Desktop virtuale Azure è un servizio di virtualizzazione di desktop e app completo in esecuzione in Microsoft Azure. Desktop virtuale consente di abilitare un'esperienza desktop remoto sicura che consente alle organizzazioni di rafforzare la resilienza aziendale. Offre una gestione semplificata, Windows 10 e 11 Enterprise multisessione e ottimizzazioni per Microsoft 365 Apps for enterprise. Con Desktop virtuale è possibile distribuire e ridimensionare i desktop e le app di Windows in Azure in pochi minuti, offrendo funzionalità integrate di sicurezza e conformità per proteggere le app e i dati.
Quando si continua ad abilitare il lavoro remoto per l'organizzazione con Desktop virtuale, è importante comprendere le funzionalità di ripristino di emergenza e le procedure consigliate. Queste procedure rafforzano l'affidabilità in tutte le aree per garantire la sicurezza dei dati e la produttività dei dipendenti. Questo articolo fornisce considerazioni sui prerequisiti di continuità aziendale e ripristino di emergenza (BCDR), i passaggi di distribuzione e le procedure consigliate. Vengono fornite informazioni su opzioni, strategie e indicazioni sull'architettura. Il contenuto di questo documento consente di preparare un piano BCDR riuscito e di offrire maggiore resilienza all'azienda durante eventi di tempo di inattività pianificati e non pianificati.
Esistono diversi tipi di emergenze e interruzioni e ognuno può avere un impatto diverso. La resilienza e il ripristino vengono illustrati in modo approfondito per gli eventi locali e a livello di area, incluso il ripristino del servizio in un'area di Azure remota diversa. Questo tipo di ripristino è denominato ripristino di emergenza geografico. È fondamentale creare l'architettura di Desktop virtuale per la resilienza e la disponibilità. È consigliabile fornire la massima resilienza locale per ridurre l'impatto degli eventi di errore. Questa resilienza riduce anche i requisiti per eseguire le procedure di ripristino. Questo articolo fornisce anche informazioni sulla disponibilità elevata e sulle procedure consigliate.
Obiettivi e ambito
Gli obiettivi di questa guida sono:
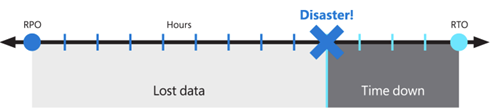
- Garantire la massima disponibilità, resilienza e funzionalità di ripristino di emergenza geografico riducendo al minimo la perdita di dati per dati utente selezionati importanti.
- Ridurre al minimo il tempo di ripristino.
Questi obiettivi sono noti anche come obiettivo del punto di ripristino (RPO) e obiettivo del tempo di ripristino (RTO).
La soluzione proposta offre disponibilità elevata locale, protezione da un singolo errore della zona di disponibilità e protezione da un errore dell'intera area di Azure. Si basa su una distribuzione ridondante in un'area di Azure diversa o secondaria per ripristinare il servizio. Anche se è ancora buona norma, Desktop virtuale e la tecnologia usata per compilare bcdr non richiedono l'associazione di aree di Azure. Le posizioni primarie e secondarie possono essere qualsiasi combinazione di aree di Azure, se la latenza di rete lo consente. I pool di host AVD operativi in più aree geografiche possono offrire maggiori vantaggi non limitati al BCDR.
Per ridurre l'impatto di un singolo errore della zona di disponibilità, usare la resilienza per migliorare la disponibilità elevata:
- A livello di calcolo, distribuire gli host di sessione di Desktop virtuale in diverse zone di disponibilità.
- A livello di archiviazione, usare la resilienza della zona quando possibile.
- A livello di rete, distribuire gateway VPN (Virtual Private Network) e Azure ExpressRoute resilienti alla zona.
- Per ogni dipendenza, esaminare l'impatto di una singola interruzione della zona e pianificare le mitigazioni. Ad esempio, distribuire Dominio di Active Directory Controller e altre risorse esterne a cui gli utenti di Desktop virtuale accedono in più zone di disponibilità.
A seconda del numero di zone di disponibilità usate, valutare il provisioning eccessivo del numero di host sessione per compensare la perdita di una zona. Ad esempio, anche con zone (n-1) disponibili, è possibile garantire l'esperienza utente e le prestazioni.
Nota
Le zone di disponibilità di Azure sono una funzionalità a disponibilità elevata che può migliorare la resilienza. Tuttavia, non considerarle una soluzione di ripristino di emergenza in grado di proteggersi da emergenze a livello di area.

A causa delle possibili combinazioni di tipi, opzioni di replica, funzionalità del servizio e restrizioni di disponibilità in alcune aree, è consigliabile usare il componente Cache cloud di FSLogix anziché i meccanismi di replica specifici dell'archiviazione.
OneDrive non è trattato in questo articolo. Per altre informazioni sulla ridondanza e sulla disponibilità elevata, vedere Resilienza dei dati di SharePoint e OneDrive in Microsoft 365.
Per il resto di questo articolo, verranno fornite informazioni sulle soluzioni per i due diversi tipi di pool di host di Desktop virtuale. Sono inoltre disponibili osservazioni per poter confrontare questa architettura con altre soluzioni:
- Personale: in questo tipo di pool di host, un utente ha un host di sessione assegnato in modo permanente, che non deve mai cambiare. Poiché è personale, questa macchina virtuale può archiviare i dati utente. Il presupposto consiste nell'usare tecniche di replica e backup per mantenere e proteggere lo stato.
- In pool: agli utenti viene assegnata temporaneamente una delle macchine virtuali host di sessione disponibili dal pool, direttamente tramite un gruppo di applicazioni desktop o tramite app remote. Le macchine virtuali sono dati e profili utente senza stato vengono archiviati nell'archiviazione esterna o in OneDrive.
Vengono discusse implicazioni sui costi, ma l'obiettivo principale consiste nel fornire una distribuzione efficace del ripristino di emergenza geografico con una perdita minima di dati. Per altri dettagli sul ripristino di emergenza, vedere le risorse seguenti:
- Considerazioni sul ripristino di emergenza per Desktop virtuale
- Ripristino di emergenza di Desktop virtuale
Prerequisiti
Distribuire l'infrastruttura di base e assicurarsi che sia disponibile nell'area primaria e secondaria di Azure. Per indicazioni sulla topologia di rete, è possibile usare i modelli di topologia e connettività di rete di Azure Cloud Adoption Framework:
In entrambi i modelli distribuire il pool di host desktop virtuale primario e l'ambiente di ripristino di emergenza secondario all'interno di reti virtuali spoke diverse e connetterli a ogni hub nella stessa area. Posizionare un hub nella posizione primaria, un hub nella posizione secondaria e quindi stabilire la connettività tra i due.
