IA con flujos de datos
En este artículo se describe cómo puede usar la inteligencia artificial (IA) con flujos de datos. En este artículo se describe:
- Cognitive Services
- ML automatizado
- Integración de Azure Machine Learning
Importante
La creación de modelos de aprendizaje automático automatizado (AutoML) de Power BI para flujos de datos v1 se ha retirado y ya no está disponible. Se recomienda a los clientes migrar la solución a la característica AutoML de Microsoft Fabric. Para más información, consulte el anuncio de retirada.
Cognitive Services en Power BI
Con Cognitive Services en Power BI, puede aplicar diversos algoritmos de Azure Cognitive Services para enriquecer los datos en la preparación de datos de autoservicio para flujos de datos.
Los servicios que hoy se admiten son Análisis de sentimiento, Extracción de frases clave, Detección de idioma y Etiquetado de imágenes. Las transformaciones se ejecutan en el servicio Power BI y no necesitan una suscripción a Azure Cognitive Services. Esta característica requiere Power BI Premium.
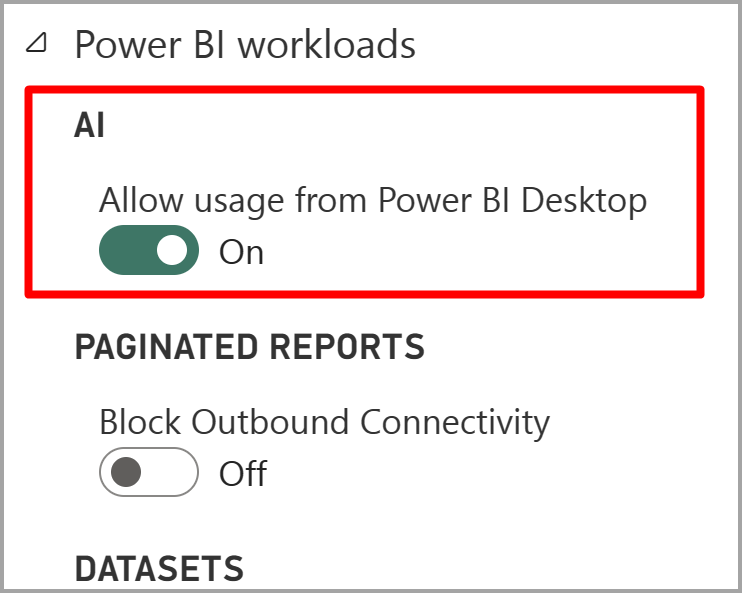
Habilitación de características de IA
Cognitive Services es compatible con los nodos de la capacidad Premium EM2, A2, P1 o F64, y otros nodos con más recursos. Cognitive Services también está disponible con una licencia Premium por usuario (PPU). Una carga de trabajo de IA independiente en la capacidad se usa para ejecutar Cognitive Services. Antes de usar Cognitive Services en Power BI, se debe habilitar la carga de trabajo de IA en la Configuración de capacidad del Portal de administración. Puede activar la carga de trabajo de IA en la sección de cargas de trabajo.
Introducción a Cognitive Services en Power BI
Las transformaciones de Cognitive Services forman parte de la preparación de datos de autoservicio para flujos de datos. Para enriquecer sus datos con Cognitive Services, empiece editando un flujo de datos.
Seleccione el botón Conclusiones de IA en la cinta superior del Editor de Power Query.
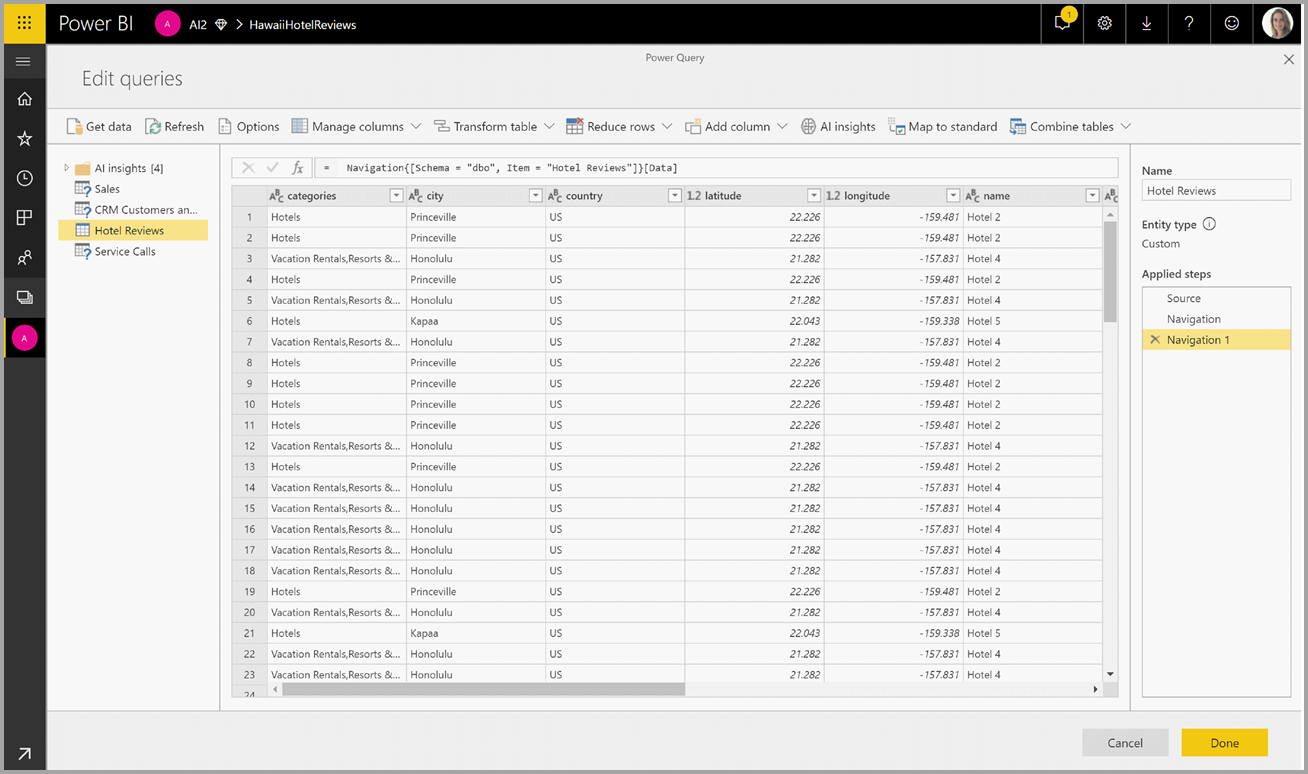
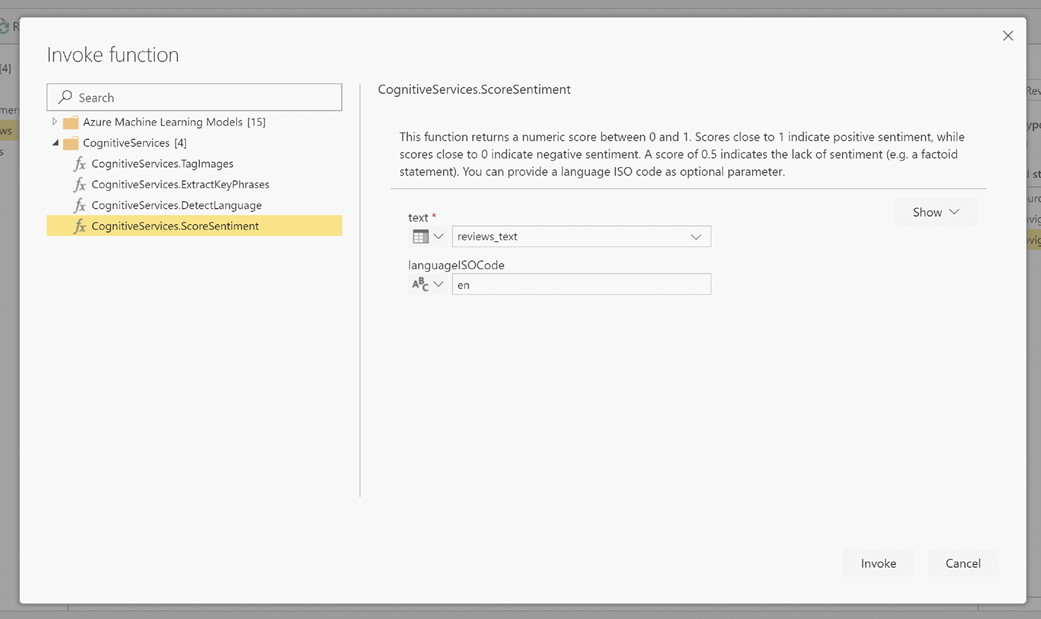
En la ventana emergente, seleccione la función que desee usar y los datos que desee transformar. En este ejemplo se puntúa la opinión de una columna que contiene texto de la crítica.
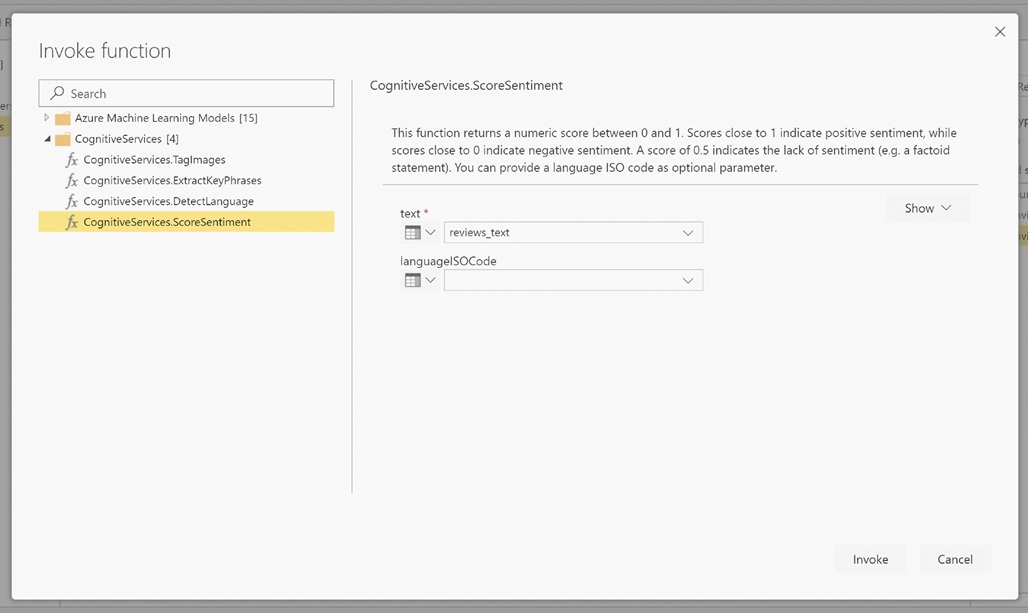
LanguageISOCode es una entrada opcional para especificar el idioma del texto. En este columna se espera un código ISO. Puede usar una columna como entrada para LanguageISOCode, o bien puede usar una columna estática. En este ejemplo, se especifica el idioma como inglés (en) para toda la columna. Si deja esta columna en blanco, Power BI detectará automáticamente el idioma antes de aplicar la función. A continuación, seleccione Invocar.
Después de invocar la función, el resultado se agrega como una nueva columna a la tabla. También se agregará la transformación como un paso aplicado en la consulta.
