Jupyter Notebook'u bilgisayarınıza yükleyin ve HDInsight üzerinde Apache Spark'a bağlanın
Bu makalede, Spark magic ile özel PySpark (Python için) ve Apache Spark (Scala için) çekirdekleriyle Jupyter Notebook'u yüklemeyi öğreneceksiniz. Ardından not defterini bir HDInsight kümesine bağlarsınız.
Jupyter'ı yükleme ve HDInsight üzerinde Apache Spark'a bağlanma konusunda dört önemli adım vardır.
- Spark kümesini yapılandırın.
- Jupyter Notebook'u yükleyin.
- Spark sihri ile PySpark ve Spark çekirdeklerini yükleyin.
- HDInsight'ta Spark kümesine erişmek için Spark magic'i yapılandırın.
Özel çekirdekler ve Spark sihri hakkında daha fazla bilgi için bkz . HDInsight üzerinde Apache Spark Linux kümeleri ile Jupyter Notebooks için kullanılabilir çekirdekler.
Önkoşullar
HDInsight üzerinde bir Apache Spark kümesi. Yönergeler için bkz. Azure HDInsight'ta Apache Spark kümeleri oluşturma. Yerel not defteri HDInsight kümesine bağlanır.
HDInsight üzerinde Spark ile Jupyter Notebook kullanma bilgisi.
Jupyter Notebook'u bilgisayarınıza yükleme
Jupyter Notebooks'u yüklemeden önce Python'ı yükleyin. Anaconda dağıtımı hem Python hem de Jupyter Notebook'u yükler.
Platformunuzun Anaconda yükleyicisini indirin ve kurulumu çalıştırın. Kurulum sihirbazını çalıştırırken, PATH değişkeninize Anaconda ekleme seçeneğini belirlediğinizden emin olun. Ayrıca bkz. Anaconda kullanarak Jupyter'ı yükleme.
Spark magic'i yükleme
HDInsight kümeleri sürüm 3.6 ve 4.0 için Spark magic'i yüklemek için komutunu
pip install sparkmagic==0.13.1girin. Ayrıca bkz . sparkmagic belgeleri.Aşağıdaki komutu çalıştırarak düzgün yüklendiğinden emin olun
ipywidgets:jupyter nbextension enable --py --sys-prefix widgetsnbextension
PySpark ve Spark çekirdeklerini yükleme
Aşağıdaki komutu girerek yüklendiği yeri
sparkmagicbelirleyin:pip show sparkmagicArdından çalışma dizininizi yukarıdaki komutla tanımlanan konuma değiştirin.
Yeni çalışma dizininizden, istenen çekirdekleri yüklemek için aşağıdaki komutlardan birini veya daha fazlasını girin:
Çekirdek Command Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelisteğe bağlı. Sunucu uzantısını etkinleştirmek için aşağıdaki komutu girin:
jupyter serverextension enable --py sparkmagic
HDInsight Spark kümesine bağlanmak için Spark büyüsünü yapılandırma
Bu bölümde, apache Spark kümesine bağlanmak için daha önce yüklediğiniz Spark büyüsünü yapılandıracaksınız.
Python kabuğunu aşağıdaki komutla başlatın:
pythonJupyter yapılandırma bilgileri genellikle kullanıcıların giriş dizininde depolanır. Giriş dizinini tanımlamak için aşağıdaki komutu girin ve .sparkmagic adlı bir klasör oluşturun. Tam yol çıkarılır.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()klasöründe
.sparkmagic, config.json adlı bir dosya oluşturun ve içine aşağıdaki JSON parçacığını ekleyin.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Dosyada aşağıdaki düzenlemeleri yapın:
Şablon değeri Yeni değer {USERNAME} Küme oturum açma, varsayılan olarak şeklindedir admin.{CLUSTERDNSNAME} Küme adı {BASE64ENCODEDPASSWORD} Gerçek parolanız için base64 ile kodlanmış bir parola. adresinde https://www.url-encode-decode.com/base64-encode-decode/bir base64 parolası oluşturabilirsiniz. "livy_server_heartbeat_timeout_seconds": 60Kullanıyorsanız sparkmagic 0.12.7tutun (kümeler v3.5 ve v3.6). kullanıyorsanızsparkmagic 0.2.3(kümeler v3.4), yerine ile"should_heartbeat": truedeğiştirin.Örnek config.json tam bir örnek dosya görebilirsiniz.
