Entwickeln von Code in Databricks-Notebooks
In diesem Artikel wird beschrieben, wie Sie Code in Databricks-Notebooks entwickeln, einschließlich AutoVervollständigen-Funktion, automatischer Formatierung für Python und SQL, der Kombination von Python und SQL in einem Notebook sowie der Verfolgung des Versionsverlaufs für ein Notebook.
Weitere Informationen zu erweiterten Funktionen, die in dem Editor verfügbar sind, wie z. B. AutoVervollständigen, Variablenauswahl, Unterstützung mehrerer Cursor und parallele Unterschiede, finden Sie unter Verwenden des Databricks-Notebooks und des Datei-Editors.
Wenn Sie das Notebook oder den Datei-Editor verwenden, steht der Databricks-Assistent zur Verfügung, um Code zu generieren, zu erläutern und zu debuggen. Weitere Informationen finden Sie unter Verwenden des Databricks-Assistenten .
Databricks-Notebooks enthalten auch einen integrierten interaktiven Debugger für Python-Notebooks. Siehe Debuggen von Notizbüchern.
Abrufen von Codierungshilfe vom Databricks-Assistenten
Der Databricks-Assistent ist ein kontextabhängiger KI-Assistent, mit dem Sie mit einer Unterhaltungsschnittstelle interagieren können, sodass Sie in Databricks produktiver arbeiten können. Sie können Ihre Aufgabe auf Englisch beschreiben und den Assistenten Python-Code oder SQL-Abfragen generieren, komplexen Code erklären und Fehler automatisch beheben lassen. Der Assistent verwendet Unity-Katalogmetadaten, um Ihre Tabellen, Spalten, Beschreibungen und beliebten Datenressourcen in Ihrem Unternehmen zu verstehen und personalisierte Antworten zu geben.
Der Databricks-Assistent kann Ihnen bei den folgenden Aufgaben helfen:
- Generieren von Code.
- Debuggen von Code, einschließlich der Identifizierung von Fehlern und Vorschlägen zu deren Behebung.
- Transformieren und Optimieren von Code.
- Erläutern von Code.
- Hilft Ihnen dabei, relevante Informationen in der Azure Databricks-Dokumentation zu finden.
Informationen zum Verwenden des Databricks-Assistenten zur effizienteren Codeerstellung finden Sie unter Verwenden des Databricks-Assistenten. Allgemeine Informationen zum Databricks-Assistenten finden Sie unter Häufig gestellte Fragen zum DatabricksIQ-powered Feature.
Zugreifen auf ein Notebook für die Bearbeitung
Verwenden Sie zum Öffnen eines Notebooks die Suchfunktion des Arbeitsbereichs, oder navigieren Sie mit dem Arbeitsbereichsbrowser zum Notebook, und klicken Sie auf den Namen oder das Symbol des Notebooks.
Durchsuchen von Daten
Verwenden Sie den Schemabrowser, um Unity Catalog-Objekte zu erkunden, die für das Notizbuch verfügbar sind. Klicken Sie auf das ![]() auf der linken Seite des Notebooks, um den Schemabrowser zu öffnen.
auf der linken Seite des Notebooks, um den Schemabrowser zu öffnen.
Die Schaltfläche Für Sie zeigt nur diejenigen Objekte an, die Sie in der aktuellen Sitzung verwendet oder zuvor als Favoriten markiert haben.
Wenn Sie Text in das Feld Filter eingeben, ändert sich die Anzeige so, dass nur die Objekte angezeigt werden, die den von Ihnen eingegebenen Text enthalten. Es werden nur Objekte angezeigt, die derzeit geöffnet sind oder in der aktuellen Sitzung geöffnet wurden. Das Feld Filter führt keine vollständige Suche nach den Katalogen, Schemas, Tabellen und Volumes aus, die für das Notebook verfügbar sind.
Um das ![]() Kebabmenü zu öffnen, halten Sie den Cursor wie gezeigt über den Namen des Objekts:
Kebabmenü zu öffnen, halten Sie den Cursor wie gezeigt über den Namen des Objekts:
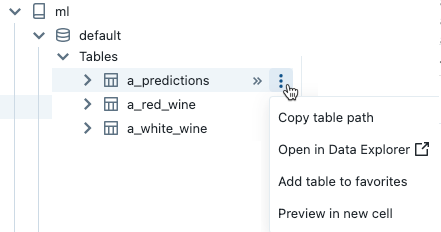
Wenn es sich bei dem Objekt um eine Tabelle handelt, können Sie die folgenden Schritte ausführen:
- Automatisches Erstellen und Ausführen einer Zelle, um eine Vorschau der Daten in der Tabelle anzuzeigen. Auswählen der Option Vorschau in einer neuen Zelle aus dem Optionsmenü.
- Anzeigen eines Katalogs, eines Schemas oder einer Tabelle im Katalog-Explorer. Wählen Sie im Optionsmenü Im Katalog-Explorer öffnen aus. Eine neue Registerkarte mit dem ausgewählten Objekt wird geöffnet.
- Abrufen des Pfads zu einem Katalog, einem Schema oder einer Tabelle. Auswählen der Option ... Pfad kopieren aus dem Optionsmenü für das Objekt.
- Hinzufügen einer Tabelle zu Favoriten. Auswählen der Option zu Favoriten hinzufügen aus dem Optionsmenü für die Tabelle.
Wenn es sich bei dem Objekt um einen Katalog, ein Schema oder ein Volume handelt, können Sie den Pfad des Objekts kopieren oder im Katalog-Explorer öffnen.
So fügen Sie einen Tabellen- oder Spaltennamen direkt in eine Zelle ein:
- Klicken Sie mit dem Cursor in der Zelle an der Position, an der Sie den Namen eingeben möchten.
- Bewegen Sie den Cursor über den Tabellen- oder Spaltennamen im Schemabrowser.
- Klicken Sie auf den Doppelpfeil
 , der rechts neben dem Namen des Objekts angezeigt wird.
, der rechts neben dem Namen des Objekts angezeigt wird.
Tastenkombinationen
Um Tastenkombinationen anzuzeigen, wählen Sie Hilfe > Tastenkombinationen aus. Die verfügbaren Tastenkombinationen hängen davon ab, ob sich der Cursor in einer Codezelle (Bearbeitungsmodus) befindet oder nicht (Befehlsmodus).
