Azure HDInsight での Apache Spark クラスターのリソースの管理
Apache Spark クラスターに関連付けられた Apache Ambari UI、Apache Hadoop YARN UI、Spark History Server などのインターフェイスにアクセスする方法、および最適なパフォーマンスが得られるようにクラスター構成を調整する方法について説明します。
Spark History Server を開く
Spark History Server は、完了および実行中の Spark アプリケーションの Web UI です。 Spark の Web UI の拡張機能です。 詳細については、Spark History Server に関する記事を参照してください。
Yarn UI を開く
Spark クラスターで現在実行されているアプリケーションを監視するには、YARN UI を使用することができます。
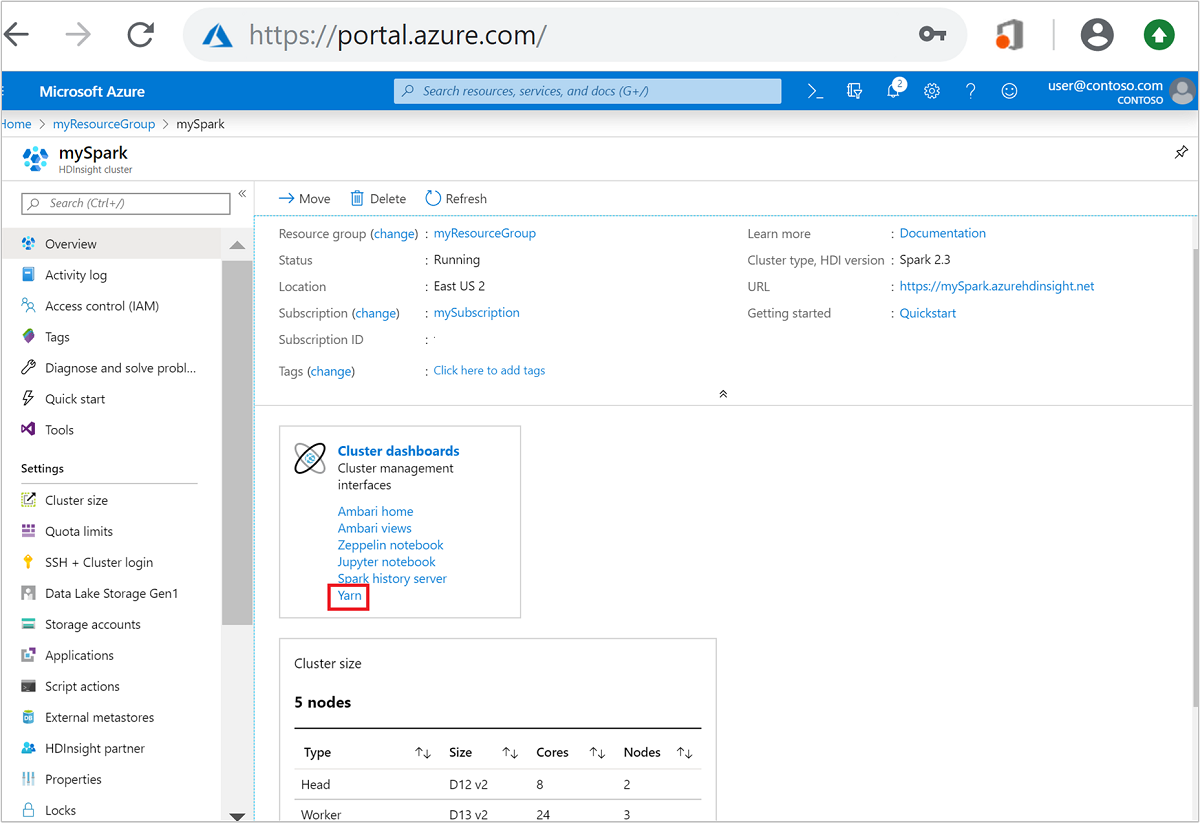
Azure Portal で Spark クラスターを開きます。 詳細については、「クラスターの一覧と表示」を参照してください。
クラスター ダッシュボード上で [Yarn] を選択します。 入力を求められたら、Spark クラスターの管理者資格情報を入力します。
ヒント
Ambari UI から YARN UI を起動してもかまいません。 Ambari UI で [YARN]>[Quick Links]\(クイック リンク\)>[Active]\(アクティブ\)>[Resource Manager UI] に移動します。
Spark アプリケーション用にクラスターを最適化する
