原生 GPU 柵欄物件
本文說明 GPU 柵欄同步處理物件,可用於 GPU 硬體排程階段 2 中真正的 GPU 對 GPU 同步處理。 從 Windows 11 版本 24H2 (WDDM 3.2) 開始支援此功能。 圖形驅動程式開發人員應該熟悉 WDDM 2.0 和 GPU 硬體排程階段 1。
現有與新的柵欄同步處理物件
現有受監視的柵欄同步處理物件
WDDM 2.x 的 受監視圍欄同步處理物件 支援下列作業:
- CPU 等候受監視的柵欄值,其方式為:
- 使用 CPU 虛擬地址進行輪詢 (VA)。
- 佇列在 Dxgkrnl 內等候封鎖,當 CPU 觀察新的受監視柵欄值時,就會收到訊號。
- 受監視值的CPU訊號。
- 寫入受監視柵欄 GPU VA 並引發受監視的柵欄訊號,發出已監視的柵欄訊號,以通知 CPU 值更新。
不支援的是原生 ON-GPU 等候受監視的柵欄值。 相反地,OS 會保留視 CPU 上等候的值而定的 GPU 工作。 它只會在發出值訊號時,將此工作發行至 GPU。
GPU 原生柵欄同步處理物件
本文介紹支援下列新增功能的受監視柵欄對象的擴充功能:
- GPU 等候受監視的柵欄值,其允許高效能的引擎對引擎同步處理,而不需要 CPU 往返。
- 條件式中斷通知僅適用於具有 CPU 等候者的 GPU 柵欄訊號。 此功能可讓 CPU 在所有 GPU 工作排入佇列時進入低電源狀態,來節省大量電源。
- 隔離 GPU 本機記憶體中的值記憶體(與系統記憶體相反)。
GPU 原生柵欄同步對象設計
下圖說明 GPU 原生柵欄物件的基本架構,著重於 CPU 與 GPU 之間共用的同步處理對象狀態。
: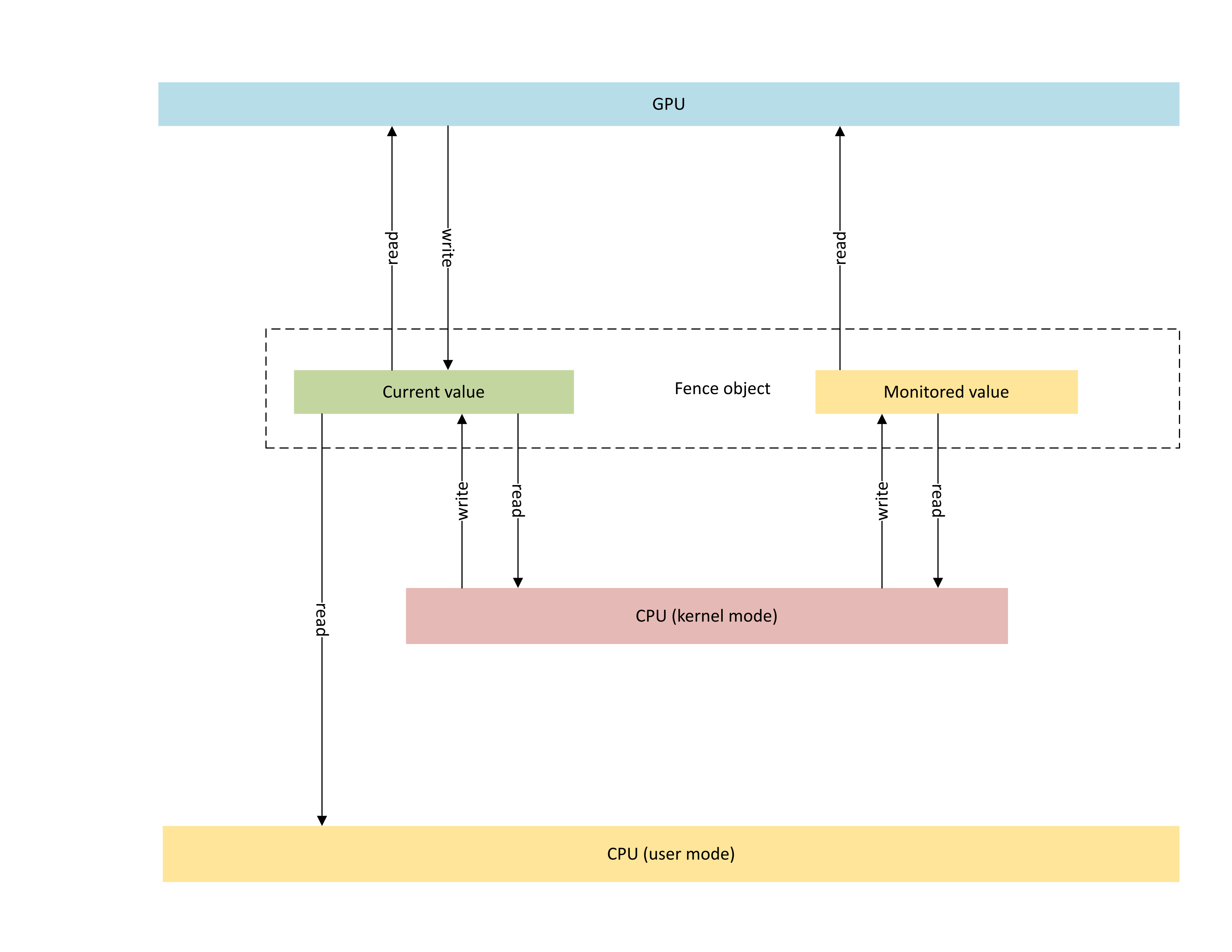
此圖表包含兩個主要元件:
目前值(在本文中稱為 CurrentValue )。 此記憶體位置包含目前發出訊號的64位柵欄值。 CurrentValue 可對應且可存取 CPU(可從核心模式寫入、可從使用者和核心模式讀取)和 GPU(可使用 GPU 虛擬位址讀取和可寫入)。 CurrentValue 需要從 CPU 和 GPU 觀點進行不可部分完成的 64 位寫入。 也就是說,高位和低 32 位的更新無法被撕毀,而且應該同時顯示。 此概念已存在於現有的受監視柵欄物件中。
受監視的值(在本文中稱為 MonitoredValue )。 此記憶體位置包含 CPU 減去 1 的值目前等候最少的值。 MonitoredValue 可對應且可存取 CPU(可從核心模式讀取和可寫入、沒有使用者模式存取權)和 GPU(可使用 GPU VA 讀取、無寫入存取權)。 OS 會維護指定柵欄物件的未處理 CPU 等候程式清單,並在新增和移除等候程式時更新 MonitoredValue 。 當沒有任何未完成的等候者時,值會設定為 UINT64_MAX。 這個概念是 GPU 原生柵欄同步物件的新功能。
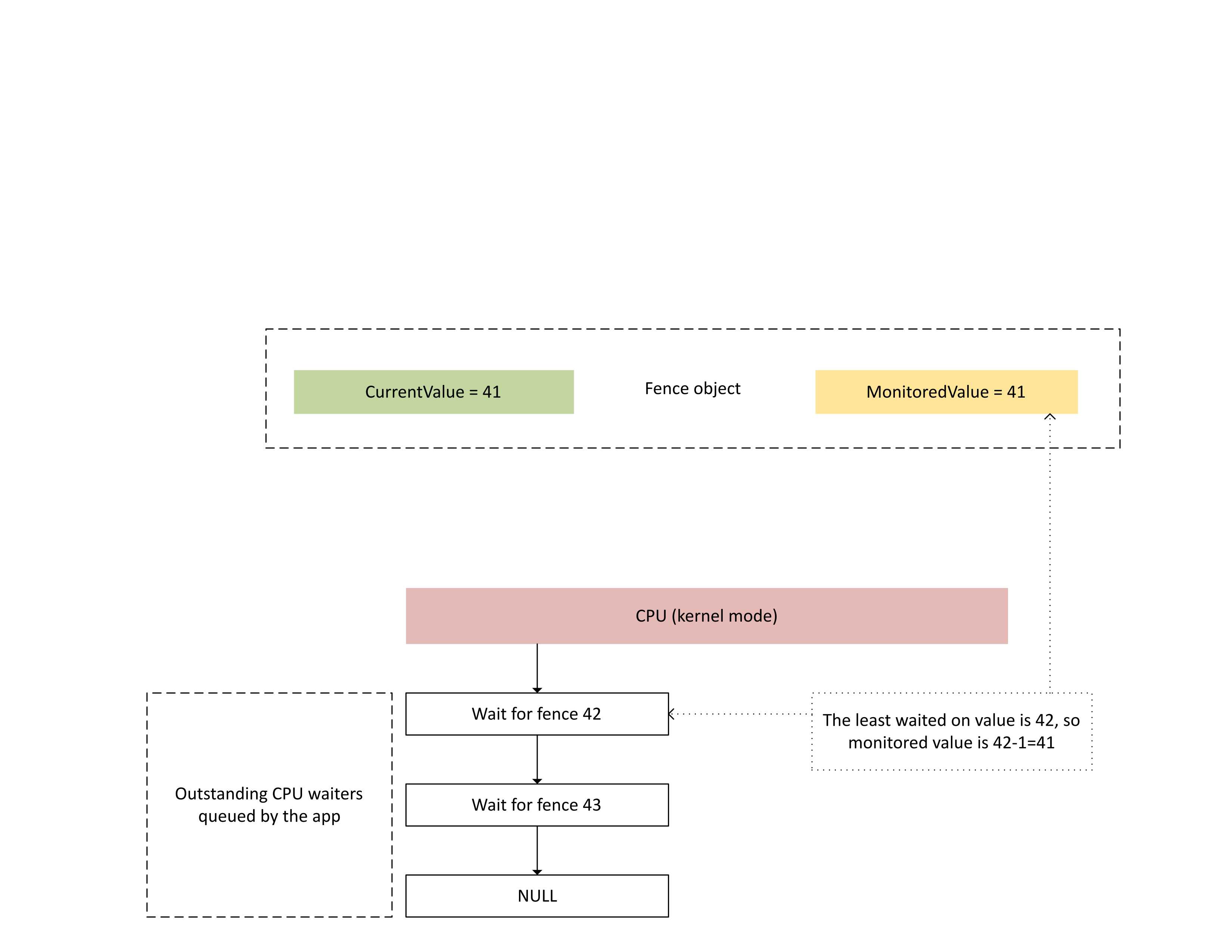
下圖說明 Dxgkrnl 如何追蹤特定受監視柵欄值上未處理的 CPU 等候者。 它也會在指定的時間點顯示受監視的柵欄值。 CurrentValue 和 MonitoredValue 都是 41,這表示:
- GPU 已完成最多 41 個柵欄值的所有工作。
- CPU 不會等候任何小於或等於 41 的柵欄值。
:
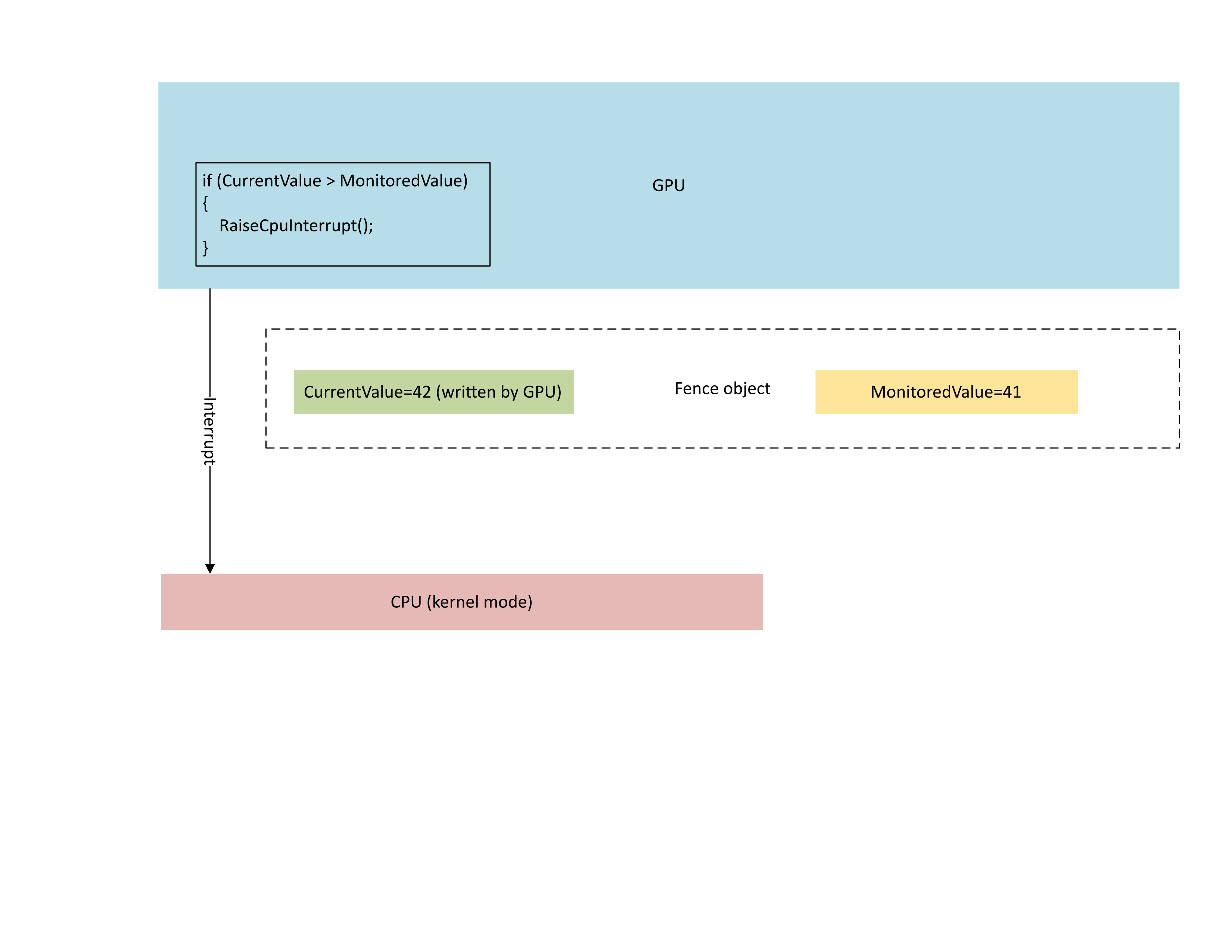
下圖說明 GPU 的內容管理處理器 (CMP) 只有在新的柵欄值大於受監視的值時,才會有條件地引發 CPU 中斷。 這類中斷表示有未完成的CPU等候程式可以滿足新寫入的值。
:
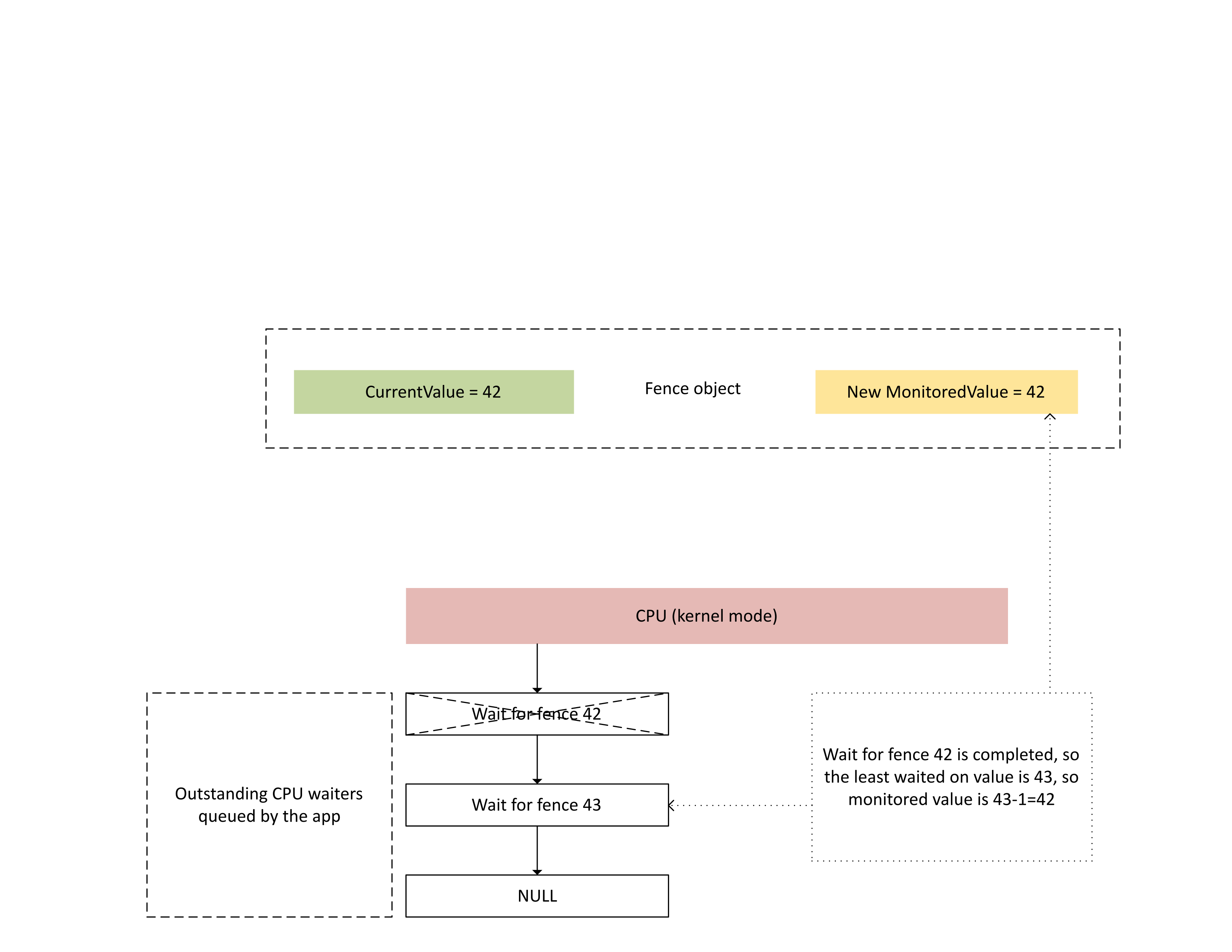
當 CPU 處理此中斷時, Dxgkrnl 會執行下列動作,如下圖所示:
- 它會解除封鎖對新寫入的柵欄感到滿意的 CPU 服務員。
- 它會將受監視的值往前推進,以對應到減去 1 的值時最不未完成的等候值。
:
目前和受監視柵欄值的實體記憶體記憶體
針對指定的柵欄物件, CurrentValue 和 MonitoredValue 會儲存在不同的位置。
無法共享的柵欄物件在相同記憶體頁面中封裝的相同進程內,針對不同柵欄對象的隔離值儲存區。 這些值會根據本文稍後所述的原生柵欄 KMD 上限中指定的步幅值進行封裝。
可共享的物件,其目前和受監視的值會放在未與其他柵欄對象共用的記憶體頁面中。
目前的值
目前的值可以位於系統記憶體或 GPU 本機記憶體中。
針對系統記憶體,OS 會從內部系統記憶體集區配置目前的值記憶體。
針對本機記憶體柵欄,OS 會從 DXGK_NATIVE_FENCE_CAPS 中指定的本機記憶體段配置目前的值記憶體,如原生柵欄功能中所述。
受監視的值
受監視的值也可以位於系統或 GPU 本機記憶體中。
針對系統記憶體隔離,OS 會從內部系統記憶體集區配置受監視的值記憶體。
針對本機記憶體柵欄,OS 會從 DXGK_NATIVE_FENCE_CAPS 中指定的本機記憶體區段配置受監視的值記憶體,如原生柵欄功能中所述。
當 OS 的 CPU 等候條件變更時,它會呼叫 KMD 的 DxgkDdiUpdateMonitoredValues 回呼,將受監視的值更新為指定的值。
同步處理問題
先前描述的機制在 CPU 和 GPU 讀取和寫入目前值與受監視的值之間具有固有的競爭條件。 如果未特別小心,可能會發生下列問題:
