HDInsight üzerinde Apache Spark kümelerinde Jupyter Notebooks ile dış paketleri kullanma
HDInsight üzerinde Apache Spark kümesinde Jupyter Notebook'u, kümede kullanıma alınmamış dış, topluluk tarafından katkıda bulunan Apache maven paketlerini kullanacak şekilde yapılandırmayı öğrenin.
Kullanılabilir paketlerin tam listesi için Maven deposunda arama yapabilirsiniz. Diğer kaynaklardan kullanılabilir paketlerin listesini de alabilirsiniz. Örneğin, topluluk tarafından katkıda bulunulmuş paketlerin tam listesi Spark Packages'da bulunabilir.
Bu makalede, Spark-CSV paketini Jupyter Notebook ile kullanmayı öğreneceksiniz.
Önkoşullar
HDInsight üzerinde bir Apache Spark kümesi. Yönergeler için bkz. Azure HDInsight'ta Apache Spark kümeleri oluşturma.
HDInsight üzerinde Spark ile Jupyter Notebook kullanma bilgisi. Daha fazla bilgi için bkz . HDInsight üzerinde Apache Spark ile veri yükleme ve sorgu çalıştırma.
Kümelerinizin birincil depolama alanı için URI şeması.
wasb://Bu,abfs://Azure Data Lake Storage 2. Nesil için Azure Depolama içindir. Azure Depolama veya Data Lake Storage 2. Nesil için güvenli aktarım etkinleştirildiyse, URI sırasıyla veyaabfss://olurwasbs://. Ayrıca bkz. güvenli aktarım.
Jupyter Notebooks ile dış paketleri kullanma
https://CLUSTERNAME.azurehdinsight.net/jupyterSpark kümenizin adı olan yereCLUSTERNAMEgidin.Yeni bir not defteri oluşturun. Yeni'yi ve ardından Spark'ı seçin.
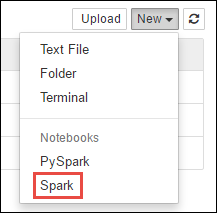
Yeni bir not defteri oluşturulur ve Untitled.pynb adı ile açılır. Üst kısımdaki not defteri adını seçin ve kolay bir ad girin.
Not defterini bir dış paket kullanacak şekilde yapılandırmak için bu sihri kullanacaksınız
%%configure. Dış paketlerin kullanıldığı not defterlerinde, ilk kod hücresinde sihri çağırdığınızdan%%configureemin olun. Bu, çekirdeğin oturum başlamadan önce paketi kullanacak şekilde yapılandırılmasını sağlar.Önemli
İlk hücrede çekirdeği yapılandırmayı unutursanız parametresiyle komutunu
-fkullanabilirsiniz%%configure, ancak bu işlem oturumu yeniden başlatır ve tüm ilerlemeler kaybolur.HDInsight sürümü Command HDInsight 3.5 ve HDInsight 3.6 için %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}HDInsight 3.3 ve HDInsight 3.4 için %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Yukarıdaki kod parçacığı Maven Central Repository'deki dış paket için maven koordinatlarını bekler. Bu kod parçacığında spark-csv
com.databricks:spark-csv_2.11:1.5.0paketi için maven koordinatı yer alır. Bir paket için koordinatları şöyle oluşturursunuz.a. Maven Deposunda paketi bulun. Bu makale için spark-csv kullanırız.
b. Depodan GroupId, ArtifactId ve Version değerlerini toplayın. Topladığınız değerlerin kümenizle eşleştiğinden emin olun. Bu durumda Scala 2.11 ve Spark 1.5.0 paketi kullanıyoruz, ancak kümenizdeki uygun Scala veya Spark sürümü için farklı sürümler seçmeniz gerekebilir. Spark Jupyter çekirdeğinde veya Spark göndermede komutunu çalıştırarak
scala.util.Properties.versionStringkümenizdeki Scala sürümünü öğrenebilirsiniz. Jupyter Notebooks üzerinde çalıştıraraksc.versionkümenizdeki Spark sürümünü öğrenebilirsiniz.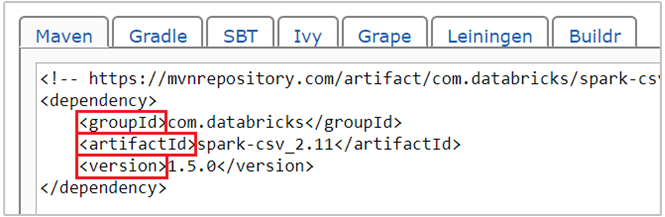
c. Üç değeri iki nokta üst üste (:) ile ayırarak birleştirir.
com.databricks:spark-csv_2.11:1.5.0Kod hücresini sihirle
%%configureçalıştırın. Bu işlem, sağladığınız paketi kullanmak için temel livy oturumunu yapılandıracaktır. Not defterindeki sonraki hücrelerde, aşağıda gösterildiği gibi paketi kullanabilirsiniz.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")HDInsight 3.4 ve altı için aşağıdaki kod parçacığını kullanmanız gerekir.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Ardından kod parçacıklarını aşağıda gösterildiği gibi çalıştırarak önceki adımda oluşturduğunuz veri çerçevesindeki verileri görüntüleyebilirsiniz.
df.show() df.select("Time").count()
Ayrıca bkz.
Senaryolar
- BI ile Apache Spark: BI araçlarıyla HDInsight'ta Spark kullanarak etkileşimli veri analizi gerçekleştirme
- Machine Learning ile Apache Spark: HVAC verilerini kullanarak bina sıcaklığını analiz etmek için HDInsight'ta Spark kullanma
- Machine Learning ile Apache Spark: Gıda denetimi sonuçlarını tahmin etmek için HDInsight'ta Spark kullanma
- HDInsight'ta Apache Spark kullanarak web sitesi günlük analizi
Uygulamaları oluşturma ve çalıştırma
- Scala kullanarak tek başına uygulama oluşturma
- Apache Livy kullanarak apache Spark kümesinde işleri uzaktan çalıştırma
Araçlar ve uzantılar
- HDInsight Linux üzerinde Apache Spark kümelerinde Jupyter Notebooks ile dış Python paketlerini kullanma
- Spark Scala uygulamaları oluşturmak ve göndermek amacıyla IntelliJ IDEA için HDInsight Araçları Eklentisini kullanma
- Apache Spark uygulamalarında uzaktan hata ayıklamak için IntelliJ IDEA için HDInsight Araçları Eklentisi'ni kullanma
- HDInsight üzerinde Apache Spark kümesiyle Apache Zeppelin not defterlerini kullanma
- HDInsight için Apache Spark kümesinde Jupyter Notebook için kullanılabilir çekirdekler
- Jupyter’i bilgisayarınıza yükleme ve bir HDInsight Spark kümesine bağlanma