Azure Storage-provider (Azure Functions)
Det här dokumentet beskriver egenskaperna hos Durable Functions Azure Storage-providern med fokus på prestanda- och skalbarhetsaspekter. Azure Storage-providern är standardprovidern. Den lagrar instanstillstånd och köer i ett Azure Storage-konto (klassiskt).
Kommentar
Mer information om lagringsprovidrar som stöds för Durable Functions och hur de jämförs finns i dokumentationen om Durable Functions-lagringsproviders .
I Azure Storage-providern drivs all funktionskörning av Azure Storage-köer. Orkestrerings- och entitetsstatus och -historik lagras i Azure-tabeller. Azure Blobs och bloblån används för att distribuera orkestreringsinstanser och entiteter över flera appinstanser (kallas även arbetare eller helt enkelt virtuella datorer). Det här avsnittet går in mer detaljerat på de olika Azure Storage-artefakterna och hur de påverkar prestanda och skalbarhet.
Lagringsrepresentation
En aktivitetshubb bevarar korrekt alla instanstillstånd och alla meddelanden. En snabb översikt över hur dessa används för att spåra förloppet för en orkestrering finns i körningsexemplet för aktivitetshubben.
Azure Storage-providern representerar uppgiftshubben i lagringen med hjälp av följande komponenter:
- Mellan två och tre Azure-tabeller. Två tabeller används för att representera historier och instanstillstånd. Om Table Partition Manager är aktiverat introduceras en tredje tabell för att lagra partitionsinformation.
- En Azure Queue lagrar aktivitetsmeddelandena.
- En eller flera Azure Queues lagrar instansmeddelandena. Var och en av dessa så kallade kontrollköer representerar en partition som tilldelas en delmängd av alla instansmeddelanden, baserat på hashen för instans-ID:t.
- Några extra blobcontainrar som används för låneblobar och/eller stora meddelanden.
Till exempel innehåller en aktivitetshubb med namnet xyz med PartitionCount = 4 följande köer och tabeller:

Därefter beskriver vi dessa komponenter och vilken roll de spelar mer detaljerat.
Historiktabell
Tabellen Historik är en Azure Storage-tabell som innehåller historikhändelser för alla orkestreringsinstanser i en aktivitetshubb. Namnet på den här tabellen finns i formatet TaskHubName-historik. När instanser körs läggs nya rader till i den här tabellen. Partitionsnyckeln i den här tabellen härleds från instans-ID:t för orkestreringen. Instans-ID:t är slumpmässiga som standard, vilket säkerställer optimal distribution av interna partitioner i Azure Storage. Radnyckeln för den här tabellen är ett sekvensnummer som används för att sortera historikhändelserna.
När en orkestreringsinstans behöver köras läses motsvarande rader i tabellen Historik in i minnet med hjälp av en intervallfråga i en enda tabellpartition. Dessa historikhändelser spelas sedan upp i orchestrator-funktionskoden för att få tillbaka den till dess tidigare kontrollpunktstillstånd. Användningen av körningshistorik för att återskapa tillståndet på det här sättet påverkas av mönstret Händelsekällor.
Dricks
Orkestreringsdata som lagras i tabellen Historik innehåller utdatanyttolaster från aktivitets- och underorkestreringsfunktioner. Nyttolaster från externa händelser lagras också i tabellen Historik. Eftersom den fullständiga historiken läses in i minnet varje gång en orkestrerare behöver köras kan en tillräckligt stor historik leda till betydande minnesbelastning på en viss virtuell dator. Orkestreringshistorikens längd och storlek kan minskas genom att stora orkestreringar delas upp i flera underorkestreringar eller genom att minska storleken på utdata som returneras av aktiviteten och de underorkestreringsfunktioner som den anropar. Du kan också minska minnesanvändningen genom att sänka samtidighetsbegränsningen per virtuell dator för att begränsa hur många orkestreringar som läses in i minnet samtidigt.
Instanstabell
Tabellen Instances innehåller status för alla orkestrerings- och entitetsinstanser i en aktivitetshubb. När instanser skapas läggs nya rader till i den här tabellen. Partitionsnyckeln i den här tabellen är orkestreringsinstansens ID eller entitetsnyckel och radnyckeln är en tom sträng. Det finns en rad per orkestrering eller entitetsinstans.
