Azure Toolkit for IntelliJ を使用した失敗した Spark ジョブのデバッグ (プレビュー)
この記事では、Azure Toolkit for IntelliJ の HDInsight Tools を使用して Spark Failure Debug アプリケーションを実行する方法に関するステップ バイ ステップ ガイダンスを提供します。
前提条件
Oracle Java Development Kit。 このチュートリアルでは、Java バージョン 8.0.202 を使用します。
IntelliJ IDEA。 この記事では、IntelliJ IDEA Community 2019.1.3 を使用します。
Azure Toolkit for IntelliJ。 「Azure Toolkit for IntelliJ のインストール」を参照してください。
HDInsight クラスターに接続します。 HDInsight クラスターへの接続に関するページを参照してください。
Microsoft Azure Storage Explorer。 Microsoft Azure Storage Explorer のダウンロードに関するページを参照してください。
デバッグ テンプレートを含むプロジェクトを作成する
このドキュメントでは、失敗したデバッグを続行し、失敗したタスク デバッグのサンプル ファイルを取得するための spark2.3.2 プロジェクトを作成します。
IntelliJ IDEA を開きます。 [新しいプロジェクト] ウィンドウを開きます。
a. 左側のウィンドウの [Azure Spark/HDInsight] を選択します。
b. メイン ウィンドウから [Spark Project with Failure Task Debugging Sample(Preview)(Scala)] (失敗したタスク デバッグのサンプルを含む Spark プロジェクト (プレビュー) (Scala)) を選択します。
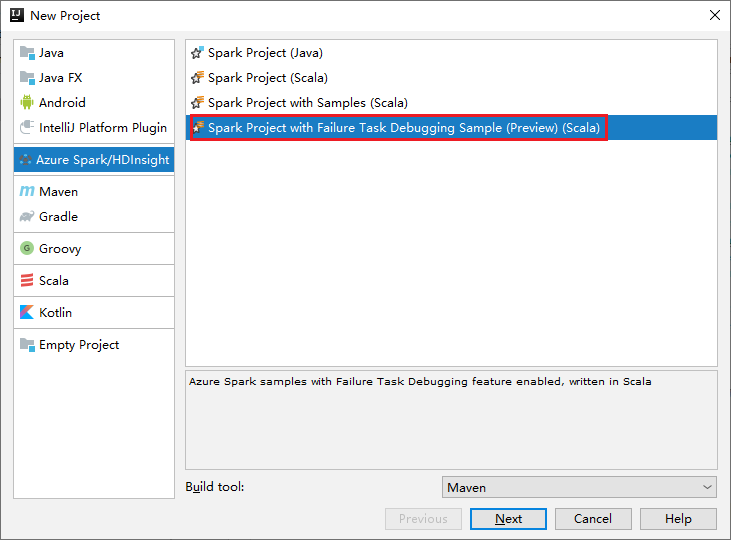
c. [次へ] を選択します。