L'hub fornisce infine la connettività ibrida alle risorse locali, ai servizi firewall, alle risorse di identità come Dominio di Active Directory controller e alle risorse di gestione come Log Analytics.
È consigliabile prendere in considerazione le applicazioni line-of-business e la disponibilità delle risorse dipendenti quando è stato eseguito il failover nella posizione secondaria.
Continuità aziendale e ripristino di emergenza del piano di controllo
Desktop virtuale offre continuità aziendale e ripristino di emergenza per il piano di controllo per mantenere i metadati dei clienti durante le interruzioni. La piattaforma Azure gestisce questi dati ed elabora e gli utenti non devono configurare o eseguire alcuna operazione.

Desktop virtuale è progettato per essere resiliente agli errori dei singoli componenti e per poter eseguire rapidamente il ripristino da errori. Quando si verifica un'interruzione in un'area, i componenti dell'infrastruttura del servizio eseguono il failover nella posizione secondaria e continuano a funzionare normalmente. È comunque possibile accedere ai metadati correlati al servizio e gli utenti possono comunque connettersi agli host disponibili. Le connessioni degli utenti finali rimangono online se l'ambiente tenant o gli host rimangono accessibili. I percorsi dei dati per Desktop virtuale sono diversi dal percorso della distribuzione delle macchine virtuali (VM) dell'host sessione del pool di host. È possibile individuare i metadati di Desktop virtuale in una delle aree supportate e quindi distribuire le macchine virtuali in un percorso diverso. Altri dettagli sono disponibili nell'articolo Architettura e resilienza del servizio Desktop virtuale.
Active-Active e Active-Passive
Se set distinti di utenti hanno requisiti BCDR diversi, Microsoft consiglia di usare più pool di host con configurazioni diverse. Ad esempio, gli utenti con un'applicazione mission critical potrebbero assegnare un pool di host completamente ridondante con funzionalità di ripristino di emergenza geografico. Tuttavia, gli utenti di sviluppo e test possono usare un pool di host separato senza alcun ripristino di emergenza.
Per ogni singolo pool di host di Desktop virtuale, è possibile basare la strategia BCDR su un modello attivo-attivo o attivo-passivo. Questo scenario presuppone che lo stesso set di utenti in una posizione geografica sia gestito da un pool di host specifico.
- Attivo/attivo
Per ogni pool di host nell'area primaria, si distribuisce un secondo pool di host nell'area secondaria.
Questa configurazione offre quasi zero RTO e RPO ha un costo aggiuntivo.
Non è necessario un amministratore intervenire o eseguire il failover. Durante le normali operazioni, il pool di host secondario fornisce all'utente risorse di Desktop virtuale.
Ogni pool di host ha i propri account di archiviazione (almeno uno) per i profili utente permanenti.
È consigliabile valutare la latenza in base alla posizione fisica dell'utente e alla connettività disponibile. Per alcune aree di Azure, ad esempio Europa occidentale ed Europa settentrionale, la differenza può essere trascurabile quando si accede alle aree primarie o secondarie. È possibile convalidare questo scenario usando lo strumento di stima dell'esperienza desktop virtuale Azure.
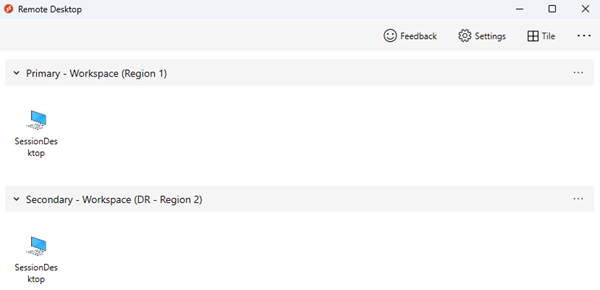
Gli utenti vengono assegnati a gruppi di applicazioni diversi, ad esempio gruppo di applicazioni desktop (DAG) e gruppo di applicazioni RemoteApp (RAG) sia nei pool di host primari che secondari. In questo caso, vengono visualizzate voci duplicate nel feed client di Desktop virtuale. Per evitare confusione, usare aree di lavoro di Desktop virtuale separate con nomi e etichette chiari che riflettono lo scopo di ogni risorsa. Informare gli utenti sull'utilizzo di queste risorse.
Se è necessario spazio di archiviazione per gestire separatamente i contenitori FSLogix Profile e ODFC, usare Cloud Cache per garantire quasi zero RPO.
- Per evitare conflitti di profilo, non consentire agli utenti di accedere contemporaneamente a entrambi i pool di host.
- A causa della natura attiva-attiva di questo scenario, è consigliabile informare gli utenti su come usare queste risorse nel modo appropriato.
Nota
L'uso di contenitori ODFC separati è uno scenario avanzato con maggiore complessità. La distribuzione di questo modo è consigliata solo in alcuni scenari specifici.
- Attivo/passivo
- Come attivo-attivo, per ogni pool di host nell'area primaria si distribuisce un secondo pool di host nell'area secondaria.
- La quantità di risorse di calcolo attive nell'area secondaria viene ridotta rispetto all'area primaria, a seconda del budget disponibile. È possibile usare il ridimensionamento automatico per offrire una maggiore capacità di calcolo, ma richiede più tempo e la capacità di Azure non è garantita.
- Questa configurazione offre un RTO superiore rispetto all'approccio attivo-attivo, ma è meno costoso.
- È necessario l'intervento dell'amministratore per eseguire una procedura di failover in caso di interruzione di Azure. Il pool di host secondario in genere non fornisce all'utente l'accesso alle risorse di Desktop virtuale.
- Ogni pool di host ha i propri account di archiviazione per i profili utente permanenti.
- Gli utenti che usano servizi Desktop virtuale con latenza e prestazioni ottimali sono interessati solo se si verifica un'interruzione di Azure. È consigliabile convalidare questo scenario usando lo strumento di stima dell'esperienza desktop virtuale Azure. Le prestazioni devono essere accettabili, anche se ridotte, per l'ambiente di ripristino di emergenza secondario.