Den här tabellen används för att uppfylla instansfrågeförfrågningar från kod samt HTTP API-anrop för statusfråga. Den hålls så småningom konsekvent med innehållet i tabellen Historik som nämnts tidigare. Användningen av en separat Azure Storage-tabell för att effektivt uppfylla instansfrågeåtgärder på det här sättet påverkas av mönstret CQRS (Command and Query Responsibility Segregation).
Dricks
Partitioneringen av tabellen Instances gör att den kan lagra miljontals orkestreringsinstanser utan någon märkbar inverkan på körningsprestanda eller skala. Antalet instanser kan dock ha en betydande inverkan på frågeprestanda för flera instanser. Om du vill kontrollera mängden data som lagras i dessa tabeller bör du överväga att regelbundet rensa gamla instansdata.
Partitionstabell
Kommentar
Den här tabellen visas endast i aktivitetshubben när Table Partition Manager den är aktiverad. Om du vill tillämpa den konfigurerar du useTablePartitionManagement inställningen i appens host.json.
Tabellen Partitioner lagrar status för partitioner för Durable Functions-appen och används för att distribuera partitioner mellan appens arbetare. Det finns en rad per partition.
Köer
Orchestrator-, entitets- och aktivitetsfunktioner utlöses alla av interna köer i funktionsappens aktivitetshubb. Om du använder köer på det här sättet får du tillförlitliga "minst en gång"-meddelandeleveransgarantier. Det finns två typer av köer i Durable Functions: kontrollkön och arbetsobjektkön.
Arbetsobjektskö
Det finns en arbetsobjektkö per aktivitetshubb i Durable Functions. Det är en grundläggande kö och fungerar på samma sätt som andra queueTrigger köer i Azure Functions. Den här kön används för att utlösa tillståndslösa aktivitetsfunktioner genom att rensa ett enda meddelande i taget. Vart och ett av dessa meddelanden innehåller aktivitetsfunktionsindata och ytterligare metadata, till exempel vilken funktion som ska köras. När ett Durable Functions-program skalar ut till flera virtuella datorer konkurrerar alla dessa virtuella datorer med att hämta uppgifter från arbetsobjektskön.
Kontrollera köer
Det finns flera kontrollköer per aktivitetshubb i Durable Functions. En kontrollkö är mer avancerad än den enklare arbetsobjektskö. Kontrollköer används för att utlösa tillståndskänsliga orkestrerings- och entitetsfunktioner. Eftersom orkestrerings- och entitetsfunktionsinstanserna är tillståndskänsliga singletons är det viktigt att varje orkestrering eller entitet endast bearbetas av en arbetare i taget. För att uppnå den här begränsningen tilldelas varje orkestreringsinstans eller entitet till en enda kontrollkö. Dessa kontrollköer lastbalanseras mellan arbetare för att säkerställa att varje kö endast bearbetas av en arbetare i taget. Mer information om det här beteendet finns i efterföljande avsnitt.
Kontrollköer innehåller en mängd olika typer av meddelandetyper för orkestreringslivscykel. Exempel är orchestrator-kontrollmeddelanden, aktivitetsfunktionssvarsmeddelanden och timermeddelanden. Så många som 32 meddelanden kommer att tas bort från en kontrollkö i en enda omröstning. Dessa meddelanden innehåller nyttolastdata samt metadata, inklusive vilken orkestreringsinstans den är avsedd för. Om flera dequeued-meddelanden är avsedda för samma orkestreringsinstans bearbetas de som en batch.
Kontrollkömeddelanden avsöks ständigt med hjälp av en bakgrundstråd. Batchstorleken för varje köundersökning styrs av controlQueueBatchSize inställningen i host.json och har standardvärdet 32 (det maximala värdet som stöds av Azure Queues). Det maximala antalet förinställda kontrollkömeddelanden som buffrats i minnet styrs av controlQueueBufferThreshold inställningen i host.json. Standardvärdet för controlQueueBufferThreshold varierar beroende på en mängd olika faktorer, inklusive typen av värdplan. Mer information om de här inställningarna finns i dokumentationen om host.json schema .
