Vill du lära dig mer om Service Fabric?
Azure Service Fabric är en distribuerad systemplattform som gör det enkelt att paketera, distribuera och hantera skalbara och tillförlitliga mikrotjänster. Service Fabric har dock en stor yta och det finns mycket att lära. Den här artikeln innehåller en sammanfattning av Service Fabric och beskriver grundläggande begrepp, programmeringsmodeller, programlivscykel, testning, kluster och hälsoövervakning. Läs Översikt och Vad är mikrotjänster? för en introduktion och hur Service Fabric kan användas för att skapa mikrotjänster. Den här artikeln innehåller ingen omfattande innehållslista, men länkar till översikts- och komma igång-artiklar för alla områden i Service Fabric.
Huvudkoncept
Service Fabric-terminologi, programmodell och programmeringsmodeller som stöds innehåller fler begrepp och beskrivningar, men här är grunderna.
- Service Fabric-kluster: Se den här länken för en träningsvideo för att få en introduktion till Service Fabric-arkitekturen och dess grundläggande begrepp och utforska många service fabric-funktioner.
- Körningsbegrepp: Kontrollera den här länken för en träningsvideo för att förstå körningsbegrepp och metodtips för Service Fabric.
- Designtypsbegrepp: Kontrollera den här länken för en träningsvideo för att förstå program, paketering och distribution, viktig Service Fabric-terminologi, abstraktioner och begrepp.
Designtid: tjänsttyp, tjänstpaket och manifest, programtyp, programpaket och manifest
En tjänsttyp är namnet/versionen som tilldelats till en tjänsts kodpaket, datapaket och konfigurationspaket. Detta definieras i en ServiceManifest.xml fil. Tjänsttypen består av körbara kod- och tjänstkonfigurationsinställningar som läses in vid körning och statiska data som används av tjänsten.
Ett tjänstpaket är en diskkatalog som innehåller tjänsttypens ServiceManifest.xml-fil, som refererar till kod-, statiska data- och konfigurationspaket för tjänsttypen. Ett tjänstpaket kan till exempel referera till kod-, statiska data- och konfigurationspaket som utgör en databastjänst.
En programtyp är namnet/versionen som tilldelats en samling tjänsttyper. Detta definieras i en ApplicationManifest.xml fil.
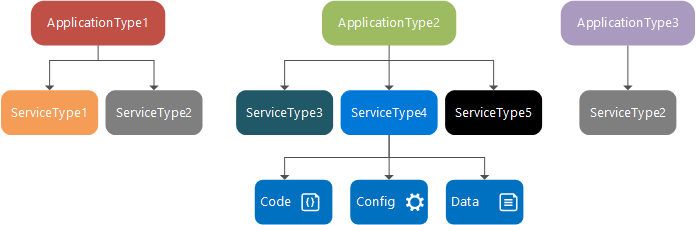
Programpaketet är en diskkatalog som innehåller programtypens ApplicationManifest.xml fil, som refererar till tjänstpaketen för varje tjänsttyp som utgör programtypen. Ett programpaket för en programtyp för e-post kan till exempel innehålla referenser till ett kötjänstpaket, ett klientdelstjänstpaket och ett databastjänstpaket.
Filerna i programpaketkatalogen kopieras till Service Fabric-klustrets avbildningsarkiv. Du kan sedan skapa ett namngivet program från den här programtypen, som sedan körs i klustret. När du har skapat ett namngivet program kan du skapa en namngiven tjänst från någon av programtypens tjänsttyper.
Körning: kluster och noder, namngivna program, namngivna tjänster, partitioner och repliker
Ett Service Fabric-kluster är en nätverksansluten uppsättning virtuella eller fysiska datorer som dina mikrotjänster distribueras till och hanteras från. Kluster kan skalas upp till tusentals datorer.