Befehlspalette
Mit der Befehlspalette können Sie schnell Aktionen im Notebook ausführen. Um einen Bereich von Notebookaktionen zu öffnen, klicken Sie in der rechten unteren Ecke des Arbeitsbereichs auf  , oder verwenden Sie die Tastenkombination CMD+UMSCHALT+P unter macOS bzw. STRG+UMSCHALT+P unter Windows.
, oder verwenden Sie die Tastenkombination CMD+UMSCHALT+P unter macOS bzw. STRG+UMSCHALT+P unter Windows.
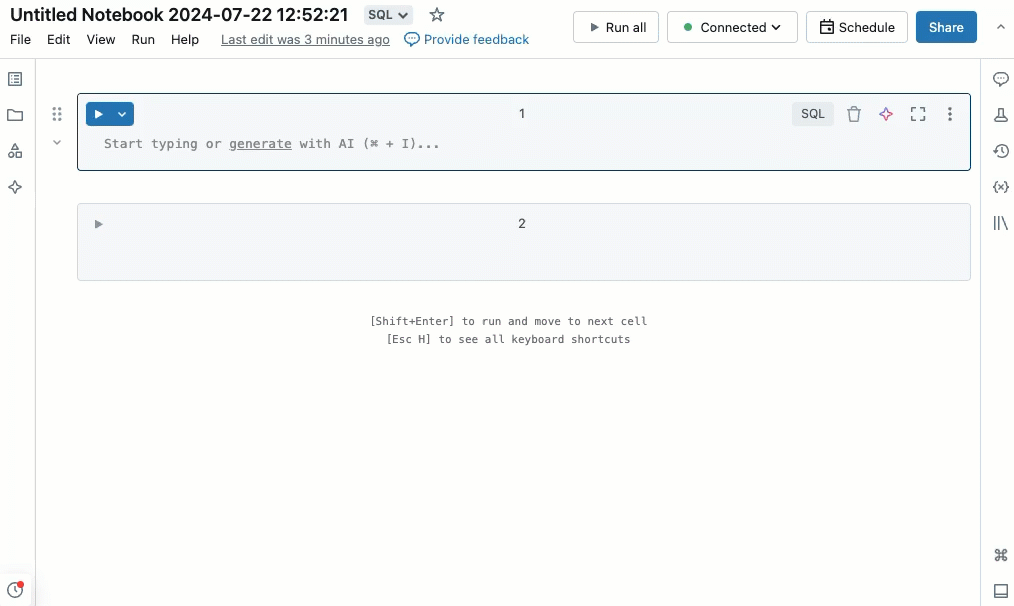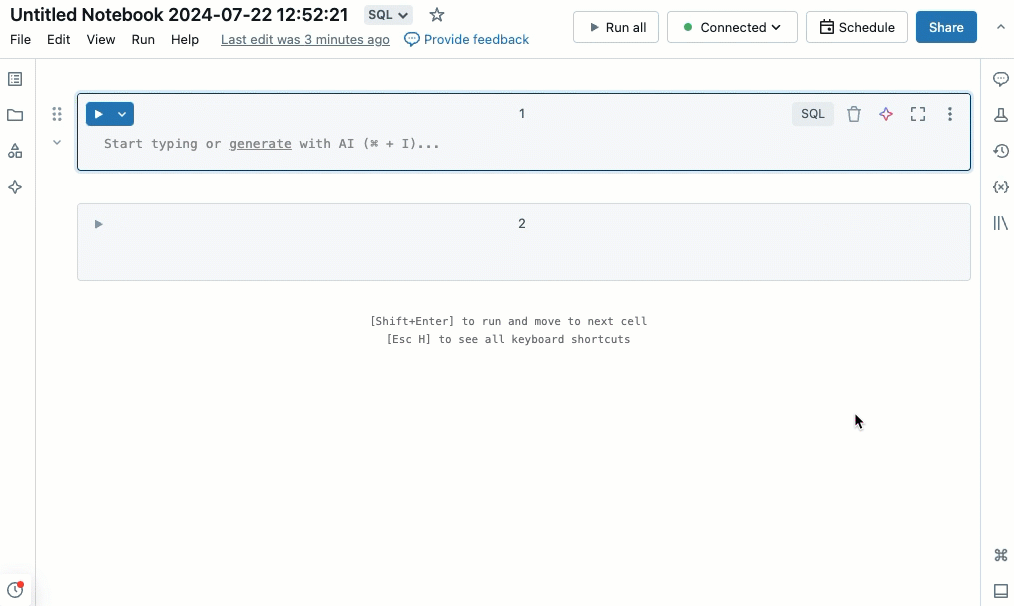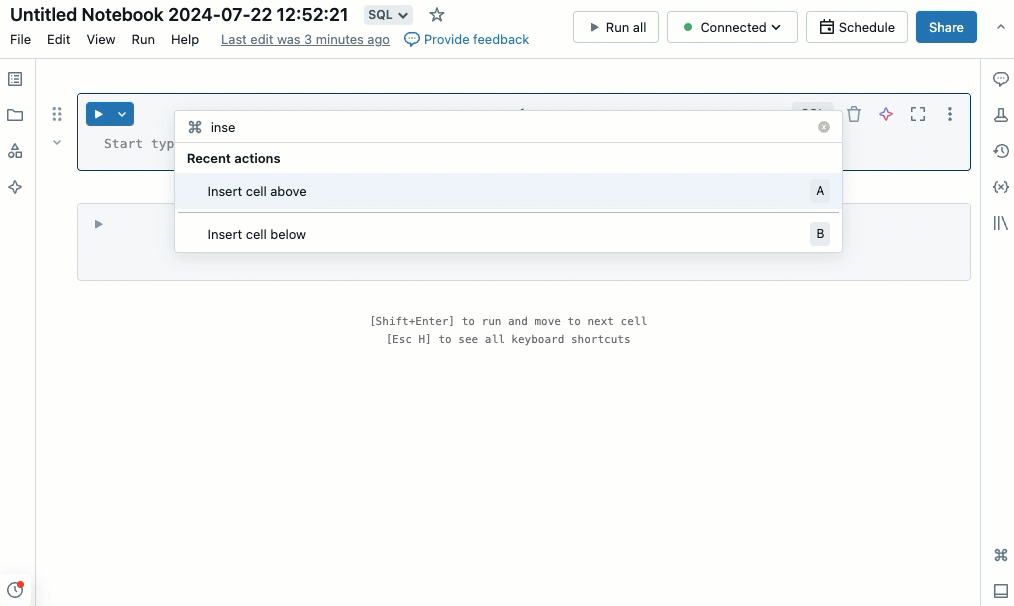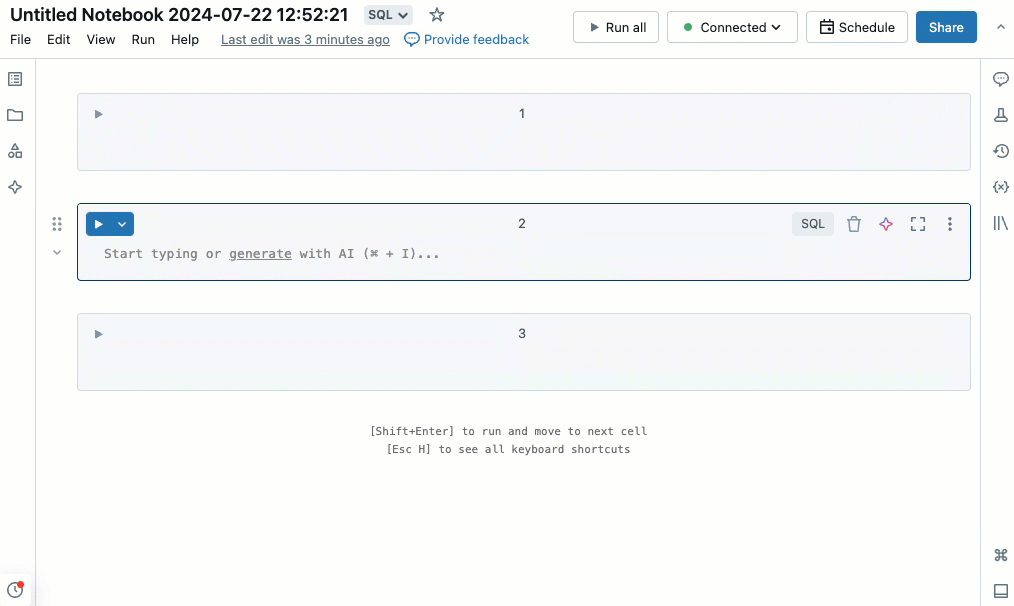
Suchen und Ersetzen von Daten
Klicken Sie auf Bearbeiten > Suchen und Ersetzen, um Text in einem Notebook zu suchen und zu ersetzen. Die aktuelle Übereinstimmung ist orange hervorgehoben. Alle anderen Übereinstimmungen sind gelb hervorgehoben.
Klicken Sie auf Ersetzen, um die aktuelle Übereinstimmung zu ersetzen. Um alle Übereinstimmungen im Notebook zu ersetzen, klicken Sie auf Alle ersetzen.
Zum Wechseln zwischen Übereinstimmungen klicken Sie auf die Schaltflächen Vorherige und Nächste. Sie können auch UMSCHALT+EINGABETASTE und EINGABETASTE drücken, um zu den vorherigen bzw. nächsten Übereinstimmungen zu wechseln.
Um das Tool zum Suchen und Ersetzen zu schließen, klicken Sie auf ![]() , oder drücken Sie die ESC-TASTE.
, oder drücken Sie die ESC-TASTE.
Ausführen ausgewählter Zellen