- GPU 可以讀取過時 的 MonitoredValue ,而不會如 CPU 預期般引發中斷。
- GPU 引擎可以在 CMP 處於決定中斷條件的中間時,撰寫較新的 CurrentValue 。 這個較 新的 CurrentValue 可能不會如預期般引發中斷,或可能無法在 CPU 擷取目前值時看見。
引擎與 CMP 之間的 GPU 內同步處理
為了提高效率,許多離散 GPU 會使用位於 GPU 本機記憶體中的陰影狀態,在下列區域之間實作受監視的圍欄訊號語意:
執行命令緩衝區數據流的 GPU 引擎,並有條件地向 CMP 發出硬體訊號。
決定是否應該引發 CPU 中斷的 GPU CMP。
在此情況下,CMP 必須與執行記憶體寫入至柵欄值的 GPU 引擎同步處理記憶體存取。 特別是,更新陰影 MonitoredValue 的作業應該使用下列步驟,從 CMP 觀點排序:
- 撰寫新的 MonitoredValue (陰影 GPU 記憶體)
- 執行記憶體屏障以同步處理與 GPU 引擎的記憶體存取
- Read CurrentValue:
- 如果 CurrentValue>MonitoredValue,請引發 CPU 中斷。
- 如果 CurrentValue<= MonitoredValue,請勿引發 CPU 中斷。
若要讓此競爭條件正確解決,步驟 2 中的記憶體屏障必須正常運作。 步驟 3 中不得有來自步驟 1 中未看到 MonitoredValue 更新的命令所產生之 CurrentValue 的暫止記憶體寫入作業。 因此,如果步驟 3 中寫入的柵欄大於步驟 1 中更新的值,則這種情況會產生中斷。
GPU 與 CPU 之間的同步處理
CPU 必須執行 MonitoredValue 的更新,並讀取 CurrentValue 的方式不會遺失實時訊號的中斷通知。
- 當新的 CPU 等候程式新增至系統時,OS 必須修改 MonitoredValue ,或現有 CPU 等候程式已淘汰時。
- OS 會呼叫 DxgkDdiUpdateMonitoredValues ,以通知 GPU 新的受監視值。
- DxgkDdiUpdateMonitoredValue 會在裝置中斷層級執行,因此會與受監視的柵欄訊號中斷服務例程 (ISR) 同步處理。
- DxgkDdiUpdateMonitoredValue 必須保證傳回之後,GPU CMP 在觀察到新的 MonitoredValue 之後,由 GPU CMP 讀取的 CurrentValue。
- 從 DxgkDdiUpdateMonitoredValue 傳回時,OS 會重新取樣 CurrentValue,並滿足新 CurrentValue 解除封鎖的任何等候者。
CPU 可以完全接受觀察較新的 CurrentValue,而不是 GPU 用來決定是否引發中斷的 CurrentValue 。 這種情況偶爾會導致中斷通知,不會解除封鎖任何服務員。 無法接受的是 CPU 不會收到受監視的最新 CurrentValue 更新中斷通知(也就是 CurrentValue> MonitoredValue)。
在OS中查詢原生柵欄功能啟用
KMD 引進下列介面,以查詢 OS 是否已啟用原生柵欄功能:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
如同硬體排程階段 1 和硬體翻轉佇列功能,驅動程式必須在驅動程式初始化期間查詢作業系統中是否啟用原生柵欄功能。 不過,從WDDM 3.2 開始,OS 會使用新增 的WDDM功能支援和啟用功能 來控制是否啟用此功能。 因此,驅動程式必須實作這個介面。
在 KMD 在DXGK_VIDSCHCAPS公告原生柵欄支援之前,KMD 應該實作DXGKDDI_FEATURE_INTERFACE介面,並查詢操作系統是否啟用DXGK_FEATURE_NATIVE_FENCE功能。 如果 KMD 在 OS 未啟用此功能時公告原生柵欄支援,OS 就會失敗適配卡初始化。
OS 會實作專用於第 1 版DXGK_FEATURE_NATIVE_FENCE的新增DXGKCB_FEATURE_NATIVEFENCE_CAPS_1介面數據表。 KMD 必須查詢此功能介面數據表,以判斷 OS 的功能。 在未來的OS版本中,OS可能會導入此介面數據表的未來版本,詳細說明新功能的支援。
查詢支援的範例驅動程式程式代碼
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
原生柵欄功能
下列介面會更新或引進來查詢原生圍欄上限:
NativeGpuFence 字段會新增至 DXGK_VIDSCHCAPS。 如果操作系統啟用DXGK_FEATURE_NATIVE_FENCE功能,驅動程式可以在適配卡初始化期間宣告支援原生 GPU 柵欄功能,方法是將 DXGK_VIDSCHCAPS::NativeGpuFence 位設定為 1。
DXGKQAITYPE_NATIVE_FENCE_CAPS會新增至 DXGK_QUERYADAPTERINFOTYPE。
Dxgkrnl 透過新增的對應 D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported 結構/位,將此功能公開給使用者模式。
KMTQAITYPE_WDDM_3_1_CAPS會新增至 KMTQUERYADAPTERINFOTYPE。