En dator eller virtuell dator som ingår i ett kluster kallas för en nod. Varje nod har tilldelats ett nodnamn (en sträng). Noder har egenskaper, till exempel placeringsegenskaper. Varje dator eller virtuell dator har en automatisk start av Windows-tjänsten, FabricHost.exe, som börjar köras vid start och sedan startar två körbara filer: Fabric.exe och FabricGateway.exe. Dessa två körbara filer utgör noden. För utvecklings- eller testscenarier kan du vara värd för flera noder på en enskild dator eller virtuell dator genom att köra flera instanser av Fabric.exe och FabricGateway.exe.
Ett namngivet program är en samling namngivna tjänster som utför en viss funktion eller funktioner. En tjänst utför en komplett och fristående funktion (den kan starta och köras oberoende av andra tjänster) och består av kod, konfiguration och data. När ett programpaket har kopierats till avbildningsarkivet skapar du en instans av programmet i klustret genom att ange programpaketets programtyp (med dess namn/version). Varje programtypinstans tilldelas ett URI-namn som ser ut som infrastrukturresurser:/MyNamedApp. I ett kluster kan du skapa flera namngivna program från en enda programtyp. Du kan också skapa namngivna program från olika programtyper. Varje namngivet program hanteras och versionshanteras oberoende av varandra.
När du har skapat ett namngivet program kan du skapa en instans av en av dess tjänsttyper (en namngiven tjänst) i klustret genom att ange tjänsttypen (med dess namn/version). Varje instans av tjänsttyp tilldelas ett URI-namn under dess namngivna program-URI. Om du till exempel skapar en "MyDatabase"-namngiven tjänst i ett "MyNamedApp"-namngivet program ser URI:n ut som: fabric:/MyNamedApp/MyDatabase. I ett namngivet program kan du skapa en eller flera namngivna tjänster. Varje namngiven tjänst kan ha ett eget partitionsschema och antal instanser/repliker.
Det finns två typer av tjänster: tillståndslösa och tillståndskänsliga. Tillståndslösa tjänster lagrar inte tillstånd i tjänsten. Tillståndslösa tjänster har ingen beständig lagring alls eller lagrar beständiga tillstånd i en extern lagringstjänst som Azure Storage, Azure SQL Database eller Azure Cosmos DB. En tillståndskänslig tjänst lagrar tillstånd i tjänsten och använder Reliable Collections eller Reliable Actors programmeringsmodeller för att hantera tillstånd.
När du skapar en namngiven tjänst anger du ett partitionsschema. Tjänster med stora mängder tillstånd delar upp data mellan partitioner. Varje partition ansvarar för en del av tjänstens fullständiga tillstånd, som är fördelat över klustrets noder.
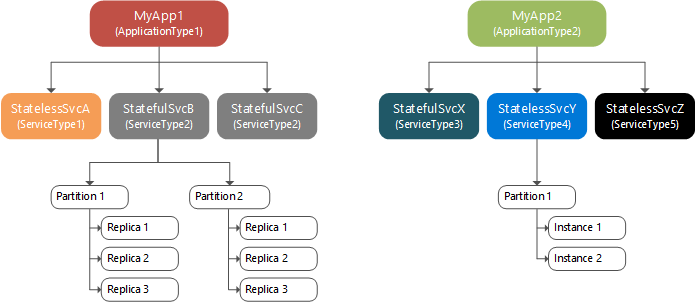
Följande diagram visar relationen mellan program och tjänstinstanser, partitioner och repliker.
Partitionering, skalning och tillgänglighet
Partitionering är inte unikt för Service Fabric. En välkänd form av partitionering är datapartitionering eller horisontell partitionering. Tillståndskänsliga tjänster med stora mängder tillstånd delar upp data mellan partitioner. Varje partition ansvarar för en del av tjänstens fullständiga tillstånd.
Replikerna för varje partition sprids över klustrets noder, vilket gör att den namngivna tjänstens tillstånd kan skalas. När databehoven växer växer partitionerna och Service Fabric balanserar om partitioner mellan noder för att effektivt använda maskinvaruresurser. Om du lägger till nya noder i klustret balanserar Service Fabric om partitionsreplikerna över det ökade antalet noder. Övergripande programprestanda förbättras och konkurrensen om åtkomst till minne minskar. Om noderna i klustret inte används effektivt kan du minska antalet noder i klustret. Service Fabric balanserar återigen om partitionsreplikerna över det minskade antalet noder för att bättre använda maskinvaran på varje nod.