[New Project](新しいプロジェクト) ウィンドウで、次の手順を実行します。
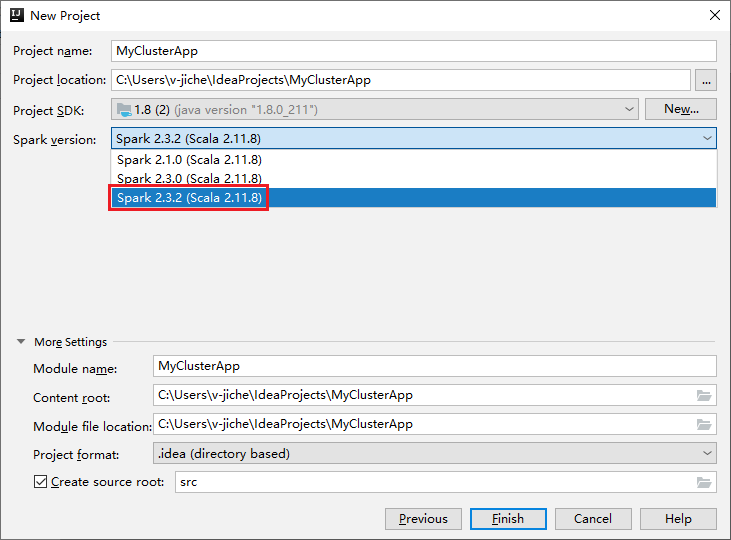
a. プロジェクト名とプロジェクトの場所を入力します。
b. [Project SDK] (プロジェクト SDK) ドロップダウン リストで、Spark 2.3.2 クラスター用に [Java 1.8] を選択します。
c. [Spark バージョン] ドロップダウン リストで、 [Spark 2.3.2(Scala 2.11.8)] を選択します。
d. [完了] を選択します。
[src]>[main]>[scala] を選択してプロジェクトのコードを開きます。 この例では、AgeMean_Div() スクリプトを使用します。
HDInsight クラスター上で Spark Scala/Java アプリケーションを実行する
Spark Scala/Java アプリケーション作成した後、次の手順を実行して、そのアプリケーションを Spark クラスター上で実行します。
[構成の追加] をクリックして [実行/デバッグ構成] ウィンドウを開きます。

[実行/デバッグ構成] ダイアログ ボックスで、プラス記号 (+) を選択します。 次に [HDInsight での Apache Spark] オプションを選択します。
[Remotely Run in Cluster](クラスターでリモート実行) タブに切り替えます。 [名前] 、 [Spark cluster](Spark クラスター) 、 [Main class name](メイン クラス名) に情報を入力します。 ツールでは、Executor を使用したデバッグがサポートされています。 [numExectors] は既定値が 5 ですが、3 より大きい値に設定することはお勧めできません。 実行時間を短縮するために、 [job Configurations] (ジョブ構成) に [spark.yarn.maxAppAttempts] を追加し、その値を 1 に設定できます。 [OK] ボタンをクリックして構成を保存します。
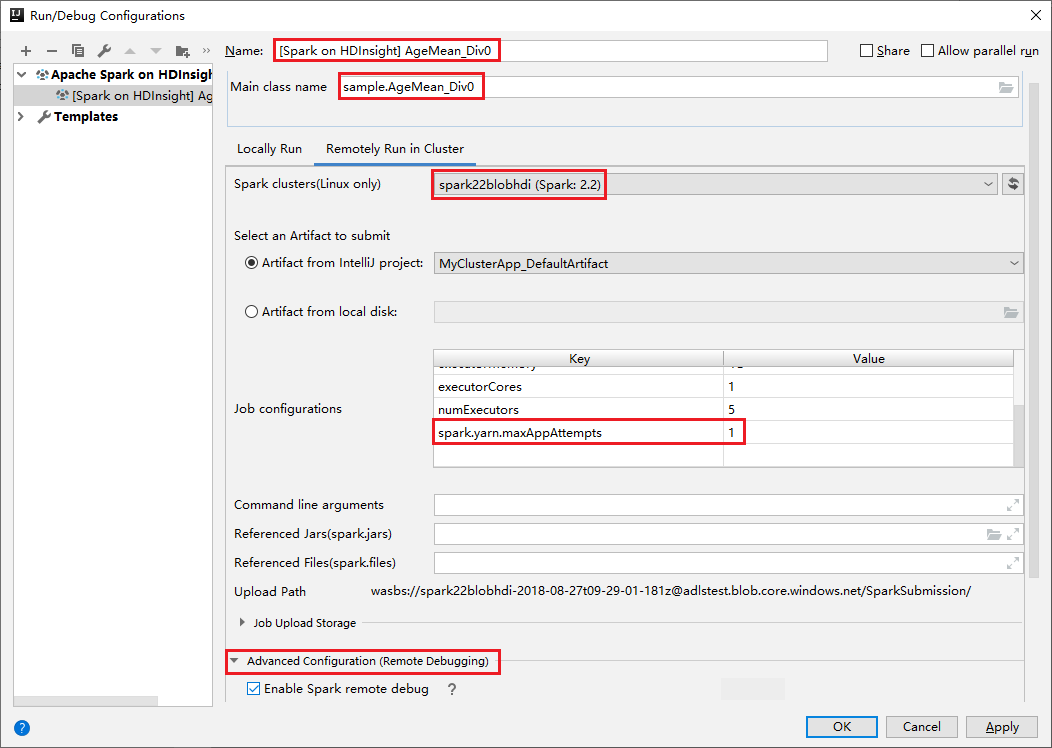