- Gli utenti vengono assegnati a un solo set di gruppi di applicazioni, ad esempio App Desktop e Remote. Durante le normali operazioni, queste app si trovano nel pool di host primario. Durante un'interruzione e dopo un failover, gli utenti vengono assegnati ai gruppi di applicazioni nel pool di host secondario. Nessuna voce duplicata viene visualizzata nel feed client desktop virtuale dell'utente, può usare la stessa area di lavoro e tutto è trasparente per loro.
- Se è necessario spazio di archiviazione per gestire i contenitori profilo FSLogix e Office, usare La cache cloud per garantire quasi zero RPO.
- Per evitare conflitti di profilo, non consentire agli utenti di accedere contemporaneamente a entrambi i pool di host. Poiché questo scenario è attivo-passivo, gli amministratori possono applicare questo comportamento a livello di gruppo di applicazioni. Solo dopo una procedura di failover l'utente è in grado di accedere a ogni gruppo di applicazioni nel pool di host secondario. L'accesso viene revocato nel gruppo di applicazioni del pool di host primario e riassegnato a un gruppo di applicazioni nel pool di host secondario.
- Eseguire un failover per tutti i gruppi di applicazioni. In caso contrario, gli utenti che usano gruppi di applicazioni diversi in pool di host diversi potrebbero causare conflitti di profilo se non sono gestiti in modo efficace.
- È possibile consentire a un sottoinsieme specifico di utenti di eseguire il failover selettivo nel pool di host secondario e fornire un comportamento attivo e una funzionalità di failover di test limitata. È anche possibile eseguire il failover di gruppi di applicazioni specifici, ma è consigliabile informare gli utenti di non usare risorse di pool di host diversi contemporaneamente.
Per circostanze specifiche, è possibile creare un singolo pool di host con una combinazione di host di sessione che si trovano in aree diverse. Il vantaggio di questa soluzione è che se si dispone di un singolo pool di host, non è necessario duplicare definizioni e assegnazioni per le app desktop e remote. Sfortunatamente, il ripristino di emergenza per i pool di host condivisi presenta diversi svantaggi:
- Per i pool di host in pool, non è possibile forzare un utente a un host di sessione nella stessa area.
- Un utente potrebbe riscontrare prestazioni di latenza e prestazioni non ottimali superiori durante la connessione a un host di sessione in un'area remota.
- Se è necessaria l'archiviazione per i profili utente, è necessaria una configurazione complessa per gestire le assegnazioni per gli host di sessione nelle aree primarie e secondarie.
- È possibile usare la modalità di svuotamento per disabilitare temporaneamente l'accesso agli host sessione che si trovano nell'area secondaria. Questo metodo introduce tuttavia maggiore complessità, sovraccarico di gestione e uso inefficiente delle risorse.
- È possibile gestire gli host di sessione in uno stato offline nelle aree secondarie, ma introduce maggiore complessità e sovraccarico di gestione.
Raccomandazioni e considerazioni
Generali
Per distribuire una configurazione attiva-attiva o attiva-passiva usando più pool di host e un meccanismo di cache cloud FSLogix, è possibile creare il pool di host all'interno della stessa area di lavoro o uno diverso, a seconda del modello. Questo approccio richiede di mantenere l'allineamento e gli aggiornamenti, mantenendo sincronizzati entrambi i pool di host e allo stesso livello di configurazione. Oltre a un nuovo pool di host per l'area di ripristino di emergenza secondario, è necessario:
- Per creare nuovi gruppi di applicazioni distinti e applicazioni correlate per il nuovo pool di host.
- Per revocare le assegnazioni utente al pool di host primario e quindi riassegnare manualmente le assegnazioni al nuovo pool di host durante il failover.
Esaminare le opzioni di continuità aziendale e ripristino di emergenza per FSLogix.
- Nessun ripristino del profilo non è trattato in questo documento.
- La cache cloud (attiva/passiva) è inclusa in questo documento, ma viene implementata usando lo stesso pool di host.
- La cache cloud (attiva/attiva) è descritta nella parte rimanente di questo documento.
Esistono limiti per le risorse di Desktop virtuale che devono essere considerate nella progettazione di un'architettura di Desktop virtuale. Convalidare la progettazione in base ai limiti del servizio Desktop virtuale.
Per la diagnostica e il monitoraggio, è consigliabile usare la stessa area di lavoro Log Analytics per il pool di host primario e secondario. Usando questa configurazione, Azure Virtual Desktop Insights offre una visualizzazione unificata della distribuzione in entrambe le aree.
Tuttavia, l'uso di una singola destinazione del log può causare problemi se l'intera area primaria non è disponibile. L'area secondaria non sarà in grado di usare l'area di lavoro Log Analytics nell'area non disponibile. Se questa situazione è inaccettabile, è possibile adottare le seguenti soluzioni:
- Usare un'area di lavoro Log Analytics separata per ogni area e quindi puntare i componenti di Desktop virtuale per accedere all'area di lavoro locale.
- Testare ed esaminare le funzionalità di replica e failover dell'area di lavoro Log Analytics.
Calcolo
Per la distribuzione di entrambi i pool di host nelle aree di ripristino di emergenza primario e secondario, è necessario distribuire la flotta di macchine virtuali host di sessione in più zone di disponibilità. Se le zone di disponibilità non sono disponibili nell'area locale, è possibile usare un set di disponibilità per rendere la soluzione più resiliente rispetto a una distribuzione predefinita.
L'immagine d'oro usata per la distribuzione del pool di host nell'area di ripristino di emergenza secondario deve essere la stessa usata per il database primario. È consigliabile archiviare le immagini nella raccolta di calcolo di Azure e configurare più repliche di immagini sia nelle posizioni primarie che secondarie. Ogni replica di immagini può sostenere una distribuzione parallela di un numero massimo di macchine virtuali e potrebbe essere necessario più di uno in base alle dimensioni del batch di distribuzione desiderate. Per altre informazioni, vedere Archiviare e condividere immagini in una raccolta di calcolo di Azure.

La raccolta di calcolo di Azure non è una risorsa globale. È consigliabile avere almeno una raccolta secondaria nell'area secondaria. Nell'area primaria creare una raccolta, una definizione di immagine della macchina virtuale e una versione dell'immagine della macchina virtuale. Creare quindi gli stessi oggetti anche nell'area secondaria. Quando si crea la versione dell'immagine della macchina virtuale, è possibile copiare la versione dell'immagine della macchina virtuale creata nell'area primaria specificando la raccolta, la definizione dell'immagine della macchina virtuale e la versione dell'immagine della macchina virtuale usata nell'area primaria. Azure copia l'immagine e crea una versione dell'immagine della macchina virtuale locale. È possibile eseguire questa operazione usando il portale di Azure o il comando dell'interfaccia della riga di comando di Azure, come descritto di seguito:
Creare una definizione di immagine e una versione dell'immagine
Non tutte le macchine virtuali host di sessione nelle posizioni di ripristino di emergenza secondarie devono essere attive e in esecuzione tutte le volte. È necessario creare inizialmente un numero sufficiente di macchine virtuali e, successivamente, usare un meccanismo di scalabilità automatica come i piani di ridimensionamento. Con questi meccanismi, è possibile mantenere la maggior parte delle risorse di calcolo in uno stato offline o deallocato per ridurre i costi.
È anche possibile usare l'automazione per creare host di sessione nell'area secondaria solo quando necessario. Questo metodo ottimizza i costi, ma a seconda del meccanismo usato, potrebbe richiedere un RTO più lungo. Questo approccio non consente test di failover senza una nuova distribuzione e non consente il failover selettivo per gruppi specifici di utenti.

Nota
Per aggiornare il token di autenticazione necessario per connettersi al piano di controllo di Desktop virtuale, è necessario accendere ogni 90 giorni ogni volta ogni 90 giorni ogni macchina virtuale host. È anche consigliabile applicare regolarmente patch di sicurezza e aggiornamenti delle applicazioni.
- La presenza di host di sessione in modalità offline o deallocata, lo stato nell'area secondaria non garantisce che la capacità sia disponibile in caso di emergenza a livello di area primaria. Si applica anche se i nuovi host di sessione vengono distribuiti su richiesta quando necessario e con l'utilizzo di Site Recovery . La capacità di calcolo può essere garantita solo se le risorse correlate sono già allocate e attive.
Importante
Le prenotazioni di Azure non forniscono capacità garantita nell'area.
Per gli scenari di utilizzo di Cache cloud, è consigliabile usare il livello Premium per i dischi gestiti.
Storage
In questa guida si usano almeno due account di archiviazione separati per ogni pool di host di Desktop virtuale. Uno è per il contenitore FSLogix Profile e uno per i dati del contenitore di Office. È anche necessario un altro account di archiviazione per i pacchetti MSIX . Si applicano le considerazioni seguenti:
- È possibile usare File di Azure condivisione e Azure NetApp Files come alternative di archiviazione. Per confrontare le opzioni, vedere le opzioni di archiviazione del contenitore FSLogix.
- File di Azure condivisione può fornire resilienza della zona usando l'opzione di resilienza dell'archiviazione con ridondanza della zona, se disponibile nell'area.
- Non è possibile usare la funzionalità di archiviazione con ridondanza geografica nelle situazioni seguenti:
- È necessaria un'area che non dispone di una coppia. Le coppie di aree per l'archiviazione con ridondanza geografica sono fisse e non possono essere modificate.
- Si sta usando il livello Premium.
- RPO e RTO sono più elevati rispetto al meccanismo della cache cloud FSLogix.
- Non è facile testare il failover e il failback in un ambiente di produzione.
- Azure NetApp Files richiede altre considerazioni:
- La ridondanza della zona non è ancora disponibile. Se il requisito di resilienza è più importante delle prestazioni, usare File di Azure condivisione.
- Azure NetApp Files può essere zonale, ovvero i clienti possono decidere in quale zona di disponibilità di Azure (singola) allocare.
- La replica tra zone può essere stabilita a livello di volume per garantire la resilienza della zona, ma la replica avviene asincrona e richiede il failover manuale. Questo processo richiede un obiettivo del punto di ripristino (RPO) e un obiettivo del tempo di ripristino (RTO) maggiore di zero. Prima di usare questa funzionalità, esaminare i requisiti e le considerazioni per la replica tra zone.
- È possibile usare Azure NetApp Files con vpn con ridondanza della zona e gateway ExpressRoute, se si usa la funzionalità di rete standard, che può essere usata per la resilienza di rete. Per altre informazioni, vedere Topologie di rete supportate.
- Azure rete WAN virtuale è supportato quando viene usato insieme alla rete standard di Azure NetApp Files. Per altre informazioni, vedere Topologie di rete supportate.
- Azure NetApp Files ha un meccanismo di replica tra aree. Si applicano le considerazioni seguenti:
- Non è disponibile in tutte le aree.
- La replica tra aree delle coppie di aree dei volumi di Azure NetApp Files può essere diversa da Archiviazione di Azure coppie di aree.
- Non può essere usato contemporaneamente con la replica tra zone
- Il failover non è trasparente e il failback richiede la riconfigurazione dell'archiviazione.
- Limiti
- Esistono limiti nelle dimensioni, nelle operazioni di input/output al secondo (IOPS), MBps di larghezza di banda sia per File di Azure condivisione che per gli account di archiviazione e i volumi di Azure NetApp Files. Se necessario, è possibile usare più di uno per lo stesso pool di host in Desktop virtuale usando le impostazioni per gruppo in FSLogix. Tuttavia, questa configurazione richiede più pianificazione e configurazione.
L'account di archiviazione usato per i pacchetti di applicazioni MSIX deve essere diverso dagli altri account per i contenitori di Profilo e Office. Sono disponibili le opzioni di ripristino di emergenza geografico seguenti:
- Un account di archiviazione con archiviazione con ridondanza geografica abilitata, nell'area primaria
- L'area secondaria è fissa. Questa opzione non è adatta per l'accesso locale in caso di failover dell'account di archiviazione.
- Due account di archiviazione separati, uno nell'area primaria e uno nell'area secondaria (scelta consigliata)
- Usare l'archiviazione con ridondanza della zona per almeno l'area primaria.
- Ogni pool di host in ogni area ha accesso all'archiviazione locale ai pacchetti MSIX con bassa latenza.
- Copiare i pacchetti MSIX due volte in entrambi i percorsi e registrare i pacchetti due volte in entrambi i pool di host. Assegnare utenti ai gruppi di applicazioni due volte.