I en partition har tillståndslösa namngivna tjänster instanser medan tillståndskänsliga namngivna tjänster har repliker. Vanligtvis har tillståndslösa namngivna tjänster bara en partition eftersom de inte har något internt tillstånd, även om det finns undantag. Partitionsinstanserna tillhandahåller tillgänglighet. Om en instans misslyckas fortsätter andra instanser att fungera normalt och sedan skapar Service Fabric en ny instans. Tillståndskänsliga namngivna tjänster behåller sitt tillstånd i repliker och varje partition har en egen replikuppsättning. Läs- och skrivåtgärder utförs på en replik (kallas primär). Ändringar i tillstånd från skrivåtgärder replikeras till flera andra repliker (kallas aktiva sekundärfiler). Om en replik misslyckas skapar Service Fabric en ny replik från de befintliga replikerna.
Tillståndslösa och tillståndskänsliga mikrotjänster för Service Fabric
Med Service Fabric kan du skapa program som består av mikrotjänster eller containrar. Tillståndslösa mikrotjänster (till exempel protokollgatewayar och webbproxyservrar) har inte ett föränderligt tillstånd utanför en begäran och svaret från tjänsten. Arbetsroller i Azure Cloud Services är ett exempel på en tillståndslös tjänst. Tillståndskänsliga mikrotjänster (till exempel användarkonton, databaser, enheter, kundvagnar och köer) har ett föränderligt och auktoritärt tillstånd bortom begäran och svaret. Dagens program med Internetskala består av en kombination av tillståndslösa och tillståndskänsliga mikrotjänster.
En viktig differentiering med Service Fabric är dess starka fokus på att skapa tillståndskänsliga tjänster, antingen med de inbyggda programmeringsmodellerna eller med containerbaserade tillståndskänsliga tjänster. Programscenarier beskriver scenarier där tillståndskänsliga tjänster används.
Varför har tillståndskänsliga mikrotjänster tillsammans med tillståndslösa? De två främsta orsakerna är:
- Du kan skapa OLTP-tjänster (high-throughput, low-latency, failure-tolerant online transaction processing) genom att hålla kod och data nära på samma dator. Några exempel är interaktiva skyltfönster, sökning, IoT-system (Internet of Things), handelssystem, kreditkortsbearbetning och system för bedrägeriidentifiering och personlig arkivhantering.
- Du kan förenkla programdesignen. Tillståndskänsliga mikrotjänster tar bort behovet av ytterligare köer och cacheminnen, som traditionellt krävs för att uppfylla tillgänglighets- och svarstidskraven för ett rent tillståndslöst program. Tillståndskänsliga tjänster är naturligtvis hög tillgänglighet och låg svarstid, vilket minskar antalet rörliga delar som ska hanteras i ditt program som helhet.
Programmeringsmodeller som stöds
Service Fabric erbjuder flera sätt att skriva och hantera dina tjänster. Tjänster kan använda Service Fabric-API:er för att dra full nytta av plattformens funktioner och programramverk. Tjänster kan också vara alla kompilerade körbara program som skrivs på valfritt språk och finns i ett Service Fabric-kluster. Mer information finns i Programmeringsmodeller som stöds.
Containers
Som standard distribuerar och aktiverar Service Fabric tjänster som processer. Service Fabric kan också distribuera tjänster i containrar. Viktigt är att du kan blanda tjänster i processer och tjänster i containrar i samma program. Service Fabric stöder distribution av Linux-containrar och Windows-containrar på Windows Server 2016. Du kan distribuera befintliga program, tillståndslösa tjänster eller tillståndskänsliga tjänster i containrar.
