Öğretici: Azure HDInsight'ta Apache Spark makine öğrenmesi uygulaması oluşturma
Bu öğreticide Jupyter Notebook'u kullanarak Azure HDInsight için apache Spark makine öğrenmesi uygulaması oluşturmayı öğreneceksiniz.
MLlib , Spark'ın yaygın öğrenme algoritmaları ve yardımcı programlarından oluşan uyarlanabilir makine öğrenmesi kitaplığıdır. (Sınıflandırma, regresyon, kümeleme, işbirliğine dayalı filtreleme ve boyutsallık azaltma. Ayrıca temel iyileştirme temelleri.)
Bu öğreticide aşağıdakilerin nasıl yapılacağını öğreneceksiniz:
- Apache Spark makine öğrenmesi uygulaması geliştirme
Önkoşullar
HDInsight üzerinde bir Apache Spark kümesi. Bkz . Apache Spark kümesi oluşturma.
HDInsight üzerinde Spark ile Jupyter Notebook kullanma bilgisi. Daha fazla bilgi için bkz . HDInsight üzerinde Apache Spark ile veri yükleme ve sorgu çalıştırma.
Veri kümesini anlamak
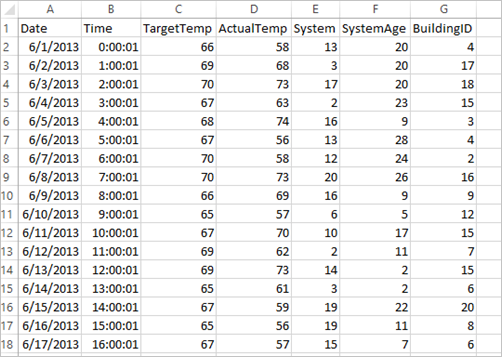
Uygulama, varsayılan olarak tüm kümelerde kullanılabilen örnek HVAC.csv verilerini kullanır. Dosya konumunda \HdiSamples\HdiSamples\SensorSampleData\hvacbulunur. Veriler, HVAC sistemlerinin yüklü olduğu bazı binaların hedef sıcaklığı ile gerçek sıcaklığını gösterir. System sütunu sistem kimliğini, SystemAge sütunu ise HVAC sisteminin binada kaç yıldır kullanıldığını ifade eder. Bir binanın hedef sıcaklığa, sistem kimliğine ve sistem yaşına göre daha sıcak mı yoksa daha soğuk mu olacağını tahmin edebilirsiniz.
Spark MLlib kullanarak Spark makine öğrenimi uygulaması geliştirme
Bu uygulama, belge sınıflandırması yapmak için Spark ML işlem hattı kullanır. ML İşlem Hatları, DataFrame'lerin üzerinde oluşturulmuş tekdüzen bir üst düzey API kümesi sağlar. DataFrame'ler kullanıcıların pratik makine öğrenmesi işlem hatları oluşturmalarına ve ayarlamalarına yardımcı olur. İşlem hattında, belgeyi sözcüklere böler, sözcükleri sayısal bir özellik vektörüne dönüştürür ve son olarak özellik vektörleri ile etiketleri kullanarak bir tahmin modeli oluşturursunuz. Uygulamayı oluşturmak için aşağıdaki adımları uygulayın.
PySpark çekirdeğini kullanarak bir Jupyter Not Defteri oluşturun. Yönergeler için bkz . Jupyter Notebook dosyası oluşturma.
Bu senaryo için gereken türleri içeri aktarın. Aşağıdaki kod parçacığını boş bir hücreye yapıştırın ve sonra SHIFT + ENTER tuşlarına basın.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayVerileri yükleyin (hvac.csv), ayrıştırın ve modeli eğitmek için kullanın.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()Kod parçacığında gerçek sıcaklığı hedef sıcaklıkla karşılaştıran bir işlev tanımlarsınız. Gerçek sıcaklık büyükse, 1.0 değeriyle gösterildiği gibi bina sıcaktır. Aksi takdirde, 0,0 değeriyle gösterildiği gibi bina soğuktur.
Üç aşamadan oluşan Spark makine öğrenmesi işlem hattını yapılandırın:
tokenizer,hashingTFvelr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])İşlem hattı ve nasıl çalıştığı hakkında daha fazla bilgi için bkz . Apache Spark makine öğrenmesi işlem hattı.
İşlem hattını eğitim belgesine uygun hale getirin.
model = pipeline.fit(training)Uygulama ile gerçekleştirdiğiniz ilerlemeyi kontrol etmek için eğitim belgesini doğrulayın.
training.show()Çıktı şuna benzer olacaktır:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Çıktıyı ham CSV dosyasıyla karşılaştırın. Örneğin, CSV dosyasının bu verileri içeren ilk satırı:

Binanın soğuk olduğunu göstermek üzere gerçek sıcaklığın hedef sıcaklıktan az olduğuna dikkat edin. İlk satırdaki etiket değeri 0,0'dır ve bu da binanın sıcak olmadığı anlamına gelir.
Eğitilen modeli çalıştırmak için bir veri kümesi hazırlayın. Bunu yapmak için bir sistem kimliği ve sistem yaşı geçirirsiniz (eğitim çıktısında SystemInfo olarak belirtilir). Model, bu sistem kimliğine ve sistem yaşına sahip binanın daha sıcak mı (1,0 ile belirtilir) yoksa daha soğuk mu (0,0 ile belirtilir) olacağını tahmin eder.
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Son olarak, test verileri üzerinde tahminlerde bulunun.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Çıktı şuna benzer olacaktır:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Tahmindeki ilk satırı gözlemleyin. Kimliği 20 ve sistem yaşı 25 olan bir HVAC sistemi için bina sıcaktır (tahmin=1.0). Birinci DenseVector değeri (0.49999) 0.0 tahminine, ikinci değer (0.5001) ise 1.0 tahminine karşılık gelir. Çıktıda ikinci değer yalnızca çok az yüksek olsa bile model tahmin = 1.0 değerini gösterir.
Kaynakları serbest bırakmak için not defterini kapatın. Bunu yapmak için not defterindeki Dosya menüsünde Kapat ve Durdur’u seçin. Bu eylem, not defterini kapatır.
Spark makine öğrenimi için Anaconda scikit-learn kitaplığını kullanma
HDInsight’ta Apache Spark kümeleri, Anaconda kitaplıklarını içerir. Ayrıca, makine öğrenimi scikit-learn kitaplığını içerir. Kitaplık ayrıca doğrudan Jupyter Notebook'tan örnek uygulamalar oluşturmak için kullanabileceğiniz çeşitli veri kümeleri içerir. scikit-learn kitaplığını kullanma örnekleri için bkz. https://scikit-learn.org/stable/auto_examples/index.html.
Kaynakları temizleme
Bu uygulamayı kullanmaya devam etmeyecekseniz, aşağıdaki adımlarla oluşturduğunuz kümeyi silin:
Azure Portal’ında oturum açın.
Üstteki Arama kutusuna HDInsight yazın.
Hizmetler'in altında HDInsight kümeleri'ne tıklayın.
Görüntülenen HDInsight kümeleri listesinde, bu öğretici için oluşturduğunuz kümenin yanındaki ... öğesini seçin.
Sil'i seçin. Evet'i seçin.
Sonraki adımlar
Bu öğreticide Jupyter Notebook'u kullanarak Azure HDInsight için apache Spark makine öğrenmesi uygulaması oluşturmayı öğrendiniz. Spark işleri için IntelliJ IDEA kullanma hakkında bilgi edinmek üzere sonraki öğreticiye ilerleyin.