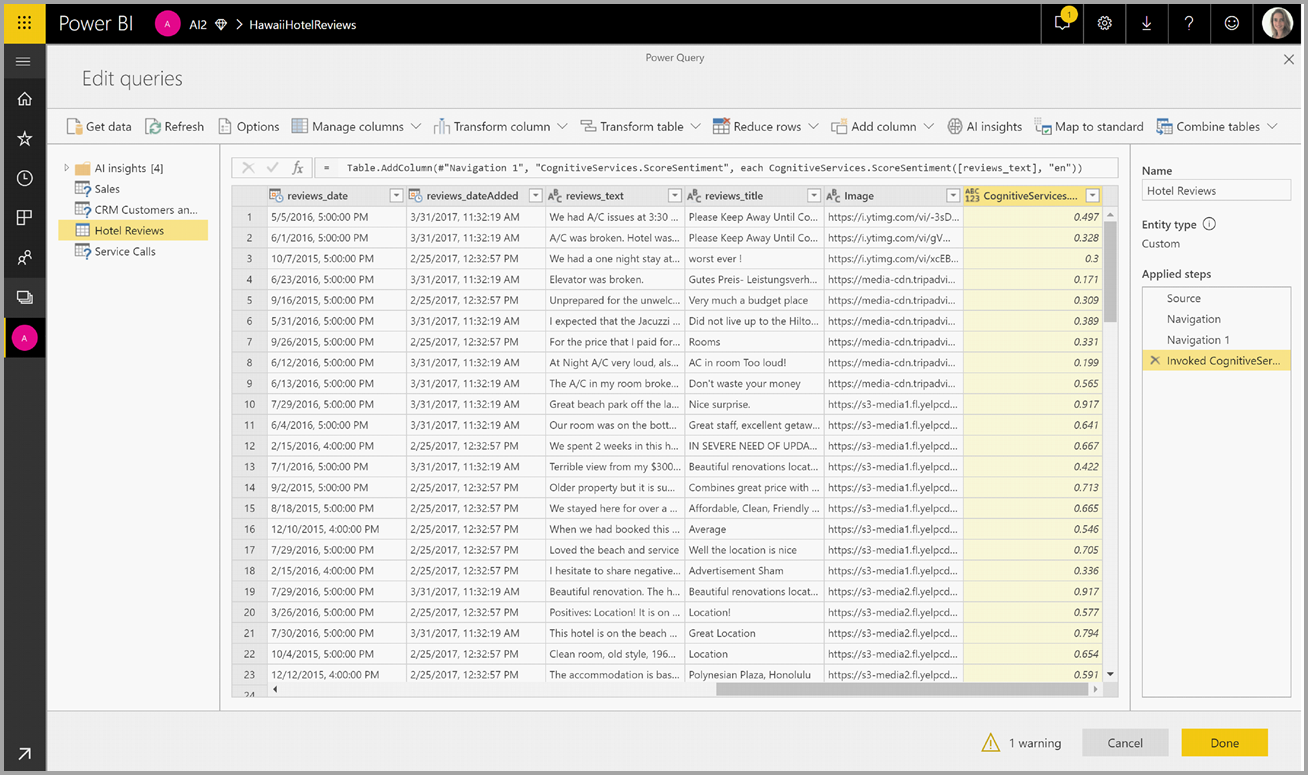
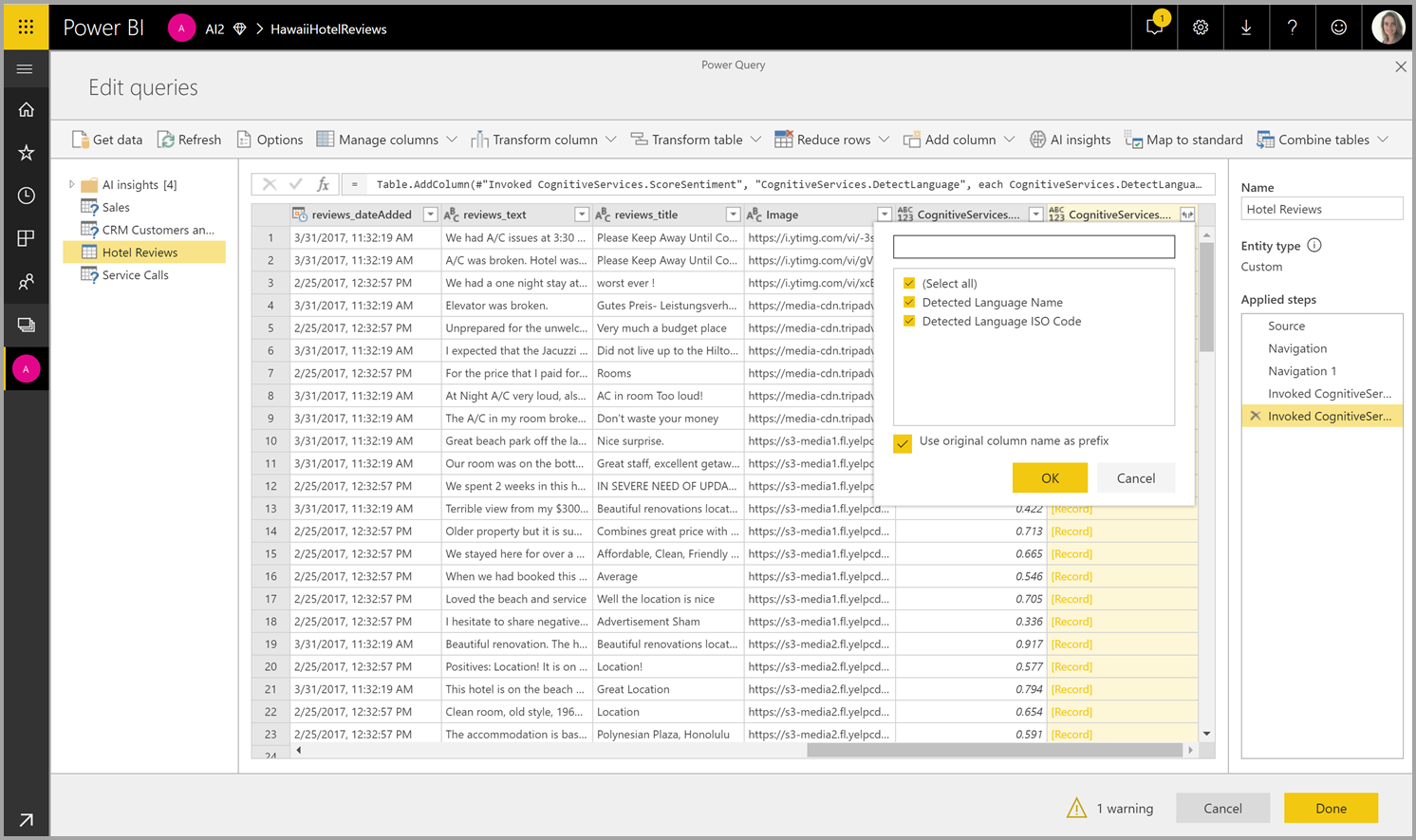
Si la función devuelve varias columnas de salida, con la invocación de la función se agrega una nueva columna con una fila de los numerosas columnas de salida.
Use la opción de expansión para agregar uno o ambos valores como columnas a sus datos.
Funciones disponibles
En esta sección se describen las funciones disponibles en Cognitive Services en Power BI.
Detección de idioma
La función de detección de idioma evalúa la entrada de texto y, para cada columna, devuelve el nombre del idioma y el identificador ISO. Esta función es útil para las columnas de datos que recopilan texto arbitrario, donde se desconoce el idioma. La función espera los datos en formato de texto como entrada.
Text Analytics reconoce hasta 120 idiomas. Para más información, vea ¿Qué es la detección de idioma en Azure Cognitive Service para lenguaje?
Extracción de frases clave
La función Extracción de frases clave evalúa el texto no estructurado y, para cada columna de texto, devuelve una lista de frases clave. La función necesita una columna de texto como entrada y acepta una entrada opcional para LanguageISOCode. Para más información, vea Introducción.
La extracción de frases clave funciona mejor si le proporciona fragmentos de texto más grandes con los que trabajar, lo contrario que el análisis de sentimiento. El rendimiento del análisis de sentimiento es mejor con bloques de texto más pequeños. Para obtener los mejores resultados de ambas operaciones, considere la posibilidad de reestructurar las entradas en consecuencia.
Puntuación de opiniones
La función Score Sentiment (Puntuar opiniones) evalúa la entrada de texto y devuelve una puntuación de opiniones para cada documento, que va desde 0 (negativa) a 1 (positiva). Esta función es útil para detectar opiniones positivas y negativas en las redes sociales, revisiones del cliente y foros de debate.
Text Analytics usa un algoritmo de clasificación de aprendizaje automático para generar una puntuación de opiniones entre 0 y 1. Las puntuaciones más cercanas a 1 indican opiniones positivas. Las puntuaciones más cercanas a 0 indican opiniones negativas. El modelo se entrena previamente con un cuerpo de texto extenso con asociaciones de opiniones. Actualmente, no es posible proporcionar sus propios datos de aprendizaje. El modelo usa una combinación de técnicas durante el análisis de texto, incluidas el procesamiento de texto, el análisis de funciones de sintaxis, la colocación de palabras y las asociaciones de palabras. Para más información sobre el algoritmo, vea Machine Learning y Text Analytics.
El análisis de sentimiento se realiza en toda la columna de entrada, en lugar de extraerse opiniones para una tabla concreta del texto. En la práctica, existe una tendencia a la precisión de la puntuación para mejorar cuando los documentos contienen una o dos frases en lugar de un gran bloque de texto. Durante una fase de evaluación de objetividad, el modelo determina si una columna de entrada como un todo es objetivo o contiene opiniones. Una columna de entrada que es principalmente objetiva no avanza a la fase de detección de opinión, lo que da lugar a una puntuación de 0,50 sin ningún procesamiento adicional. Para las siguientes columnas de entrada de la canalización, la siguiente fase genera una puntuación superior o inferior a 0,50, en función del grado de opinión detectado en la columna de entrada.
Actualmente, Análisis de sentimiento admite inglés, alemán, español y francés. Otros idiomas están en versión preliminar. Para más información, vea ¿Qué es la detección de idioma en Azure Cognitive Service para lenguaje?
Etiquetar imágenes
La función Tag Images (Etiquetar imágenes) devuelve etiquetas basadas en más de 2000 objetos reconocibles, seres vivos, paisajes y acciones. Cuando las etiquetas son ambiguas o no son conocimientos habituales, el resultado proporciona "sugerencias" para aclarar el significado de la etiqueta en el contexto de una configuración conocida. Las etiquetas no se organizan como una taxonomía y no existe ninguna jerarquía de herencia. Una colección de etiquetas de contenido es la base de la "descripción" de una imagen que se muestra en lenguaje natural con formato de oraciones completas.
Después de cargar una imagen o especificar una dirección URL de la imagen, los algoritmos de Computer Vision generan etiquetas basadas en los objetos, seres vivos y acciones identificados en la imagen. El etiquetado no se limita al sujeto principal, como una persona en primer plano, sino que también incluye el entorno (interior o exterior), muebles, herramientas, plantas, animales, accesorios, gadgets, etc.
Esta función requiere una dirección URL de la imagen o una columna Base 64 como entrada. En este momento, el etiquetado de imágenes admite inglés, español, japonés, portugués y chino simplificado. Para más información, vea Interfaz de ComputerVision.
Aprendizaje automático automatizado en Power BI
El aprendizaje automático automatizado (AutoML) para flujos de trabajo permite a los analistas de negocios entrenar, validar e invocar modelos de Machine Learning (ML) directamente en Power BI. Incluye una experiencia sencilla para crear un modelo de aprendizaje automático en el que los analistas pueden usar sus flujos de datos para especificar los datos de entrada para entrenar el modelo. El servicio extrae automáticamente las características más apropiadas, selecciona un algoritmo adecuado, y ajusta y valida el modelo de ML. Después de entrenar un modelo, Power BI genera automáticamente un informe de rendimiento que incluye los resultados de la validación. El modelo se puede invocar sobre los datos nuevos o actualizados del flujo de datos.
Automated Machine Learning está disponible únicamente para flujos de datos hospedados en las capacidades Premium y Embedded.
Uso de AutoML
El aprendizaje automático y la inteligencia artificial están experimentando un aumento sin precedentes de su popularidad en los sectores y los campos de investigación científica. Las empresas también buscan formas de integrar estas nuevas tecnologías en sus operaciones.
Los flujos de datos ofrecen autoservicio de preparación de los datos para macrodatos. AutoML está integrado en flujos de datos y le permite usar el trabajo de preparación de los datos para compilar modelos de Machine Learning, directamente en Power BI.
AutoML en Power BI permite a los analistas de datos usar flujos de datos para compilar modelos de Machine Learning con una experiencia simplificada, solo con usar los conocimientos de Power BI. Power BI automatiza la mayor parte de la ciencia de datos que subyace a la creación de los modelos de ML. Tiene límites de protección para asegurarse de que el modelo generado sea de buena calidad y proporcione una visibilidad sobre el proceso que se usa para crear el modelo de ML.
AutoML admite la creación de modelos de predicción binaria, clasificación y regresión para flujos de datos. Estas características son tipos de técnicas de aprendizaje automático supervisadas, lo que significa que aprenden de los resultados conocidos de observaciones anteriores para predecir los resultados de otras observaciones. El modelo semántico de entrada para entrenar un modelo AutoML es un conjunto de filas que se etiquetan con los resultados conocidos.
AutoML en Power BI integra el aprendizaje automático automatizado de Azure Machine Learning para crear los modelos de aprendizaje automático. Sin embargo, no necesita una suscripción a Azure para usar AutoML en Power BI. El proceso de entrenamiento y hospedaje de los modelos de Machine Learning se administra por completo en el servicio Power BI.
Después de entrenar un modelo de aprendizaje automático, AutoML genera automáticamente un informe de Power BI que explica el rendimiento probable del modelo. AutoML acentúa la explicabilidad y resalta los influenciadores clave en sus entradas que influyen en las predicciones que devuelve el modelo. El informe también incluye métricas clave para el modelo.
Otras páginas del informe generado muestran el resumen estadístico del modelo y los detalles del entrenamiento. El resumen estadístico es de interés para los usuarios que desean ver las medidas estándar de ciencia de datos del rendimiento del modelo. Los detalles de entrenamiento resumen todas las iteraciones que se ejecutaron para crear el modelo, con los parámetros de modelado asociados. También se describe cómo se usó cada entrada para crear el modelo de aprendizaje automático.
Luego, puede aplicar su modelo de aprendizaje automático a los datos para puntuarlos. Cuando se actualiza el flujo de datos, los datos se actualizan con predicciones del modelo de ML. Power BI también incluye una explicación individualizada de cada predicción específica que genera el modelo de ML.
Creación de un modelo de Machine Learning
En esta sección se describe cómo crear un modelo de AutoML.
Preparación de los datos para crear un modelo de aprendizaje automático
Para crear un modelo de Machine Learning en Power BI, primero debe crear un flujo de datos para los datos que incluya información de los resultados históricos; esta información se usa para entrenar el modelo de ML. También debe agregar columnas calculadas para las métricas empresariales que puedan ser fuertes predictores del resultado que intenta predecir. Para más información sobre cómo configurar el flujo de datos, vea Configuración y consumo de un flujo de datos.
AutoML presenta unos requisitos de datos específicos para entrenar un modelo de aprendizaje automático. Estos requisitos se describen en las secciones siguientes, en función de los tipos de modelo correspondientes.
Configuración de las entradas del modelo de Machine Learning
Para crear un modelo de AutoML, seleccione el icono de ML en la columna Acciones de la tabla de flujo de datos y, luego, Agregar un modelo de Machine Learning.