Reliable Services
Reliable Services är ett enkelt ramverk för att skriva tjänster som integreras med Service Fabric-plattformen och drar nytta av alla plattformsfunktioner. Reliable Services kan vara tillståndslösa (liknar de flesta tjänstplattformar, till exempel webbservrar eller arbetsroller i Azure Cloud Services), där tillståndet sparas i en extern lösning, till exempel Azure DB eller Azure Table Storage. Reliable Services kan också vara tillståndskänsliga, där tillståndet sparas direkt i själva tjänsten med hjälp av Reliable Collections. Tillståndet görs mycket tillgängligt via replikering och distribueras via partitionering, som hanteras automatiskt av Service Fabric.
Reliable Actors
Reliable Actor-ramverket bygger på Reliable Services och är ett programramverk som implementerar mönstret Virtuell aktör baserat på aktörens designmönster. Reliable Actor-ramverket använder oberoende beräkningsenheter och tillstånd med en trådad körning som kallas aktörer. Ramverket Reliable Actor tillhandahåller inbyggd kommunikation för aktörer och förinställda tillståndsbeständighet och utskalningskonfigurationer.
ASP.NET Core
Service Fabric integreras med ASP.NET Core som en förstklassig programmeringsmodell för att skapa webb- och API-program. ASP.NET Core kan användas på två olika sätt i Service Fabric:
- Körs som körbar gäst. Detta används främst för att köra befintliga ASP.NET Core-program på Service Fabric utan kodändringar.
- Kör i en tillförlitlig tjänst. Detta möjliggör bättre integrering med Service Fabric-körningen och tillåter tillståndskänsliga ASP.NET Core-tjänster.
Körbara gästfiler
En körbar gäst är en befintlig, godtycklig körbar fil (skriven på alla språk) som finns i ett Service Fabric-kluster tillsammans med andra tjänster. Körbara gästprogram integreras inte direkt med Service Fabric-API:er. Men de drar fortfarande nytta av funktioner som plattformen erbjuder, till exempel anpassad hälso- och belastningsrapportering och tjänstidentifiering genom att anropa REST-API:er. De har också fullständig support för programmets livscykel.
Programlivscykel
Precis som med andra plattformar går ett program på Service Fabric vanligtvis igenom följande faser: design, utveckling, testning, distribution, uppgradering, underhåll och borttagning. Service Fabric ger förstklassigt stöd för hela programlivscykeln för molnprogram, från utveckling till distribution, daglig hantering och underhåll till eventuell avveckling. Tjänstmodellen gör det möjligt för flera olika roller att delta oberoende i programmets livscykel. Service Fabric-programmets livscykel ger en översikt över API:erna och hur de används av de olika rollerna under faserna i Service Fabric-programmets livscykel.
Hela appens livscykel kan hanteras med PowerShell-cmdletar, CLI-kommandon, C#-API:er, Java-API:er och REST-API:er. Du kan också konfigurera pipelines för kontinuerlig integrering/kontinuerlig distribution med hjälp av verktyg som Azure Pipelines eller Jenkins.
Se den här länken för en träningsvideo som beskriver hur du hanterar programmets livscykel:
Testa program och tjänster
För att skapa verkligt molnskalade tjänster är det viktigt att kontrollera att dina program och tjänster klarar verkliga fel. Felanalystjänsten är utformad för att testa tjänster som bygger på Service Fabric. Med Tjänsten för felanalys kan du inducera meningsfulla fel och köra fullständiga testscenarier mot dina program. Dessa fel och scenarier övar och validerar de många tillstånd och övergångar som en tjänst kommer att uppleva under hela sin livstid, allt på ett kontrollerat, säkert och konsekvent sätt.
Åtgärder riktar in sig på en tjänst för testning med hjälp av enskilda fel. En tjänstutvecklare kan använda dessa som byggstenar för att skriva komplicerade scenarier. Exempel på simulerade fel är:
- Starta om en nod för att simulera valfritt antal situationer där en dator eller virtuell dator startas om.
- Flytta en replik av din tillståndskänsliga tjänst för att simulera belastningsutjämning, redundans eller programuppgradering.
