Azure HDInsight'ta Apache Spark kümesiyle Apache Zeppelin not defterlerini kullanma
HDInsight Spark kümeleri Apache Zeppelin not defterlerini içerir. Apache Spark işlerini çalıştırmak için not defterlerini kullanın. Bu makalede, HDInsight kümesinde Zeppelin not defterini kullanmayı öğreneceksiniz.
Önkoşullar
- HDInsight üzerinde bir Apache Spark kümesi. Yönergeler için bkz. Azure HDInsight'ta Apache Spark kümeleri oluşturma.
- Kümelerinizin birincil depolama alanı için URI şeması. Şema Azure Blob Depolama,
abfs://Azure Data Lake Storage 2. Nesil veyaadl://Azure Data Lake Storage 1. Nesil için olabilirwasb://. Blob Depolama için güvenli aktarım etkinleştirilirse, URI olacaktırwasbs://. Daha fazla bilgi için bkz. Azure Depolama'de güvenli aktarım gerektirme.
Apache Zeppelin not defterini başlatma
Spark kümesine Genel Bakış'tan Küme panolarından Zeppelin not defteri'ni seçin. Kümenin yönetici kimlik bilgilerini girin.
Not
Ayrıca, tarayıcınızda aşağıdaki URL'yi açarak kümenizin Zeppelin Not Defteri'ne de ulaşabilirsiniz. CLUSTERNAME değerini kümenizin adıyla değiştirin:
https://CLUSTERNAME.azurehdinsight.net/zeppelinYeni bir not defteri oluşturun. Üst bilgi bölmesinde Not Defteri>Yeni not oluştur'a gidin.
Not defteri için bir ad girin ve Not Oluştur'u seçin.
Not defteri üst bilgisinin bağlı bir durum gösterdiğinden emin olun. Sağ üst köşedeki yeşil noktayla gösterilir.
Örnek verilerini geçici bir tabloya yükleyin. HDInsight'ta bir Spark kümesi oluşturduğunuzda, örnek veri dosyası
hvac.csvaltında\HdiSamples\SensorSampleData\hvacilişkili depolama hesabına kopyalanır.Yeni not defterinde varsayılan olarak oluşturulan boş paragrafa aşağıdaki kod parçacığını yapıştırın.
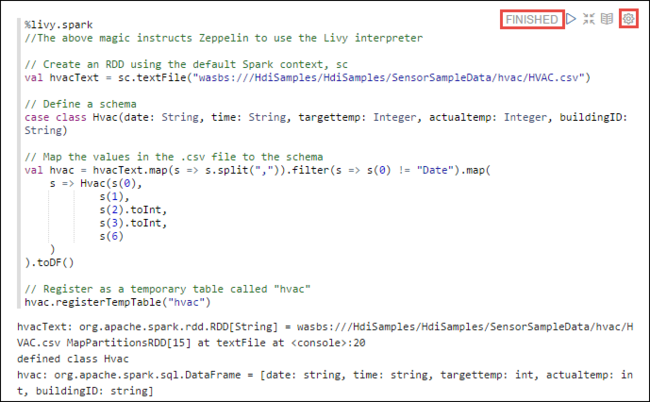
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Kod parçacığını çalıştırmak için SHIFT + ENTER tuşlarına basın veya paragrafın Yürüt düğmesini seçin. Paragrafın sağ köşesindeki durum HAZIR, BEKLENİYOR, ÇALıŞTıRILIYOR durumundan TAMAMLANDı durumuna ilerlemelidir. Çıkış, aynı paragrafın en altında gösterilir. Ekran görüntüsü aşağıdaki görüntüye benzer:
Ayrıca her paragrafa bir başlık da sağlayabilirsiniz. Paragrafın sağ köşesinden Ayarlar simgesini (dişli) ve ardından Başlığı göster'i seçin.
Not
Tüm HDInsight sürümlerinde Zeppelin not defterlerinde %spark2 yorumlayıcısı ve HDInsight 4.0'dan sonra %sh yorumlayıcısı desteklenmez.
