VPN aracılığıyla HDInsight'ta Apache Spark uygulamalarında uzaktan hata ayıklamak için IntelliJ için Azure Toolkit'i kullanma
Apache Spark uygulamalarında SSH aracılığıyla uzaktan hata ayıklamanızı öneririz. Yönergeler için bkz . SSH aracılığıyla IntelliJ için Azure Toolkit ile HDInsight kümesinde Apache Spark uygulamalarında uzaktan hata ayıklama.
Bu makalede, HDInsight Spark kümesinde Spark işi göndermek ve ardından masaüstü bilgisayarınızdan uzaktan hata ayıklamak için IntelliJ için Azure Toolkit'te HDInsight Araçları'nı kullanma hakkında adım adım yönergeler sağlanır. Bu görevleri tamamlamak için aşağıdaki üst düzey adımları gerçekleştirmeniz gerekir:
- Siteden siteye veya noktadan siteye Azure sanal ağı oluşturun. Bu belgedeki adımlarda siteden siteye ağ kullandığınız varsayılır.
- HDInsight'ta siteden siteye sanal ağın parçası olan bir Spark kümesi oluşturun.
- Küme baş düğümü ile masaüstünüz arasındaki bağlantıyı doğrulayın.
- IntelliJ IDEA'da bir Scala uygulaması oluşturun ve bunu uzaktan hata ayıklama için yapılandırın.
- Uygulamayı çalıştırın ve uygulamada hata ayıklayın.
Önkoşullar
- Azure aboneliği. Daha fazla bilgi için bkz . Azure'ın ücretsiz deneme sürümünü alma.
- HDInsight'ta Apache Spark kümesi. Yönergeler için bkz. Azure HDInsight'ta Apache Spark kümeleri oluşturma.
- Oracle Java geliştirme seti. Oracle web sitesinden yükleyebilirsiniz.
- IntelliJ IDEA. Bu makalede 2017.1 sürümü kullanılır. JetBrains web sitesinden yükleyebilirsiniz.
- IntelliJ için Azure Toolkit'te HDInsight Araçları. IntelliJ için HDInsight araçları, IntelliJ için Azure Toolkit'in bir parçası olarak kullanılabilir. Azure Toolkit'i yükleme yönergeleri için bkz . IntelliJ için Azure Toolkit'i yükleme.
- IntelliJ IDEA'dan Azure Aboneliğinizde oturum açın. HDInsight kümesi için Apache Spark uygulamaları oluşturmak üzere IntelliJ için Azure Toolkit kullanma başlığı altındaki yönergeleri izleyin.
- Özel durum geçici çözümü. Windows bilgisayarda uzaktan hata ayıklama için Spark Scala uygulamasını çalıştırırken bir özel durumla karşı karşıya olabilirsiniz. Bu özel durum SPARK-2356'da açıklanmıştır ve Windows'ta eksik bir WinUtils.exe dosyası nedeniyle oluşur. Bu hatayı geçici olarak çözmek için Winutils.exe C:\WinUtils\bin gibi bir konuma indirmeniz gerekir. bir HADOOP_HOME ortam değişkeni ekleyin ve değişkenin değerini C\WinUtils olarak ayarlayın.
1. Adım: Azure sanal ağı oluşturma
Bir Azure sanal ağı oluşturmak için aşağıdaki bağlantılardan yönergeleri izleyin ve ardından masaüstü bilgisayarınızla sanal ağ arasındaki bağlantıyı doğrulayın:
- Azure portalını kullanarak siteden siteye VPN bağlantısıyla sanal ağ oluşturma
- PowerShell kullanarak siteden siteye VPN bağlantısıyla sanal ağ oluşturma
- PowerShell kullanarak sanal ağa noktadan siteye bağlantı yapılandırma
2. Adım: HDInsight Spark kümesi oluşturma
Oluşturduğunuz Azure sanal ağının parçası olan Azure HDInsight'ta bir Apache Spark kümesi de oluşturmanızı öneririz. HDInsight'ta Linux tabanlı kümeler oluşturma bölümünde sağlanan bilgileri kullanın. İsteğe bağlı yapılandırmanın bir parçası olarak, önceki adımda oluşturduğunuz Azure sanal ağını seçin.
