AI-berikande i Azure AI Search
I Azure AI Search refererar AI-berikning till integrering med Azure AI-tjänster för att bearbeta innehåll som inte kan sökas i dess råa form. Genom berikning används analys och slutsatsdragning för att skapa sökbart innehåll och en struktur där ingen tidigare fanns.
Eftersom Azure AI Search används för text- och vektorfrågor är syftet med AI-berikning att förbättra verktyget för ditt innehåll i sökrelaterade scenarier. Råinnehåll måste vara text eller bilder (du kan inte berika vektorer), men utdata från en berikningspipeline kan vektoriseras och indexeras i ett vektorindex med hjälp av kunskaper som textdelningsfärdighet för segmentering och AzureOpenAIEmbedding-kunskaper för kodning. Mer information om hur du använder kunskaper i vektorscenarier finns i Integrerad datasegmentering och inbäddning.
AI-berikande baseras på färdigheter.
Inbyggda kunskaper trycker på Azure AI-tjänster. De tillämpar följande transformeringar och bearbetning på råinnehåll:
- Översättning och språkidentifiering för flerspråkig sökning
- Entitetsigenkänning för att extrahera personnamn, platser och andra entiteter från stora textsegment
- Extrahering av nyckelfraser för att identifiera och mata ut viktiga termer
- Optisk teckenigenkänning (OCR) för att identifiera tryckt och handskriven text i binära filer
- Bildanalys för att beskriva bildinnehåll och mata ut beskrivningarna som sökbara textfält
Anpassade kunskaper kör din externa kod. Anpassade kunskaper kan användas för alla anpassade bearbetningar som du vill inkludera i pipelinen.
AI-berikning är ett tillägg till en indexerarpipeline som ansluter till Azure-datakällor. En berikningspipeline innehåller alla komponenter i en indexeringspipeline (indexerare, datakälla, index) plus en kompetensuppsättning som anger atomiska berikningssteg.
Följande diagram visar utvecklingen av AI-berikning:
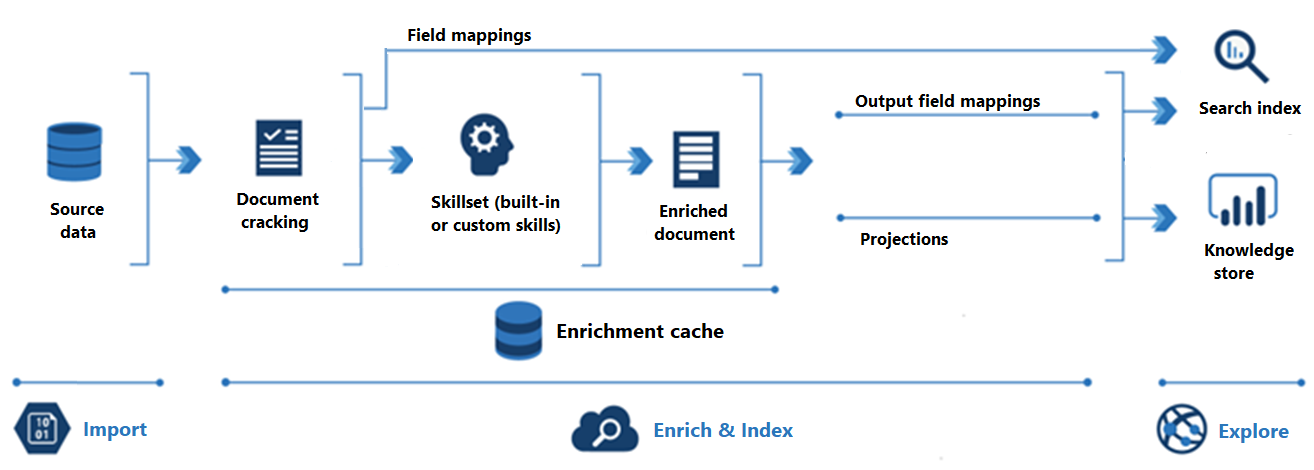
Import är det första steget. Här ansluter indexeraren till en datakälla och hämtar innehåll (dokument) till söktjänsten. Azure Blob Storage är den vanligaste resursen som används i AI-berikningsscenarier, men alla datakällor som stöds kan tillhandahålla innehåll.