- Anropa kvorumförlust på en tillståndskänslig tjänst för att skapa en situation där skrivåtgärder inte kan fortsätta eftersom det inte finns tillräckligt med "säkerhetskopiering" eller "sekundära" repliker för att acceptera nya data.
- Anropa dataförlust på en tillståndskänslig tjänst för att skapa en situation där allt minnesinternt tillstånd är helt rensat.
Scenarier är komplexa åtgärder som består av en eller flera åtgärder. Tjänsten Felanalys innehåller två inbyggda kompletta scenarier:
- Kaosscenario – simulerar kontinuerliga, interfolierade fel (både graciösa och ospårbara) i hela klustret under längre tidsperioder.
- Redundansscenario – en version av kaostestscenariot som riktar sig mot en specifik tjänstpartition samtidigt som andra tjänster inte påverkas.
Kluster
Ett Service Fabric-kluster är en nätverksansluten uppsättning virtuella eller fysiska datorer som dina mikrotjänster distribueras till och hanteras från. Kluster kan skalas upp till tusentals datorer. En dator eller virtuell dator som ingår i ett kluster kallas för en klusternod. Varje nod har tilldelats ett nodnamn (en sträng). Noder har egenskaper, till exempel placeringsegenskaper. Varje dator eller virtuell dator har en tjänst för automatisk start, FabricHost.exe, som börjar köras vid start och sedan startar två körbara filer: Fabric.exe och FabricGateway.exe. Dessa två körbara filer utgör noden. För testscenarier kan du vara värd för flera noder på en enda dator eller virtuell dator genom att köra flera instanser av Fabric.exe och FabricGateway.exe.
Service Fabric-kluster kan skapas på virtuella eller fysiska datorer som kör Windows Server eller Linux. Du kan distribuera och köra Service Fabric-program i alla miljöer där du har en uppsättning Windows Server- eller Linux-datorer som är sammankopplade: lokalt, i Microsoft Azure eller på valfri molnleverantör.
Kluster i Azure
Att köra Service Fabric-kluster i Azure ger integrering med andra Azure-funktioner och -tjänster, vilket gör driften och hanteringen av klustret enklare och mer tillförlitlig. Ett kluster är en Azure Resource Manager-resurs, så du kan modellera kluster som andra resurser i Azure. Resource Manager ger också enkel hantering av alla resurser som används av klustret som en enda enhet. Kluster i Azure är integrerade med Azure-diagnostik och Azure Monitor-loggar. Klusternodtyper är vm-skalningsuppsättningar, så funktioner för automatisk skalning är inbyggda.
Du kan skapa ett kluster i Azure via Azure-portalen, från en mall eller från Visual Studio.
Med Service Fabric i Linux kan du skapa, distribuera och hantera högtillgängliga, mycket skalbara program i Linux precis som i Windows. Service Fabric-ramverken (Reliable Services och Reliable Actors) är tillgängliga i Java i Linux, förutom C# (.NET Core). Du kan också skapa körbara gästtjänster med valfritt språk eller ramverk. Orkestrering av Docker-containrar stöds också. Docker-containrar kan köra körbara gästprogram eller interna Service Fabric-tjänster, som använder Service Fabric-ramverken. Mer information finns i Om Service Fabric på Linux.
Det finns vissa funktioner som stöds i Windows, men inte i Linux. Mer information finns i Skillnader mellan Service Fabric i Linux och Windows.
Fristående kluster
Service Fabric tillhandahåller ett installationspaket som du kan använda för att skapa fristående Service Fabric-kluster lokalt eller på valfri molnleverantör. Fristående kluster ger dig friheten att vara värd för ett kluster var du vill. Om dina data omfattas av efterlevnads- eller regelbegränsningar, eller om du vill hålla dina data lokala, kan du vara värd för ditt eget kluster och program. Service Fabric-program kan köras i flera värdmiljöer utan ändringar, så dina kunskaper om att skapa program överförs från en värdmiljö till en annan.