KMD 會新增下列實體,以指出其原生 GPU 柵欄功能的支援功能。
DXGK_NATIVE_FENCE_CAPS結構描述 GPU 的原生柵欄功能。 當 KMD 設定此結構的 MapToGpuSystemProcess 位時,它會指示 OS 保留系統進程 GPU 虛擬地址空間以供 CMP 使用,並建立 GPU VA 對應到原生柵欄 CurrentValue 和 MonitoredValue 的該地址空間。 這些 GPU VA 稍後會傳遞至 KMD 的柵欄建立回呼,DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa 和 MonitoredValueSystemProcessGpuVa。
KMD 會傳回其填入DXGK_NATIVE_FENCE_CAPS結構,當其 DxgkDdiQueryAdapterInfo 函式使用新增DXGKQAITYPE_NATIVE_FENCE_CAPS查詢配接器資訊類型呼叫時。
用來建立、開啟、關閉及終結原生柵欄物件的 KMD DIS
引進下列 KMD 實作的 DIS 來建立、開啟、關閉及終結原生柵欄物件。 Dxgkrnl 代表使用者模式元件呼叫這些 DIS。 只有在操作系統啟用DXGK_FEATURE_NATIVE_FENCE功能時,Dxgkrnl 才會呼叫它們。
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiCreateNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
已更新下列 DIS 以支援原生柵欄物件:
下列成員已新增至 DRIVER_INITIALIZATION_DATA。 支援原生 GPU 柵欄對象的驅動程式應該實作函式,並透過此結構提供 Dxgkrnl 的指標。
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (WDDM 3.1 中新增)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (WDDM 3.1 中新增)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (在 WDDM 3.2 中新增)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (WDDM 3.2 中新增)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (在 WDDM 3.2 中新增)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (WDDM 3.2 中新增)
共享柵欄的全域和本機句柄
想像一下進程 A 會建立共用原生柵欄,然後處理 B 會開啟此柵欄。
當行程 A 建立共用原生柵欄時,Dxgkrnl 會呼叫 DxgkDdiCreateNativeFence 與建立此柵欄的配接器驅動程式句柄。 在 hGlobalNativeFence 中建立和傳回的柵欄句柄是全局柵欄控點。
Dxgkrnl 接著接著呼叫 DxgkDdiOpenNativeFence 以開啟進程 A 特定的本機句柄(hLocalNativeFenceA)。
當進程 B 開啟相同的共用原生柵欄時, Dxgkrnl 會呼叫 DxgkDdiOpenNativeFence 來開啟進程 B 特定的本機句柄(hLocalNativeFenceB)。
如果進程 A 終結其共用原生柵欄實例,Dxgkrnl 就會看到此全域柵欄仍有暫止參考,因此只會呼叫 DxgkDdiCloseNativeFence(hLocalNativeFence A),讓驅動程式清除進程 A 特定結構。 hGlobalNativeFence 句柄仍然存在。
當處理 B 終結其柵欄實例時,Dxgkrnl 會呼叫 DxgkDdiCloseNativeFence(hLocalNativeFenceB),然後呼叫 DxgkDdiDestroyNativeFence(hGlobalNativeFence)以允許 KMD 終結其全域柵欄數據。
CMP 使用分頁進程位址空間中的 GPU VA 對應
KMD 會在硬體上設定 DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess 上限,這些硬體需要原生柵欄 GPU VA 也對應到 GPU 分頁進程地址空間。 設定 MapToGpuSystemProcess 位會指示 OS 在原生柵欄的 CurrentValue 和 MonitoredValue 的分頁進程地址空間中建立 GPU VA 對應,以供 CMP 使用。 這些 GPU VA 稍後會以 DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa 和 MonitoredValueSystemProcessGpuVa 的形式傳遞至 DxgkDdiCreateNativeFence。
原生柵欄的 D3DKMT 核心 API
引進下列 D3DKMT 核心模式 API 來建立和開啟原生柵欄物件。
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl 會呼叫現有的 D3DKMTDestroySynchronizationObject 函式來關閉和終結現有的原生柵欄物件。
