Kanály a aktivity ve službě Azure Data Factory a Azure Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Důležité
Podpora nástroje Azure Machine Learning Studio (classic) skončí 31. srpna 2024. Doporučujeme, abyste do tohoto data přešli na Azure Machine Learning .
Od 1. prosince 2021 nemůžete vytvářet nové prostředky machine Learning Studia (klasické) (pracovní prostor a plán webových služeb). Až do 31. srpna 2024 můžete dál používat stávající experimenty a webové služby Machine Learning Studio (klasické). Další informace naleznete v tématu:
- Migrace do Služby Azure Machine Learning z nástroje Machine Learning Studio (Classic)
- Co je Azure Machine Learning?
Dokumentace k nástroji Machine Learning Studio (classic) se vyřadí z provozu a nemusí se v budoucnu aktualizovat.
Tento článek vám pomůže pochopit kanály a aktivity ve službě Azure Data Factory a Azure Synapse Analytics a používat je k vytváření kompletních pracovních postupů řízených daty pro scénáře přesunu a zpracování dat.
Přehled
Pracovní prostor Data Factory nebo Synapse může mít jeden nebo více kanálů. Kanál je logické seskupení aktivit, které společně provádějí úlohu. Kanál může například obsahovat sadu aktivit, které ingestují a čistí data protokolu a pak odstartují mapování toku dat k analýze data protokolu. Kanál umožňuje spravovat aktivity jako sadu, místo toho, abyste je museli spravovat jednotlivě. Místo toho, abyste nezávisle nasazovali a plánovali aktivity, nasadíte a naplánujete kanál.
Aktivity v kanálu definují akce, které se mají s daty provádět. Například můžete použít aktivitu kopírování ke zkopírování dat z SQL Serveru do služby Azure Blob Storage. Pak pomocí aktivity toku dat nebo aktivity poznámkového bloku Databricks můžete zpracovávat a transformovat data z úložiště objektů blob do fondu Azure Synapse Analytics, na kterém se sestavují řešení pro vytváření sestav business intelligence.
Azure Data Factory a Azure Synapse Analytics mají tři skupiny aktivit: aktivity přesunu dat, aktivity transformace dat a aktivity řízení. Každá aktivita může mít nula nebo více vstupních datových sad a může generovat jednu nebo více výstupních datových sad. Následující diagram znázorňuje vztah mezi kanálem, aktivitou a datovou sadou:

Vstupní datová sada představuje vstup pro aktivitu v kanálu a výstupní datová sada představuje výstup aktivity. Datové sady identifikují data v rámci různých úložišť dat, jako jsou tabulky, soubory, složky a dokumenty. Po vytvoření datové sady můžete tuto datovou sadu používat v aktivitách v rámci kanálu. Datová sada například může být vstupní/výstupní datovou sadou aktivity kopírování nebo aktivity HDInsightHive. Další informace o datových sadách najdete v článku Datové sady v Azure Data Factory.
Poznámka:
Existuje výchozí omezení maximálního maximálního počtu 80 aktivit na kanál, který zahrnuje vnitřní aktivity pro kontejnery.
Aktivity přesunu dat
Aktivita kopírování ve službě Data Factory kopíruje data ze zdrojového úložiště dat do úložiště dat jímky. Služba Data Factory podporuje úložiště dat uvedená v tabulce v této části. Data z libovolného zdroje lze zapsat do libovolné jímky.
Další informace najdete v článku Aktivita kopírování – přehled.
Kliknutím na úložiště dat se dozvíte, jak kopírovat data z a do daného úložiště.
Poznámka:
Konektory s označením Preview si můžete vyzkoušet a poskytnout nám k nim zpětnou vazbu. Pokud do svého řešení chcete zavést závislost na konektorech ve verzi Preview, kontaktujte podporu Azure.
Aktivity transformace dat
Azure Data Factory a Azure Synapse Analytics podporují následující aktivity transformace, které je možné přidat jednotlivě nebo zřetězený s jinou aktivitou.
