Устранение проблем с производительностью действий копирования
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описано, как устранить проблему с производительностью действия копирования в Фабрике данных Azure.
После выполнения действия копирования можно собрать результаты выполнения и статистику производительности с помощью представления мониторинга действия копирования. Пример приведен ниже.
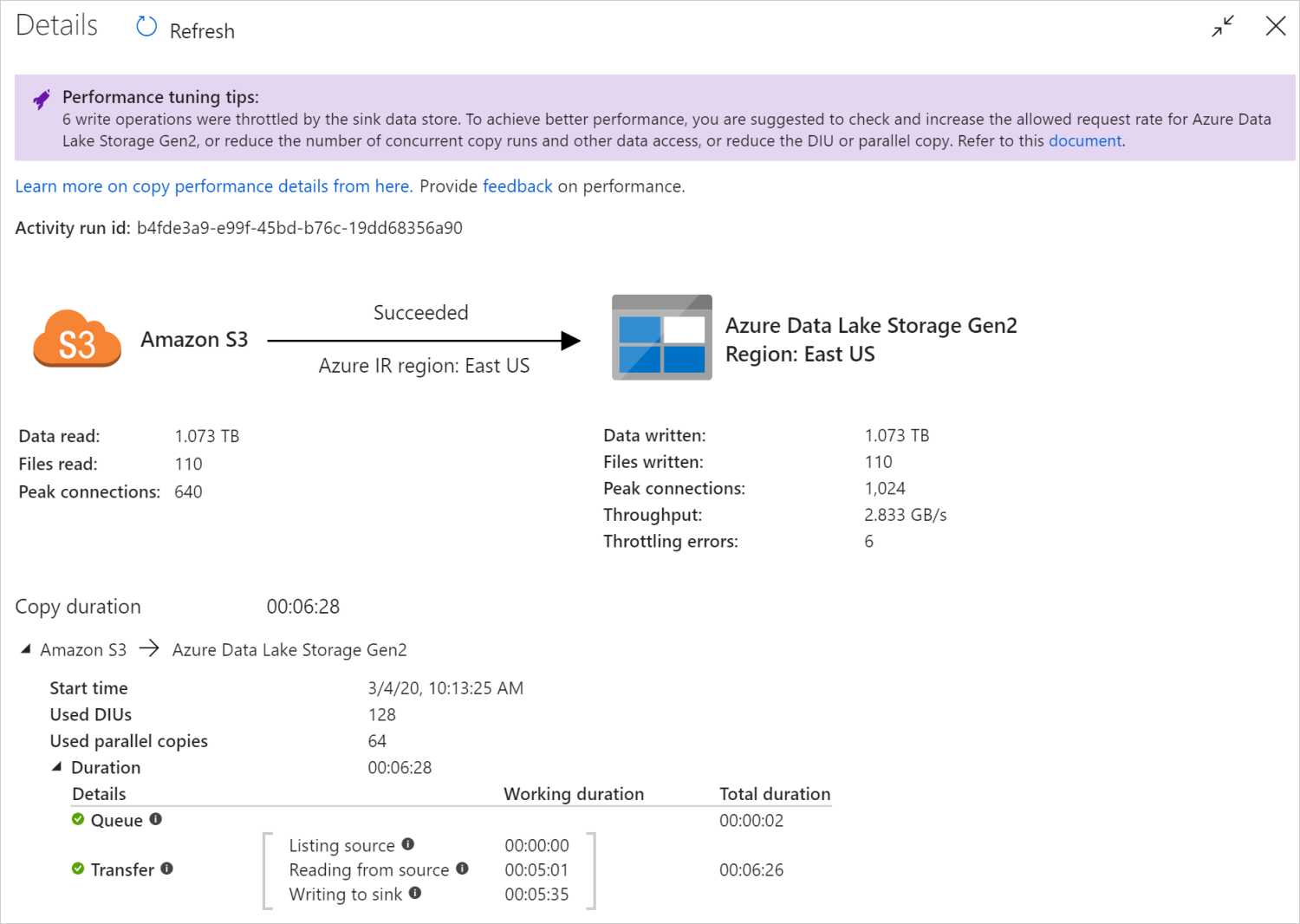
Советы по настройке производительности
В некоторых сценариях при выполнении действия копирования вы увидите Советы по настройке производительности в верхней части окна, как показано в примере выше. Советы указывают на узкие места, выявленные службой для конкретного выполнения операции копирования, а также дают рекомендации по увеличению пропускной способности копирования. Попробуйте внести рекомендованное изменение, а затем снова выполните действие копирования.