Dricks
Genom att öka värdet för controlQueueBufferThreshold kan en enskild orkestrering eller entitet bearbeta händelser snabbare. Att öka det här värdet kan dock också leda till högre minnesanvändning. Den högre minnesanvändningen beror delvis på att fler meddelanden hämtas från kön och delvis på att mer orkestreringshistorik hämtas till minnet. Att minska värdet för controlQueueBufferThreshold kan därför vara ett effektivt sätt att minska minnesanvändningen.
Kösökning
Det varaktiga aktivitetstillägget implementerar en slumpmässig exponentiell algoritm för säkerhetskopiering för att minska effekten av inaktiv kösökning på lagringstransaktionskostnader. När ett meddelande hittas söker körningen omedelbart efter ett annat meddelande. När inget meddelande hittas väntar det en stund innan det försöker igen. Efter efterföljande misslyckade försök att få ett kömeddelande fortsätter väntetiden att öka tills den når den maximala väntetiden, som standard är 30 sekunder.
Den maximala avsökningsfördröjningen maxQueuePollingInterval kan konfigureras via egenskapen i filen host.json. Om du ställer in den här egenskapen på ett högre värde kan det leda till svarstider för meddelandebearbetning. Högre svarstider förväntas endast efter perioder av inaktivitet. Om du anger den här egenskapen till ett lägre värde kan det leda till högre lagringskostnader på grund av ökade lagringstransaktioner.
Kommentar
När du kör i Azure Functions-förbruknings- och Premium-abonnemangen avsöker Azure Functions Scale Controller varje kontroll- och arbetsobjektkö en gång var 10:e sekund. Den här ytterligare avsökningen är nödvändig för att avgöra när funktionsappinstanser ska aktiveras och för att fatta skalningsbeslut. I skrivande stund är det här intervallet på 10 sekunder konstant och kan inte konfigureras.
Orkestreringsstartfördröjningar
Orkestreringsinstanser startas genom att ett ExecutionStarted meddelande placeras i en av aktivitetshubbens kontrollköer. Under vissa förhållanden kan du observera fördröjningar i flera sekunder mellan när en orkestrering är schemalagd att köras och när den faktiskt börjar köras. Under det här tidsintervallet förblir orkestreringsinstansen i tillståndet Pending . Det finns två möjliga orsaker till den här fördröjningen:
Backloggade kontrollköer: Om kontrollkön för den här instansen innehåller ett stort antal meddelanden kan det ta tid innan
ExecutionStartedmeddelandet tas emot och bearbetas av körningen. Meddelandeloggar kan inträffa när orkestreringar bearbetar många händelser samtidigt. Händelser som går in i kontrollkön inkluderar orkestreringsstarthändelser, aktivitetsavslut, varaktiga timers, avslutning och externa händelser. Om den här fördröjningen inträffar under normala omständigheter bör du överväga att skapa en ny aktivitetshubb med ett större antal partitioner. Om du konfigurerar fler partitioner kan körningen skapa fler kontrollköer för belastningsdistribution. Varje partition motsvarar 1:1 med en kontrollkö, med högst 16 partitioner.Fördröjningar i avsökningen: En annan vanlig orsak till orkestreringsfördröjningar är det tidigare beskrivna avsökningsbeteendet för kontrollköer. Den här fördröjningen förväntas dock bara när en app skalas ut till två eller flera instanser. Om det bara finns en appinstans eller om appinstansen som startar orkestreringen också är samma instans som avsöker målkontrollkön, kommer det inte att uppstå någon fördröjning av kösökningen. Fördröjningar av avsökningar kan minskas genom att uppdatera inställningarna för host.json enligt beskrivningen tidigare.