Další informace najdete v článku Aktivity transformace dat.
| Aktivita transformace dat | Výpočetní prostředí |
|---|---|
| Tok dat | Clustery Apache Spark spravované službou Azure Data Factory |
| Funkce Azure Functions | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Streamování Hadoop | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Aktivity nástroje ML Studio (klasické): Dávkové spouštění a aktualizace prostředku | Virtuální počítač Azure |
| Uložená procedura | Azure SQL, Azure Synapse Analytics nebo SQL Server |
| U-SQL | Azure Data Lake Analytics |
| Vlastní aktivita | Azure Batch |
| Poznámkový blok Databricks | Azure Databricks |
| Aktivita Jar databricks | Azure Databricks |
| Aktivita Pythonu v Databricks | Azure Databricks |
| Aktivita poznámkového bloku Synapse | Azure Synapse Analytics |
Aktivity toku řízení
Podporují se následující aktivity toku řízení:
| Aktivita řízení | Popis |
|---|---|
| Připojit proměnnou | Přidejte hodnotu do existující proměnné pole. |
| Spuštění kanálu | Aktivita spuštění kanálu umožňuje kanálu Data Factory nebo Synapse vyvolat jiný kanál. |
| Filtr | Použití výrazu filtru na vstupní pole |
| Pro každou z nich | Aktivita ForEach definuje ve vašem kanálu opakovaný tok řízení. Tato aktivita se používá k opakování v kolekci a spouští zadané aktivity ve smyčce. Smyčková implementace této aktivity se podobá struktuře smyčky Foreach používané v programovacích jazycích. |
| Získání metadat | Aktivita GetMetadata se dá použít k načtení metadat všech dat v kanálu Data Factory nebo Synapse. |
| Aktivita podmínky If | Podmínka If se dá použít k vytvoření větve na základě podmínky, která provádí vyhodnocení na hodnotu True nebo False. Aktivita podmínky If funguje stejně jako příkaz if v programovacích jazycích. Vyhodnotí sadu aktivit, když se podmínka vyhodnotí na true jinou sadu aktivit, když se podmínka vyhodnotí jako false. |
| Aktivita vyhledávání | Aktivita vyhledávání slouží ke čtení nebo vyhledání záznamu / názvu tabulky / hodnoty z jakéhokoli externího zdroje. Na tento výstup mohou dále odkazovat následující aktivity. |
| Nastavit proměnnou | Nastavte hodnotu existující proměnné. |
| Aktivita Until | Implementuje smyčku Do-Until, která se podobá struktuře smyčky Do-Until v programovacích jazycích. Provádí ve smyčce sadu aktivit, dokud se podmínka přidružená k aktivitě nevyhodnotí jako pravdivá. Můžete zadat hodnotu časového limitu pro aktivitu do té doby. |
| Aktivita ověření | Zajistěte, aby kanál pokračoval ve spouštění pouze v případě, že existuje referenční datová sada, splňuje zadaná kritéria nebo byl dosažen časový limit. |
| Aktivita Wait | Pokud v kanálu použijete aktivitu Wait, kanál před pokračováním v provádění následných aktivit počká na zadaný čas. |
| Webová aktivita | Webová aktivita se dá použít k volání vlastního koncového bodu REST z kanálu. Můžete předávat datové sady a propojené služby, které má aktivita používat a ke kterým má mít přístup. |
| Aktivita webhooku | Pomocí aktivity webhooku zavolejte koncový bod a předejte adresu URL zpětného volání. Spuštění kanálu čeká na vyvolání zpětného volání, než přejde k další aktivitě. |
Vytvoření kanálu s uživatelským rozhraním
Pokud chcete vytvořit nový kanál, přejděte v nástroji Data Factory Studio na kartu Autor (reprezentovaná ikonou tužky), klikněte na znaménko plus a v nabídce zvolte Kanál a z podnabídky znovu kanál.