3. Adım: Küme baş düğümü ile masaüstünüz arasındaki bağlantıyı doğrulama
Baş düğümün IP adresini alın. Küme için Ambari kullanıcı arabirimini açın. Küme dikey penceresinde Pano'yu seçin.
Ambari kullanıcı arabiriminden Konaklar'ı seçin.

Baş düğümlerin, çalışan düğümlerinin ve zookeeper düğümlerinin listesini görürsünüz. Baş düğümlerin bir hn* ön eki vardır. İlk baş düğümü seçin.
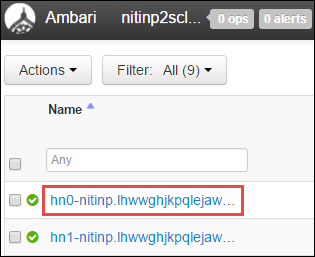
Açılan sayfanın alt kısmındaki Özet bölmesinden baş düğümün IP Adresini ve Ana Bilgisayar Adını kopyalayın.
Spark işini çalıştırmak ve uzaktan hatalarını ayıklamak istediğiniz bilgisayardaki konak dosyasına baş düğümün IP adresini ve ana bilgisayar adını ekleyin. Bu, ana bilgisayar adının yanı sıra IP adresini kullanarak baş düğümle iletişim kurmanızı sağlar.
a. Yükseltilmiş izinlere sahip bir Not Defteri dosyası açın. Dosya menüsünde Aç'ı seçin ve konak dosyasının konumunu bulun. Bir Windows bilgisayarda, konum C:\Windows\System32\Drivers\etc\hosts şeklindedir.
b. Konaklar dosyasına aşağıdaki bilgileri ekleyin:
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netHDInsight kümesi tarafından kullanılan Azure sanal ağına bağladığınız bilgisayardan, ana bilgisayar adının yanı sıra IP adresini kullanarak baş düğümlere ping atabildiğinizi doğrulayın.
SSH kullanarak bir HDInsight kümesine Bağlan yönergeleri izleyerek küme baş düğümüne bağlanmak için SSH kullanın. Küme baş düğümünden masaüstü bilgisayarın IP adresine ping gönderin. Bilgisayara atanan her iki IP adresine bağlantıyı test edin:
- Ağ bağlantısı için bir tane
- Azure sanal ağı için bir tane
Diğer baş düğüm için adımları yineleyin.
4. Adım: IntelliJ için Azure Toolkit'te HDInsight Araçları'nı kullanarak apache Spark Scala uygulaması oluşturma ve uzaktan hata ayıklama için yapılandırma
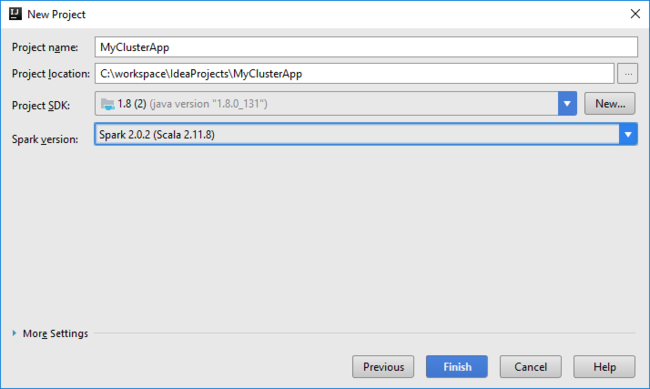
IntelliJ IDEA'ı açın ve yeni bir proje oluşturun. Yeni Proje iletişim kutusunda aşağıdakileri yapın:
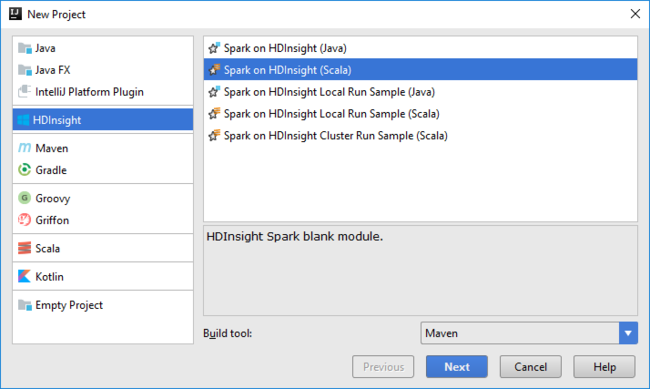
a. HDInsight>HDInsight’ta Spark (Scala) seçeneğini belirleyin.