Sie können eine einzelne Zelle oder eine Sammlung von Zellen ausführen. Um eine einzelne Zelle auszuwählen, klicken Sie auf eine beliebige Stelle in der Zelle. Halten Sie zum Auswählen mehrerer Zellen die Command-Taste unter MacOS oder die Ctrl-Taste unter Windows gedrückt, und klicken Sie auf die Zelle außerhalb des Textbereichs, wie im Screenshot gezeigt.
Die Ausführung des ausgewählten Verhaltens dieses Befehls hängt vom Cluster ab, an den das Notebook angefügt ist.
- In einem Cluster mit Databricks Runtime 13.3 LTS oder niedriger werden ausgewählte Zellen einzeln ausgeführt. Wenn in einer Zelle ein Fehler auftritt, wird die Ausführung mit nachfolgenden Zellen fortgesetzt.
- In einem Cluster mit Databricks Runtime 14.0 oder höher oder in einem SQL-Warehouse werden Zellen als Batch ausgeführt. Jeder Fehler hält die Ausführung an, und Sie können die Ausführung einzelner Zellen nicht abbrechen. Sie können die Schaltfläche Interrupt (Unterbrechen) verwenden, um die Ausführung aller Zellen zu beenden.
Modularisieren des Codes
Wichtig
Dieses Feature befindet sich in der Public Preview.
Mit Databricks Runtime 11.3 LTS und höher können Sie Quellcodedateien im Azure Databricks-Arbeitsbereich erstellen und verwalten und diese Dateien dann nach Bedarf in Ihre Notebooks importieren.
Weitere Informationen zum Arbeiten mit Quellcodedateien finden Sie unter Freigeben von Code zwischen Databricks-Notebooks und Arbeiten mit Python- und R-Modulen.
Ausführen von ausgewähltem Text
Sie können Code oder SQL-Anweisungen in einer Notebookzelle markieren und nur diese Auswahl ausführen. Dies ist für das schnelle Durchlaufen von Code und Abfragen nützlich.
Markieren Sie die Zeilen, die Sie ausführen möchten.