Blobar
I de flesta fall använder Durable Functions inte Azure Storage Blobs för att spara data. Köer och tabeller har dock storleksgränser som kan förhindra att Durable Functions bevarar alla nödvändiga data i en lagringsrad eller ett kömeddelande. När till exempel en databit som behöver sparas i en kö är större än 45 kB när de serialiseras komprimerar Durable Functions data och lagrar dem i en blob i stället. När du sparar data till bloblagring på det här sättet lagrar Durable Function en referens till den bloben i tabellraden eller kömeddelandet. När Durable Functions behöver hämta data hämtas de automatiskt från bloben. Dessa blobar lagras i blobcontainern <taskhub>-largemessages.
Prestandaöverväganden
De extra komprimerings- och blobåtgärdsstegen för stora meddelanden kan vara dyra när det gäller kostnader för CPU- och I/O-svarstid. Dessutom måste Durable Functions läsa in bevarade data i minnet och kan göra det för många olika funktionskörningar samtidigt. Därför kan bestående stora datanyttolaster också orsaka hög minnesanvändning. För att minimera minneskostnaderna bör du överväga att spara stora datanyttolaster manuellt (till exempel i bloblagring) och i stället skicka referenser till dessa data. På så sätt kan koden bara läsa in data när det behövs för att undvika redundanta belastningar under omspelningar av orkestreringsfunktionen. Lagring av nyttolaster till lokala diskar rekommenderas dock inte eftersom det inte är säkert att disktillståndet är tillgängligt eftersom funktioner kan köras på olika virtuella datorer under hela livslängden.
Val av lagringskonto
Köer, tabeller och blobar som används av Durable Functions skapas i ett konfigurerat Azure Storage-konto. Kontot som ska användas kan anges med hjälp av durableTask/storageProvider/connectionStringName inställningen (eller durableTask/azureStorageConnectionStringName inställningen i Durable Functions 1.x) i filen host.json .
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"azureStorageConnectionStringName": "MyStorageAccountAppSetting"
}
}
}
Om det inte anges används standardlagringskontot AzureWebJobsStorage . För prestandakänsliga arbetsbelastningar rekommenderar vi dock att du konfigurerar ett lagringskonto som inte är standard. Durable Functions använder Azure Storage kraftigt och med ett dedikerat lagringskonto isoleras Durable Functions-lagringsanvändningen från den interna användningen av Azure Functions-värden.
Kommentar
Azure Storage-standardkonton för generell användning krävs när du använder Azure Storage-providern. Alla andra typer av lagringskonton stöds inte. Vi rekommenderar starkt att du använder äldre v1-lagringskonton för generell användning för Durable Functions. De nyare v2-lagringskontona kan vara betydligt dyrare för Durable Functions-arbetsbelastningar. Mer information om Azure Storage-kontotyper finns i översiktsdokumentationen för lagringskontot.
Utskalning av Orchestrator
Även om aktivitetsfunktioner kan skalas ut oändligt genom att lägga till fler virtuella datorer elastiskt, är enskilda orchestrator-instanser och entiteter begränsade till att bebo en enda partition och det maximala antalet partitioner begränsas av partitionCount inställningen i .host.json
Kommentar
I allmänhet är orkestreringsfunktioner avsedda att vara lätta och bör inte kräva stora mängder databehandlingskraft. Det är därför inte nödvändigt att skapa ett stort antal kontrollköpartitioner för att få bra dataflöde för orkestreringar. Det mesta av det tunga arbetet bör utföras i tillståndslösa aktivitetsfunktioner, som kan skalas ut oändligt.
Antalet kontrollköer definieras i filen host.json . Följande exempel host.json kodfragment anger durableTask/storageProvider/partitionCount egenskapen (eller durableTask/partitionCount i Durable Functions 1.x) till 3. Observera att det finns lika många kontrollköer som det finns partitioner.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
En aktivitetshubb kan konfigureras med mellan 1 och 16 partitioner. Om det inte anges är standardantalet för partition 4.
Under scenarier med låg trafik skalas programmet in, så partitioner hanteras av ett litet antal arbetare. Tänk till exempel på diagrammet nedan.