Skapa ditt första fristående Service Fabric-kluster
Fristående Linux-kluster stöds ännu inte.
Klustersäkerhet
Kluster måste skyddas för att förhindra att obehöriga användare ansluter till klustret, särskilt när det finns produktionsarbetsbelastningar som körs på det. Även om det är möjligt att skapa ett osäkert kluster kan anonyma användare ansluta till det om hanteringsslutpunkter exponeras för det offentliga Internet. Det går inte att senare aktivera säkerhet i ett osäkert kluster: klustersäkerhet aktiveras när klustret skapas.
Klustersäkerhetsscenarierna är:
- Säkerhet från nod till nod
- Säkerhet från klient till nod
- Rollbaserad åtkomstkontroll för Service Fabric
Mer information finns i Skydda ett kluster.
Skalning
Om du lägger till nya noder i klustret balanserar Service Fabric om partitionsreplikerna och instanserna över det ökade antalet noder. Övergripande programprestanda förbättras och konkurrensen om åtkomst till minne minskar. Om noderna i klustret inte används effektivt kan du minska antalet noder i klustret. Service Fabric balanserar återigen om partitionsreplikerna och instanserna över det minskade antalet noder för att bättre använda maskinvaran på varje nod. Du kan skala kluster i Azure manuellt eller programmatiskt. Fristående kluster kan skalas manuellt.
Klusteruppgraderingar
Med jämna mellanrum släpps nya versioner av Service Fabric-körningen. Utför körnings- eller infrastrukturuppgraderingar på klustret så att du alltid kör en version som stöds. Förutom infrastrukturuppgraderingar kan du även uppdatera klusterkonfigurationen, till exempel certifikat eller programportar.
Ett Service Fabric-kluster är en resurs som du äger, men som delvis hanteras av Microsoft. Microsoft ansvarar för att korrigera det underliggande operativsystemet och utföra infrastrukturuppgraderingar i klustret. Du kan ange att klustret ska ta emot automatiska infrastrukturuppgraderingar när Microsoft släpper en ny version eller välja en infrastrukturversion som stöds. Infrastrukturresurser och konfigurationsuppgraderingar kan ställas in via Azure-portalen eller via Resource Manager. Mer information finns i Uppgradera ett Service Fabric-kluster.
Ett fristående kluster är en resurs som du äger helt och hållet. Du ansvarar för att korrigera det underliggande operativsystemet och initiera infrastrukturuppgraderingar. Om klustret kan ansluta till https://www.microsoft.com/downloadkan du ställa in klustret på att automatiskt ladda ned och etablera det nya Service Fabric-körningspaketet. Sedan initierar du uppgraderingen. Om klustret inte kan komma åt https://www.microsoft.com/downloadkan du manuellt ladda ned det nya körningspaketet från en internetansluten dator och sedan starta uppgraderingen. Mer information finns i Uppgradera ett fristående Service Fabric-kluster.
Hälsoövervakning
Service Fabric introducerar en hälsomodell som är utformad för att flagga feltillstånd för kluster och programvillkor på specifika entiteter (till exempel klusternoder och tjänstrepliker). Hälsomodellen använder hälsoreportrar (systemkomponenter och vakthundar). Målet är enkel och snabb diagnos och reparation. Tjänstförfattare måste tänka i förväg om hälsa och hur du utformar hälsorapportering. Alla villkor som kan påverka hälsan bör rapporteras på, särskilt om det kan hjälpa till att flagga problem nära roten. Hälsoinformationen kan spara tid och arbete med felsökning och undersökning när tjänsten är igång och körs i stor skala i produktion.
Service Fabric-reportrarna övervakar identifierade intressevillkor. De rapporterar om dessa villkor baserat på deras lokala vy. Hälsolagret aggregerar hälsodata som skickas av alla reportrar för att avgöra om entiteter är globalt felfria. Modellen är avsedd att vara omfattande, flexibel och lätt att använda. Hälsorapporternas kvalitet avgör precisionen i klustrets hälsovy. Falska positiva identifieringar som felaktigt visar problem med fel kan påverka uppgraderingar eller andra tjänster som använder hälsodata negativt. Exempel på sådana tjänster är reparationstjänster och aviseringsmekanismer. Därför behövs en viss tanke för att tillhandahålla rapporter som fångar in intresseförhållanden på bästa möjliga sätt.