Wählen Sie Ausführen > Ausgewählten Text ausführen, oder verwenden Sie die Tastenkombination
Ctrl+Shift+Enter. Wenn kein Text markiert ist, wird über Ausgewählten Text ausführen die aktuelle Zeile ausgeführt.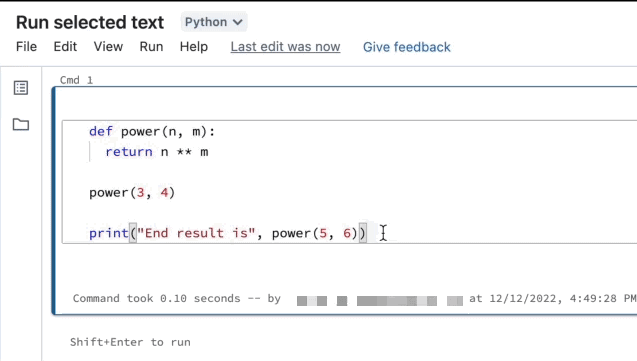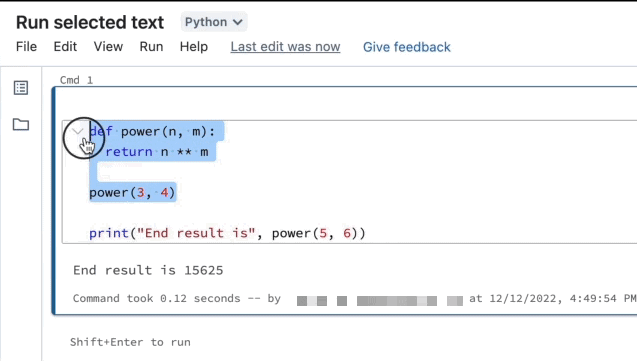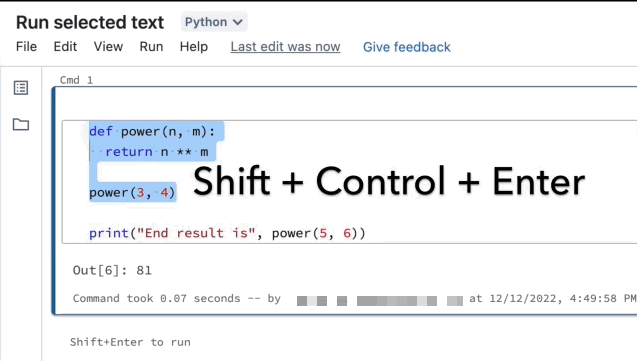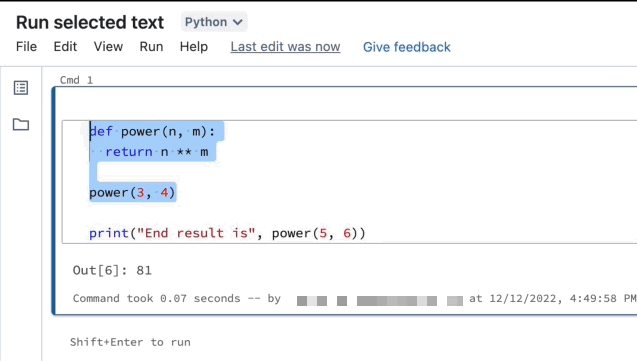
Wenn Sie mehrere Sprachen in einer Zelle kombinieren, müssen Sie die Zeile %<language> in die Auswahl einschließen.
Durch Ausgewählten Text ausführen wird auch ausgeblendeter Code ausgeführt, sofern solcher in der markierten Auswahl vorhanden ist.
Spezielle Zellenbefehle wie %run, %pip und %sh werden unterstützt.
Sie können Ausgewählten Text ausführen nicht für Zellen verwenden, die mehrere Ausgaberegisterkarten umfassen (d. h. Zellen, in denen Sie ein Datenprofil oder eine Visualisierung definiert haben).
Formatieren von Codezellen
Azure Databricks bietet Tools, mit denen Sie Python- und SQL-Code in Notebookzellen schnell und einfach formatieren können. Diese Tools reduzieren den Aufwand für die Formatierung Ihres Codes und tragen dazu bei, in allen Notebooks die gleichen Codierungsstandards umzusetzen.
Python-Bibliothek für den Black-Formatierer
Wichtig
Dieses Feature befindet sich in der Public Preview.
Azure Databricks unterstützt die Python-Codeformatierung mithilfe von Black im Notebook. Das Notebook muss mit einem Cluster verbunden sein, auf dem die Python-Pakete black und tokenize-rt installiert sind.
In Databricks Runtime 11.3 LTS und höher installiert Azure Databricks black und tokenize-rt vorab. Sie können den Formatierer direkt verwenden, ohne diese Bibliotheken installieren zu müssen.
Unter Databricks Runtime 10.4 LTS und früher müssen Sie black==22.3.0 und tokenize-rt==4.2.1 aus PyPI in Ihrem Notebook oder Cluster installieren, um den Python-Formatierer nutzen zu können. Sie können den folgenden Befehl in Ihrem Notebook ausführen:
%pip install black==22.3.0 tokenize-rt==4.2.1
oder die Bibliothek auf Ihrem Cluster installieren.
Weitere Informationen zum Installieren von Bibliotheken finden Sie unter Python-Umgebungsverwaltung.
Für Dateien und Notebooks in Databricks Git-Ordnern können Sie den Python-Formatierer basierend auf der pyproject.toml-Datei konfigurieren. Um dieses Feature zu verwenden, erstellen Sie eine pyproject.toml-Datei im Stammverzeichnis des Git-Ordners, und konfigurieren Sie sie gemäß dem Konfigurationsformat „Black“. Bearbeiten Sie den Abschnitt [tool.black] in der Datei. Die Konfiguration wird angewendet, wenn Sie eine beliebige Datei und ein Notebook in diesem Git-Ordner formatieren.
Formatieren von Python- und SQL-Zellen
Sie benötigen die KANN BEARBEITEN-Berechtigung für das Notebook, um Code zu formatieren.
Azure Databricks verwendet die Gethue/sql-formatter-Bibliothek, um SQL und den Black-Codeformatierer für Python zu formatieren.
Sie können die Formatierung auf folgende Weise auslösen:
Formatieren einer einzelnen Zelle
- Tastenkombination: Drücken Sie CMD+UMSCHALT+F.
- Befehlskontextmenü:
- SQL-Zelle formatieren: Wählen Sie SQL formatieren im Befehlskontext-Dropdownmenü einer SQL-Zelle aus. Dieses Menüelement ist nur in SQL-Notebookzellen oder in Zellen mit einem Sprach-Magic-Befehl des Typs
%sqlsichtbar. - Python-Zelle formatieren: Wählen Sie Python formatieren im Befehlskontext-Dropdownmenü einer Python-Zelle aus. Dieses Menüelement ist nur in Python-Notebookzellen oder in Zellen mit einem Sprach-Magic-Befehl des Typs
%pythonsichtbar.