引進或更新的支持結構和列舉包括:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
指出原生硬體佇列進度柵欄物件
引進下列更新以指出原生硬體佇列進度柵欄物件:
已針對對 DxgkDdiCreateHwQueue 的呼叫新增 NativeProgressFence 旗標。
- 在支持的系統上,OS 會將硬體佇列進度柵欄更新為原生柵欄。 當 OS 設定 NativeProgressFence 時,它會向 KMD 指出DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence 句柄指向先前使用 DxgkDdiCreateNativeFence 建立的原生 GPU 柵欄物件的驅動程式句柄。
原生柵欄發出中斷信號
中斷機制會進行下列變更,以支援原生柵欄信號中斷:
- DXGK_INTERRUPT_TYPE列舉會更新為具有DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED中斷類型。
- DXGKARGCB_NOTIFY_INTERRUPT_DATA 結構會更新為包含 NativeFenceSignaled 結構,以表示發出信號中斷的原生柵欄。 NativeFenceSignaled 可用來通知 OS,CPU 所監視的一組原生柵欄 GPU 物件在 GPU 引擎上發出訊號。 如果 GPU 能夠判斷具有作用中 CPU 等候程式之對象的確切子集,它會透過 pSignaledNativeFenceArray 傳遞此子集。 此陣列中的句柄必須是 Dxgkrnl 在 DxgkDdiCreateNativeFence 中傳遞至 KMD 的有效 hGlobalNativeFence 句柄。 將句柄傳遞至損毀的原生柵欄物件會導致錯誤檢查。
- DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS 結構會更新為包含 EvaluateLegacyMonitoredFences 成員。
GPU 可以在下列情況下傳遞 NULL pSignaledNativeFenceArray :
- GPU 無法判斷具有作用中 CPU 等候程式之對象的確切子集。
- 多個訊號中斷會折疊在一起,使得很難判斷具有作用中服務員的訊號集。
NULL 值會指示 OS 掃描所有未處理的原生 GPU 柵欄物件服務員。
OS 與驅動程式之間的合約是:如果 OS 具有作用中的 CPU 等候程式(如 MonitoredValue 所表示),且 GPU 引擎會將對象發出訊號給需要 CPU 中斷的值,GPU 必須採取下列其中一項動作:
- 在 pSignaledNativeFenceArray 中包含這個原生柵欄句柄。
- 使用 NULL pSignaledNativeFenceArray 引發 NativeFenceSignaled 中斷。
根據預設,當 KMD 以 NULL pSignaledNativeFenceArray 引發此中斷時,Dxgkrnl 只會掃描所有擱置中的原生圍欄服務員,而且不會掃描舊版受監視的圍欄服務員。 在無法區分舊版DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED和DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED的硬體上,KMD 一律只能引發引進的DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED中斷,pSignaledNativeFenceArray = NULL 和 EvaluateLegacyMonitoredFences = 1,這表示 OS 掃描所有服務員(舊版受監視的柵欄服務員和原生圍欄服務員)。
指示 KMD 更新值的批次
引進下列介面,指示 KMD 更新一批目前或受監視的值:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
交叉配接器原生柵欄
OS 必須支援建立跨適配卡原生柵欄,因為現有的 DX12 應用程式會建立和使用交叉配接器監視的柵欄。 如果這些應用程式的基礎佇列和排程切換至使用者模式提交,則其受監視的柵欄也必須切換至原生柵欄(使用者模式佇列不支援受監視的柵欄)。
必須建立具有類型 D3DDDI_NATIVEFENCE_TYPE_DEFAULT的交叉配接器柵欄。 否則, D3DKMTCreateNativeFence 會失敗。
所有 GPU 都會共用 CurrentValue 記憶體的相同複本,一律配置於系統記憶體中。 當運行時間在 GPU1 上建立交叉配接器原生柵欄,並在 GPU2 上開啟它時,兩個 GPU 上的 GPU VA 對應會指向相同的 CurrentValue 實體記憶體。
每個 GPU 都會取得自己的 MonitoredValue 複本。 因此, MonitoredValue 記憶體可以配置於系統記憶體或本機記憶體中。