Artık tabloda Spark SQL deyimlerini
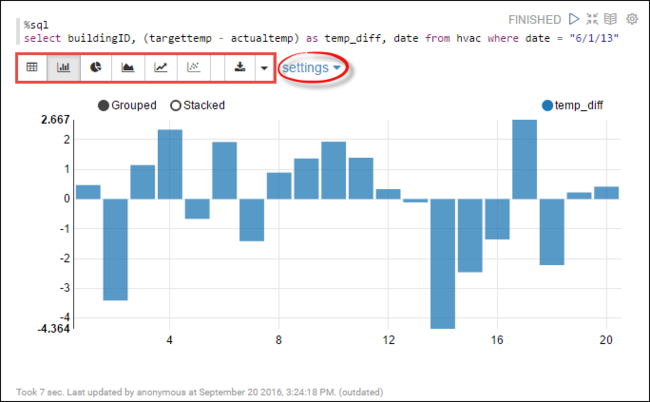
hvacçalıştırabilirsiniz. Aşağıdaki sorguyu yeni bir paragrafa yapıştırın. Sorgu, yapı kimliğini alır. Ayrıca, belirli bir tarihte her bina için hedef ve gerçek sıcaklıklar arasındaki fark. SHIFT + ENTER tuşlarına basın.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"Başlangıçtaki %sql deyimi not defterine Livy Scala yorumlayıcısını kullanmasını söyler.
Ekranı değiştirmek için Çubuk Grafik simgesini seçin. ayarlar Çubuk Grafik'i seçtikten sonra görünür, Anahtarlar ve Değerler'i seçmenize olanak tanır. Aşağıdaki ekran görüntüsünde çıkış gösterilmektedir.
Sorgudaki değişkenleri kullanarak Spark SQL deyimlerini de çalıştırabilirsiniz. Sonraki kod parçacığında sorguda,
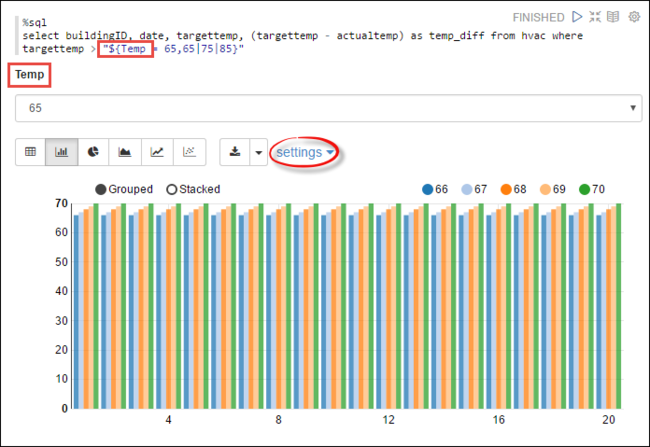
Tempsorgulamak istediğiniz olası değerleri içeren bir değişkenin nasıl tanımlanacağı gösterilir. Sorguyu ilk kez çalıştırdığınızda, değişken için belirttiğiniz değerlerle otomatik olarak bir açılan menü doldurulur.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Bu kod parçacığını yeni bir paragrafa yapıştırın ve SHIFT + ENTER tuşlarına basın. Ardından Geçici açılan listesinden 65'i seçin.
Ekranı değiştirmek için Çubuk Grafik simgesini seçin. Ardından ayarları seçin ve aşağıdaki değişiklikleri yapın:
Gruplar: Targettemp ekleyin.
Değerler: 1. Tarihi kaldırın. 2. temp_diff ekleyin. 3. Toplayıcıyı SUM olan AVG olarak değiştirin.
Aşağıdaki ekran görüntüsünde çıkış gösterilmektedir.
Not defteriyle dış paketler Nasıl yaparım??
HDInsight üzerinde Apache Spark kümesindeki Zeppelin not defteri, kümeye dahil olmayan dış, topluluk tarafından katkıda bulunan paketleri kullanabilir. Kullanılabilir paketlerin tam listesini Maven deposunda arayın. Diğer kaynaklardan kullanılabilir paketlerin listesini de alabilirsiniz. Örneğin, topluluk tarafından katkıda bulunulmuş paketlerin tam listesi Spark Packages'da bulunabilir.
Bu makalede, Spark-CSV paketini Jupyter Notebook ile nasıl kullanacağınızı göreceksiniz.
Yorumlayıcı ayarlarını açın. Sağ üst köşeden oturum açmış kullanıcı adını ve ardından Yorumlayıcı'yı seçin.
Livy2'ye kaydırın ve düzenle'yi seçin.