- SQL-Zelle formatieren: Wählen Sie SQL formatieren im Befehlskontext-Dropdownmenü einer SQL-Zelle aus. Dieses Menüelement ist nur in SQL-Notebookzellen oder in Zellen mit einem Sprach-Magic-Befehl des Typs
- Menü Bearbeiten eines Notebooks: Wählen Sie eine Python- oder SQL-Zelle aus, und wählen Sie dann Bearbeiten > Zelle(n) formatieren aus.
Formatieren mehrerer Zellen
Wählen Sie mehrere Zellen und dann Bearbeiten > Zelle(n) formatieren aus. Wenn Sie Zellen mit mehreren Sprachen auswählen, werden nur SQL- und Python-Zellen formatiert. Dies umfasst auch diejenigen, die
%sqlund%pythonverwenden.Formatieren aller Python- und SQL-Zellen im Notebook
Wählen Sie Bearbeiten > Notebook formatieren aus. Wenn Ihr Notebook mehrere Zellen beinhaltet, werden nur SQL- und Python-Zellen formatiert. Dies schließt auch Zellen mit Verwendung von
%sqlund%pythonein.
Einschränkungen der Codeformatierung
- Black erzwingt PEP 8-Standards für einen Einzug aus 4 Leerzeichen. Der Einzug ist nicht konfigurierbar.
- Das Formatieren eingebetteter Python-Zeichenfolgen in einer SQL-UDF wird nicht unterstützt. Ebenso wird das Formatieren von SQL-Zeichenfolgen innerhalb einer Python-UDF nicht unterstützt.
Versionsverlauf
Azure Databricks-Notebooks verwalten einen Verlauf von Notebookversionen, sodass Sie frühere Momentaufnahmen des Notebooks anzeigen und wiederherstellen können. Sie können die folgenden Aktionen für Versionen ausführen: Kommentare hinzufügen, Versionen wiederherstellen und löschen sowie den Versionsverlauf löschen.
Sie können Ihre Arbeit in Databricks auch mit einem Git-Remoterepository synchronisieren.
Klicken Sie auf das  auf der Seitenleiste rechts, um die Revisionen des Notebooks aufzurufen. Der Versionsverlauf des Notebooks erscheint. Sie können auch Datei > Versionsverlauf auswählen.
auf der Seitenleiste rechts, um die Revisionen des Notebooks aufzurufen. Der Versionsverlauf des Notebooks erscheint. Sie können auch Datei > Versionsverlauf auswählen.
Kommentar hinzufügen
Zum Hinzufügen eines Kommentars zur neuesten Version gehen Sie wie folgt vor:
Klicken Sie auf die Version.
Klicken Sie auf Jetzt speichern.
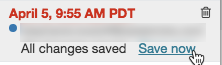
Geben Sie im Dialogfeld „Notebookversion speichern“ einen Kommentar ein.
Klicken Sie auf Speichern. Die Notebookversion wird mit dem eingegebenen Kommentar gespeichert.
Wiederherstellen einer Version
So stellen Sie eine Version wieder her:
Klicken Sie auf die Version.
Klicken Sie auf Diese Version wiederherstellen.
Klicken Sie auf Confirm (Bestätigen). Die ausgewählte Version wird zur neuesten Version des Notebooks.
Löschen von Versionen
So löschen Sie einen Versionseintrag
Klicken Sie auf die Version.
Klicken Sie auf das Papierkorbsymbol
 .
.
Klicken Sie auf Ja, löschen. Die ausgewählte Version wird aus dem Verlauf gelöscht.
Löschen des Versionsverlaufs
Der Versionsverlauf kann nicht wiederhergestellt werden, nachdem er gelöscht wurde.
So löschen Sie den Versionsverlauf für ein Notebook:
- Wählen Sie Datei > Versionsverlauf löschen aus.
- Klicken Sie auf Ja, löschen. Der Versionsverlauf des Notebooks wird gelöscht.
Codesprachen in Notebooks
Festlegen der Standardsprache
Die Standardsprache für das Notebook wird neben dem Notebooknamen angezeigt.

Um die Standardsprache zu ändern, klicken Sie auf die Schaltfläche „Sprache“, und wählen Sie im Dropdownmenü die neue Sprache aus. Um sicherzustellen, dass vorhandene Befehle weiterhin funktionieren, wird Befehlen der vorherigen Standardsprache automatisch ein Magic-Befehl für Sprache vorangestellt.
Mischen von Sprachen
Standardmäßig verwenden Zellen die Standardsprache des Notebooks. Sie können die Standardsprache in einer Zelle überschreiben, indem Sie auf die Schaltfläche „Sprache“ klicken und eine Sprache aus dem Dropdownmenü auswählen.
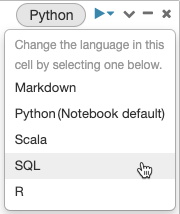
Alternativ können Sie auch den Magic-Befehl für Sprache %<language> am Anfang einer Zelle verwenden. Die unterstützten Magic-Befehle sind: %python, %r, %scala und %sql.
Hinweis
Wenn Sie einen Magic-Befehl für Sprache aufrufen, wird der Befehl an die REPL im Ausführungskontext für das Notebook gesendet. Variablen, die in einer Sprache (und somit in der REPL für diese Sprache) definiert sind, sind in der REPL einer anderen Sprache nicht verfügbar. REPLs können den Status nur über externe Ressourcen wie Dateien im DBFS oder Objekte im Objektspeicher gemeinsam nutzen.
Notebooks unterstützen auch einige zusätzliche Magic-Befehle:
%sh: Ermöglicht das Ausführen von Shellcode in Ihrem Notebook. Fügen Sie die Option-ehinzu, damit die Zelle einen Fehler auslöst, wenn der Shellbefehl einen Beendigungsstatus ungleich null aufweist. Dieser Befehl wird nur auf dem Apache Spark-Treiber und nicht auf den Workern ausgeführt. Um einen Shellbefehl auf allen Knoten auszuführen, verwenden Sie ein Initialisierungsskript.%fs: Ermöglicht die Verwendung vondbutils-Dateisystembefehlen. Um beispielsweise den Befehldbutils.fs.lszum Auflisten von Dateien auszuführen, können Sie stattdessen%fs lsangeben. Weitere Informationen finden Sie unter Arbeiten mit Dateien in Azure Databricks.%md: Ermöglicht Ihnen die Verwendung verschiedener Arten von Dokumentationen, einschließlich Text, Bildern und mathematischer Formeln und Formeln. Siehe nächster Abschnitt.