Для справки: в настоящее время советы по настройке производительности предоставляют рекомендации в следующих случаях.
| Категория | Советы по настройке производительности |
|---|---|
| Конкретное хранилище данных | Загрузка данных в Azure Synapse Analytics: рекомендуется использовать PolyBase или оператор COPY, если они не используются. |
| Копирование данных из базы данных SQL Azure и обратно: при использовании большого количества единиц пропускной способности базы данных рекомендуется выполнить обновление до более высокого уровня. | |
| Копирование данных из Azure Cosmos DB и обратно: при использовании большого количества единиц запроса рекомендуется выполнить обновление до большего количества ЕЗ. | |
| Копирование данных из таблицы SAP: при копировании большого объема данных рекомендуется использовать параметр секции соединителя SAP, чтобы включить параллельную нагрузку и увеличить максимальный номер секции. | |
| Прием данных из Amazon RedShift: рекомендуется использовать UNLOAD, если еще не используется. | |
| Регулирование в хранилище данных | Если количество операций чтения и записи во время копирования регулируется хранилищем данных, рекомендуется проверить и увеличить разрешенную частоту запросов для хранилища данных или уменьшить число параллельных рабочих нагрузок. |
| Среда выполнения интеграции | Если вы используете локальную среду выполнения интеграции (IR) и действие копирования долго ждет в очереди появления в IR доступного ресурса для выполнения, рекомендуется масштабировать IR. |
| Если вы используете среду Azure Integration Runtime, находящуюся не в оптимальном регионе, что приводит к медленному выполнению операций чтения и записи, рекомендуется настроить использование IR в другом регионе. | |
| Отказоустойчивость | Если настройка отказоустойчивости и пропуск несовместимых строк приводят к снижению производительности, рекомендуется обеспечить совместимость данных источника и приемника. |
| промежуточное копирование | Если промежуточное копирование настроено, но бесполезно для пары источник-приемник, рекомендуется удалить его. |
| Возобновить | Обратите внимание, что, если действие копирования возобновляется с последней точки сбоя, а параметр DIU после первоначального выполнения был изменен, новый параметр DIU не вступит в силу. |
Сведения о выполнении действия копирования
Сведения о выполнении и длительности в нижней части представления мониторинга действия копирования описывают ключевые этапы, которые проходит действие копирования (см. пример в начале этой статьи), что особенно полезно для устранения проблем с производительностью копирования. Узким местом при выполнении копирования является операция с самой большой длительностью. Ознакомьтесь со следующей таблицей, в которой представлены определения всех этапов, и узнайте, как устранять проблемы с действием копирования в Azure IR, а также устранять проблемы с действием копирования в локально размещенной IR с использованием такой информации.