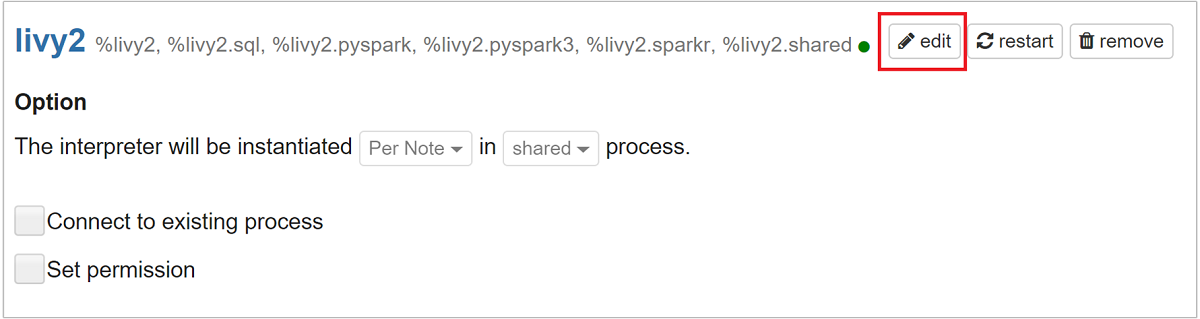
anahtarına
livy.spark.jars.packagesgidin ve değerini biçimindegroup:id:versionayarlayın. Bu nedenle, spark-csv paketini kullanmak istiyorsanız anahtarının değerini olarakcom.databricks:spark-csv_2.10:1.4.0ayarlamanız gerekir.
Livy yorumlayıcısını yeniden başlatmak için Kaydet'i ve ardından Tamam'ı seçin.
Yukarıda girilen anahtarın değerine nasıl ulaşabileceğinizi anlamak istiyorsanız, bunu şu şekilde yapabilirsiniz.
a. Maven Deposunda paketi bulun. Bu makalede spark-csv kullandık.
b. Depodan GroupId, ArtifactId ve Version değerlerini toplayın.
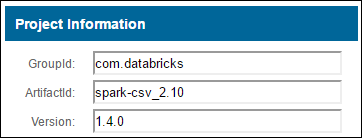
c. Üç değeri iki nokta üst üste (:) ile ayırarak birleştirir.
com.databricks:spark-csv_2.10:1.4.0
Zeppelin not defterleri nereye kaydedilir?
Zeppelin not defterleri küme baş düğümlerine kaydedilir. Bu nedenle, kümeyi silerseniz not defterleri de silinir. Not defterlerinizi daha sonra diğer kümelerde kullanmak üzere korumak istiyorsanız, işleri çalıştırmayı bitirdikten sonra bunları dışarı aktarmanız gerekir. Not defterini dışarı aktarmak için aşağıdaki resimde gösterildiği gibi Dışarı Aktar simgesini seçin.
Bu eylem, not defterini indirme konumunuza JSON dosyası olarak kaydeder.
Not
HDI 4.0'da zeppelin not defteri dizin yolu şu şekildedir:
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Örn. /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
HDI 5.0 ve üzeri gibi bu yol farklı olduğunda
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Örn. /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Depolanan dosya adı HDI 5.0'da farklıdır. Şu şekilde depolanır:
<notebook_name>_<sessionid>.zplnÖrn. testzeppelin_2JJK53XQA.zpln
HDI 4.0'da dosya adı yalnızca session_id dizininde depolanan note.json.
Örn. /2JMC9BZ8X/note.json
HDI Zeppelin, not defterini her zaman hn0 yerel diskindeki yola
/usr/hdp/<version>/zeppelin/notebook/kaydeder.Not defterinin küme silme işleminden sonra bile kullanılabilir olmasını istiyorsanız, azure dosya depolamayı (SMB protokolunu kullanarak) kullanmayı ve yerel yola bağlamayı deneyebilirsiniz. Daha fazla ayrıntı için bkz . Linux'ta SMB Azure dosya paylaşımını bağlama
Bağladıktan sonra zeppelin yapılandırmasını zeppelin.notebook.dir dosyasını ambari kullanıcı arabirimindeki bağlı yola değiştirebilirsiniz.