SQL-Syntaxhervorhebung und AutoVervollständigen in Python-Befehlen
Syntaxhervorhebung und SQL-AutoVervollständigen sind verfügbar, wenn Sie SQL in einem Python-Befehl verwenden, z. B. in einem spark.sql-Befehl.
Erkunden von SQL-Zellergebnissen
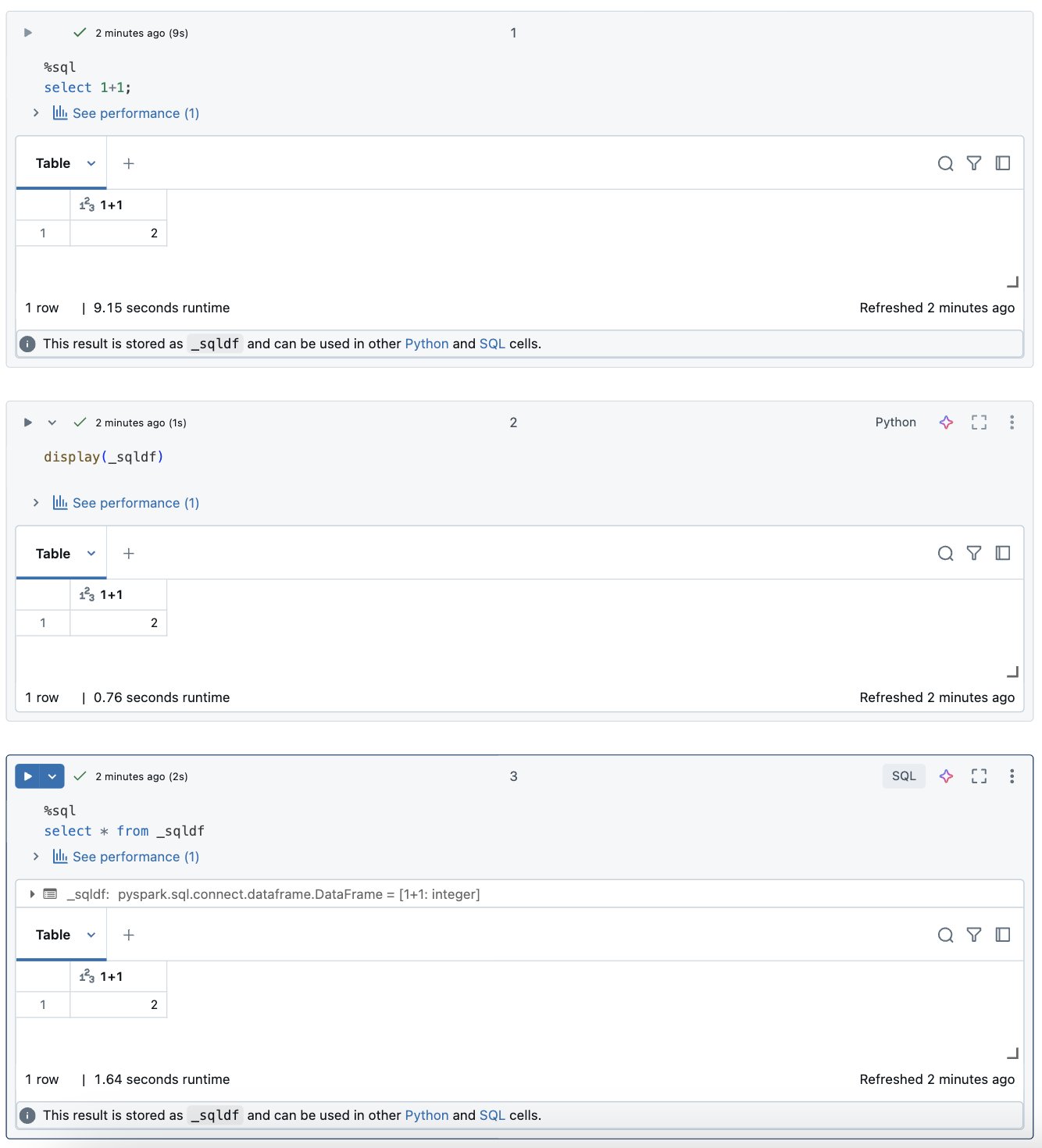
In einem Databricks-Notizbuch werden Ergebnisse aus einer SQL-Sprachzelle automatisch als impliziter DataFrame zur Verfügung gestellt, der der Variablen _sqldfzugewiesen ist. Sie können diese Variable dann in allen Python- und SQL-Zellen verwenden, die Sie danach ausführen, unabhängig von ihrer Position im Notizbuch.
Hinweis
Für diese Funktion gelten folgende Einschränkungen:
- Die
_sqldfVariable ist in Notizbüchern, die ein SQL Warehouse für die Berechnung verwenden, nicht verfügbar. - Die Verwendung
_sqldfin nachfolgenden Python-Zellen wird in Databricks Runtime 13.3 und höher unterstützt. - Die Verwendung
_sqldfin nachfolgenden SQL-Zellen wird nur für Databricks Runtime 14.3 und höher unterstützt. - Wenn die Abfrage die Schlüsselwörter
CACHE TABLEverwendet oderUNCACHE TABLEdie_sqldfVariable nicht verfügbar ist.
Der folgende Screenshot zeigt, wie _sqldf in nachfolgenden Python- und SQL-Zellen verwendet werden kann:
Wichtig
Die Variable _sqldf wird jedes Mal neu zugewiesen, wenn eine SQL-Zelle ausgeführt wird. Um den Verweis auf ein bestimmtes DataFrame-Ergebnis zu vermeiden, weisen Sie ihn einem neuen Variablennamen zu, bevor Sie die nächste SQL-Zelle ausführen:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Paralleles Ausführen von SQL-Zellen
Während ein Befehl ausgeführt wird und Ihr Notebook an einen interaktiven Cluster angefügt ist, können Sie eine SQL-Zelle gleichzeitig mit dem aktuellen Befehl ausführen. Die SQL-Zelle wird in einer neuen parallelen Sitzung ausgeführt.