Enrich &Index omfattar merparten av AI-berikande pipelinen:
Berikningen börjar när indexeraren "spricker dokument" och extraherar bilder och text. Vilken typ av bearbetning som sker härnäst beror på dina data och vilka färdigheter du har lagt till i en kompetensuppsättning. Om du har bilder kan de vidarebefordras till färdigheter som utför bildbearbetning. Textinnehåll placeras i kö för bearbetning av text och naturligt språk. Internt skapar färdigheter ett "berikat dokument" som samlar in omvandlingarna när de inträffar.
Berikat innehåll genereras under körningen av kompetensuppsättningen och är tillfälligt om du inte sparar det. Du kan aktivera en berikningscache för att bevara knäckta dokument och kunskapsutdata för efterföljande återanvändning under framtida körning av kompetensuppsättningar.
För att få innehåll till ett sökindex måste indexeraren ha mappningsinformation för att skicka berikat innehåll till målfältet. Fältmappningar (explicit eller implicit) anger datasökvägen från källdata till ett sökindex. Utdatafältmappningar anger datasökvägen från berikade dokument till ett index.
Indexering är den process där rådata och berikat innehåll matas in i de fysiska datastrukturerna i ett sökindex (dess filer och mappar). Lexikal analys och tokenisering sker i det här steget.
Utforskning är det sista steget. Utdata är alltid ett sökindex som du kan köra frågor mot från en klientapp. Utdata kan också vara ett kunskapslager som består av blobar och tabeller i Azure Storage som nås via verktyg för datautforskning eller underordnade processer. Om du skapar ett kunskapslager avgör projektionerna datasökvägen för berikat innehåll. Samma berikade innehåll kan visas i både index och kunskapslager.
När du ska använda AI-berikning
Berikning är användbart om råinnehåll är ostrukturerad text, bildinnehåll eller innehåll som behöver språkidentifiering och översättning. Genom att använda AI via de inbyggda färdigheterna kan du låsa upp det här innehållet för fulltextsökning och datavetenskapsprogram.
Du kan också skapa anpassade kunskaper för att tillhandahålla extern bearbetning. Kod med öppen källkod, tredje part eller första part kan integreras i pipelinen som en anpassad färdighet. Klassificeringsmodeller som identifierar viktiga egenskaper för olika dokumenttyper tillhör den här kategorin, men alla externa paket som lägger till värde i ditt innehåll kan användas.
Användningsfall för inbyggda färdigheter
Inbyggda kunskaper baseras på API:er för Azure AI-tjänster: Azure AI Visuellt innehåll och Language Service. Om inte dina innehållsindata är små kan du förvänta dig att bifoga en fakturerbar Azure AI-tjänstresurs för att köra större arbetsbelastningar.
En kompetensuppsättning som monteras med hjälp av inbyggda färdigheter passar bra för följande programscenarier:
Bildbearbetningsfärdigheter inkluderar optisk teckenigenkänning (OCR) och identifiering av visuella funktioner, till exempel ansiktsigenkänning, bildtolkning, bildigenkänning (kända personer och landmärken) eller attribut som bildorientering. Dessa kunskaper skapar textrepresentationer av bildinnehåll för fulltextsökning i Azure AI Search.
Maskinöversättning tillhandahålls av kunskaper i textöversättning , som ofta kombineras med språkidentifiering för lösningar på flera språk.
Bearbetning av naturligt språk analyserar textsegment. Kunskaper i den här kategorin är Entitetsigenkänning, Sentimentidentifiering (inklusive åsiktsutvinning) och Identifiering av personlig identifierbar information. Med dessa kunskaper mappas ostrukturerad text som sökbara och filterbara fält i ett index.
Användningsfall för anpassade kunskaper
Anpassade kunskaper kör extern kod som du anger och omsluter i webbgränssnittet för anpassade kunskaper. Flera exempel på anpassade kunskaper finns på GitHub-lagringsplatsen azure-search-power-skills .
Anpassade kunskaper är inte alltid komplexa. Om du till exempel har ett befintligt paket som tillhandahåller mönstermatchning eller en dokumentklassificeringsmodell kan du omsluta det med en anpassad färdighet.