アプリケーションの要件に応じて Spark を構成するための主要なパラメーターは、spark.executor.instances、spark.executor.cores、spark.executor.memory の 3 つです。 Executor は、Spark アプリケーション用に起動されるプロセスです。 ワーカー ノードで動作し、アプリケーションのタスクを実行する役割を担います。 それぞれのクラスターで使用される Executor の既定の数とサイズは、ワーカー ノードの数とワーカー ノードのサイズに基づいて計算され、 この情報はクラスターのヘッド ノード上の spark-defaults.conf に保存されます。
3 つの構成パラメーターは、クラスター レベルで (クラスター上で動作するすべてのアプリケーションに対して) 構成できるほか、個々のアプリケーションに対して指定することもできます。
Ambari UI を使用したパラメーターの変更
Ambari UI で [Spark 2]>[Configs]>[Custom spark2-defaults] に移動します。
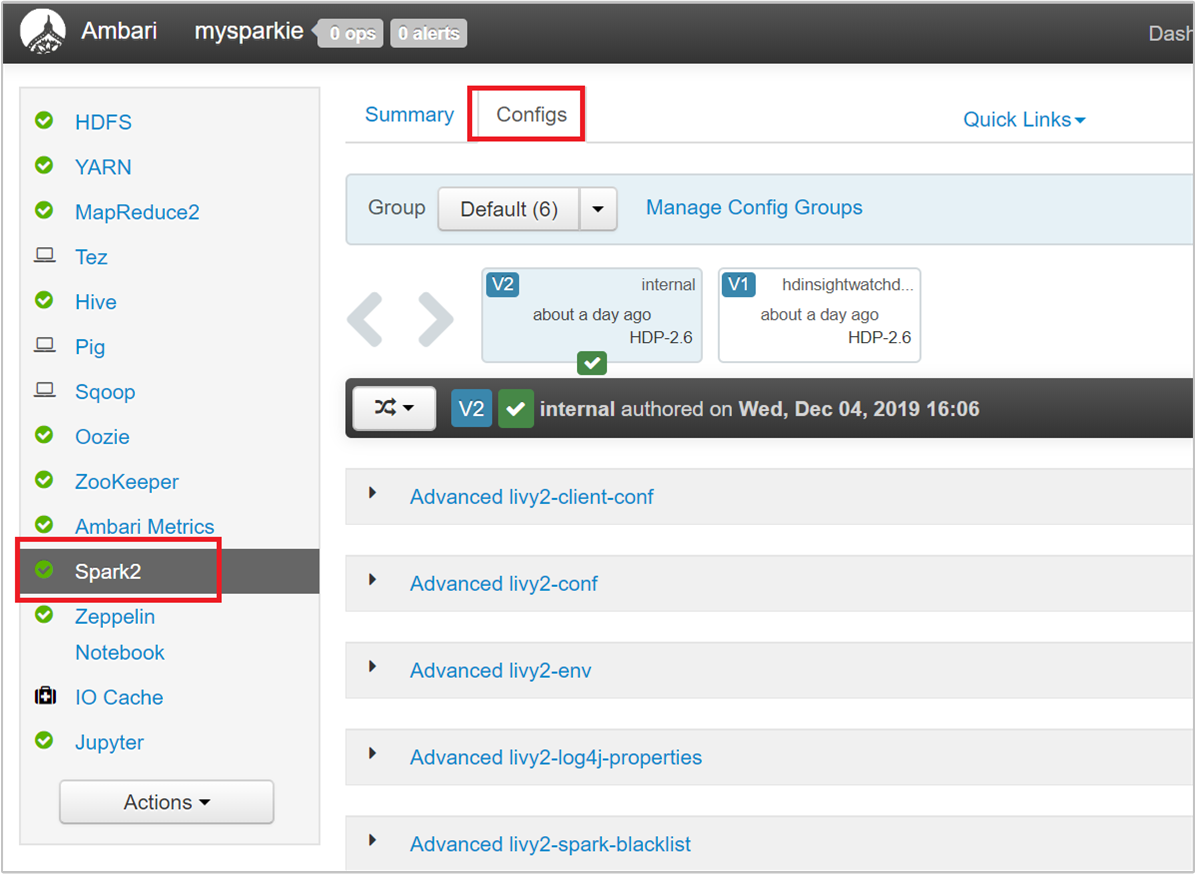
一連の既定値は、クラスター上で 4 つの Spark アプリケーションを同時実行することを想定して決められています。 次のスクリーンショットに示すように、これらの値をユーザー インターフェイスから変更できます。
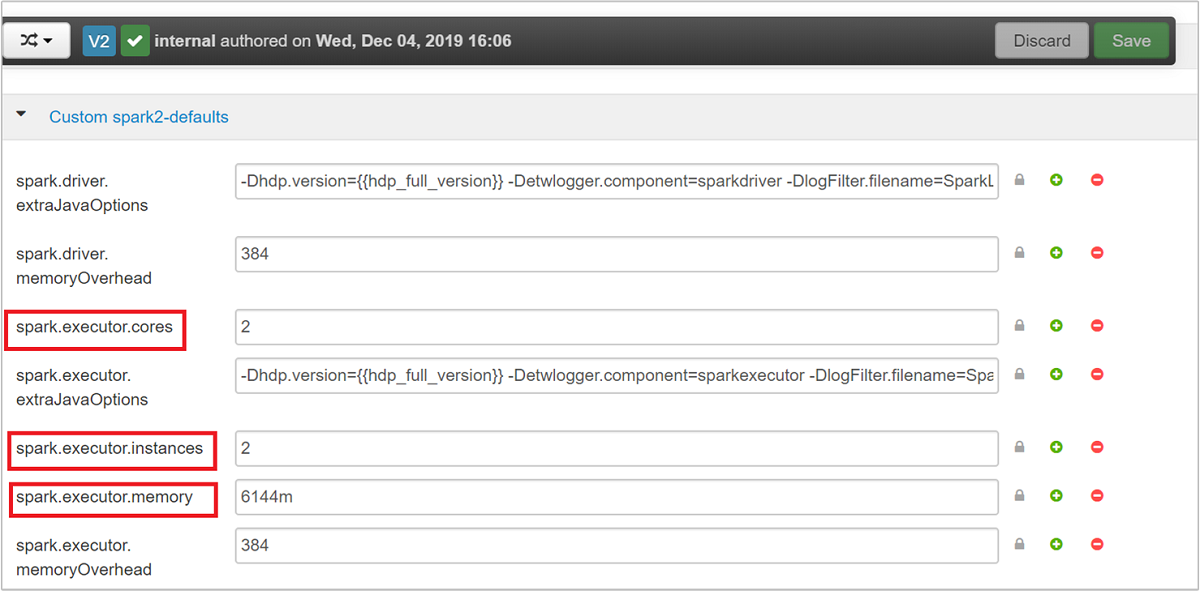
[Save]\(保存\) を選択して構成の変更を保存します。 変更に関係したサービスをすべて再開するよう求めるメッセージがページの上部に表示されます。 [Restart]\(再起動\) をクリックします。
Jupyter Notebook で実行するアプリケーションのパラメーター変更