So führen Sie eine Zelle parallel aus:
Klicken Sie auf Jetzt ausführen. Die Zelle wird sofort ausgeführt.
Da die Zelle in einer neuen Sitzung ausgeführt wird, werden temporäre Ansichten, UDFs und der implizite Python-DatenFrame (_sqldf) für parallel ausgeführte Zellen nicht unterstützt. Darüber hinaus werden die Standardkatalog- und Datenbanknamen während der parallelen Ausführung verwendet. Wenn Ihr Code auf eine Tabelle in einem anderen Katalog oder in einer anderen Datenbank verweist, müssen Sie den Tabellennamen mithilfe des dreiteiligen Namespace (catalog.schema.table) angeben.
Ausführen von SQL-Zellen in einem SQL-Warehouse
Sie können SQL-Befehle in einem Databricks-Notebook in einem SQL-Warehouse ausführen, einem Computetyp, der für SQL-Analysen optimiert ist. Weitere Informationen finden Sie unter Verwenden eines Notebooks mit einem SQL-Warehouse.
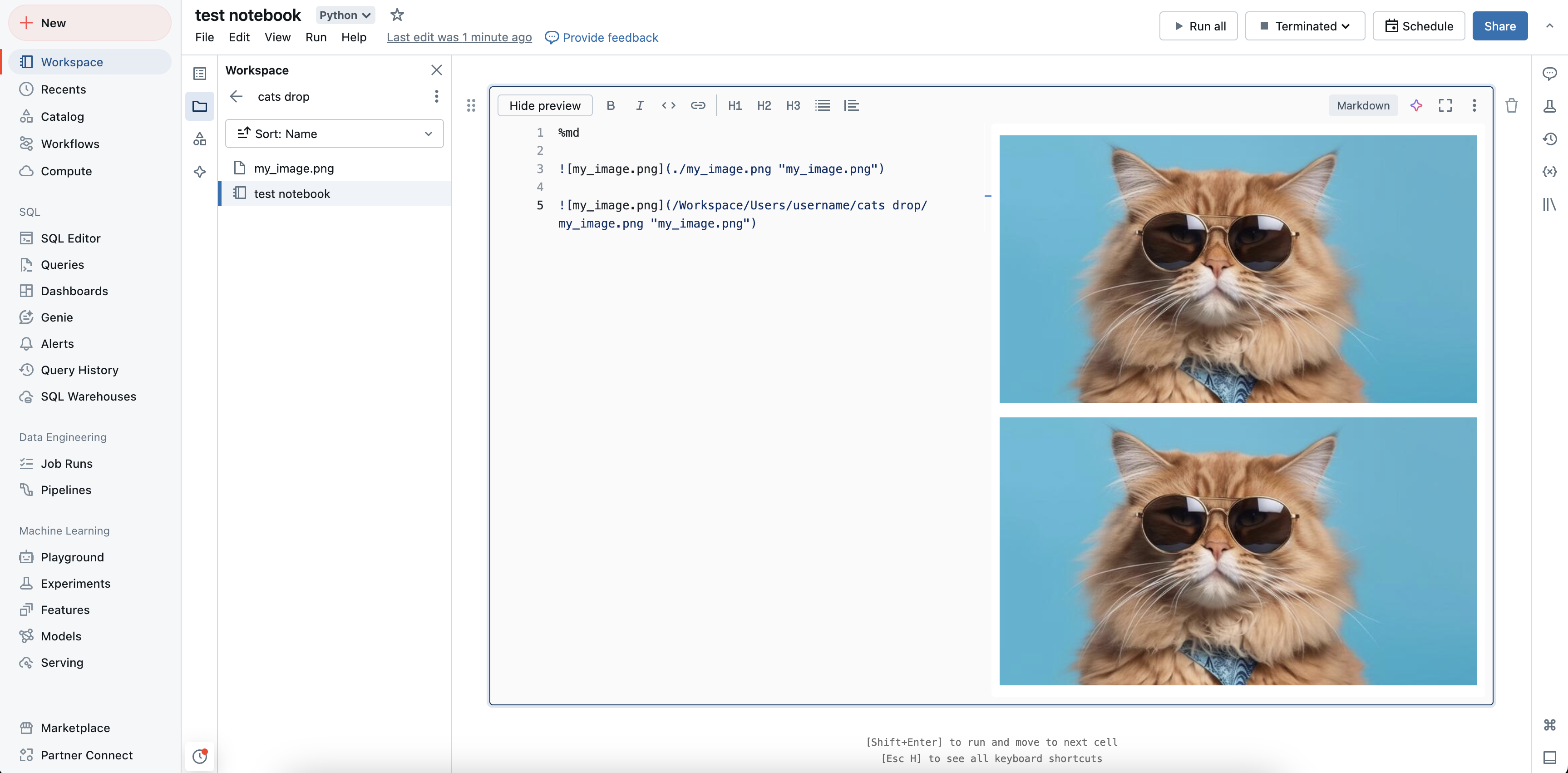
Anzeigen von Bildern
Azure Databricks unterstützt die Anzeige von Bildern in Markdown-Zellen. Sie können Bilder anzeigen, die im Arbeitsbereich, in Volumes oder im FileStore gespeichert sind.
