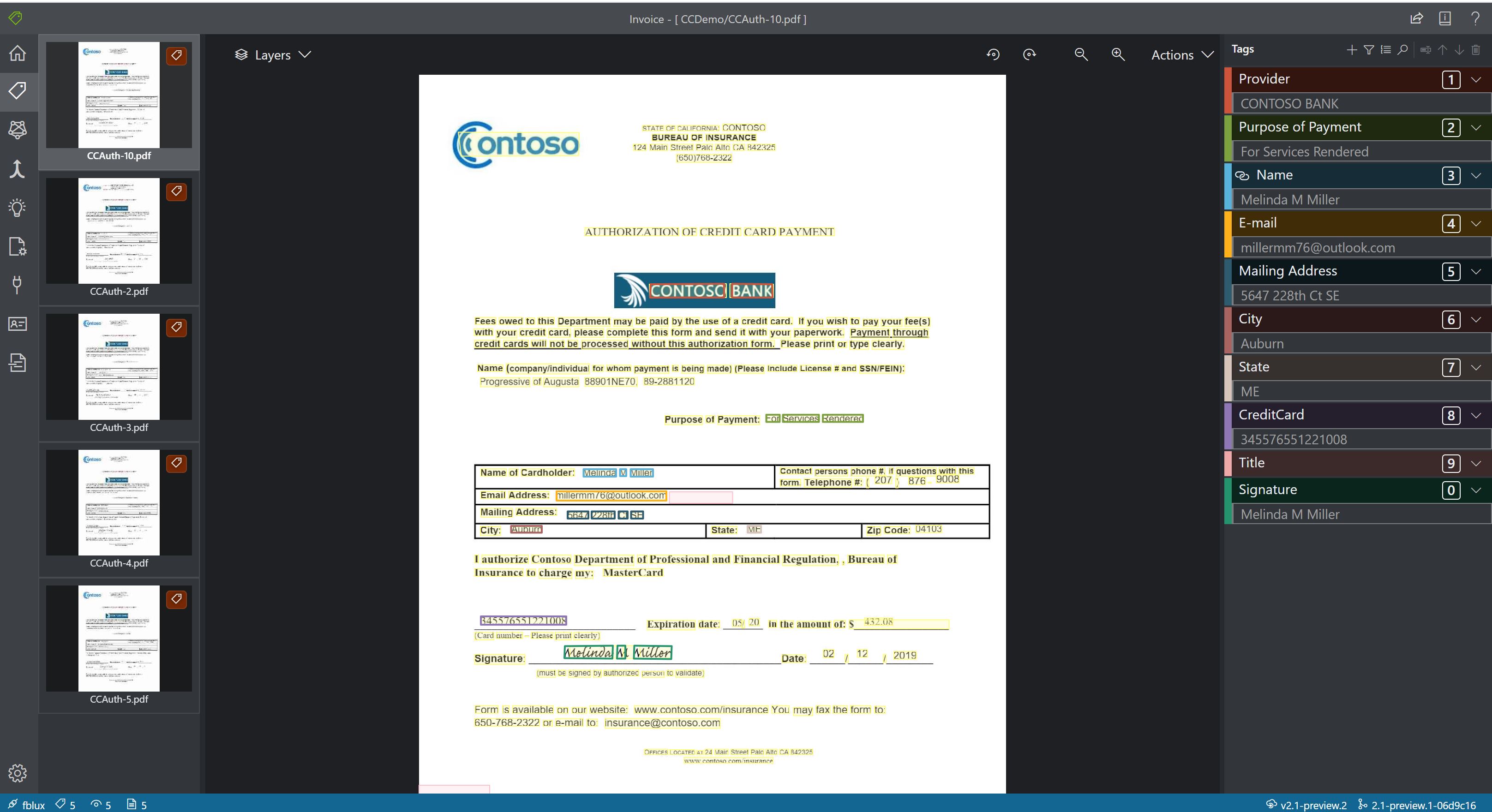
Skapad anpassad modell
En sammansatt modell skapas genom att ta en samling anpassade modeller och tilldela dem till en enda modell som skapats från dina formulärtyper. Du kan tilldela flera anpassade modeller till en sammansatt modell som heter med ett enda modell-ID. Du kan tilldela upp till 100 tränade anpassade modeller till en enda sammansatt modell.
Dialogrutan Skapad modell med hjälp av verktyget Exempeletiketter:
Extrahering av modelldata
| Modell | Extrahering av text | Språkidentifiering | Markeringsmarkeringar | Tabeller | Punkterna | Styckeroller | Nyckel/värde-par | Fält |
|---|---|---|---|---|---|---|---|---|
| Layout | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Faktura | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Kvitto | ✓ | ✓ | ✓ | |||||
| ID-dokument | ✓ | ✓ | ✓ | |||||
| Visitkort | ✓ | ✓ | ✓ | |||||
| Anpassat formulär | ✓ | ✓ | ✓ | ✓ | ✓ |
Indatakrav
Filformat som stöds:
Modell PDF Bild: JPEG/JPG,PNG,BMP, ,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLästa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för betald (S0) nivå och
4MB för den kostnadsfria nivån (F0).Bilddimensioner måste vara mellan 50 bildpunkter x 50 bildpunkter och 10 000 bildpunkter x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar om
8punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och
1GB för den neurala modellen.För anpassad klassificeringsmodellträning är
1den totala storleken på träningsdata GB med högst 10 000 sidor. För förhandsversionen 2024-07-31 och senare är2den totala storleken på träningsdata GB med högst 10 000 sidor.
Kommentar
Verktyget Exempeletiketter stöder inte BMP-filformatet. Det här är en begränsning för verktyget, inte dokumentunderrättelsetjänsten.
Versionsmigrering
Du kan lära dig hur du använder Document Intelligence v3.0 i dina program genom att följa migreringsguiden för Document Intelligence v3.1
Nästa steg
Prova att bearbeta dina egna formulär och dokument med Document Intelligence Studio.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.
Prova att bearbeta dina egna formulär och dokument med verktyget Exempeletiketter för dokumentinformation.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.