Jupyter Notebook で実行しているアプリケーションについては、%%configure マジックを使用して構成に変更を加えることができます。 そのような変更は、できればアプリケーションの冒頭で、1 つ目のコード セルを実行する前に記述してください。 これを行うと、Livy セッションの作成時に、確実に構成が適用されます。 アプリケーションの終盤で構成の変更が生じた場合は、 -f パラメーターを使用する必要があります。 ただしその場合、アプリケーションのすべての進捗が失われます。
次のスニペットは、Jupyter で実行しているアプリケーションの構成を変更する方法を示しています。
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
例の列で示されているように、構成パラメーターは JSON 文字列として渡し、マジックの後の次の行に置く必要があります。
spark-submit を使用して送信されたアプリケーションのパラメーター変更
次のコマンドは、 spark-submitを使用して送信されたバッチ アプリケーションの構成パラメーターを変更する例です。
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
cURL を使用して送信されたアプリケーションのパラメーター変更
次のコマンドは、cURL を使用して送信されたバッチ アプリケーションの構成パラメーターを変更する例です。
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Note
JAR ファイルをご自分のクラスター ストレージ アカウントにコピーします。 JAR ファイルをヘッド ノードに直接コピーしないでください。
これらのパラメーターを Spark Thrift サーバーで変更する