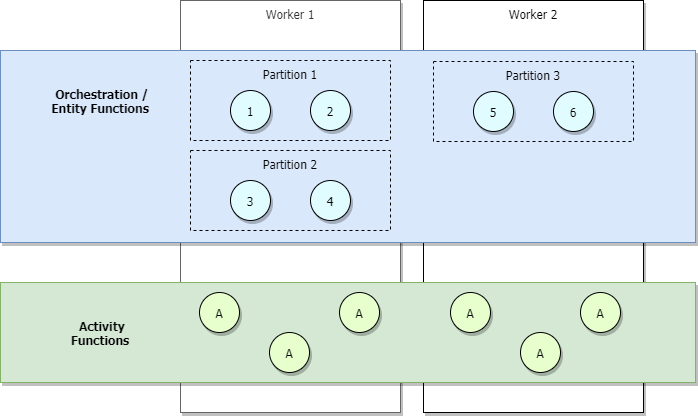
I föregående diagram ser vi att orchestrators 1 till 6 lastbalanseras mellan partitioner. På samma sätt lastbalanseras partitioner, till exempel aktiviteter, mellan arbetare. Partitioner belastningsutjämning mellan arbetare oavsett antalet orkestratorer som kommer igång.
Om du kör azure functions-förbruknings- eller Elastic Premium-abonnemangen, eller om du har konfigurerat belastningsbaserad automatisk skalning, allokeras fler arbetare när trafiken ökar och partitionerna så småningom lastbalanserar alla arbetare. Om vi fortsätter att skala ut kommer varje partition så småningom att hanteras av en enda arbetare. Aktiviteterna kommer däremot att fortsätta att vara belastningsutjämningsbelastade för alla arbetstagare. Detta visas i bilden nedan.
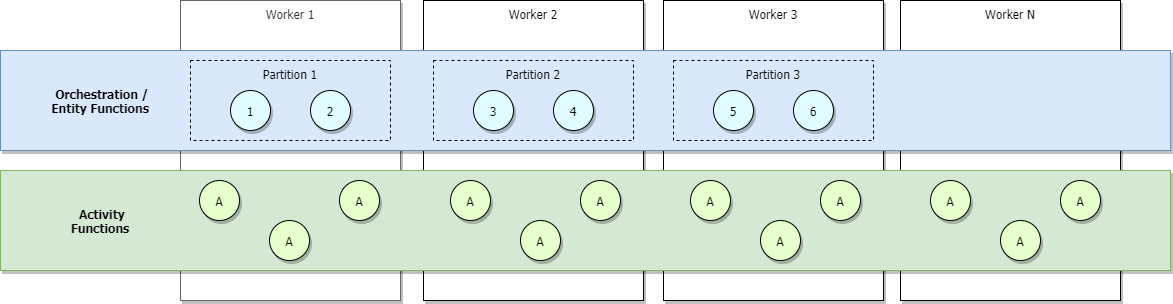
Den övre gränsen för det maximala antalet samtidiga aktiva orkestreringar vid en viss tidpunkt är lika med det antal arbetare som allokeras till programmet gånger värdet för maxConcurrentOrchestratorFunctions. Den här övre gränsen kan göras mer exakt när partitionerna skalas ut fullständigt mellan arbetare. När den är helt utskalad, och eftersom varje arbetare bara har en enda Functions-värdinstans, är det maximala antalet aktiva samtidiga orchestrator-instanser lika med ditt antal partitioner gånger värdet för maxConcurrentOrchestratorFunctions.
Kommentar
I det här sammanhanget innebär aktiv att en orkestrering eller entitet läses in i minnet och bearbetar nya händelser. Om orkestreringen eller entiteten väntar på fler händelser, till exempel returvärdet för en aktivitetsfunktion, tas den bort från minnet och anses inte längre vara aktiv. Orkestreringar och entiteter läses sedan in i minnet igen endast när det finns nya händelser att bearbeta. Det finns inget praktiskt maximalt antal totala orkestreringar eller entiteter som kan köras på en enda virtuell dator, även om de alla är i tillståndet "Körs". Den enda begränsningen är antalet samtidiga aktiva orkestrerings- eller entitetsinstanser.
Bilden nedan illustrerar ett fullständigt utskalat scenario där fler orkestrerare läggs till men vissa är inaktiva, som visas i grått.