Lagra utdata
I Azure AI Search sparar en indexerare utdata som skapas. En enda indexerare kan skapa upp till tre datastrukturer som innehåller berikade och indexerade utdata.
| Datalager | Obligatoriskt | Plats | beskrivning |
|---|---|---|---|
| sökbart index | Obligatoriskt | Söktjänst | Används för fulltextsökning och andra frågeformulär. Att ange ett index är ett indexeringskrav. Indexinnehåll fylls i från kunskapsutdata, plus alla källfält som mappas direkt till fält i indexet. |
| kunskapslager | Valfritt | Azure Storage | Används för nedströmsappar som kunskapsutvinning eller datavetenskap. Ett kunskapslager definieras inom en kompetensuppsättning. Dess definition avgör om dina berikade dokument projiceras som tabeller eller objekt (filer eller blobar) i Azure Storage. |
| berikningscache | Valfritt | Azure Storage | Används för cachelagring av berikningar för återanvändning i efterföljande körning av kompetensuppsättningar. Cacheminnet lagrar importerat, obearbetat innehåll (spruckna dokument). Den lagrar även de berikade dokument som skapades under körningen av kompetensuppsättningen. Cachelagring är användbart om du använder bildanalys eller OCR och vill undvika tid och kostnader för ombearbetning av bildfiler. |
Index och kunskapslager är helt oberoende av varandra. Du måste bifoga ett index för att uppfylla indexeringskraven, men om ditt enda mål är ett kunskapslager kan du ignorera indexet när det har fyllts i.
Utforska innehåll
När du har definierat och läst in ett sökindex eller ett kunskapslager kan du utforska dess data.
Fråga ett sökindex
Kör frågor för att komma åt det berikade innehåll som genereras av pipelinen. Indexet är som alla andra du kan skapa för Azure AI Search: du kan komplettera textanalys med anpassade analysverktyg, anropa fuzzy-sökfrågor, lägga till filter eller experimentera med bedömningsprofiler för att justera sökrelevansen.
Använda verktyg för datautforskning i ett kunskapslager
I Azure Storage kan ett kunskapslager anta följande formulär: en blobcontainer med JSON-dokument, en blobcontainer med avbildningsobjekt eller tabeller i Table Storage. Du kan använda Storage Explorer, Power BI eller valfri app som ansluter till Azure Storage för att få åtkomst till ditt innehåll.
En blobcontainer samlar in berikade dokument i sin helhet, vilket är användbart om du skapar ett flöde i andra processer.
En tabell är användbar om du behöver segment av berikade dokument, eller om du vill inkludera eller exkludera specifika delar av utdata. För analys i Power BI är tabeller den rekommenderade datakällan för datautforskning och visualisering i Power BI.
Tillgänglighet och priser
Berikning är tillgängligt i regioner som har Azure AI-tjänster. Du kan kontrollera tillgängligheten för berikning på sidan med regioners lista .
Faktureringen följer en prismodell för betala per användning. Kostnaderna för att använda inbyggda kunskaper överförs när en Azure AI-tjänstnyckel för flera regioner anges i kompetensuppsättningen. Det finns också kostnader som är kopplade till extrahering av avbildningar, som mäts av Azure AI Search. Textextrahering och verktygskunskaper kan dock inte faktureras. Mer information finns i Så här debiteras du för Azure AI Search.
Checklista: Ett typiskt arbetsflöde
En berikningspipeline består av indexerare som har kompetensuppsättningar. Efter indexering kan du fråga ett index för att verifiera dina resultat.
Börja med en delmängd data i en datakälla som stöds. Indexerare och kompetensuppsättningsdesign är en iterativ process. Arbetet går snabbare med en liten representativ datauppsättning.
Skapa en datakälla som anger en anslutning till dina data.
Skapa en kompetensuppsättning. Om inte projektet är litet bör du koppla en Azure AI-resurs med flera tjänster. Om du skapar ett kunskapslager definierar du det inom kompetensuppsättningen.
Skapa ett indexschema som definierar ett sökindex.
Skapa och kör indexeraren för att sammanföra alla ovanstående komponenter. Det här steget hämtar data, kör kompetensuppsättningen och läser in indexet.
En indexerare är också där du anger fältmappningar och mappningar för utdatafält som konfigurerar datasökvägen till ett sökindex.
Du kan också aktivera cachelagring av berikning i indexerarens konfiguration. Med det här steget kan du återanvända befintliga berikningar senare.
Kör frågor för att utvärdera resultat eller starta en felsökningssession för att gå igenom eventuella problem med kompetensuppsättningar.
Om du vill upprepa något av stegen ovan återställer du indexeraren innan du kör den. Du kan också ta bort och återskapa objekten på varje körning (rekommenderas om du använder den kostnadsfria nivån). Om du har aktiverat cachelagring hämtar indexeraren från cacheminnet om data är oförändrade vid källan och om dina ändringar i pipelinen inte ogiltigförklarar cacheminnet.