| Этап | Description |
|---|---|
| Queue | Время, прошедшее до фактического запуска действия копирования в среде выполнения интеграции. |
| Сценарий, предваряющий копирование | Время, прошедшее между запуском действия копирования в среде IR и моментом, когда это действие завершает выполнение сценария, предваряющего копирование, в хранилище данных приемника. Применяется при настройке сценария, предваряющего копирование, для приемников базы данных, например, когда операция записи данных в Базу данных SQL Azure выполняет очистку перед копированием новых данных. |
| Передать | Время, прошедшее между окончанием предыдущего шага и передачей IR всех данных от источника к приемнику. Обратите внимание, что вложенные шаги в процессе переноса выполняются параллельно, а некоторые операции сейчас не отображаются, например анализ или создание формата файлов. - Время до первого байта: время, прошедшее между окончанием предыдущего шага и моментом, когда IR получает первый байт из исходного хранилища данных. Применяется к источникам не на основе файлов. - Вывод источника: количество времени, затраченное на перечисление исходных файлов или секций данных. Последний параметр применяется при настройке вариантов секционирования для источников базы данных, например при копировании данных из баз данных, таких как Oracle, SAP HANA, Teradata, Netezza и т. д. -Чтение из источника: время, затраченное на получение данных из исходного хранилища данных. - Запись в приемник: время, затраченное на запись данных в хранилище данных приемника. Обратите внимание, что на данный момент некоторые соединители не имеют этой метрики, включая поиск Azure ИИ, Azure Data Explorer, хранилище таблиц Azure, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Устранение проблем с действием копирования в Azure IR
Выполните шаги по настройке производительности, чтобы спланировать и провести тест производительности для своего сценария.
Если производительность действия копирования не соответствует ожиданиям, то для устранения проблем с одним действием копирования в Azure Integration Runtime выполните Советы по настройке производительности, если таковые отображаются в представлении мониторинга действия копирования, после чего повторите попытку. В противном случае ознакомьтесь со сведениями о выполнении действия копирования, выясните, какой этап занимает наибольшее время, и выполните приведенные ниже инструкции для повышения производительности копирования.
Длительное выполнение этапа "Сценарий, предваряющий копирование": означает, что выполнение сценария, предваряющего копирование, в базе данных приемника занимает слишком много времени. Настройте логику указанного сценария, предваряющего копирование, чтобы повысить производительность. Если вам нужна дополнительная помощь по улучшению сценария, обратитесь к команде, занимающейся базами данных.
Длительное выполнение этапа "Перенос — время до первого байта": означает, что на возврат данных исходным запросом уходит много времени. Проверьте и оптимизируйте запрос или сервер. Если вам нужна дополнительная помощь, обратитесь к команде, занимающейся хранилищем данных.
Длительное выполнение этапа "Перенос — вывод источника": означает, что перечисление исходных файлов или секций данных базы данных-источника выполняется медленно.
Если при копировании данных из файлового источника используется фильтр с подстановочным знаком для пути к папке или имени файла (
wildcardFolderPathилиwildcardFileName) или фильтр по времени последнего изменения файла (modifiedDatetimeStartилиmodifiedDatetimeEnd), обратите внимание, что это может привести к перечислению действием копирования всех файлов в указанной папке на стороне клиента и последующему применению фильтра. Такое перечисление файлов может стать узким местом, особенно в том случае, если только небольшой набор файлов удовлетворяет правилу фильтра.Проверьте, можно ли копировать файлы на основе пути или имени файла с секционированием по дате и времени. Такой подход позволяет снизить нагрузку на стороне вывода источника.
Проверьте, можно ли использовать собственный фильтр хранилища данных, а именно prefix для Amazon S3/BLOB-объекта Azure/хранилища файлов Azure и listAfter/listBefore для ADLS 1-го поколения. Это фильтры на стороне сервера хранилища данных, способные обеспечить гораздо более высокую производительность.
Рассмотрите возможность разбиения одного большого набора данных на несколько меньших и одновременного выполнения заданий копирования, каждое из которых обрабатывает только часть данных. Это можно сделать с помощью команд Lookup/GetMetadata + ForEach + Copy. См. шаблоны решений Копирование файлов из нескольких контейнеров или Перенос данных из Amazon S3 в ADLS 2-го поколения в качестве общих примеров.
Проверьте, сообщает ли служба об ошибке регулирования в источнике, а также находится ли хранилище данных в состоянии высокой загрузки. Если это так, либо сократите рабочие нагрузки в хранилище данных, либо попробуйте обратиться к администратору хранилища данных, чтобы увеличить предел регулирования или объем доступных ресурсов.
Используйте Azure IR в регионе исходного хранилища данных или регионе, расположенном близко к нему.