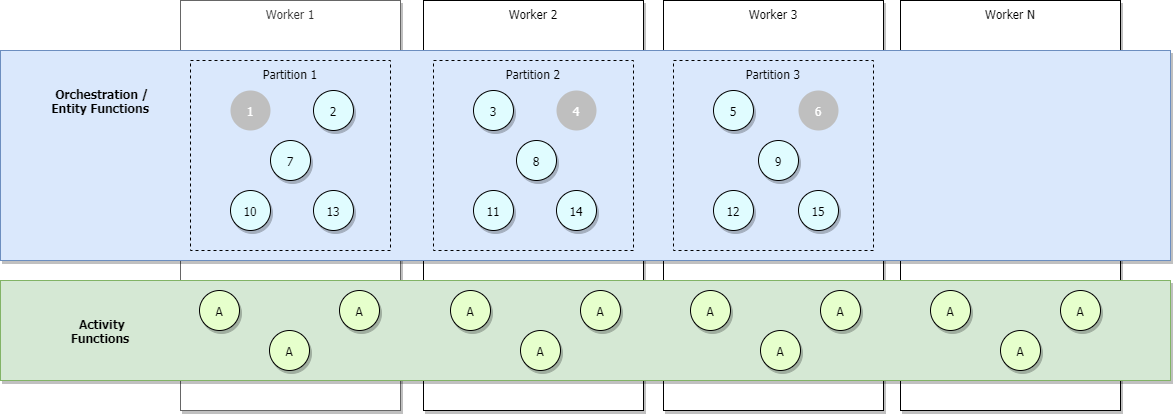
Vid utskalning kan kontrollkölån distribueras om mellan Functions-värdinstanser för att säkerställa att partitionerna är jämnt fördelade. Dessa lån implementeras internt som Azure Blob Storage-lån och säkerställer att alla enskilda orkestreringsinstanser eller entiteter endast körs på en enda värdinstans i taget. Om en aktivitetshubb har konfigurerats med tre partitioner (och därför tre kontrollköer) kan orkestreringsinstanser och entiteter belastningsutjäxas över alla tre värdinstanser med lån. Ytterligare virtuella datorer kan läggas till för att öka kapaciteten för aktivitetsfunktionskörning.
Följande diagram visar hur Azure Functions-värden interagerar med lagringsentiteterna i en utskalad miljö.
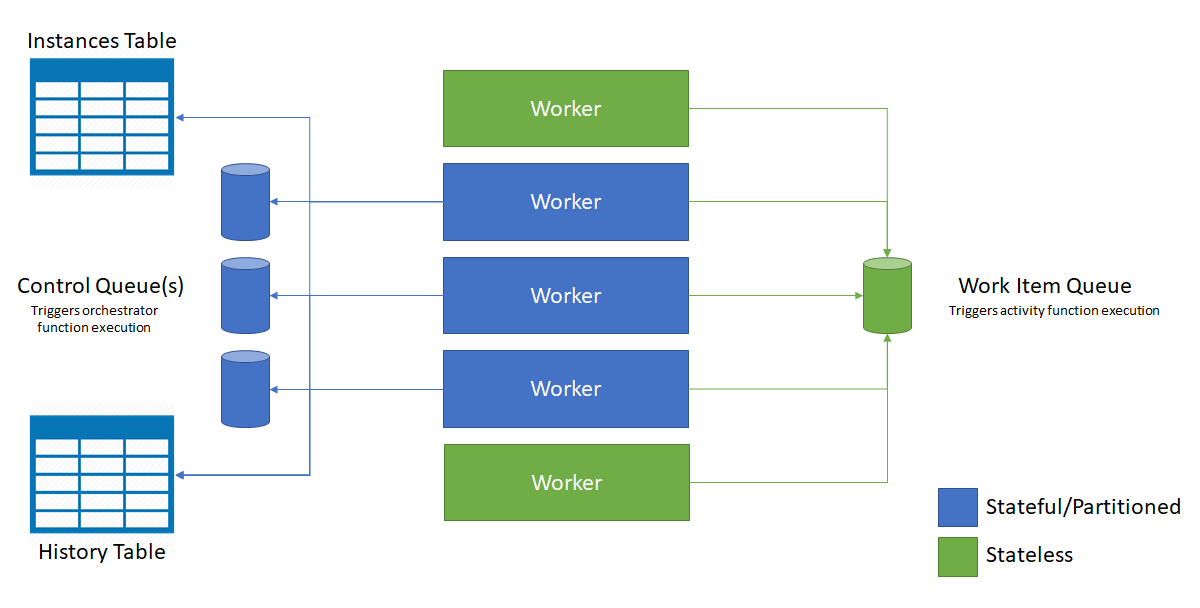
Som du ser i föregående diagram konkurrerar alla virtuella datorer om meddelanden i arbetsobjektkön. Men endast tre virtuella datorer kan hämta meddelanden från kontrollköer och varje virtuell dator låser en enda kontrollkö.