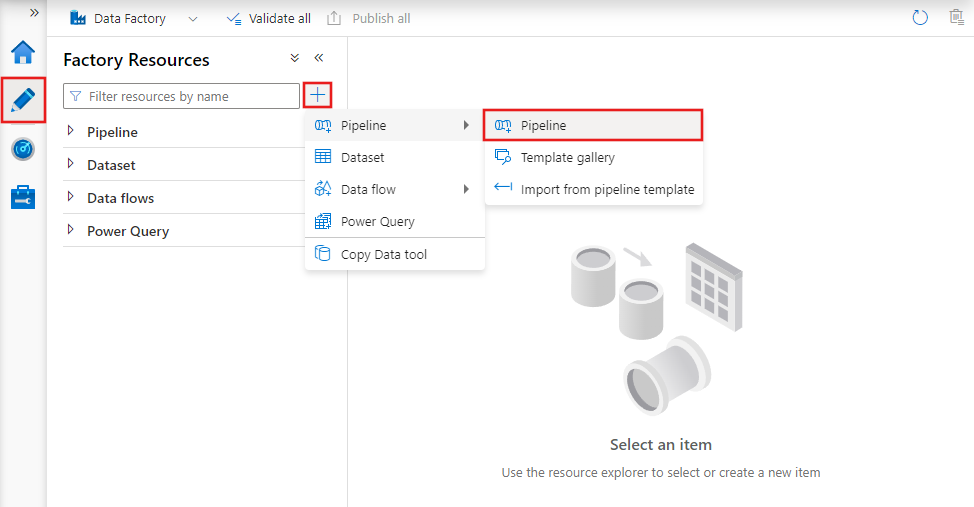
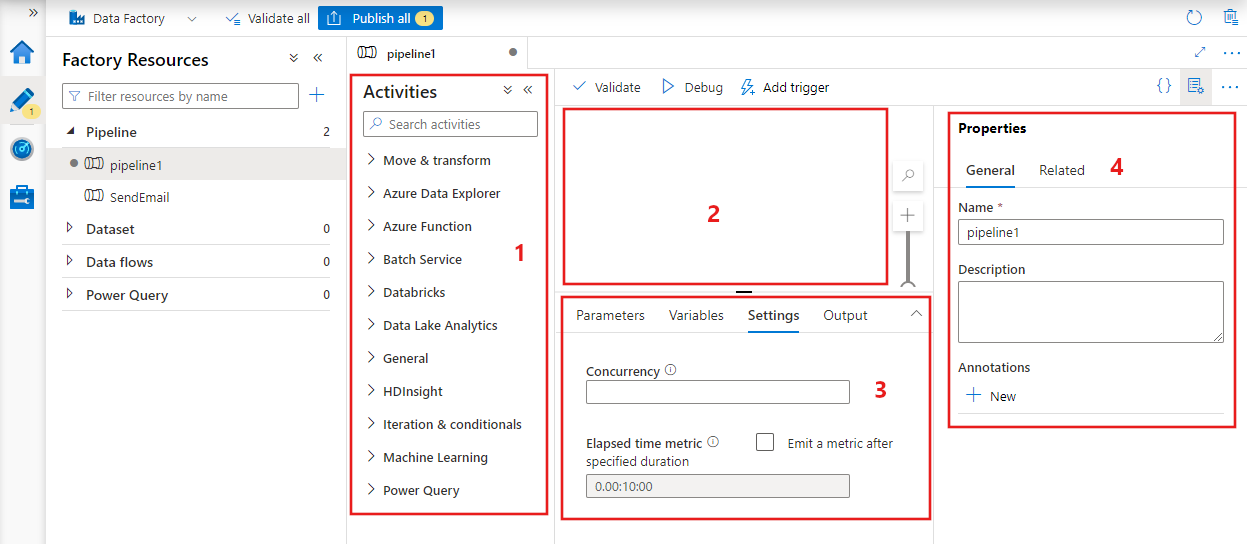
Datová továrna zobrazí editor kanálů, kde můžete najít:
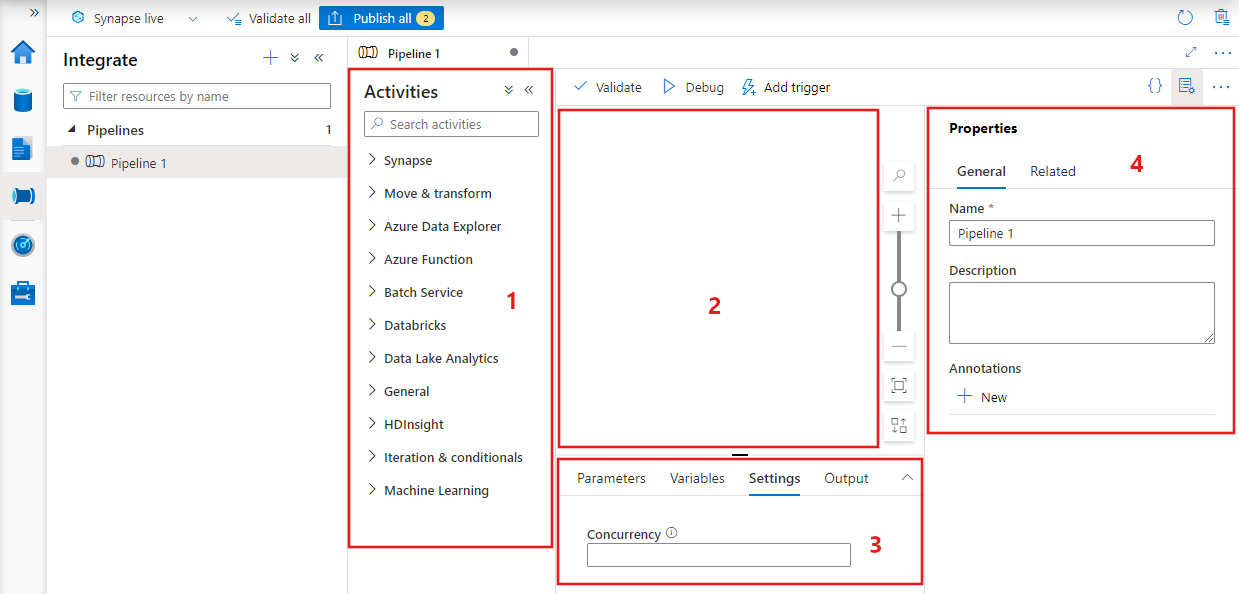
- Všechny aktivity, které lze použít v rámci kanálu.
- Plátno editoru kanálů, kde se při přidání do kanálu zobrazí aktivity.
- Podokno konfigurace kanálu, včetně parametrů, proměnných, obecných nastavení a výstupu.
- Podokno vlastností kanálu, kde je možné nakonfigurovat název kanálu, volitelný popis a poznámky. V tomto podokně se také zobrazí všechny související položky kanálu v datové továrně.
JSON kanálu
Tady je způsob definice kanálu ve formátu JSON:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Značka | Popis | Typ | Požaduje se |
|---|---|---|---|
| name | Název kanálu. Určuje název, který představuje akci prováděnou kanálem.
|
String | Ano |
| description | Určuje text popisující, k čemu se kanál používá. | Řetězcové | No |
| activities | Část activities může obsahovat definici jedné nebo více aktivit. Podrobnosti o elementu activities formátu JSON najdete v části Zápis JSON aktivity. | Pole | Ano |
| parametry | Část parameters může obsahovat definici jednoho nebo více parametrů v kanálu, aby byl kanál flexibilní pro opakované použití. | List | No |
| souběžnost | Maximální počet souběžných spuštění kanálu může mít. Ve výchozím nastavení neexistuje žádné maximum. Pokud dosáhnete limitu souběžnosti, další spuštění kanálu se zařadí do fronty, dokud se nedokončí dřívější spuštění. | Počet | No |
| anotace | Seznam značek přidružených ke kanálu | Pole | No |
Zápis JSON aktivity
Část activities může obsahovat definici jedné nebo více aktivit. Existují dva hlavní typy aktivit: aktivity spuštění a aktivity řízení.
Aktivity spuštění
Aktivity spuštění zahrnují aktivity přesunu dat a transformace dat. Mají následující strukturu nejvyšší úrovně:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
Následující tabulka obsahuje popis vlastností v definici aktivity ve formátu JSON:
| Značka | Popis | Povinní účastníci |
|---|---|---|
| name | Název aktivity. Určuje název, který představuje akci prováděnou danou aktivitou.
|
Ano |
| description | Text popisující, k čemu aktivita slouží. | Ano |
| type | Typ aktivity. Informace o různých typech aktivit najdete v částech Aktivity přesunu dat, Aktivity transformace dat a Aktivity řízení. | Ano |
| linkedServiceName | Název propojené služby používané aktivitou. Aktivita může vyžadovat, abyste zadali propojenou službu, která odkazuje na požadované výpočetní prostředí. |
Ano pro aktivitu HDInsight, aktivitu vyhodnocování dávky ML Studio (classic), aktivitu uložených procedur. Ne ve všech ostatních případech |
| typeProperties | Vlastnosti v části typeProperties závisí na příslušném typu aktivity. Pokud chcete zobrazit vlastnosti typu určité aktivity, klikněte na odkaz na aktivitu v předchozí části. | No |
| policy | Zásady, které ovlivňují chování aktivity za běhu. Tato vlastnost zahrnuje vypršení časového limitu a chování opakování. Pokud není zadaný, použijí se výchozí hodnoty. Další informace najdete v části Zásada aktivity. | No |
| dependsOn | Tato vlastnost slouží k určení závislostí aktivity a toho, jak následující aktivity závisejí na předchozích aktivitách. Další informace najdete v části Závislost aktivit. | No |
Zásady aktivity
Zásady ovlivňují chování aktivity za běhu a poskytují možnosti konfigurace. Zásady aktivit jsou dostupné jenom pro aktivity spuštění.
Definice zásady aktivity ve formátu JSON
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| Název JSON | Popis | Povolené hodnoty | Požaduje se |
|---|---|---|---|
| timeout | Určuje časový limit pro spuštění aktivity. | Časový interval | Ne. Výchozí časový limit je 12 hodin, minimálně 10 minut. |
| retry | Maximální počet opakovaných pokusů. | Celé číslo | Ne. Výchozí hodnota je 0. |
| retryIntervalInSeconds | Prodleva mezi pokusy o opakování v sekundách. | Celé číslo | Ne. Výchozí hodnota je 30 sekund. |
| secureOutput | Pokud je nastavená hodnota true, výstup z aktivity se považuje za zabezpečený a neprotokoluje se pro monitorování. | Logická hodnota | Ne. Výchozí hodnota je False. |
Aktivita řízení
Aktivity řízení mají následující strukturu nejvyšší úrovně:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Značka | Popis | Povinní účastníci |
|---|---|---|
| name | Název aktivity. Určuje název, který představuje akci prováděnou danou aktivitou.
|
Ano |
| description | Text popisující, k čemu aktivita slouží. | Ano |
| type | Typ aktivity. Informace o různých typech aktivit najdete v částech Aktivity přesunu dat, Aktivity transformace dat a Aktivity řízení. | Ano |
| typeProperties | Vlastnosti v části typeProperties závisí na příslušném typu aktivity. Pokud chcete zobrazit vlastnosti typu určité aktivity, klikněte na odkaz na aktivitu v předchozí části. | No |
| dependsOn | Tato vlastnost slouží k určení závislostí aktivity a toho, jak následující aktivity závisejí na předchozích aktivitách. Další informace najdete v části Závislost aktivit. | No |
Závislost aktivit
Závislost aktivity definuje, jak další aktivity závisejí na předchozích aktivitách, a určuje podmínku, zda se má pokračovat v provádění další úlohy. Aktivita může záviset na jedné nebo více předchozích aktivitách s různými podmínkami závislosti.
Existují různé podmínky závislosti: Úspěch, Chyba, Vynecháno, Dokončeno.
Pokud například kanál obsahuje aktivitu A –> Aktivita B, mohou k tomu dojít v různých scénářích:
- Aktivita B má podmínku závislosti na aktivitě A s hodnotou Úspěch: aktivita B se spustí jenom v případě, že má aktivita A konečný stav Úspěch.
- Aktivita B má podmínku závislosti na aktivitě A s hodnotou Chyba: aktivita B se spustí jenom v případě, že má aktivita A konečný stav Chyba.
- Aktivita B má podmínku závislosti na aktivitě A s hodnotou Dokončeno: aktivita B se spustí v případě, že má aktivita A konečný stav Dokončeno.
- Aktivita B má podmínku závislosti na aktivitě A s přeskočenou aktivitou: Aktivita B se spustí, pokud má aktivita A konečný stav vynechání. Vynecháno je ve scénáři aktivity X –> Aktivita Y –> Aktivita Z, kde se každá aktivita spouští pouze v případě, že předchozí aktivita proběhne úspěšně. Pokud aktivita X selže, má aktivita Y stav Vynecháno, protože se nikdy nespustí. Podobně má aktivita Z také stav "Vynecháno".