Длительное выполнение этапа "Перенос — чтение из источника":
Выполните рекомендации по загрузке данных для конкретного соединителя, если применимо. Например, при копировании данных из Amazon RedShift настройте использование REDSHIFT UNLOAD.
Проверьте, сообщает ли служба об ошибке регулирования в источнике, а также находится ли хранилище данных в состоянии высокой загрузки. Если это так, либо сократите рабочие нагрузки в хранилище данных, либо попробуйте обратиться к администратору хранилища данных, чтобы увеличить предел регулирования или объем доступных ресурсов.
Проверьте шаблон копирования источника и приемника:
Если шаблон копирования поддерживает больше 4 единиц интеграции данных (DIU), см. сведения в этом разделе. Как правило, можно попробовать увеличить DIU, чтобы повысить производительность.
В противном случае рассмотрите возможность разбиения одного большого набора данных на несколько меньших и одновременного выполнения заданий копирования, каждое из которых обрабатывает только часть данных. Это можно сделать с помощью команд Lookup/GetMetadata + ForEach + Copy. См. шаблоны решений Копирование файлов из нескольких контейнеров, Перенос данных из Amazon S3 в ADLS 2-го поколения или Массовое копирование с помощью таблицы управления в качестве общих примеров.
Используйте Azure IR в регионе исходного хранилища данных или регионе, расположенном близко к нему.
Длительное выполнение этапа "Перенос — запись в приемник":
Выполните рекомендации по загрузке данных для конкретного соединителя, если применимо. Например, при копировании данных в Azure Synapse Analyticsиспользуйте PolyBase или оператор COPY.
Проверьте, сообщает ли служба об ошибке регулирования в приемнике, а также находится ли хранилище данных в состоянии высокой загрузки. Если это так, либо сократите рабочие нагрузки в хранилище данных, либо попробуйте обратиться к администратору хранилища данных, чтобы увеличить предел регулирования или объем доступных ресурсов.
Проверьте шаблон копирования источника и приемника:
Если шаблон копирования поддерживает больше 4 единиц интеграции данных (DIU), см. сведения в этом разделе. Как правило, можно попробовать увеличить DIU, чтобы повысить производительность.
В противном случае постепенно настраивайте операции параллельного копирования. Обратите внимание, что слишком большое количество операций параллельного копирования может даже навредить производительности.
Используйте Azure IR в регионе хранилища данных приемника или регионе, расположенном близко к нему.
Устранение проблем с действием копирования на локально размещенной среде IR
Выполните шаги по настройке производительности, чтобы спланировать и провести тест производительности для своего сценария.
Если производительность копирования не соответствует ожиданиям, то для устранения проблем с одним действием копирования в Azure Integration Runtime выполните Советы по настройке производительности, если таковые отображаются в представлении мониторинга действия копирования, после чего повторите попытку. В противном случае ознакомьтесь со сведениями о выполнении действия копирования, выясните, какой этап занимает наибольшее время, и выполните приведенные ниже инструкции для повышения производительности копирования.
Длительное выполнение этапа "Очередь": означает, что действие копирования долго ждет в очереди появления в локально размещенной среде IR ресурса, доступного для выполнения. Проверьте емкость и потребление IR и увеличьте масштаб в соответствии с рабочей нагрузкой.
Длительное выполнение этапа "Перенос — время до первого байта": означает, что на возврат данных исходным запросом уходит много времени. Проверьте и оптимизируйте запрос или сервер. Если вам нужна дополнительная помощь, обратитесь к команде, занимающейся хранилищем данных.
Длительное выполнение этапа "Перенос — вывод источника": означает, что перечисление исходных файлов или секций данных базы данных-источника выполняется медленно.
Проверьте, имеет ли компьютер локально размещаемой IR низкую задержку при подключении к исходному хранилищу данных. Если источник находится в Azure, можно использовать это средство для проверки задержки от компьютера локально размещаемой IR в регион Azure (чем меньше — тем лучше).