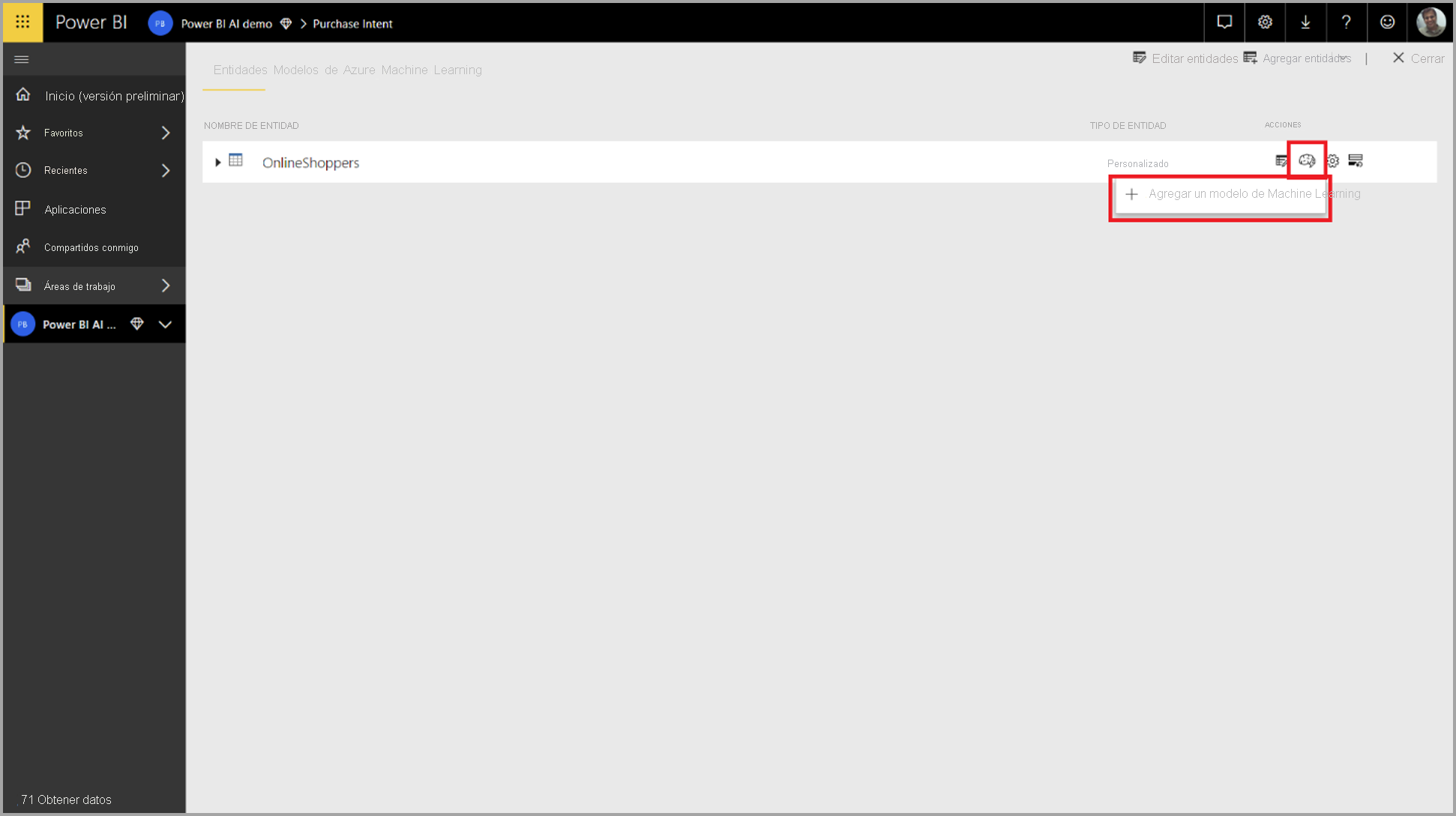
Se inicia una experiencia simplificada, que consta de un asistente que le guía por el proceso de creación del modelo de Machine Learning. El asistente incluye estos sencillos pasos.
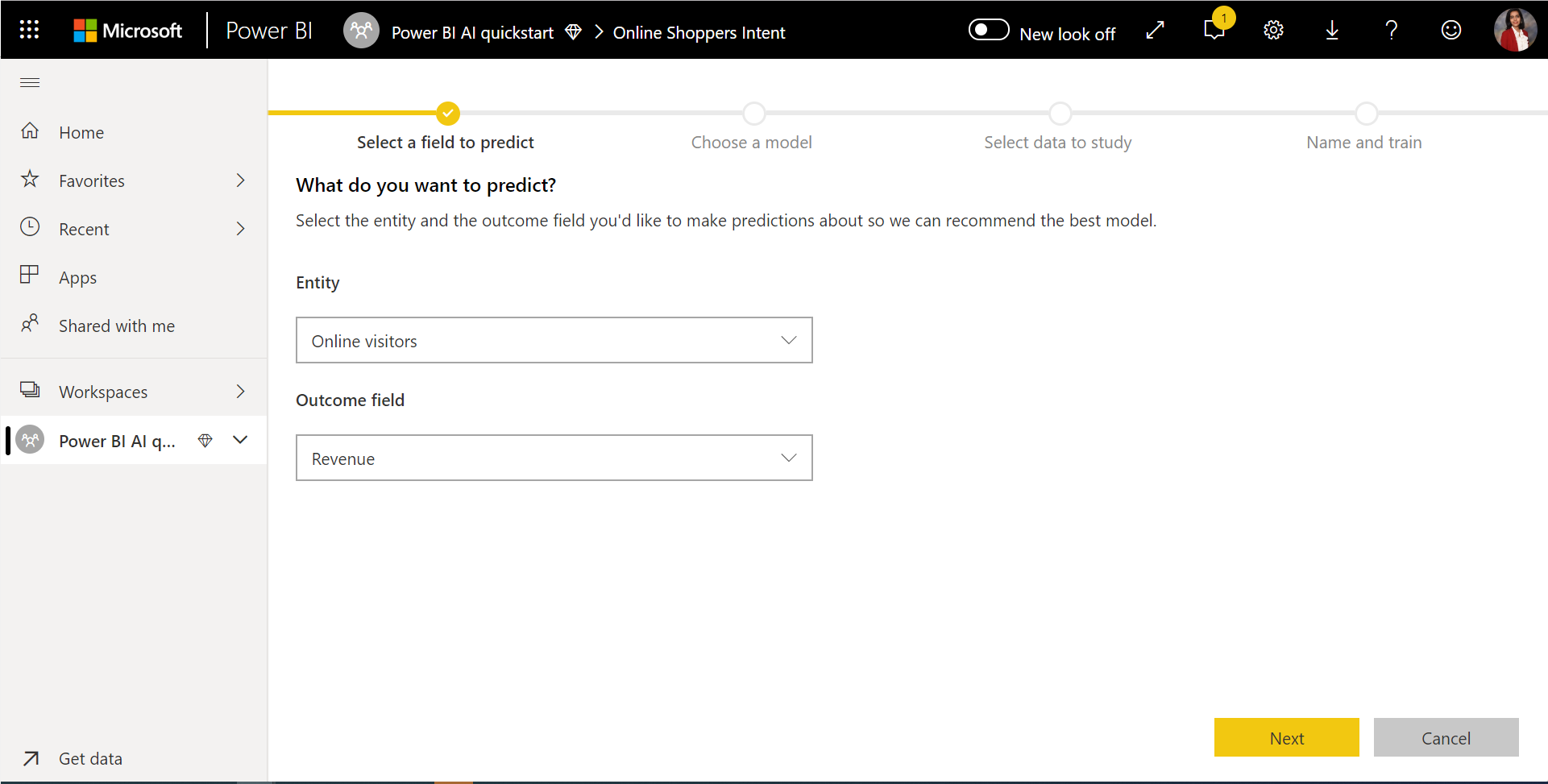
1. Seleccione la tabla con los datos históricos y elija la columna de resultados para la que quiere una predicción
La columna de resultados identifica el atributo de etiqueta para entrenar el modelo de ML, que se muestra en la siguiente imagen.
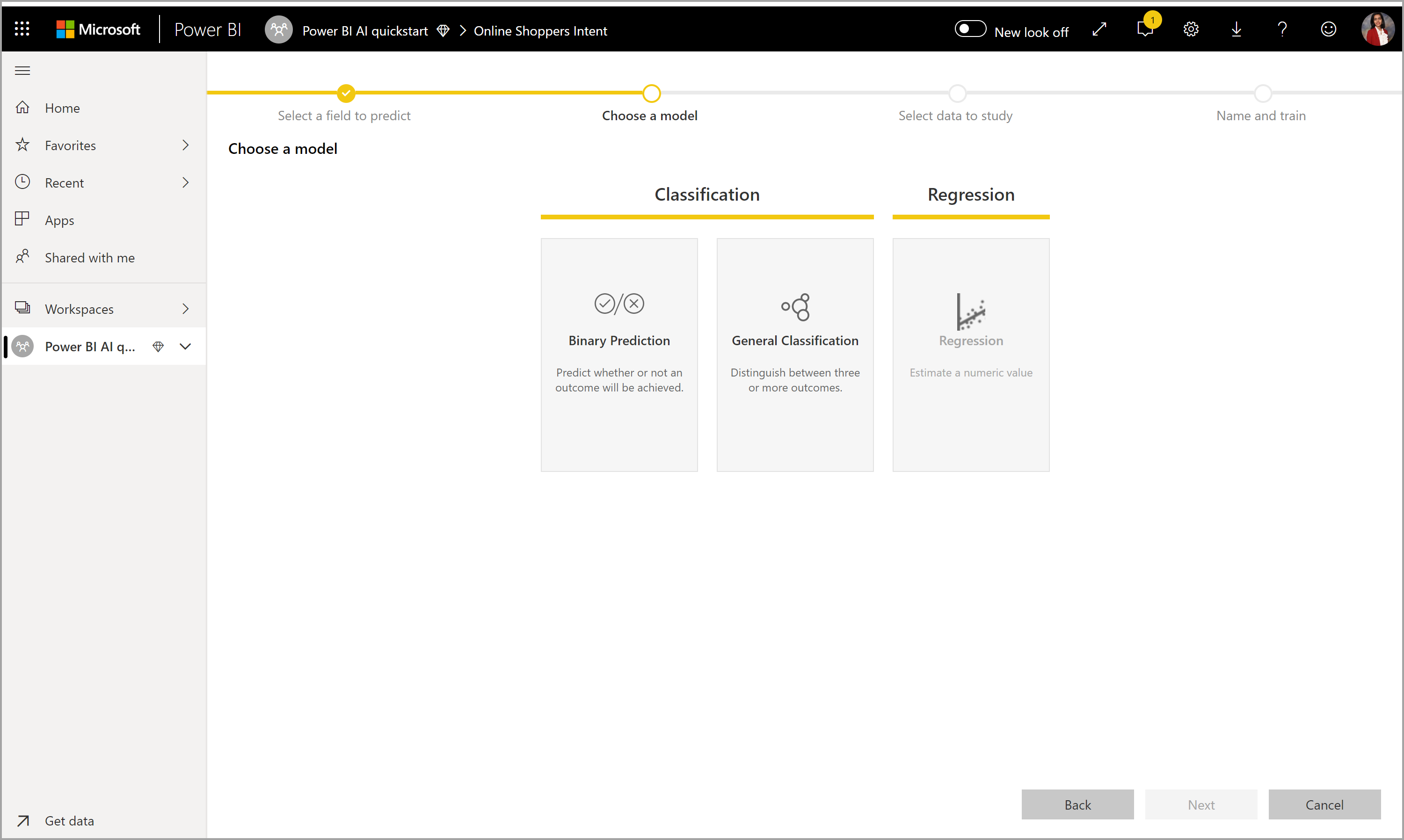
2. Elija un tipo de modelo
Al especificar la columna de resultados, AutoML analiza los datos de etiqueta para recomendar el tipo de modelo de ML más probable que se puede entrenar. Puede elegir otro tipo de modelo en la imagen siguiente si hace clic en Seleccionar un modelo.
Nota
Es posible que algunos tipos de modelo no se admitan con los datos que ha seleccionado y, por tanto, estarán deshabilitados. En el ejemplo anterior, la regresión está deshabilitada, ya que hay una columna de texto seleccionada como columna de resultados.
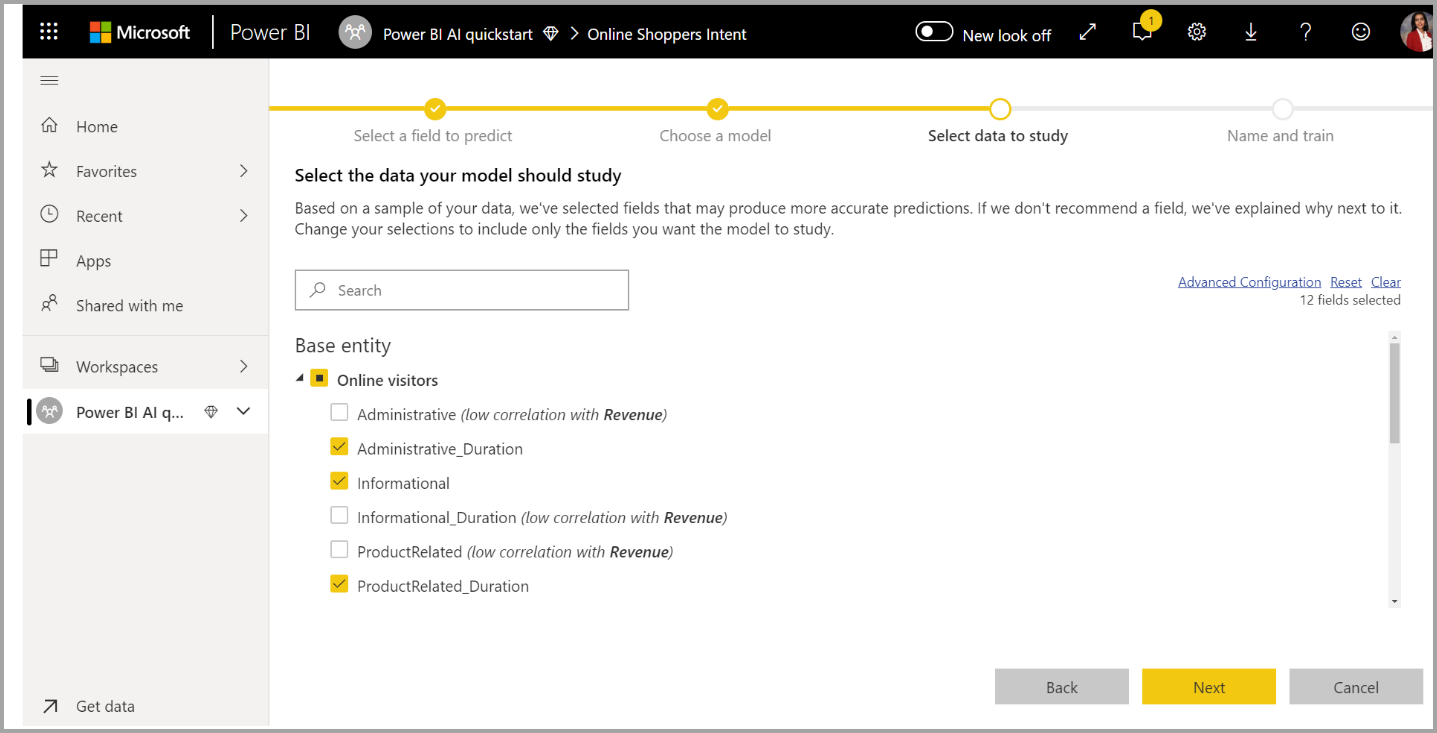
3. Seleccione las entradas que quiere que use el modelo como señales predictivas
AutoML analiza una muestra de la tabla seleccionada para sugerir las entradas que se pueden usar para entrenar el modelo de ML. Las explicaciones se proporcionan junto a las columnas que no están seleccionadas. Si una columna concreta tiene demasiados valores distintos o solo un valor, o bien una correlación baja o alta con la columna de salida, no se recomienda.
Las entradas que dependan de la columna de resultados (o de la columna de etiqueta) no se deben utilizar para entrenar el modelo de ML, ya que afectan a su rendimiento. Estas columnas se marcan como si tuvieran una "correlación sospechosamente alta con la columna de salida". Al introducir estas columnas en los datos de entrenamiento se produce una pérdida de etiquetas, donde el modelo funciona bien con los datos de prueba o validación, pero no puede alcanzar ese rendimiento cuando se utiliza en producción para la puntuación. La pérdida de etiquetas puede ser un posible problema en los modelos de AutoML, cuando el rendimiento del modelo de entrenamiento es demasiado bueno para ser cierto.