交叉配接器原生柵欄必須解決 GPU1 正在等候 GPU2 發出訊號的原生柵欄的情況。 今天,沒有 GPU 對 GPU 訊號的概念;因此,OS 會透過向CPU發出 GPU1 的訊號,明確解析此條件。 將交叉配接器柵欄的 MonitoredValue 設定為 0,以達到此訊號。 然後,當 GPU2 發出原生柵欄訊號時,也會引發 CPU 中斷,讓 Dxgkrnl 更新 GPU1 上的 CurrentValue(使用 DxgkDdiUpdateCurrentValuesFromCpu 並設定為 TRUE 的 NotificationOnly 旗標),並解除封鎖該 GPU 的任何暫止 CPU/GPU 等候程式。
雖然 MonitoredValue 一律為 0,適用於跨適配卡原生柵欄,但在相同 GPU 上提交的等候和訊號仍可受益於 GPU 同步處理的速度較快。 不過,降低 CPU 中斷的電源優點會遺失,因為 CPU 中斷會無條件地引發,即使其他 GPU 上沒有 CPU 等候者或等候者也一樣。 這項取捨是為了讓跨配接器原生柵欄的設計和實作成本保持簡單。
OS 支援在 GPU1 上建立原生柵欄物件並在 GPU2 上開啟的案例,其中 GPU1 支援功能和 GPU2。 柵欄物件會以 GPU2 上的一般 MonitoredFence 開啟。
OS 支援在 GPU1 上建立一般受監視的柵欄物件,並在 GPU2 上以原生柵欄開啟,以支援此功能的案例。 柵欄物件會以 GPU2 上的原生柵欄開啟。
交叉配接器等候/訊號組合
下列子區段中的數據表會採用 iGPU 和 dGPU 系統的範例,並列出可從 CPU/GPU 進行原生柵欄等候/訊號的各種設定。 下列兩個案例會被視為:
- 這兩個 GPU 都支援原生柵欄。
- iGPU 不支援原生柵欄,但 dGPU 確實支援原生柵欄。
第二個案例也類似於這兩個 GPU 都支援原生柵欄的情況,但原生柵欄等候/訊號會提交至 iGPU 上的內核模式佇列。
從數據行選取一對等候和訊號,例如 WaitFromGPU - SignalFromGPU 或 WaitFromGPU - SignalFromCPU 等,即可讀取數據表。
實例 1
在案例 1 中,dGPU 和 iGPU 都支援原生柵欄。
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD 會在命令緩衝區中插入等候 hfence CurrentValue == 10 指令 | 運行時間呼叫 D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch 會在其原生柵欄 CPU 等候程式清單中追蹤此同步物件 | |||
| UMD 會在命令緩衝區中插入寫入 hFence CurrentValue = 10 個訊號指令 | 運行時間呼叫 D3DKMTSignalSynchronizationObjectFromCpu | ||
| 當 CurrentValue 寫入時,VidSch 會收到以 ISR 發出信號的原生柵欄(因為 MonitoredValue == 0 一律) | VidSch 呼叫 DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch 會將訊號 (hFence, 10) 傳播至 iGPU | VidSch 會將訊號 (hFence, 10) 傳播至 iGPU | ||
| VidSch 會接收傳播的訊號,並呼叫 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch 會接收傳播的訊號,並呼叫 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD 會重新掃描執行清單,以解除封鎖等候 hFence 的 HW 通道 | VidSch 透過發出KEVENT信號來解除封鎖CPU等候條件 |
案例 2a
在案例 2a 中,iGPU 不支援原生柵欄,但 dGPU 則支援。 iGPU 上會提交等候,並在 dGPU 上提交訊號。
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| 運行時間呼叫 D3DKMTWaitForSynchronizationObjectFromGpu | 運行時間呼叫 D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch 會在其受監視的柵欄等候清單中追蹤此同步物件 | VidSch 會追蹤此同步處理物件在其受監視的柵欄 CPU 等候程式清單標頭中 | ||
| UMD 會在命令緩衝區中插入寫入 hFence CurrentValue = 10 個訊號指令 | 運行時間呼叫 D3DKMTSignalSynchronizationObjectFromCpu | ||
| 當 CurrentValue 寫入時,VidSch 會收到 NativeFenceSignaledISR (因為 MV == 0 一律) | VidSch 呼叫 DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch 會將訊號 (hFence, 10) 傳播至 iGPU | VidSch 會將訊號 (hFence, 10) 傳播至 iGPU | ||
| VidSch 會接收傳播的訊號並觀察新的柵欄值 | VidSch 會接收傳播的訊號並觀察新的柵欄值 | ||
| VidSch 會掃描其受監視的柵欄等候清單,並解除封鎖軟體內容 | VidSch 會掃描其受監視的柵欄 CPU 等候程式清單前端,併發出 KEVENT 訊號來解除封鎖 CPU 等候 |
案例 2b