Если при копировании данных из файлового источника используется фильтр с подстановочным знаком для пути к папке или имени файла (
wildcardFolderPathилиwildcardFileName) или фильтр по времени последнего изменения файла (modifiedDatetimeStartилиmodifiedDatetimeEnd), обратите внимание, что это может привести к перечислению действием копирования всех файлов в указанной папке на стороне клиента и последующему применению фильтра. Такое перечисление файлов может стать узким местом, особенно в том случае, если только небольшой набор файлов удовлетворяет правилу фильтра.Проверьте, можно ли копировать файлы на основе пути или имени файла с секционированием по дате и времени. Такой подход позволяет снизить нагрузку на стороне вывода источника.
Проверьте, можно ли использовать собственный фильтр хранилища данных, а именно prefix для Amazon S3/BLOB-объекта Azure/хранилища файлов Azure и listAfter/listBefore для ADLS 1-го поколения. Это фильтры на стороне сервера хранилища данных, способные обеспечить гораздо более высокую производительность.
Рассмотрите возможность разбиения одного большого набора данных на несколько меньших и одновременного выполнения заданий копирования, каждое из которых обрабатывает только часть данных. Это можно сделать с помощью команд Lookup/GetMetadata + ForEach + Copy. См. шаблоны решений Копирование файлов из нескольких контейнеров или Перенос данных из Amazon S3 в ADLS 2-го поколения в качестве общих примеров.
Проверьте, сообщает ли служба об ошибке регулирования в источнике, а также находится ли хранилище данных в состоянии высокой загрузки. Если это так, либо сократите рабочие нагрузки в хранилище данных, либо попробуйте обратиться к администратору хранилища данных, чтобы увеличить предел регулирования или объем доступных ресурсов.
Длительное выполнение этапа "Перенос — чтение из источника":
Проверьте, имеет ли компьютер локально размещаемой IR низкую задержку при подключении к исходному хранилищу данных. Если источник находится в Azure, можно использовать это средство для проверки задержки от компьютера локально размещаемой IR в регионы Azure (чем меньше — тем лучше).
Убедитесь, что входная пропускная способность компьютера локально размещаемой IR достаточно велика для эффективного чтения и передачи данных. Если исходное хранилище данных находится в Azure, это средство можно использовать для проверки скорости загрузки.
Проверьте тенденцию использования ЦП и памяти локальной среды IR: портал Azure -> фабрика данных или рабочая область Synapse -> страница обзора. Рассмотрите возможность масштабирования IR, если потребление ресурсов ЦП велико или объем доступной памяти мал.
Выполните рекомендации по загрузке данных для конкретного соединителя, если применимо. Например:
При копировании данных из Oracle, Netezza, Teradata, SAP HANA, таблицы SAP и SAP Open Hub включите параллельное копирование данных параметрами секционирования данных.
При копировании данных из HDFS настройте использование DistCp.
При копировании данных из Amazon Redshift настройте использование Redshift UNLOAD.
Проверьте, сообщает ли служба об ошибке регулирования в источнике, а также находится ли хранилище данных в состоянии высокой загрузки. Если это так, либо сократите рабочие нагрузки в хранилище данных, либо попробуйте обратиться к администратору хранилища данных, чтобы увеличить предел регулирования или объем доступных ресурсов.
Проверьте шаблон копирования источника и приемника:
При копировании данных из хранилищ данных с поддержкой параметров секционирования рекомендуется настраивать операции параллельного копирования постепенно. Обратите внимание, что слишком большое количество операций параллельного копирования может даже снизить производительность.
В противном случае рассмотрите возможность разбиения одного большого набора данных на несколько меньших и одновременного выполнения заданий копирования, каждое из которых обрабатывает только часть данных. Это можно сделать с помощью команд Lookup/GetMetadata + ForEach + Copy. См. шаблоны решений Копирование файлов из нескольких контейнеров, Перенос данных из Amazon S3 в ADLS 2-го поколения или Массовое копирование с помощью таблицы управления в качестве общих примеров.