Esta recomendación de características se basa en una muestra de datos, por lo que debe revisar las entradas utilizadas. Puede cambiar las selecciones para incluir solo las columnas que quiera que estudie el modelo. También puede seleccionar todas las columnas; para ello, active la casilla junto al nombre de la tabla.
4. Asigne un nombre al modelo y guarde la configuración
En el paso final, puede asignar un nombre al modelo, y seleccionar Guardar, lo que comenzará a entrenar el modelo de ML. Puede optar por reducir el tiempo de entrenamiento para ver unos resultados rápidos o aumentar la cantidad de tiempo empleado en el entrenamiento para obtener el mejor modelo.
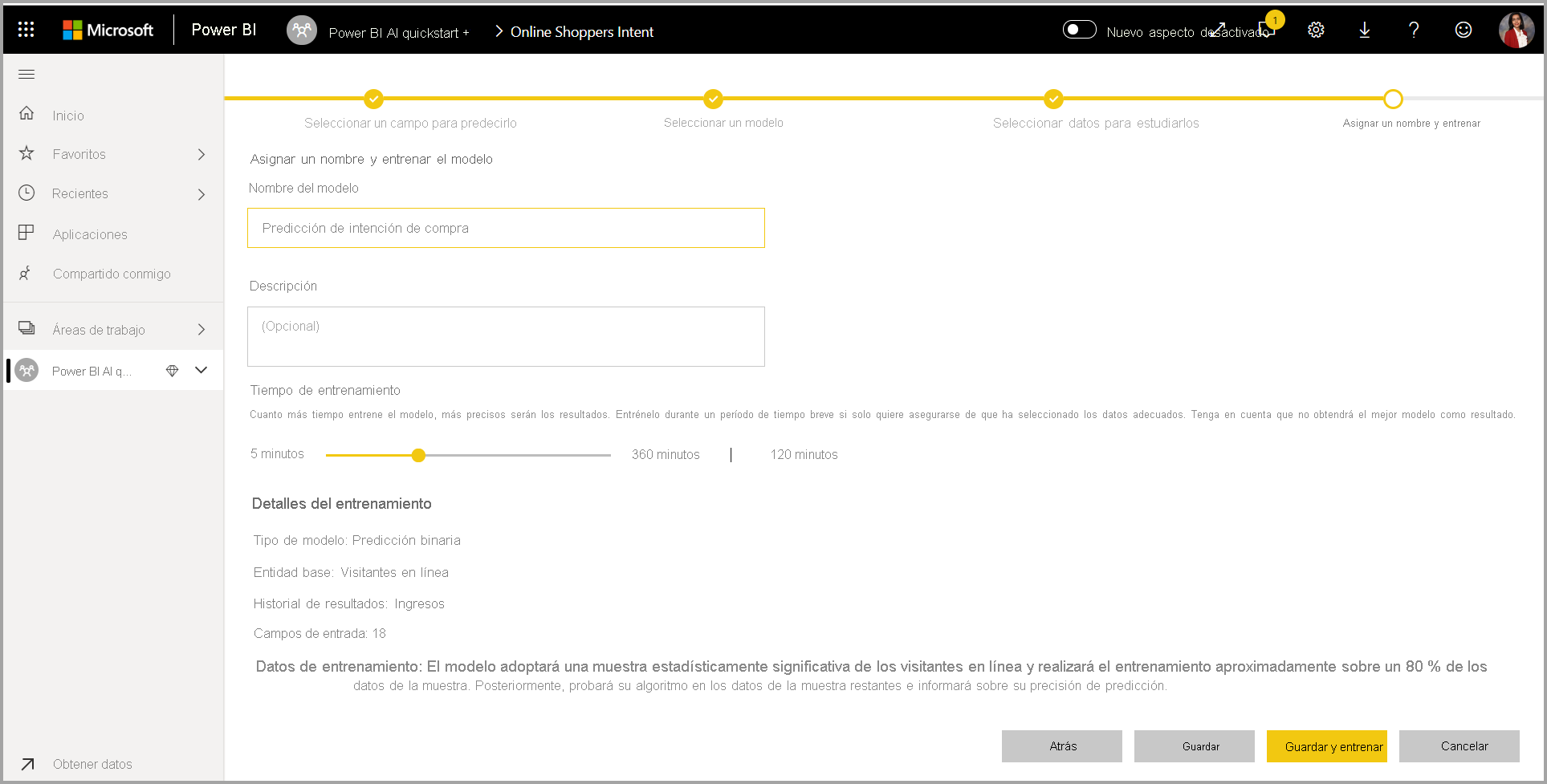
Entrenamiento del modelo de aprendizaje automático
El entrenamiento de modelos de AutoML forma parte de la actualización del flujo de datos. AutoML prepara primero los datos para el entrenamiento. AutoML divide los datos históricos que se proporcionan en modelos semánticos de entrenamiento y pruebas. El modelo semántico de prueba es un conjunto de espera que se usa para validar el rendimiento del modelo después del entrenamiento. Estos conjuntos se consideran tablas de entrenamiento y prueba en el flujo de datos. AutoML usa la validación cruzada para la validación del modelo.
A continuación, se analiza cada columna de entrada y se aplica imputación, que reemplaza los valores que faltan por valores sustitutos. AutoML usa un par de estrategias de imputación diferentes. En el caso de atributos de entrada tratados como características numéricas, la media de los valores de columna se utiliza para imputación. En el caso de atributos de entrada tratados como características de categorías, AutoML utiliza el modo de los valores de columna para imputación. El marco AutoML calcula la media y el modo de los valores usados para la imputación en el modelo semántico de entrenamiento de submuestreo.
A continuación, se aplica a los datos el muestreo y la normalización, tal como sea necesario. En el caso de los modelos de clasificación, AutoML ejecuta los datos de entrada mediante el muestreo estratificado y equilibra las clases para asegurarse de que los recuentos de filas son iguales para todos.
AutoML aplica varias transformaciones a cada columna de entrada seleccionada en función de su tipo de datos y sus propiedades estadísticas. Luego, usa estas transformaciones para extraer características que se emplean para entrenar el modelo de aprendizaje automático.
El proceso de entrenamiento de los modelos de AutoML consta de hasta 50 iteraciones con distintos algoritmos de modelado y configuraciones de hiperparámetros hasta encontrar el modelo con el mejor rendimiento. El entrenamiento puede finalizar pronto con iteraciones menores si AutoML ve que no se observa ninguna mejora del rendimiento. AutoML evalúa el rendimiento de cada uno de estos modelos validando con el modelo semántico de prueba de retención. Durante este paso del entrenamiento, AutoML crea varias canalizaciones para el entrenamiento y la validación de estas iteraciones. El proceso de evaluación del rendimiento de los modelos puede llevar tiempo, entre varios minutos y un par de horas, hasta el tiempo de entrenamiento configurado en el asistente. El tiempo necesario depende del tamaño del modelo semántico y de los recursos de capacidad disponibles.
En algunos casos, es posible que el modelo final generado use aprendizaje de conjunto, donde se utilizan varios modelos para ofrecer un mejor rendimiento predictivo.
Explicabilidad del modelo de AutoML
Después de entrenar el modelo, AutoML analiza la relación entre las características de entrada y la salida del modelo. Evalúa la magnitud del cambio en la salida del modelo semántico de la prueba de retención para cada característica de entrada. Esta relación se conoce como importancia de la característica. Este análisis sucede como parte de la actualización después de completar el entrenamiento. Por tanto, es posible que la actualización tarde más que el tiempo de entrenamiento configurado en el asistente.
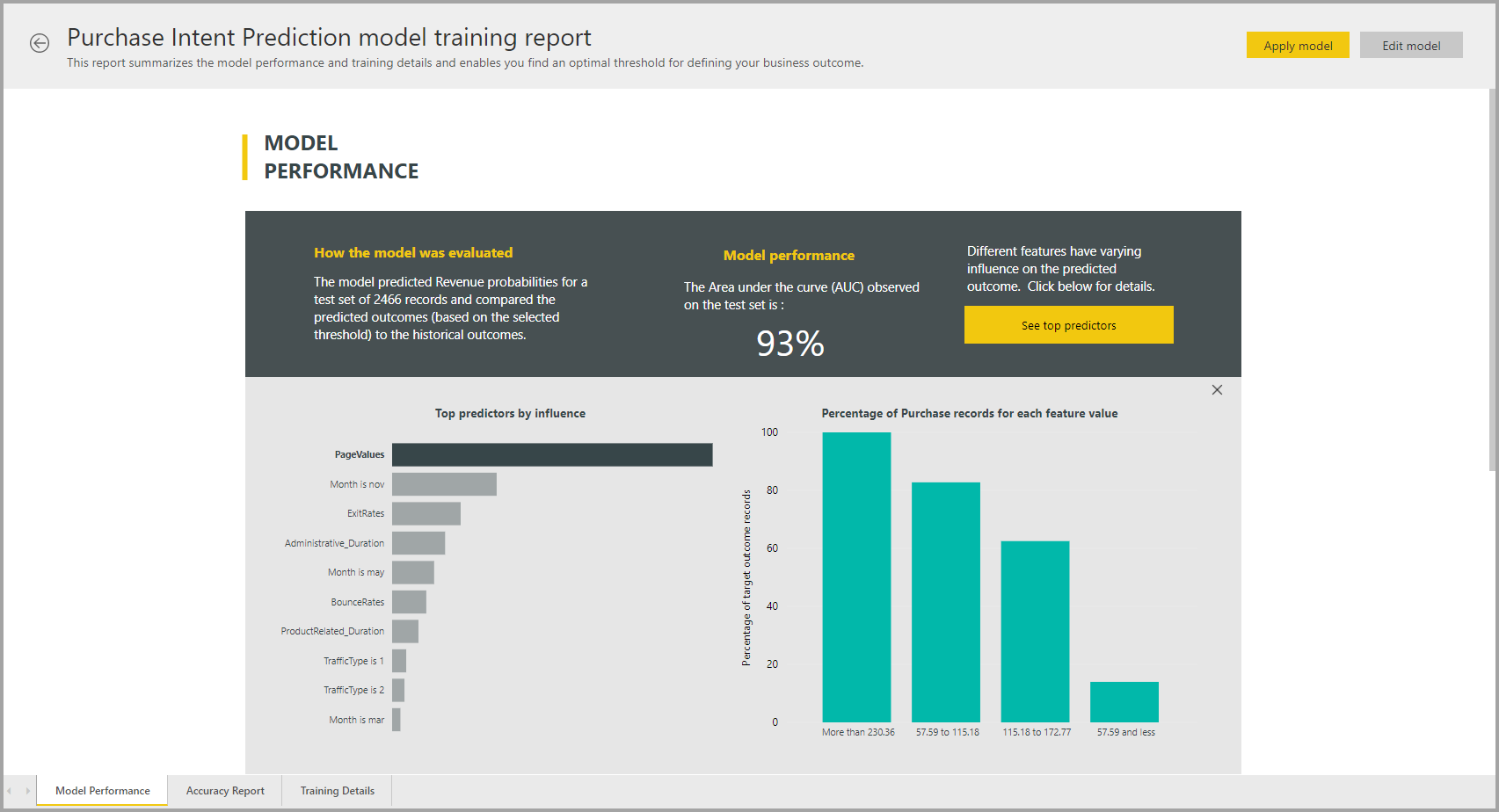
Informe del modelo de AutoML
AutoML genera un informe de Power BI que resume el rendimiento del modelo durante la validación, junto con la importancia de característica global. Se puede acceder a este informe desde la pestaña Modelos de Machine Learning después de que la actualización del flujo de datos sea correcta. En él se resumen los resultados de aplicar el modelo de aprendizaje automático a los datos de prueba de exclusión y comparar las predicciones con los valores de resultado conocidos.
Puede revisar el informe del modelo para comprender su rendimiento. También puede validar que los influenciadores clave del modelo se alineen con las conclusiones empresariales sobre los resultados conocidos.
Los gráficos y las medidas que se usan para describir el rendimiento del modelo en el informe dependen del tipo de modelo. Estos gráficos y medidas del rendimiento se describen en las secciones siguientes.
Es posible que en otras páginas del informe se describan medidas estadísticas sobre el modelo desde una perspectiva de la ciencia de datos. Por ejemplo, el informe de Predicción binaria incluye un gráfico de ganancia y la curva ROC del modelo.
También incluye una página Detalles de aprendizaje con una descripción de cómo se entrenó el modelo y un gráfico que indica el rendimiento del modelo en cada ejecución de iteraciones.
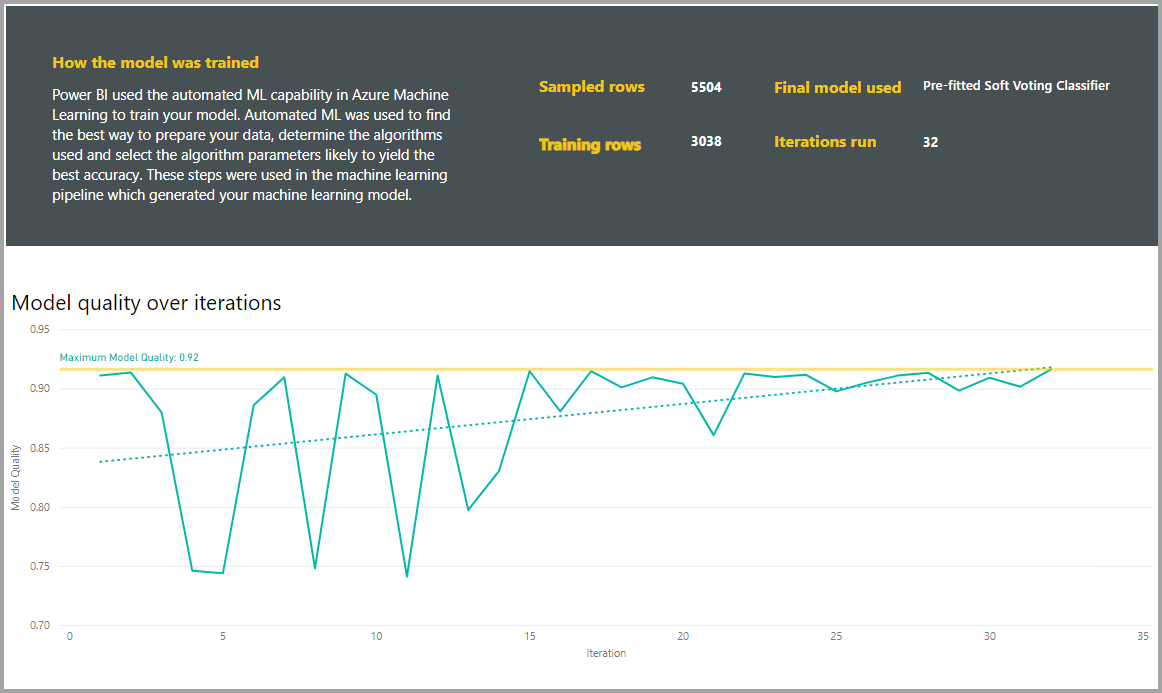
Otra sección de esta página describe el tipo detectado de la columna de entrada y el método de imputación que se usa para rellenar los valores que faltan. También incluye los parámetros que usa el modelo final.