b. İleri'yi seçin.
Sonraki Yeni Proje iletişim kutusunda aşağıdakileri yapın ve son'u seçin:
Bir proje adı ve konum girin.
Proje SDK’sı açılır listesinde, Spark 2.x kümesi için Java 1.8’i seçin veya Spark 1.x kümesi için Java 1.7’yi seçin.
Spark sürümü açılan listesinde Scala proje oluşturma sihirbazı Spark SDK ve Scala SDK'sı için uygun sürümü tümleştirir. Spark kümesi sürümü 2.0’dan eskiyse Spark 1.x seçeneğini belirleyin. Aksi takdirde, Spark2.x seçeneğini belirleyin. Bu örnek, Spark 2.0.2 (Scala 2.11.8) kullanır.
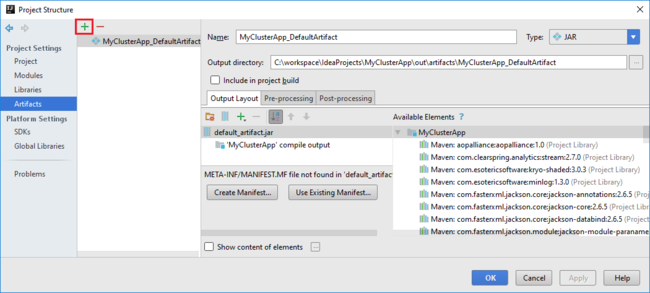
Spark projesi sizin için otomatik olarak bir yapıt oluşturur. Yapıtı görüntülemek için aşağıdakileri yapın:
a. Dosya menüsünden Proje Yapısı’nı seçin.
b. Oluşturulan varsayılan yapıtı görüntülemek için Proje Yapısı iletişim kutusunda Yapıtlar'ı seçin. Artı işaretini (+ ) seçerek kendi yapıtınızı da oluşturabilirsiniz.
Projenize kitaplıklar ekleyin. Kitaplık eklemek için aşağıdakileri yapın:
a. Proje ağacında proje adına sağ tıklayın ve modül Ayarlar Aç'ı seçin.
b. Proje Yapısı iletişim kutusunda Kitaplıklar'ı seçin, (+) simgesini ve ardından Maven'dan'ı seçin.