Длительное выполнение этапа "Перенос — запись в приемник":
Выполните рекомендации по загрузке данных для конкретного соединителя, если применимо. Например, при копировании данных в Azure Synapse Analyticsиспользуйте PolyBase или оператор COPY.
Проверьте, имеет ли компьютер локально размещаемой IR низкую задержку при подключении к хранилищу данных приемника. Если приемник находится в Azure, можно использовать это средство для проверки задержки от компьютера локально размещаемой IR в регион Azure (чем меньше — тем лучше).
Убедитесь, что выходная пропускная способность компьютера локально размещаемой IR достаточно велика для эффективной передачи и записи данных. Если хранилище данных приемника находится в Azure, это средство можно использовать для проверки скорости передачи.
Проверьте тенденцию использования ЦП и памяти локальной среды IR: портал Azure -> фабрика данных или рабочая область Synapse -> страница обзора. Рассмотрите возможность масштабирования IR, если потребление ресурсов ЦП велико или объем доступной памяти мал.
Проверьте, сообщает ли служба об ошибке регулирования в приемнике, а также находится ли хранилище данных в состоянии высокой загрузки. Если это так, либо сократите рабочие нагрузки в хранилище данных, либо попробуйте обратиться к администратору хранилища данных, чтобы увеличить предел регулирования или объем доступных ресурсов.
Постепенно настраивайте операции параллельного копирования. Обратите внимание, что слишком большое количество операций параллельного копирования может даже навредить производительности.
Производительность соединителя и IR
В этом разделе рассматриваются некоторые инструкции по устранению проблем с производительностью для определенного типа соединителя или среды выполнения интеграции.
Время выполнения действия зависит от используемой среды — Azure IR или Azure VNet IR
Время выполнения действия зависит от среды выполнения интеграции, на которой основан набор данных.
Симптомы: простое переключение раскрывающегося меню "Связанная служба" в наборе данных выполняет те же действия конвейера, однако показывает совершенно разные значения времени выполнения. Если набор данных основан на среде выполнения интеграции с управляемой виртуальной сетью, выполнение занимает больше времени, чем при использовании среды выполнения интеграции по умолчанию.
Причина: при проверке сведений о выполнении конвейера можно заметить, что медленный конвейер выполняется в IR управляемой виртуальной сети (виртуальной сети), а обычный — в Azure IR. Для среды выполнения интеграции в управляемой виртуальной сети требуется больше времени в очереди, чем для среды выполнения интеграции Azure. Это связано с тем, что мы не резервируем один вычислительный узел на каждый экземпляр службы, поэтому для каждого действия копирования нужно время на подготовку, и это в основном происходит в месте подключения виртуальной сети, а не в среде выполнения интеграции Azure.
Низкая производительность при загрузке данных в Базу данных SQL Azure
Симптомы: при копировании данных в Базу данных SQL Azure происходит снижение скорости.
Причина: основная причина проблемы, как правило, связана с узким местом на стороне Базы данных SQL Azure. Ниже представлены некоторые возможные причины.
Уровень Базы данных SQL Azure недостаточно высок.
Потребление DTU Базы данных SQL Azure составляет почти 100 %. Вы можете отслеживать производительность, а также рассмотреть возможность обновления уровня Базы данных SQL Azure.
Индексы заданы неправильно. Удалите все индексы перед загрузкой данных и создайте их повторно после завершения загрузки.
WriteBatchSize не вмещает строку схемы. Попробуйте увеличить свойство для решения этой проблемы.
Вместо массовой вставки используется хранимая процедура, которая, как ожидается, может ухудшить производительность.
Время ожидания или снижение производительности при анализе большого файла Excel
Симптомы
При создании набора данных Excel и импорте схемы из подключения или хранилища, предварительном просмотре данных, выводе списка или обновлении листов может появиться ошибка времени ожидания, если файл Excel имеет большой размер.
При использовании действия Copy для копирования данных из большого файла Excel (>= 100 МБ) в другое хранилище данных может наблюдаться снижение производительности или появляться проблема OOM.
Причина.