Spark Thrift サーバーを使用すると、Spark クラスターに JDBC/ODBC でアクセスし、Spark SQL クエリを実行することができます。 Power BI や Tableau などのツールは、ODBC プロトコルを使用して Spark Thrift サーバーとやり取りし、Spark アプリケーションとして Spark SQL クエリを実行します。 Spark クラスターを作成すると、Spark Thrift サーバーの 2 つのインスタンスが起動されます (ヘッド ノードごとに 1 つ)。 YARN UI には、各 Spark Thrift サーバーが Spark アプリケーションとして表示されます。
Spark Thrift サーバーでは、Spark の Dynamic Executor Allocation が使用されるため、spark.executor.instances は使用されません。 代わりに、Executor 数の指定に spark.dynamicAllocation.maxExecutors と spark.dynamicAllocation.minExecutors が使用されます。 Executor のサイズ変更には、構成パラメーターとして spark.executor.cores と spark.executor.memory が使用されます。 次の手順に示すように、これらのパラメーターは変更できます。
spark.dynamicAllocation.maxExecutors、spark.dynamicAllocation.minExecutorsの各パラメーターを更新するには、Advanced spark2-thrift-sparkconf カテゴリを展開します。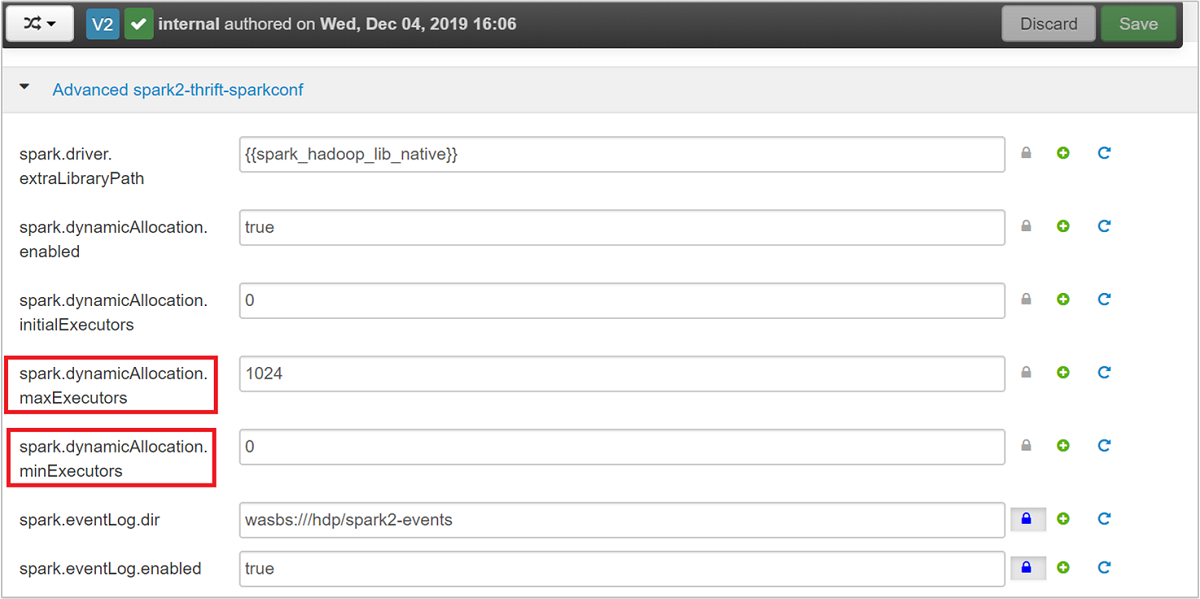
パラメーター
spark.executor.coresおよびspark.executor.memoryを更新するには、Custom spark2-thrift-sparkconf カテゴリを展開します。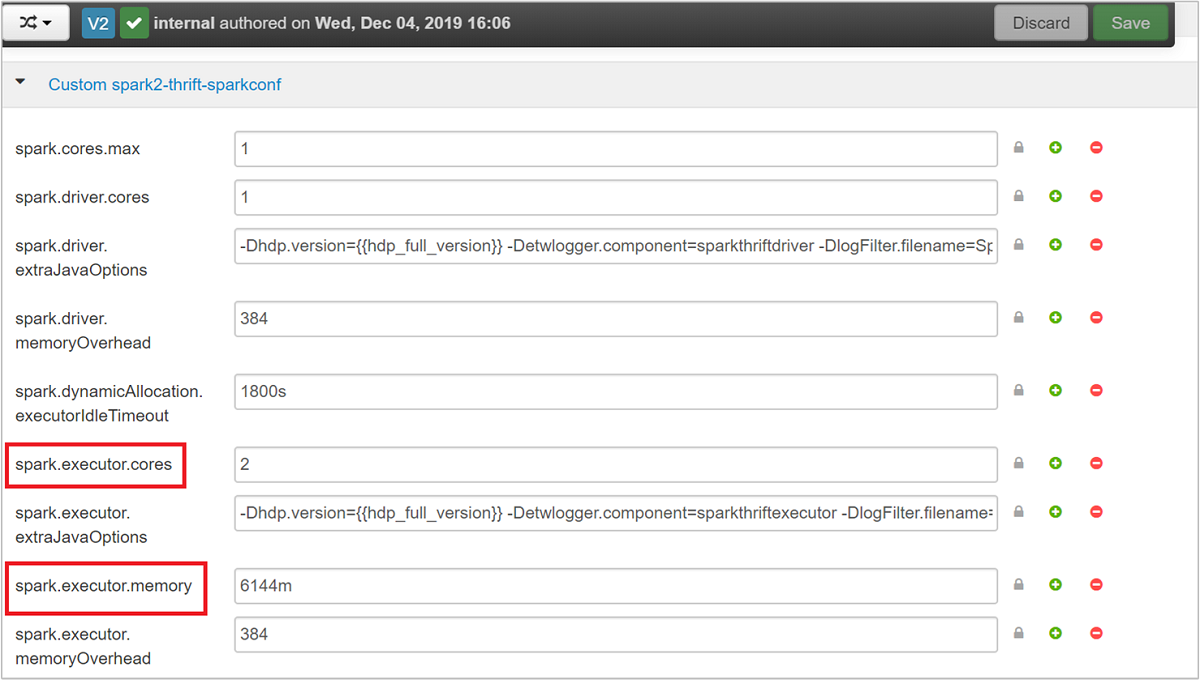