Příklad: Aktivita 2 závisí na předchozí aktivitě 1.
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Ukázkový kanál kopírování
V následujícím ukázkovém kanálu je v části activities jedna aktivita typu Kopírování. V této ukázce aktivita kopírování kopíruje data z úložiště objektů blob v Azure do databáze ve službě Azure SQL Database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Mějte na paměti následující body:
- V části aktivit je jenom jedna aktivita, jejíž vlastnost type je nastavená na Copy.
- Vstup aktivity je nastavený na InputDataset a výstup aktivity je nastavený na OutputDataset. Informace o definicích datových sad ve formátu JSON najdete v článku Datové sady.
- V části typeProperties je jako typ zdroje určen BlobSource a jako typ jímky SqlSink. Pokud chcete zjistit více informací o přesouvání dat do úložiště dat a z něj, v části Aktivity přesunu dat klikněte na úložiště dat, které chcete použít jako zdroj nebo jímku.
Úplný návod k vytvoření tohoto kanálu najdete v tématu Rychlý start: Vytvoření datové továrny.
Ukázkový kanál transformace
V následujícím ukázkovém kanálu je v části activities jedna aktivita typu HDInsightHive. V této ukázce aktivita HDInsight Hive transformuje data ze služby Azure Blob Storage tak, že v clusteru Azure HDInsight Hadoop spustí soubor skriptu Hive.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Mějte na paměti následující body:
- V části activities je jenom jedna aktivita, jejíž vlastnost type má hodnotu HDInsightHive.
- Soubor skriptu Hive partitionweblogs.hql je uložený v účtu Azure Storage (určený scriptLinkedService, který se nazývá AzureStorageLinkedService) a ve složce skriptu v kontejneru
adfgetstarted. - Část
definesurčuje nastavení běhového prostředí, které se předá skriptu Hive jako konfigurační hodnoty Hive (např. ${hiveconf:inputtable},${hiveconf:partitionedtable}).
Část typeProperties je u každé aktivity transformace odlišná. Další informace o vlastnostech typu podporovaných u aktivit transformace získáte kliknutím na aktivitu transformace v části Aktivity transformace dat.
Kompletní postup vytváření tohoto kanálu najdete v části Kurz: Transformace dat pomocí jazyka Spark.
Více aktivit v kanálu
Oba předchozí ukázkové kanály obsahovaly jenom jednu aktivitu. Kanál může obsahovat víc než jednu aktivitu. Pokud máte v kanálu více aktivit a následné aktivity nejsou závislé na předchozích aktivitách, můžou se aktivity spouštět paralelně.
Dvě aktivity můžete zřetězit pomocí závislosti aktivit, která určuje, jak následující aktivity závisejí na předchozích aktivitách, a stanovuje podmínku určující, jestli se má pokračovat provedením další úlohy. Aktivita může záviset na jedné nebo více předchozích aktivitách s různými podmínkami závislosti.
Plánování kanálů
Kanály se plánují pomocí aktivačních událostí. Existují různé typy aktivačních událostí (trigger Plánovače, který umožňuje aktivaci kanálů podle časového plánu a ruční aktivační události, která aktivuje kanály na vyžádání). Další informace o aktivačních událostech najdete v článku Spouštění kanálů a aktivační události.
Pokud chcete, aby aktivační událost aktivovala spuštění kanálu, musíte do definice aktivační události zahrnout odkaz na příslušný kanál. Mezi kanály a aktivačními událostmi existuje vztah n-m. Více triggerů může aktivovat jeden kanál a jeden trigger může aktivovat více kanálů. Jakmile je aktivační událost definovaná, musíte ji spustit, aby mohla začít aktivovat kanál. Další informace o aktivačních událostech najdete v článku Spouštění kanálů a aktivační události.
Řekněme například, že máte aktivační událost Plánovače A, kterou chci aktivovat kanál MyCopyPipeline. Aktivační událost definujete, jak je znázorněno v následujícím příkladu:
Definice aktivační události Trigger A
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}