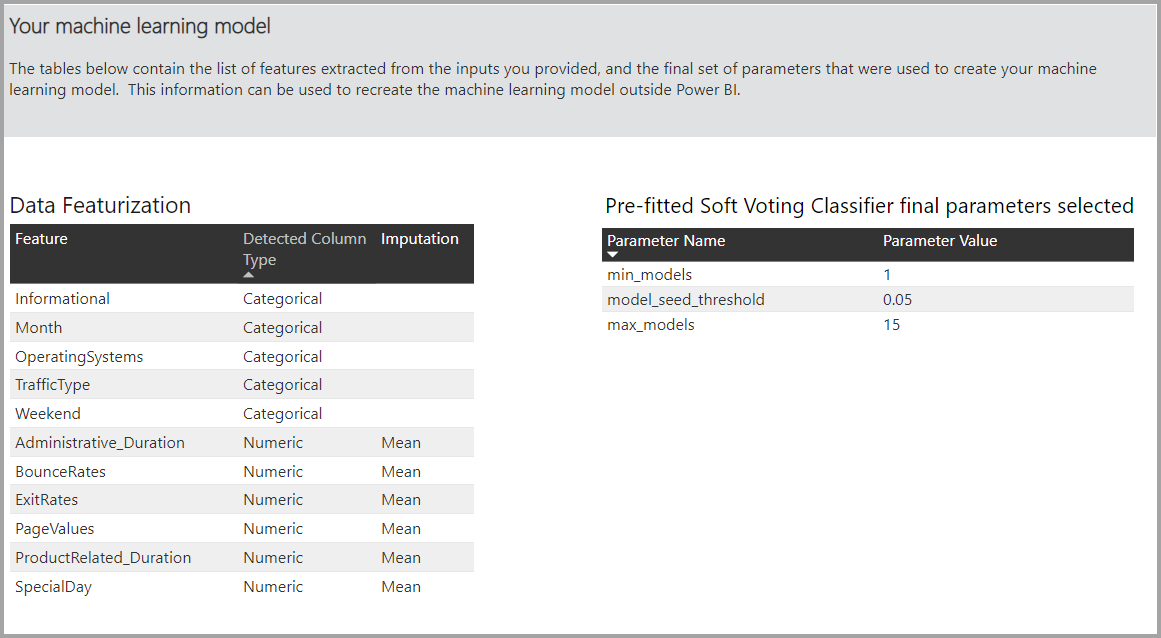
Si el modelo generado usa el aprendizaje de conjunto, en la página Detalles del aprendizaje también se incluye un gráfico en el que se muestra el peso de cada modelo constituyente en el conjunto y sus parámetros.

Aplicación del modelo de AutoML
Si está satisfecho con el rendimiento del modelo de aprendizaje automático creado, puede aplicarlo a los datos nuevos o actualizados cuando se actualice el flujo de datos. En el informe del modelo, seleccione el botón Aplicar en la esquina superior derecha o el botón Aplicar el modelo de ML en las acciones de la pestaña Modelos de Machine Learning.
Para aplicar el modelo de ML, debe especificar el nombre de la tabla a la que se debe aplicar y un prefijo para las columnas que se agregarán a esta tabla en la salida del modelo. El prefijo predeterminado de los nombres de columna es el nombre del modelo. Es posible que la función Aplicar incluya más parámetros específicos del tipo de modelo.
Al aplicar el modelo de ML, se crean dos tablas de flujo de datos que contienen las predicciones y las explicaciones individualizadas para cada fila que puntúa en la tabla de salida. Por ejemplo, si aplica el modelo PurchaseIntent a la tabla OnlineShoppers, la salida genera las tablas OnlineShoppers enriched PurchaseIntent y OnlineShoppers enriched PurchaseIntent explanations. Para cada fila de la tabla enriquecida, Explanations se divide en varias filas de la tabla de explicaciones enriquecidas basada en la característica de entrada. ExplanationIndex ayuda a asignar las filas de la tabla de explicaciones enriquecidas a la fila en una tabla enriquecida.
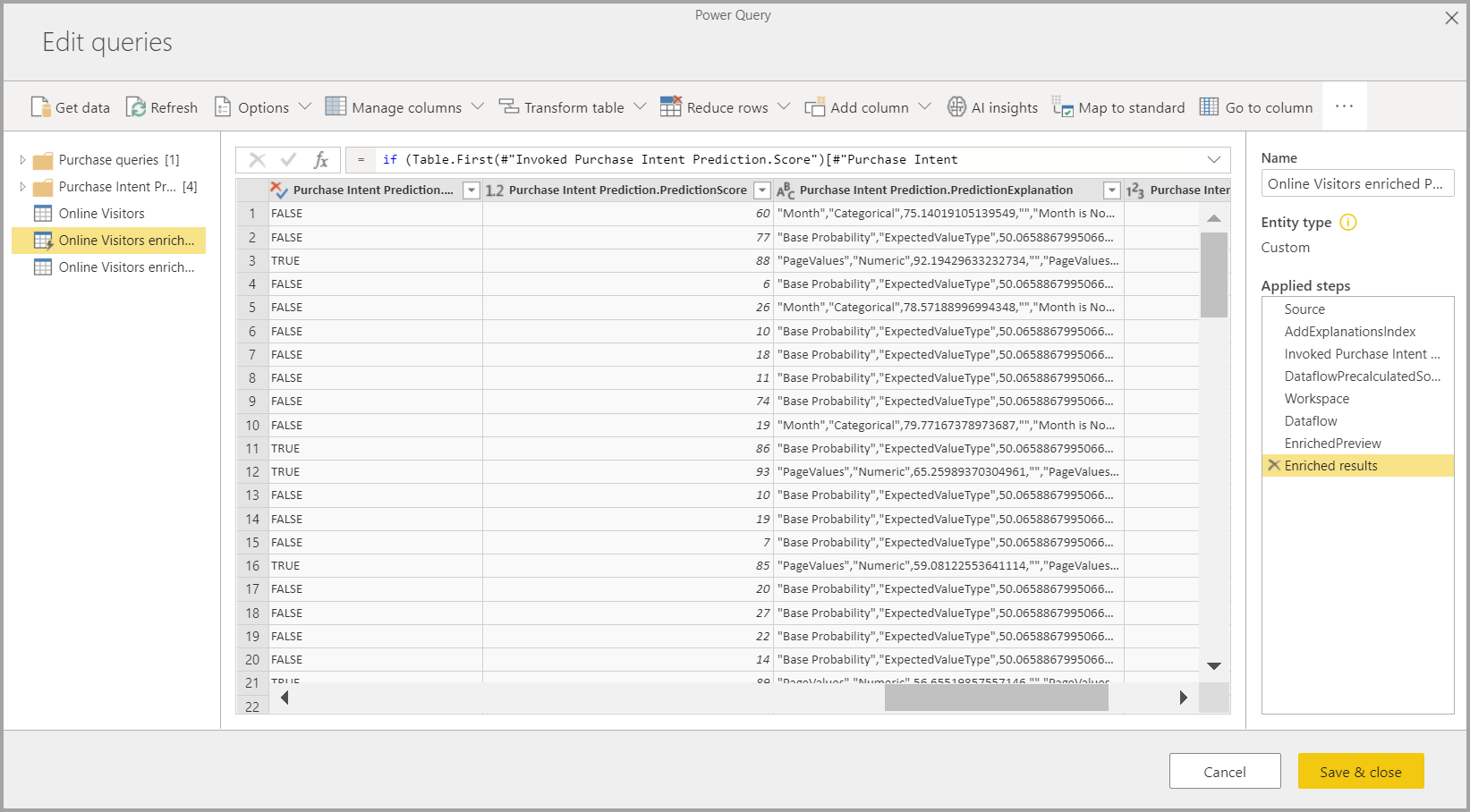
También puede aplicar un modelo de AutoML de Power BI a tablas de cualquier flujo de datos de la misma área de trabajo mediante Conclusiones de IA del explorador de funciones de PQO. De esta manera, puede usar los modelos creados por otros en la misma área de trabajo sin tener que ser propietario del flujo de datos que tiene el modelo. Power Query detecta todos los modelos de aprendizaje automático de Power BI del área de trabajo y los expone como funciones dinámicas de Power Query. Pueden invocar esas funciones si accede a ellas desde la cinta del Editor de Power Query, o bien si invoca directamente la función M. Actualmente, esta funcionalidad solo es compatible con los flujos de datos de Power BI y con Power Query Online en el servicio Power BI. Este proceso es diferente a aplicar modelos de Machine Learning dentro de un flujo de datos mediante el asistente para AutoML. Con este método no se crea ninguna tabla de explicaciones. A menos que sea el propietario del flujo de datos, no puede acceder a los informes de entrenamiento del modelo ni volver a entrenar el modelo. Además, si el modelo de origen se edita (se agregan o se quitan columnas de entrada), o si se elimina el modelo o el flujo de datos de origen, este flujo de datos dependiente se interrumpirá.
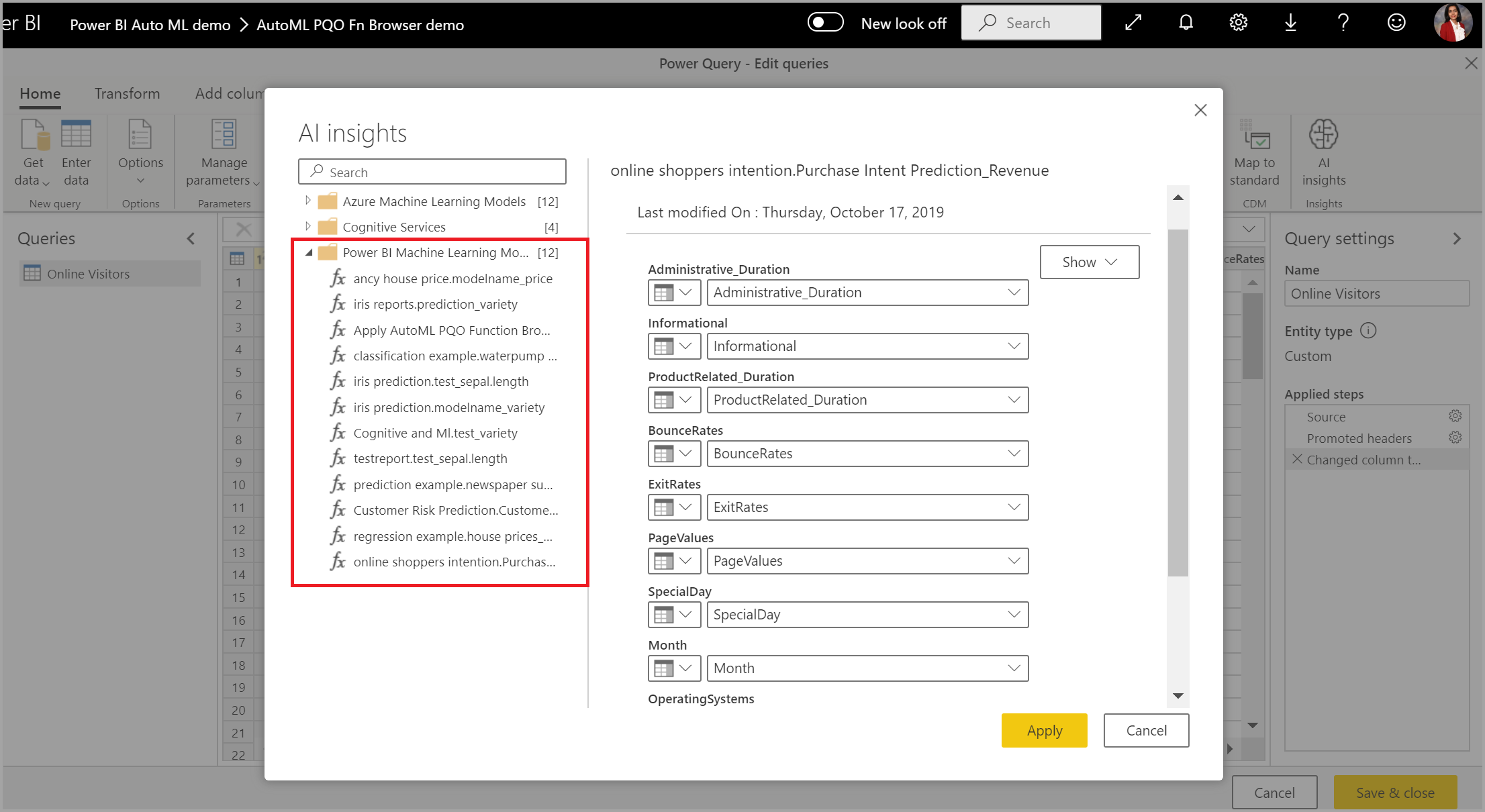
Tras aplicar el modelo, AutoML mantiene siempre las predicciones actualizadas cuando se actualiza el flujo de datos.
Para usar las conclusiones y las predicciones del modelo de ML en un informe de Power BI, puede conectarse a la tabla de salida desde Power BI Desktop mediante el conector de flujos de datos.
Modelos de predicción binaria
Los modelos de predicción binaria, conocidos más formalmente como modelos de clasificación binaria, se usan para clasificar un modelo semántico en dos grupos. Se usan para predecir eventos que puedan tener un resultado binario. Por ejemplo, si una oportunidad de ventas se va a convertir, si una cuenta se va a renovar, si una factura se va a pagar a tiempo, si una transacción es fraudulenta, etc.
La salida de un modelo de predicción binaria es una puntuación de probabilidad, que identifica la probabilidad de que se alcance el resultado objetivo.
Entrenamiento de un modelo de predicción binaria
Requisitos previos:
- Se requieren 20 filas como mínimo de datos históricos para cada clase de resultados.
El proceso de creación de un modelo de predicción binaria sigue los mismos pasos que otros modelos de AutoML, descritos en la sección anterior Configuración de las entradas del modelo de Machine Learning. La única diferencia se encuentra en el paso Seleccionar un modelo, donde puede seleccionar el valor del resultado de destino que más le interese. También puede proporcionar etiquetas descriptivas para los resultados que se van a usar en el informe generado automáticamente y que resume los resultados de la validación del modelo.
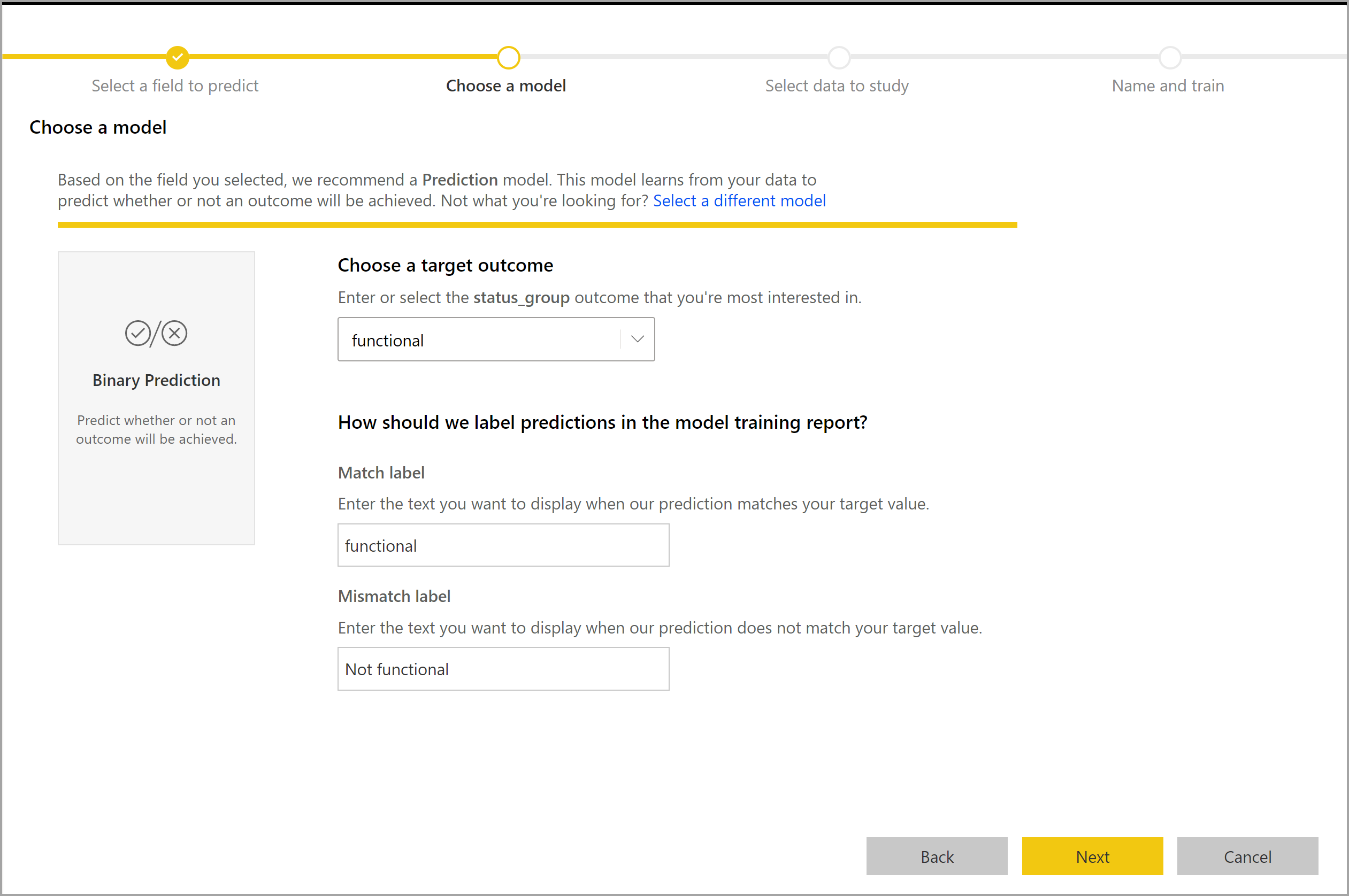
Informe del modelo de predicción binaria
El modelo de predicción binaria genera como salida una probabilidad de que una fila logre el resultado objetivo. El informe incluye un sector para el umbral de probabilidad, que influye en cómo se interpretan las puntuaciones por encima y por debajo del umbral de probabilidad.
El informe describe el rendimiento del modelo en términos de verdaderos positivos, falsos positivos, verdaderos negativos y falsos negativos. Los verdaderos positivos y verdaderos negativos son resultados que se predicen correctamente para las dos clases de los datos de resultados. Los falsos positivos son filas de las que se ha predicho que tendrían un resultado objetivo, pero en realidad no lo han tenido. Por el contrario, los falsos negativos son filas que han tenido un resultado objetivo, pero de las que se ha predicho que no lo tendrían.
Las medidas, como la precisión y la recuperación, describen el efecto del umbral de probabilidad en los resultados de predicción. Puede usar la segmentación de datos del umbral de probabilidad para seleccionar un umbral que logre un compromiso equilibrado entre la precisión y la recuperación.

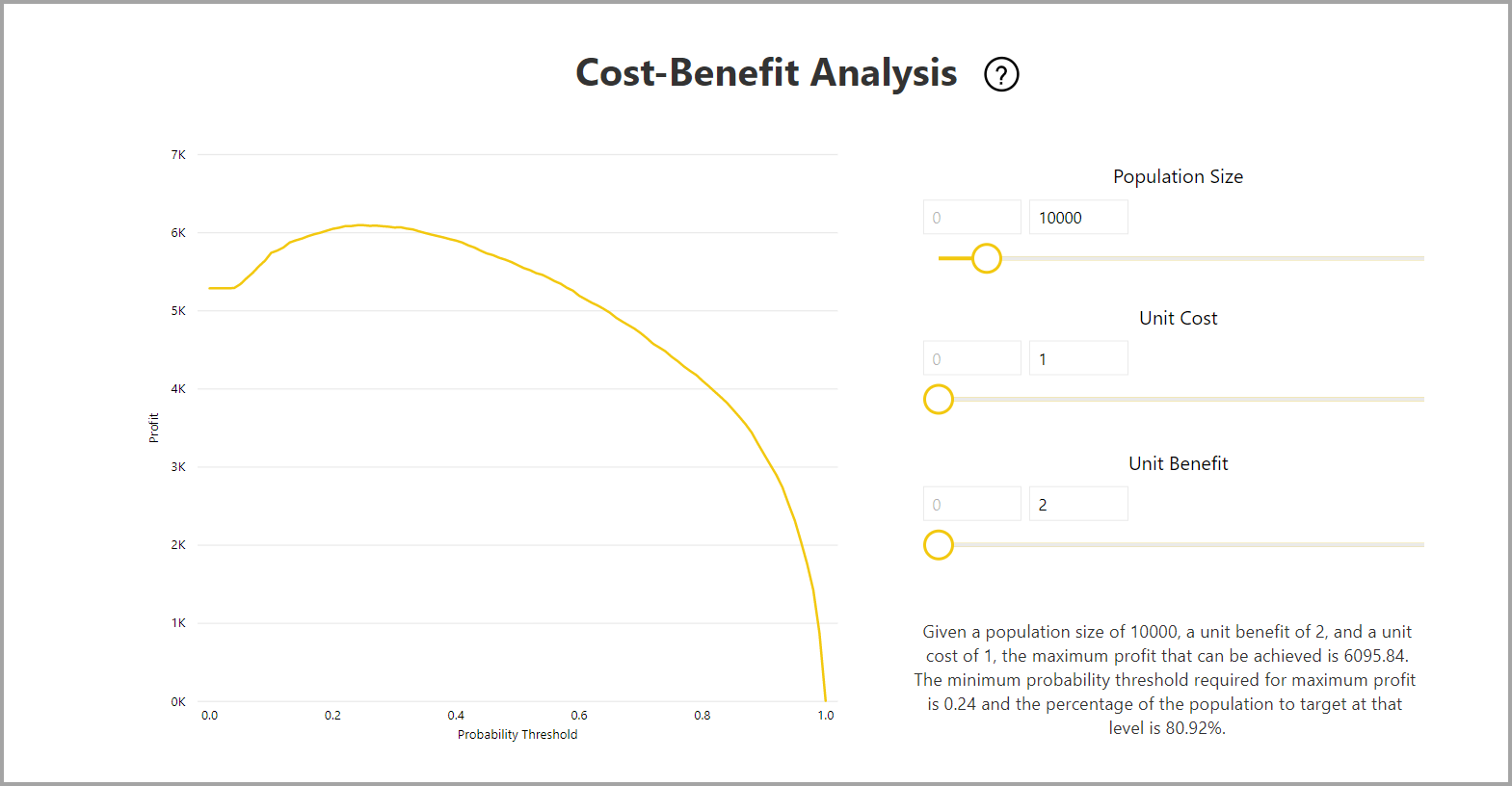
El informe también incluye una herramienta de análisis de costos y beneficios que ayuda a identificar el subconjunto de la población al que debe dirigirse para obtener las mayores ganancias. Dado un costo unitario estimado de destino y un beneficio unitario de lograr un resultado objetivo, el análisis de costos y beneficios intenta maximizar las ganancias. Puede usar esta herramienta para elegir el umbral de probabilidad en función del punto máximo del gráfico para maximizar las ganancias. También puede utilizar el gráfico para calcular las ganancias o los costos para el umbral de probabilidad elegido.
La página Accuracy Report (Informe de precisión) del informe del modelo incluye el gráfico Cumulative Gains (Ganancias acumulativas) y la curva de ROC del modelo. Estos datos proporcionan medidas estadísticas del rendimiento del modelo. Los informes incluyen descripciones de los gráficos que se muestran.
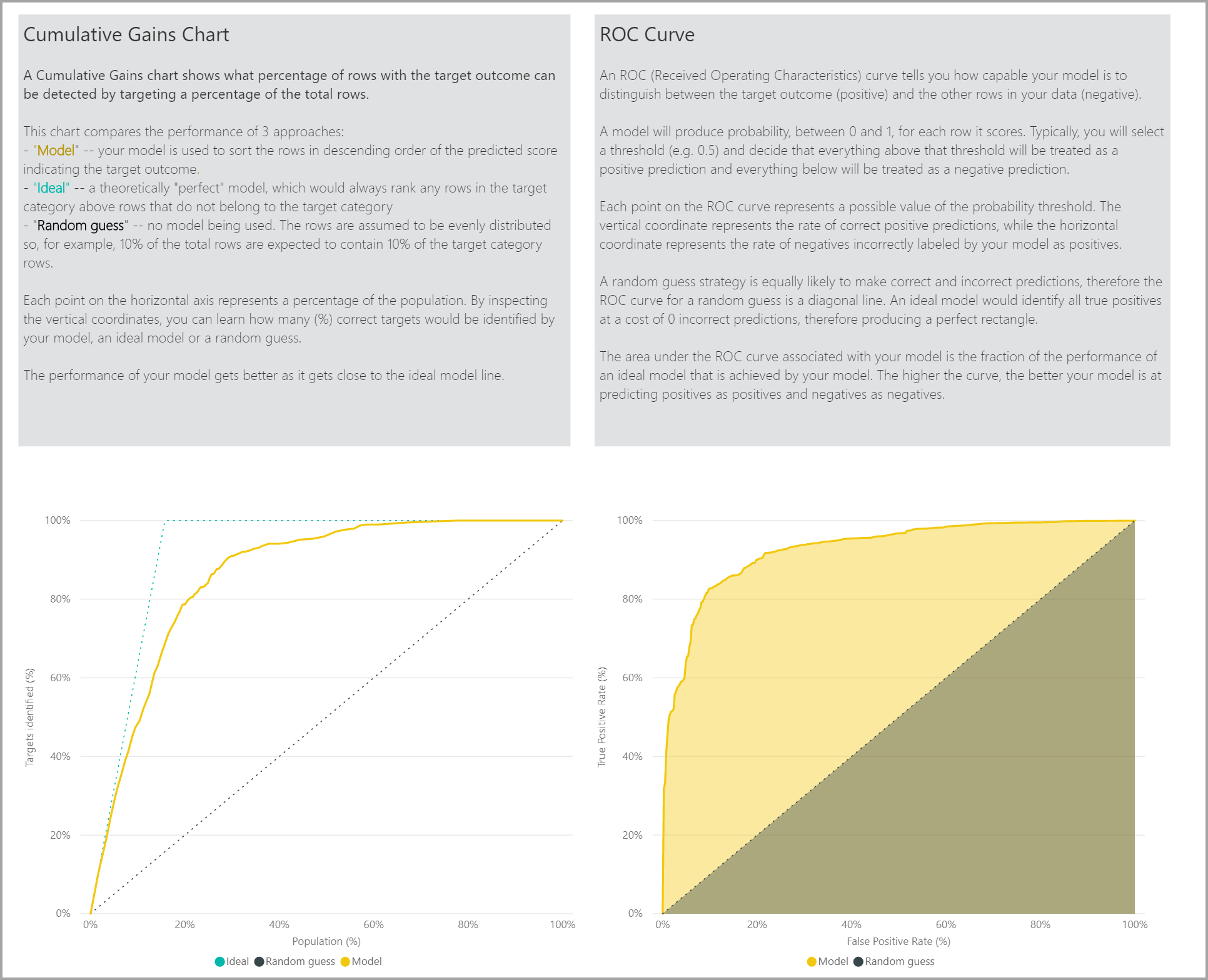
Aplicación de un modelo de predicción binaria
Para aplicar un modelo de predicción binaria, debe especificar la tabla con los datos a los que quiere aplicar las predicciones del modelo de aprendizaje automático. Otros parámetros incluyen el prefijo de nombre de la columna de salida y el umbral de probabilidad para clasificar el resultado de predicción.
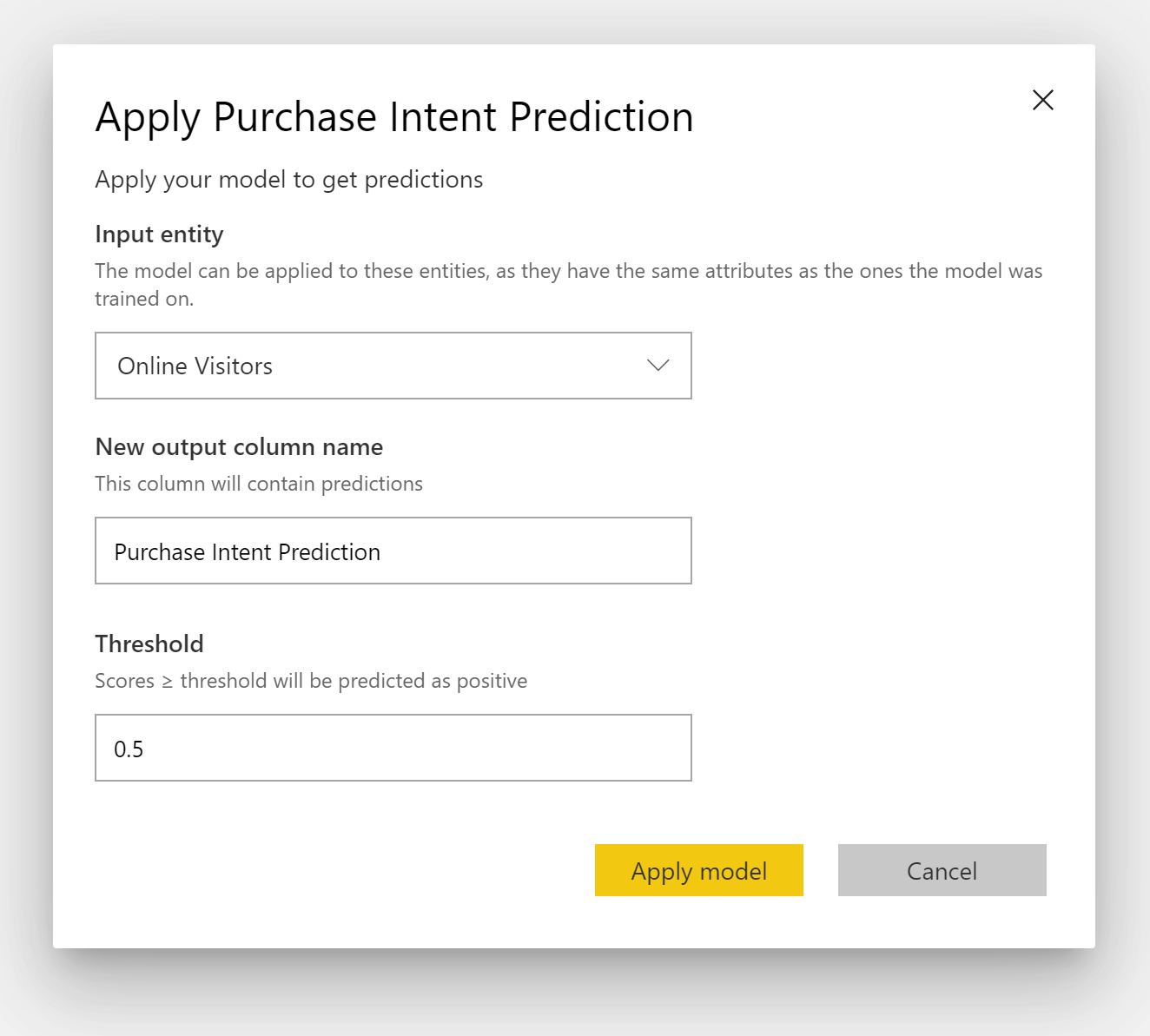
Cuando se aplica un modelo de predicción binaria, se agregan cuatro columnas de salida a la tabla de salida enriquecida: Outcome, PredictionScore, PredictionExplanation y ExplanationIndex. El prefijo se especifica en los nombres de columna de la tabla al aplicar el modelo.
PredictionScore es una probabilidad porcentual, que identifica la probabilidad de que se alcance el resultado objetivo.
La columna Outcome contiene la etiqueta del resultado de predicción. Los registros con probabilidades que superan el umbral se predicen como probables para lograr el resultado objetivo y se etiquetan como verdaderos. Los registros que se encuentran por debajo del umbral se predicen como improbables para lograr el resultado y se etiquetan como Falsos.
La columna PredictionExplanation contiene una explicación con la influencia específica que tuvieron las características de entrada en PredictionScore.
Modelos de clasificación
Los modelos de clasificación se usan para clasificar un modelo semántico en varios grupos o clases. Se utilizan para predecir eventos que pueden tener uno de los diversos resultados posibles. Por ejemplo, si es probable que un cliente tenga un valor de duración alto, medio o bajo. También pueden predecir si el riesgo de impago es alto, moderado, bajo o muy bajo, etc.
La salida de un modelo de clasificación es una puntuación de probabilidad, que identifica la probabilidad de que una fila alcance los criterios de una clase determinada.
Entrenamiento de un modelo de clasificación
La tabla de entrada que contiene los datos de entrenamiento para un modelo de clasificación debe tener una columna de número entero o de cadena como columna de resultados para identificar los resultados conocidos anteriores.
Requisitos previos:
- Se requieren 20 filas como mínimo de datos históricos para cada clase de resultados.
El proceso de creación de un modelo de clasificación sigue los mismos pasos que otros modelos de AutoML, descritos en la sección anterior Configuración de las entradas del modelo de Machine Learning.
Informe del modelo de clasificación
Power BI crea el informe del modelo de clasificación aplicando el modelo de ML a los datos de prueba de exclusión. Después, compara la clase predicha de una fila con la clase conocida real.
El informe del modelo incluye un gráfico con el desglose de las filas clasificadas correcta e incorrectamente para cada clase conocida.
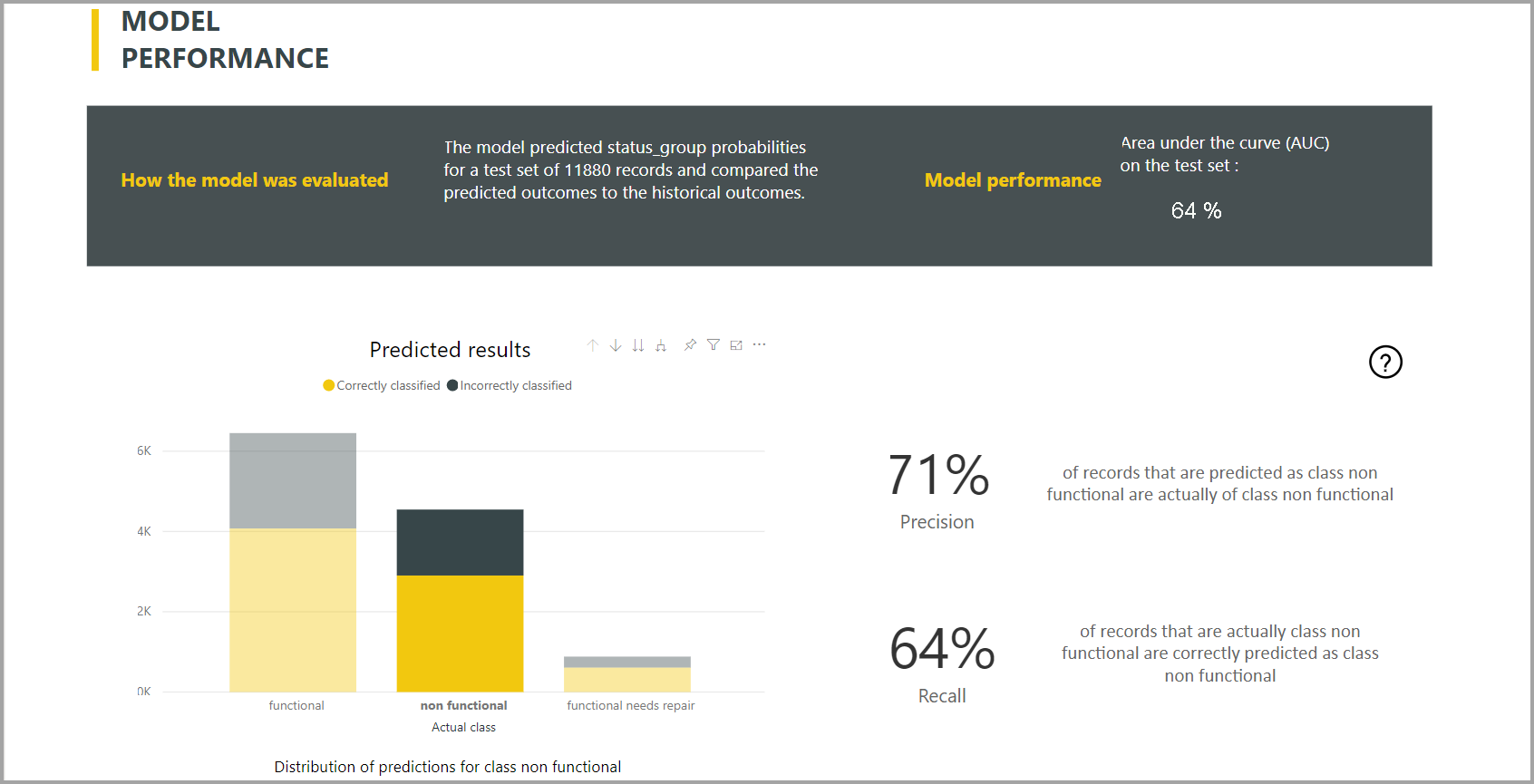
Una acción de exploración en profundidad adicional específica de la clase permite analizar cómo se distribuyen las predicciones de una clase conocida. En este análisis se muestran las otras clases en las que es probable que las filas de esa clase conocida estén mal clasificadas.
La explicación del modelo en el informe también incluye los principales predictores de cada clase.
El informe del modelo de clasificación también incluye una página de detalles de entrenamiento similar a las páginas de otros tipos de modelos, como se ha descrito antes en Informe del modelo de AutoML.
Aplicación de un modelo de clasificación
Para aplicar un modelo de Machine Learning de clasificación, debe especificar la tabla con los datos de entrada y el prefijo del nombre de la columna de salida.
Cuando se aplica un modelo de clasificación, agrega cinco columnas de salida a la tabla de salida enriquecida: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities y ExplanationIndex. El prefijo se especifica en los nombres de columna de la tabla al aplicar el modelo.
La columna ClassProbabilities contiene la lista de puntuaciones de probabilidad de la fila de cada clase posible.
ClassificationScore es el porcentaje de probabilidad, que identifica la probabilidad de que una fila alcance los criterios de una clase determinada.
La columna ClassificationResult contiene la clase de predicción más probable para la fila.
La columna ClassificationExplanation contiene una explicación con la influencia específica que tuvieron las características de entrada en ClassificationScore.
Modelos de regresión
Los modelos de regresión se usan para predecir un valor numérico y se pueden utilizar en escenarios para determinar lo siguiente:
- Los ingresos probables que se pueden obtener a partir de una venta.
- El valor de duración de una cuenta.
- El importe de una factura por cobrar que es probable que se pague.
- La fecha en la que se puede pagar una factura, etc.
La salida de un modelo de regresión es el valor de predicción.
Entrenamiento de un modelo de regresión
La tabla de entrada que contiene los datos de entrenamiento de un modelo de regresión debe tener una columna numérica como columna de resultados para identificar los valores de resultados conocidos.
Requisitos previos:
- En un modelo de regresión se necesitan 100 filas como mínimo de datos históricos.
El proceso de creación de un modelo de regresión sigue los mismos pasos que otros modelos de AutoML, descritos en la sección anterior Configuración de las entradas del modelo de Machine Learning.
Informe del modelo de regresión
Al igual que los demás informes del modelo de AutoML, el informe de regresión se basa en los resultados de aplicar el modelo a los datos de prueba de exclusión.
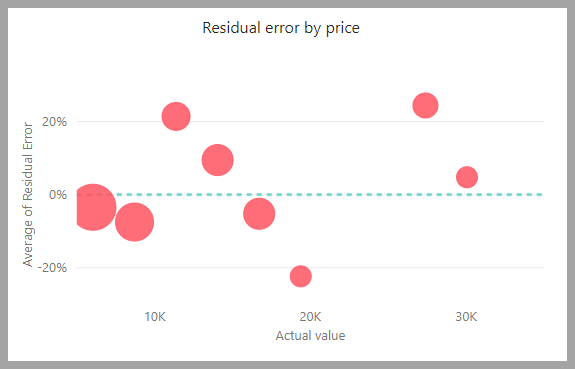
El informe del modelo incluye un gráfico que compara los valores de predicción con los valores reales. En este gráfico, la distancia desde la diagonal indica el error en la predicción.
El gráfico de errores residuales muestra la distribución del porcentaje de error medio para distintos valores en el modelo semántico de prueba de espera. El eje horizontal representa la media del valor real del grupo. El tamaño de la burbuja muestra la frecuencia o el recuento de valores en ese intervalo. El eje vertical es el error residual medio.
En el informe del modelo de regresión también se incluye una página de detalles de entrenamiento como los informes de otros tipos de modelos, como se describe en la sección anterior, Informe del modelo de AutoML.
Aplicación de un modelo de regresión
Para aplicar un modelo de aprendizaje automático de regresión, debe especificar la tabla con los datos de entrada y el prefijo del nombre de la columna de salida.
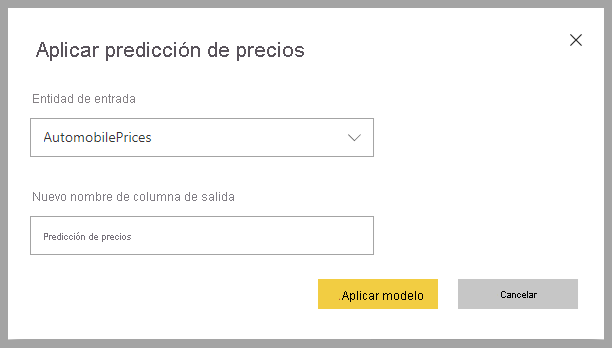
Cuando se aplica un modelo de regresión, se agregan tres columnas de salida a la tabla de salida enriquecida: RegressionResult, RegressionExplanation y ExplanationIndex. El prefijo se especifica en los nombres de columna de la tabla al aplicar el modelo.
La columna RegressionResult contiene el valor de predicción de la fila en función de las columnas de entrada. La columna RegressionExplanation contiene una explicación con la influencia específica que tuvieron las características de entrada en RegressionResult.