Spark Thrift サーバーのドライバーのメモリを変更する
ヘッド ノードの RAM の合計サイズが 14 GB を超える場合、Spark Thrift サーバーのドライバーのメモリはヘッド ノードの RAM サイズの 25% に構成されます。 ドライバーのメモリ構成は、次のスクリーンショットのように Ambari UI を使用して変更できます。
Ambari UI で [Spark2]>[Configs]\(構成\)>[Advanced spark2.x-env] に移動します。 次に、spark_thrift_cmd_opts の値を指定します。
Spark クラスター リソースを解放する
Spark の動的割り当てにより、Thrift サーバーから利用できるリソースは、2 つのアプリケーション マスターのリソースのみです。 これらのリソースの領域を解放するには、クラスター上で実行されている Thrift サーバー サービスを停止する必要があります。
Ambari UI の左ペインで [Spark2] を選択します。
次のページで、[Spark 2 Thrift Servers] を選択します。
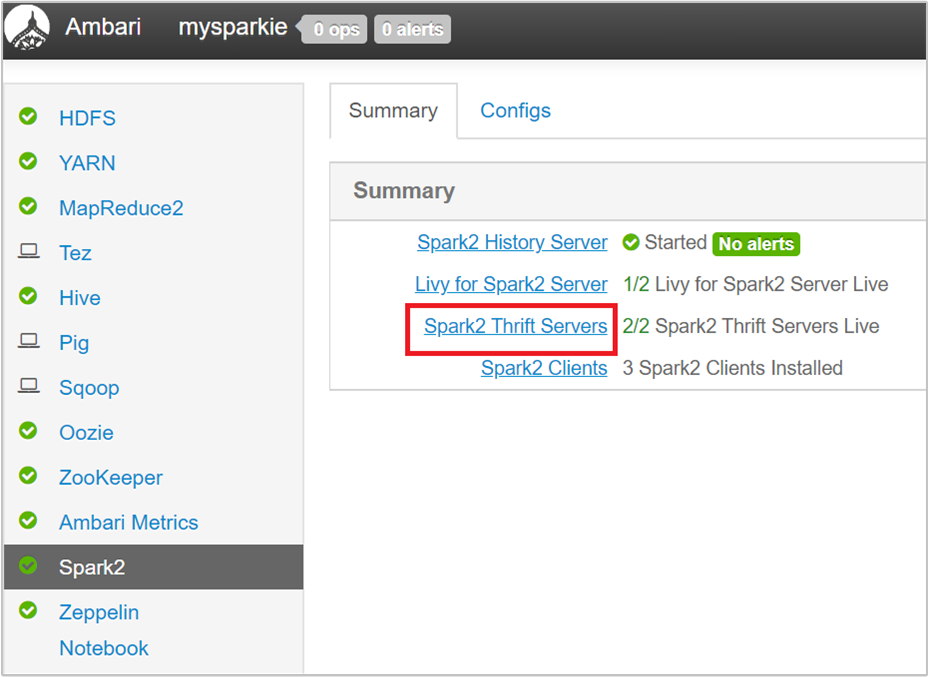
Spark 2 Thrift サーバーが実行されている 2 つのヘッド ノードが表示されます。 いずれかのヘッド ノードを選択してください。
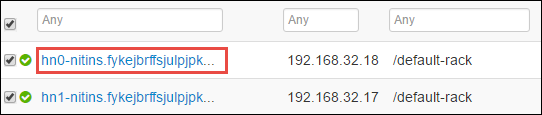
そのヘッド ノードで実行されているすべてのサービスが次のページに一覧表示されます。 一覧から、Spark 2 Thrift Server の横にあるドロップダウン ボタンを選択し、[Stop] を選択します。
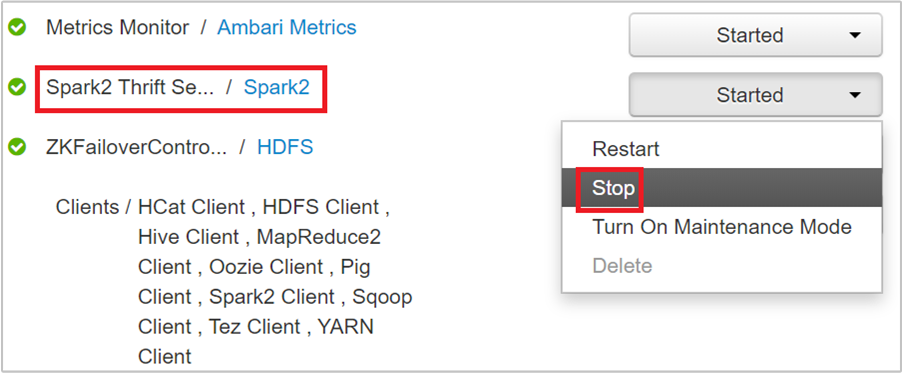