Anzeigen von im Arbeitsbereich gespeicherten Bildern
Sie können entweder absolute Pfade oder relative Pfade verwenden, um im Arbeitsbereich gespeicherte Bilder anzuzeigen. Verwenden Sie die folgende Syntax, um ein im Arbeitsbereich gespeichertes Bild anzuzeigen:
%md


Anzeigen von in Volumes gespeicherten Bildern
Sie können absolute Pfade verwenden, um in Volumes gespeicherte Bilder anzuzeigen. Verwenden Sie die folgende Syntax, um ein in Volumes gespeichertes Bild anzuzeigen:
%md

Anzeigen von im FileStore gespeicherten Bildern
Verwenden Sie die folgende Syntax, um Bilder anzuzeigen, die in FileStore gespeichert sind:
%md

Angenommen, Sie verfügen in FileStore über die Bilddatei für das Databricks-Logo:
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
Geben Sie den folgenden Code in eine Markdownzelle ein:

Das Bild wird in der Zelle gerendert:

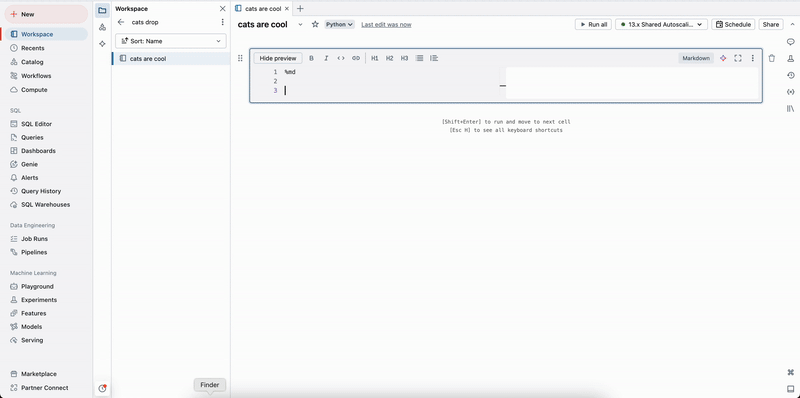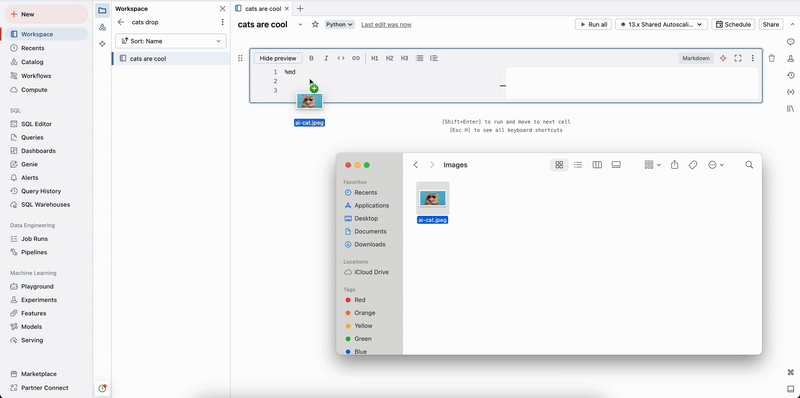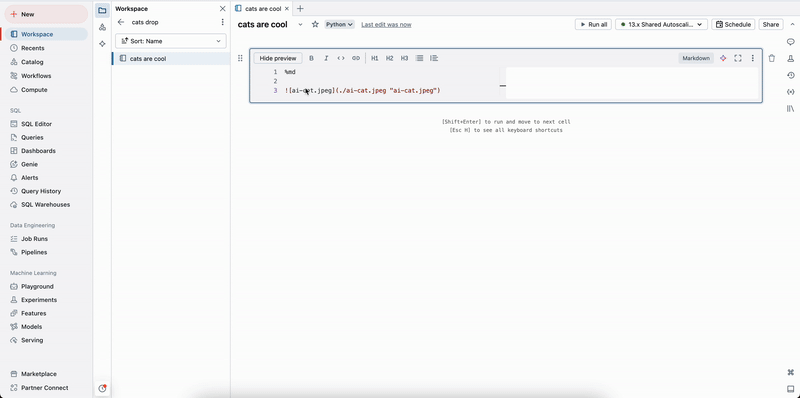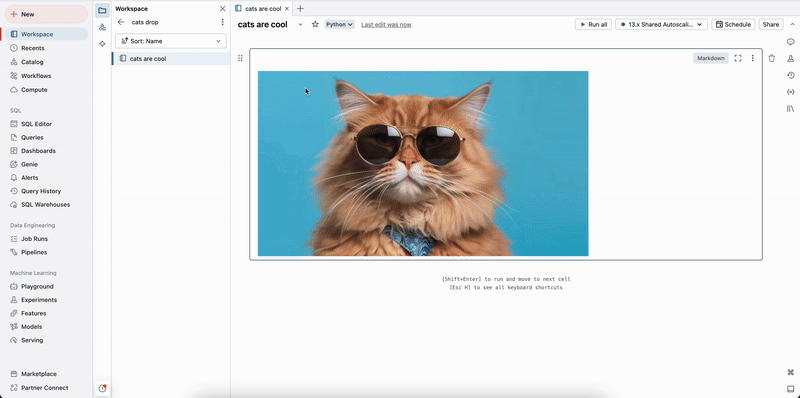
Verbschieben von Bildern per Drag & Drop
Sie können Bilder per Drag & Drop aus Ihrem lokalen Dateisystem in Markdown-Zellen verschieben. Das Bild wird in das aktuelle Arbeitsbereichsverzeichnis hochgeladen und in der Zelle angezeigt.
Anzeigen mathematischer Gleichungen
Notebooks unterstützen KaTeX zum Anzeigen mathematischer Formeln und Gleichungen. Ein auf ein Objekt angewendeter
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
rendert als:

and
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
rendert als:
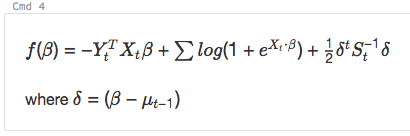
Einschließen von HTML
Mit der Funktion displayHTML können Sie HTML in ein Notebook einschließen. Ein Beispiel hierfür finden Sie unter HTML, D3 und SVG in Notebooks.
Hinweis
Der iframe displayHTML wird von der Domäne databricksusercontent.com bereitgestellt, und die iframe-Sandbox enthält das Attribut allow-same-origin. Auf databricksusercontent.com muss über Ihren Browser zugegriffen werden können. Wenn sie zurzeit in Ihrem Unternehmensnetzwerk blockiert ist, muss sie von der IT zur Positivliste hinzugefügt werden.
Link zu anderen Notebooks
Mithilfe von relativen Pfaden können Sie Links zu anderen Notebooks oder Ordnern in Markdownzellen erstellen. Geben Sie das href-Attribut eines Ankertags als relativen Pfad an. Beginnen Sie dabei mit $, und folgen Sie dann dem gleichen Muster wie in Unix-Dateisystemen:
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>