指定した名前で構成が保存されます。 構成の詳細を表示するには、構成名を選択します。 変更するには、 [構成の編集] を選択します。
構成の設定を完了したら、リモート クラスターに対してプロジェクトを実行できます。

出力ウィンドウからアプリケーション ID を確認できます。

失敗したジョブのプロファイルをダウンロードする
ジョブの送信に失敗した場合は、さらにデバッグするために、失敗したジョブのプロファイルをローカル コンピューターにダウンロードできます。
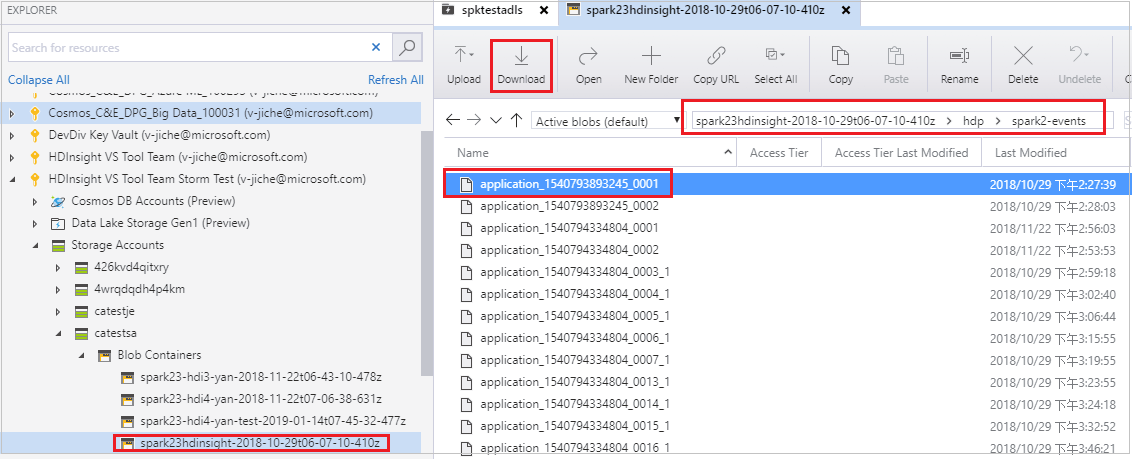
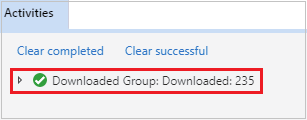
Microsoft Azure Storage Explorer を開き、失敗したジョブに対するクラスターの HDInsight アカウントを見つけて、失敗したジョブのリソースを、対応する場所である \hdp\spark2-events\.spark-failures\<アプリケーション ID> からローカル フォルダーにダウンロードします。[アクティビティ] ウィンドウに、ダウンロードの進捗状況が表示されます。
ローカルのデバッグ環境を構成して失敗をデバッグする
元のプロジェクトを開くか新しいプロジェクトを作成して、元のソース コードに関連付けます。現在、エラー デバッグでは spark2.3.2 バージョンのみがサポートされています。
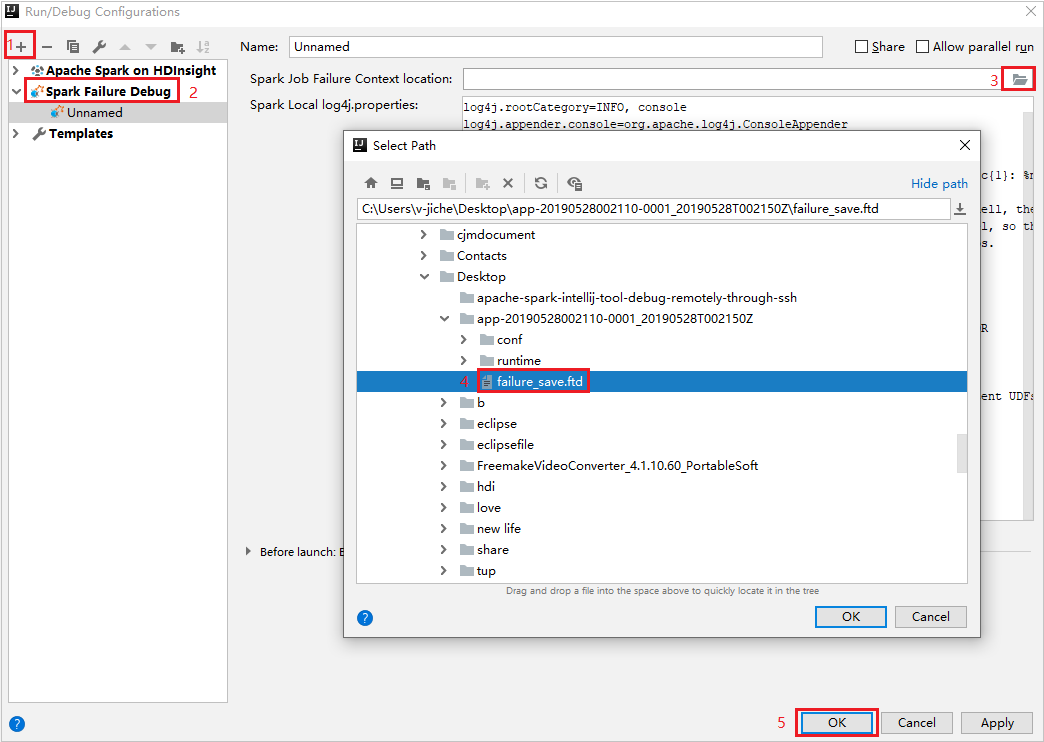
IntelliJ IDEA で、Spark Failure Debug 構成ファイルを作成し、 [Spark Job Failure Context location] (Spark ジョブの失敗したコンテキストの場所) フィールドで前にダウンロードされた失敗したジョブのリソースから FTD ファイルを選択します。
ツールバーのローカル実行ボタンをクリックすると、エラーが [実行] ウィンドウに表示されます。
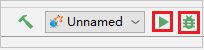