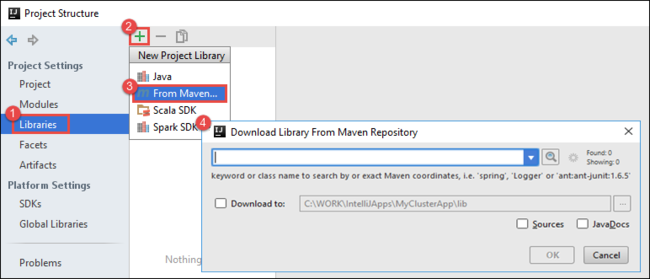
c. Maven Deposundan Kitaplığı İndir iletişim kutusunda aşağıdaki kitaplıkları arayın ve ekleyin:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Küme baş düğümünden ve
core-site.xmlkopyalayıpyarn-site.xmlprojeye ekleyin. Dosyaları kopyalamak için aşağıdaki komutları kullanın. Cygwin'i kullanarak aşağıdakiscpkomutları çalıştırarak küme baş düğümlerinden dosyaları kopyalayabilirsiniz:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Masaüstündeki konaklar dosyası için küme baş düğümü IP adresini ve konak adlarını zaten eklediğimizden, komutları aşağıdaki şekilde kullanabiliriz
scp:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Bu dosyaları projenize eklemek için, bunları proje ağacınızdaki /src klasörünün altına kopyalayın, örneğin
<your project directory>\src.core-site.xmlAşağıdaki değişiklikleri yapmak için dosyayı güncelleştirin:a. Şifrelenmiş anahtarı değiştirin. Dosya,
core-site.xmlkümeyle ilişkilendirilmiş depolama hesabının şifrelenmiş anahtarını içerir. Projeye eklediğiniz dosyadacore-site.xml, şifrelenmiş anahtarı varsayılan depolama hesabıyla ilişkili gerçek depolama anahtarıyla değiştirin. Daha fazla bilgi için bkz . Depolama hesabı erişim anahtarlarını yönetme.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. öğesinden
core-site.xmlaşağıdaki girdileri kaldırın:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Dosyayı kaydedin.
Uygulamanızın ana sınıfını ekleyin. Proje Gezgini'nden src'ye sağ tıklayın, Yeni'nin üzerine gelin ve Scala sınıfı'nı seçin.
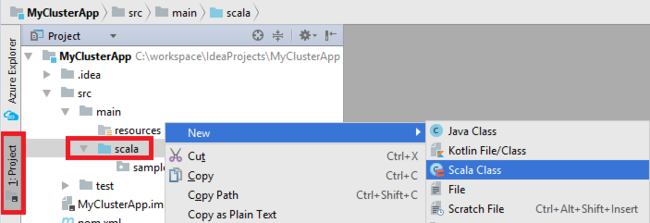
Yeni Scala Sınıfı Oluştur iletişim kutusunda bir ad girin, Tür kutusunda Nesne'yi seçin ve ardından Tamam'ı seçin.
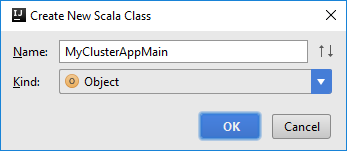
MyClusterAppMain.scalaDosyasına aşağıdaki kodu yapıştırın. Bu kod Spark bağlamını oluşturur ve nesnesindenSparkSamplebirexecuteJobyöntem açar.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }adlı
*SparkSampleyeni bir Scala nesnesi eklemek için 8. ve 9. adımları yineleyin. Aşağıdaki kodu bu sınıfa ekleyin. Bu kod HVAC.csv verileri okur (tüm HDInsight Spark kümelerinde kullanılabilir). CSV dosyasındaki yedinci sütunda yalnızca bir basamak içeren satırları alır ve ardından çıktıyı kümenin varsayılan depolama kapsayıcısı altında /HVACOut dosyasına yazar.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }adlı
RemoteClusterDebuggingyeni bir sınıf eklemek için 8. ve 9. adımları yineleyin. Bu sınıf, uygulamalarda hata ayıklamak için kullanılan Spark test çerçevesini uygular. SınıfınaRemoteClusterDebuggingaşağıdaki kodu ekleyin:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Dikkat edilmesi gereken birkaç önemli nokta vardır:
- için
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")Spark derleme JAR'sinin belirtilen yolda küme depolamada kullanılabilir olduğundan emin olun. - için
setJars, yapıt JAR'sinin oluşturulduğu konumu belirtin. Genellikle , şeklindedir<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar.