Orkestreringsinstanser och entiteter distribueras över alla kontrollköinstanser. Fördelningen görs genom att hasha instans-ID:t för orkestreringen eller entitetsnamnet och nyckelparet. Orkestreringsinstans-ID:er är som standard slumpmässiga GUID:er, vilket säkerställer att instanser är lika fördelade i alla kontrollköer.
I allmänhet är orkestreringsfunktioner avsedda att vara lätta och bör inte kräva stora mängder databehandlingskraft. Det är därför inte nödvändigt att skapa ett stort antal kontrollköpartitioner för att få bra dataflöde för orkestreringar. Det mesta av det tunga arbetet bör utföras i tillståndslösa aktivitetsfunktioner, som kan skalas ut oändligt.
Utökade sessioner
Utökade sessioner är en cachelagringsmekanism som håller orkestreringar och entiteter i minnet även efter att de har bearbetat meddelanden. Den typiska effekten av att aktivera utökade sessioner är minskad I/O mot det underliggande hållbara arkivet och det övergripande förbättrade dataflödet.
Du kan aktivera utökade sessioner genom att ange durableTask/extendedSessionsEnabled i true filen host.json . Inställningen durableTask/extendedSessionIdleTimeoutInSeconds kan användas för att styra hur länge en inaktiv session ska hållas i minnet:
Funktioner 2.0
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Funktioner 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
Det finns två möjliga nackdelar med den här inställningen att vara medveten om:
- Minnesanvändningen för funktionsappen ökar totalt sett eftersom inaktiva instanser inte tas bort från minnet lika snabbt.
- Det kan bli en total minskning av dataflödet om det finns många samtidiga, distinkta, kortlivade orkestrerings- eller entitetsfunktionskörningar.
Om det till exempel durableTask/extendedSessionIdleTimeoutInSeconds är inställt på 30 sekunder upptar ett kortlivad orkestrerings- eller entitetsfunktionsavsnitt som körs på mindre än 1 sekund fortfarande minnet i 30 sekunder. Det räknas också mot den durableTask/maxConcurrentOrchestratorFunctions kvot som nämnts tidigare, vilket potentiellt hindrar andra orkestrerings- eller entitetsfunktioner från att köras.
De specifika effekterna av utökade sessioner på orkestrerings- och entitetsfunktioner beskrivs i nästa avsnitt.
Kommentar
Utökade sessioner stöds för närvarande endast på .NET-språk, till exempel C# eller F#. Om du anger extendedSessionsEnabled till true för andra plattformar kan det leda till körningsproblem, till exempel att det inte går att köra aktivitet och orkestreringsutlösta funktioner utan avbrott.
Orchestrator-funktionsrepris
Som tidigare nämnts spelas orkestreringsfunktioner upp med hjälp av innehållet i tabellen Historik . Som standard spelas orchestrator-funktionskoden upp varje gång en batch meddelanden tas bort från en kontrollkö. Även om du använder-out- och-in-mönstret och väntar på att alla uppgifter ska slutföras (till exempel i Task.WhenAll() .NET, context.df.Task.all() i JavaScript eller context.task_all() i Python) kommer det att finnas repriser som inträffar när batchar med uppgiftssvar bearbetas över tid. När utökade sessioner är aktiverade lagras orchestrator-funktionsinstanser längre i minnet och nya meddelanden kan bearbetas utan en fullständig historikrepris.