- GitNotebookRepo depolama alanı olarak SMB dosya paylaşımı, zeppelin sürüm 0.10.1 için önerilmez
Kurumsal Güvenlik Paketi (ESP) Kümelerinde Zeppelin Yorumlayıcılarına Erişimi Yapılandırmak için Kullanın Shiro
Yukarıda belirtildiği gibi, %sh yorumlayıcı HDInsight 4.0'dan itibaren desteklenmez. Ayrıca, %sh yorumlayıcı kabuk komutlarını kullanarak erişim tuş sekmeleri gibi olası güvenlik sorunları ortaya çıkardığından HDInsight 3.6 ESP kümelerinden de kaldırılmıştır. Bu, Yeni not oluştur'a tıklandığında veya Varsayılan olarak Yorumlayıcı kullanıcı arabiriminde yorumlayıcının kullanılamadığı anlamına gelir%sh.
Ayrıcalıklı etki alanı kullanıcıları, Yorumlayıcı kullanıcı arabirimine erişimi denetlemek için dosyayı kullanabilir Shiro.ini . Yalnızca bu kullanıcılar yeni %sh yorumlayıcılar oluşturabilir ve her yeni %sh yorumlayıcı üzerinde izinler ayarlayabilir. Dosyayı kullanarak shiro.ini erişimi denetlemek için aşağıdaki adımları kullanın:
Var olan bir etki alanı grubu adını kullanarak yeni bir rol tanımlayın. Aşağıdaki örnekte,
adminGroupNameAAD'de ayrıcalıklı bir kullanıcı grubu verilmiştir. Grup adında özel karakterler veya boşluklar kullanmayın. Sonrasındaki karakterler=bu rol için izinler verir.*, grubun tam izinlere sahip olduğu anlamına gelir.[roles] adminGroupName = *Zeppelin yorumlayıcılarına erişim için yeni rolü ekleyin. Aşağıdaki örnekte, içindeki
adminGroupNametüm kullanıcılara Zeppelin yorumlayıcılarına erişim verilir ve yeni yorumlayıcılar oluşturabilir. içindeki köşeli ayraçlarınroles[]arasına virgülle ayırarak birden çok rol koyabilirsiniz. Ardından, gerekli izinlere sahip kullanıcılar Zeppelin yorumlayıcılarına erişebilir.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Birden çok etki alanı grubu için örnek shiro.ini:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy oturum yönetimi
Zeppelin not defterinizdeki ilk kod paragrafı kümenizde yeni bir Livy oturumu oluşturur. Bu oturum, daha sonra oluşturduğunuz tüm Zeppelin not defterleri arasında paylaşılır. Livy oturumu herhangi bir nedenle öldürülürse işler Zeppelin not defterinden çalıştırılamaz.
Böyle bir durumda, işleri Bir Zeppelin not defterinden çalıştırmaya başlamadan önce aşağıdaki adımları gerçekleştirmeniz gerekir.
Zeppelin not defterinden Livy yorumlayıcısını yeniden başlatın. Bunu yapmak için sağ üst köşeden oturum açmış kullanıcı adını seçip Yorumlayıcı'yı seçerek yorumlayıcı ayarlarını açın.
Livy2'ye kaydırın ve yeniden başlat'ı seçin.
Mevcut bir Zeppelin not defterinden kod hücresi çalıştırma. Bu kod, HDInsight kümesinde yeni bir Livy oturumu oluşturur.
Genel bilgiler
Hizmeti doğrulama
Ambari'den hizmeti doğrulamak için https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary CLUSTERNAME'in kümenizin adı olduğu yere gidin.
Hizmeti bir komut satırından doğrulamak için SSH'den baş düğüme. komutunu sudo su zeppelinkullanarak kullanıcıyı zeppelin'e geçin. Durum komutları:
| Komut | Açıklama |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Hizmet durumu. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Hizmet sürümü. |
ps -aux | grep zeppelin |
PID'i tanımlayın. |
Günlük konumları
| Hizmet | Yol |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Sunucu Günlükleri | /var/log/zeppelin |
Yapılandırma Yorumlayıcısı, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf veya /etc/zeppelin/conf |
| PID dizini | /var/run/zeppelin |
Hata ayıklama günlüğüne kaydetmeyi etkinleştirme
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summaryCLUSTERNAME'in kümenizin adı olduğu yere gidin.CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content gidin.
olarak
log4j.appender.dailyfile.Threshold = DEBUGdeğiştirinlog4j.appender.dailyfile.Threshold = INFO.ekleyin
log4j.logger.org.apache.zeppelin.realm=DEBUG.Değişiklikleri kaydedin ve hizmeti yeniden başlatın.