在案例 2b 中,原生柵欄支持維持不變(iGPU 不支援 dGPU。 這次會在 iGPU 上提交訊號,並在 dGPU 上提交等候。
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD 會在命令緩衝區中插入等候 hfence CurrentValue == 10 指令 | 運行時間呼叫 D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch 會在其原生柵欄 CPU 等候程式清單中追蹤此同步物件 | |||
| UMD 呼叫 D3DKMTSignalSynchronizationObjectFromGpu | UMD 呼叫 D3DKMTSignalSynchronizationObjectFromCpu | ||
| 當封包位於軟體內容的前端時, VidSch 會直接從 CPU 更新隔離值 | VidSch 會直接從 CPU 更新隔離值 | ||
| VidSch 會將訊號 (hFence, 10) 傳播至 dGPU | VidSch 會將訊號 (hFence, 10) 傳播至 dGPU | ||
| VidSch 會接收傳播的訊號,並呼叫 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch 會接收傳播的訊號,並呼叫 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD 會重新掃描執行清單,以解除封鎖等候 hFence 的 HW 通道 | VidSch 透過發出KEVENT信號來解除封鎖CPU等候條件 |
未來的 GPU 對 GPU 交叉配接器訊號
如同步處理問題中所述,針對跨適配卡原生柵欄,我們會因為無條件引發 CPU 中斷而失去電源。
在未來的版本中,OS 會開發基礎結構,以允許一個 GPU 上的 GPU 訊號透過寫入通用門鈴記憶體來中斷其他 GPU,讓其他 GPU 喚醒、處理其執行清單並解除封鎖就緒 HW 佇列。
這項工作的挑戰是設計:
- 常見的門鈴記憶體。
- GPU 可以寫入門鈴的智慧型手機承載或句柄,可讓其他 GPU 判斷發出信號的柵欄,使其只能掃描 HWQueues 的子集。
有了這樣的交叉配接器訊號,GPU 甚至可以共用相同原生柵欄記憶體複本(線性格式交叉配接器配置,類似於跨適配卡掃描配置),而所有 GPU 都會讀取和寫入。
原生柵欄記錄緩衝區設計
使用原生柵欄和使用者模式提交時, 當原生 GPU 等候和從 UMD 加入訊號時,Dxgkrnl 無法看見特定 HWQueue 的 GPU 上解除封鎖。 使用原生柵欄時,可以針對指定的柵欄隱藏受監視的柵欄發出中斷訊號。
:
需要重新建立柵欄作業的方式,如此 GPUView 映射所示。 深粉紅色的方塊是信號,淺粉色的方塊正在等待。 每個方塊會在 CPU 上提交作業至 Dxgkrnl 時開始,並在 Dxgkrnl 完成 CPU 上的作業時結束。 如此一來,我們就能夠研究命令的整個存留期。
因此,概括而言,需要記錄的每個 HWQueue 條件如下:
| Condition | 意義 |
|---|---|
| FENCE_WAIT_QUEUED | UMD 在命令佇列中插入 GPU 等候指令時的 CPU 時間戳 |
| FENCE_SIGNAL_QUEUED | 當 UMD 在命令佇列中插入 GPU 訊號指令時的 CPU 時間戳 |
| FENCE_SIGNAL_EXECUTED | 在 HWQueue 的 GPU 上執行訊號命令時的 GPU 時間戳 |
| FENCE_WAIT_UNBLOCKED | GPU 上滿足等候條件且 HWQueue 解除封鎖時的 GPU 時間戳 |
原生柵欄記錄緩衝區 DIS
引進下列 DDI、結構和列舉,以支援原生柵欄記錄緩衝區:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- 包含記錄項目的標頭和陣列的記錄緩衝區。 標頭會識別專案是否為等候或訊號,而每個專案都會識別作業類型(已執行或解除封鎖):
記錄緩衝區機制
Dxgkrnl 會為每個 HWQueue 配置兩個專用的 4 KB 記錄緩衝區。
- 一個用於記錄等候。
- 一個用於記錄訊號。
這些記錄緩衝區具有核心模式 CPU VA (LogBufferCpuVa)、進程地址空間中的 GPU VA (LogBufferGpuVa) 和 CMP VA (LogBufferSystemProcessGpuVa) 的對應,因此它們可以讀取/寫入 KMD、GPU 引擎和 CMP。 Dxgkrnl 呼叫 DxgkDdiSetNativeFenceLogBuffer 兩次:一次可設定記錄等候的記錄緩衝區,一次設定記錄訊號的記錄緩衝區。
在 UMD 在命令清單中插入原生柵欄等候或訊號指令之後,它也會插入命令,指示 GPU 在特定專案寫入記錄緩衝區中的承載。
GPU 引擎執行隔離作業之後,會看到 UMD 指令,將承載寫入記錄緩衝區中的指定專案。 此外,GPU 也會將目前的 FenceEndGpuTimestamp 寫入此記錄緩衝區專案。
雖然 UMD 無法存取 GPU 可存取的記錄緩衝區,但它會控制記錄緩衝區的進展。 也就是說,UMD 會決定要寫入的下一個免費專案,如果有的話,並使用這項資訊對 GPU 進行程式。 當 GPU 寫入記錄緩衝區時,它會遞增 記錄標頭中的 FirstFreeEntryIndex 值。 UMD 必須確保對記錄專案的寫入單調增加。