Prestandaförbättringen för utökade sessioner observeras oftast i följande situationer:
- När det finns ett begränsat antal orkestreringsinstanser som körs samtidigt.
- När orkestreringar har ett stort antal sekventiella åtgärder (till exempel hundratals aktivitetsfunktionsanrop) som slutförs snabbt.
- När orkestrering fläktar ut och fläktar in ett stort antal åtgärder som slutförs ungefär samtidigt.
- När orkestreringsfunktioner behöver bearbeta stora meddelanden eller utföra processorintensiv databearbetning.
I alla andra situationer finns det vanligtvis ingen observerbar prestandaförbättring för orkestreringsfunktioner.
Kommentar
De här inställningarna bör endast användas när en orkestreringsfunktion har utvecklats och testats fullt ut. Standardbeteendet för aggressiv uppspelning kan vara användbart för att identifiera överträdelser av funktionskodsbegränsningar för orchestrator vid utvecklingstillfället och är därför inaktiverat som standard.
Prestandamål
I följande tabell visas de förväntade maximala dataflödesnumren för de scenarier som beskrivs i avsnittet Prestandamål i artikeln Prestanda och skala.
"Instans" refererar till en enda instans av en orkestreringsfunktion som körs på en enda liten (A1) virtuell dator i Azure App Service. I samtliga fall förutsätts det att utökade sessioner är aktiverade. Faktiska resultat kan variera beroende på processor- eller I/O-arbete som utförs av funktionskoden.
| Scenario | Maximalt dataflöde |
|---|---|
| Körning av sekventiell aktivitet | 5 aktiviteter per sekund, per instans |
| Parallell aktivitetskörning (uttjänt) | 100 aktiviteter per sekund, per instans |
| Parallell svarsbearbetning (inaktivt) | 150 svar per sekund, per instans |
| Bearbetning av externa händelser | 50 händelser per sekund, per instans |
| Bearbetning av entitetsåtgärd | 64 åtgärder per sekund |
Om du inte ser de dataflödesnummer du förväntar dig och processor- och minnesanvändningen verkar felfri kontrollerar du om orsaken är relaterad till hälsotillståndet för ditt lagringskonto. Durable Functions-tillägget kan lägga betydande belastning på ett Azure Storage-konto och tillräckligt hög belastning kan leda till begränsning av lagringskontot.
Dricks
I vissa fall kan du avsevärt öka dataflödet för externa händelser, inaktiv aktivitet och entitetsåtgärder genom att öka värdet controlQueueBufferThreshold för inställningen i host.json. Om du ökar det här värdet utöver standardvärdet kan durable task framework-lagringsprovidern använda mer minne för att föregripa dessa händelser mer aggressivt, vilket minskar fördröjningar som är associerade med att ta bort meddelanden från Azure Storage-kontrollköerna. Mer information finns i referensdokumentationen för host.json .
Bearbetning med högt dataflöde
Arkitekturen för Azure Storage-serverdelen begränsar den maximala teoretiska prestandan och skalbarheten för Durable Functions. Om testningen visar att Durable Functions på Azure Storage inte uppfyller dina dataflödeskrav bör du i stället överväga att använda Netherite-lagringsprovidern för Durable Functions.
Om du vill jämföra det uppnåeliga dataflödet för olika grundläggande scenarier kan du läsa avsnittet Grundläggande scenarier i dokumentationen för Netherite Storage Provider.
Netherite Storage-serverdelen har utformats och utvecklats av Microsoft Research. Den använder Azure Event Hubs och FASTER-databastekniken ovanpå Azure Page Blobs. Netherite-designen möjliggör betydligt högre dataflödesbearbetning av orkestreringar och entiteter jämfört med andra leverantörer. I vissa benchmark-scenarier visade sig dataflödet öka med mer än en storleksordning jämfört med standardleverantören för Azure Storage.
Mer information om lagringsprovidrar som stöds för Durable Functions och hur de jämförs finns i dokumentationen om Durable Functions-lagringsproviders .