FSLogix
Microsoft consiglia di usare la configurazione e le funzionalità FSLogix seguenti:
Se il contenuto del contenitore profilo deve avere una gestione BCDR separata e ha requisiti diversi rispetto al contenitore di Office, è necessario suddividerli.
- Il contenitore di Office include solo contenuto memorizzato nella cache che può essere ricompilato o ripopolato dall'origine in caso di emergenza. Con Il contenitore di Office, potrebbe non essere necessario mantenere i backup, riducendo i costi.
- Quando si usano account di archiviazione diversi, è possibile abilitare solo i backup nel contenitore del profilo. In alternativa, è necessario avere impostazioni diverse, ad esempio il periodo di conservazione, l'archiviazione usata, la frequenza e l'obiettivo RTO/RPO.
Cache cloud è un componente FSLogix in cui è possibile specificare più percorsi di archiviazione dei profili e replicare in modo asincrono i dati del profilo, senza basarsi su alcun meccanismo di replica di archiviazione sottostante. Se la prima posizione di archiviazione ha esito negativo o non è raggiungibile, La cache cloud esegue automaticamente il failover per l'uso del database secondario e aggiunge in modo efficace un livello di resilienza. Usare La cache cloud per replicare sia i contenitori profilo che i contenitori di Office tra account di archiviazione diversi nelle aree primarie e secondarie.

È necessario abilitare Cache cloud due volte nel registro delle macchine virtuali dell'host sessione, una volta per il contenitore del profilo e una volta per il contenitore di Office. Non è possibile abilitare La cache cloud per il contenitore di Office, ma non abilitarla potrebbe causare un errore di allineamento dei dati tra l'area primaria e quella secondaria in caso di failover e failback. Testare attentamente questo scenario prima di usarlo nell'ambiente di produzione.
La cache cloud è compatibile con le impostazioni di suddivisione del profilo e per gruppo. per gruppo richiede un'attenta progettazione e pianificazione dei gruppi e dell'appartenenza di Active Directory. È necessario assicurarsi che ogni utente faccia parte esattamente di un gruppo e che tale gruppo venga usato per concedere l'accesso ai pool di host.
Il parametro CCDLocations specificato nel Registro di sistema per il pool di host nell'area di ripristino di emergenza secondario viene ripristinato in ordine, rispetto alle impostazioni nell'area primaria. Per altre informazioni, vedere Esercitazione: Configurare La cache cloud per reindirizzare i contenitori del profilo o il contenitore di office a più provider.
Suggerimento
Questo articolo è incentrato su uno scenario specifico. Altri scenari sono descritti in Opzioni di disponibilità elevata per FSLogix e Opzioni di continuità aziendale e ripristino di emergenza per FSLogix.

L'esempio seguente mostra una configurazione di Cloud Cache e le chiavi del Registro di sistema correlate:
Area primaria = Europa settentrionale
URI dell'account di archiviazione del contenitore del profilo = \northeustg1\profiles
- Percorso della chiave del Registro di > sistema = HKEY_LOCAL_MACHINE profili SOFTWARE > FSLogix >
- CCDLocations value = type=smb,connectionString=\northeustg1\profiles; type=smb,connectionString=\westeustg1\profiles
Nota
Se in precedenza sono stati scaricati i modelli FSLogix, è possibile eseguire le stesse configurazioni tramite La Console gestione Criteri di gruppo di Active Directory. Per altre informazioni su come configurare l'oggetto Criteri di gruppo per FSLogix, vedere la guida Usare file di criteri di gruppo FSLogix.

URI dell'account di archiviazione del contenitore di Office = \northeustg2\odcf
Percorso chiave del Registro di sistema = HKEY_LOCAL_MACHINE SOFTWARE >Policy > FSLogix > > ODFC
CCDLocations value = type=smb,connectionString=\northeustg2\odfc; type=smb,connectionString=\westeustg2\odfc



Nota
Negli screenshot precedenti non vengono segnalate tutte le chiavi del Registro di sistema consigliate per FSLogix e Cloud Cache, per brevità e semplicità. Per altre informazioni, vedere Esempi di configurazione di FSLogix.
Area secondaria = Europa occidentale
- URI dell'account di archiviazione del contenitore del profilo = \westeustg1\profiles
- Percorso della chiave del Registro di > sistema = HKEY_LOCAL_MACHINE profili SOFTWARE > FSLogix >
- CCDLocations value = type=smb,connectionString=\westeustg1\profiles; type=smb,connectionString=\northeustg1\profiles
- URI dell'account di archiviazione del contenitore di Office = \westeustg2\odcf
- Percorso chiave del Registro di sistema = HKEY_LOCAL_MACHINE SOFTWARE >Policy > FSLogix > > ODFC
- CCDLocations value = type=smb,connectionString=\westeustg2\odfc; type=smb,connectionString=\northeustg2\odfc
Replica di Cache cloud
La configurazione della cache cloud e i meccanismi di replica garantiscono la replica dei dati del profilo tra aree diverse con una perdita minima di dati. Poiché lo stesso file di profilo utente può essere aperto in modalità ReadWrite da un solo processo, è consigliabile evitare l'accesso simultaneo, pertanto gli utenti non devono aprire una connessione a entrambi i pool di host contemporaneamente.

Scaricare un file di Visio di questa architettura.
Flusso di dati
Un utente di Desktop virtuale avvia il client Desktop virtuale e quindi apre un'applicazione Desktop o App remota pubblicata assegnata al pool di host dell'area primaria.
FSLogix recupera i contenitori profilo utente e Office e quindi monta il VHD/X di archiviazione sottostante dall'account di archiviazione situato nell'area primaria.
Allo stesso tempo, il componente Cache cloud inizializza la replica tra i file nell'area primaria e i file nell'area secondaria. Per questo processo, Cache cloud nell'area primaria acquisisce un blocco di lettura/scrittura esclusivo su questi file.
Lo stesso utente di Desktop virtuale vuole ora avviare un'altra applicazione pubblicata assegnata nel pool di host dell'area secondaria.
Il componente FSLogix in esecuzione nell'host sessione di Desktop virtuale nell'area secondaria tenta di montare i file VHD/X del profilo utente dall'account di archiviazione locale. Tuttavia, il montaggio non riesce perché questi file sono bloccati dal componente Cache cloud in esecuzione nell'host sessione desktop virtuale nell'area primaria.
Nella configurazione predefinita di FSLogix e Cache cloud, l'utente non può accedere e viene rilevato un errore nei log di diagnostica FSLogix, ERROR_LOCK_VIOLATION 33 (0x21).


Identità
Una delle dipendenze più importanti per Desktop virtuale è la disponibilità dell'identità utente. Per accedere a desktop virtuali remoti completi e app remote dagli host di sessione, gli utenti devono essere in grado di eseguire l'autenticazione. Microsoft Entra ID è il servizio di gestione delle identità cloud centralizzato di Microsoft che consente tale funzionalità. Microsoft Entra ID viene sempre usato per autenticare gli utenti per Desktop virtuale. Gli host di sessione possono essere aggiunti allo stesso tenant di Microsoft Entra o a un dominio di Active Directory tramite Dominio di Active Directory Services (AD DS) o Microsoft Entra Domain Services, offrendo una scelta di opzioni di configurazione flessibili.
Microsoft Entra ID
- Si tratta di un servizio globale multi-area e resiliente con disponibilità elevata. Nessun'altra azione è necessaria in questo contesto come parte di un piano BCDR di Desktop virtuale.
Active Directory Domain Services
- Affinché i servizi di Dominio di Active Directory siano resilienti e a disponibilità elevata, anche in caso di emergenza a livello di area, è consigliabile distribuire almeno due controller di dominio nell'area primaria di Azure. Questi controller di dominio devono trovarsi in zone di disponibilità diverse, se possibile, ed è necessario garantire una replica corretta con l'infrastruttura nell'area secondaria e infine in locale. È consigliabile creare almeno un altro controller di dominio nell'area secondaria con il catalogo globale e i ruoli DNS. Per altre informazioni, vedere Distribuire Dominio di Active Directory Services (AD DS) in una rete virtuale di Azure.
Microsoft Entra Connect
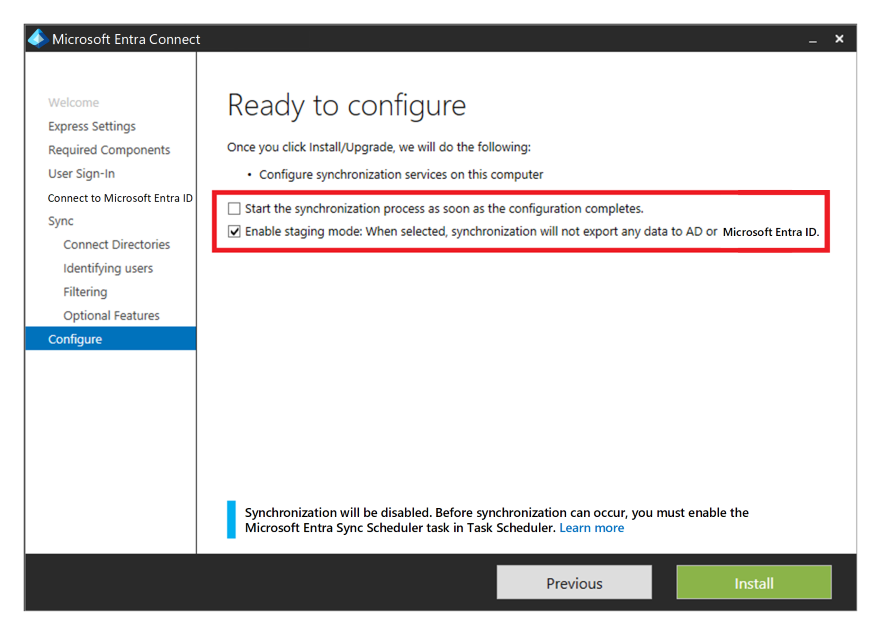
Se si usa Microsoft Entra ID con Dominio di Active Directory Services e quindi Microsoft Entra Connect per sincronizzare i dati di identità utente tra Dominio di Active Directory Services e Microsoft Entra ID, è consigliabile prendere in considerazione la resilienza e il ripristino di questo servizio per la protezione da un'emergenza permanente.
È possibile fornire disponibilità elevata e ripristino di emergenza installando una seconda istanza del servizio nell'area secondaria e abilitando la modalità di gestione temporanea.
Se è presente un ripristino, l'amministratore deve alzare di livello l'istanza secondaria eliminando la modalità di gestione temporanea. Devono seguire la stessa procedura di inserimento di un server in modalità di gestione temporanea. Per eseguire questa configurazione sono necessarie le credenziali di amministratore globale di Microsoft Entra.
Microsoft Entra Domain Services
- È possibile usare Microsoft Entra Domain Services in alcuni scenari come alternativa ai servizi di Dominio di Active Directory.
- Offre disponibilità elevata.
- Se il ripristino di emergenza geografico rientra nell'ambito dello scenario, è consigliabile distribuire un'altra replica nell'area secondaria di Azure usando un set di repliche. È anche possibile usare questa funzionalità per aumentare la disponibilità elevata nell'area primaria.
Diagrammi dell'architettura
Pool di host personali

Scaricare un file di Visio di questa architettura.
Pool di host in pool

Scaricare un file di Visio di questa architettura.
Failover e failback
Scenario del pool di host personali
Nota
In questa sezione viene trattato solo il modello attivo-passivo. Un attivo-attivo non richiede alcun intervento di failover o di amministratore.
Il failover e il failback per un pool di host personali sono diversi, perché non esiste alcuna cache cloud e spazio di archiviazione esterno usato per i contenitori di Profilo e Office. È comunque possibile usare la tecnologia FSLogix per salvare i dati in un contenitore dall'host di sessione. Non esiste alcun pool di host secondario nell'area di ripristino di emergenza, quindi non è necessario creare più aree di lavoro e risorse di Desktop virtuale per replicare e allineare. È possibile usare Site Recovery per replicare le macchine virtuali host sessione.
È possibile usare Site Recovery in diversi scenari. Per Desktop virtuale usare l'architettura di ripristino di emergenza da Azure ad Azure in Azure Site Recovery.