試想以下情況:
- 有兩個 HWQueues:HWQueueA 和 HWQueueB,具有具有具有 FenceLogA 和 FenceLogB 之 GPU VA 的對應柵欄記錄緩衝區。 HWQueueA 與記錄等候的記錄緩衝區相關聯,而 HWQueueB 與記錄訊號的記錄緩衝區相關聯。
- 有原生柵欄物件,其使用者模式D3DKMT_HANDLE 為 FenceF。
- 當 CPUT1 時,針對 Value V1 的 FenceF 等候已排入 HWQueueA。 當UMD建置命令緩衝區時,它會插入命令,指示 GPU 記錄承載:LOG(FenceF、V1、DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED)。
- 具有值 V1 之 FenceF 的 GPU 訊號會在 CPUT2 時排入 HWQueueB。 當UMD建置命令緩衝區時,它會插入命令,指示 GPU 記錄承載:LOG(FenceF、V1、DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED)。
GPU 排程器在 GPU 時間 GPUT1 在 HWQueueB 上執行 GPU 訊號之後,它會讀取 UMD 承載,並在 HWQueueB 的 OS 提供的柵欄記錄中記錄事件:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
在 GPU 排程器觀察到在 GPU 時間 GPUT2 解除封鎖 HWQueueA 之後,它會讀取 UMD 承載,並將事件記錄在 HWQueueA 的 OS 提供的柵欄記錄中:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl 可以終結並重新建立記錄緩衝區。 每次這樣做時,都會呼叫 DxgkDdiSetNativeFenceLogBuffer 來通知 KMD 新位置。
隔離佇列作業的 CPU 時間戳
假設有下列優點,讓 UMD 記錄這些 CPU 時間戳沒有什麼好處:
- 命令清單可以在 GPU 執行包含命令清單的命令緩衝區之前記錄數分鐘。
- 幾分鐘可以與其他位於相同命令緩衝區中的同步物件不同步。
在 UMD 指示中納入 GPU 寫入記錄緩衝區的 CPU 時間戳,因此 CPU 時間戳不會包含在記錄項目承載中。
相反地,運行時間或 UMD 可以在記錄命令清單時發出具有 CPU 時間戳的原生圍欄佇列 ETW 事件。 因此,工具可以結合這個新事件的CPU時間戳,以及記錄緩衝區專案中的 GPU 時間戳,來建置隔離佇列和已完成事件的時程表。
發出訊號或解除封鎖柵欄時 GPU 上的作業順序
UMD 必須在建置命令清單指示 GPU 發出/解除封鎖柵欄時,確保其維持下列順序:
- 將新的柵欄值寫入至隔離 GPU VA/CMP VA。
- 將記錄承載寫入對應的記錄緩衝區 GPU VA/CMP VA。
- 視需要引發原生柵欄,表示中斷。
此作業順序可確保 當中斷引發至OS時,Dxgkrnl 會看到最新的記錄專案。
允許記錄緩衝區滿溢
GPU 可以覆寫作業系統尚未看到的專案,以覆寫記錄緩衝區。 其方式是遞增 WraparoundCount。
當 OS 最終讀取記錄檔時,它可以藉由比較記錄標頭中的 new WraparoundCount 值與其快取值,來偵測發生滿溢的情況。 如果發生超支,OS 有下列後援選項:
- 為了在發生滿溢時解除封鎖柵欄,OS 會掃描所有柵欄,並判斷哪些服務人員已解除封鎖。
- 如果已啟用追蹤,OS 可以在追蹤中發出旗標,以通知使用者事件遺失。 此外,啟用追蹤時,OS 會先增加記錄緩衝區的大小,以防止第一次滿溢。
UMD 不需要在進行記錄緩衝區專案時實作回壓支援。
空白或重複的記錄緩衝區時間戳
在常見情況下, Dxgkrnl 預期記錄專案中的時間戳會單調增加。 不過,當後續記錄項目的時間戳為零或與先前的記錄專案相同時,在某些情況下。
例如,在具有連結顯示適配卡的案例中,LDA 中的其中一個鏈結適配卡可以略過柵欄寫入作業。 在此情況下,其記錄緩衝區專案具有零時間戳。 Dxgkrnl 會處理這類情況。 也就是說, Dxgkrnl 絕不會預期指定記錄項目的時間戳小於先前記錄項目的時間戳;也就是說,時間戳永遠無法回溯。
同步更新原生柵欄記錄
GPU 寫入以更新柵欄值和對應的記錄緩衝區,必須確保寫入會在 CPU 讀取之前完整傳播。 這項需求需要使用記憶體屏障。 例如:
- 訊號柵欄(N):將 N 寫入為新的目前值
- 寫入 LOG 專案,包括 GPU 時間戳
- MemoryBarrier
- Increment FirstFreeEntryIndex
- MemoryBarrier
- 受監視的柵欄中斷 (N):閱讀位址 「M」。,並將值與 N 進行比較,以決定傳遞 CPU 中斷
在每一個 GPU 訊號上插入兩個屏障太昂貴,特別是當條件式中斷檢查不滿意且不需要 CPU 中斷時。 因此,設計會將將其中一個記憶體屏障的成本從 GPU(產生者)插入 CPU(取用者)。 Dxgkrnl 會呼叫引進的 DxgkDdiUpdateNativeFenceLogs 函式,導致 KMD 視需要同步排清擱置的原生柵欄記錄寫入(類似於針對 HW 翻轉佇列記錄排清引進的 DxgkddiUpdateflipqueuelog 的方式)。
GPU 作業:
- 訊號柵欄(N):將 N 寫入為新的目前值
- 寫入 LOG 專案,包括 GPU 時間戳