- için
*RemoteClusterDebuggingsınıfında anahtar sözcüğünetestsağ tıklayın ve ardından RemoteClusterDebugging Yapılandırması Oluştur'u seçin.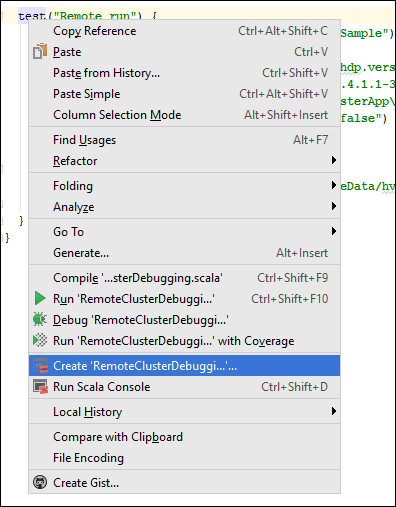
RemoteClusterDebugging Yapılandırması Oluştur iletişim kutusunda yapılandırma için bir ad girin ve test adı olarak Test türü'nü seçin. Diğer tüm değerleri varsayılan ayarlar olarak bırakın. Uygula’yı ve sonra Tamam’ı seçin.
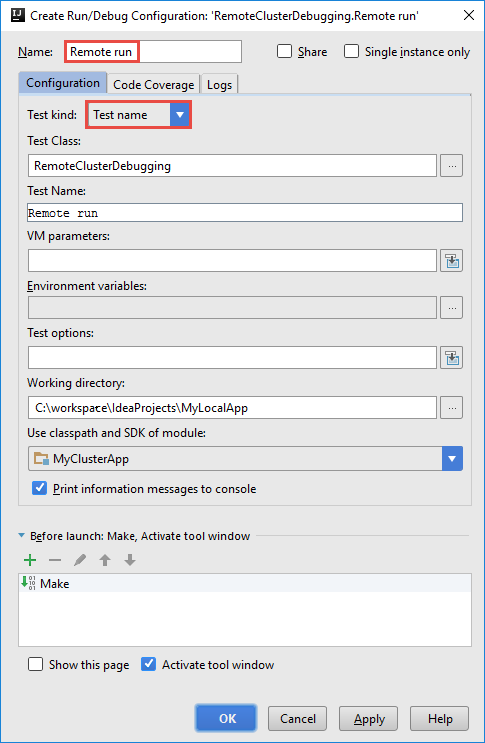
Şimdi menü çubuğunda uzaktan çalıştırma yapılandırması açılan listesini görmeniz gerekir.

5. Adım: Uygulamayı hata ayıklama modunda çalıştırma
IntelliJ IDEA projenizde öğesini açın
SparkSample.scalave yanındaval rdd1bir kesme noktası oluşturun. Açılır menü için Kesme Noktası Oluştur menüsünde executeJob işlevindeki satırı seçin.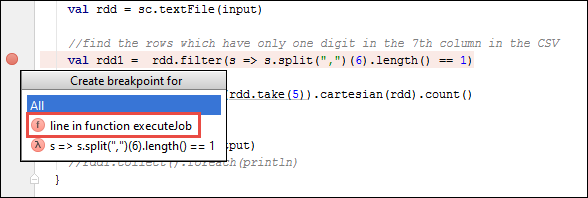
Uygulamayı çalıştırmak için Uzaktan Çalıştırma yapılandırması açılan listesinin yanındaki Çalıştırma hatalarını ayıkla düğmesini seçin.

Program yürütme kesme noktasına ulaştığında, alt bölmede bir Hata Ayıklayıcısı sekmesi görürsünüz.