もう一方のヘッド ノードについても同じ手順を繰り返します。
Jupyter サービスを再起動する
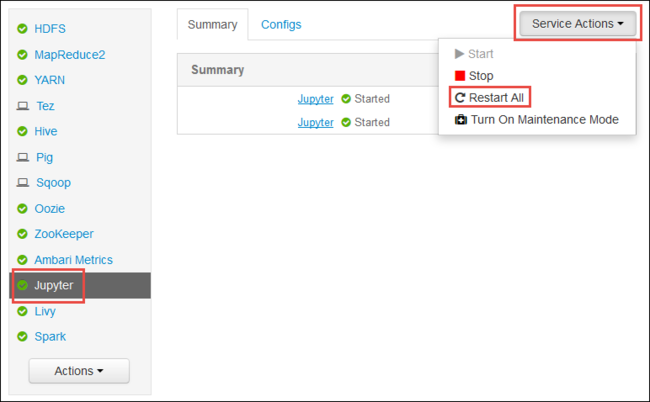
この記事の最初で示したように、Ambari Web UI を起動します。 左側のナビゲーション ウィンドウで、 [Jupyter] 、 [Service Actions]\(サービス アクション\) 、 [Restart All]\(すべて再起動\) の順に選択します。 これで、すべてのヘッドノードで Jupyter サービスが開始されます。
リソースの監視
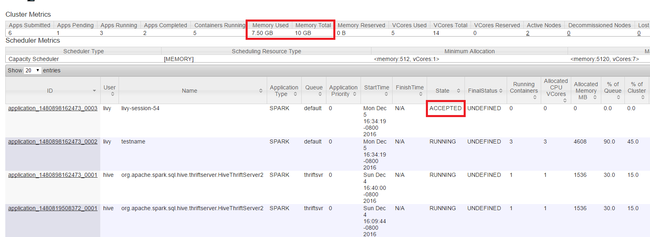
この記事の最初で示したように、Yarn Web UI を起動します。 画面上部の [Cluster Metrics] テーブルで、 [Memory Used] と [Memory Total] の列の値を確認します。 2 つの値が近い場合は、次のアプリケーションを開始するためのリソースが十分でない可能性があります。 [VCores Used] と [VCores Total] の列でも同じことが言えます。 また、メイン ビューに、 [ACCEPTED] の状態のまま、 [RUNNING] にも [FAILED] の状態にも移行していないアプリケーションがある場合も、開始するためのリソースが十分でないことを示している可能性があります。
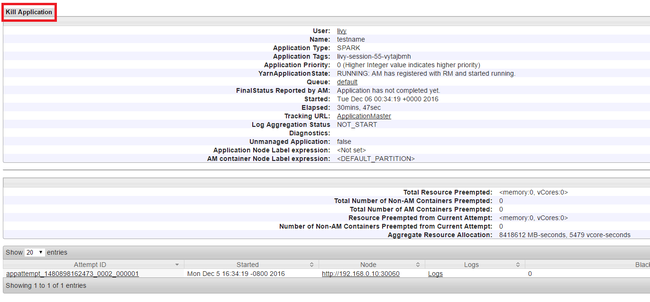
実行中のアプリケーションを強制終了する
Yarn UI の左側のパネルで [Running]\(実行中\) をクリックします。 実行中のアプリケーションの一覧から、強制終了するアプリケーションを決定し、 [ID] を選択します。
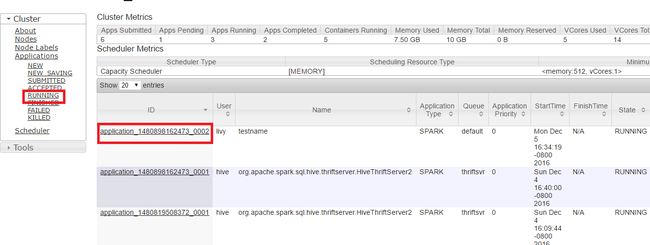
右上隅の [Kill Application]\(アプリの強制終了\) をクリックして、 [OK] をクリックします。
関連項目
データ アナリスト向け
- Apache Spark と Machine Learning: HDInsight で Spark を使用して、HVAC データを使用して建物の温度を分析する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して食品の検査結果を予測する
- HDInsight 上での Apache Spark を使用した Web サイト ログ分析
- HDInsight での Apache Spark を使用した Application Insight テレメトリ データ分析
Apache Spark 開発者向け
- Scala を使用してスタンドアロン アプリケーションを作成する
- Apache Livy を使用して Apache Spark クラスターでジョブをリモートから実行する
- IntelliJ IDEA 用の HDInsight Tools プラグインを使用して Spark Scala アプリケーションを作成し、送信する
- IntelliJ IDEA 用の HDInsight Tools プラグインを使用して Apache Spark アプリケーションをリモートでデバッグする
- HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
- HDInsight 用の Apache Spark クラスター内の Jupyter Notebook で使用可能なカーネル
- Jupyter Notebook で外部のパッケージを使用する
- Jupyter をコンピューターにインストールして HDInsight Spark クラスターに接続する