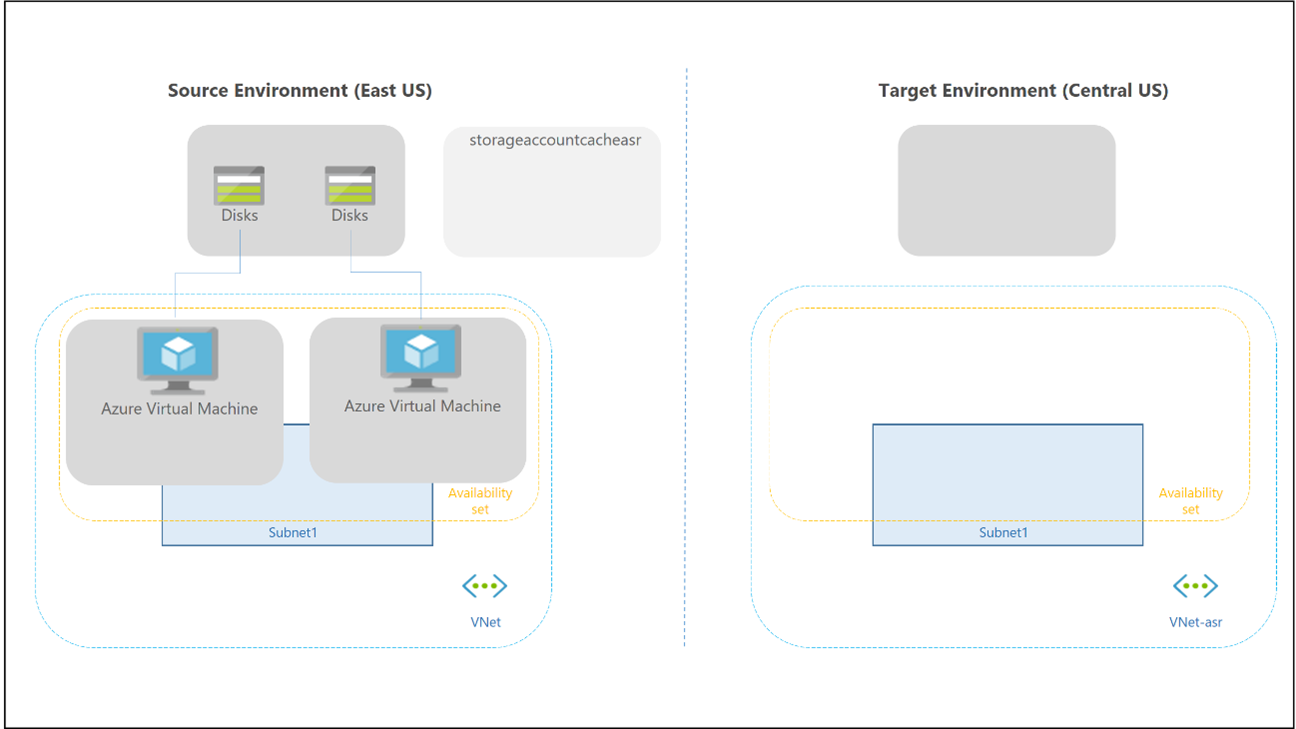
Si applicano le considerazioni e le raccomandazioni seguenti:
- Il failover di Site Recovery non è automatico. Un amministratore deve attivarlo usando il portale di Azure o PowerShell/API.
- È possibile creare script e automatizzare l'intera configurazione e le operazioni di Site Recovery usando PowerShell.
- Site Recovery ha un RTO dichiarato all'interno del contratto di servizio. La maggior parte del tempo, Site Recovery può eseguire il failover delle macchine virtuali entro pochi minuti.
- È possibile usare Site Recovery con Backup di Azure. Per altre informazioni, vedere Supporto per l'uso di Site Recovery con Backup di Azure.
- È necessario abilitare Site Recovery a livello di macchina virtuale, perché non esiste alcuna integrazione diretta nell'esperienza del portale di Desktop virtuale. È anche necessario attivare il failover e il failback a livello di singola macchina virtuale.
- Site Recovery offre funzionalità di failover di test in una subnet separata per le macchine virtuali di Azure generali. Non usare questa funzionalità per le macchine virtuali di Desktop virtuale, perché si dispone di due host di sessione di Desktop virtuale identici che chiamano contemporaneamente il piano di controllo del servizio.
- Site Recovery non gestisce le estensioni della macchina virtuale durante la replica. Se si abilitano estensioni personalizzate per le macchine virtuali host sessione di Desktop virtuale, è necessario riabilitare le estensioni dopo il failover o il failback. Le estensioni predefinite di Desktop virtuale joindomain e Microsoft.PowerShell.DSC vengono usate solo quando viene creata una macchina virtuale host di sessione. È sicuro perderli dopo un primo failover.
- Assicurarsi di consultare Matrice di supporto per il ripristino di emergenza delle macchine virtuali di Azure tra aree di Azure e verificare i requisiti, le limitazioni e la matrice di compatibilità per lo scenario di ripristino di emergenza da Azure ad Azure di Site Recovery, in particolare le versioni del sistema operativo supportate.
- Quando si esegue il failover di una macchina virtuale da un'area a un'altra, la macchina virtuale viene avviata nell'area di ripristino di emergenza di destinazione in uno stato non protetto. Il failback è possibile, ma l'utente deve riproteggere le macchine virtuali nell'area secondaria e quindi abilitare di nuovo la replica nell'area primaria.
- Eseguire test periodici delle procedure di failover e failback. Documentare quindi un elenco esatto di passaggi e azioni di ripristino in base all'ambiente desktop virtuale specifico.
Scenario del pool di host in pool
Una delle caratteristiche desiderate di un modello di ripristino di emergenza attivo-attivo è che l'intervento dell'amministratore non è necessario per ripristinare il servizio in caso di interruzione. Le procedure di failover devono essere necessarie solo in un'architettura attiva-passiva.
In un modello attivo-passivo, l'area di ripristino di emergenza secondaria deve essere inattiva, con risorse minime configurate e attive. La configurazione deve essere mantenuta allineata all'area primaria. Se è presente un failover, le riassegnazioni per tutti gli utenti a tutti i gruppi di applicazioni e desktop per le app remote nel pool di host di ripristino di emergenza secondario vengono eseguite contemporaneamente.