İpucu
Sinyaller, oturumların sızdırılmadığından emin olmak için gönderilir. Bir bilgisayar uyku moduna geçtiğinde veya kapatıldığında sinyal gönderilmez ve oturum temizlenir. v3.4 kümelerinde, bu davranışı devre dışı bırakmak isterseniz Livy yapılandırmasını
livy.server.interactive.heartbeat.timeoutAmbari kullanıcı arabiriminden olarak0ayarlayabilirsiniz. v3.5 kümeleri için yukarıdaki 3.5 yapılandırmasını ayarlamazsanız oturum silinmez.Jupyter'ı başlatın. Komut isteminden aşağıdaki komutu kullanın.
jupyter notebookÇekirdeklerle kullanılabilen Spark büyüsünü kullanabileceğinizi doğrulayın. Aşağıdaki adımları tamamlayın.
a. Yeni bir not defteri oluşturun. Sağ köşeden Yeni'yi seçin. Varsayılan Python 2 veya Python 3 çekirdeğini ve yüklediğiniz çekirdekleri görmeniz gerekir. Gerçek değerler, yükleme seçimlerinize bağlı olarak değişebilir. PySpark'ı seçin.
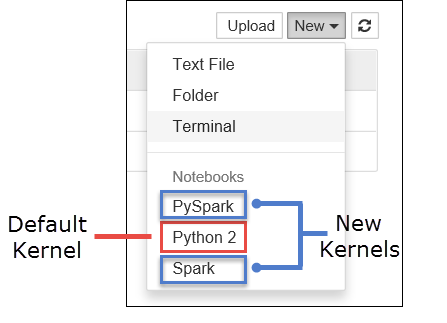
Önemli
Yeni'yi seçtikten sonra herhangi bir hata için kabuğunuzu gözden geçirin. Hatayı
TypeError: __init__() got an unexpected keyword argument 'io_loop'görürseniz Tornado'nun belirli sürümlerinde bilinen bir sorun yaşıyor olabilirsiniz. Öyleyse, çekirdeği durdurun ve aşağıdaki komutla Tornado yüklemenizi düşürun:pip install tornado==4.5.3.b. Aşağıdaki kod parçacığını çalıştırın.
%%sql SELECT * FROM hivesampletable LIMIT 5Çıktıyı başarıyla alabilirseniz HDInsight kümesine bağlantınız test edilir.
Not defteri yapılandırmasını farklı bir kümeye bağlanacak şekilde güncelleştirmek istiyorsanız, config.json yukarıdaki 3. Adımda gösterildiği gibi yeni değer kümesiyle güncelleştirin.
Jupyter'i neden bilgisayarıma yüklemeliyim?
Jupyter'ı bilgisayarınıza yükleme ve hdInsight'ta apache Spark kümesine bağlama nedenleri:
- Not defterlerinizi yerel olarak oluşturma, uygulamanızı çalışan bir kümede test etme ve ardından not defterlerini kümeye yükleme seçeneği sağlar. Not defterlerini kümeye yüklemek için, çalıştıran Jupyter Notebook'u veya kümeyi kullanarak bunları karşıya yükleyebilir veya kümeyle ilişkilendirilmiş depolama hesabındaki klasöre kaydedebilirsiniz
/HdiNotebooks. Not defterlerinin kümede nasıl depolandığı hakkında daha fazla bilgi için bkz . Jupyter Notebook'lar nerede depolanır? - Not defterleri yerel olarak kullanılabilir durumdaysa, uygulama gereksinimlerinize göre farklı Spark kümelerine bağlanabilirsiniz.
- GitHub'ı kullanarak bir kaynak denetim sistemi uygulayabilir ve not defterleri için sürüm denetimine sahip olabilirsiniz. Birden çok kullanıcının aynı not defteriyle çalışabileceği işbirliğine dayalı bir ortamınız da olabilir.
- Kümeyi bile kurmadan not defterleriyle yerel olarak çalışabilirsiniz. Not defterlerinizi veya geliştirme ortamınızı el ile yönetmek için değil, yalnızca not defterlerinizi test etmek için bir kümeye ihtiyacınız vardır.
- Kendi yerel geliştirme ortamınızı yapılandırmak, kümede Jupyter yüklemesini yapılandırmaktan daha kolay olabilir. Bir veya daha fazla uzak küme yapılandırmadan yerel olarak yüklediğiniz tüm yazılımlardan yararlanabilirsiniz.
Uyarı
Yerel bilgisayarınızda Jupyter yüklü olduğunda, birden çok kullanıcı aynı not defterini aynı Spark kümesinde aynı anda çalıştırabilir. Böyle bir durumda birden çok Livy oturumu oluşturulur. Bir sorunla karşılaşırsanız ve bu sorunun hatalarını ayıklamak istiyorsanız, hangi Livy oturumunu hangi kullanıcıya ait olduğunu izlemek karmaşık bir görev olacaktır.