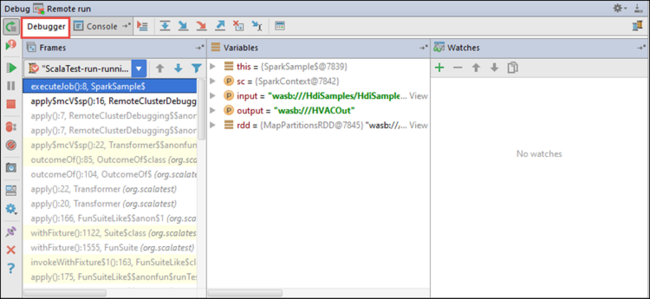
Saat eklemek için (+) simgesini seçin.
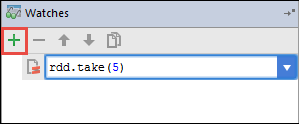
Bu örnekte, değişken
rdd1oluşturulmadan önce uygulama bozuldu. Bu saati kullanarak değişkenindekirddilk beş satırı görebiliriz. Gir'i seçin.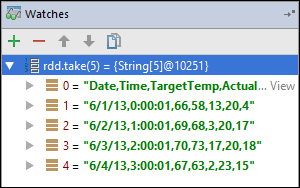
Önceki görüntüde gördüğünüz şey, çalışma zamanında terabaytlar kadar veriyi sorgulayıp uygulamanızın ilerlemesinde hata ayıklaması yapabileceğinizdir. Örneğin, önceki görüntüde gösterilen çıktıda, çıkışın ilk satırının bir üst bilgi olduğunu görebilirsiniz. Bu çıkışa bağlı olarak, gerekirse üst bilgi satırını atlamak için uygulama kodunuzu değiştirebilirsiniz.
Artık uygulama çalıştırmanıza devam etmek için Programı Sürdür simgesini seçebilirsiniz.
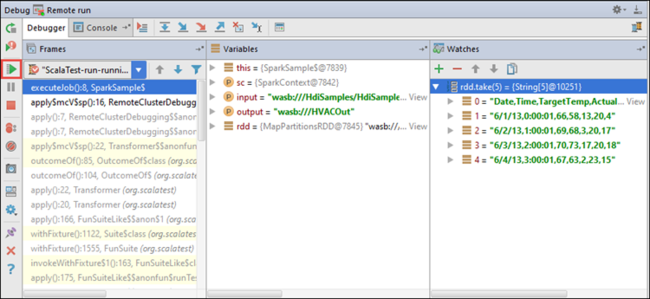
Uygulama başarıyla tamamlanırsa aşağıdaki gibi bir çıktı görmeniz gerekir:
Sonraki adımlar
Senaryolar
- BI ile Apache Spark: BI araçlarıyla HDInsight'ta Spark kullanarak etkileşimli veri analizi gerçekleştirme
- Machine Learning ile Apache Spark: HVAC verilerini kullanarak bina sıcaklığını analiz etmek için HDInsight'ta Spark kullanma
- Machine Learning ile Apache Spark: Gıda denetimi sonuçlarını tahmin etmek için HDInsight'ta Spark kullanma
- HDInsight'ta Apache Spark kullanarak web sitesi günlük analizi
Uygulamaları oluşturma ve çalıştırma
- Scala kullanarak tek başına uygulama oluşturma
- Apache Livy kullanarak apache Spark kümesinde işleri uzaktan çalıştırma
Araçlar ve uzantılar
- HDInsight kümesi için Apache Spark uygulamaları oluşturmak üzere IntelliJ için Azure Toolkit kullanma
- SSH aracılığıyla Apache Spark uygulamalarında uzaktan hata ayıklamak için IntelliJ için Azure Toolkit kullanma
- Apache Spark uygulamaları oluşturmak için Azure Toolkit for Eclipse'te HDInsight Araçları'nı kullanma
- HDInsight'ta Apache Spark kümesiyle Apache Zeppelin not defterlerini kullanma
- HDInsight için Apache Spark kümesinde Jupyter Notebook için kullanılabilir çekirdekler
- Jupyter Notebooks ile dış paketleri kullanma
- Jupyter’i bilgisayarınıza yükleme ve bir HDInsight Spark kümesine bağlanma