Integración de Azure Machine Learning en Power BI
Muchas organizaciones usan modelos de Machine Learning para obtener mejores conclusiones y predicciones sobre sus negocios. Puede usar el aprendizaje automático con los informes, paneles y otros análisis para obtener estas conclusiones. La capacidad de visualizar e invocar conclusiones a partir de estos modelos puede ayudar a divulgar estas conclusiones a los usuarios profesionales que más lo necesiten. Ahora Power BI facilita la incorporación de las conclusiones de modelos hospedados en Azure Machine Learning, mediante movimientos sencillos de apuntar y hacer clic.
Para usar esta funcionalidad, un científico de datos puede conceder acceso al modelo de Azure Machine Learning al analista de BI simplemente desde Azure Portal. Después, al inicio de cada sesión, Power Query detecta todos los modelos de Azure Machine Learning a los que tiene acceso el usuario y los expone como funciones de Power Query dinámicas. Después, el usuario puede invocar esas funciones obteniendo acceso a ellas desde la cinta de opciones del Editor de Power Query o invocando la función M directamente. Power BI también procesa por lotes las solicitudes de acceso de forma automática al invocar el modelo de Azure Machine Learning para que un conjunto de filas logre un mejor rendimiento.
Actualmente, esta funcionalidad solo es compatible con los flujos de datos de Power BI y con Power Query Online en el servicio Power BI.
Para obtener más información sobre los flujos de datos, consulte Introducción a los flujos de datos y preparación de datos de autoservicio.
Para más información sobre Azure Machine Learning, vea lo siguiente:
- Información general: ¿Qué es Azure Machine Learning?
- Guías de inicio rápido y tutoriales de Azure Machine Learning: Documentación de Azure Machine Learning
Concesión de acceso al modelo de Azure Machine Learning a un usuario de Power BI
Para acceder a un modelo de Azure Machine Learning desde Power BI, el usuario debe tener acceso de lectura a la suscripción de Azure y al área de trabajo de Machine Learning.
En los pasos de este artículo se describe cómo conceder acceso a un usuario de Power BI a un modelo hospedado en el servicio Azure Machine Learning de modo que pueda acceder a este modelo como función de Power Query. Para más información, consulte Asignación de roles de Azure mediante Azure Portal.
Inicie sesión en Azure Portal.
Vaya a la página Suscripciones. Encontrará la página Suscripciones mediante la lista Todos los servicios del menú del panel de navegación de Azure Portal.

Seleccione su suscripción.
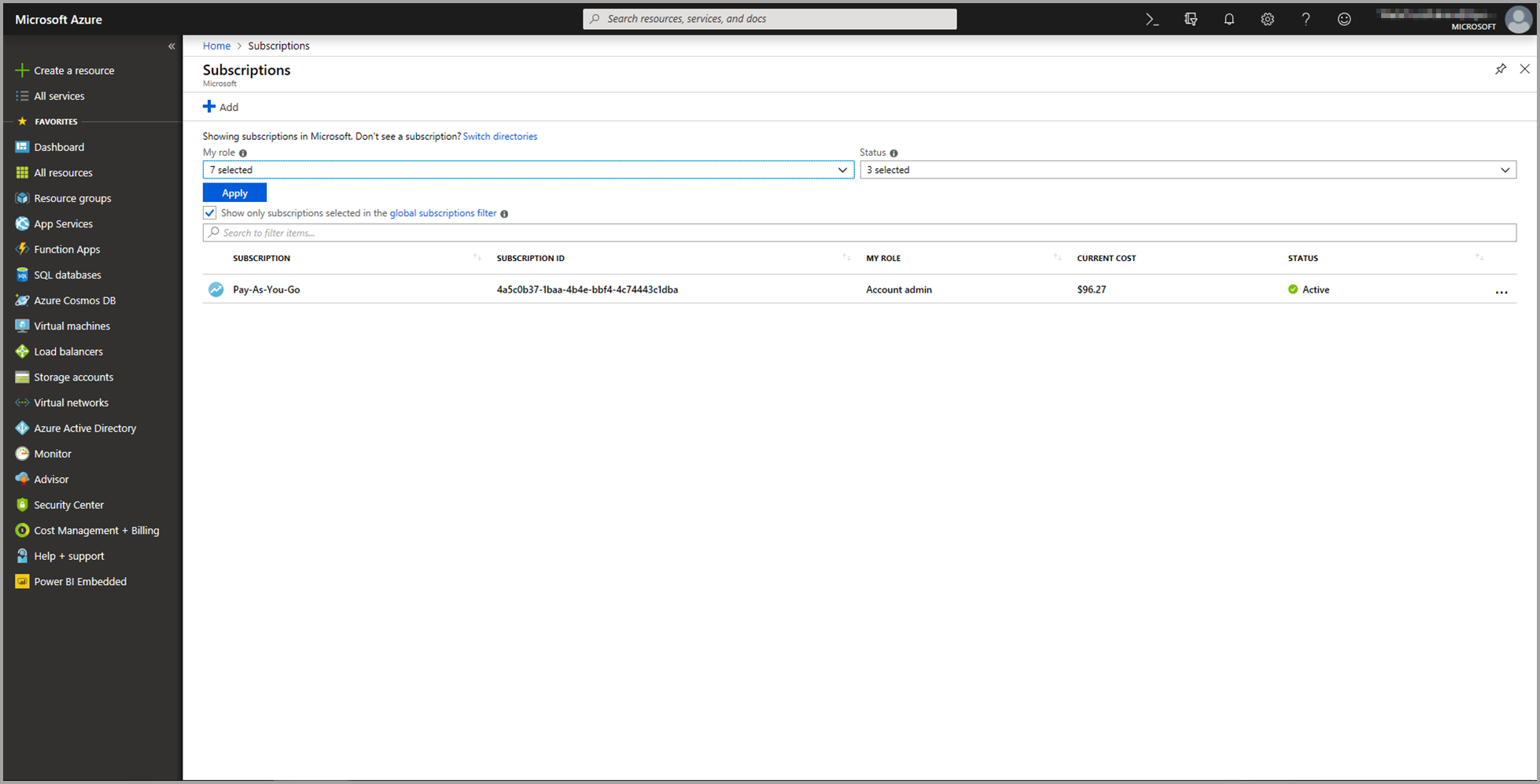
Seleccione Control de acceso (IAM) y, después, elija el botón Agregar.

Seleccione Lector como rol. Después, seleccione el usuario de Power BI a quien quiera conceder acceso al modelo de Azure Machine Learning.

Seleccione Guardar.
Repita los pasos del 3 al 6 para conceder acceso de Lector al usuario para el área de trabajo de Machine Learning específica en la que se hospeda el modelo.




Detección de esquemas para modelos de Machine Learning
Los científicos de datos usan principalmente Python para desarrollar e incluso implementar sus modelos de Machine Learning para el aprendizaje automático. El científico de datos debe generar explícitamente el archivo de esquema mediante Python.
Este archivo de esquema se debe incluir en el servicio web implementado para los modelos de Machine Learning. Para generar de forma automática el esquema para el servicio web, debe proporcionar un ejemplo de la entrada y salida en el script de entrada para el modelo implementado. Para más información, vea Implementación y puntuación de un modelo de Machine Learning mediante un punto de conexión en línea. El vínculo incluye el script de entrada de ejemplo con las instrucciones para la generación de esquemas.
En concreto, las funciones @input_schema y @output_schema del script de entrada hacen referencia a los formatos de ejemplo de entrada y salida de las variables input_sample y output_sample. Las funciones usan estos ejemplos para generar una especificación de OpenAPI (Swagger) para el servicio web durante la implementación.
Estas instrucciones para la generación de esquemas mediante la actualización del script de entrada también se deben aplicar a los modelos creados mediante experimentos de aprendizaje automático automatizado con el SDK de Azure Machine Learning.
Nota
Actualmente, en los modelos creados con la interfaz visual de Azure Machine Learning no se admite la generación de esquemas, pero se admitirá en versiones posteriores.
Invocación del modelo de Azure Machine Learning en Power BI
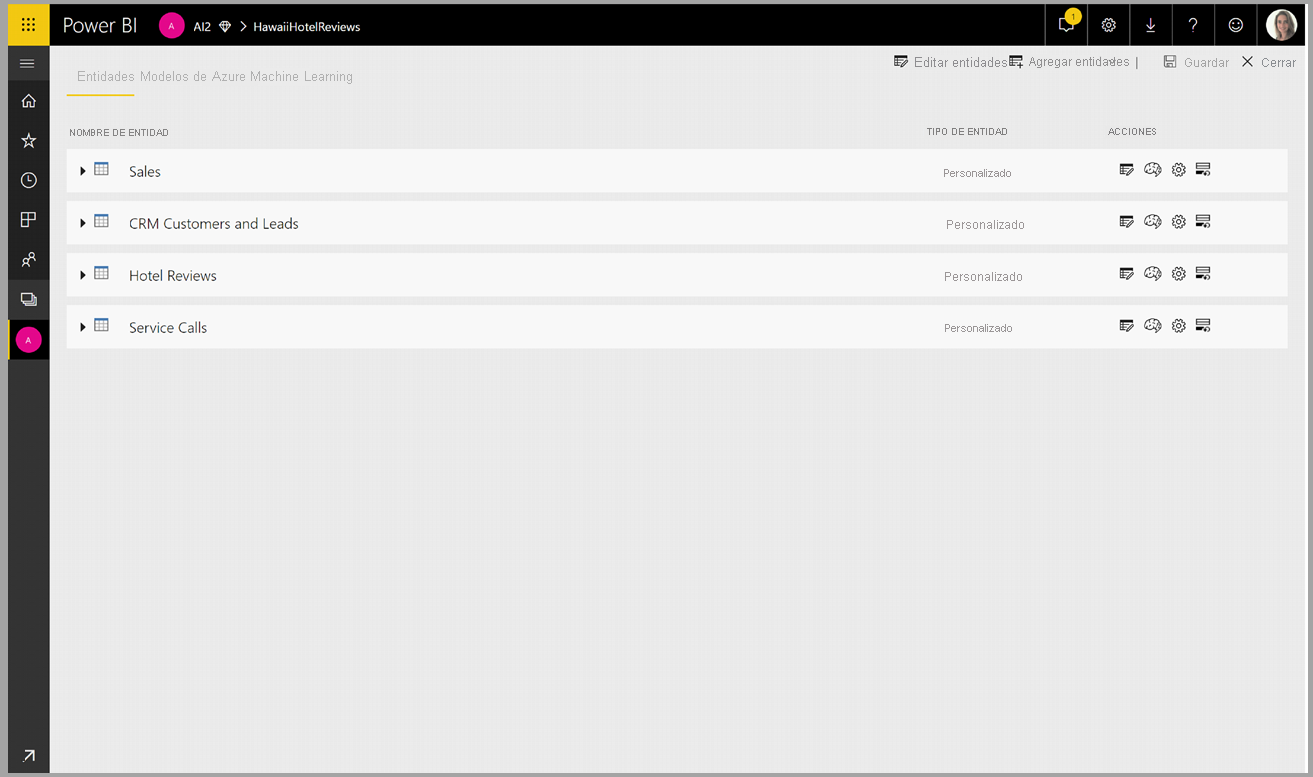
Puede invocar cualquier modelo de Azure Machine Learning al que se le haya concedido acceso, directamente desde el Editor de Power Query del flujo de datos. Para acceder a los modelos de Azure Machine Learning, seleccione el botón Editar tabla de la tabla que quiera enriquecer con conclusiones del modelo de Azure Machine Learning, como se muestra en la siguiente imagen.

Al seleccionar el botón Editar tabla se abre el Editor de Power Query para las tablas del flujo de datos.

Seleccione el botón Conclusiones de AI de la cinta de opciones y, a continuación, seleccione la carpeta Modelos de Azure Machine Learning en el menú del panel de navegación. Todos los modelos de Azure Machine Learning a los que tiene acceso se enumeran aquí como funciones de Power Query. Además, los parámetros de entrada para el modelo de Azure Machine Learning se asignan automáticamente como parámetros de la función de Power Query correspondiente.
Para invocar un modelo de Azure Machine Learning, puede especificar cualquiera de las columnas de la tabla seleccionadas como entrada del menú desplegable. También puede especificar un valor constante que se va a usar como entrada cambiando el icono de la columna a la izquierda del cuadro de diálogo de entrada.

Seleccione Invocar para ver la versión preliminar del resultado del modelo de Azure Machine Learning como nueva columna en la tabla. La invocación del modelo se muestra como un paso aplicado para la consulta.

Si el modelo devuelve varios parámetros de salida, se agrupan como una fila en la columna de salida. Puede expandir la columna para producir parámetros de salida individuales en columnas independientes.

Después de guardar el flujo de datos, el modelo se invocará automáticamente al actualizarse el flujo de datos, para cualquier fila nueva o actualizada de la tabla.
Consideraciones y limitaciones
- Los flujos de datos Gen2 no se integran actualmente con el aprendizaje automático automatizado.
- Las conclusiones de IA (Cognitive Services y los modelos de Azure Machine Learning) no se admiten en máquinas con la configuración de autenticación de proxy.
- Los modelos de Azure Machine Learning no se admiten para los usuarios invitados.
- Hay algunos problemas conocidos con el uso de la puerta de enlace con AutoML y Cognitive Services. Si necesita usar una puerta de enlace, se recomienda crear un flujo de datos que importe primero los datos necesarios a través de la puerta de enlace. A continuación, cree otro flujo de datos que haga referencia al primer flujo de datos para crear o aplicar estos modelos y funciones de IA.
- Si se produce un error en el trabajo de inteligencia artificial con flujos de datos, es posible que tenga que habilitar Combinación rápida al usar IA con flujos de datos. Una vez que haya importado la tabla y antes de empezar a agregar características de IA, seleccione Opciones en la cinta Inicio y, en la ventana que aparece, active la casilla situada junto a Permitir la combinación de datos de varios orígenes para habilitar la característica y, a continuación, seleccione Aceptar para guardar la selección. A continuación, puede agregar características de inteligencia artificial al flujo de datos.
Contenido relacionado
En este artículo se proporciona información general de Automated Machine Learning para flujos de datos en el servicio Power BI. Los siguientes artículos también pueden resultarle útiles.
- Tutorial: Creación de un modelo de Machine Learning en Power BI
- Tutorial: Uso de Cognitive Services en Power BI
En los artículos siguientes encontrará más información sobre los flujos de datos y Power BI:
- Introducción a los flujos de datos y la preparación de datos de autoservicio
- Creación de un flujo de datos
- Configurar y consumir un flujo de datos
- Configuración del almacenamiento de flujo de datos para usar Azure Data Lake Gen 2
- Características prémium de flujos de datos
- Consideraciones y limitaciones de flujos de datos
- Procedimientos recomendados para flujos de datos