È possibile avere un modello attivo-attivo e un failover parziale. Se il pool di host viene usato solo per fornire gruppi di applicazioni e desktop, è possibile partizionare gli utenti in più gruppi di Active Directory non sovrapposti e riassegnare il gruppo ai gruppi di applicazioni e desktop nei pool di host di ripristino di emergenza primario o secondario. Un utente non deve avere accesso a entrambi i pool di host contemporaneamente. Se sono presenti più gruppi di applicazioni e applicazioni, i gruppi di utenti usati per assegnare gli utenti potrebbero sovrapporsi. In questo caso, è difficile implementare una strategia attiva-attiva. Ogni volta che un utente avvia un'app remota nel pool di host primario, il profilo utente viene caricato da FSLogix in una macchina virtuale host di sessione. Il tentativo di eseguire la stessa operazione nel pool di host secondario potrebbe causare un conflitto sul disco del profilo sottostante.
Avviso
Per impostazione predefinita, le impostazioni del Registro di sistema FSLogix impediscono l'accesso simultaneo allo stesso profilo utente da più sessioni. In questo scenario BCDR non è consigliabile modificare questo comportamento e lasciare il valore 0 per ProfileType chiave del Registro di sistema.
Ecco la situazione iniziale e i presupposti di configurazione:
- I pool di host nell'area primaria e nelle aree di ripristino di emergenza secondario vengono allineati durante la configurazione, inclusa la cache cloud.
- Nei pool di host, sia i gruppi di applicazioni remote DAG1 che APPG2 e APPG3 vengono offerti agli utenti.
- Nel pool di host nell'area primaria, i gruppi di utenti di Active Directory GRP1, GRP2 e GRP3 vengono usati per assegnare gli utenti a DAG1, APPG2 e APPG3. Questi gruppi potrebbero avere appartenenze utente sovrapposte, ma poiché in questo caso il modello usa active-passive con failover completo, non è un problema.
I passaggi seguenti descrivono quando si verifica un failover, dopo un ripristino di emergenza pianificato o non pianificato.
- Nel pool di host primario rimuovere le assegnazioni utente dai gruppi GRP1, GRP2 e GRP3 per i gruppi di applicazioni DAG1, APPG2 e APPG3.
- Esiste una disconnessione forzata per tutti gli utenti connessi dal pool di host primario.
- Nel pool di host secondario, in cui sono configurati gli stessi gruppi di applicazioni, è necessario concedere l'accesso utente a DAG1, APPG2 e APPG3 usando i gruppi GRP1, GRP2 e GRP3.
- Esaminare e modificare la capacità del pool di host nell'area secondaria. In questo caso, è possibile basarsi su un piano di scalabilità automatica per attivare automaticamente gli host di sessione. È anche possibile avviare manualmente le risorse necessarie.
I passaggi di failback e il flusso sono simili ed è possibile eseguire l'intero processo più volte. Cache cloud e configurazione degli account di archiviazione garantisce che i dati del profilo e del contenitore di Office vengano replicati. Prima del failback, assicurarsi che la configurazione del pool di host e le risorse di calcolo vengano ripristinate. Per la parte di archiviazione, se si verifica una perdita di dati nell'area primaria, Cache cloud replica i dati del profilo e del contenitore di Office dall'archiviazione dell'area secondaria.
È anche possibile implementare un piano di failover di test con alcune modifiche alla configurazione, senza influire sull'ambiente di produzione.
- Creare alcuni nuovi account utente in Active Directory per la produzione.
- Creare un nuovo gruppo di Active Directory denominato GRP-TEST e assegnare gli utenti.
- Assegnare l'accesso a DAG1, APPG2 e APPG3 usando il gruppo GRP-TEST.
- Fornire istruzioni agli utenti nel gruppo GRP-TEST per testare le applicazioni.
- Testare la procedura di failover usando il gruppo GRP-TEST per rimuovere l'accesso dal pool di host primario e concedere l'accesso al pool di ripristino di emergenza secondario.
Raccomandazioni importanti:
- Automatizzare il processo di failover usando PowerShell, l'interfaccia della riga di comando di Azure o un'altra API o un altro strumento disponibile.
- Testare periodicamente l'intera procedura di failover e failback.
- Eseguire un controllo regolare dell'allineamento della configurazione per assicurarsi che i pool di host nell'area di emergenza primaria e secondaria siano sincronizzati.
Backup
Un presupposto in questa guida è che esiste la separazione dei profili e la separazione dei dati tra i contenitori profilo e i contenitori di Office. FSLogix consente questa configurazione e l'utilizzo di account di archiviazione separati. Una volta in account di archiviazione separati, è possibile usare criteri di backup diversi.
Per il contenitore ODFC, se il contenuto rappresenta solo i dati memorizzati nella cache che possono essere ricompilati dall'archivio dati online come Microsoft 365, non è necessario eseguire il backup dei dati.
Se è necessario eseguire il backup dei dati dei contenitori di Office, è possibile usare una risorsa di archiviazione meno costosa o un periodo di conservazione e una frequenza di backup diversi.
Per un tipo di pool di host personale, è necessario eseguire il backup a livello di macchina virtuale host sessione. Questo metodo si applica solo se i dati vengono archiviati in locale.
Se si usa OneDrive e il reindirizzamento di cartelle note, il requisito di salvare i dati all'interno del contenitore potrebbe scomparire.
Nota
Il backup di OneDrive non è considerato in questo articolo e in questo scenario.
A meno che non esista un altro requisito, il backup per l'archiviazione nell'area primaria deve essere sufficiente. Il backup dell'ambiente di ripristino di emergenza non viene usato normalmente.
Per File di Azure condivisione, usare Backup di Azure.
- Per il tipo di resilienza dell'insieme di credenziali, usare l'archiviazione con ridondanza della zona se non è necessaria l'archiviazione di backup fuori sede o dell'area. Se questi backup sono necessari, usare l'archiviazione con ridondanza geografica.
Azure NetApp Files offre una propria soluzione di backup predefinita.
- Assicurarsi di controllare la disponibilità delle funzionalità dell'area, insieme ai requisiti e alle limitazioni.
Gli account di archiviazione separati usati per MSIX devono essere coperti anche da un backup se i repository dei pacchetti dell'applicazione non possono essere facilmente ricompilati.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Ben Martin Baur | Cloud Solution Architect
- Igor Pagliai | Ingegnere principale di FastTrack per Azure (FTA)
Altri contributori:
- Nelson Del Villar | Cloud Solution Architect, Infrastruttura di base di Azure
- Jason Martinez | Writer tecnico
Passaggi successivi
- Piano di ripristino di emergenza di Desktop virtuale
- BCDR per Desktop virtuale - Cloud Adoption Framework
- Cache cloud per creare resilienza e disponibilità