- Increment FirstFreeEntryIndex
- MemoryBarrier => 確保 FirstFreeEntryIndex 已完全傳播
- 受監視的柵欄中斷 (N):閱讀位址 「M」。,並將值與 N 進行比較,以決定傳遞中斷
CPU 作業:
在 Dxgkrnl 的原生柵欄中,信號中斷處理程式 (DISPATCH_IRQL):
- 針對每個 HWQueue 記錄檔:讀取 FirstFreeEntryIndex ,並判斷是否已寫入新的專案。
- 針對每個具有新專案的 HWQueue 記錄:呼叫 DxgkDdiUpdateNativeFenceLogs ,並提供這些 HWQueues 的核心句柄。 在此 DDI 中,KMD 會將記憶體屏障插入每個指定的 HWQueue,以確保認可所有記錄專案寫入。
- Dxgkrnl 會讀取記錄專案以擷取時間戳承載。
因此,只要硬體在寫入 FirstFreeEntryIndex 之後插入記憶體屏障,Dxgkrnl 一律會呼叫 KMD 的 DDI,讓 KMD 在 Dxgkrnl 讀取任何記錄專案之前插入記憶體屏障。
未來的硬體需求
大部分目前的世代硬體可能只支援撰寫它在原生柵欄信號中斷中發出訊號之柵欄物件的核心句柄。 此設計稍早會在原生柵欄發出信號中斷中所述。 在此情況下, Dxgkrnl 會處理中斷承載,如下所示:
- OS 會執行柵欄值的讀取(可能跨PCI)。
- 知道哪個柵欄已發出訊號和柵欄值,OS 會喚醒正在等候該柵欄/值的 CPU 服務員。
- 另外,針對這個柵欄的父裝置,OS 會掃描其所有 HWQueues 的記錄緩衝區。 然後,OS 會讀取最後寫入的記錄緩衝區專案,以判斷哪個 HWQueue 會發出訊號並擷取對應的時間戳承載。 這種方法可能會重複讀取PCI中的一些柵欄值。
在未來的平臺上, Dxgkrnl 偏好取得原生柵欄信號中斷中核心 HwQueue 句柄的陣列。 此方法可讓OS:
- 讀取該 HwQueue 的最新記錄緩衝區專案。 中斷處理程式不知道用戶裝置;因此,此 HwQueue 句柄必須是核心句柄。
- 掃描記錄緩衝區中是否有記錄專案,指出哪些柵欄已發出訊號,以及哪些值。 只讀取記錄緩衝區可確保透過PCI進行單一讀取,而不必重複讀取柵欄值和記錄緩衝區。 只要記錄緩衝區尚未滿溢,此優化就會成功(捨棄 Dxgkrnl 從未讀取的專案)。
- 如果OS偵測到記錄緩衝區已滿溢,它會回復為非優化路徑,該路徑會讀取相同裝置所擁有之每個柵欄的即時值。 效能與裝置所擁有的柵欄數目成正比。 如果柵欄值位於視訊記憶體中,則這些讀取會在PCI之間快取一致。
- 知道哪些柵欄已發出訊號和柵欄值,OS 會喚醒正在等候這些柵欄/值的 CPU 服務員。
優化原生柵欄發出信號中斷
除了原生柵欄訊號中斷中所述的變更之外,也會進行下列變更以支持優化的方法:
- OptimizedNativeFenceSignaledInterrupt cap 會新增至 DXGK_VIDSCHCAPS。
如果硬體支援,則 GPU 應該只提及引發中斷時正在執行的 HWQueue KMD 句柄,而不是填入發出訊號的柵欄控點數位。 Dxgkrnl 會掃描此 HWQueue 的柵欄記錄緩衝區,並讀取 GPU 自上次更新後完成的所有柵欄作業,並解除封鎖任何對應的 CPU 等候者。 如果 GPU 無法判斷哪些柵欄子集已發出訊號,則它應該指定 NULL HWQueue 句柄。 當 Dxgkrnl 看到 NULL HWQueue 句柄時,它會倒退以重新掃描此引擎上所有 HWQueues 的記錄緩衝區,以判斷哪些柵欄已收到訊號。
此優化的支持是選擇性的;KMD 應設定 硬體支援的 DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt 上限。 如果未設定 OptimizedNativeFenceSignaledInterrupt 上限,則 GPU/KMD 應該遵循原生隔離訊號中斷中所述的行為。
優化原生柵欄訊號中斷的範例
HWQueueA:GPU 訊號至柵欄 F1、值 V1 - 寫入記錄緩衝區專案 E1 ->> 不需要中斷
HWQueueA:GPU 訊號至柵欄 F1、值 V2 - 寫入記錄緩衝區專案 E2 ->> 不需要中斷
HWQueueA:GPU 訊號至柵欄 F2、值 V3 - 寫入記錄緩衝區專案 E3 ->> 不需要中斷
HWQueueA:GPU 訊號至柵欄 F2、值 V3 - 寫入記錄緩衝區專案 E4 ->> 引發中斷
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl 會讀取 HWQueueA 的記錄緩衝區。 它會讀取記錄緩衝區專案 E1、E2、E3 和 E4 來觀察信號柵欄 F1 @ Value V1、 F1 @ Value V2、 F2 @ Value V3 和 F2 @ Value V3,並解除封鎖等候這些柵欄和值的任何等候者
選擇性和強制記錄
必須支援DXGK_NATIVE_FENCE_LOG_TYPE_WAITS和DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS的原生柵欄記錄。
未來,只有在 GPUView 之類的工具在 OS 中啟用詳細資訊 ETW 記錄時,才能新增其他記錄類型。 OS 必須通知 UMD 和 KMD 何時啟用和停用詳細信息記錄,以便選擇性地啟用這些詳細資訊事件的記錄。