ログに示されているようにブレークポイントを設定した後、ローカル デバッグ ボタンをクリックして、IntelliJ の通常の Scala/Java プロジェクトと同様にローカル デバッグを実行します。
デバッグの後、プロジェクトが正常に完了した場合は、失敗したジョブを HDInsight クラスター上の Spark に再送信できます。
次のステップ
シナリオ
- Apache Spark と BI:HDInsight と BI ツールで Spark を使用して対話型データ分析を実行する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して、HVAC データを使用して建物の温度を分析する
- Apache Spark と Machine Learning:HDInsight で Spark を使用して食品の検査結果を予測する
- HDInsight 上での Apache Spark を使用した Web サイト ログ分析
アプリケーションの作成と実行
ツールと拡張機能
- Azure Toolkit for IntelliJ を使用して HDInsight クラスター向けの Apache Spark アプリケーションを作成する
- Azure Toolkit for IntelliJ を使用して VPN 経由で Apache Spark アプリケーションをリモートでデバッグする
- Azure Toolkit for Eclipse 上の HDInsight Tools を使用して Apache Spark アプリケーションを作成する
- HDInsight 上の Apache Spark クラスターで Apache Zeppelin Notebook を使用する
- HDInsight 用の Apache Spark クラスター内の Jupyter Notebook で使用可能なカーネル
- Jupyter Notebook で外部のパッケージを使用する
- Jupyter をコンピューターにインストールして HDInsight Spark クラスターに接続する
リソースの管理
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示