Rapportering kan göras från:
- Den övervakade Service Fabric-tjänstrepliken eller instansen.
- Interna vakthundar som distribueras som en Service Fabric-tjänst (till exempel en tillståndslös Service Fabric-tjänst som övervakar villkor och utfärdar rapporter). Vakthundarna kan distribueras på alla noder eller kopplas till den övervakade tjänsten.
- Interna vakthundar som körs på Service Fabric-noderna men som inte implementeras som Service Fabric-tjänster.
- Externa vakthundar som avsöker resursen utanför Service Fabric-klustret (till exempel övervakningstjänsten som Gomez).
Service Fabric-komponenter rapporterar hälsotillståndet för alla entiteter i klustret. Systemhälsorapporter ger insyn i kluster- och programfunktioner och flaggar problem via hälsa. För program och tjänster verifierar systemhälsorapporter att entiteter implementeras och fungerar korrekt ur Service Fabric-körningens perspektiv. Rapporterna tillhandahåller ingen hälsoövervakning av tjänstens affärslogik eller identifierar processer som har slutat svara. Om du vill lägga till hälsoinformation som är specifik för tjänstens logik implementerar du anpassad hälsorapportering i dina tjänster.
Service Fabric innehåller flera sätt att visa hälsorapporter aggregerade i hälsoarkivet:
- Service Fabric Explorer eller andra visualiseringsverktyg.
- Hälsofrågor (via PowerShell, CLI, C# FabricClient-API:er och Java FabricClient-API:er eller REST-API:er).
- Allmänna frågor som returnerar en lista över entiteter som har hälsotillstånd som en av egenskaperna (via PowerShell, CLI, API:er eller REST).
Övervakning och diagnostik
Övervakning och diagnostik är avgörande för att utveckla, testa och distribuera program och tjänster i alla miljöer. Service Fabric-lösningar fungerar bäst när du planerar och implementerar övervakning och diagnostik som hjälper till att säkerställa att program och tjänster fungerar som förväntat i en lokal utvecklingsmiljö eller i produktion.
Huvudmålen med övervakning och diagnostik är att:
- Identifiera och diagnostisera maskinvaru- och infrastrukturproblem
- Identifiera programvaru- och appproblem, minska tjänstavbrott
- Förstå resursförbrukning och hjälpa till att driva driftsbeslut
- Optimera program-, tjänst- och infrastrukturprestanda
- Generera affärsinsikter och identifiera förbättringsområden
Det övergripande arbetsflödet för övervakning och diagnostik består av tre steg:
- Händelsegenerering: Detta omfattar händelser (loggar, spårningar, anpassade händelser) på infrastrukturnivå (kluster), plattform och program/tjänstnivå
- Händelsesammansättning: genererade händelser måste samlas in och aggregeras innan de kan visas
- Analys: händelser måste visualiseras och vara tillgängliga i något format för att kunna analyseras och visas efter behov
Flera produkter är tillgängliga som täcker dessa tre områden, och du kan välja olika tekniker för var och en. Mer information finns i Övervakning och diagnostik för Azure Service Fabric.
Nästa steg
- Lär dig hur du skapar ett kluster i Azure eller ett fristående kluster i Windows.
- Prova att skapa en tjänst med hjälp av programmeringsmodellerna Reliable Services eller Reliable Actors.
- Lär dig hur du migrerar från Cloud Services.
- Lär dig hur du övervakar och diagnostiserar tjänster.
- Lär dig att testa dina appar och tjänster.
- Lär dig hur du hanterar och samordnar klusterresurser.
- Titta igenom Service Fabric-exemplen.
- Läs mer om service fabric-supportalternativ.
- Läs teambloggen för artiklar och meddelanden.