Для таких операций, как импорт схемы, предварительный просмотр данных и вывод списка листов в наборе данных Excel, время ожидания составляет 100 с и является статическим. Для большого файла Excel эти операции могут не завершиться в течение времени ожидания.
Действие копирования считывает весь файл Excel в память, а затем находит указанный лист и ячейки для чтения данных. Это поведение вызвано базовым пакетом SDK, используемым службой.
Решение.
Для импорта схемы можно создать образец файла меньшего размера, который является подмножеством исходного файла, и выбрать параметр "импортировать схему из образца файла" вместо параметра "импортировать схему из подключения или хранилища".
Для вывода листа в раскрывающемся списке листа можно щелкнуть "Изменить" и ввести имя или индекс листа.
Чтобы скопировать большой файл Excel (> 100 МБ) в другое хранилище, можно использовать источник Excel Потока данных, который выполняет потоковое чтение и обеспечивает более высокую производительность.
Проблема OOM с чтением больших JSON/Excel/XML-файлов
Симптомы: при чтении больших JSON/Excel/XML-файлов во время выполнения действия возникает проблема с нехваткой памяти ..
Причина.
- Для больших XML-файлов: проблема OOM с чтением больших XML-файлов выполняется по проектированию. Причина заключается в том, что весь XML-файл должен быть считывается в память, так как он является одним объектом, то схема выводится и извлекается данные.
- Для больших файлов Excel: проблема OOM с чтением больших файлов Excel выполняется по проектированию. Причина заключается в том, что пакет SDK (POI/NPOI) должен считывать весь файл excel в память, а затем выводить схему и получать данные.
- Для больших JSON-файлов: проблема OOM с чтением больших JSON-файлов выполняется путем разработки, когда JSON-файл является одним объектом.
Рекомендация. Примените один из следующих вариантов для решения проблемы.
- Вариант-1. Регистрация локальной локальной среды выполнения интеграции с мощным компьютером (высоким объемом ЦП или памяти) для чтения данных из большого файла с помощью действия копирования.
- Вариант-2. Использование оптимизированной памяти и кластера больших размеров (например, 48 ядер) для чтения данных из большого файла с помощью действия потока данных сопоставления.
- Вариант-3. Разделение большого файла на небольшие, а затем использование действия потока данных копирования или сопоставления для чтения папки.
- Вариант 4. Если во время копирования папки XML/Excel/JSON возникла проблема с OOM, используйте действие foreach + действие потока данных копирования и сопоставления в конвейере для обработки каждого файла или вложенной папки.
- Вариант-5: другие:
- Для XML используйте действие Notebook с оптимизированным для памяти кластером для чтения данных из файлов, если каждый файл имеет одну и ту же схему. В настоящее время Spark имеет различные реализации для обработки XML.
- Для JSON используйте различные формы документов (например, один документ, документ на строку и массив документов) в параметрах JSON в разделе сопоставления источника потока данных. Если содержимое JSON-файла является документом на строку, оно потребляет очень мало памяти.
Прочие ссылки
Ниже приведены справочные материалы по мониторингу и настройке производительности для некоторых поддерживаемых хранилищ данных.
- Хранилище BLOB-объектов Azure: Целевые показатели масштабируемости и производительности для хранилища BLOB-объектов и Контрольный список для обеспечения масштабируемости и производительности хранилища BLOB-объектов.
- Хранилище таблиц Azure: Целевые показатели масштабируемости и производительности для Хранилища таблиц и Контрольный список для обеспечения масштабируемости и производительности Хранилища таблиц.
- База данных SQL Azure: вы можете наблюдать за производительностью и проверять процент использования единиц транзакций базы данных (DTU).
- Azure Synapse Analytics: возможности измеряются в единицах использования хранилища данных (DWU). См. статью Управление вычислительными ресурсами в Azure Synapse Analytics (обзор).
- Azure Cosmos DB: уровни производительности в Azure Cosmos DB.
- SQL Server: мониторинг и настройка производительности.
- Локальный файловый сервер: настройка производительности для файловых серверов.
Связанный контент
См. другие статьи о действии копирования: